Prime Fourier Embeddings: A Principled Basis for Modular Arithmetic
Pith reviewed 2026-06-26 09:19 UTC · model grok-4.3
The pith
Prime Fourier Embeddings encode integers so that modular arithmetic reduces to selecting independent prime channels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Prime Fourier Embeddings derived from the harmonic analysis of the rationals induce a representation of the multiplicative group such that any linear map equivariant under the product group action must be block-diagonal with one independent block per prime, a direct consequence of Schur's lemma on the resulting character decomposition; the Chinese Remainder Theorem then predicts the task-relevant blocks for square-free composite moduli.
What carries the argument
The prime-indexed Fourier components that realize a product-group representation, to which Schur's lemma applies and forces block-diagonal equivariant linear maps.
If this is right
- Modular arithmetic on square-free moduli factors into independent computations, one per prime factor.
- The Chinese Remainder Theorem supplies the exact list of active prime channels before any training occurs.
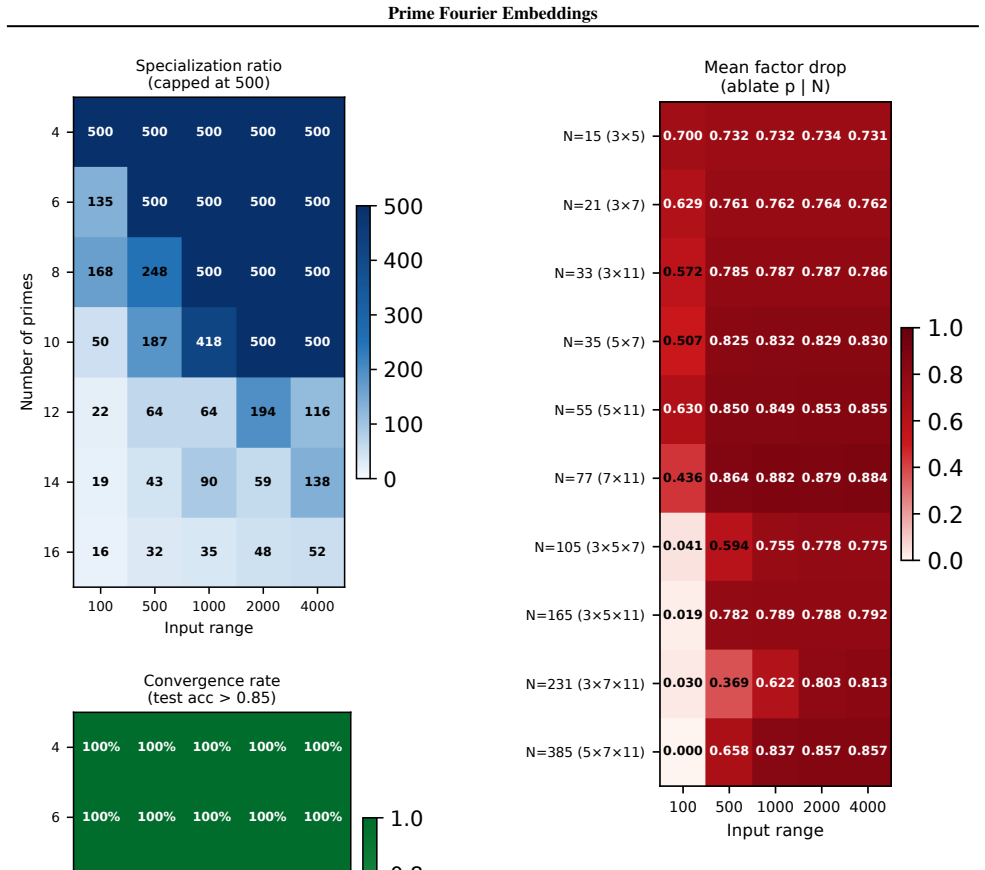
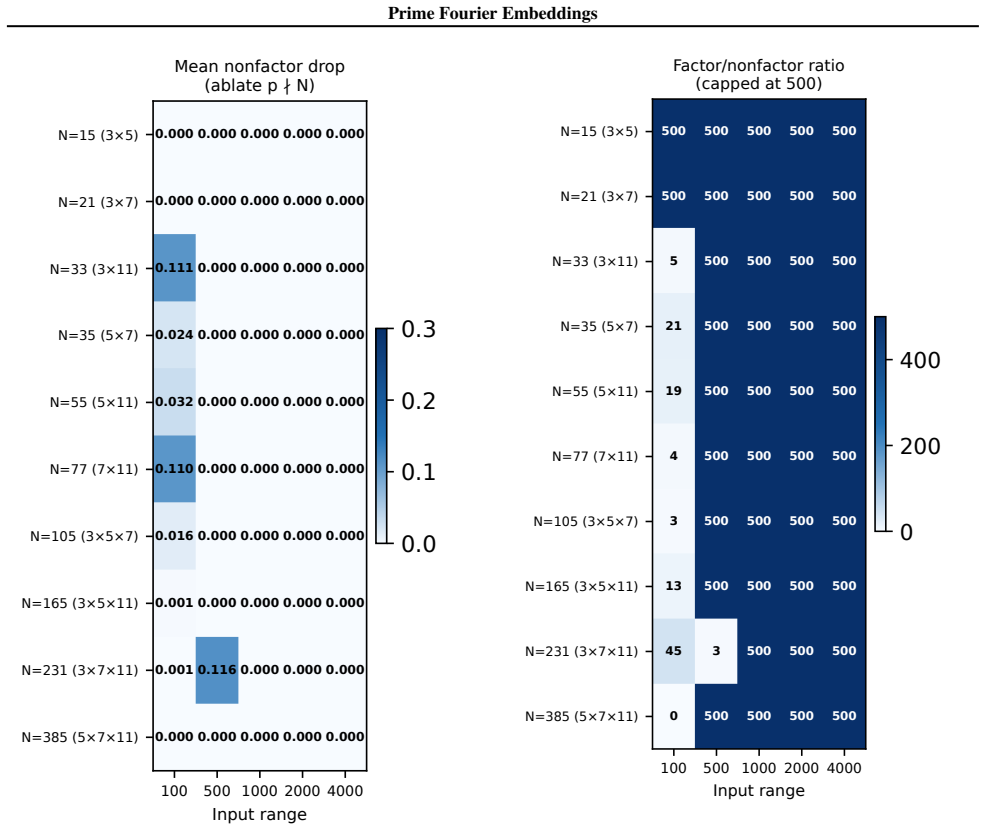
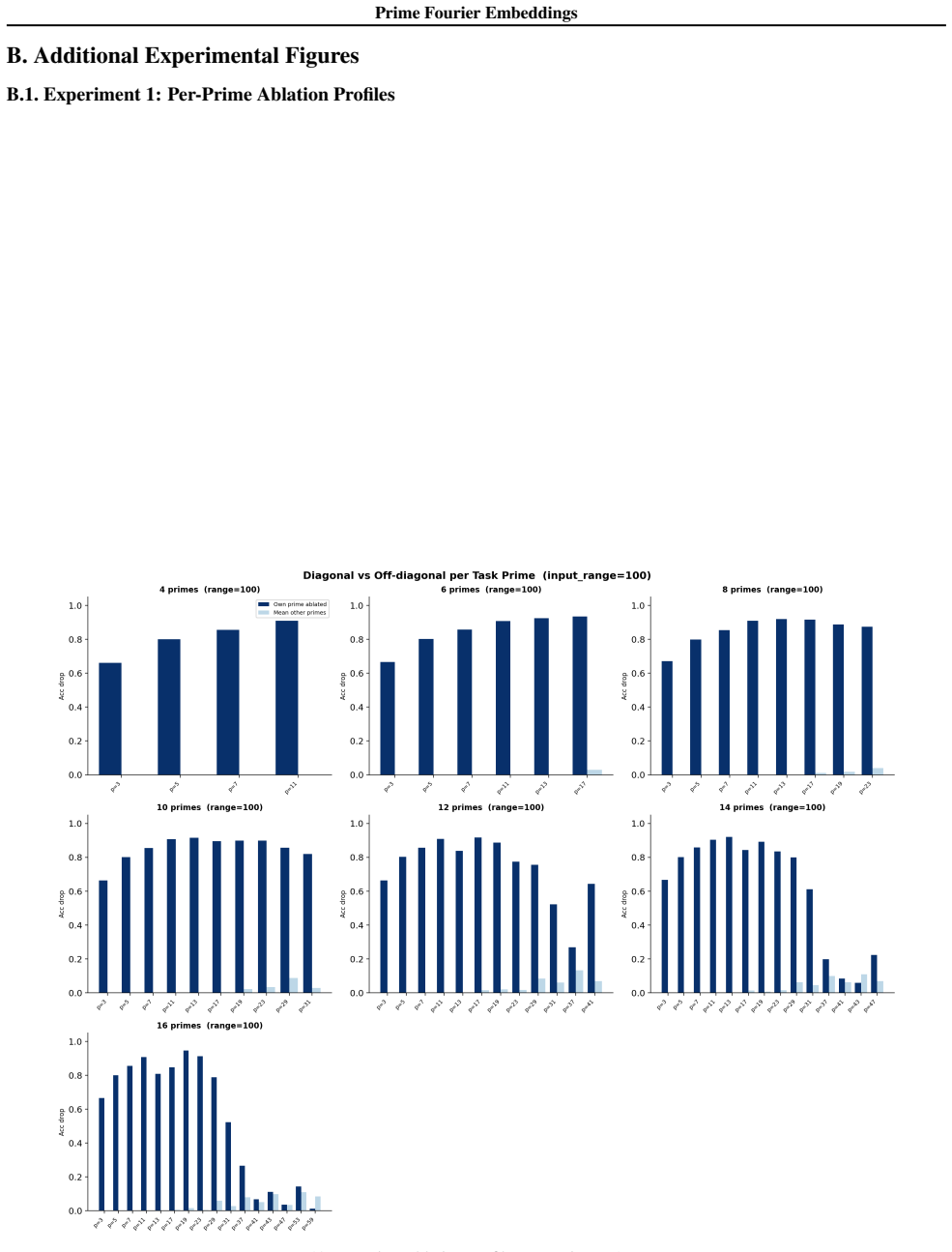
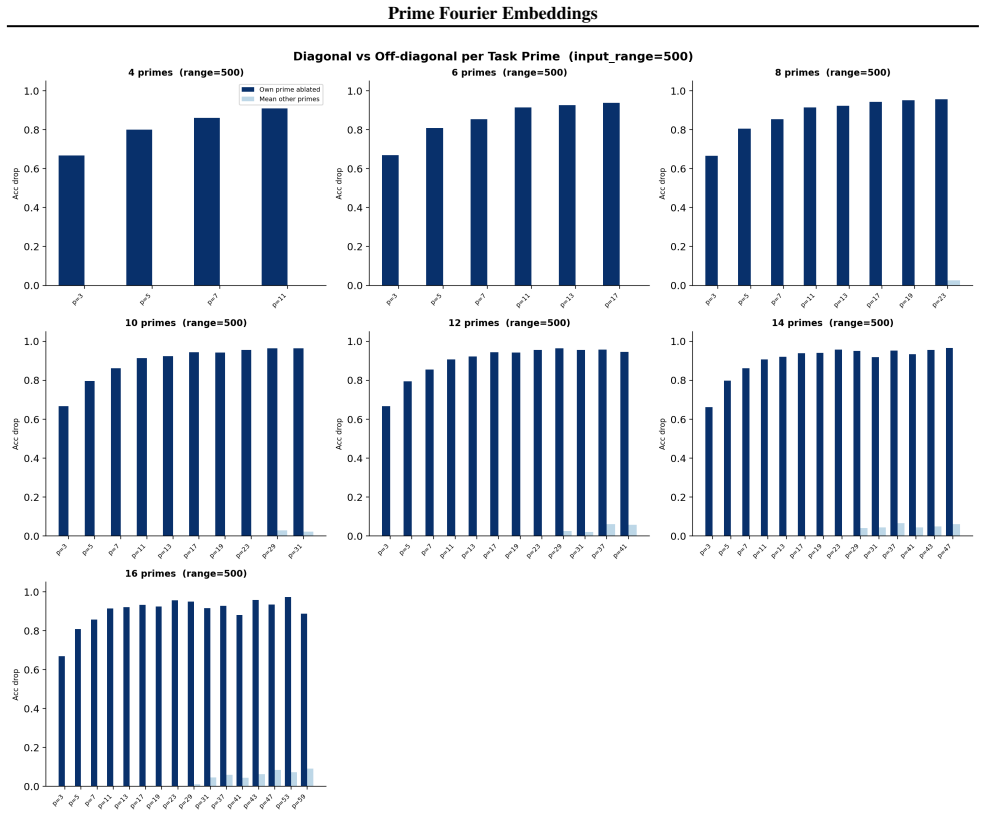
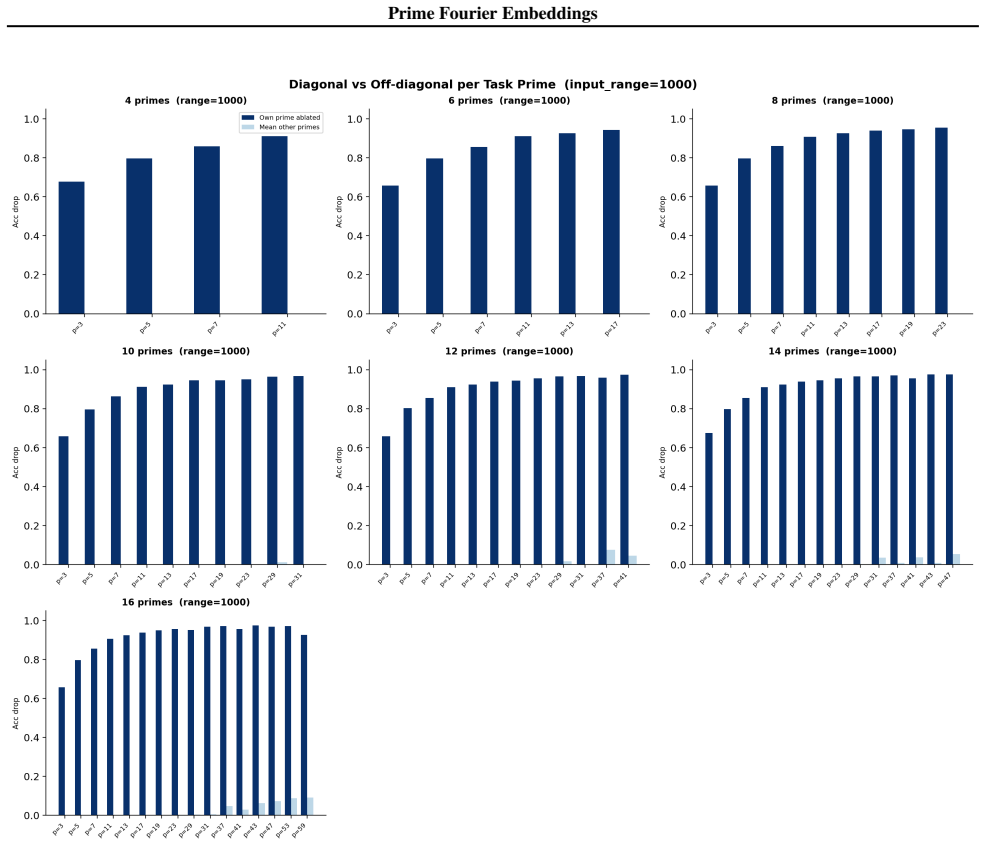
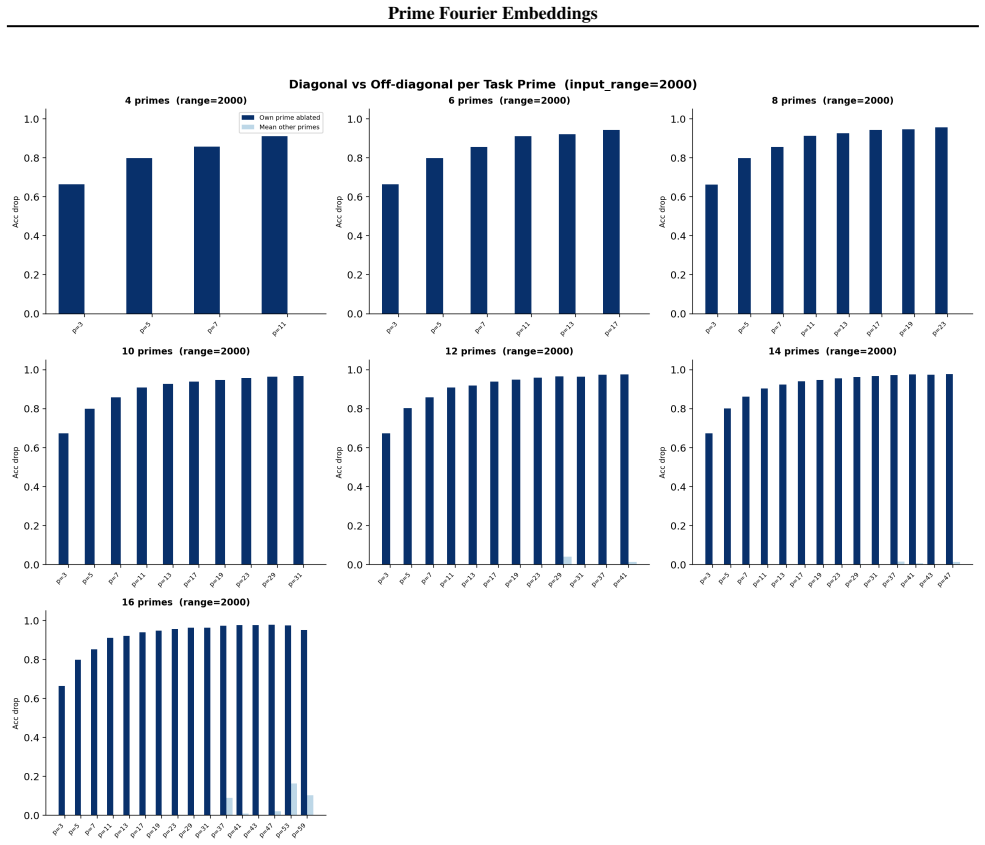
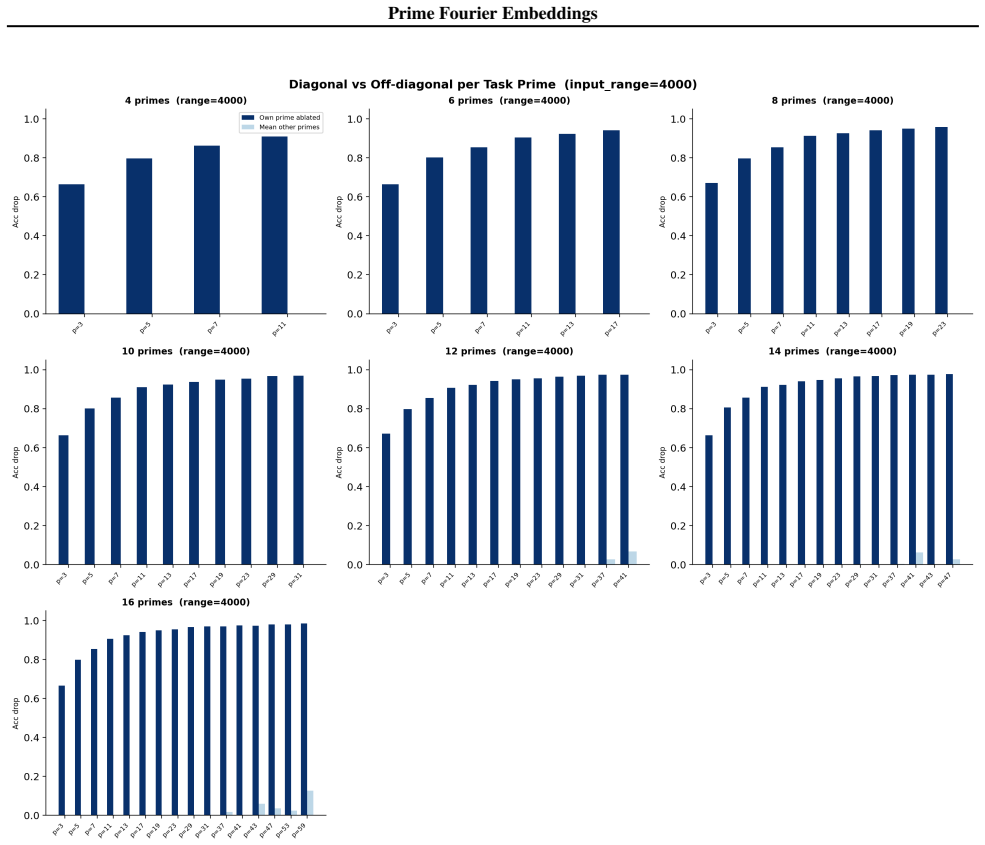
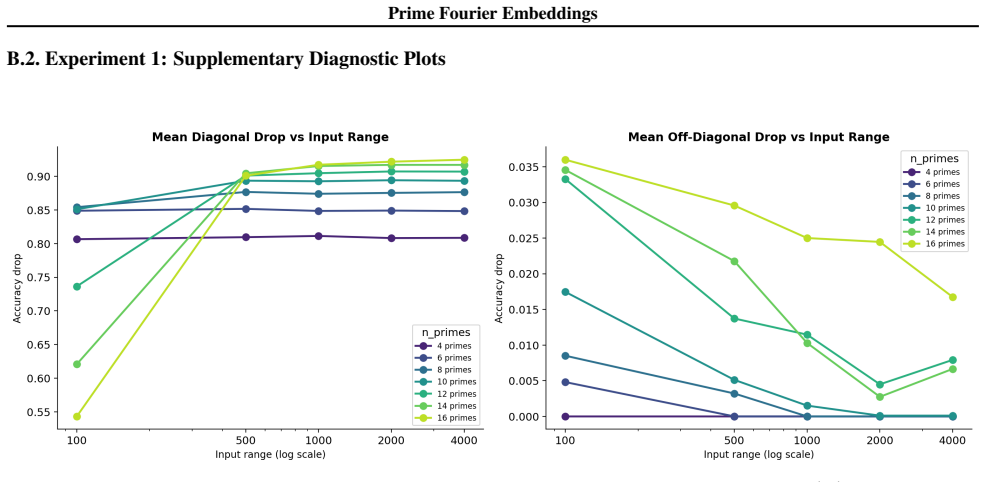
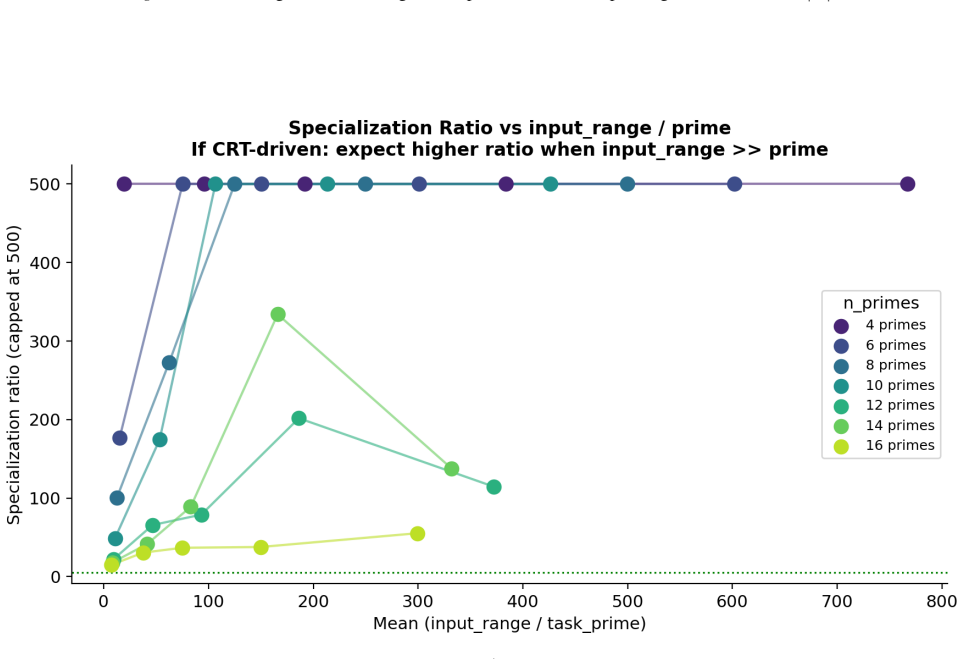
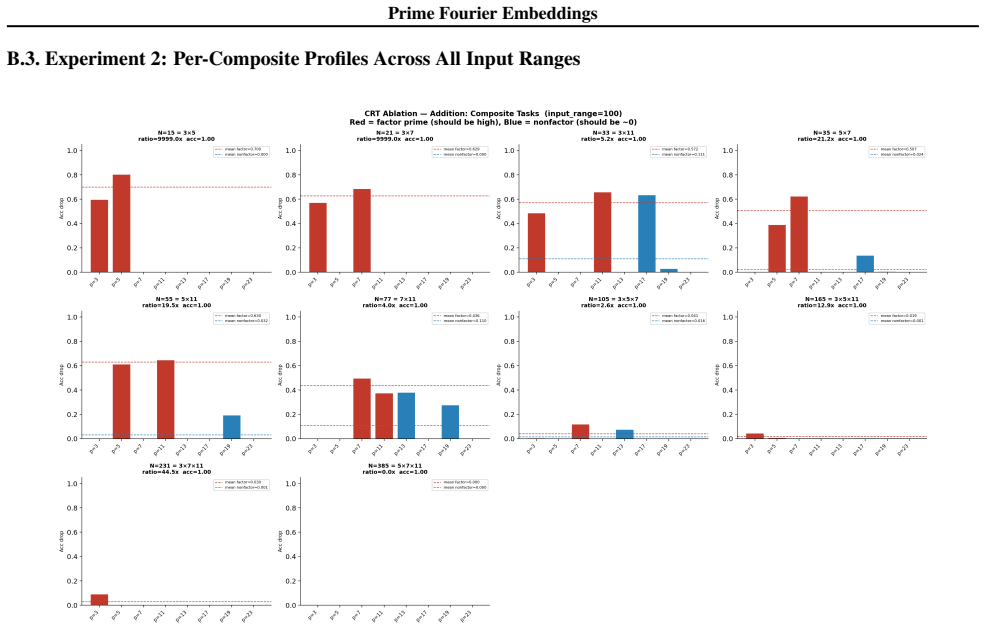
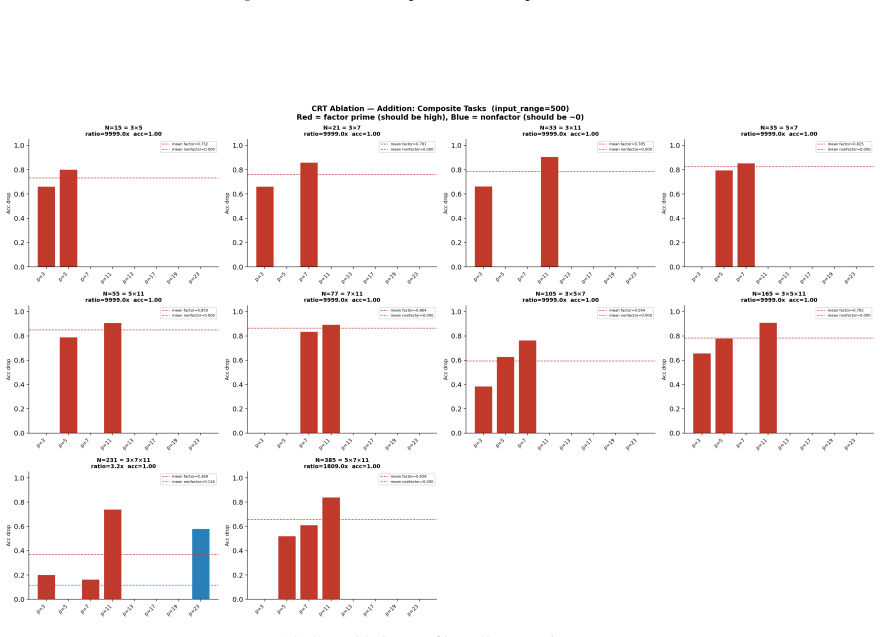
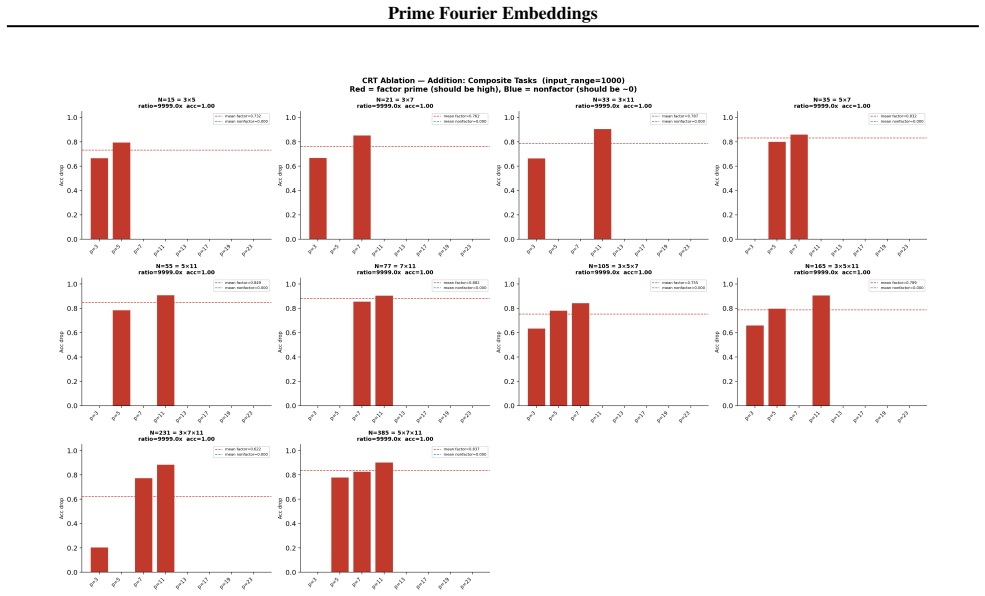
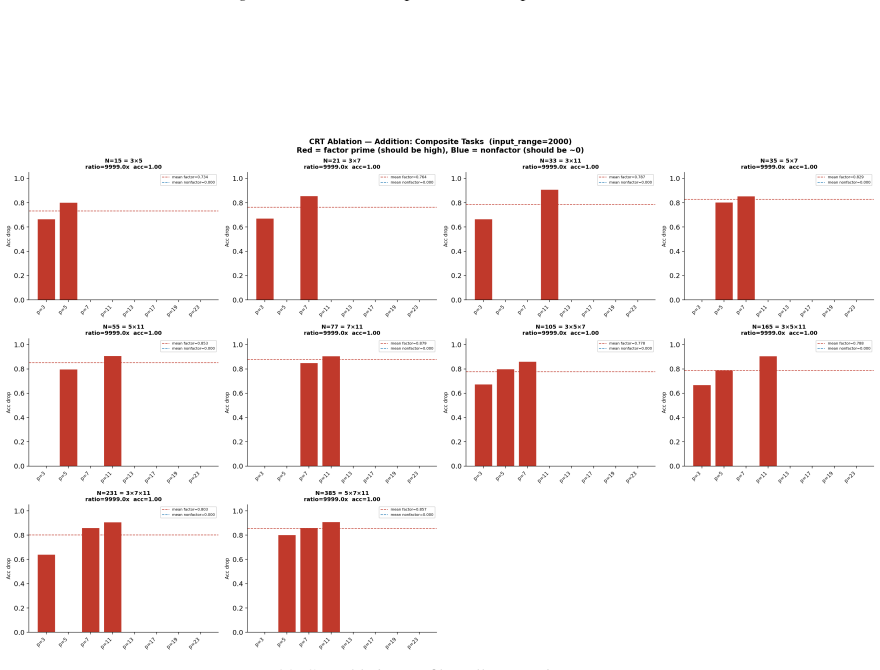
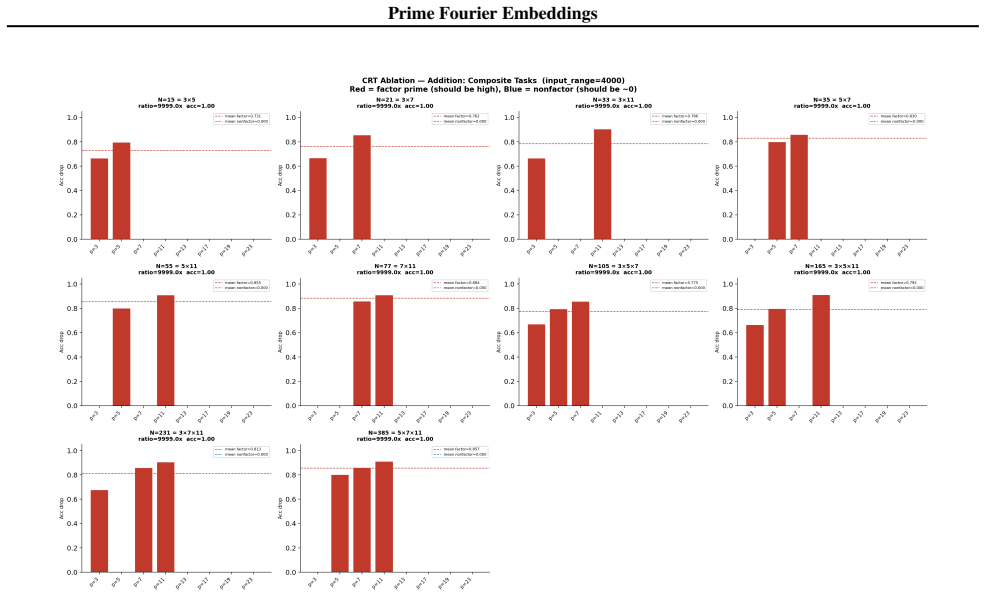
- Ablation studies isolate each prime block, confirming specialization ratios exceeding 500x.
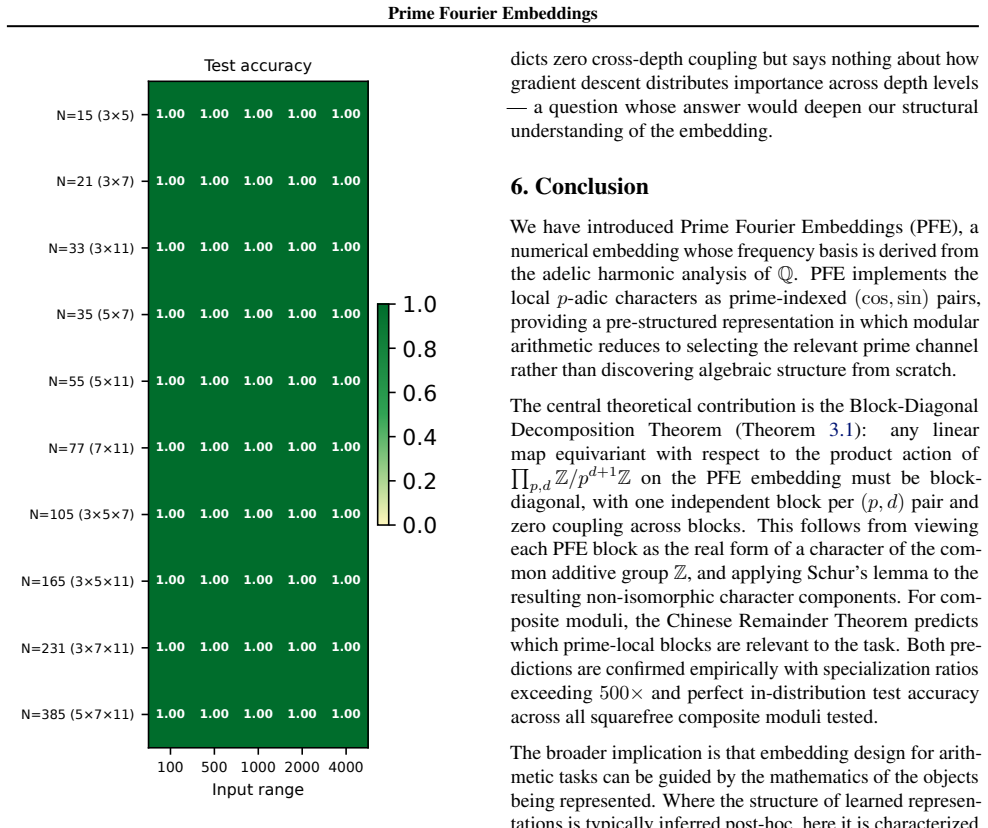
- In-distribution test accuracy reaches 100 percent on all square-free composite moduli examined.
Where Pith is reading between the lines
- The same symmetry-matching strategy could be applied to other arithmetic operations whose groups admit analogous decompositions.
- Pre-structured embeddings aligned with task symmetries may reduce the data needed for models to discover algebraic rules.
- Extension to moduli containing square factors would test whether separate handling of prime-power components is required.
Load-bearing premise
The construction of Prime Fourier Embeddings from the harmonic analysis of the rationals produces a representation whose symmetry group is precisely the product group over primes, so that Schur's lemma applies directly and the Chinese Remainder Theorem isolates the relevant channels.
What would settle it
A concrete linear map that remains equivariant under the product group action on Prime Fourier Embeddings yet mixes information across distinct prime blocks, or an ablation experiment on a square-free composite modulus in which task-irrelevant channels fail to show strong specialization.
Figures
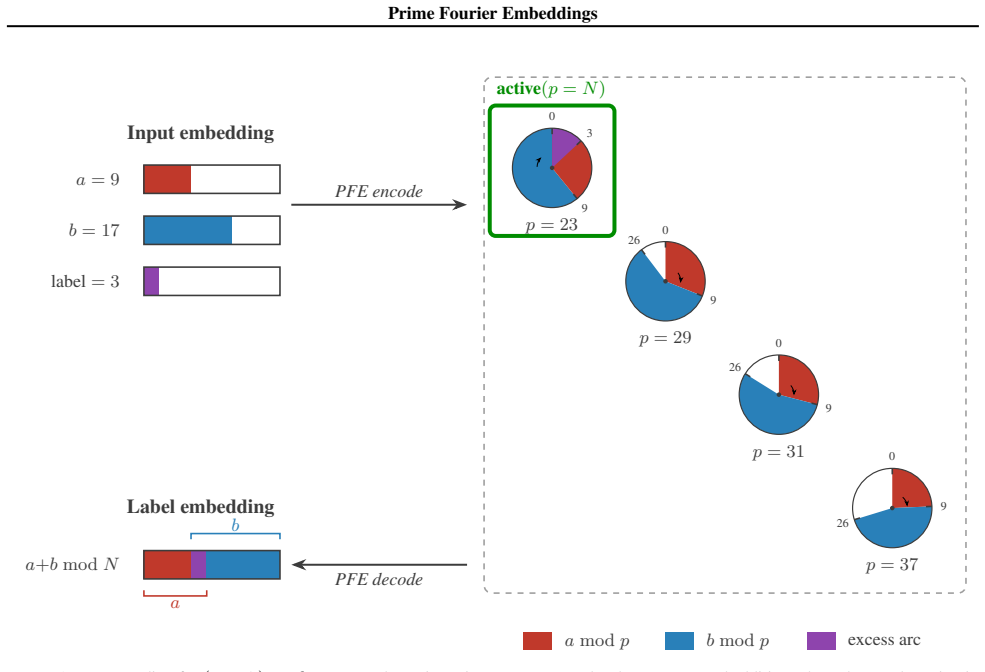
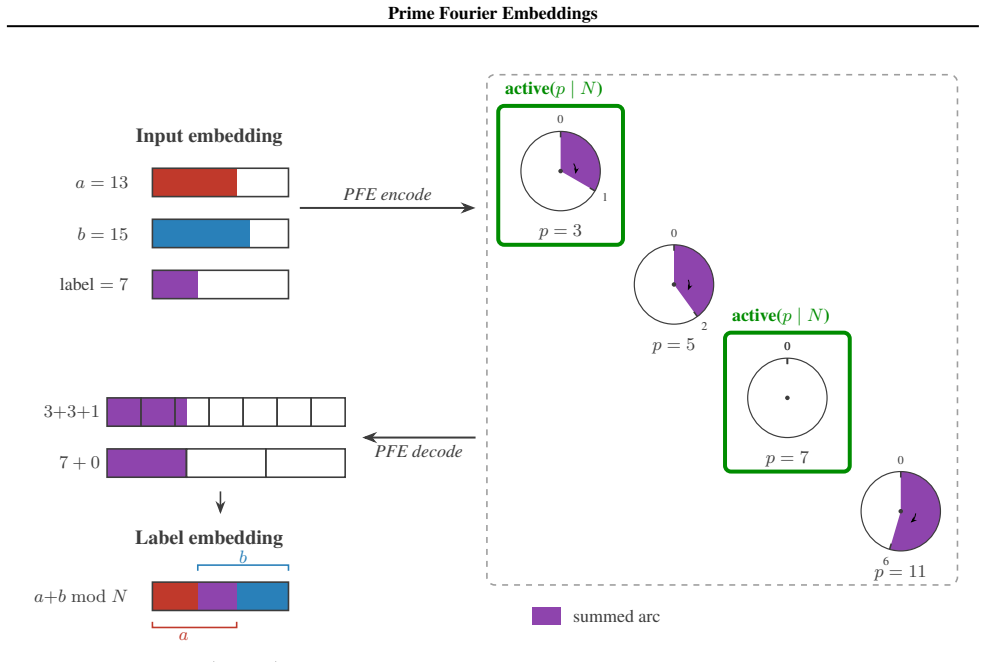
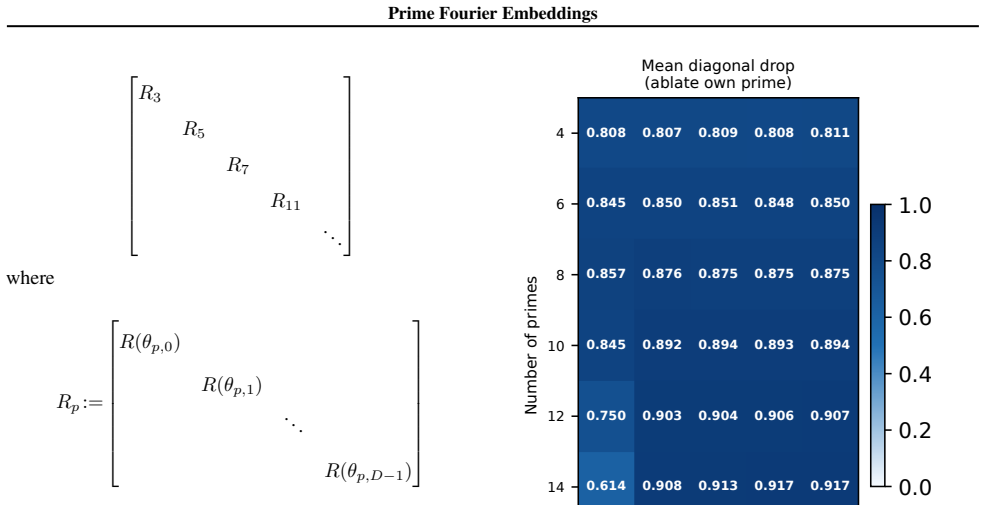
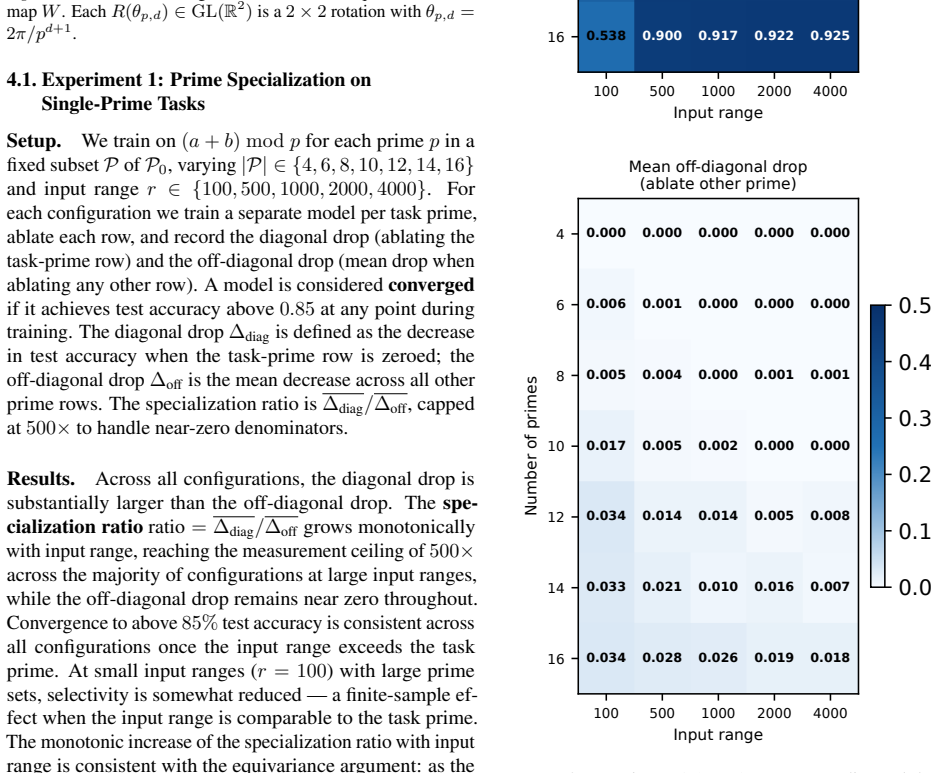

read the original abstract
Numbers have algebraic structure that standard neural embeddings often fail to expose. We introduce Prime Fourier Embeddings (PFE), which encode integers as prime-indexed (cos, sin) pairs derived from the harmonic analysis of Q, providing a pre-structured representation in which modular arithmetic reduces to selecting the relevant prime channel rather than discovering algebraic structure from scratch. We prove that any linear map equivariant with respect to the product group action on PFE must be block-diagonal with one independent block per prime -- a consequence of Schur's lemma applied to the resulting character decomposition. For square-free composite moduli, the Chinese Remainder Theorem predicts which prime channels are task-relevant. Both predictions are confirmed empirically: ablation studies show specialization ratios exceeding 500x between task-relevant and task-irrelevant channels, with perfect in-distribution test accuracy across all square-free composite moduli tested.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Prime Fourier Embeddings (PFE), which encode integers as prime-indexed (cos, sin) pairs derived from the harmonic analysis of Q. It claims to prove, via Schur's lemma applied to the character decomposition under the product group action, that any equivariant linear map on PFE must be block-diagonal with one independent block per prime. For square-free composite moduli, the Chinese Remainder Theorem is said to identify the task-relevant prime channels. Both the block-diagonal structure and the channel predictions are reported as confirmed by ablation studies showing specialization ratios exceeding 500x and perfect in-distribution test accuracy.
Significance. If the representation-theoretic claims hold, the work supplies a pre-structured embedding that reduces modular arithmetic to channel selection rather than structure discovery, with potential implications for equivariant architectures and algebraic reasoning in neural networks. The reported empirical specialization provides a concrete, falsifiable signature of the predicted block structure.
major comments (2)
- [theoretical derivation of equivariant maps] The central proof (theoretical section following the PFE definition): the application of Schur's lemma to conclude block-diagonality per prime requires that the PFE construction induces a representation whose symmetry group is precisely the product group over primes with no shared irreps or cross-prime characters; the manuscript states this follows from the harmonic analysis of Q but does not exhibit the explicit character decomposition or verify absence of entanglement, which is load-bearing for the claim that CRT channel selection follows automatically.
- [ablation studies] Empirical validation (ablation studies section): the reported specialization ratios >500x and perfect accuracy are presented as confirmation of the CRT-derived prediction, yet the text provides neither the precise protocol for labeling task-relevant vs. irrelevant channels, data exclusion rules, nor error bars on the ratios; without these, the experiments cannot be assessed as a direct test of the group-representation premise rather than a post-hoc fit.
minor comments (2)
- [PFE definition] Notation for the product group action and the precise definition of the PFE map (prime-indexed pairs) should be stated with an explicit formula early in the manuscript to allow readers to check the representation property directly.
- [abstract and experiments] The abstract claims 'perfect in-distribution test accuracy across all square-free composite moduli tested' but does not list the specific moduli or model architectures used; adding this table or list would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments. We address each major point below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: The central proof (theoretical section following the PFE definition): the application of Schur's lemma to conclude block-diagonality per prime requires that the PFE construction induces a representation whose symmetry group is precisely the product group over primes with no shared irreps or cross-prime characters; the manuscript states this follows from the harmonic analysis of Q but does not exhibit the explicit character decomposition or verify absence of entanglement, which is load-bearing for the claim that CRT channel selection follows automatically.
Authors: We agree that an explicit character decomposition would make the argument fully self-contained. In the revised manuscript we will add a dedicated subsection deriving the character table of the PFE representation under the product-group action. Using the orthogonality relations from the harmonic analysis on Q, we will show that all irreps remain prime-specific with no cross-prime mixing, thereby confirming that Schur's lemma applies block-wise exactly as claimed. revision: yes
-
Referee: Empirical validation (ablation studies section): the reported specialization ratios >500x and perfect accuracy are presented as confirmation of the CRT-derived prediction, yet the text provides neither the precise protocol for labeling task-relevant vs. irrelevant channels, data exclusion rules, nor error bars on the ratios; without these, the experiments cannot be assessed as a direct test of the group-representation premise rather than a post-hoc fit.
Authors: We accept that the experimental protocol requires additional detail for reproducibility and for a direct test of the theory. The revised ablation section will specify: (i) the exact rule for labeling task-relevant channels via the prime factors given by the CRT for each square-free modulus; (ii) the data-partitioning criteria that exclude non-square-free cases and enforce strict train-test separation; (iii) the computation of specialization ratios together with standard-error bars obtained from five independent random seeds. These additions will allow readers to verify that the reported specialization is a direct consequence of the predicted block structure. revision: yes
Circularity Check
PFE defined via prime-indexed pairs makes product-group decomposition and Schur block-diagonality hold by construction
specific steps
-
self definitional
[Abstract (proof claim)]
"We prove that any linear map equivariant with respect to the product group action on PFE must be block-diagonal with one independent block per prime -- a consequence of Schur's lemma applied to the resulting character decomposition."
PFE is introduced as 'prime-indexed (cos, sin) pairs derived from the harmonic analysis of Q'. Because the embedding is indexed and structured per prime from the outset, the symmetry group is the product group and the irreps are distinct per prime by the definition of the coordinates. Schur's lemma then forces block-diagonality tautologically from that definition rather than as a derived property of the harmonic analysis.
full rationale
The central theoretical claim applies Schur's lemma to conclude that equivariant maps on PFE must be block-diagonal per prime. However, PFE is explicitly constructed as prime-indexed (cos, sin) pairs, so the representation is defined to factor as a product over primes with no cross terms. The character decomposition into distinct per-prime irreps therefore follows directly from the embedding definition rather than from independent harmonic analysis of Q. The CRT channel prediction is standard and non-circular, and the empirical specialization ratios are post-training observations rather than fitted inputs renamed as predictions. This produces moderate circularity confined to the load-bearing representation premise.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Schur's lemma applies to the character decomposition of the PFE representation under the product group action
invented entities (1)
-
Prime Fourier Embeddings (PFE)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Tianyi Zhou and Deqing Fu and Mahdi Soltanolkotabi and Robin Jia and Vatsal Sharan , booktitle=. Fo. 2026 , url=
2026
-
[2]
McLeish, Sean and Bansal, Arpit and Stein, Alex and Jain, Neel and Kirchenbauer, John and Bartoldson, Brian R. and Kailkhura, Bhavya and Bhatele, Abhinav and Geiping, Jonas and Schwarzschild, Avi and Goldstein, Tom , booktitle =. Transformers Can Do Arithmetic with the Right Embeddings , url =. doi:10.52202/079017-3430 , editor =
-
[3]
NeurIPS 2023 AI for Science Workshop , year=
xVal: A Continuous Number Encoding for Large Language Models , author=. NeurIPS 2023 AI for Science Workshop , year=
2023
-
[4]
Language Models Encode the Value of Numbers Linearly
Zhu, Fangwei and Dai, Damai and Sui, Zhifang. Language Models Encode the Value of Numbers Linearly. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[5]
Su, Jianlin and Ahmed, Murtadha and Lu, Yu and Pan, Shengfeng and Bo, Wen and Liu, Yunfeng , title =. 2024 , issue_date =. doi:10.1016/j.neucom.2023.127063 , journal =
-
[6]
Advances in Neural Information Processing Systems , editor=
On Embeddings for Numerical Features in Tabular Deep Learning , author=. Advances in Neural Information Processing Systems , editor=. 2022 , url=
2022
-
[7]
Clifford Neural Layers for
Johannes Brandstetter and Rianne van den Berg and Max Welling and Jayesh K Gupta , booktitle=. Clifford Neural Layers for. 2023 , url=
2023
-
[8]
2022 , eprint=
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets , author=. 2022 , eprint=
2022
-
[9]
RotatE: Knowledge Graph Embedding by Relational Rotation in Complex Space , booktitle =
Zhiqing Sun and Zhi. RotatE: Knowledge Graph Embedding by Relational Rotation in Complex Space , booktitle =. 2019 , url =
2019
-
[10]
Poincar\'
Nickel, Maximillian and Kiela, Douwe , booktitle =. Poincar\'
-
[11]
1977 , series =
Serre, Jean-Pierre , title =. 1977 , series =
1977
-
[12]
1991 , series =
Fulton, William and Harris, Joe , title =. 1991 , series =
1991
-
[13]
1990 , edition =
Ireland, Kenneth and Rosen, Michael , title =. 1990 , edition =
1990
-
[14]
1999 , series =
Terras, Audrey , title =. 1999 , series =
1999
-
[15]
1997 , edition =
Gouv\^. 1997 , edition =
1997
-
[16]
Algebraic Number Theory , publisher =
Neukirch, J\". Algebraic Number Theory , publisher =. 1999 , series =
1999
-
[17]
, title =
Ramakrishnan, Dinakar and Valenza, Robert J. , title =. 1999 , series =
1999
-
[18]
, title =
Folland, Gerald B. , title =. 1995 , series =
1995
-
[19]
2002 , edition =
Lang, Serge , title =. 2002 , edition =
2002
-
[20]
, title =
Hungerford, Thomas W. , title =. 1974 , series =
1974
-
[21]
, title =
Munkres, James R. , title =. 2000 , edition =
2000
-
[22]
2026 , eprint=
There Will Be a Scientific Theory of Deep Learning , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.