EnerInfer: Energy-Aware On-Device LLM Inference
Pith reviewed 2026-06-26 07:55 UTC · model grok-4.3
The pith
EnerInfer predicts throughput and power from model structure to select energy-efficient NPU and memory frequencies for on-device LLM inference without QoE loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EnerInfer is the first on-device LLM inference framework that jointly manages energy efficiency, throughput, and thermal comfort by replacing per-model profiling with disaggregated model-structure-aware prediction of throughput and power, ranking-driven online feedback for configuration selection, and limited-horizon thermal prediction for dynamic mode switching.
What carries the argument
Disaggregated model-structure-aware prediction of throughput and power with ranking-driven online feedback and limited-horizon thermal prediction to select NPU/DDR frequency settings.
Load-bearing premise
Predictions of throughput and power derived from model structure generalize accurately to unseen LLMs and changing runtime conditions without per-model profiling or component-level sensors.
What would settle it
Run an unseen LLM on a phone, apply the predicted efficient frequency setting under typical interference, and measure whether energy use drops by the claimed amount while response latency and thermal limits stay within QoE bounds.
Figures






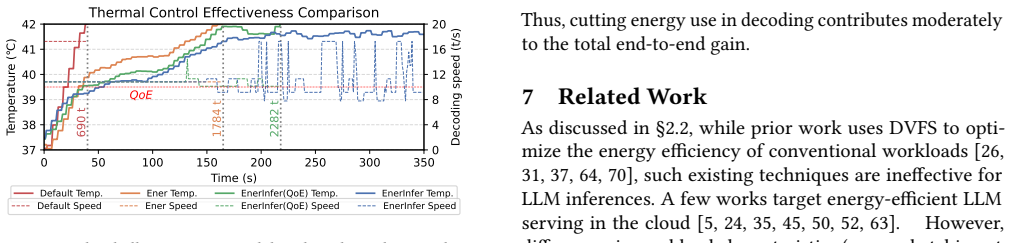
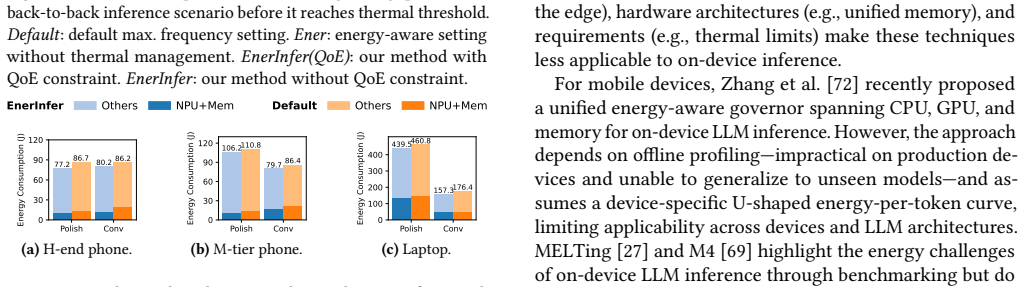
read the original abstract
On-device LLM inference is increasingly attractive for privacy-preserving, reliable, and cost-effective deployment, yet its energy and thermal costs remain a critical bottleneck. Existing systems primarily optimize for decoding speed, implicitly assuming that faster execution is always preferable. We show instead that on-device LLM inference often has exploitable configuration slack: modestly lowering NPU and memory frequencies preserves quality of experience (QoE) while substantially improving energy efficiency and reducing heat. Realizing this opportunity in production is challenging. The most energy-efficient NPU/DDR setting varies with the model, inference engine, platform, and runtime conditions, with no stable ranking across configurations. Commercial devices further lack component-level power sensing, and shell temperature evolves with request arrivals, response lengths, and thermal history. To address these challenges, we propose EnerInfer, the first on-device LLM inference framework that jointly manages energy efficiency, throughput, and thermal comfort for LLM workloads. EnerInfer replaces per-model profiling and sensor-heavy control with disaggregated, model-structure-aware prediction and ranking-driven online feedback. It predicts throughput and power for unseen LLMs across NPU/DDR frequency settings, selects QoE-satisfying efficient configurations under runtime interference, and uses lightweight limited-horizon thermal prediction to dynamically switch between energy-optimized and thermally constrained inference. Evaluations on real-world LLMs show that EnerInfer improves energy efficiency by up to 65%, 12%, and 24% on phones, a laptop, and a development board, respectively, without QoE violation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EnerInfer, an on-device LLM inference framework that uses disaggregated model-structure-aware predictions of throughput and power to select QoE-safe NPU/DDR frequency configurations, combined with limited-horizon thermal prediction for dynamic switching. It claims this replaces per-model profiling and component sensors, yielding energy-efficiency gains of up to 65% on phones, 12% on a laptop, and 24% on a development board across real-world LLMs without QoE violation.
Significance. If the prediction-based selection generalizes reliably, the work would offer a practical advance for energy- and thermally-constrained on-device LLM deployment by exploiting configuration slack that speed-only optimizers miss. The disaggregated prediction approach could reduce the need for device-specific profiling, which is valuable for production systems.
major comments (2)
- [Abstract] Abstract: the headline energy-efficiency gains (65%/12%/24%) rest on the claim that model-structure-aware throughput/power predictions generalize to unseen LLMs and select QoE-safe settings without per-model profiling or component sensors. No prediction accuracy metrics, training-set composition, held-out LLM results, or error analysis under runtime interference are supplied, so the central claim that the ranking step preserves QoE while delivering the reported savings cannot be evaluated.
- [Evaluation] Evaluation section (implied by abstract claims): the absence of cross-model validation or sensitivity analysis for the predictors directly undermines the assertion that the framework works for LLMs never seen during predictor construction. If prediction error increases for models whose structure deviates from the training distribution, the QoE guarantee or the energy savings can fail; this is load-bearing for the replacement of profiling.
minor comments (1)
- [Abstract] The abstract refers to 'disaggregated, model-structure-aware prediction' without defining the structural features used or the disaggregation granularity; a short methods paragraph would clarify this for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on EnerInfer. The comments highlight the need for clearer presentation of the prediction components that underpin our energy-efficiency claims. We respond to each major comment below and indicate where revisions will strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline energy-efficiency gains (65%/12%/24%) rest on the claim that model-structure-aware throughput/power predictions generalize to unseen LLMs and select QoE-safe settings without per-model profiling or component sensors. No prediction accuracy metrics, training-set composition, held-out LLM results, or error analysis under runtime interference are supplied, so the central claim that the ranking step preserves QoE while delivering the reported savings cannot be evaluated.
Authors: We agree the abstract is too terse on these supporting details. The full manuscript (Section 4.2) describes the disaggregated predictor training on a set of 12 LLMs and reports MAE for throughput and power on held-out models, plus a sensitivity study under background interference. However, these numbers are not summarized in the abstract. We will revise the abstract to include a concise statement of prediction accuracy (e.g., average MAE < 8% for throughput and < 12% for power on held-out models) and note the training-set composition. We will also add a short paragraph in the evaluation section explicitly linking prediction error to QoE preservation under the reported workloads. revision: yes
-
Referee: [Evaluation] Evaluation section (implied by abstract claims): the absence of cross-model validation or sensitivity analysis for the predictors directly undermines the assertion that the framework works for LLMs never seen during predictor construction. If prediction error increases for models whose structure deviates from the training distribution, the QoE guarantee or the energy savings can fail; this is load-bearing for the replacement of profiling.
Authors: The manuscript does contain cross-model results (held-out LLMs in Section 5.3) and a limited sensitivity analysis to structural deviation. Nevertheless, the referee is correct that a more explicit ablation showing how prediction error scales with model size and architecture deviation would strengthen the generalization argument. We will expand the evaluation section with an additional table reporting per-model prediction error and the resulting QoE margin for three LLMs outside the original training distribution, plus a short discussion of failure modes when error exceeds the QoE slack. revision: yes
Circularity Check
No circularity; empirical predictors presented without self-referential reduction
full rationale
The provided abstract and context describe a systems framework that fits disaggregated predictors on model structure to estimate throughput/power for unseen LLMs, then uses those estimates for configuration selection. No equations, self-definitions, or load-bearing self-citations are shown that would make any 'prediction' equivalent to its training inputs by construction. The central energy-saving claims rest on reported empirical results across devices rather than a closed derivation chain, so the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Abdelhafez, Karthik Pattabiraman, and Matei Ripeanu
Amirhossein Ahmadi, Hazem A. Abdelhafez, Karthik Pattabiraman, and Matei Ripeanu. 2023. EdgeEngine: A Thermal-Aware Optimization Framework for Edge Inference. In2023 IEEE/ACM Symposium on Edge Computing (SEC). 67–79
2023
-
[2]
Joshua Ainslie, James Lee-Thorp, Michiel De Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. 2023. Gqa: Training generalized multi-query transformer models from multi-head checkpoints.arXiv (2023)
2023
- [3]
-
[4]
Apple. 2024. Introducing Apple’s On-Device and Server Foundation Models.https://machinelearning.apple.com/research/introducing- apple-foundation-models. Accessed 7 Feb 2025
2024
-
[5]
Mauricio Fadel Argerich and Marta Patiño-Martínez. 2024. Measur- ing and Improving the Energy Efficiency of Large Language Models Inference.IEEE Access12 (2024), 80194–80207
2024
-
[6]
Mariette Awad, Rahul Khanna, Mariette Awad, and Rahul Khanna
-
[7]
Support vector regression.Efficient learning machines: Theories, concepts, and applications for engineers and system designers(2015), 67–80
2015
-
[8]
Edward Beeching, Clémentine Fourrier, Nathan Habib, Sheon Han, Nathan Lambert, Nazneen Rajani, Omar Sanseviero, Lewis Tunstall, and Thomas Wolf. [n. d.]. Open LLM Leaderboard.https://huggingfac e.co/spaces/HuggingFaceH4/open_llm_leaderboard. Accessed 11 Apr 2025
2025
-
[9]
Mulugeta K Berhe. 2007. Ergonomic temperature limits for hand- held electronic devices. InInternational Electronic Packaging Technical Conference and Exhibition, Vol. 42789. 1041–1047
2007
-
[10]
Leo Breiman. 2001. Random forests.Machine learning45 (2001), 5–32
2001
-
[11]
Marc Brysbaert. 2019. How many words do we read per minute? A review and meta-analysis of reading rate.Journal of Memory and Language109 (2019), 104047
2019
- [12]
-
[13]
Marcus Chow and Daniel Wong. 2023. CoFRIS: Coordinated frequency and resource scaling for GPU inference servers. InProceedings of the 14th International Green and Sustainable Computing Conference. 45–51
2023
-
[14]
Lucian Codrescu, Willie Anderson, Suresh Venkumanhanti, Mao Zeng, Erich Plondke, Chris Koob, Ajay Ingle, Charles Tabony, and Rick Maule
-
[15]
Hexagon DSP: An architecture optimized for mobile multimedia and communications.IEEE Micro34, 2 (2014), 34–43
2014
-
[16]
Benj Edwards. 2024. Exponential growth brews 1 million AI models on Hugging Face.https://arstechnica.com/information-technology /2024/09/ai-hosting-platform-surpasses-1-million-models-for-the- first-time/. Accessed 7 Feb 2025
2024
-
[17]
FNIRSI. 2025. FNB58 USB Fast Charge Tester.https://www.fnirsi.com /products/fnb58. Accessed 25 Apr 2025
2025
-
[18]
Ricardo Gonzalez, Benjamin M Gordon, and Mark A Horowitz. 1997. Supply and threshold voltage scaling for low power CMOS.IEEE Journal of Solid-State Circuits32, 8 (1997), 1210–1216
1997
-
[19]
Google. 2025. Chat with Gemini to supercharge your creativity and productivity.https://store.google.com/intl/en/ideas/categories/ai/. Accessed 7 Feb 2025
2025
-
[20]
Google. 2025. Thermal mitigation.https://source.android.com/docs/ core/power/thermal-mitigation. Accessed 15 May 2025
2025
-
[21]
Joseph L Greathouse and Gabriel H Loh. 2018. Machine learning for performance and power modeling of heterogeneous systems. In Proceedings of the International Conference on Computer-Aided Design. 1–6
2018
-
[22]
Ling Huang, Jinzhu Jia, Bin Yu, Byung-Gon Chun, Petros Maniatis, and Mayur Naik. 2010. Predicting execution time of computer programs using sparse polynomial regression. InAdvances in neural information processing systems (NeurIPS). 883–891
2010
-
[23]
Christian Janiesch, Patrick Zschech, and Kai Heinrich. 2021. Machine learning and deep learning.Electronic markets31, 3 (2021), 685–695
2021
-
[24]
Mojan Javaheripi, Sébastien Bubeck, Marah Abdin, Jyoti Aneja, Se- bastien Bubeck, Caio César Teodoro Mendes, Weizhu Chen, Allie Del Giorno, Ronen Eldan, Sivakanth Gopi, et al. 2023. Phi-2: The sur- prising power of small language models.Microsoft Research Blog1, 3 (2023), 3
2023
-
[25]
JEDEC. 2023. LOW POWER DOUBLE DATA RATE (LPDDR) 5/5X. https://www.jedec.org/standards- documents/docs/jesd209- 5c. Accessed 25 Apr 2025
2023
-
[26]
Andreas Kosmas Kakolyris, Dimosthenis Masouros, Sotirios Xydis, and Dimitrios Soudris. 2024. SLO-Aware GPU DVFS for Energy-Efficient LLM Inference Serving.IEEE Computer Architecture Letters23, 2 (July 2024), 150–153
2024
-
[27]
M. G. KENDALL. 1938. A NEW MEASURE OF RANK CORRELATION. Biometrika30, 1-2 (06 1938), 81–93
1938
-
[28]
Seyeon Kim, Kyungmin Bin, Sangtae Ha, Kyunghan Lee, and Song Chong. 2022. zTT: Learning-Based DVFS with Zero Thermal Throt- tling for Mobile Devices.GetMobile: Mobile Comp. and Comm.25, 4 (March 2022), 30–34
2022
-
[29]
Stefanos Laskaridis, Kleomenis Katevas, Lorenzo Minto, and Hamed Haddadi. 2024. MELTing Point: Mobile Evaluation of Language Trans- formers. InProceedings of the 30th Annual International Conference on Mobile Computing and Networking (MobiCom). 890–907
2024
-
[30]
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. 2021. GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding. InInternational Conference on Learning Representations
2021
-
[31]
Yaniv Leviathan, Matan Kalman, and Yossi Matias. 2023. Fast Inference from Transformers via Speculative Decoding. InProceedings of the 40th ICML (Proceedings of Machine Learning Research, Vol. 202). PMLR, 19274–19286
2023
-
[32]
Yuanchun Li, Hao Wen, Weijun Wang, Xiangyu Li, Yizhen Yuan, Guo- hong Liu, Jiacheng Liu, Wenxing Xu, Xiang Wang, Yi Sun, Rui Kong, Yile Wang, Hanfei Geng, Jian Luan, Xuefeng Jin, Zilong Ye, Guanjing Xiong, Fan Zhang, Xiang Li, Mengwei Xu, Zhijun Li, Peng Li, Yang Liu, Ya-Qin Zhang, and Yunxin Liu. 2024. Personal LLM Agents: Insights and Survey about the C...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Chengdong Lin, Kun Wang, Zhenjiang Li, and Yu Pu. 2023. A Workload- Aware DVFS Robust to Concurrent Tasks for Mobile Devices. InAn- nual International Conference on Mobile Computing and Networking (MobiCom). Article 19, 16 pages
2023
- [34]
-
[35]
Meta Llama Team. 2024. The Llama 3 Herd of Models. arXiv:2407.21783 [cs.AI]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Macken, M
P. Macken, M. Degrauwe, M. Van Paemel, and H. Oguey. 1990. A voltage reduction technique for digital systems. InIEEE International Conference on Solid-State Circuits. 238–239. 13
1990
- [37]
-
[38]
2023-2025.MLC-LLM
MLC team. 2023-2025.MLC-LLM
2023
-
[39]
Dipayan Mukherjee, Sam Hachem, Jeremy Bao, Curtis Madsen, Tian Ma, Saugata Ghose, and Gul Agha. 2025. CRAVE: Analyzing Cross- Resource Interaction to Improve Energy Efficiency in Systems-on- Chip. InProceedings of the Twentieth European Conference on Computer Systems (EuroSys ’25). 59–75
2025
-
[40]
Yang Ni, Yeseong Kim, Tajana Rosing, and Mohsen Imani. 2022. Online performance and power prediction for edge TPU via comprehensive characterization. In2022 Design, Automation & Test in Europe Confer- ence & Exhibition (DATE). IEEE, 612–615
2022
-
[41]
Harbin Institute of Technology and iFLYTEK Joint Laboratory (HFL)
-
[42]
https://huggingface.co/hfl/chinese-llama-2-1.3b
Chinese-LLaMA-2-1.3B: A Chinese-Enhanced LLaMA-2 Model. https://huggingface.co/hfl/chinese-llama-2-1.3b. Accessed 19 Aug 2025
2025
-
[43]
Ollama. 2025. Ollama: Chat & build with open models.https://ollama .com/. Accessed 15 May 2025
2025
-
[44]
OPPO. 2024. OPPO Find X8 Series to Debut MediaTek Dimensity 9400 SOC for Global Markets Combining Ultra Performance, Efficiency & AI Experiences. Accessed 25 Apr 2025
2024
-
[45]
Eva Ostertagová. 2012. Modelling using Polynomial Regression.Pro- cedia Engineering48 (2012), 500–506. Modelling of Mechanical and Mechatronics Systems
2012
-
[46]
Charlie Hu, Ming Zhang, Paramvir Bahl, and Yi- Min Wang
Abhinav Pathak, Y. Charlie Hu, Ming Zhang, Paramvir Bahl, and Yi- Min Wang. 2011. Fine-grained power modeling for smartphones using system call tracing. InProceedings of the Sixth Conference on Computer Systems(Salzburg, Austria)(EuroSys ’11). Association for Computing Machinery, New York, NY, USA, 153–168
2011
-
[47]
Orange Pi. 2025. Orange Pi 5 Pro.http://www.orangepi.org/. Accessed 25 Apr 2025
2025
-
[48]
Haoran Qiu, Weichao Mao, Archit Patke, Shengkun Cui, Saurabh Jha, Chen Wang, Hubertus Franke, Zbigniew Kalbarczyk, Tamer Başar, and Ravishankar K. Iyer. 2024. Power-aware Deep Learning Model Serving with 𝜇-Serve. In2024 USENIX Annual Technical Conference (USENIX ATC 24). USENIX Association, Santa Clara, CA, 75–93
2024
-
[49]
Kalbarczyk, Tamer Başar, and Ravishankar K
Haoran Qiu, Weichao Mao, Archit Patke, Shengkun Cui, Saurabh Jha, Chen Wang, Hubertus Franke, Zbigniew T. Kalbarczyk, Tamer Başar, and Ravishankar K. Iyer. 2024. Efficient Interactive LLM Serving with Proxy Model-based Sequence Length Prediction. InThe 5th Interna- tional Workshop on Cloud Intelligence / AIOps at ASPLOS 2024, Vol. 5. 1–7
2024
-
[50]
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners.OpenAI blog1, 8 (2019), 9
2019
-
[51]
Rafael J. Wysocki. 2017. intel pstate CPU Performance Scaling Driver. https://www.kernel.org/doc/html/latest/admin-guide/pm/intel_pst ate.html. Accessed 15 May 2025
2017
-
[52]
Rockchip. 2025. RKLLM Project.https://github.com/airockchip/rknn- llm. Accessed 25 Apr 2025
2025
-
[53]
Siddharth Samsi, Dan Zhao, Joseph McDonald, Baolin Li, Adam Michaleas, Michael Jones, William Bergeron, Jeremy Kepner, Devesh Tiwari, and Vijay Gadepally. 2023. From Words to Watts: Benchmark- ing the Energy Costs of Large Language Model Inference. In2023 IEEE High Performance Extreme Computing Conference (HPEC). 1–9
2023
-
[54]
Yixin Song, Zeyu Mi, Haotong Xie, and Haibo Chen. 2024. PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU. In ACM SIGOPS 30th Symposium on Operating Systems Principles (SOSP ’24). 590–606
2024
- [55]
-
[56]
Jovan Stojkovic, Chaojie Zhang, Íñigo Goiri, Josep Torrellas, and Esha Choukse. 2025. DynamoLLM: Designing LLM Inference Clusters for Performance and Energy Efficiency. InIEEE International Symposium on High Performance Computer Architecture (HPCA)
2025
-
[57]
Tianxiang Tan and Guohong Cao. 2024. Thermal-aware scheduling for deep learning on mobile devices with NPU.IEEE Transactions on Mobile Computing(2024)
2024
-
[58]
Zhenheng Tang, Yuxin Wang, Qiang Wang, and Xiaowen Chu. 2019. The Impact of GPU DVFS on the Energy and Performance of Deep Learning: an Empirical Study. InProceedings of the Tenth ACM Inter- national Conference on Future Energy Systems. 315–325
2019
-
[59]
Gemma Team. 2024. Gemma 2: Improving Open Language Models at a Practical Size. arXiv:2408.00118 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[60]
The Linux Kernel Community. 2024. Power Management Quality of Service (PM QoS) Interface.https://www.kernel.org/doc/html/latest/p ower/pm_qos_interface.html. Accessed 15 May 2025
2024
-
[61]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Alma- hairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Har...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[62]
Susanne Trauzettel-Klosinski, Klaus Dietz, and IReST Study Group
-
[63]
Standardized assessment of reading performance: The new international reading speed texts IReST.Investigative ophthalmology & visual science53, 9 (2012), 5452–5461
2012
-
[64]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. At- tention is all you need.Advances in neural information processing systems (NeurIPS)30 (2017)
2017
-
[65]
Li Wang. 2021. British English-speaking speed 2020.Acad. J. Humanit. Soc. Sci4 (2021), 93–100
2021
-
[66]
Yunhe Wang, Hanting Chen, Yehui Tang, Tianyu Guo, Kai Han, Ying Nie, Xutao Wang, Hailin Hu, Zheyuan Bai, Yun Wang, Fangcheng Liu, Zhicheng Liu, Jianyuan Guo, Sinan Zeng, Yinchen Zhang, Qinghua Xu, Qun Liu, Jun Yao, Chao Xu, and Dacheng Tao. 2023. PanGu-𝜋: Enhanc- ing Language Model Architectures via Nonlinearity Compensation. arXiv:2312.17276 [cs.CL]
-
[67]
Zibo Wang, Yijia Zhang, Fuchun Wei, Bingqiang Wang, Yanlin Liu, Zhiheng Hu, Jingyi Zhang, Xiaoxin Xu, Jian He, Xiaoliang Wang, Wanchun Dou, Guihai Chen, and Chen Tian. 2025. Using Analytical Performance/Power Model and Fine-Grained DVFS to Enhance AI Accelerator Energy Efficiency. InACM International Conference on Ar- chitectural Support for Programming L...
2025
-
[68]
Rafael J. Wysocki. 2017. CPU Performance Scaling.https://docs.kerne l.org/admin-guide/pm/cpufreq.html. Accessed 25 Apr 2025
2017
-
[69]
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. 2023. SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models. InInternational conference on machine learning (ICML). 38087–38099
2023
-
[70]
Daliang Xu, Hao Zhang, Liming Yang, Ruiqi Liu, Gang Huang, Meng- wei Xu, and Xuanzhe Liu. 2025. Fast On-device LLM Inference with NPUs. InACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS ’25). 445–462. 14
2025
- [71]
-
[72]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guant- ing Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jianxin Yang, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Kem- ing Lu, Keqin Chen, Kexin Yang,...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[73]
Jinliang Yuan, Chen Yang, Dongqi Cai, Shihe Wang, Xin Yuan, Zeling Zhang, Xiang Li, Dingge Zhang, Hanzi Mei, Xianqing Jia, Shangguang Wang, and Mengwei Xu. 2024. Mobile Foundation Model as Firmware. InAnnual International Conference on Mobile Computing and Network- ing (MobiCom). 279–295
2024
-
[74]
Wanghong Yuan and Klara Nahrstedt. 2003. Energy-efficient soft real- time CPU scheduling for mobile multimedia systems. InProceedings of the Nineteenth ACM Symposium on Operating Systems Principles (Bolton Landing, NY, USA)(SOSP ’03). Association for Computing Machinery, New York, NY, USA, 149–163
2003
-
[75]
Sangwoon Yun and Kyungtae Kang. 2023. Runtime WCET Estimation Using Machine Learning. InAnnual International Conference on Mobile Computing and Networking (MobiCom). 1–3
2023
-
[76]
Charlie Hu, Jian Li, and Haibing Guan
Zongpu Zhang, Pranab Dash, Qiang Xu, Y. Charlie Hu, Jian Li, and Haibing Guan. 2026. Rethinking DVFS for Mobile LLMs: Unified Energy-Aware Scheduling with CORE. InMLSys.https://openreview .net/forum?id=PSyHQ8kVUT
2026
-
[77]
Bohua Zou, Binqi Sun, Yigong Hu, Tomasz Kloda, Marco Caccamo, and Tarek Abdelzaher. 2024. A Performance Prediction-based DNN Partitioner for Edge TPU Pipelining. InIEEE Military Communications Conference (MILCOM). 1–6. 15
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.