Bagpiper-TTS: Natural Language Guided Universal Speech Synthesis
Pith reviewed 2026-06-26 08:52 UTC · model grok-4.3
The pith
Bagpiper-TTS converts natural language prompts into speech by first reasoning over intent to build a detailed caption that then guides synthesis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
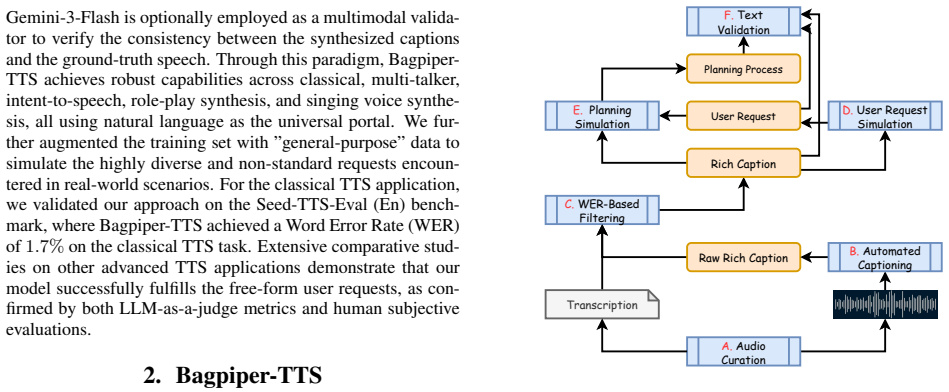
Bagpiper-TTS first reasons over a natural language prompt to derive a comprehensive caption that encodes transcription together with nuanced metadata, then uses that caption to direct the synthesis of the target speech, thereby supporting classical TTS and a wide range of additional applications within a single model.
What carries the argument
The reasoning module that extracts a rich caption from the natural language prompt to serve as the textual blueprint for synthesis.
If this is right
- A single trained model can perform classical TTS, multi-talker synthesis, singing voice synthesis, role-play, and intent-to-speech without separate fine-tuning for each task.
- Performance reaches 1.7 percent WER on the Seed-TTS-Eval benchmark while matching dedicated models in LLM-as-a-judge and human evaluations.
- The caption acts as an interpretable intermediate representation that decouples intent understanding from acoustic rendering.
Where Pith is reading between the lines
- The separation of reasoning and synthesis stages may allow independent improvement of either component without retraining the entire system.
- Because the caption is produced in natural language, users could inspect or edit it before synthesis to correct intent mismatches.
- The same caption-guided approach could be tested on related audio generation problems such as sound-effect creation or music continuation.
Load-bearing premise
The reasoning module can reliably extract every transcription and metadata detail required for high-quality synthesis directly from the natural language prompt without task-specific fine-tuning or extra supervision.
What would settle it
A controlled test set of natural language prompts whose required speaker, style, or emotion details are only implied indirectly; if the generated captions systematically omit those details and the resulting audio fails to match human expectations, the central claim is falsified.
Figures



read the original abstract
Classical TTS systems typically rely on rigid input formats and predefined metadata slots, limiting their ability to fulfill flexible user requirements. This paper introduces Bagpiper-TTS, a universal speech synthesis system that deals with diverse natural language user requests. Given a natural language prompt, Bagpiper-TTS first reasons over the users' intent to derive a rich caption, i.e., a comprehensive textual blueprint encompassing both transcription and nuanced metadata. Subsequently, this caption guides the synthesis of the target speech. Our model inherently supports a broad spectrum of tasks besides classical TTS applications, including multi-talker, intent-to-speech, role-play synthesis, singing voice synthesis, and more. Experimental results demonstrate that Bagpiper-TTS achieves an 1.7% Word Error Rate (WER) on the Seed-TTS-Eval benchmark and match the performance of dedicated models in both LLM-as-a-judge and human subjective evaluations across multiple applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Bagpiper-TTS, a universal speech synthesis system that processes arbitrary natural-language user prompts by first applying a reasoning module to derive a rich caption (encoding both exact transcription and metadata such as speaker, emotion, style, pitch, and singing instructions) and then using this caption to guide speech synthesis. The system is claimed to inherently support a broad range of tasks including classical TTS, multi-talker synthesis, intent-to-speech, role-play, and singing voice synthesis. Experimental results are stated to show 1.7% WER on the Seed-TTS-Eval benchmark while matching the performance of dedicated task-specific models in both LLM-as-a-judge and human subjective evaluations.
Significance. If the central claims are substantiated with full methodological detail and ablations, the work would be significant for the field by demonstrating a single model capable of flexible, natural-language-driven synthesis across diverse applications, potentially reducing reliance on rigid input formats and task-specific fine-tuning in TTS systems.
major comments (2)
- [Methods / pipeline description] The universality claim rests entirely on the reasoning module's ability to extract a comprehensive caption that encodes all required transcription and metadata nuances without task-specific fine-tuning or additional supervision. The manuscript supplies no architecture, training regime, loss functions, or ablation studies for this module, leaving the load-bearing assumption unverified (Methods / pipeline description).
- [Results / experimental evaluation] The performance claims (1.7% WER on Seed-TTS-Eval and matching dedicated models) are presented without reference to data splits, baseline systems, evaluation protocols, or error analysis, preventing verification that the system truly matches specialized models on non-standard tasks (Results / experimental evaluation).
minor comments (2)
- [Abstract] Grammatical error in the abstract: 'an 1.7% Word Error Rate' should read 'a 1.7% Word Error Rate'.
- [Abstract / §3] The abstract and pipeline description would benefit from a diagram or explicit notation clarifying the flow from natural-language prompt to caption to synthesized waveform.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions that will be incorporated.
read point-by-point responses
-
Referee: [Methods / pipeline description] The universality claim rests entirely on the reasoning module's ability to extract a comprehensive caption that encodes all required transcription and metadata nuances without task-specific fine-tuning or additional supervision. The manuscript supplies no architecture, training regime, loss functions, or ablation studies for this module, leaving the load-bearing assumption unverified (Methods / pipeline description).
Authors: We agree that the current manuscript provides only a high-level overview of the reasoning module. In the revised version we will expand the Methods section with the module's architecture, training regime, loss functions, and ablation studies to substantiate how it derives rich captions from natural-language prompts without task-specific supervision. revision: yes
-
Referee: [Results / experimental evaluation] The performance claims (1.7% WER on Seed-TTS-Eval and matching dedicated models) are presented without reference to data splits, baseline systems, evaluation protocols, or error analysis, preventing verification that the system truly matches specialized models on non-standard tasks (Results / experimental evaluation).
Authors: We acknowledge that additional experimental details are required. The revised manuscript will include explicit descriptions of data splits, baseline systems, evaluation protocols, and error analysis to support the reported WER and subjective results across tasks. revision: yes
Circularity Check
No circularity: results are empirical benchmarks, not derived predictions
full rationale
The paper presents an empirical TTS system whose performance claims rest on experimental evaluations (WER on Seed-TTS-Eval, LLM-as-a-judge, human ratings) rather than any mathematical derivation chain. No equations, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the provided text. The reasoning module is described as a black-box component whose output caption is validated only by downstream results on external benchmarks, not by construction from its own inputs. This is the normal case of a self-contained experimental paper with no reduction of claims to tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Traditional text-to-speech (TTS) systems are primarily engi- neered to synthesize speech from text transcriptions, often aug- mented by specific metadata such as speaker identity, language, emotion, and stress [1, 2]. To incorporate these attributes, early designs rely on specialized, disjointed modules (e.g., dedicated speaker encoders) to c...
Pith/arXiv arXiv 2026
-
[2]
Let's see
Bagpiper-TTS 2.1. Bagpiper-Base Bagpiper-TTS is built upon existing Bagpiper-Base [23], an audio-centric foundational model designed for cross-modal un- derstanding and synthesis. Its architecture utilizes the Qwen3- 8B-Base [24] decoder-only LLM as its computational back- bone, which provides strong text-only capability. To support audio generation, it t...
-
[3]
Experiments 3.1. Experimental Setup Building upon the Bagpiper-Base foundational model, we per- form supervised fine-tuning on all our curated simulation datasets for 2 epochs to build this universal speech generation model. We utilize a global batch size of 160k tokens and main- tain a constant learning rate of1×10 −5. During inference, we employ a decou...
-
[4]
Limitations Although we implement rigorous filtering, hallucinations per- sist across various stages of data simulation and model infer- ence, particularly within the rich captions produced by the au- tomated captioner. Furthermore, while this work focuses on tex- tual natural language as a universal interface, we acknowledge that certain metadata are mor...
-
[5]
By employing an end-to-end reasoning workflow with rich captions, Bagpiper-TTS success- fully interprets complex user intent across diverse tasks
Conclusion This paper introduces Bagpiper-TTS, a framework that replaces rigid metadata inputs with a natural language interface for flex- ible, free-form speech synthesis. By employing an end-to-end reasoning workflow with rich captions, Bagpiper-TTS success- fully interprets complex user intent across diverse tasks. Our results demonstrate that this hum...
-
[6]
Use of Generative AI Disclosure Generative AI tools were utilized in the preparation of this manuscript primarily for stylistic polishing and grammatical re- finement; they were not used to author significant original tech- nical content. Additionally, as detailed in §2.2 and §2.3.1, Large Language Models (LLMs) and multimodal foundational mod- els were s...
-
[7]
Acknowledgment Parts of this work used the PSC Bridges2 system and Delta/DeltaAI system at NCSA through allocations CIS210014 and IRI120008P from the ACCESS program, supported by NSF grants #2138259,#2138286, #2138307, #2137603, and #2138296
-
[8]
A survey on neural speech synthesis,
X. Tan, T. Qin, F. Soong, and T.-Y . Liu, “A survey on neural speech synthesis,”arXiv preprint arXiv:2106.15561, 2021
arXiv 2021
-
[9]
Towards con- trollable speech synthesis in the era of large language models: A systematic survey,
T. Xie, Y . Rong, P. Zhang, W. Wang, and L. Liu, “Towards con- trollable speech synthesis in the era of large language models: A systematic survey,” inProceedings of the 2025 Conference on Em- pirical Methods in Natural Language Processing, 2025, pp. 764– 791
2025
-
[10]
Fastspeech: Fast, robust and controllable text to speech,
Y . Ren, Y . Ruan, X. Tan, T. Qin, S. Zhao, Z. Zhao, and T.-Y . Liu, “Fastspeech: Fast, robust and controllable text to speech,” in Advances in Neural Information Processing Systems, H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alch ´e-Buc, E. Fox, and R. Garnett, Eds., vol. 32. Curran Associates, Inc., 2019. [Online]. Available: https://proceedings.ne...
2019
-
[11]
Tacotron: Towards End-to-End Speech Synthesis,
Y . Wang, R. Skerry-Ryan, D. Stanton, Y . Wu, R. J. Weiss, N. Jaitly, Z. Yang, Y . Xiao, Z. Chen, S. Bengio, Q. Le, Y . Agiomyrgiannakis, R. Clark, and R. A. Saurous, “Tacotron: Towards End-to-End Speech Synthesis,” inInterspeech 2017, 2017, pp. 4006–4010
2017
-
[12]
Neural codec language mod- els are zero-shot text to speech synthesizers,
C. Wang, S. Chen, Y . Wu, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y . Liu, H. Wang, J. Liet al., “Neural codec language mod- els are zero-shot text to speech synthesizers,”arXiv preprint arXiv:2301.02111, 2023
Pith/arXiv arXiv 2023
-
[13]
Vibevoice: Expressive podcast generation with next-token diffusion,
Z. Peng, J. Yu, W. Wang, Y . Chang, Y . Sun, L. Dong, Y . Zhu, W. Xu, H. Bao, Z. Wang, S. Huang, Y . Xia, and F. Wei, “Vibevoice: Expressive podcast generation with next-token diffusion,” inThe Fourteenth International Conference on Learning Representations, 2026. [Online]. Available: https://openreview.net/forum?id=FihSkzyxdv
2026
-
[14]
Opuslm: A family of open unified speech language models,
J. Tian, W. Chen, Y . Peng, J. Shi, S. Arora, S. Bharadwaj, T. Maekaku, Y . Shinohara, K. Goto, X. Yueet al., “Opuslm: A family of open unified speech language models,”arXiv preprint arXiv:2506.17611, 2025
arXiv 2025
-
[15]
V oxtlm: Unified decoder-only models for consolidating speech recognition, synthesis and speech, text continuation tasks,
S. Maiti, Y . Peng, S. Choi, J.-w. Jung, X. Chang, and S. Watan- abe, “V oxtlm: Unified decoder-only models for consolidating speech recognition, synthesis and speech, text continuation tasks,” inICASSP 2024-2024 IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 13 326–13 330
2024
-
[16]
Simplespeech 2: Towards simple and efficient text-to-speech with flow-based scalar latent transformer diffusion models,
D. Yang, R. Huang, Y . Wang, H. Guo, D. Chong, S. Liu, X. Wu, and H. Meng, “Simplespeech 2: Towards simple and efficient text-to-speech with flow-based scalar latent transformer diffusion models,”IEEE Transactions on Audio, Speech and Language Pro- cessing, 2025
2025
-
[17]
H. Hu, X. Zhu, T. He, D. Guo, B. Zhang, X. Wang, Z. Guo, Z. Jiang, H. Hao, Z. Guoet al., “Qwen3-tts technical report,” arXiv preprint arXiv:2601.15621, 2026
Pith/arXiv arXiv 2026
-
[18]
V oicebox: Text-guided multilingual universal speech generation at scale,
M. Le, A. Vyas, B. Shi, B. Karrer, L. Sari, R. Moritz, M. Williamson, V . Manohar, Y . Adi, J. Mahadeokaret al., “V oicebox: Text-guided multilingual universal speech generation at scale,”Advances in neural information processing systems, vol. 36, pp. 14 005–14 034, 2023
2023
-
[19]
Naturalspeech 3: Zero-shot speech syn- thesis with factorized codec and diffusion models,
Z. Ju, Y . Wang, K. Shen, X. Tan, D. Xin, D. Yang, Y . Liu, Y . Leng, K. Song, S. Tanget al., “Naturalspeech 3: Zero-shot speech syn- thesis with factorized codec and diffusion models,”arXiv preprint arXiv:2403.03100, 2024
arXiv 2024
-
[20]
F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching,
Y . Chen, Z. Niu, Z. Ma, K. Deng, C. Wang, J. JianZhao, K. Yu, and X. Chen, “F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 6255–6271
2025
-
[21]
E3 tts: Easy end-to-end diffusion-based text to speech,
Y . Gao, N. Morioka, Y . Zhang, and N. Chen, “E3 tts: Easy end-to-end diffusion-based text to speech,” in2023 IEEE Auto- matic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2023, pp. 1–8
2023
-
[22]
Cosyvoice 3: Towards in-the- wild speech generation via scaling-up and post-training,
Z. Du, C. Gao, Y . Wang, F. Yu, T. Zhao, H. Wang, X. Lv, H. Wang, C. Ni, X. Shiet al., “Cosyvoice 3: Towards in-the- wild speech generation via scaling-up and post-training,”arXiv preprint arXiv:2505.17589, 2025
Pith/arXiv arXiv 2025
-
[23]
Seed-tts: A family of high-quality versatile speech generation models,
P. Anastassiou, J. Chen, J. Chen, Y . Chen, Z. Chen, Z. Chen, J. Cong, L. Deng, C. Ding, L. Gaoet al., “Seed-tts: A family of high-quality versatile speech generation models,”arXiv preprint arXiv:2406.02430, 2024
Pith/arXiv arXiv 2024
-
[24]
Mooncast: High-quality zero- shot podcast generation,
Z. Ju, D. Yang, K. Shen, Y . Leng, Z. Wang, S. Liu, X. Zhou, T. Qin, X. Li, J. Yu, and X. Tan, “Mooncast: High-quality zero- shot podcast generation,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. [Online]. Available: https://openreview.net/forum?id=MVlKSYR7HX
2025
-
[25]
Omnicharacter: Towards im- mersive role-playing agents with seamless speech-language per- sonality interaction,
H. Zhang, R. Luo, X. Liu, Y . Wu, T.-E. Lin, P. Zeng, Q. Qu, F. Fang, M. Yang, L. Gaoet al., “Omnicharacter: Towards im- mersive role-playing agents with seamless speech-language per- sonality interaction,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 26 318–26 331
2025
-
[26]
Omni-captioner: Data pipeline, mod- els, and benchmark for omni detailed perception,
Z. Ma, R. Xu, Z. Xing, Y . Chu, Y . Wang, J. He, J. Xu, P.-A. Heng, K. Yu, J. Linet al., “Omni-captioner: Data pipeline, mod- els, and benchmark for omni detailed perception,”arXiv preprint arXiv:2510.12720, 2025
arXiv 2025
-
[27]
video-salmonn 2: Captioning-enhanced audio-visual large language models,
C. Tang, Y . Li, Y . Yang, J. Zhuang, G. Sun, W. Li, Z. Ma, and C. Zhang, “video-salmonn 2: Captioning-enhanced audio-visual large language models,”arXiv preprint arXiv:2506.15220, 2025
arXiv 2025
-
[28]
The rich transcrip- tion 2006 spring meeting recognition evaluation,
J. Fiscus, J. Ajot, M. Michel, and J. Garofolo, “The rich transcrip- tion 2006 spring meeting recognition evaluation,” inProceedings of the Rich Transcription Spring Meeting Recognition Evaluation (RT-06S). NIST, May 2006
2006
-
[29]
Audiochat: Unified audio sto- rytelling, editing, and understanding with transfusion forcing,
W. Chen, P. Seetharaman, R. Kumar, O. Nieto, S. Watan- abe, J. Salamon, and Z. Jin, “Audiochat: Unified audio sto- rytelling, editing, and understanding with transfusion forcing,” arXiv preprint arXiv:2602.17097, 2026
arXiv 2026
-
[30]
Bagpiper: Solv- ing open-ended audio tasks via rich captions,
J. Tian, H. Wang, B.-H. Su, C.-y. Huang, Q. Wang, J. Shi, W. Chen, X. Gong, S. Arora, C.-J. Liet al., “Bagpiper: Solv- ing open-ended audio tasks via rich captions,”arXiv preprint arXiv:2602.05220, 2026
Pith/arXiv arXiv 2026
-
[31]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[32]
Codec does matter: Exploring the semantic shortcoming of codec for audio language model,
Z. Ye, P. Sun, J. Lei, H. Lin, X. Tan, Z. Dai, Q. Kong, J. Chen, J. Pan, Q. Liuet al., “Codec does matter: Exploring the semantic shortcoming of codec for audio language model,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, 2025, pp. 25 697–25 705
2025
-
[33]
X. Shi, X. Wang, Z. Guo, Y . Wang, P. Zhang, X. Zhang, Z. Guo, H. Hao, Y . Xi, B. Yanget al., “Qwen3-asr technical report,”arXiv preprint arXiv:2601.21337, 2026
Pith/arXiv arXiv 2026
-
[34]
Q. Team, “Qwen3-omni technical report,”arXiv preprint arXiv:2509.17765, 2025
Pith/arXiv arXiv 2025
-
[35]
Instructtts: Modelling expressive tts in discrete latent space with natural lan- guage style prompt,
D. Yang, S. Liu, R. Huang, C. Weng, and H. Meng, “Instructtts: Modelling expressive tts in discrete latent space with natural lan- guage style prompt,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 2913–2925, 2024
2024
-
[36]
Libritts-r: A restored multi-speaker text-to-speech corpus,
Y . Koizumi, H. Zen, S. Karita, Y . Ding, K. Yatabe, N. Morioka, M. Bacchiani, Y . Zhang, W. Han, and A. Bapna, “Libritts-r: A restored multi-speaker text-to-speech corpus,”arXiv preprint arXiv:2305.18802, 2023
arXiv 2023
-
[37]
Genshin-V oice Dataset,
Simon, “Genshin-V oice Dataset,” https://huggingface.co/datasets/ simon3000/genshin-voice, 2024, accessed: 2026-02-24
2024
-
[38]
Starrail-V oice Dataset,
——, “Starrail-V oice Dataset,” https://huggingface.co/datasets/ simon3000/starrail-voice, 2024, accessed: 2026-02-24
2024
-
[39]
GigaSpeech: An Evolving, Multi-Domain ASR Cor- pus with 10,000 Hours of Transcribed Audio,
G. Chen, S. Chai, G.-B. Wang, J. Du, W.-Q. Zhang, C. Weng, D. Su, D. Povey, J. Trmal, J. Zhang, M. Jin, S. Khudanpur, S. Watanabe, S. Zhao, W. Zou, X. Li, X. Yao, Y . Wang, Z. You, and Z. Yan, “GigaSpeech: An Evolving, Multi-Domain ASR Cor- pus with 10,000 Hours of Transcribed Audio,” inInterspeech 2021, 2021, pp. 3670–3674
2021
-
[40]
Scalable Spontaneous Speech Dataset (SSSD): Crowdsourcing Data Collection to Promote Dialogue Research,
Z. Sheikh, S. Shimizu, S. Arora, J. Shi, S. Cornell, X. Li, and S. Watanabe, “Scalable Spontaneous Speech Dataset (SSSD): Crowdsourcing Data Collection to Promote Dialogue Research,” inInterspeech 2025, 2025, pp. 3963–3967
2025
-
[41]
VIBEVOICE-ASR technical report,
Z. Peng, J. Yu, Y . Chang, Z. Wang, L. Dong, Y . Hao, Y . Tu, C. Yang, W. Wang, S. Xuet al., “VIBEVOICE-ASR technical report,”arXiv preprint arXiv:2601.18184, 2026
arXiv 2026
-
[42]
gpt-oss-120b & gpt- oss-20b model card,
S. Agarwal, L. Ahmad, J. Ai, S. Altman, A. Applebaum, E. Arbus, R. K. Arora, Y . Bai, B. Baker, H. Baoet al., “gpt-oss-120b & gpt- oss-20b model card,”arXiv preprint arXiv:2508.10925, 2025
Pith/arXiv arXiv 2025
-
[43]
Classifier-free diffusion guidance,
J. Ho and T. Salimans, “Classifier-free diffusion guidance,”arXiv preprint arXiv:2207.12598, 2022
Pith/arXiv arXiv 2022
-
[44]
Cosyvoice 2: Scalable stream- ing speech synthesis with large language models,
Z. Du, Y . Wang, Q. Chen, X. Shi, X. Lv, T. Zhao, Z. Gao, Y . Yang, C. Gao, H. Wanget al., “Cosyvoice 2: Scalable stream- ing speech synthesis with large language models,”arXiv preprint arXiv:2412.10117, 2024
Pith/arXiv arXiv 2024
-
[45]
Yue: Scaling open foundation models for long-form music generation,
R. Yuan, H. Lin, S. Guo, G. Zhang, J. Pan, Y . Zang, H. Liu, Y . Liang, W. Ma, X. Du, X. Du, Z. Ye, T. Zheng, Z. Jiang, Y . Ma, M. Liu, Z. Tian, Z. Zhou, L. Xue, X. Qu, Y . Li, S. Wu, T. Shen, Z. Ma, J. Zhan, C. Wang, Y . Wang, X. Chi, X. Zhang, Z. Yang, X. Wang, S. Liu, L. Mei, P. Li, J. Wang, J. Yu, G. Pang, X. Li, Z. Wang, X. Zhou, L. Yu, E. Benetos, Y...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.