Scalable Physics-Inspired Transformers for Spin Glasses
Pith reviewed 2026-06-26 06:30 UTC · model grok-4.3
The pith
A physics-inspired transformer with sparse attention and spin-tailored embeddings scales variational sampling of Boltzmann distributions in frustrated spin glasses to unprecedented sizes on one GPU.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
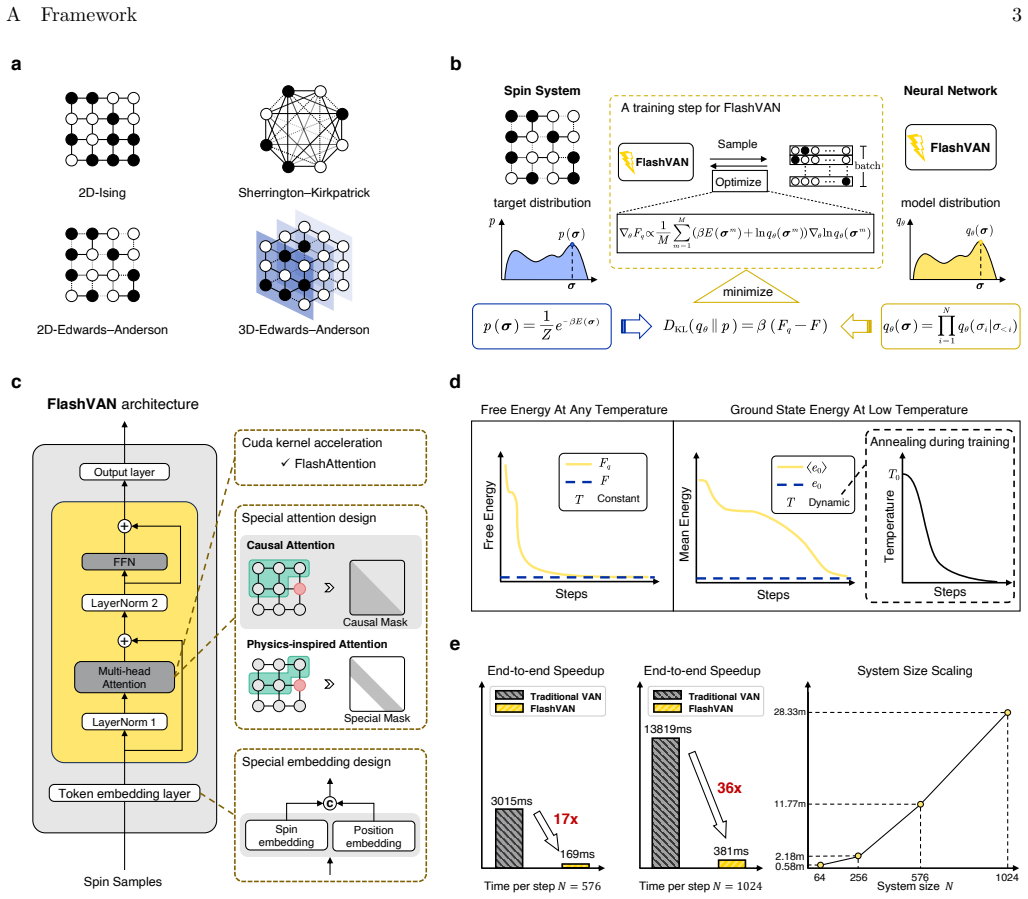
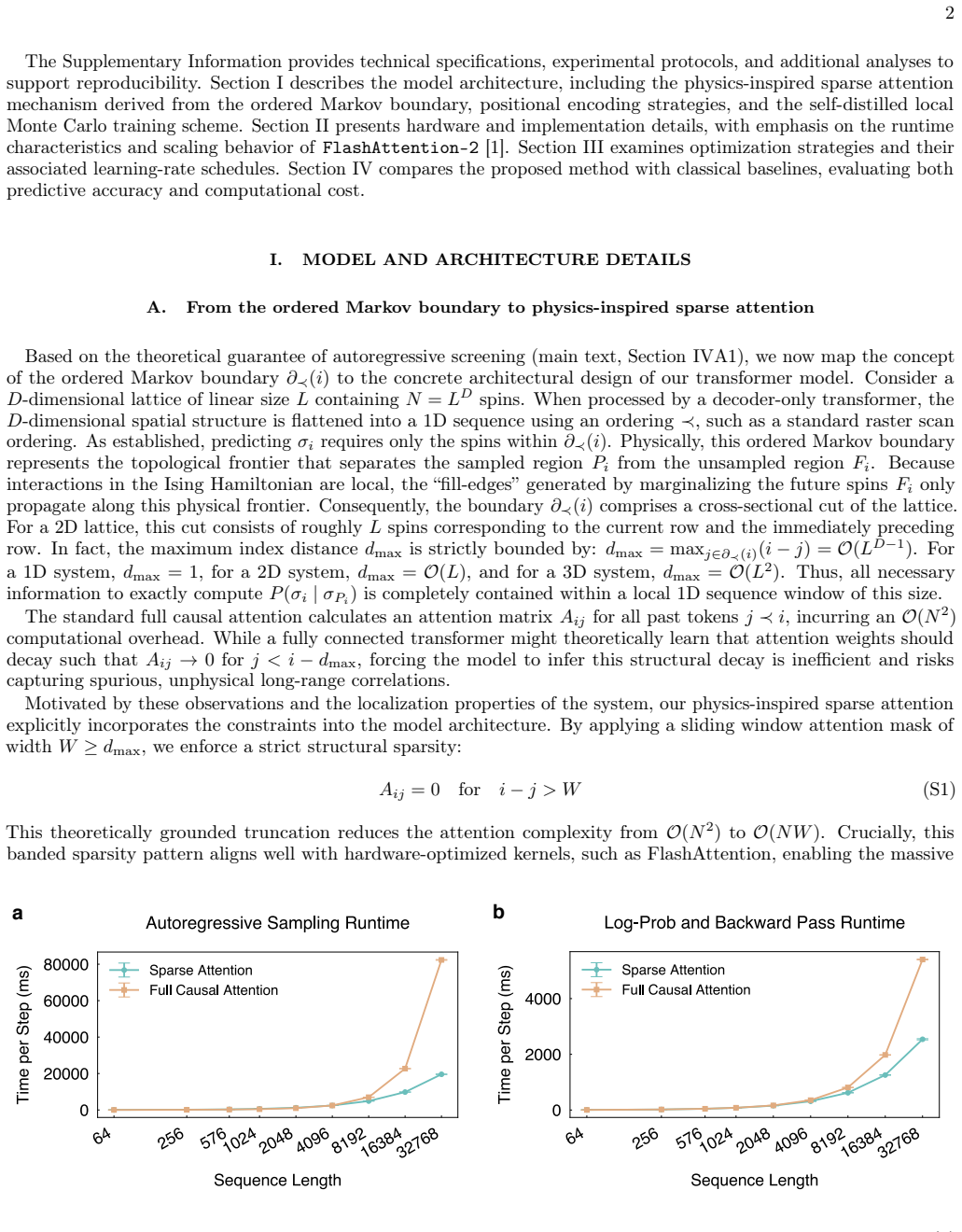
The central claim is that interpretable sparse attention together with spin-tailored positional embeddings allow a transformer to benefit from increased scale when representing the Boltzmann distribution of frustrated spin systems, and that FlashAttention-enabled parallel ancestral sampling reduces computational cost enough to reach system sizes unattainable by prior variational methods on a single GPU.
What carries the argument
Physics-inspired transformer equipped with interpretable sparse attention and spin-tailored positional embeddings, accelerated by FlashAttention for parallel ancestral sampling.
If this is right
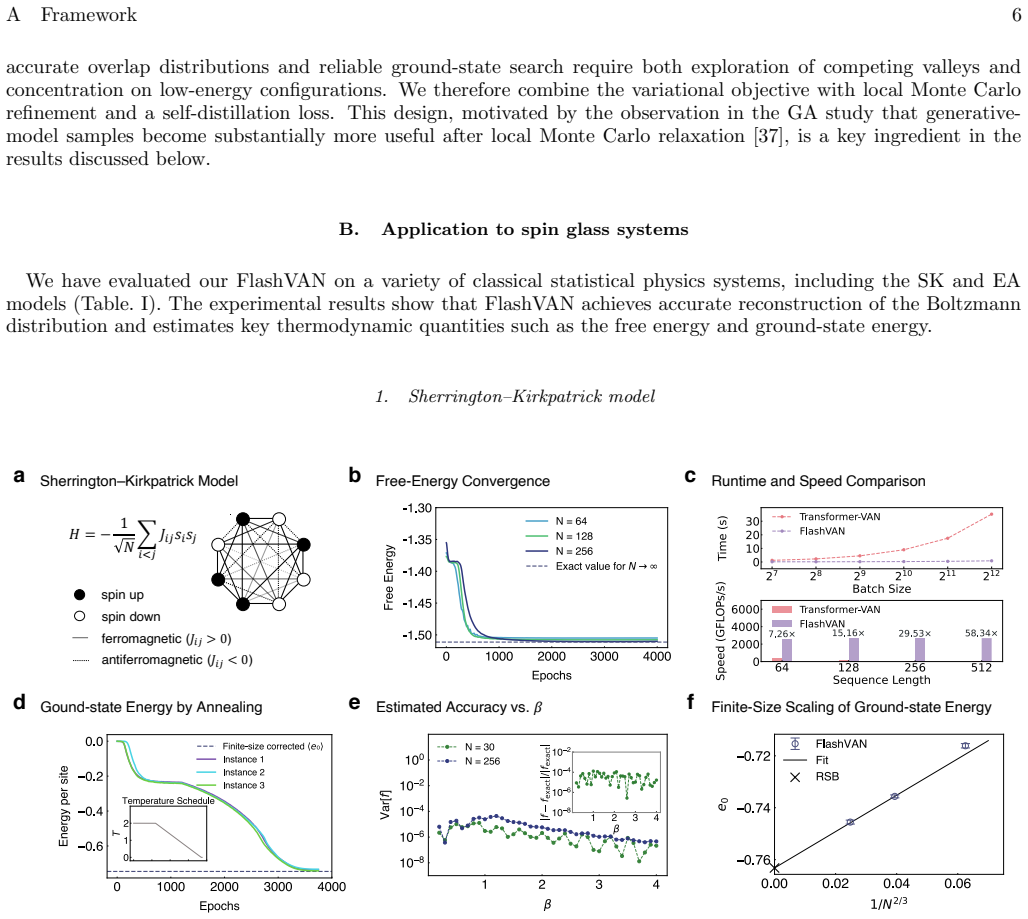
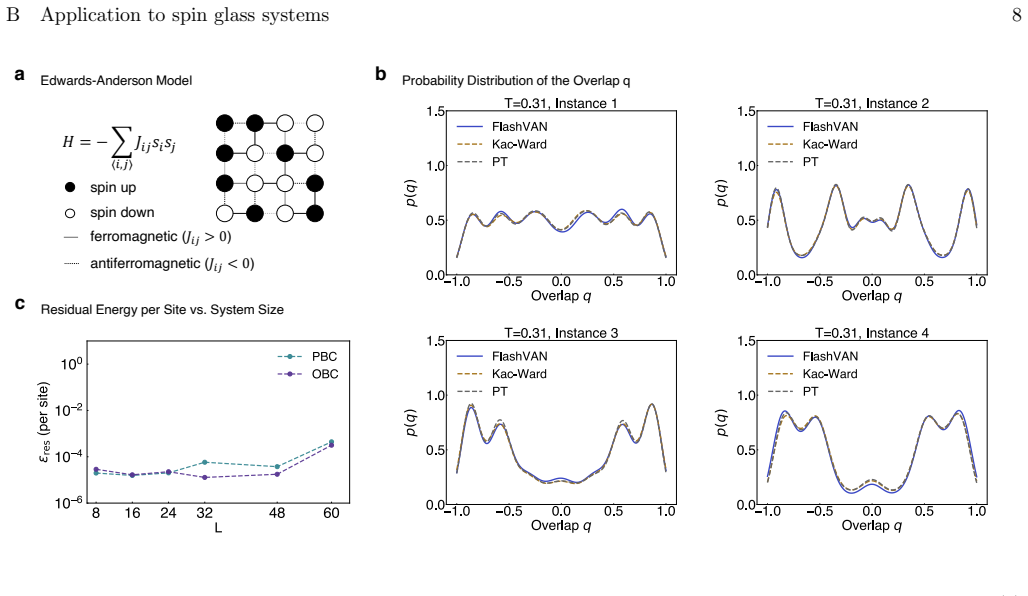
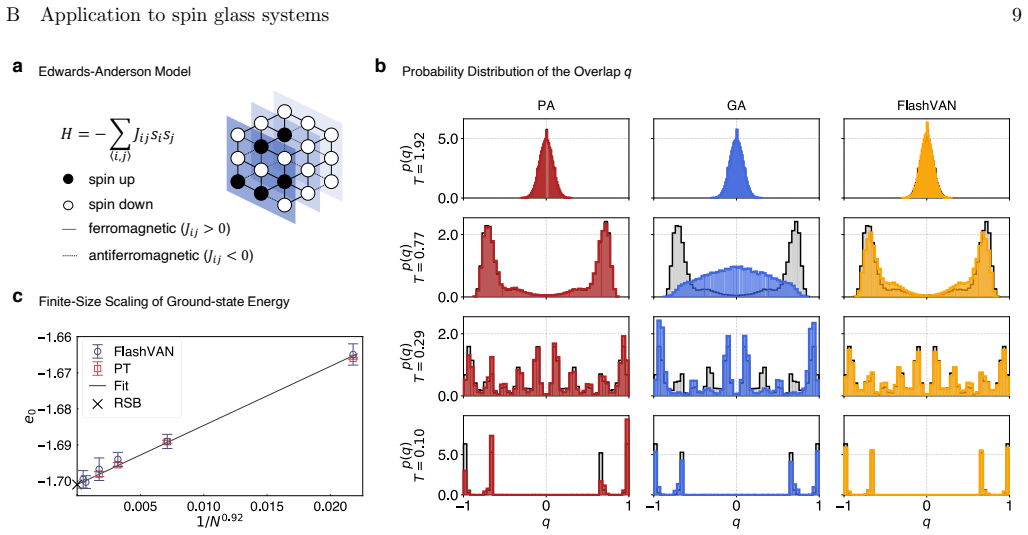
- The method yields full probability distributions, free energies, and overlap statistics across temperatures for Sherrington-Kirkpatrick and two- or three-dimensional Edwards-Anderson models.
- Neural-network simulations of these spin-glass systems become feasible at sizes previously limited by computational cost on a single GPU.
- Up to two orders of magnitude speedup is realized over vanilla variational autoregressive networks through FlashAttention parallel sampling.
- The architecture resolves regimes where existing machine-learning sampling methods encounter limitations at certain temperatures.
Where Pith is reading between the lines
- The same sparse-attention and embedding design could be tested on other combinatorial optimization problems that map to spin-glass Hamiltonians.
- If the scaling behavior holds, the approach may reduce reliance on specialized hardware or cluster resources for large frustrated systems.
- Overlap statistics extracted at scale could be compared directly with replica-symmetry-breaking predictions without additional post-processing steps.
Load-bearing premise
The physics-inspired modifications will let the transformer improve monotonically with scale and faithfully capture the Boltzmann distribution of frustrated spins, unlike earlier variational models.
What would settle it
On Sherrington-Kirkpatrick or Edwards-Anderson instances at low temperature and larger N, the model either fails to reproduce known free-energy or overlap values within statistical error or ceases to improve with added parameters or depth.
Figures
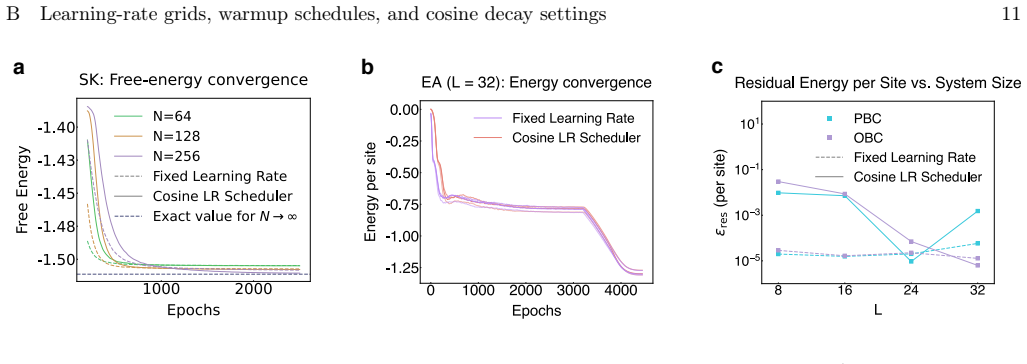
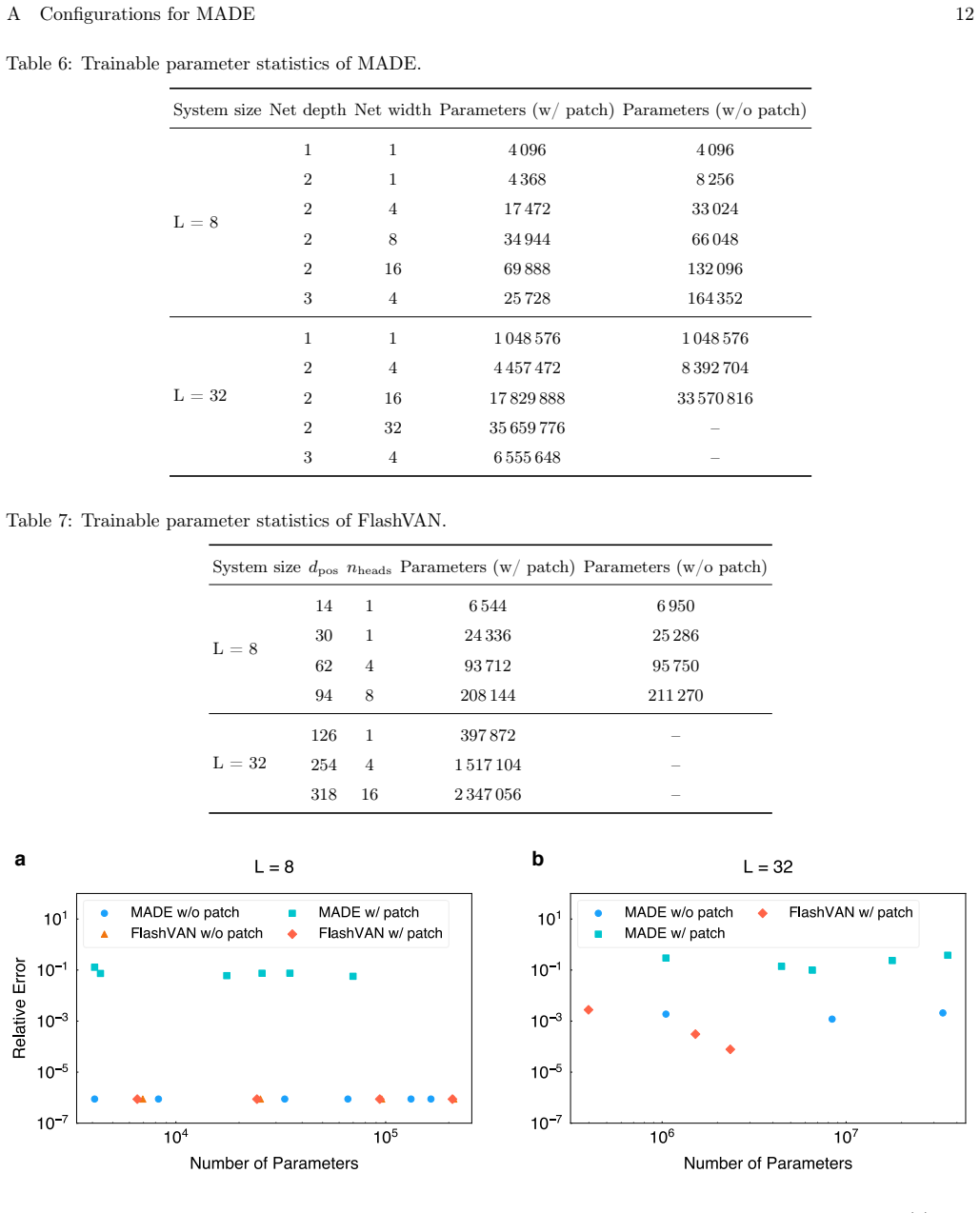
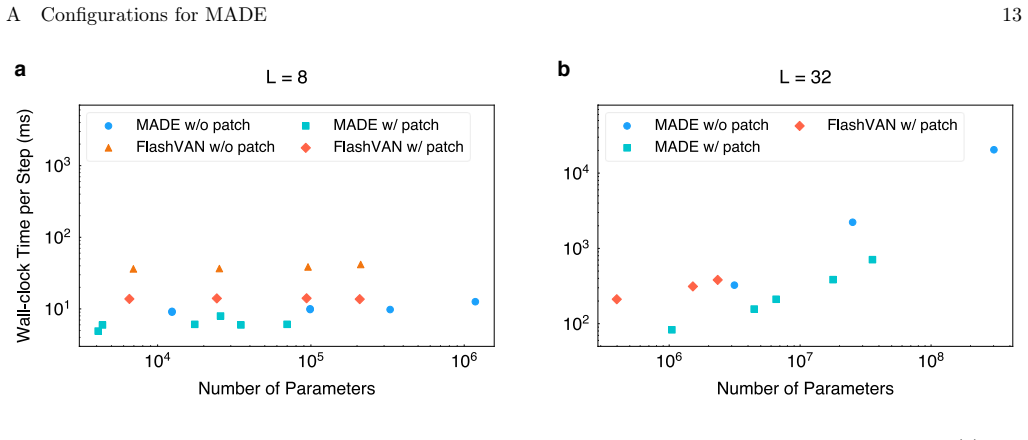
read the original abstract
Efficient sampling of the Boltzmann distribution in frustrated spin glasses is central to statistical mechanics and combinatorial optimization. Despite advances in machine-learning-based approaches, two issues persist: limited understanding of why variational models fail to benefit from increased scale, unlike the monotonic scaling law of large language models; and high computational cost on large systems that negates advantages over classical sampling methods. Here, we develop a physics-inspired transformer with interpretable sparse attention and spin-tailored positional embeddings to address these challenges. By further leveraging FlashAttention for parallel ancestral sampling, it achieves up to two orders of magnitude speedup over vanilla variational autoregressive networks, enabling neural-network simulations of spin-glass systems to unprecedented sizes on a single GPU. It can resolve full probability distributions, free energies, and overlap statistics across temperatures, for Sherrington-Kirkpatrick and 2D or 3D Edwards-Anderson models, where existing machine-learning methods encounter limitations at certain temperatures. This framework thus establishes a scalable paradigm for frustrated spin-glass systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a physics-inspired transformer for sampling Boltzmann distributions in frustrated spin glasses. It incorporates interpretable sparse attention and spin-tailored positional embeddings, then leverages FlashAttention to enable parallel ancestral sampling. The central claims are up to 100x speedup over vanilla variational autoregressive networks, access to unprecedented system sizes on a single GPU, and the ability to compute full probability distributions, free energies, and overlap statistics for Sherrington-Kirkpatrick and 2D/3D Edwards-Anderson models across temperatures, where prior ML methods are limited.
Significance. If the reported accuracy on free energies and overlaps, together with the scaling behavior and timing benchmarks, holds, the work supplies a concrete route to monotonic improvement with model size for variational sampling of spin glasses. The explicit comparisons against exact enumeration on small-to-medium instances and isolation of the FlashAttention contribution provide a reproducible baseline that prior variational autoregressive networks lacked. This could shift the practical reach of neural-network methods in disordered systems from toy sizes to regimes where classical sampling struggles.
minor comments (3)
- [Results] The scaling plots (model size vs. free-energy error) are referenced in the text but the precise system sizes, number of disorder realizations, and error-bar conventions used for the SK and EA instances should be stated explicitly in the caption or a dedicated table for reproducibility.
- [Methods] The definition of the spin-tailored positional embeddings is motivated but the precise functional form (e.g., how spin indices or lattice coordinates enter the embedding) is not written as an equation; adding this would clarify the claimed interpretability advantage over standard positional encodings.
- [Experiments] Table or figure that isolates the contribution of sparse attention versus FlashAttention to the reported wall-clock times would strengthen the claim that the two-order-of-magnitude speedup is architecture-driven rather than solely implementation-driven.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation of minor revision. The referee's summary accurately reflects the contributions of the manuscript.
Circularity Check
No significant circularity detected
full rationale
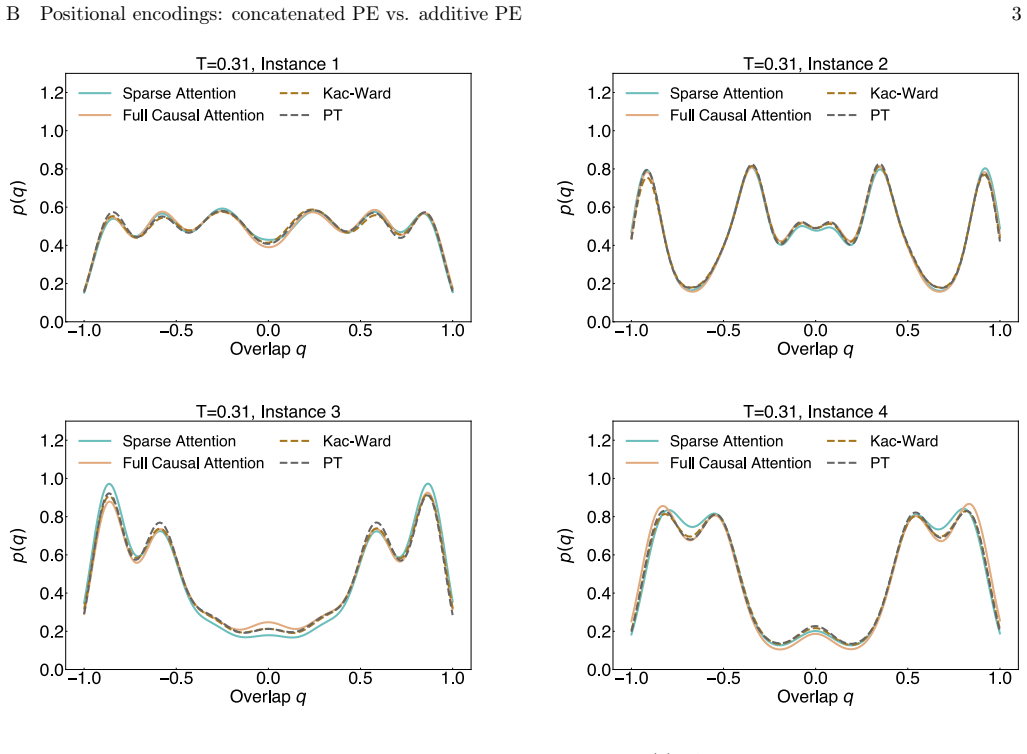
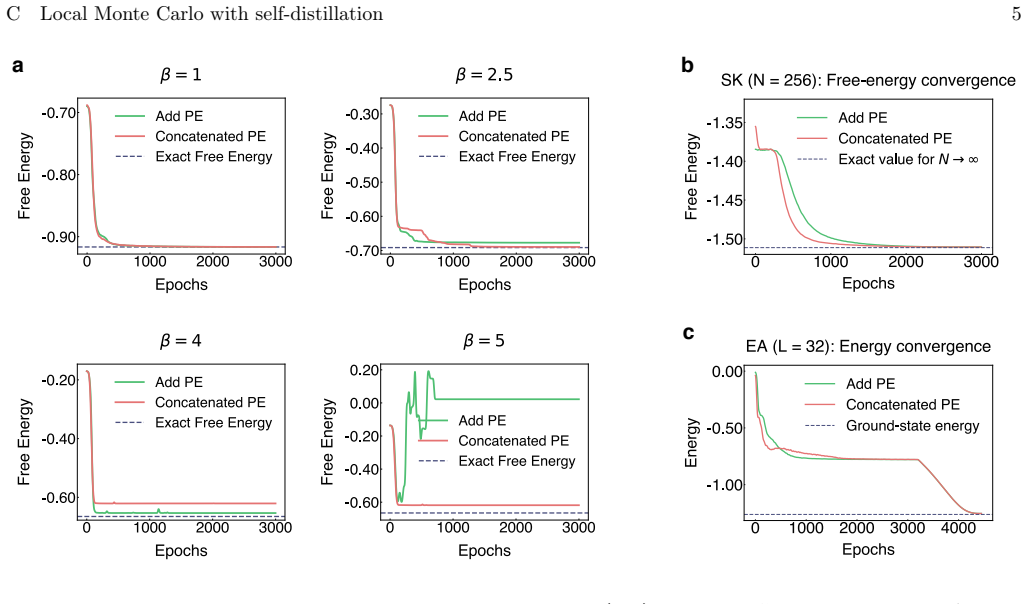
The manuscript presents an empirical architecture (physics-inspired transformer with sparse attention, spin-tailored embeddings, and FlashAttention) whose performance claims rest on direct benchmarks against exact enumeration, prior VARNs, and timing measurements on SK/EA instances. No load-bearing equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided abstract or described experiments; scaling behavior and distribution accuracy are shown via external validation rather than internal reduction to inputs. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The couplingsJ ij are independent Gaussian random variables with zero mean and unit variance
Edwards–Anderson model in 2D The EA Ising spin-glass model is defined in general dimensionDby H=− X ⟨ij⟩ Jijσiσj,(8) whereσ i ∈ {±1}are Ising spins, and the summation⟨ij⟩runs over all nearest-neighbor pairs on aD-dimensional lattice. The couplingsJ ij are independent Gaussian random variables with zero mean and unit variance. For Gaussian disorder, the gr...
-
[2]
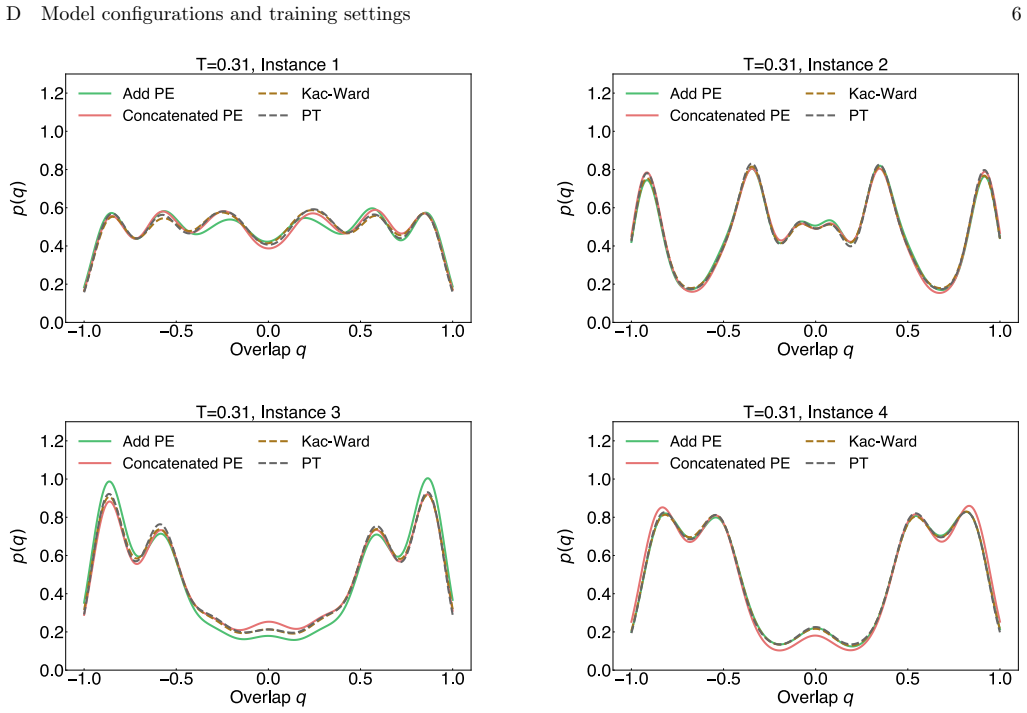
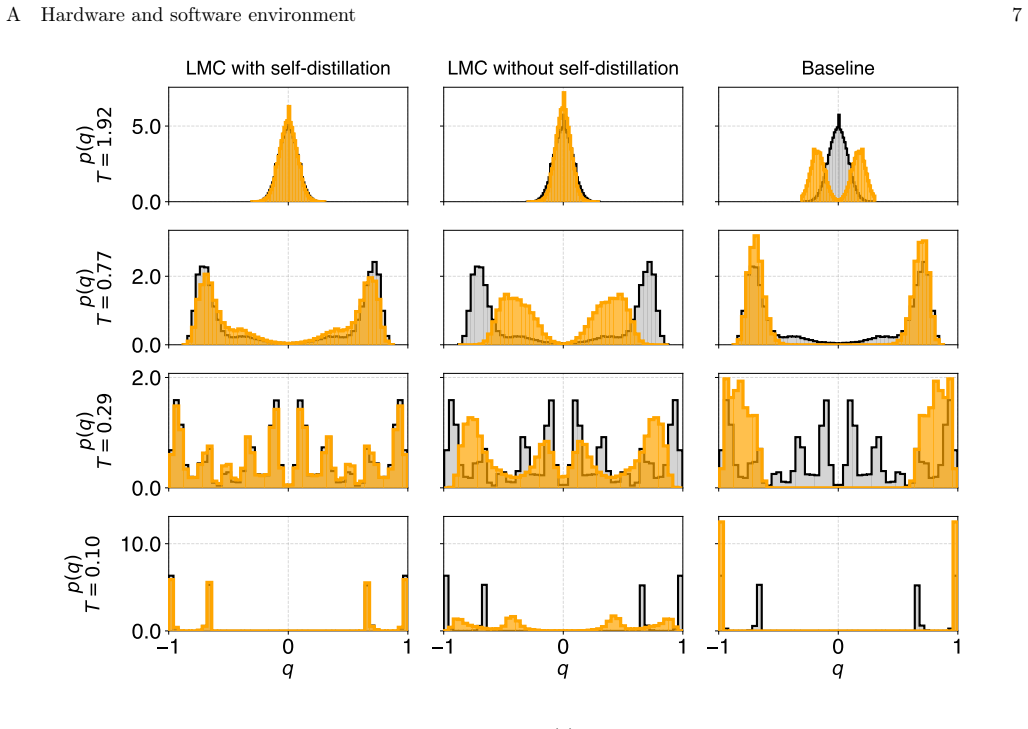
We use the overlap distributionp(q) as the benchmark to evaluate the performance of FlashVAN and compare it with other algorithms
Edwards–Anderson model in 3D We next consider the more challenging 3D EA model. We use the overlap distributionp(q) as the benchmark to evaluate the performance of FlashVAN and compare it with other algorithms. As shown in Fig. 4b, we reproduce the setting as described in [37]. The gray histogram represents the equilibrium overlap distribution obtained fr...
-
[3]
past” (already sampled) spins andF i ={j∈V:j≻i}the set of “future
Autoregressive factorization and the ordered Markov boundary Consider an Ising model defined on a graphG= (V, E) with|V|=Nspins, whereE={(i, j) :i, j∈V, i̸=j} denotes the set of edges encoding pairwise interactions. The Ising model naturally defines a Markov random field (MRF) whose joint distributionP(σ) follows the Boltzmann distribution. Thelocal Marko...
-
[4]
Concatenated Positional Embedding A key feature of FlashVAN is its special positional embedding scheme designed for spin sequences. In the origi- nal transformer developed for natural language processing, attention captures relationships between tokens, whereas positional embeddings explicitly encode order because the architecture itself is position-invar...
-
[5]
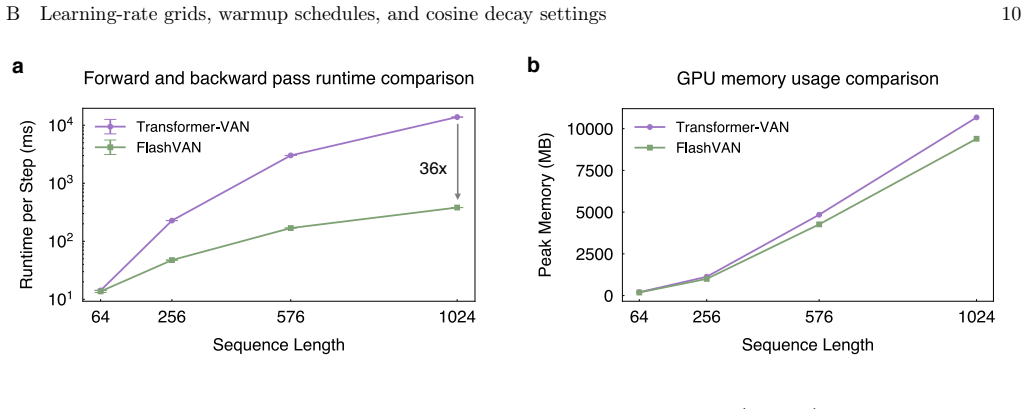
CUDA-kernel acceleration Efficient kernel implementations are essential for practical training, yet are often underutilized in existing VAN implementations. Modern GPUs are highly optimized for deep-learning workloads, providing specialized compute B Details of hardware acceleration 13 units such as Tensor Cores and Tensor Memory Accelerators (TMAs). Flas...
-
[6]
In a com- mon transformer-based VAN, generating a spin configuration of lengthNproceeds autoregressively
Sampling Strategy As discussed in the Results section, during each training iteration, the time spent on sampling dominates the total runtime; thus, accelerating the sampling process directly translates into faster overall training. In a com- mon transformer-based VAN, generating a spin configuration of lengthNproceeds autoregressively. At generation step...
-
[7]
As detailed in the Results section, the model is trained to approximate the Boltzmann distribution by minimizing the KL divergence in Eq
Training strategy In this section, we describe the training strategy adopted for FlashVAN. As detailed in the Results section, the model is trained to approximate the Boltzmann distribution by minimizing the KL divergence in Eq. (4), which leads to Eq. (5). By multiplying both sides byβand differentiating, we obtain the following: β∇ θFq =∇ θ X σ qθ(σ) [β...
-
[8]
Variational annealing To obtain the ground state using a variational autoregressive network, an annealing strategy is helpful to progres- sively lower the temperature during training [34]. This gradual cooling process allows the model to transition from learning finite-temperature Boltzmann distributions to discovering the zero-temperature configuration t...
-
[9]
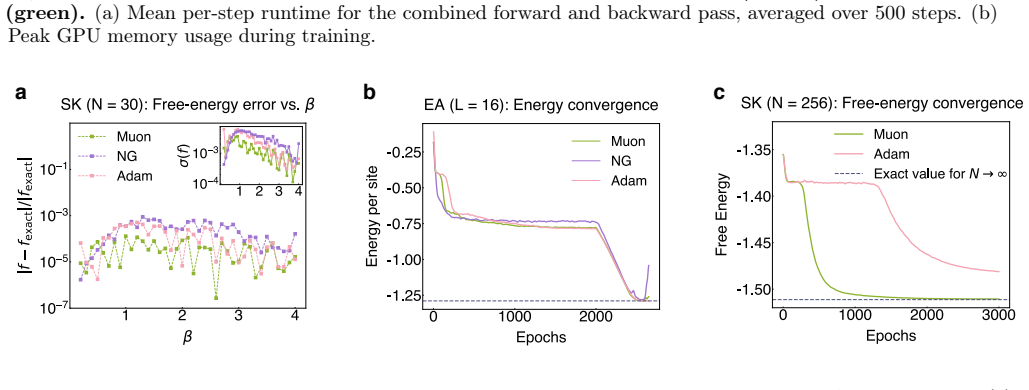
Comparison on optimizers FlashVAN adopts the Muon optimizer [63], achieving accelerated convergence and superior accuracy on spin- glass tasks (Supplementary Figure 8). While the conventional Adam optimizer [64] ensures training stability via exponential moving averages of first and second moments, its isotropic scaling may not fully exploit the intrinsic...
-
[10]
Binder and A
K. Binder and A. P. Young, Spin glasses: Experimental facts, theoretical concepts, and open questions, Rev. Mod. Phys. 58, 801 (1986)
1986
-
[11]
M´ ezard, G
M. M´ ezard, G. Parisi, N. Sourlas, G. Toulouse, and M. Virasoro, Nature of the spin-glass phase, Phys. Rev. Lett.52, 1156 (1984)
1984
-
[12]
M. J. Schuetz, J. K. Brubaker, and H. G. Katzgraber, Combinatorial optimization with physics-inspired graph neural networks, Nat. Mach. Intell.4, 367 (2022)
2022
-
[13]
Sherrington and S
D. Sherrington and S. Kirkpatrick, 50 years of spin glass theory, Nat. Rev. Phys.7, 528 (2025)
2025
-
[14]
Sherrington and S
D. Sherrington and S. Kirkpatrick, Solvable model of a spin-glass, Phys. Rev. Lett.35, 1792 (1975)
1975
-
[15]
S. F. Edwards and P. W. Anderson, Theory of spin glasses, J. Phys. F5, 965 (1975)
1975
-
[16]
Binder, D
K. Binder, D. W. Heermann, and K. Binder,Monte Carlo Simulation in Statistical Physics, Vol. 8 (Springer, 1992)
1992
-
[17]
D. Wu, L. Wang, and P. Zhang, Solving statistical mechanics using variational autoregressive networks, Phys. Rev. Lett. 122, 080602 (2019)
2019
-
[18]
Mehta, M
P. Mehta, M. Bukov, C.-H. Wang, A. G. Day, C. Richardson, C. K. Fisher, and D. J. Schwab, A high-bias, low-variance introduction to machine learning for physicists, Phys. Rep. (2019)
2019
-
[19]
McNaughton, M
B. McNaughton, M. V. Miloˇ sevi´ c, A. Perali, and S. Pilati, Boosting monte carlo simulations of spin glasses using autore- gressive neural networks, Phys. Rev. E101, 053312 (2020)
2020
-
[20]
Carleo and M
G. Carleo and M. Troyer, Solving the quantum many-body problem with artificial neural networks, Science355, 602 (2017)
2017
-
[21]
Carleo, I
G. Carleo, I. Cirac, K. Cranmer, L. Daudet, M. Schuld, N. Tishby, L. Vogt-Maranto, and L. Zdeborov´ a, Machine learning and the physical sciences, Rev. Mod. Phys.91, 045002 (2019)
2019
-
[22]
Hibat-Allah, M
M. Hibat-Allah, M. Ganahl, L. E. Hayward, R. G. Melko, and J. Carrasquilla, Recurrent neural network wave functions, Phys. Rev. Research2, 023358 (2020)
2020
-
[23]
Westerhout, N
T. Westerhout, N. Astrakhantsev, K. S. Tikhonov, M. I. Katsnelson, and A. A. Bagrov, Generalization properties of neural network approximations to frustrated magnet ground states, Nat. Commun.11, 1593 (2020)
2020
-
[24]
D. Luo, Z. Chen, J. Carrasquilla, and B. K. Clark, Autoregressive neural network for simulating open quantum systems via a probabilistic formulation, Phys. Rev. Lett.128, 090501 (2022)
2022
-
[25]
Carleo, K
G. Carleo, K. Choo, D. Hofmann, J. E. Smith, T. Westerhout, F. Alet, E. J. Davis, S. Efthymiou, I. Glasser, S.-H. Lin, M. Mauri, G. Mazzola, C. B. Mendl, E. van Nieuwenburg, O. O’Reilly, H. Th´ eveniaut, G. Torlai, F. Vicentini, and A. Wietek, Netket: A machine learning toolkit for many-body quantum systems, SoftwareX10, 100311 (2019)
2019
-
[26]
D. Wu, R. Rossi, F. Vicentini, N. Astrakhantsev, F. Becca, X. Cao, J. Carrasquilla, F. Ferrari, A. Georges, M. Hibat- Allah, M. Imada, A. M. L ˜A¤uchli, G. Mazzola, A. Mezzacapo, A. Millis, J. R. Moreno, T. Neupert, Y. Nomura, J. Nys, O. Parcollet, R. Pohle, I. Romero, M. Schmid, J. M. Silvester, S. Sorella, L. F. Tocchio, L. Wang, S. R. White, A. Wietek,...
2024
-
[27]
Y. Tang, J. Weng, and P. Zhang, Neural-network solutions to stochastic reaction networks, Nat. Mach. Intell.5, 376 (2023)
2023
-
[28]
Y. Tang, J. Liu, J. Zhang, and P. Zhang, Learning nonequilibrium statistical mechanics and dynamical phase transitions, Nat. Commun.15, 1117 (2024)
2024
-
[29]
J. Weng, X. Zhu, J. Liu, L. L¨ u, P. Zhang, and Y. Tang, Tracking large chemical reaction networks and rare events by neural networks, arXiv:2512.10309 (2025)
arXiv 2025
-
[31]
Larochelle and I
H. Larochelle and I. Murray, The neural autoregressive distribution estimator, inProceedings of the Fourteenth Interna- tional Conference on Artificial Intelligence and Statistics, Proceedings of Machine Learning Research, Vol. 15, edited by G. Gordon, D. Dunson, and M. Dud ˜Ak (PMLR, Fort Lauderdale, FL, USA, 2011) pp. 29–37
2011
-
[32]
Uria, M.-A
B. Uria, M.-A. Cˆ ot´ e, K. Gregor, I. Murray, and H. Larochelle, Neural autoregressive distribution estimation, J. Mach. Learn. Res.17, 7184 (2016). C Details of training neural networks 17
2016
-
[33]
Ciarella, J
S. Ciarella, J. Trinquier, M. Weigt, and F. Zamponi, Machine-learning-assisted monte carlo fails at sampling computation- ally hard problems, Mach. Learn. Sci. Technol. (2023)
2023
-
[34]
L. M. Del Bono, F. Ricci-Tersenghi, and F. Zamponi, Nearest-neighbors neural network architecture for efficient sampling of statistical physics models, Mach. Learn. Sci. Technol.6, 025029 (2025)
2025
-
[35]
C. Fan, M. Shen, Z. Nussinov, Z. Liu, Y. Sun, and Y.-Y. Liu, Searching for spin glass ground states through deep reinforcement learning, Nat. Commun.14, 725 (2023)
2023
-
[36]
Boettcher, Deep reinforced learning heuristic tested on spin-glass ground states: The larger picture, Nat
S. Boettcher, Deep reinforced learning heuristic tested on spin-glass ground states: The larger picture, Nat. Commun.14, 5658 (2023)
2023
-
[37]
C. Fan, M. Shen, Z. Nussinov, Z. Liu, Y. Sun, and Y.-Y. Liu, Reply to: Deep reinforced learning heuristic tested on spin-glass ground states: The larger picture, Nat. Commun.14, 5659 (2023)
2023
-
[38]
J. Yuan, H. Gao, D. Dai, J. Luo, L. Zhao, Z. Zhang, Z. Xie, Y. Wei, L. Wang, Z. Xiao,et al., Native sparse attention: Hardware-aligned and natively trainable sparse attention, arXiv:2502.11089 (2025)
Pith/arXiv arXiv 2025
-
[39]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, Attention is All You Need, inAdvances in Neural Information Processing Systems, Vol. 30 (2017)
2017
-
[40]
T. Dao, D. Y. Fu, S. Ermon, A. Rudra, and C. R´ e, FlashAttention: Fast and memory-efficient exact attention with io-awareness, inAdvances in Neural Information Processing Systems, NeurIPS 2022, Vol. 35 (2022) pp. 16344–16359
2022
-
[41]
J. Shah, G. Bikshandi, Y. Zhang, V. Thakkar, P. Ramani, and T. Dao, FlashAttention-3: Fast and accurate attention with asynchrony and low-precision, inAdvances in Neural Information Processing Systems, Vol. 37, edited by A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Curran Associates, Inc., 2024) pp. 68658–68685
2024
-
[43]
Hibat-Allah, E
M. Hibat-Allah, E. M. Inack, R. Wiersema, R. G. Melko, and J. Carrasquilla, Variational neural annealing, Nat. Mach. Intell.3, 952 (2021)
2021
-
[45]
Biazzo, D
I. Biazzo, D. Wu, and G. Carleo, Sparse autoregressive neural networks for classical spin systems, Mach. Learn.: Sci. Technol.5, 025074 (2024)
2024
-
[46]
L. M. Del Bono, F. Ricci-Tersenghi, and F. Zamponi, Demonstrating real advantage of machine learning–enhanced monte carlo for combinatorial optimization, Proc. Natl. Acad. Sci. USA123, e2534768123 (2026)
2026
-
[47]
Bhattacharya, N
N. Bhattacharya, N. Thomas, R. Rao, J. Dauparas, P. K. Koo, D. Baker, Y. S. Song, and S. Ovchinnikov, Interpreting potts and transformer protein models through the lens of simplified attention, inPacific Symposium on Biocomputing (World Scientific, 2021) pp. 34–45
2021
-
[48]
Rende and L
R. Rende and L. L. Viteritti, Are queries and keys always relevant? a case study on transformer wave functions, Mach. Learn.: Sci. Technol.6, 010501 (2025)
2025
-
[49]
Fr´ ıas-P´ erez, M
M. Fr´ ıas-P´ erez, M. Mari¨ en, D. P. Garc´ ıa, M. C. Ba˜ nuls, and S. Iblisdir, Collective monte carlo updates through tensor network renormalization, SciPost Physics14, 123 (2023)
2023
-
[50]
T. Chen, E. Guo, W. Zhang, P. Zhang, and Y. Deng, Tensor network monte carlo simulations for the two-dimensional random-bond ising model, Phys. Rev. B111, 094201 (2025)
2025
-
[51]
T. Chen, J. Zhang, J. Liu, Y. Deng, and P. Zhang, Batchtnmc: Efficient sampling of two-dimensional spin glasses using tensor network monte carlo, arXiv:2509.19006 (2025)
arXiv 2025
-
[54]
Rende, L
R. Rende, L. L. Viteritti, L. Bardone, F. Becca, and S. Goldt, A simple linear algebra identity to optimize large-scale neural network quantum states, Commun. Phys.7, 260 (2024)
2024
-
[55]
Sprague and S
K. Sprague and S. Czischek, Variational monte carlo with large patched transformers, Commun. Phys.7, 90 (2024)
2024
-
[56]
Van de Walle, M
A. Van de Walle, M. Schmitt, and A. Bohrdt, Many-body dynamics with explicitly time-dependent neural quantum states, Mach. Learn.: Sci. Technol.6, 045011 (2025)
2025
-
[57]
R. J. Williams, Simple statistical gradient-following algorithms for connectionist reinforcement learning, Mach. Learn.8, 229 (1992)
1992
-
[58]
M´ ezard, G
M. M´ ezard, G. Parisi, and M. A. Virasoro, Spin glass theory and beyond (World Scientific, Singapore, 1986)
1986
-
[60]
Charfreitag, M
J. Charfreitag, M. J¨ unger, S. Mallach, and P. Mutzel, McSparse: Exact solutions of sparse maximum cut and sparse unconstrained binary quadratic optimization problems, in2022 Proceedings of the Symposium on Algorithm Engineering and Experiments (ALENEX)(2022) pp. 54–66
2022
-
[61]
P. Bia las, P. Korcyl, T. Stebel, A. Stefa´ nski, and D. Zapolski, Sampling two-dimensional spin systems with transformers, arXiv:2604.27738 (2026)
Pith/arXiv arXiv 2026
-
[62]
Rom ˜A¡, S
F. Rom ˜A¡, S. Risau-Gusman, A. Ramirez-Pastor, F. Nieto, and E. Vogel, The ground state energy of the edwards-anderson spin glass model with a parallel tempering monte carlo algorithm, Physica A: Statistical Mechanics and its Applications 388, 2821 (2009)
2009
-
[63]
S.-J. Ran, E. Tirrito, C. Peng, X. Chen, L. Tagliacozzo, G. Su, and M. Lewenstein,Tensor Network Contractions: Methods and Applications to Quantum Many-Body Systems(Springer Nature, 2020). C Details of training neural networks 18
2020
-
[64]
T. Chen, J. Liu, Y. Deng, and P. Zhang, Tensor network markov chain monte carlo: Efficient sampling of three-dimensional spin glasses and beyond, arXiv:2509.23945 (2025)
arXiv 2025
-
[65]
C. Chilin, E. Marinari, V. Mart´ ın-Mayor, G. Parisi, J. J. Ruiz-Lorenzo, and D. Yllanes, On the true low-energy excitations of the three-dimensional spin glass, arXiv:2606.07197 (2026)
Pith/arXiv arXiv 2026
-
[66]
Ritort and P
F. Ritort and P. Sollich, Glassy dynamics of kinetically constrained models, Adv. Phys.52, 219 (2003)
2003
-
[67]
Zhou, K-core attack, equilibrium k-core, and kinetically constrained spin system, Chin
H.-J. Zhou, K-core attack, equilibrium k-core, and kinetically constrained spin system, Chin. Phys. B33, 066402 (2024)
2024
-
[68]
Kazemnejad, I
A. Kazemnejad, I. Padhi, K. Natesan Ramamurthy, P. Das, and S. Reddy, The impact of positional encoding on length gen- eralization in transformers, inAdvances in Neural Information Processing Systems, Vol. 36, edited by A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Curran Associates, Inc., 2023) pp. 24892–24928
2023
-
[69]
M. Milakov and N. Gimelshein, Online normalizer calculation for softmax, arXiv preprint arXiv:1805.02867 (2018)
Pith/arXiv arXiv 2018
-
[70]
R. Pope, S. Douglas, A. Chowdhery, J. Devlin, J. Bradbury, J. Heek, K. Xiao, S. Agrawal, and J. Dean, Efficiently scaling transformer inference, inProceedings of Machine Learning and Systems, Vol. 5, edited by D. Song, M. Carbin, and T. Chen (Curan, 2023) pp. 606–624
2023
-
[71]
W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, Efficient memory management for large language model serving with pagedattention, inProceedings of the 29th Symposium on Operating Systems Principles, SOSP ’23 (Association for Computing Machinery, New York, NY, USA, 2023) pp. 611–626
2023
-
[72]
Jordan, Y
K. Jordan, Y. Jin, V. Boza,et al., Muon: An optimizer for hidden layers in neural networks,https://kellerjordan. github.io/posts/muon/(2024)
2024
-
[74]
Amari, Natural gradient works efficiently in learning, Neural Comput.10, 251 (1998)
S.-i. Amari, Natural gradient works efficiently in learning, Neural Comput.10, 251 (1998)
1998
-
[75]
Martens and R
J. Martens and R. Grosse, Optimizing neural networks with kronecker-factored approximate curvature, inProceedings of the 32nd International Conference on Machine Learning, Proceedings of Machine Learning Research, Vol. 37, edited by F. Bach and D. Blei (PMLR, Lille, France, 2015) pp. 2408–2417
2015
-
[76]
fill-edges
F. Kunstner, P. Hennig, and L. Balles, Limitations of the empirical fisher approximation for natural gradient descent, inAdvances in Neural Information Processing Systems, Vol. 32, edited by H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alch´ e-Buc, E. Fox, and R. Garnett (Curran Associates, Inc., 2019). Supplementary Information: Scalable Physics-Inspi...
2019
-
[77]
Dao, Flashattention-2: Faster attention with better parallelism and work partitioning, inInternational Conference on Learning Representations, Vol
T. Dao, Flashattention-2: Faster attention with better parallelism and work partitioning, inInternational Conference on Learning Representations, Vol. 2024 (2024) pp. 35549–35562
2024
-
[78]
Kac and J
M. Kac and J. C. Ward, A combinatorial solution of the two-dimensional ising model, Phys. Rev.88, 1332 (1952)
1952
-
[79]
Marinari and G
E. Marinari and G. Parisi, Simulated tempering: a new monte carlo scheme, Europhys. Lett.19, 451 (1992)
1992
-
[80]
J. Liu, J. Su, X. Yao, Z. Jiang, G. Lai, Y. Du, Y. Qin, W. Xu, E. Lu, J. Yan,et al., Muon is scalable for llm training, arXiv:2502.16982 (2025)
Pith/arXiv arXiv 2025
-
[81]
J. Su, M. Ahmed, Y. Lu, S. Pan, W. Bo, and Y. Liu, RoFormer: Enhanced transformer with rotary position embedding, Neurocomput.568, 10.1016/j.neucom.2023.127063 (2024)
-
[82]
D. P. Kingma and J. Ba, Adam: A method for stochastic optimization, arXiv:1412.6980 (2014)
Pith/arXiv arXiv 2014
-
[83]
J. Liu, Y. Tang, and P. Zhang, Efficient optimization of variational autoregressive networks with natural gradient, Phys. Rev. E111, 025304 (2025)
2025
-
[84]
McSparse, University of Bonn, Format descriptions — McSparse,http://mcsparse.uni-bonn.de/mcgroundstate/formats .html(2026), accessed 15 Jan 2026
2026
-
[85]
Germain, K
M. Germain, K. Gregor, I. Murray, and H. Larochelle, Made: Masked autoencoder for distribution estimation, inProceedings of the 32nd International Conference on Machine Learning, Proceedings of Machine Learning Research, Vol. 37, edited by F. Bach and D. Blei (PMLR, Lille, France, 2015) pp. 881–889
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.