PhoneBuddy: Training Open Models for Agentic Phone Use
Pith reviewed 2026-06-26 08:13 UTC · model grok-4.3
The pith
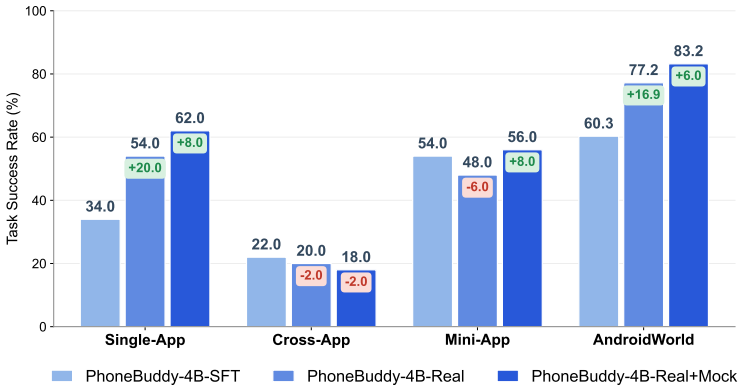
Mixing reinforcement learning on real phone apps with a mock environment raises agent success on real devices from 37% to 45%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
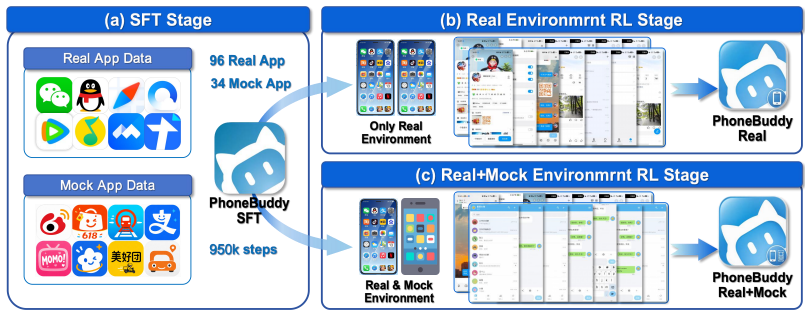
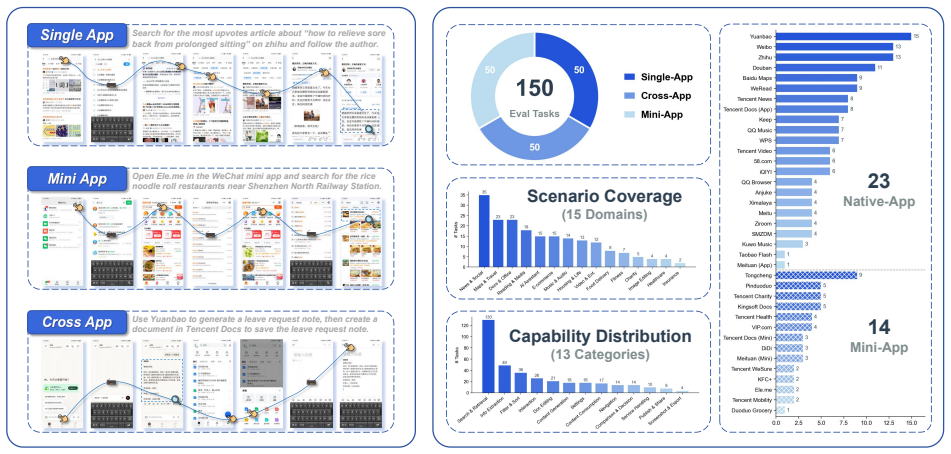
PhoneBuddy first constructs a shared supervised fine-tuning stage from trajectories collected in both real-app and PhoneWorld mock-app environments, then compares real-app RL against mixed RL. On a 150-task human evaluation spanning apps, mini-apps, and cross-app workflows the success rate moves from 36.67% after supervised fine-tuning to 40.67% after real-app RL and 45.33% after mixed RL. The same sequence on AndroidWorld moves from 60.3% to 77.2% to 83.2%. These numbers indicate that mock-app training is a complementary source of scalable, resettable, and automatically checked interaction rather than a substitute for real-app RL.
What carries the argument
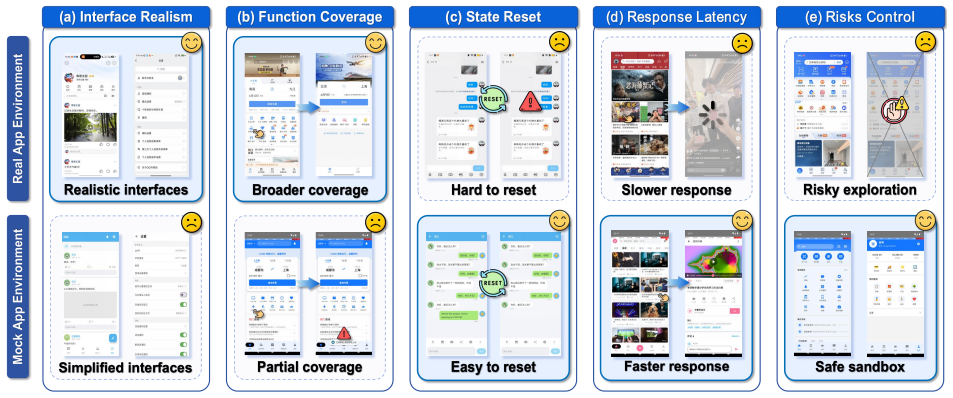
The PhoneWorld mock-app environment that reconstructs runnable mock apps from real GUI usage structure, used together with real-app environments in a mixed RL stage after shared supervised fine-tuning.
If this is right
- Task success on real phones increases by roughly nine percentage points when mock data is added to RL.
- The ordering of methods remains consistent between real-phone evaluation and the AndroidWorld benchmark.
- Improvements concentrate on single-app and mini-app tasks rather than long cross-app sequences.
- Mock environments provide resettable and automatically checked trajectories that can be generated at larger scale than real devices allow.
Where Pith is reading between the lines
- The same mixed-environment recipe could be tested on other stateful interfaces such as desktop operating systems where reset costs are also high.
- Because PhoneWorld supplies automatic verification, early-stage training could rely more heavily on mock rollouts before any real-device evaluation.
- Extending the reconstruction process to a wider set of apps would increase the volume of mixed training data without additional human effort.
Load-bearing premise
The mock apps built in PhoneWorld behave closely enough to real apps that policies trained partly on them transfer effectively to real phones.
What would settle it
Training a model with mixed RL and then measuring its success rate on the same 150 real-phone tasks; if the rate does not exceed the 40.67% achieved by real-app RL alone, the claimed benefit of the mock component disappears.
Figures

read the original abstract
Phones are becoming an important execution surface for general-purpose agents, but training open models for reliable phone use remains difficult because the environment that matters at deployment, real devices running real apps, is slow, stateful, side-effectful, and hard to reset or verify, while scalable mock environments only approximate real behavior. We present PhoneBuddy, a training recipe and open-model line for agentic phone use that combines a real-app environment with a mock-app environment, PhoneWorld, which reconstructs runnable mock apps from real GUI usage structure. PhoneBuddy first builds a shared supervised fine-tuning stage from trajectories collected in both environments, then compares real-app RL against mixed RL across both environments. Across a 150-task human evaluation on real phones spanning apps, mini-apps, and cross-app workflows, task success rate improves from 36.67\% after supervised fine-tuning to 40.67\% after real-app RL and 45.33\% after mixed RL. On AndroidWorld, the same progression rises from 60.3\% to 77.2\% to 83.2\%. These results show that mock-app training is not a replacement for real-app RL, but a complementary source of scalable, resettable, and automatically checked interaction. The gains are strongest on app and mini-app tasks, while long-horizontal cross-app workflows remain an important open challenge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents PhoneBuddy, a training recipe for open models performing agentic tasks on phones. It first performs supervised fine-tuning on trajectories from both real apps and the mock PhoneWorld environment (reconstructed from real GUI usage logs), then compares RL on real apps alone versus mixed RL across both environments. On a 150-task human evaluation on real phones, success rates rise from 36.67% (SFT) to 40.67% (real-app RL) to 45.33% (mixed RL); on AndroidWorld the progression is 60.3% to 77.2% to 83.2%. The central claim is that mock-app training complements rather than replaces real-app RL.
Significance. If the results hold, the work demonstrates a practical path to scaling phone-agent training by leveraging resettable mock environments alongside real devices, which is a meaningful contribution to mobile agent research given the difficulty of real-app resets and verification. The concrete 150-task real-phone evaluation and open-model release are positive features; the paper also provides direct empirical measurements from training runs rather than fitted or self-referential quantities.
major comments (2)
- [PhoneWorld description and results comparison] The attribution of the additional 4.66pp real-phone gain (and 6pp AndroidWorld gain) to complementarity between environments is load-bearing for the abstract's conclusion, yet the PhoneWorld construction section provides no quantitative validation (state-distribution divergence, action-outcome mismatch rate, or failure-mode overlap) that PhoneWorld trajectories produce dynamics close enough to real apps for the observed transfer to be confidently ascribed to mock signal rather than extra training volume or seed variance.
- [Experimental setup and evaluation protocol] The experimental setup section does not report the RL algorithm (e.g., PPO vs. GRPO), number of training runs or random seeds, or any statistical significance tests/confidence intervals on the success-rate deltas, which undermines interpretation of whether the ordering 36.67% < 40.67% < 45.33% is robust.
minor comments (2)
- [Evaluation] The human-evaluation protocol (task selection criteria, inter-rater reliability, and how cross-app workflows were scored) is described only at high level; adding these details would improve reproducibility without altering the central claim.
- [Figures] Figure captions and axis labels could more explicitly indicate whether error bars or multiple runs are shown.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on PhoneBuddy. We address the two major comments point by point below and will revise the manuscript to incorporate additional details and analyses where feasible.
read point-by-point responses
-
Referee: [PhoneWorld description and results comparison] The attribution of the additional 4.66pp real-phone gain (and 6pp AndroidWorld gain) to complementarity between environments is load-bearing for the abstract's conclusion, yet the PhoneWorld construction section provides no quantitative validation (state-distribution divergence, action-outcome mismatch rate, or failure-mode overlap) that PhoneWorld trajectories produce dynamics close enough to real apps for the observed transfer to be confidently ascribed to mock signal rather than extra training volume or seed variance.
Authors: We agree that explicit quantitative validation of PhoneWorld's similarity to real-app dynamics would make the complementarity claim more robust and reduce the possibility that gains stem solely from additional training volume. The environment is reconstructed from real GUI logs, and the consistent ordering of results across independent real-phone and AndroidWorld evaluations provides supporting evidence, but we will add a dedicated subsection with state-distribution divergence, action-outcome mismatch rates, and failure-mode overlap statistics computed from the available logs. revision: yes
-
Referee: [Experimental setup and evaluation protocol] The experimental setup section does not report the RL algorithm (e.g., PPO vs. GRPO), number of training runs or random seeds, or any statistical significance tests/confidence intervals on the success-rate deltas, which undermines interpretation of whether the ordering 36.67% < 40.67% < 45.33% is robust.
Authors: We acknowledge that these experimental details are necessary for reproducibility and for assessing whether the observed ordering is robust. We will revise the experimental setup section to name the RL algorithm, state the number of random seeds used per condition, and report confidence intervals (or other statistical measures) on the success-rate differences. revision: yes
Circularity Check
No circularity: results are direct empirical measurements with no derivations or fitted quantities
full rationale
The paper reports task success rates from supervised fine-tuning, real-app RL, and mixed RL on a 150-task human evaluation and on AndroidWorld. These are measured outcomes from training runs and evaluations, with no equations, parameter fits, predictions, or first-principles derivations that could reduce to inputs by construction. The PhoneWorld mock environment is described as reconstructed from real GUI usage, but its role is as an additional training source whose contribution is assessed via the same external human eval; no self-referential definitions or uniqueness theorems are invoked. The central claims rest on observed ordering of success rates rather than any tautological or self-citation-dependent step.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption GUI usage structure from real apps can be used to reconstruct runnable mock apps that approximate real behavior for training purposes.
invented entities (1)
-
PhoneWorld
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[3]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[4]
2026 , eprint=
PhoneWorld: Scaling Phone-Use Agent Environments , author=. 2026 , eprint=
2026
-
[5]
2026 , eprint=
Do Phone-Use Agents Respect Your Privacy? , author=. 2026 , eprint=
2026
-
[6]
2026 , eprint=
Safe, or Simply Incapable? Rethinking Safety Evaluation for Phone-Use Agents , author=. 2026 , eprint=
2026
-
[7]
2026 , howpublished=
PhoneHarness: A Mixed-Action Orchestration Harness and Benchmark for Phone Agents across CLI, GUI, and MCP Tools , author=. 2026 , howpublished=
2026
-
[8]
arXiv preprint arXiv:2405.14573 , year=
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents , author=. arXiv preprint arXiv:2405.14573 , year=
-
[9]
arXiv preprint arXiv:2307.10088 , year=
Android in the Wild: A Large-Scale Dataset for Android Device Control , author=. arXiv preprint arXiv:2307.10088 , year=
-
[10]
arXiv preprint arXiv:2312.13771 , year=
AppAgent: Multimodal Agents as Smartphone Users , author=. arXiv preprint arXiv:2312.13771 , year=
-
[11]
arXiv preprint arXiv:2401.16158 , year=
Mobile-Agent: Autonomous Multi-Modal Mobile Device Agent with Visual Perception , author=. arXiv preprint arXiv:2401.16158 , year=
-
[12]
arXiv preprint arXiv:2406.01014 , year=
Mobile-Agent-v2: Mobile Device Operation Assistant with Effective Navigation via Multi-Agent Collaboration , author=. arXiv preprint arXiv:2406.01014 , year=
-
[13]
arXiv preprint arXiv:2406.08184 , year=
MobileAgentBench: An Efficient and User-Friendly Benchmark for Mobile LLM Agents , author=. arXiv preprint arXiv:2406.08184 , year=
-
[14]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , pages=
Mobile-Bench: An Evaluation Benchmark for LLM-Based Mobile Agents , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , pages=
-
[15]
arXiv preprint arXiv:2505.11891 , year=
Mobile-Bench-v2: A More Realistic and Comprehensive Benchmark for VLM-Based Mobile Agents , author=. arXiv preprint arXiv:2505.11891 , year=
-
[16]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics , pages=
AndroidLab: Training and Systematic Benchmarking of Android Autonomous Agents , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics , pages=
-
[17]
arXiv preprint arXiv:2512.19432 , year=
MobileWorld: Benchmarking Autonomous Mobile Agents in Agent-User Interactive and MCP-Augmented Environments , author=. arXiv preprint arXiv:2512.19432 , year=
-
[18]
arXiv preprint arXiv:2605.10347 , year=
How Mobile World Model Guides GUI Agents? , author=. arXiv preprint arXiv:2605.10347 , year=
-
[19]
arXiv preprint , year=
A3: Android Agent Arena for Mobile GUI Agents , author=. arXiv preprint , year=
-
[20]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
MobileSteward: Integrating Multiple App-Oriented Agents with Self-Evolution to Automate Cross-App Instructions , author=. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[21]
arXiv preprint arXiv:2404.07972 , year=
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments , author=. arXiv preprint arXiv:2404.07972 , year=
-
[22]
arXiv preprint arXiv:2409.08264 , year=
Windows Agent Arena: Evaluating Multi-Modal OS Agents at Scale , author=. arXiv preprint arXiv:2409.08264 , year=
-
[23]
arXiv preprint arXiv:2506.04135 , year=
macOSWorld: A Multilingual Interactive Benchmark for GUI Agents , author=. arXiv preprint arXiv:2506.04135 , year=
-
[24]
arXiv preprint arXiv:2510.24563 , year=
OSWorld-MCP: Benchmarking MCP Tool Invocation in Computer-Use Agents , author=. arXiv preprint arXiv:2510.24563 , year=
-
[25]
arXiv preprint arXiv:2604.11201 , year=
CocoaBench: Evaluating Unified Digital Agents in the Wild , author=. arXiv preprint arXiv:2604.11201 , year=
-
[26]
arXiv preprint arXiv:2510.25726 , year=
The Tool Decathlon: Benchmarking Language Agents for Diverse, Realistic, and Long-Horizon Task Execution , author=. arXiv preprint arXiv:2510.25726 , year=
-
[27]
arXiv preprint arXiv:2606.05405 , year=
Agents' Last Exam , author=. arXiv preprint arXiv:2606.05405 , year=
-
[28]
arXiv preprint arXiv:2306.06070 , year=
Mind2Web: Towards a Generalist Agent for the Web , author=. arXiv preprint arXiv:2306.06070 , year=
-
[29]
arXiv preprint arXiv:2307.13854 , year=
WebArena: A Realistic Web Environment for Building Autonomous Agents , author=. arXiv preprint arXiv:2307.13854 , year=
-
[30]
arXiv preprint arXiv:2401.13649 , year=
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks , author=. arXiv preprint arXiv:2401.13649 , year=
-
[31]
arXiv preprint arXiv:2207.01206 , year=
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents , author=. arXiv preprint arXiv:2207.01206 , year=
-
[32]
arXiv preprint arXiv:2403.07718 , year=
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks? , author=. arXiv preprint arXiv:2403.07718 , year=
-
[33]
arXiv preprint arXiv:2407.05291 , year=
WorkArena++: Towards Compositional Planning and Reasoning-Based Common Knowledge Work Tasks , author=. arXiv preprint arXiv:2407.05291 , year=
-
[34]
arXiv preprint arXiv:2412.14161 , year=
TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks , author=. arXiv preprint arXiv:2412.14161 , year=
-
[35]
arXiv preprint arXiv:2406.12045 , year=
tau-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains , author=. arXiv preprint arXiv:2406.12045 , year=
-
[36]
arXiv preprint arXiv:2304.08244 , year=
API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs , author=. arXiv preprint arXiv:2304.08244 , year=
-
[37]
arXiv preprint arXiv:2305.15334 , year=
Gorilla: Large Language Model Connected with Massive APIs , author=. arXiv preprint arXiv:2305.15334 , year=
-
[38]
arXiv preprint arXiv:2307.16789 , year=
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-World APIs , author=. arXiv preprint arXiv:2307.16789 , year=
-
[39]
arXiv preprint arXiv:2403.12014 , year=
EnvGen: Generating and Adapting Environments via LLMs for Training Embodied Agents , author=. arXiv preprint arXiv:2403.12014 , year=
-
[40]
arXiv preprint arXiv:2602.14093 , year=
GUI-Genesis: Automated Synthesis of Efficient Environments with Verifiable Rewards for GUI Agent Post-Training , author=. arXiv preprint arXiv:2602.14093 , year=
-
[41]
arXiv preprint arXiv:2604.18292 , year=
Agent-World: Scaling Real-World Environment Synthesis for Evolving General Agent Intelligence , author=. arXiv preprint arXiv:2604.18292 , year=
-
[42]
arXiv preprint arXiv:2601.04126 , year=
InfiniteWeb: Scalable Web Environment Synthesis for GUI Agent Training , author=. arXiv preprint arXiv:2601.04126 , year=
-
[43]
arXiv preprint arXiv:2602.14296 , year=
AutoWebWorld: Synthesizing Infinite Verifiable Web Environments via Finite State Machines , author=. arXiv preprint arXiv:2602.14296 , year=
-
[44]
arXiv preprint arXiv:2604.06126 , year=
Gym-Anything: Turn Any Software into an Agent Environment , author=. arXiv preprint arXiv:2604.06126 , year=
-
[45]
arXiv preprint arXiv:2605.25624 , year=
CUA-Gym: Scaling Verifiable Training Environments and Tasks for Computer-Use Agents , author=. arXiv preprint arXiv:2605.25624 , year=
-
[46]
arXiv preprint arXiv:2605.19769 , year=
OpenComputer: Verifiable Software Worlds for Computer-Use Agents , author=. arXiv preprint arXiv:2605.19769 , year=
-
[47]
arXiv preprint arXiv:2508.14040 , year=
ComputerRL: Scaling End-to-End Online Reinforcement Learning for Computer Use Agents , author=. arXiv preprint arXiv:2508.14040 , year=
-
[48]
arXiv preprint arXiv:2511.13091 , year=
STEP: Success-Rate-Aware Trajectory-Efficient Policy Optimization , author=. arXiv preprint arXiv:2511.13091 , year=
-
[49]
arXiv preprint arXiv:2602.24142 , year=
Come: Empowering channel-of-mobile-experts with informative hybrid-capabilities reasoning , author=. arXiv preprint arXiv:2602.24142 , year=
-
[50]
arXiv preprint arXiv:2606.11042 , year=
Workflow-GYM: Towards Long-Horizon Evaluation of Computer-Use Agentic Tasks in Real-World Professional Fields , author=. arXiv preprint arXiv:2606.11042 , year=
-
[51]
arXiv preprint arXiv:2604.27955 , year=
GUI Agents with Reinforcement Learning: Toward Digital Inhabitants , author=. arXiv preprint arXiv:2604.27955 , year=
-
[52]
arXiv preprint arXiv:2501.12326 , year=
UI-TARS: Pioneering Automated GUI Interaction with Native Agents , author=. arXiv preprint arXiv:2501.12326 , year=
-
[53]
arXiv preprint arXiv:2509.02544 , year=
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning , author=. arXiv preprint arXiv:2509.02544 , year=
-
[54]
arXiv preprint arXiv:2501.11733 , year=
Mobile-Agent-E: Self-Evolving Mobile Assistant for Complex Tasks , author=. arXiv preprint arXiv:2501.11733 , year=
-
[55]
arXiv preprint arXiv:2512.22047 , year=
MAI-UI Technical Report: Real-World Centric Foundation GUI Agents , author=. arXiv preprint arXiv:2512.22047 , year=
-
[56]
arXiv preprint arXiv:2602.16855 , year=
Mobile-Agent-v3.5: Multi-Platform Fundamental GUI Agents , author=. arXiv preprint arXiv:2602.16855 , year=
-
[57]
Advances in Neural Information Processing Systems , volume=
On the Effects of Data Scale on UI Control Agents , author=. Advances in Neural Information Processing Systems , volume=
-
[58]
arXiv preprint arXiv:2509.18119 , year=
MobileRL: Online Agentic Reinforcement Learning for Mobile GUI Agents , author=. arXiv preprint arXiv:2509.18119 , year=
-
[59]
arXiv preprint arXiv:2507.05720 , year=
MobileGUI-RL: Advancing Mobile GUI Agent through Reinforcement Learning in Online Environment , author=. arXiv preprint arXiv:2507.05720 , year=
-
[60]
arXiv preprint arXiv:2505.12299 , year=
MobileIPL: Enhancing Mobile Agents Thinking Process via Iterative Preference Learning , author=. arXiv preprint arXiv:2505.12299 , year=
-
[61]
arXiv preprint arXiv:2504.10458 , year=
GUI-R1: A Generalist R1-Style Vision-Language Action Model for GUI Agents , author=. arXiv preprint arXiv:2504.10458 , year=
-
[62]
arXiv preprint arXiv:2601.06328 , year=
ToolGym: An Open-World Tool-Using Environment for Scalable Agent Testing and Data Curation , author=. arXiv preprint arXiv:2601.06328 , year=
-
[63]
arXiv preprint arXiv:2510.19488 , year=
VideoAgentTrek: Computer Use Pretraining from Unlabeled Videos , author=. arXiv preprint arXiv:2510.19488 , year=
-
[64]
arXiv preprint arXiv:2508.09123 , year=
OpenCUA: Open Foundations for Computer-Use Agents , author=. arXiv preprint arXiv:2508.09123 , year=
-
[65]
arXiv preprint arXiv:2603.04601 , year=
Vibe Code Bench: Evaluating AI Models on End-to-End Web Application Development , author=. arXiv preprint arXiv:2603.04601 , year=
-
[66]
arXiv preprint arXiv:2605.03546 , year=
ProgramBench: Can Language Models Rebuild Programs From Scratch? , author=. arXiv preprint arXiv:2605.03546 , year=
-
[67]
arXiv preprint arXiv:2606.03854 , year=
CLI-Anything: Towards Agent-Native Computer Use , author=. arXiv preprint arXiv:2606.03854 , year=
-
[68]
arXiv preprint arXiv:2309.15817 , year=
Identifying the Risks of LM Agents with an LM-Emulated Sandbox , author=. arXiv preprint arXiv:2309.15817 , year=
-
[69]
arXiv preprint arXiv:2406.13352 , year=
AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents , author=. arXiv preprint arXiv:2406.13352 , year=
-
[70]
arXiv preprint arXiv:2412.14470 , year=
Agent-SafetyBench: Evaluating the Safety of LLM Agents , author=. arXiv preprint arXiv:2412.14470 , year=
-
[71]
arXiv preprint arXiv:2503.04957 , year=
SafeArena: Evaluating the Safety of Autonomous Web Agents , author=. arXiv preprint arXiv:2503.04957 , year=
-
[72]
arXiv preprint arXiv:2604.28139 , year=
Claw-Eval-Live: A Live Agent Benchmark for Evolving Real-World Workflows , author=. arXiv preprint arXiv:2604.28139 , year=
-
[73]
arXiv preprint arXiv:2605.10832 , year=
Towards On-Policy Data Evolution for Visual-Native Multimodal Deep Search Agents , author=. arXiv preprint arXiv:2605.10832 , year=
-
[74]
arXiv preprint arXiv:2410.23218 , year=
OS-Atlas: A Foundation Action Model for Generalist GUI Agents , author=. arXiv preprint arXiv:2410.23218 , year=
-
[75]
arXiv preprint arXiv:2508.10833 , year=
UI-Venus Technical Report: Building High-performance UI Agents with RFT , author=. arXiv preprint arXiv:2508.10833 , year=
-
[76]
arXiv preprint arXiv:2508.15144 , year=
Mobile-Agent-v3: Foundamental Agents for GUI Automation , author=. arXiv preprint arXiv:2508.15144 , year=
-
[77]
arXiv preprint arXiv:2512.15431 , year=
Step-GUI Technical Report , author=. arXiv preprint arXiv:2512.15431 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.