Policy-as-Data: Learning Generalizable HOI Diffusion Models from Simulated Physics
Pith reviewed 2026-06-26 09:38 UTC · model grok-4.3
The pith
A pipeline generating HOI training data from reinforcement learning policies in a physics simulator lets diffusion models generalize to unseen objects and long time horizons.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
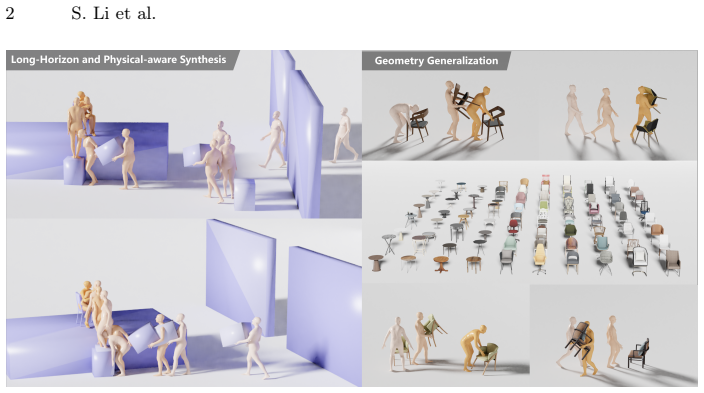
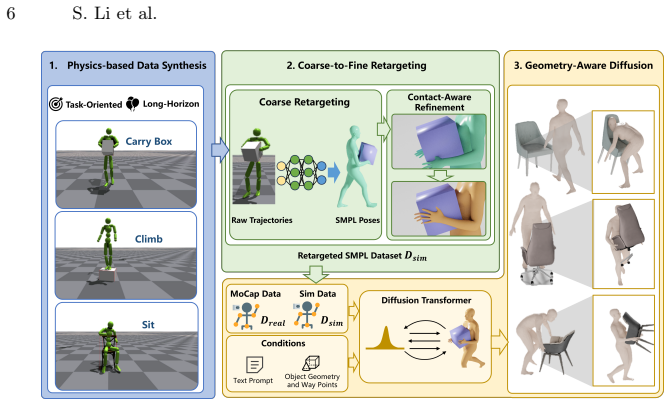
The paper claims that its Policy-as-Data framework, which trains RL policies in a physics simulator to generate task-oriented HOI data and applies a coarse-to-fine retargeting process to match standard parametric body models, trains diffusion models that achieve enhanced generalization to unseen objects, long-horizon generation capability, greater dynamic diversity, and improved physical plausibility.
What carries the argument
The scalable pipeline that trains reinforcement learning policies in a physics simulator to generate synthetic HOI data and uses coarse-to-fine retargeting to align simulator outputs with generative model requirements.
If this is right
- The trained diffusion models can produce interactions with objects absent from any real training data.
- Generated sequences maintain consistency and physical rules across longer time horizons than prior approaches.
- Motions display increased dynamic variety while respecting simulator-derived constraints.
- The method reduces dependence on scaled-up motion capture collections for HOI tasks.
Where Pith is reading between the lines
- The same simulation-driven data generation could apply to training models for multi-person or tool-use scenarios.
- It points toward hybrid pipelines where simulation supplies the bulk of data and limited real captures provide fine-tuning.
- Direct transfer tests onto physical robots would reveal whether the generated motions remain valid outside simulation.
- The framework suggests simulation can systematically address data scarcity across other physics-constrained generative tasks.
Load-bearing premise
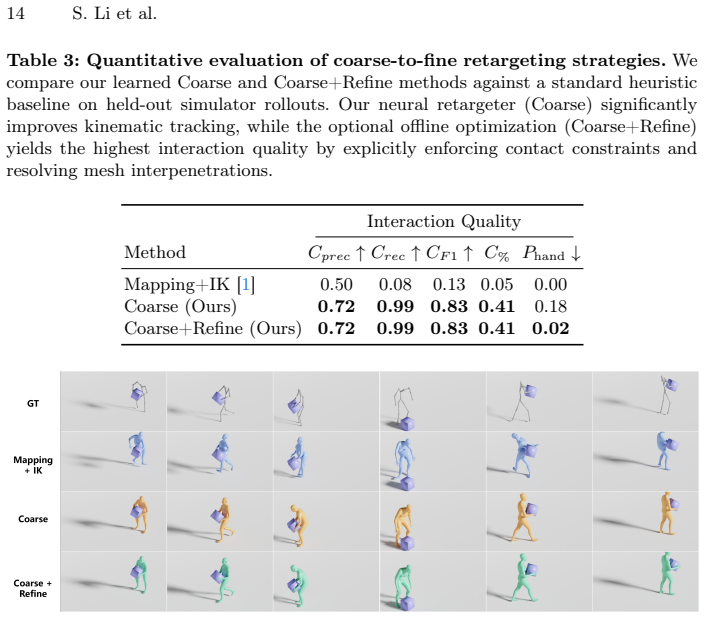
The coarse-to-fine retargeting process accurately maps simplified simulator body representations to standard parametric models while preserving physical validity and task success.
What would settle it
A side-by-side test showing that models trained on the generated data produce more object interpenetrations or lower task completion rates on unseen objects than models trained on motion capture data would falsify the generalization and plausibility claims.
Figures


read the original abstract
Synthesizing realistic Human-Object Interactions (HOI) is critical for creating embodied avatars and functional virtual environments. However, current data-driven approaches primarily rely on motion capture datasets, which are expensive to scale and limited in functional diversity. Models trained with these datasets fail to generalize to unseen objects and maintain physical consistency over long horizons. In this paper, we propose a novel framework that leverages a physics simulator to overcome the data-scarcity bottleneck in HOI generation. Specifically, we propose a scalable pipeline, called \ours, which leverages policies trained with reinforcement learning in a physics simulator for task-oriented data generation and trains a generative model on the augmented dataset for generalizable HOI generation. To seamlessly utilize the synthetic data, we introduce a coarse-to-fine retargeting process that bridges the representation gap between the simplified model used in physics simulator and the standard parametric body models required for generative training. Validated through comprehensive experiments, our method demonstrates enhanced generalization to unseen objects and the capability of long-horizon generation, while exhibiting greater dynamic diversity and physical plausibility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a framework ( exttt{Policy-as-Data}) that trains RL policies inside a physics simulator to produce task-oriented HOI trajectories, applies a coarse-to-fine retargeting step to map the simplified simulator body to standard parametric models, augments existing mocap data with the retargeted trajectories, and trains a diffusion model on the combined corpus, claiming improved generalization to unseen objects, long-horizon generation, greater dynamic diversity, and physical plausibility.
Significance. If the retargeting step demonstrably preserves contact dynamics and long-term consistency, the simulation-driven data pipeline would offer a scalable route to overcoming the limited functional diversity of motion-capture datasets for HOI generation.
major comments (2)
- [coarse-to-fine retargeting description] The coarse-to-fine retargeting process is introduced precisely to close the representation gap between the simulator body and parametric models required for diffusion training, yet the manuscript supplies no quantitative validation (contact-force error, penetration statistics, kinematic fidelity, or velocity preservation metrics) that the retargeted sequences retain the task-oriented properties optimized by the RL policies. This validation is load-bearing for the central claim of improved physical plausibility and generalization.
- [experimental validation] The abstract states that "comprehensive experiments" support enhanced generalization to unseen objects and long-horizon generation, but the provided text contains no reported metrics, baselines, ablation studies, or error analysis, preventing assessment of whether the claimed advantages are realized.
minor comments (1)
- [abstract] The acronym exttt{\\{ours}} is used in the abstract without an explicit expansion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments highlight important gaps in validation and reporting that we will address in the revision. We respond to each point below.
read point-by-point responses
-
Referee: [coarse-to-fine retargeting description] The coarse-to-fine retargeting process is introduced precisely to close the representation gap between the simulator body and parametric models required for diffusion training, yet the manuscript supplies no quantitative validation (contact-force error, penetration statistics, kinematic fidelity, or velocity preservation metrics) that the retargeted sequences retain the task-oriented properties optimized by the RL policies. This validation is load-bearing for the central claim of improved physical plausibility and generalization.
Authors: We agree that quantitative validation of the retargeting step is necessary to substantiate claims of preserved task-oriented dynamics and physical plausibility. The current manuscript does not include these metrics. In the revised version we will add contact-force error, penetration statistics, kinematic fidelity, and velocity preservation metrics comparing retargeted trajectories to the original simulator outputs, along with analysis showing retention of RL-optimized properties. revision: yes
-
Referee: [experimental validation] The abstract states that "comprehensive experiments" support enhanced generalization to unseen objects and long-horizon generation, but the provided text contains no reported metrics, baselines, ablation studies, or error analysis, preventing assessment of whether the claimed advantages are realized.
Authors: We acknowledge that the manuscript text as provided lacks the detailed experimental metrics, baselines, ablations, and error analysis referenced in the abstract. This is a reporting omission. The revised manuscript will include a full experimental section with quantitative results, baseline comparisons, ablation studies, and error analysis to support the claims of improved generalization, long-horizon generation, dynamic diversity, and physical plausibility. revision: yes
Circularity Check
No circularity; pipeline is externally grounded.
full rationale
The paper presents an engineering pipeline that generates synthetic HOI trajectories via RL policies inside an external physics simulator, applies a coarse-to-fine retargeting step to map simplified bodies onto parametric models, and then trains a diffusion model on the resulting dataset. No equations, fitted parameters, or self-citations are shown that would make any claimed prediction or generalization result equivalent to its own inputs by construction. The retargeting procedure is introduced as an independent preprocessing choice rather than a self-defining or load-bearing assumption, and the central claims rest on the simulator and RL components being independent of the diffusion stage. This is the normal case of a self-contained applied method without circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Computer Graphics Forum
Aristidou, A., Lasenby, J., Chrysanthou, Y., Shamir, A.: Inverse kinematics tech- niques in computer graphics: A survey. In: Computer Graphics Forum. vol. 37(6), pp. 35–58 (2018)
2018
-
[2]
In: SIGGRAPH Asia 2024 Conference Papers
Bar-Tal, O., Chefer, H., Tov, O., Herrmann, C., Paiss, R., Zada, S., Ephrat, A., Hur, J., Liu, G., Raj, A., et al.: Lumiere: A space-time diffusion model for video generation. In: SIGGRAPH Asia 2024 Conference Papers. pp. 1–11 (2024)
2024
-
[3]
In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion
Bhatnagar, B.L., Xie, X., Petrov, I.A., Sminchisescu, C., Theobalt, C., Pons-Moll, G.: Behave: Dataset and method for tracking human object interactions. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion. pp. 15935–15946 (2022)
2022
-
[4]
arXiv preprint arXiv:2311.15127 (2023)
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023)
Pith/arXiv arXiv 2023
-
[5]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Cong, P., Wang, Z., Ma, Y., Yue, X.: Semgeomo: Dynamic contextual human motion generation with semantic and geometric guidance. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 17561–17570 (2025)
2025
-
[6]
In: The Fourteenth Inter- national Conference on Learning Representations (2026),https://openreview
Deng, Z., Shi, Y., Ji, K., Xu, L., Huang, S., Wang, J.: Human-object interaction via automatically designed VLM-guided motion policy. In: The Fourteenth Inter- national Conference on Learning Representations (2026),https://openreview. net/forum?id=LfkPlFTfe0
2026
-
[7]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Diller, C., Dai, A.: Cg-hoi: Contact-guided 3d human-object interaction generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19888–19901 (2024)
2024
-
[8]
arXiv preprint arXiv:2309.11351 (2023)
Dou, Z., Chen, X., Fan, Q., Komura, T., Wang, W.: C·ase: Learning condi- tional adversarial skill embeddings for physics-based characters. arXiv preprint arXiv:2309.11351 (2023)
arXiv 2023
-
[9]
In: Forty-first international conference on machine learning (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024)
2024
-
[10]
In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion
Fan, Z., Taheri, O., Tzionas, D., Kocabas, M., Kaufmann, M., Black, M.J., Hilliges, O.: Arctic: A dataset for dexterous bimanual hand-object manipulation. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion. pp. 12943–12954 (2023)
2023
-
[11]
In: Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., Zhang, C
Gao, J., Wang, Z., Xiao, Z., Wang, J., Wang, T., Cao, J., Hu, X., Liu, S., Dai, J., Pang, J.: Coohoi: Learning cooperative human-object interaction with 16 S. Li et al. manipulated object dynamics. In: Advances in Neural Information Process- ing Systems. pp. 79741–79763 (2024).https://doi.org/10.52202/079017- 2532,https : / / proceedings . neurips . cc / ...
-
[12]
Geng, Z., Hayder, Z., Liu, W., Mian, A.S.: Auto-regressive diffusion for generating 3dhuman-objectinteractions.In:ProceedingsoftheAAAIConferenceonArtificial Intelligence. vol. 39, pp. 3131–3139 (2025)
2025
-
[13]
In: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision
Hassan, M., Ceylan, D., Villegas, R., Saito, J., Yang, J., Zhou, Y., Black, M.J.: Stochastic scene-aware motion prediction. In: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision. pp. 11374–11384 (2021)
2021
-
[14]
In: Proceedings of the IEEE/CVF international conference on computer vision
Hassan, M., Choutas, V., Tzionas, D., Black, M.J.: Resolving 3d human pose ambi- guities with 3d scene constraints. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 2282–2292 (2019)
2019
-
[15]
InACM SIGGRAPH 2023 Conference Proceedings
Hassan, M., Guo, Y., Wang, T., Black, M., Fidler, S., Peng, X.B.: Synthesiz- ing physical character-scene interactions. In: ACM SIGGRAPH 2023 Confer- ence Proceedings. SIGGRAPH ’23, Association for Computing Machinery, New York, NY, USA (2023).https://doi.org/10.1145/3588432.3591525,https: //doi.org/10.1145/3588432.3591525
-
[16]
arXiv preprint arXiv:2210.02303 (2022)
Ho, J., Chan, W., Saharia, C., Whang, J., Gao, R., Gritsenko, A., Kingma, D.P., Poole, B., Norouzi, M., Fleet, D.J., et al.: Imagen video: High definition video generation with diffusion models. arXiv preprint arXiv:2210.02303 (2022)
Pith/arXiv arXiv 2022
-
[17]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[18]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, S., Wang, Z., Li, P., Jia, B., Liu, T., Zhu, Y., Liang, W., Zhu, S.C.: Diffusion-based generation, optimization, and planning in 3d scenes. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16750–16761 (2023)
2023
-
[19]
Huang, Y., Taheri, O., Black, M.J., Tzionas, D.: InterCap: Joint Markerless 3D Tracking of Humans and Objects in Interaction from Multi-view RGB-D Images. International Journal of Computer Vision132(7), 2551–2566 (Jul 2024).https: //doi.org/10.1007/s11263-024-01984-1,https://doi.org/10.1007/s11263- 024-01984-1
-
[20]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Ji, B., Pan, Y., Liu, Z., Tan, S., Jin, X., Yang, X.: Pomp: Physics-consistent motion generative model through phase manifolds. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 22690–22701 (2025)
2025
-
[21]
In: Proceedings of European Conference on Computer Vision
Jiang, J., Streli, P., Qiu, H., Fender, A., Laich, L., Snape, P., Holz, C.: Avatarposer: Articulated full-body pose tracking from sparse motion sensing. In: Proceedings of European Conference on Computer Vision. Springer (2022)
2022
-
[22]
In: ICCV (2023)
Jiang, N., Liu, T., Cao, Z., Cui, J., Chen, Y., Wang, H., Zhu, Y., Huang, S.: Full-body articulated human-object interaction. In: ICCV (2023)
2023
-
[23]
In: European Conference on Computer Vision
Li, J., Clegg, A., Mottaghi, R., Wu, J., Puig, X., Liu, C.K.: Controllable human- object interaction synthesis. In: European Conference on Computer Vision. pp. 54–72. Springer (2024)
2024
-
[24]
ACM Transactions on Graphics (TOG)42(6), 1–11 (2023)
Li, J., Wu, J., Liu, C.K.: Object motion guided human motion synthesis. ACM Transactions on Graphics (TOG)42(6), 1–11 (2023)
2023
-
[25]
arXiv preprint arXiv:2506.15483 (2025)
Li, S., Zhang, H., Chen, X., Wang, Y., Ban, Y.: Genhoi: Generalizing text- driven 4d human-object interaction synthesis for unseen objects. arXiv preprint arXiv:2506.15483 (2025)
arXiv 2025
-
[26]
arXiv (2025) Abbreviated paper title 17
Lin, Y., Xie, Y., Xie, J., Huang, Y., Wang, R., Lv, J., Ma, Y., Zuo, X.: Sim- genhoi: Physically realistic whole-body humanoid-object interaction via generative modeling and reinforcement learning. arXiv (2025) Abbreviated paper title 17
2025
-
[27]
In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference
Liu, Y., Zhang, C., Xing, R., Tang, B., Yang, B., Yi, L.: Core4d: A 4d human- object-human interaction dataset for collaborative object rearrangement. In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference. pp. 1769– 1782 (2025)
2025
-
[28]
In: Seminal Graphics Papers: Pushing the Boundaries, Volume 2
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., Black, M.J.: Smpl: A skinned multi-person linear model. In: Seminal Graphics Papers: Pushing the Boundaries, Volume 2. Association for Computing Machinery, New York, NY, USA, 1 edn. (2023),https://doi.org/10.1145/3596711.3596800
-
[29]
arXiv preprint arXiv:2503.20118 (2025)
Lou, Y., Wang, Y., Wu, Z., Zhao, R., Wang, W., Shi, M., Komura, T.: Zero- shot human-object interaction synthesis with multimodal priors. arXiv preprint arXiv:2503.20118 (2025)
arXiv 2025
-
[30]
ACM Transactions on Graphics45(2), 1–18 (2025)
Lu, J., Zhang, H., Ye, Y., Shiratori, T., Starke, S., Komura, T.: Choice: Coordi- nated human-object interaction in cluttered environments for pick-and-place ac- tions. ACM Transactions on Graphics45(2), 1–18 (2025)
2025
-
[31]
Advances in Neural Information Processing Systems37, 2161–2184 (2024)
Luo, Z., Cao, J., Christen, S., Winkler, A., Kitani, K., Xu, W.: Omnigrasp: Grasp- ing diverse objects with simulated humanoids. Advances in Neural Information Processing Systems37, 2161–2184 (2024)
2024
-
[32]
Luo, Z., Cao, J., Kitani, K., Xu, W., et al.: Perpetual humanoid control for real- timesimulatedavatars.In:ProceedingsoftheIEEE/CVFInternationalConference on Computer Vision. pp. 10895–10904 (2023)
2023
-
[33]
In: The Twelfth Inter- national Conference on Learning Representations (2024),https://openreview
Luo, Z., Cao, J., Merel, J., Winkler, A., Huang, J., Kitani, K.M., Xu, W.: Universal humanoid motion representations for physics-based control. In: The Twelfth Inter- national Conference on Learning Representations (2024),https://openreview. net/forum?id=OrOd8PxOO2
2024
-
[34]
In: Advances in Neural Information Processing Systems (2021)
Luo, Z., Hachiuma, R., Yuan, Y., Kitani, K.: Dynamics-regulated kinematic pol- icy for egocentric pose estimation. In: Advances in Neural Information Processing Systems (2021)
2021
-
[35]
In: Advances in Neural Information Processing Systems (2022)
Luo, Z., Iwase, S., Yuan, Y., Kitani, K.: Embodied scene-aware human pose esti- mation. In: Advances in Neural Information Processing Systems (2022)
2022
-
[36]
Luo, Z., Yuan, Y., Kitani, K.M.: From universal humanoid control to automatic physically valid character creation. ArXivabs/2206.09286(2022)
arXiv 2022
-
[37]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Pan, L., Yang, Z., Dou, Z., Wang, W., Huang, B., Dai, B., Komura, T., Wang, J.: Tokenhsi: Unified synthesis of physical human-scene interactions through task tokenization. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5379–5391 (2025)
2025
-
[38]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Pavlakos, G., Choutas, V., Ghorbani, N., Bolkart, T., Osman, A.A., Tzionas, D., Black, M.J.: Expressive body capture: 3d hands, face, and body from a single im- age. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10975–10985 (2019)
2019
-
[39]
arXiv preprint arXiv:2312.06553 (2023)
Peng, X., Xie, Y., Wu, Z., Jampani, V., Sun, D., Jiang, H.: Hoi-diff: Text-driven synthesis of 3d human-object interactions using diffusion models. arXiv preprint arXiv:2312.06553 (2023)
arXiv 2023
-
[40]
arXiv preprint arXiv:2510.13794 (2025),https://arxiv.org/abs/ 2510.13794
Peng, X.B.: Mimickit: A reinforcement learning framework for motion imitation and control. arXiv preprint arXiv:2510.13794 (2025),https://arxiv.org/abs/ 2510.13794
arXiv 2025
-
[41]
ACM Transactions On Graphics (TOG)37(4), 1–14 (2018)
Peng, X.B., Abbeel, P., Levine, S., Van de Panne, M.: Deepmimic: Example-guided deep reinforcement learning of physics-based character skills. ACM Transactions On Graphics (TOG)37(4), 1–14 (2018)
2018
-
[42]
Li et al
Peng, X.B., Guo, Y., Halper, L., Levine, S., Fidler, S.: Ase: Large-scale reusable adversarialskillembeddingsforphysicallysimulatedcharacters.ACMTransactions On Graphics (TOG)41(4), 1–17 (2022) 18 S. Li et al
2022
-
[43]
ACM Transactions on Graphics (ToG)40(4), 1–20 (2021)
Peng, X.B., Ma, Z., Abbeel, P., Levine, S., Kanazawa, A.: Amp: Adversarial motion priors for stylized physics-based character control. ACM Transactions on Graphics (ToG)40(4), 1–20 (2021)
2021
-
[44]
arXiv preprint arXiv:2209.14988 (2022)
Poole, B., Jain, A., Barron, J.T., Mildenhall, B.: Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988 (2022)
Pith/arXiv arXiv 2022
-
[45]
In: Proceedings of the IEEE/CVF international conference on computer vision
Prokudin, S., Lassner, C., Romero, J.: Efficient learning on point clouds with basis point sets. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4332–4341 (2019)
2019
-
[46]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[47]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[48]
arXiv preprint arXiv:2201.02610 (2022)
Romero, J., Tzionas, D., Black, M.J.: Embodied hands: Modeling and capturing hands and bodies together. arXiv preprint arXiv:2201.02610 (2022)
arXiv 2022
-
[49]
Advances in neural information processing systems35, 36479–36494 (2022)
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E.L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan, B., Salimans, T., et al.: Photorealistic text- to-image diffusion models with deep language understanding. Advances in neural information processing systems35, 36479–36494 (2022)
2022
-
[50]
In: ACM SIGGRAPH Asia 2025 Conference Proceedings (2025)
Tessler, C., Jiang, Y., Coumans, E., Luo, Z., Chechik, G., Peng, X.B.: Masked- manipulator: Versatile whole-body manipulation. In: ACM SIGGRAPH Asia 2025 Conference Proceedings (2025)
2025
-
[51]
In: ACM SIGGRAPH 2023 conference proceedings
Tessler, C., Kasten, Y., Guo, Y., Mannor, S., Chechik, G., Peng, X.B.: Calm: Conditional adversarial latent models for directable virtual characters. In: ACM SIGGRAPH 2023 conference proceedings. pp. 1–9 (2023)
2023
-
[52]
arXiv preprint arXiv:2410.03441 (2024)
Tevet, G., Raab, S., Cohan, S., Reda, D., Luo, Z., Peng, X.B., Bermano, A.H., van de Panne, M.: Closd: Closing the loop between simulation and diffusion for multi-task character control. arXiv preprint arXiv:2410.03441 (2024)
arXiv 2024
-
[53]
In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=SJ1kSyO2jwu
Tevet, G., Raab, S., Gordon, B., Shafir, Y., Cohen-or, D., Bermano, A.H.: Human motion diffusion model. In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=SJ1kSyO2jwu
2023
-
[54]
Npga: Neural parametric gaussian avatars
Truong, T.E., Piseno, M., Xie, Z., Liu, K.: Pdp: Physics-based character animation via diffusion policy. SA ’24, Association for Computing Machinery, New York, NY, USA (2024).https://doi.org/10.1145/3680528.3687683,https://doi.org/ 10.1145/3680528.3687683
-
[55]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, Y., Zhao, Q., Yu, R., Tsui, H.W., Zeng, A., Lin, J., Luo, Z., Yu, J., Li, X., Chen, Q., et al.: Skillmimic: Learning basketball interaction skills from demon- strations. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 17540–17549 (2025)
2025
-
[56]
Advances in Neural Informa- tion Processing Systems35, 14959–14971 (2022)
Wang, Z., Chen, Y., Liu, T., Zhu, Y., Liang, W., Huang, S.: Humanise: Language- conditioned human motion generation in 3d scenes. Advances in Neural Informa- tion Processing Systems35, 14959–14971 (2022)
2022
-
[57]
arXiv preprint arXiv:2403.11208 (2024)
Wu, Q., Shi, Y., Huang, X., Yu, J., Xu, L., Wang, J.: Thor: Text to human-object interaction diffusion via relation intervention. arXiv preprint arXiv:2403.11208 (2024)
arXiv 2024
-
[58]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2025) Abbreviated paper title 19
Wu, Y., Karunratanakul, K., Luo, Z., Tang, S.: Uniphys: Unified planner and con- troller with diffusion for flexible physics-based character control. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2025) Abbreviated paper title 19
2025
-
[59]
In: Proceedings of the IEEE/CVF International Conference on Com- puter Vision (ICCV) (October 2025)
Wu, Z., Li, J., Xu, P., Liu, C.K.: Human-object interaction from human-level in- structions. In: Proceedings of the IEEE/CVF International Conference on Com- puter Vision (ICCV) (October 2025)
2025
-
[60]
In: The Twelfth Interna- tional Conference on Learning Representations (2024),https://openreview.net/ forum?id=1vCnDyQkjg
Xiao, Z., Wang, T., Wang, J., Cao, J., Zhang, W., Dai, B., Lin, D., Pang, J.: Unified human-scene interaction via prompted chain-of-contacts. In: The Twelfth Interna- tional Conference on Learning Representations (2024),https://openreview.net/ forum?id=1vCnDyQkjg
2024
-
[61]
In: Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers
Xu, M., Shi, Y., Yin, K., Peng, X.B.: Parc: Physics-based augmentation with rein- forcement learning for character controllers. In: Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers. pp. 1–11 (2025)
2025
-
[62]
ACM Transactions on Graphics42(6) (2023).https://doi.org/10.1145/3618375
Xu, P., Xie, K., Andrews, S., Kry, P.G., Neff, M., McGuire, M., Karamouzas, I., Zordan, V.: AdaptNet: Policy adaptation for physics-based character control. ACM Transactions on Graphics42(6) (2023).https://doi.org/10.1145/3618375
-
[63]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xu, S., Li, D., Zhang, Y., Xu, X., Long, Q., Wang, Z., Lu, Y., Dong, S., Jiang, H., Gupta, A., etal.:Interact: Advancing large-scaleversatile 3dhuman-object interac- tion generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 7048–7060 (2025)
2025
-
[64]
In: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision
Xu, S., Li, Z., Wang, Y.X., Gui, L.Y.: Interdiff: Generating 3d human-object in- teractions with physics-informed diffusion. In: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision. pp. 14928–14940 (2023)
2023
-
[65]
Yang, J., Niu, X., Jiang, N., Zhang, R., Huang, S.: F-hoi: Toward fine-grained semantic-aligned 3d human-object interactions (2024),https://arxiv.org/abs/ 2407.12435
arXiv 2024
-
[66]
In: European Conference on Computer Vision
Yi, H., Thies, J., Black, M.J., Peng, X.B., Rempe, D.: Generating human interac- tion motions in scenes with text control. In: European Conference on Computer Vision. pp. 246–263. Springer (2024)
2024
-
[67]
arXiv preprint arXiv:2310.085292(3), 5 (2023)
Yi, T., Fang, J., Wu, G., Xie, L., Zhang, X., Liu, W., Tian, Q., Wang, X.: Gaus- siandreamer: Fast generation from text to 3d gaussian splatting with point cloud priors. arXiv preprint arXiv:2310.085292(3), 5 (2023)
arXiv 2023
-
[68]
In: Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers
Yu,R.,Wang,Y.,Zhao,Q.,Tsui,H.W.,Wang,J.,Tan,P.,Chen,Q.:Skillmimic-v2: Learning robust and generalizable interaction skills from sparse and noisy demon- strations. In: Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers. pp. 1–11 (2025)
2025
-
[69]
In: Proceedings of the IEEE/CVF international con- ference on computer vision
Yuan, Y., Song, J., Iqbal, U., Vahdat, A., Kautz, J.: Physdiff: Physics-guided hu- man motion diffusion model. In: Proceedings of the IEEE/CVF international con- ference on computer vision. pp. 16010–16021 (2023)
2023
-
[70]
arXiv preprint arXiv:2506.12769 (2025)
Yue, J., Wang, Z., Wang, Y., Zeng, W., Wang, J., Xu, X., Zhang, Y., Zheng, S., Ding, Z., Lu, Z.: Rl from physical feedback: Aligning large motion models with humanoid control. arXiv preprint arXiv:2506.12769 (2025)
arXiv 2025
-
[71]
arXiv preprint arXiv:2503.13130 (2025)
Zeng, L.A., Huang, G., Wei, Y.L., Gu, S., Tang, Y.M., Meng, J., Zheng, W.S.: Chainhoi: Joint-based kinematic chain modeling for human-object interaction gen- eration. arXiv preprint arXiv:2503.13130 (2025)
arXiv 2025
-
[72]
Zhang, H., Chen, X., Wang, Y., Liu, X., Wang, Y., Qiao, Y.: 4diffusion: Multi-view videodiffusionmodelfor4dgeneration.AdvancesinNeuralInformationProcessing Systems37, 15272–15295 (2024)
2024
-
[73]
A person approaches a chair/box/table, picks it up, and places it in the designated location
Zhang, X., Bhatnagar, B.L., Starke, S., Guzov, V., Pons-Moll, G.: Couch: Towards controllable human-chair interactions. In: European Conference on Computer Vi- sion. pp. 518–535. Springer (2022) 20 S. Li et al. Policy-as-Data: Learning Generalizable HOI Diffusion Models from Simulated Physics Supplementary A Expert Policy Training This section details the...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.