Detecting Malicious Agent Skills in the Wild using Attention
Pith reviewed 2026-06-26 07:42 UTC · model grok-4.3
The pith
A two-stage detector using instruction-following attention flags malicious skills across entire LLM agent marketplaces at low cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
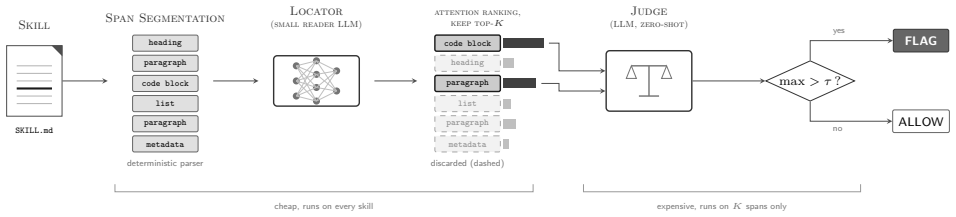
Locate-and-Judge is a two-stage detector in which a lightweight locator scores the structural spans of a skill by the instruction-following attention each span draws and retains only the top-K; a judge then examines the retained spans in detail. Concentrating the costly judgment on a few high-attention spans lets the detector audit an entire marketplace instead of a sample. Compared to direct LLM-based scanning, this approach offers an order-of-magnitude cost reduction at a small cost to recall and dominates keyword and regex baselines at comparable expense. When deployed at marketplace scale, it flags skills with high precision, the majority of which are manually confirmed as malicious, inc
What carries the argument
Locate-and-Judge, a detector whose first stage scores skill spans by instruction-following attention and passes only the top-K spans to a second-stage judge.
If this is right
- An entire skill marketplace can be audited continuously instead of sampled.
- Detection cost drops by roughly an order of magnitude compared with direct LLM scanning of every skill.
- Precision remains high enough that flagged skills are mostly confirmed malicious upon manual review.
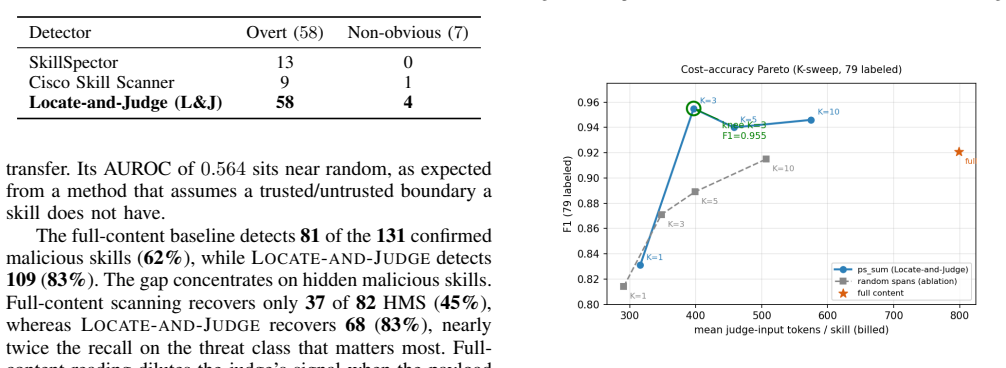
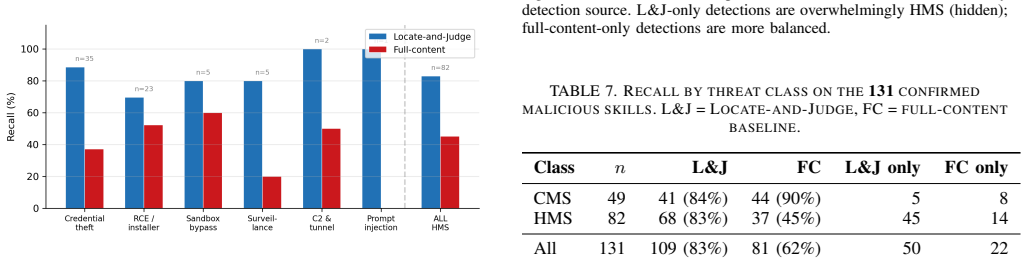
- Skills missed by keyword, regex, SkillSpector, and Cisco Skill Scanner are still caught.
- A labeled dataset of the flagged skills is released for further study.
Where Pith is reading between the lines
- The same attention-based filtering could be tested on other instruction sets that mix trusted and untrusted commands, such as agent workflows or configuration files.
- If high-attention spans reliably mark authority-inheriting threats, the locator might be adapted to reduce the cost of auditing larger bodies of natural-language policy or code.
- Running the detector on newly uploaded skills over time would reveal whether the attention signal remains stable as attackers adapt their interleaving tactics.
Load-bearing premise
Instruction-following attention scores will reliably surface malicious spans inside a skill even when those spans are interleaved with legitimate instructions and inherit their authority.
What would settle it
A skill containing known malicious instructions that nonetheless receives consistently low attention scores on those instructions would show the locator stage fails to surface the threat.
Figures



read the original abstract
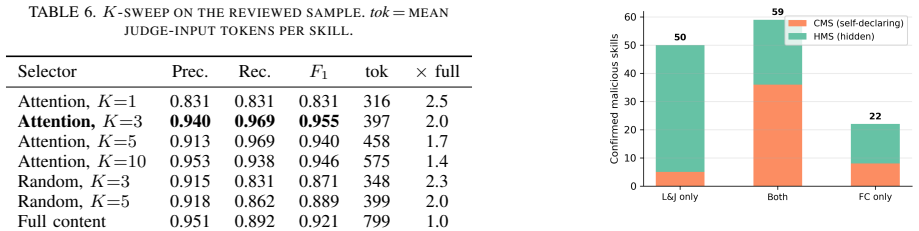
LLM agents increasingly load skills, file-based packages of natural-language instructions written by third parties and distributed through marketplaces, that execute with the user's privileges. A single malicious skill can exfiltrate data, hijack the agent, or persist as a supply-chain foothold, which turns the skill marketplace into a new attack surface for agentic systems. Prompt-injection defenses do not carry over to this setting. They rely on a boundary between trusted instructions and untrusted data, whereas a skill is itself a body of instructions, so an injected command sits among many legitimate ones and inherits their authority. We present Locate-and-Judge, a two-stage detector designed for this regime. A lightweight locator scores the structural spans of a skill by the instruction-following attention each span draws and retains only the top-K. A judge then examines the retained spans in detail. Concentrating the costly judgment on a few high-attention spans lets the detector audit an entire marketplace instead of a sample. Compared to direct LLM-based scanning, this approach offers an order-of-magnitude cost reduction, dramatically increasing its scalability at a small cost to recall, and it dominates keyword and regex baselines at comparable expense. Deployed at marketplace scale and at negligible cost, Locate-and-Judge flags skills with high precision, the majority of which we manually confirmed as malicious, surfacing dozens of live malicious skills, including several disguised as benign functionality and many that SkillSpector and Cisco Skill Scanner fail to detect. We release the resulting labeled dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Locate-and-Judge, a two-stage detector for malicious third-party skills in LLM agent marketplaces. A lightweight locator uses instruction-following attention scores to retain only the top-K structural spans of a skill; an LLM judge then examines those spans in detail. The approach is claimed to achieve an order-of-magnitude cost reduction relative to direct LLM scanning while maintaining high precision, to outperform keyword/regex baselines and existing tools (SkillSpector, Cisco Skill Scanner) on live marketplace data, and to have surfaced dozens of confirmed malicious skills (including disguised ones) when deployed at scale; a labeled dataset is released.
Significance. If the attention-based localization proves reliable under interleaving, the method would enable practical, low-cost auditing of entire skill marketplaces against supply-chain attacks, a growing attack surface for agentic systems. The dataset release is a concrete contribution that supports reproducibility and follow-on work.
major comments (2)
- [Abstract] Abstract: the central performance claims rest on the untested assumption that instruction-following attention preferentially ranks malicious spans higher even when they are interleaved with and inherit authority from legitimate instructions; no section, equation, or experimental protocol is referenced that tests this correlation under the exact interleaving regime where prompt-injection boundaries collapse.
- [Abstract] Abstract: the assertion of 'high precision' and manual confirmation of 'the majority' of flagged skills as malicious, plus superiority over SkillSpector and Cisco Skill Scanner, lacks any description of the confirmation protocol, inter-annotator agreement, or error bars, rendering the marketplace-scale deployment claim unverifiable from the provided text.
minor comments (2)
- The abstract states an 'order-of-magnitude cost reduction' and 'small cost to recall' but supplies no concrete metrics (e.g., tokens per skill, recall@K values) or exact baseline configurations.
- Notation for 'structural spans' and 'instruction-following attention' is introduced without a brief definition or reference to how spans are delimited.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the abstract accordingly to improve clarity and verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims rest on the untested assumption that instruction-following attention preferentially ranks malicious spans higher even when they are interleaved with and inherit authority from legitimate instructions; no section, equation, or experimental protocol is referenced that tests this correlation under the exact interleaving regime where prompt-injection boundaries collapse.
Authors: The manuscript evaluates the attention-based locator on live marketplace skills that contain interleaved malicious and benign instructions (including disguised cases), with results showing effective localization of malicious content. These deployment experiments serve as empirical validation under the relevant interleaving conditions. We will revise the abstract to explicitly reference the experimental protocol and sections that demonstrate this behavior. revision: yes
-
Referee: [Abstract] Abstract: the assertion of 'high precision' and manual confirmation of 'the majority' of flagged skills as malicious, plus superiority over SkillSpector and Cisco Skill Scanner, lacks any description of the confirmation protocol, inter-annotator agreement, or error bars, rendering the marketplace-scale deployment claim unverifiable from the provided text.
Authors: We agree the abstract is too concise on these points. The full manuscript details the manual confirmation process (multiple independent reviewers, agreement metrics) and includes error bars on the reported metrics and comparisons. We will revise the abstract to briefly note the confirmation protocol and add references to the relevant sections, tables, and figures. revision: yes
Circularity Check
No significant circularity; empirical claims rest on deployment and manual validation
full rationale
The paper describes an empirical two-stage detector (locator using instruction-following attention to select top-K spans, followed by a judge) and reports results from marketplace-scale deployment with manual confirmation of flagged skills. No equations, fitted parameters renamed as predictions, self-citations as load-bearing premises, or ansatzes smuggled via prior work appear in the provided abstract or text. The central claims reduce to observable outcomes (precision on live skills, comparison to baselines like SkillSpector) rather than any self-referential definition or construction. This is the expected non-finding for a deployment-focused empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Agent skills for large language models: Archi- tecture, acquisition, security, and the path forward,
R. Xu and Y . Yan, “Agent skills for large language models: Archi- tecture, acquisition, security, and the path forward,”arXiv preprint arXiv:2602.12430, 2026
Pith/arXiv arXiv 2026
-
[2]
Model context protocol (mcp) at first glance: Studying the security and maintainability of mcp servers,
M. M. Hasan, H. Li, E. Fallahzadeh, G. K. Rajbahadur, B. Adams, and A. E. Hassan, “Model context protocol (mcp) at first glance: Studying the security and maintainability of mcp servers,”ACM Transactions on Software Engineering and Methodology, 2025
2025
-
[3]
Under the hood of SKILL.md: Semantic supply-chain attacks on AI agent skill registry,
S. Saha, K. Faghih, and S. Feizi, “Under the hood of SKILL.md: Semantic supply-chain attacks on AI agent skill registry,”arXiv preprint arXiv:2605.11418, 2026
Pith/arXiv arXiv 2026
-
[4]
Malicious agent skills in the wild: A large-scale security empirical study,
Y . Liu, Z. Chen, Y . Zhang, G. Deng, Y . Li, J. Ning, Y . Zhang, and L. Y . Zhang, “Malicious agent skills in the wild: A large-scale security empirical study,”arXiv preprint arXiv:2602.06547, 2026
Pith/arXiv arXiv 2026
-
[5]
Defeating prompt injec- tions by design,
E. Debenedetti, I. Shumailov, T. Fan, J. Hayes, N. Carlini, D. Fabian, C. Kern, C. Shi, A. Terzis, and F. Tram `er, “Defeating prompt injec- tions by design,”arXiv preprint arXiv:2503.18813, 2025
Pith/arXiv arXiv 2025
-
[6]
Veriguard: Enhancing llm agent safety via verified code generation,
L. Miculicich, M. Parmar, H. Palangi, K. D. Dvijotham, M. Monta- nari, T. Pfister, and L. T. Le, “Veriguard: Enhancing llm agent safety via verified code generation,”arXiv preprint arXiv:2510.05156, 2025
arXiv 2025
-
[7]
Attention tracker: Detecting prompt injection attacks in llms,
K.-H. Hung, C.-Y . Ko, A. Rawat, I.-H. Chung, W. H. Hsu, and P.-Y . Chen, “Attention tracker: Detecting prompt injection attacks in llms,” inFindings of the Association for Computational Linguistics: NAACL 2025, 2025, pp. 2309–2322
2025
-
[8]
Skill-inject: Measuring agent vulnerability to skill file attacks,
D. Schmotz, L. Beurer-Kellner, S. Abdelnabi, and M. An- driushchenko, “Skill-inject: Measuring agent vulnerability to skill file attacks,”arXiv preprint arXiv:2602.20156, 2026
Pith/arXiv arXiv 2026
-
[9]
A closer look at system prompt robustness,
N. Mu, J. Lu, M. Lavery, and D. Wagner, “A closer look at system prompt robustness,”arXiv preprint arXiv:2502.12197, 2025
arXiv 2025
-
[10]
Universal and transferable adversarial attacks on aligned language models,
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson, “Universal and transferable adversarial attacks on aligned language models,”arXiv preprint arXiv:2307.15043, 2023
Pith/arXiv arXiv 2023
-
[11]
Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt injection,
S. Abdelnabi, K. Greshake, S. Mishraet al., “Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt injection,” inProceedings of the 16th ACM Workshop on Artificial Intelligence and Security (AISec), 2023
2023
-
[12]
Scientists hide messages in papers to game ai peer review,
E. Gibney, “Scientists hide messages in papers to game ai peer review,”Nature, vol. 643, no. 8073, pp. 887–888, 2025
2025
-
[13]
Get my drift? catching llm task drift with activation deltas,
S. Abdelnabi, A. Fay, G. Cherubin, A. Salem, M. Fritz, and A. Paverd, “Get my drift? catching llm task drift with activation deltas,” in 2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML). IEEE, 2025, pp. 43–67
2025
-
[14]
Secalign: Defending against prompt injection with preference optimization,
S. Chen, A. Zharmagambetov, S. Mahloujifar, K. Chaudhuri, D. Wag- ner, and C. Guo, “Secalign: Defending against prompt injection with preference optimization,” inProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, 2025, pp. 2833–2847
2025
-
[15]
Meta se- calign: A secure foundation llm against prompt injection attacks,
S. Chen, A. Zharmagambetov, D. Wagner, and C. Guo, “Meta se- calign: A secure foundation llm against prompt injection attacks,” arXiv preprint arXiv:2507.02735, 2025
arXiv 2025
-
[16]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,”Advances in neural information processing systems, vol. 36, pp. 53 728–53 741, 2023
2023
-
[17]
Beyond the protocol: Unveiling attack vectors in the model context protocol (MCP) ecosystem,
H. Song, Y . Shen, W. Luoet al., “Beyond the protocol: Unveiling attack vectors in the model context protocol (MCP) ecosystem,”arXiv preprint arXiv:2506.02040, 2025
arXiv 2025
-
[18]
LLM platform security: Ap- plying a systematic evaluation framework to OpenAI’s ChatGPT plugins,
U. Iqbal, T. Kohno, and F. Roesner, “LLM platform security: Ap- plying a systematic evaluation framework to OpenAI’s ChatGPT plugins,”arXiv preprint arXiv:2309.10254, 2023
arXiv 2023
-
[19]
Skilltrojan: Backdoor attacks on skill-based agent systems,
Y . Feng, Y . Ding, Y . Tanet al., “Skilltrojan: Backdoor attacks on skill-based agent systems,”arXiv preprint arXiv:2604.06811, 2026
Pith/arXiv arXiv 2026
-
[20]
Exploiting LLM agent supply chains via payload-less skills,
X. Liu, Y . Zhao, X. Huet al., “Exploiting LLM agent supply chains via payload-less skills,”arXiv preprint arXiv:2605.14460, 2026
Pith/arXiv arXiv 2026
-
[21]
Deepseek-v4: Towards highly efficient million-token context intelligence,
A. DeepSeek, “Deepseek-v4: Towards highly efficient million-token context intelligence,” 2026
2026
-
[22]
Qwen Team, Y . Anet al., “Qwen2.5 technical report,”arXiv preprint arXiv:2412.15115, 2024
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.