DART: Draft-Agreement Routing for Training-Free Adaptive Thinking Budgets in Hybrid Reasoning Models
Pith reviewed 2026-06-26 08:33 UTC · model grok-4.3
The pith
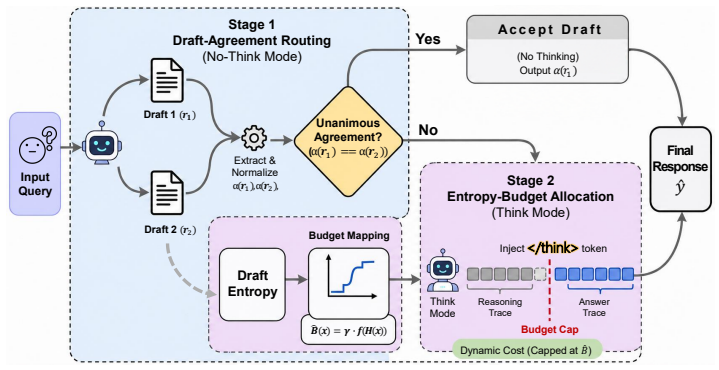
DART samples two no-think drafts and routes to direct answering when they agree, setting adaptive thinking budgets from draft entropy when they disagree.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DART samples two cheap no-think drafts, accepts direct answering when the drafts agree, and predicts a thinking budget from draft entropy when they disagree, thereby adapting the thinking budget per query without any labeled data or gradient updates.
What carries the argument
Agreement between two no-think drafts as the signal for direct answering, with draft entropy used to set the thinking budget on disagreement.
If this is right
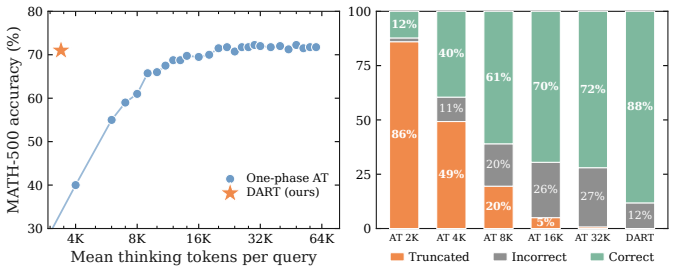
- Accuracy on Olympiad-level math improves up to 9.0 points while thinking tokens fall 15-69 percent.
- Code reasoning accuracy rises up to 22.5 points under execution-based checks while thinking tokens drop 51-63 percent.
- The same Stage-1 agreement signal operates across 0.6B-32B models, multiple families, and API-only hosted models without training.
- Accuracy is preserved or improved relative to always-thinking in most evaluated settings.
Where Pith is reading between the lines
- The draft-agreement signal could be tested on additional domains such as multi-step planning or tool-use tasks.
- Production systems might combine the two-draft check with a small set of follow-up drafts when entropy is borderline to further refine the budget.
- The approach suggests that internal consistency checks inside a single forward pass can substitute for separately trained routers in many hybrid setups.
Load-bearing premise
Agreement between two no-think drafts reliably signals an easy query that can be answered directly without accuracy loss.
What would settle it
A dataset in which queries where the two drafts agree show substantially lower direct-answer accuracy than the always-thinking baseline would falsify the core routing signal.
Figures
read the original abstract
Hybrid reasoning models can answer directly or spend extra tokens on extended thinking. A practical router should choose between these modes for each query, so easy problems avoid unnecessary reasoning and hard problems receive enough budget to finish the answer. Existing routers move in this direction, but they typically require labeled training data or fix thinking budgets up front, ignoring answer-level evidence from the model itself. We introduce DART, a training-free routing framework that samples two cheap no-think drafts, accepts direct answering when the drafts agree, and predicts a thinking budget from draft entropy when they disagree. Across the main comparisons, DART preserves or improves always-thinking accuracy in most settings while reducing thinking-token use. On math reasoning, accuracy improves by up to $+$9.0 points on Olympiad-level problems while thinking tokens drop 15-69%. On code reasoning under execution-based equivalence, accuracy improves by up to +22.5 points while thinking tokens drop 51-63%. The Stage~1 signal extends across model scales (0.6B-32B), model families, and API-only hosted settings, with no labeled data and no gradient updates required.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DART, a training-free routing framework for hybrid reasoning models. It samples two no-think drafts from the model; if the drafts agree, it accepts the direct (no-think) answer; if they disagree, it allocates an adaptive thinking budget derived from the entropy of the drafts. The central empirical claim is that this routing preserves or improves accuracy relative to always-thinking baselines while reducing thinking-token usage, with reported gains of up to +9.0 points on Olympiad-level math and +22.5 points on execution-based code tasks, holding across model scales (0.6B–32B), families, and API-only settings without any labeled data or gradient updates.
Significance. If the routing signal is validated, the result would be significant for practical hybrid reasoning systems: it supplies an adaptive, zero-training method for choosing between direct and extended thinking modes using only model-internal evidence. Credit is due for the fully training-free design, the absence of fitted parameters, the demonstrated applicability to API-only models, and the coverage across scales and task types.
major comments (3)
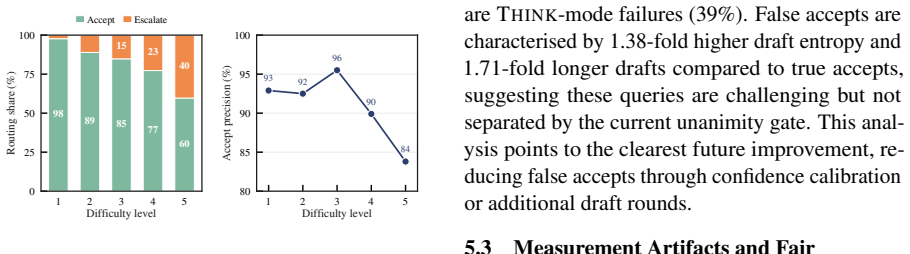
- [Experimental Results] The load-bearing assumption—that draft agreement preferentially occurs on queries where the no-think answer is correct—is not supported by any per-subset accuracy breakdown (agreed vs. disagreed cases). Without this split, the reported accuracy gains (+9.0 math, +22.5 code) cannot be attributed to the routing rule rather than sampling variance or evaluation protocol; this must be added to the main results.
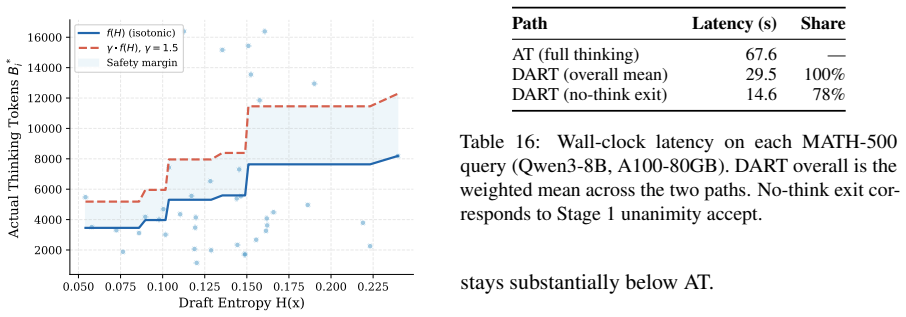
- [Method] The mapping from draft entropy to thinking budget is described only at a high level; no explicit formula, calibration procedure, or justification with error bars or statistical testing is supplied. This leaves the adaptive-budget component of the central claim ungrounded and prevents assessment of robustness.
- [Evaluation Protocol] No information is given on data splits, number of evaluation runs, or statistical significance tests for the token-reduction and accuracy claims. This is required to substantiate the cross-task and cross-scale results.
minor comments (2)
- [Abstract] The term 'Stage 1 signal' appears in the abstract without prior definition; introduce it explicitly in the method section.
- [Notation] Ensure consistent terminology between 'thinking tokens' and 'thinking budget' across text and figures.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will revise the manuscript accordingly to strengthen the empirical support and methodological clarity.
read point-by-point responses
-
Referee: [Experimental Results] The load-bearing assumption—that draft agreement preferentially occurs on queries where the no-think answer is correct—is not supported by any per-subset accuracy breakdown (agreed vs. disagreed cases). Without this split, the reported accuracy gains (+9.0 math, +22.5 code) cannot be attributed to the routing rule rather than sampling variance or evaluation protocol; this must be added to the main results.
Authors: We agree that a per-subset breakdown is necessary to substantiate the routing signal. In the revision we will add a table reporting accuracy on the agreed subset (where the direct answer is used) versus the disagreed subset (where the thinking budget is allocated), together with the corresponding always-thinking and no-thinking baselines. This will allow readers to verify that agreement correlates with correctness of the no-think answer. revision: yes
-
Referee: [Method] The mapping from draft entropy to thinking budget is described only at a high level; no explicit formula, calibration procedure, or justification with error bars or statistical testing is supplied. This leaves the adaptive-budget component of the central claim ungrounded and prevents assessment of robustness.
Authors: We acknowledge the description was high-level. The revised manuscript will include the explicit formula relating draft entropy to the allocated thinking budget, the procedure used to select the budget values, and any accompanying error bars or statistical tests that demonstrate robustness of the mapping. revision: yes
-
Referee: [Evaluation Protocol] No information is given on data splits, number of evaluation runs, or statistical significance tests for the token-reduction and accuracy claims. This is required to substantiate the cross-task and cross-scale results.
Authors: We will expand the experimental section to report the data splits employed, the number of independent evaluation runs, and the statistical significance tests (including p-values where appropriate) supporting the accuracy and token-reduction claims across tasks and model scales. revision: yes
Circularity Check
No circularity: routing rule defined directly from model outputs with no fitted parameters or self-referential reductions.
full rationale
The DART method is introduced as sampling two no-think drafts from the model, accepting the direct answer on agreement, and using draft entropy to set thinking budget on disagreement. This is presented as a direct heuristic operating on raw model generations without any equations, fitted parameters, or derivations that reduce to the inputs by construction. No self-citations are invoked to justify the core routing logic, and performance numbers are reported as empirical observations across scales and tasks rather than as predictions forced by the method's own definitions. The approach is therefore self-contained and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A dapt T hink: Reasoning Models Can Learn When to Think
Zhang, Jiajie and Lin, Nianyi and Hou, Lei and Feng, Ling and Li, Juanzi. A dapt T hink: Reasoning Models Can Learn When to Think. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.184
-
[2]
T hink S witcher: When to Think Hard, When to Think Fast
Liang, Guosheng and Zhong, Longguang and Yang, Ziyi and Quan, Xiaojun. T hink S witcher: When to Think Hard, When to Think Fast. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.278
-
[3]
When to Continue Thinking: Adaptive Thinking Mode Switching for Efficient Reasoning
Zhang, Xiaoyun and Ruan, Jingqing and Ma, Xing and Zhu, Yawen and Zhao, Haodong and Li, Hao and Chen, Jiansong and Zeng, Ke and Cai, Xunliang. When to Continue Thinking: Adaptive Thinking Mode Switching for Efficient Reasoning. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.310
-
[4]
arXiv preprint arXiv:2505.11274 , year=
SelfBudgeter: Adaptive Token Allocation for Efficient LLM Reasoning , author=. arXiv preprint arXiv:2505.11274 , year=. 2505.11274 , archivePrefix=
-
[5]
2025 , eprint=
Hierarchical Budget Policy Optimization for Adaptive Reasoning , author=. 2025 , eprint=
2025
-
[6]
arXiv preprint arXiv:2505.19435 , year=
Route to Reason: Adaptive Routing for LLM and Reasoning Strategy Selection , author=. arXiv preprint arXiv:2505.19435 , year=. 2505.19435 , archivePrefix=
-
[7]
2025 , eprint=
Demystifying Hybrid Thinking: Can LLMs Truly Switch Between Think and No-Think? , author=. 2025 , eprint=
2025
-
[8]
arXiv preprint arXiv:2507.02076 , year=
Reasoning on a Budget: A Survey of Adaptive and Controllable Test-Time Compute in LLMs , author=. arXiv preprint arXiv:2507.02076 , year=. 2507.02076 , archivePrefix=
-
[9]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 Technical Report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[10]
2026 , howpublished=
2026
-
[11]
Transactions on Machine Learning Research , issn=
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models , author=. Transactions on Machine Learning Research , issn=. 2025 , url=
2025
-
[12]
Transactions on Machine Learning Research , issn=
Efficient Reasoning Models: A Survey , author=. Transactions on Machine Learning Research , issn=. 2025 , url=
2025
-
[13]
The Eleventh International Conference on Learning Representations , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[14]
arXiv preprint arXiv:2512.02556 , year=
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models , author=. arXiv preprint arXiv:2512.02556 , year=. 2512.02556 , archivePrefix=
-
[15]
arXiv preprint arXiv:2501.12948 , year=
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. arXiv preprint arXiv:2501.12948 , year=
-
[16]
doi: 10.18653/v1/2024.acl-long.211
He, Chaoqun and Luo, Renjie and Bai, Yuzhuo and Hu, Shengding and Thai, Zhen and Shen, Junhao and Hu, Jinyi and Han, Xu and Huang, Yujie and Zhang, Yuxiang and Liu, Jie and Qi, Lei and Liu, Zhiyuan and Sun, Maosong. O lympiad B ench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems. Proceedings of the ...
-
[17]
The Eleventh International Conference on Learning Representations , year=
Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation , author=. The Eleventh International Conference on Learning Representations , year=
-
[18]
Measuring Mathematical Problem Solving With the
Dan Hendrycks and Collin Burns and Saurav Kadavath and Akul Arora and Steven Basart and Eric Tang and Dawn Song and Jacob Steinhardt , booktitle=. Measuring Mathematical Problem Solving With the. 2021 , url=
2021
-
[19]
The Twelfth International Conference on Learning Representations , year=
Let's Verify Step by Step , author=. The Twelfth International Conference on Learning Representations , year=
-
[20]
Think you have Solved Question Answering? Try
Clark, Peter and Cowhey, Isaac and Etzioni, Oren and Khot, Tushar and Sabharwal, Ashish and Schoenick, Carissa and Tafjord, Oyvind , journal=. Think you have Solved Question Answering? Try
-
[21]
Bowman , booktitle=
David Rein and Betty Li Hou and Asa Cooper Stickland and Jackson Petty and Richard Yuanzhe Pang and Julien Dirani and Julian Michael and Samuel R. Bowman , booktitle=. 2024 , url=
2024
-
[22]
Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =
Wang, Yubo and Ma, Xueguang and Zhang, Ge and Ni, Yuansheng and Chandra, Abhranil and Guo, Shiguang and Ren, Weiming and Arulraj, Aaran and He, Xuan and Jiang, Ziyan and Li, Tianle and Ku, Max and Wang, Kai and Zhuang, Alex and Fan, Rongqi and Yue, Xiang and Chen, Wenhu , title =. Proceedings of the 38th International Conference on Neural Information Proc...
2024
-
[23]
arXiv preprint arXiv:2107.03374 , year=
Evaluating Large Language Models Trained on Code , author=. arXiv preprint arXiv:2107.03374 , year=
-
[24]
arXiv preprint arXiv:2108.07732 , year=
Program Synthesis with Large Language Models , author=. arXiv preprint arXiv:2108.07732 , year=. 2108.07732 , archivePrefix=
-
[25]
Jia, Maxwell , year=
-
[26]
2025 , publisher=
AIME 2025 - Unified Test-Time Scaling Format , author=. 2025 , publisher=
2025
-
[27]
arXiv preprint arXiv:2409.12122 , year=
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement , author=. arXiv preprint arXiv:2409.12122 , year=. 2409.12122 , archivePrefix=
-
[28]
arXiv preprint arXiv:2506.23840 , year=
Do Thinking Tokens Help or Trap? Towards More Efficient Large Reasoning Model , author=. arXiv preprint arXiv:2506.23840 , year=
-
[29]
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph and Zhang, Hao and Stoica, Ion , title =. Proceedings of the 29th Symposium on Operating Systems Principles , pages =. 2023 , isbn =. doi:10.1145/3600006.3613165 , abstract =
-
[30]
Lingjiao Chen and Matei Zaharia and James Zou , journal=. Frugal. 2024 , url=
2024
-
[31]
Gonzalez and M Waleed Kadous and Ion Stoica , booktitle=
Isaac Ong and Amjad Almahairi and Vincent Wu and Wei-Lin Chiang and Tianhao Wu and Joseph E. Gonzalez and M Waleed Kadous and Ion Stoica , booktitle=. Route. 2025 , url=
2025
-
[32]
Charlie Victor Snell and Jaehoon Lee and Kelvin Xu and Aviral Kumar , booktitle=. Scaling. 2025 , url=
2025
-
[33]
ICML 2024 Workshop on In-Context Learning , year=
Universal Self-Consistency for Large Language Models , author=. ICML 2024 Workshop on In-Context Learning , year=
2024
-
[34]
2017 , eprint=
Adaptive Computation Time for Recurrent Neural Networks , author=. 2017 , eprint=
2017
-
[35]
Advances in Neural Information Processing Systems , editor=
Confident Adaptive Language Modeling , author=. Advances in Neural Information Processing Systems , editor=. 2022 , url=
2022
-
[36]
arXiv preprint arXiv:2207.05221 , year=
Language Models (Mostly) Know What They Know , author=. arXiv preprint arXiv:2207.05221 , year=
-
[37]
The Annals of Mathematical Statistics , volume=
An Empirical Distribution Function for Sampling with Incomplete Information , author=. The Annals of Mathematical Statistics , volume=. 1955 , doi=
1955
-
[38]
International Conference on Machine Learning , pages=
Fast inference from transformers via speculative decoding , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[39]
Let ' s Sample Step by Step: Adaptive-Consistency for Efficient Reasoning and Coding with LLM s
Aggarwal, Pranjal and Madaan, Aman and Yang, Yiming and Mausam. Let ' s Sample Step by Step: Adaptive-Consistency for Efficient Reasoning and Coding with LLM s. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.761
-
[40]
2026 , howpublished=
Introducing. 2026 , howpublished=
2026
-
[41]
2026 , howpublished=
Building with Extended Thinking , author=. 2026 , howpublished=
2026
-
[42]
2025 , eprint=
MiniCPM-V 4.5: Cooking Efficient MLLMs via Architecture, Data, and Training Recipe , author=. 2025 , eprint=
2025
-
[43]
2026 , eprint=
Nemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.