EEG Benchmarking Needs a Task Specification Layer: NeuroDoc for Rulebook-Guided, Executable Benchmark Construction
Pith reviewed 2026-06-26 09:11 UTC · model grok-4.3
The pith
Heterogeneous EEG datasets can be standardized into reusable benchmarks through a structured task specification language paired with a shared rulebook.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Heterogeneous public EEG datasets can be standardized through a structured task specification language paired with a shared rulebook, demonstrated by releasing a community-reviewed corpus of 53 entries with 245 task definitions that can be instantiated across EEG foundation model backbones.
What carries the argument
A task document synchronized with an executable task kernel, where the rulebook enforces fields, evidence requirements, document-kernel alignment, review states, and machine-checkable constraints.
If this is right
- Multi-dataset training of EEG foundation models becomes possible on auditable, executable task units rather than ad-hoc interpretations.
- Benchmark construction shifts from manual paper reading to rulebook-guided drafting, community review, and automated checks.
- Task semantics move from scattered papers and code into versioned, machine-readable documents that support upgrades and amendments.
- Execution-based evidence for reusability can be collected by running the same task definitions on different model backbones.
Where Pith is reading between the lines
- The same rulebook approach could be adapted to other signal modalities such as MEG or intracranial recordings to create cross-modal benchmark suites.
- If the corpus grows through community contributions, it could support systematic comparisons of how task definitions affect model generalization.
- Automated constraint checking might eventually flag inconsistencies between a new dataset description and existing task definitions before review.
Load-bearing premise
The chosen task fields, evidence requirements, and machine-checkable constraints in the rulebook capture the critical semantics of diverse EEG paradigms without material loss or distortion from the original study descriptions.
What would settle it
A direct test would be to instantiate the 245 task definitions on the four foundation model backbones and check whether performance metrics or decoded task semantics deviate substantially from the source papers' reported results due to omitted details.
Figures

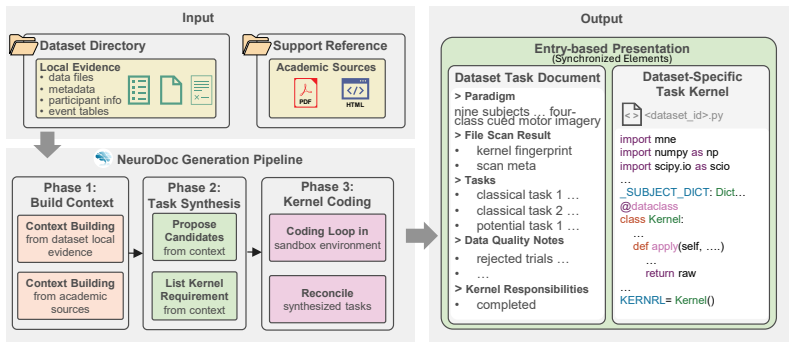
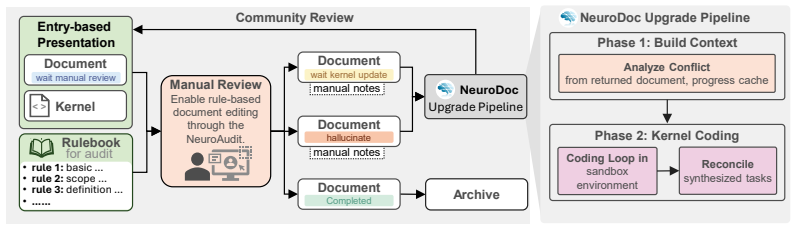
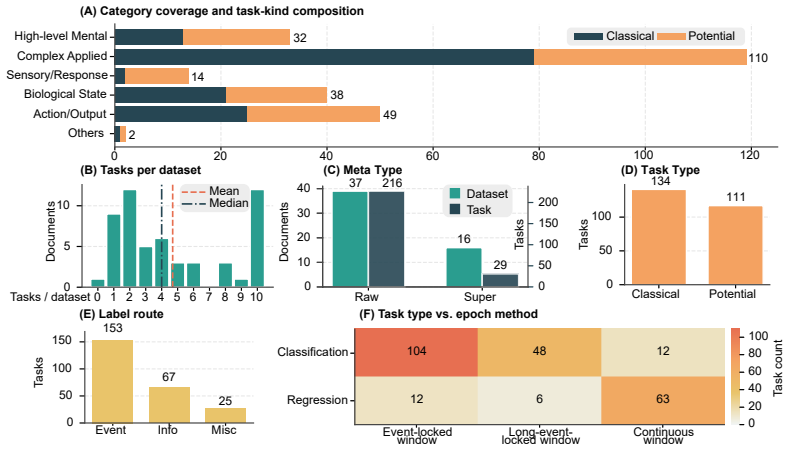
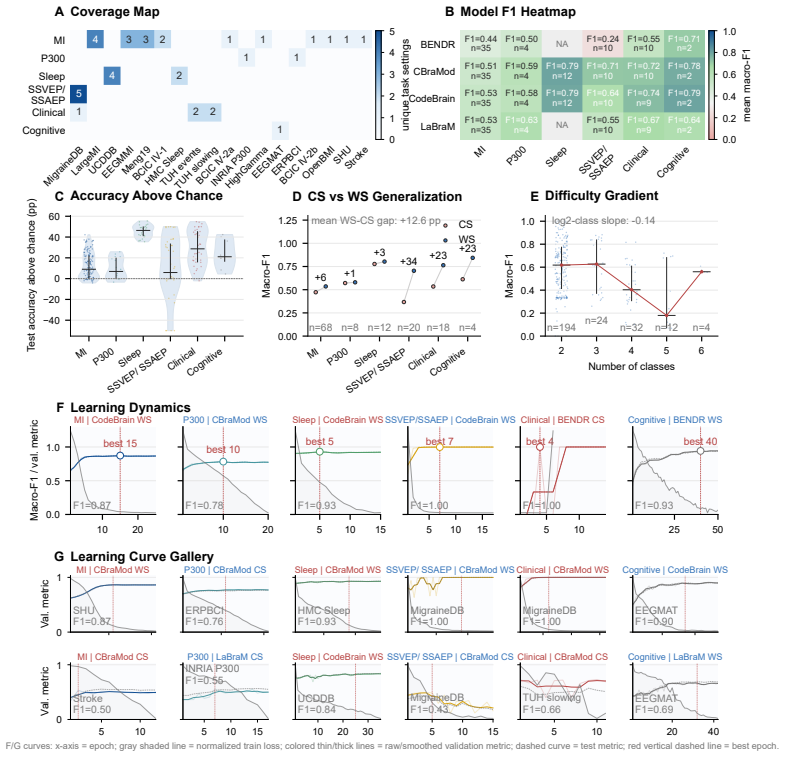
read the original abstract
Electroencephalography (EEG) foundation models increasingly rely on multi-dataset training and evaluation, yet public EEG datasets still lack a shared task specification layer that can turn heterogeneous recordings into reusable benchmark units. Existing standards organize files, metadata, and provenance, but they do not specify EEG tasks under a common language and rulebook, leaving critical task semantics scattered across papers, code, and manual interpretation. We investigate whether heterogeneous public EEG datasets can be standardized through a structured task specification language paired with a shared rulebook. Our methodology represents each benchmark entry as a task document synchronized with an executable task kernel, with the rulebook defining task fields, evidence requirements, document-kernel alignment, review states, and machine-checkable constraints. Using this methodology, we release a community-reviewed EEG benchmark corpus centered on 53 completed and reviewed entries with 245 task definitions spanning diverse paradigms, and we introduce NeuroDoc and NeuroAudit as the operational support layer for rulebook-guided drafting, upgrading, review, amendment, and release management. We further examine whether the resulting benchmark units can be instantiated in a shared downstream setting across four EEG foundation model backbones, providing execution-based evidence for reusable, auditable, and executable EEG benchmarking infrastructure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that heterogeneous public EEG datasets can be standardized via a structured task specification language and shared rulebook (defining fields, evidence requirements, document-kernel alignment, review states, and machine-checkable constraints), implemented through NeuroDoc and NeuroAudit. This is demonstrated by releasing a community-reviewed corpus of 53 entries containing 245 task definitions spanning diverse paradigms, with execution-based evidence that the resulting benchmark units can be instantiated across four EEG foundation model backbones.
Significance. If the rulebook and alignment process hold, the work supplies reusable, auditable infrastructure that directly addresses the lack of shared task semantics in EEG benchmarking. The release of the reviewed corpus and the operational tooling constitute concrete, community-usable contributions that could reduce manual reinterpretation and support reproducible multi-dataset training for EEG foundation models.
major comments (2)
- [Abstract / results] Abstract and results discussion: the claim of 'execution-based evidence' for instantiation across four backbones is load-bearing for the reusability argument, yet the manuscript supplies no quantitative details on alignment success rates, failure modes, or how post-review amendments were handled; this leaves the central demonstration unverifiable from the provided evidence.
- [Methodology] Methodology section on rulebook and document-kernel alignment: the central claim that the chosen task fields and machine-checkable constraints capture critical EEG paradigm semantics (stimulus protocols, montages, trial structures, artifact criteria) without material loss or forced reinterpretation is not supported by an explicit audit of edge-case paradigms; if any entry requires external paper consultation for correct instantiation, the standardization claim is undermined.
minor comments (2)
- [Introduction / Methodology] Clarify the exact definition and scope of 'task kernel' versus 'task document' early in the text to avoid ambiguity in later sections describing synchronization.
- [Methodology] The description of NeuroAudit review states would benefit from a small table or diagram enumerating the states and transitions.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which highlight important aspects of verifiability and methodological rigor in our work on EEG benchmark standardization. We address each major comment below, proposing specific revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / results] Abstract and results discussion: the claim of 'execution-based evidence' for instantiation across four backbones is load-bearing for the reusability argument, yet the manuscript supplies no quantitative details on alignment success rates, failure modes, or how post-review amendments were handled; this leaves the central demonstration unverifiable from the provided evidence.
Authors: We agree that quantitative details would enhance the verifiability of the execution-based evidence. In the revised version, we will expand the results section to include specific metrics on alignment success rates across the 245 task definitions and four backbones, common failure modes encountered during instantiation, and details on how any post-review amendments were resolved through the NeuroAudit process. This will directly support the reusability argument with concrete data. revision: yes
-
Referee: [Methodology] Methodology section on rulebook and document-kernel alignment: the central claim that the chosen task fields and machine-checkable constraints capture critical EEG paradigm semantics (stimulus protocols, montages, trial structures, artifact criteria) without material loss or forced reinterpretation is not supported by an explicit audit of edge-case paradigms; if any entry requires external paper consultation for correct instantiation, the standardization claim is undermined.
Authors: The rulebook and constraints were designed based on an analysis of diverse EEG paradigms to minimize loss, and the community review by multiple experts for each of the 53 entries served to validate this. However, we recognize the value of an explicit edge-case audit. We will add to the methodology section a subsection auditing several edge-case paradigms (e.g., complex stimulus protocols or non-standard montages) to demonstrate that instantiation can be achieved using only the task document and kernel without external consultation. If any cases required additional information, we will report them transparently. revision: yes
Circularity Check
Methodological proposal with released corpus shows no circularity
full rationale
The paper proposes a task specification language and rulebook for standardizing EEG datasets, releasing a community-reviewed corpus of 53 entries with 245 task definitions. No mathematical derivations, equations, fitted parameters, or predictions appear in the provided text. The central claim is supported by the released entries, review process, and execution across backbones rather than any internal reduction to inputs or self-citation chains. This matches the default expectation for non-circular methodological work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption EEG task semantics from heterogeneous studies can be captured by a finite set of fields, evidence requirements, and machine-checkable constraints without material loss.
invented entities (2)
-
NeuroDoc
no independent evidence
-
NeuroAudit
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Anisha Agarwal, Rafael Dowsley, Nicholas McKinney, Dongrui Wu, Chin-Teng Lin, Martine De Cock, and Anderson Nascimento. Protecting privacy of users in brain-computer interface applications.IEEE Transactions on Neural Systems and Rehabilitation Engineering, 27(8): 1546–1555, 2019. doi: 10.1109/TNSRE.2019.2926965. URL https://doi.org/10.1109/ TNSRE.2019.2926965
-
[2]
Croissant: A meta- data format for ML-ready datasets
Mubashara Akhtar, Omar Benjelloun, Costanza Conforti, Luca Foschini, Pieter Gijsbers, Joan Giner-Miguelez, Sujata Goswami, Nitisha Jain, Michalis Karamousadakis, Satyapriya Krishna, Michael Kuchnik, Sylvain Lesage, Quentin Lhoest, Pierre Marcenac, Manil Maskey, Peter Mattson, Luis Oala, Hamidah Oderinwale, Pierre Ruyssen, Tim Santos, Rajat Shinde, Elena S...
-
[3]
Stefan Appelhoff, Matthew Sanderson, Teon Brooks, Marijn van Vliet, Romain Quentin, Chris Holdgraf, Maximilien Chaumon, Ezequiel Mikulan, Kambiz Tavabi, Richard Höchenberger, Dominik Welke, Clemens Brunner, Alexander Rockhill, Eric Larson, Alexandre Gramfort, and Mainak Jas. MNE-BIDS: Organizing electrophysiological data into the BIDS format and facilitat...
-
[4]
Barker, Valentina Borghesani, Nils Broeckx, Patricia Clement, Kyrre E
Elise Bannier, Gareth J. Barker, Valentina Borghesani, Nils Broeckx, Patricia Clement, Kyrre E. Emblem, Satrajit Ghosh, Enrico Glerean, Krzysztof J. Gorgolewski, Marko Havu, Yaroslav O. Halchenko, Peer Herholz, Anne Hespel, Stephan Heunis, Yue Hu, Chuan-Peng Hu, Dorien Huijser, María de la Iglesia Vayá, Radim Janˇcálek, Vasileios K. Katsaros, Marie-Luise ...
1945
-
[5]
URLhttps://doi.org/10.1002/hbm.25351
doi: 10.1002/hbm.25351. URLhttps://doi.org/10.1002/hbm.25351
-
[6]
REVE: A foundation model for EEG adapting to any setup with large-scale pretraining on 25,000 subjects
Yassine El Ouahidi, Jonathan Lys, Philipp Thölke, Nicolas Farrugia, Bastien Pasdeloup, Vincent Gripon, Karim Jerbi, and Giulia Lioi. REVE: A foundation model for EEG adapting to any setup with large-scale pretraining on 25,000 subjects. InAdvances in Neural Information Processing Systems, volume 38, 2025. URLhttps://openreview.net/forum?id=ZeFMtRBy4Z
2025
-
[7]
Christoph Hofer, Florian Graf, Bastian Rieck, Marc Niethammer, and Roland Kwitt
Ary L. Goldberger, Luis A. N. Amaral, Leon Glass, Jeffrey M. Hausdorff, Plamen Ch. Ivanov, Roger G. Mark, Joseph E. Mietus, George B. Moody, C.-K. Peng, and H. Eugene Stanley. PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals.Circulation, 101(23):e215–e220, 2000. doi: 10.1161/01.CIR.101.23.e215...
-
[8]
Krzysztof J. Gorgolewski, Tibor Auer, Vince Calhoun, Cameron Craddock, Samir Das, Eu- gene Duff, Guillaume Flandin, Satrajit Ghosh, Tristan Glatard, Yaroslav Halchenko, Daniel Handwerker, Michael Hanke, David Keator, Xiangrui Li, Zachary Michael, Camille Maumet, Nolan Nichols, Thomas Nichols, John Pellman, Jean-Baptiste Poline, Ariel Rokem, Gunnar 10 Scha...
-
[9]
Alexandre Gramfort, Martin Luessi, Eric Larson, Denis A. Engemann, Daniel Strohmeier, Christian Brodbeck, Roman Goj, Mainak Jas, Teon Brooks, Lauri Parkkonen, and Matti Hämäläinen. MEG and EEG data analysis with MNE-Python.Frontiers in Neuroscience, 7: 267, 2013. doi: 10.3389/fnins.2013.00267. URL https://doi.org/10.3389/fnins.2013. 00267
-
[10]
Aris Hofmann, Inge Vejsbjerg, Dhaval Salwala, and Elizabeth Daly. Auto- BenchmarkCard: Automated synthesis of benchmark documentation.Proceed- ings of the AAAI Conference on Artificial Intelligence, 40(48):41598–41600, 2026. doi: 10.1609/aaai.v40i48.42352. URL https://research.ibm.com/publications/ auto-benchmarkcard-automated-synthesis-of-benchmark-documentation
-
[11]
Benhao Huang, Yingzhuo Yu, Jin Huang, Xingjian Zhang, and Jiaqi Ma. DCA-Bench: A benchmark for dataset curation agents. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining, V .2, pages 5482–5492, 2025. doi: 10.1145/3711896. 3737422. URLhttps://doi.org/10.1145/3711896.3737422
-
[12]
Vinay Jayaram and Alexandre Barachant. MOABB: Trustworthy algorithm benchmarking for BCIs.Journal of Neural Engineering, 15(6):066011, 2018. doi: 10.1088/1741-2552/aadea0. URLhttps://doi.org/10.1088/1741-2552/aadea0
-
[13]
Large brain model for learning generic representations with tremendous EEG data in BCI
Weibang Jiang, Liming Zhao, and Baoliang Lu. Large brain model for learning generic representations with tremendous EEG data in BCI. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=QzTpTRVtrP
2024
-
[14]
Demetres Kostas, Stéphane Aroca-Ouellette, and Frank Rudzicz. BENDR: Using transformers and a contrastive self-supervised learning task to learn from massive amounts of EEG data. Frontiers in Human Neuroscience, 15:653659, 2021. doi: 10.3389/fnhum.2021.653659. URL https://doi.org/10.3389/fnhum.2021.653659
-
[15]
Mt-bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues
Jiarui Liu, Wenkai Li, Zhijing Jin, and Mona Diab. Automatic generation of model and data cards: A step towards responsible AI. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 1975–1997, 2024. doi: 10.18653/v1/2024. naacl-long.11...
-
[16]
CodeBrain: Bridging decoupled tokenizer and multi-scale architecture for EEG foundation model
Jingying Ma, Feng Wu, Qika Lin, Yucheng Xing, Chenyu Liu, Ziyu Jia, and Mengling Feng. CodeBrain: Bridging decoupled tokenizer and multi-scale architecture for EEG foundation model. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=msJgEkjwh5
2026
-
[17]
Christopher Markiewicz, Krzysztof Gorgolewski, Franklin Feingold, Ross Blair, Yaroslav O. Halchenko, Eric Miller, Nell Hardcastle, Joe Wexler, Oscar Esteban, Mathias Goncavles, Anita Jwa, and Russell Poldrack. The openneuro resource for sharing of neuroscience data.eLife, 10: e71774, 2021. doi: 10.7554/eLife.71774. URL https://doi.org/10.7554/eLife.71774
-
[18]
Cyril Pernet, Stefan Appelhoff, Krzysztof Gorgolewski, Guillaume Flandin, Christophe Phillips, Arnaud Delorme, and Robert Oostenveld. EEG-BIDS, an extension to the brain imaging data structure for electroencephalography.Scientific Data, 6:103, 2019. doi: 10.1038/s41597-019-0104-8. URLhttps://doi.org/10.1038/s41597-019-0104-8
-
[19]
Cyril Pernet, Marta Garrido, Alexandre Gramfort, Natasha Maurits, Christoph Michel, Elizabeth Pang, Riitta Salmelin, Jan Mathijs Schoffelen, Pedro Valdés-Sosa, and Aina Puce. Issues and recommendations from the OHBM COBIDAS MEEG committee for reproducible EEG and MEG research.Nature Neuroscience, 23:1473–1483, 2020. doi: 10.1038/s41593-020-00709-0. URLhtt...
-
[20]
Chengxuan Qin, Rui Yang, Wenlong You, Zhige Chen, Longsheng Zhu, Mengjie Huang, and Zidong Wang. EEGUnity: Open-source tool in facilitating unified EEG datasets toward large- scale EEG model.IEEE Transactions on Neural Systems and Rehabilitation Engineering, 33: 1653–1663, 2025. doi: 10.1109/TNSRE.2025.3565158. URL https://doi.org/10.1109/ TNSRE.2025.3565158
-
[21]
Kay Robbins, Dung Truong, Stefan Appelhoff, Arnaud Delorme, and Scott Makeig. Capturing the nature of events and event context using hierarchical event descriptors (HED).NeuroImage, 245:118766, 2021. doi: 10.1016/j.neuroimage.2021.118766. URL https://doi.org/10. 1016/j.neuroimage.2021.118766
-
[22]
Phil Tinn, Sondre Sørbø, Shanshan Jiang, Konstantinos V outetakis, Sotiris Moudouris Giounis, Eleftherios Pilalis, Olga Papadodima, and Dumitru Roman. Pre-meta: priors-augmented re- trieval for LLM-based metadata generation.Bioinformatics, 41(10):btaf519, 2025. doi: 10.1093/ bioinformatics/btaf519. URLhttps://doi.org/10.1093/bioinformatics/btaf519
-
[23]
CBraMod: A criss-cross brain foundation model for EEG decoding
Jiquan Wang, Sha Zhao, Zhiling Luo, Yangxuan Zhou, Haiteng Jiang, Shijian Li, Tao Li, and Gang Pan. CBraMod: A criss-cross brain foundation model for EEG decoding. In The Thirteenth International Conference on Learning Representations, 2025. URL https: //openreview.net/forum?id=NPNUHgHF2w
2025
-
[24]
BrainOmni: A brain foundation model for unified EEG and MEG signals
Qinfan Xiao, Ziyun Cui, Chi Zhang, Siqi Chen, Wen Wu, Andrew Thwaites, Alexandra Woolgar, Bowen Zhou, and Chao Zhang. BrainOmni: A brain foundation model for unified EEG and MEG signals. InAdvances in Neural Information Processing Systems, volume 38, 2025. URL https://openreview.net/forum?id=cjHQj0tCy6
2025
-
[25]
Are EEG foundation models worth it? comparative evaluation with traditional decoders in diverse BCI tasks
Liuyin Yang, Qiang Sun, Ang Li, and Marc Van Hulle. Are EEG foundation models worth it? comparative evaluation with traditional decoders in diverse BCI tasks. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=5Xwm8e6vbh
2026
-
[26]
Sha Zhao, Mingyi Peng, Haiteng Jiang, Tao Li, Shijian Li, and Gang Pan. EEGAgent: A unified framework for automated EEG analysis using large language models.Proceedings of the AAAI Conference on Artificial Intelligence, 40(21):18063–18071, 2026. doi: 10.1609/aaai.v40i21. 38867. 12 A Project Scale, Reference Resources, and Execution Validation Context This...
-
[27]
Provide human reviewers with consistent, explicit, actionable review standards
-
[28]
Provide LLM review scripts with stable, programmable, traceable decision rules
-
[29]
Article 2
Provide structured implementation guidance for later kernels, EEGUnity exports, and HDF5 produc- tion. Article 2. Scope This rulebook applies to:
-
[30]
Creating new dataset documents
-
[31]
Revising existing dataset documents
-
[32]
Reviewing core areas such asClassical Task,Potential Task,Event Structure, and meta- data
-
[33]
Article 3
Writing later LLM review rules, prompt rules, and fallback rules. Article 3. Core Principles Document generation and review must follow these principles:
-
[34]
Actual data has priority over web descriptions
-
[35]
Conservatism has priority over guessing
-
[36]
Traceability has priority over brevity
-
[37]
Chapter 2
Implementable task definitions have priority over theoretically imaginable ones. Chapter 2. Terms Article 4. Dataset Document A dataset document means the analysis.md file under a single dataset directory, or a same-structure successor version. Article 5. Raw Meta raw meta means labels, events, codes, annotations, fields, or markers that already exist in ...
-
[38]
Raw codes in trigger or stim channels
-
[39]
Discrete events in raw annotation files
-
[40]
Article 6
Directly available behavioral fields in raw tables. Article 6. Super Meta super meta means labels or targets that do not directly exist in the raw data and must be generated, mapped, folded, paired, aggregated, joined, or otherwise derived by code, rules, or human logic. Examples include:
-
[41]
Binary labels folded from multiple raw classes
-
[42]
Clinical groups derived from filenames, participant tables, or external tables
-
[43]
18 Article 7
Correct or incorrect, target or non-target, fast or slow, and similar labels derived by pairing multiple events. 18 Article 7. Kernel kernel means the later data-processing code or data-loading logic used to parse raw data, construct labels, route labels, and generate EEGUnity-compatible output. Article 8. Label Route Historically,Label Route meant the fi...
-
[44]
The official dataset page
-
[45]
Official documentation
-
[46]
Papers that clearly use the dataset
-
[47]
Chapter 3
Other authoritative sources. Chapter 3. Evidence Priority and Conflict Handling Article 13. Evidence Priority When sources conflict, use this priority order:
-
[48]
Verifiable data files and accompanying annotation files
-
[49]
Official dataset page, official README, or official documentation
-
[50]
Official papers or papers that clearly use the dataset
-
[51]
Article 14
Third-party pages, blogs, or unofficial descriptions. Article 14. General Conflict Rule When sources conflict, use the higher-priority evidence and record the conflict and decision in Data Quality Notes. Article 15. Data Priority When online material or paper descriptions conflict with actual data files, the actual data files prevail. The inconsistency mu...
-
[52]
Prefer downgrading it toPotential Task
-
[53]
Use placeholders such asNeeds verification,Variable,N/A, ornullwhen appropriate
-
[54]
Article 17
Do not fabricate missing information. Article 17. Implementability Even if a paper used the dataset, a task must not be treated as a validClassical Task unless the public data contains labels, events, or a verifiable derivation path sufficient to implement it. 19 Chapter 4. Roles Article 18. Administrator Responsibilities Administrators are responsible for:
-
[55]
Deciding dataset entry names
-
[56]
Deciding whether to accept human revisions or rule updates in pull requests
-
[57]
Article 19
Deciding whether a kernel must be added or rewritten. Article 19. Human Reviewer Responsibilities Human reviewers are responsible for:
-
[58]
Reviewing whether aClassical Taskis valid
-
[59]
Reviewing whether fields match actual data and official material
-
[60]
Deciding how to resolve conflicting information
-
[61]
Article 20
FillingManual Reviewwhen appropriate. Article 20. LLM Review Script Responsibilities LLM review scripts are responsible for:
-
[62]
Pre-generating or pre-correcting documents under the rulebook
-
[63]
Detecting likely conflicts, omissions, and invalid tasks
-
[64]
Producing conservative, traceable suggestions without inventing raw labels. Part II. Specific Rules Chapter 5. Meta Area Article 21. General Field Rule Meta Area records identifying dataset metadata. Unless otherwise specified, fields should be concise, stable, and easy for programs to read. Article 22.Dataset 1.Datasetis the dataset identifier
-
[65]
It should follow<source_name_id>
-
[66]
Administrators decide this name
-
[67]
Article 23.Year 1.Yearrecords key years related to collection, processing, or release
Reviewers and LLMs must not proactively modify it. Article 23.Year 1.Yearrecords key years related to collection, processing, or release
-
[68]
It does not need to distinguish collection year from release year
-
[69]
Multiple key years may be joined with/, for example2004/2021
2021
-
[70]
Continuous ranges may use-, for example2008-2015/2017
2015
-
[71]
The field need not cover every historical year, but should be updated as well as trusted sources allow
-
[72]
Article 24.URL 1.URL should preferably point to an information page that gives access to downloads or documentation
Do not ignore key years clearly present in the data because a web page title shows a different year. Article 24.URL 1.URL should preferably point to an information page that gives access to downloads or documentation
-
[73]
If both a direct file link and an information page exist, keep the information page
-
[74]
If a link is dead and cannot be replaced with an authoritative information page, delete it or replace it with an accessible authoritative page
-
[75]
Article 25.Category 1.Categorymust be exactly one of: •Complex Applied •High-level Mental •Action/Output •Sensory/Response 20 •Biological State •Others
The field does not need to be permanently valid, but must have practical review value at the time of review. Article 25.Category 1.Categorymust be exactly one of: •Complex Applied •High-level Mental •Action/Output •Sensory/Response 20 •Biological State •Others
-
[76]
The field is normally proposed by a program or preprocessing LLM
-
[77]
Human reviewers should correct it only when the classification is clearly wrong
-
[78]
Article 26.Subjects 1.Subjectsis the integer number of valid subjects in the dataset
Do not create category values outside the six listed values. Article 26.Subjects 1.Subjectsis the integer number of valid subjects in the dataset
-
[79]
If the official count differs from the actually usable count, prefer the actually usable count
-
[80]
Article 27.Files (Completed) 1.Files (Completed)is the number of files parsed by EEGUnity asCompleted
Record this conflict inData Quality Notes. Article 27.Files (Completed) 1.Files (Completed)is the number of files parsed by EEGUnity asCompleted
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.