Kamera: Unified Position-Invariant Multimodal KV Cache for Training-Free Reuse
Pith reviewed 2026-06-26 07:11 UTC · model grok-4.3
The pith
Storing a low-rank patch with each KV chunk restores the lost cross-chunk conditioning for training-free position-invariant reuse in multimodal models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
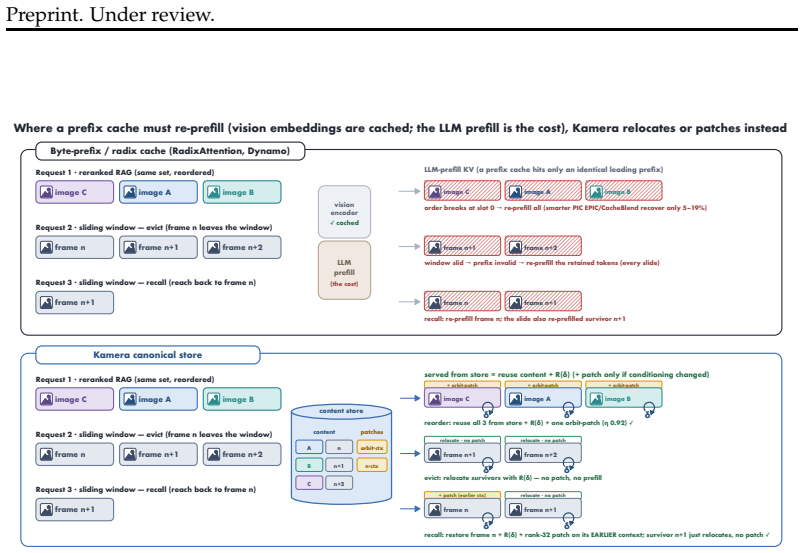
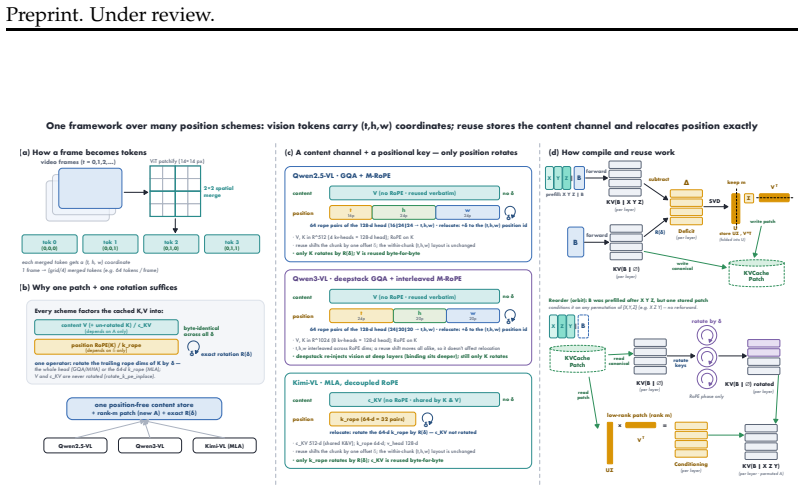
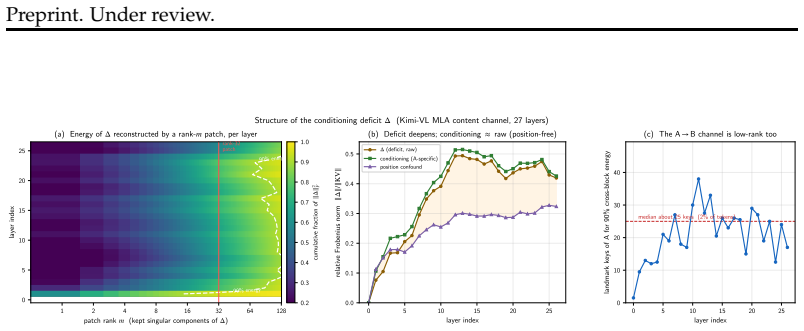
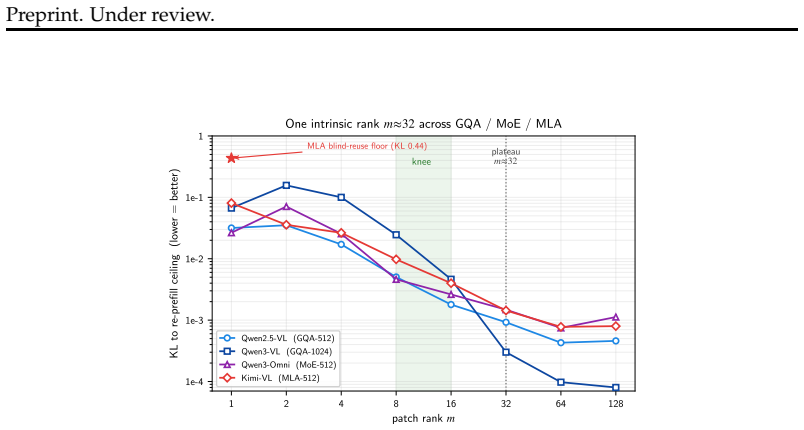
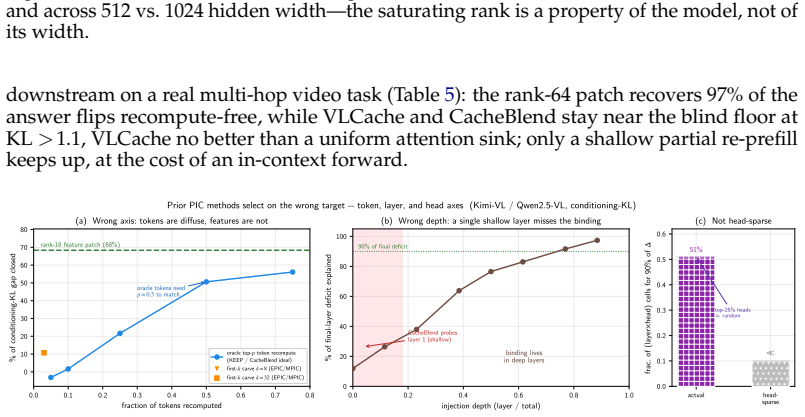
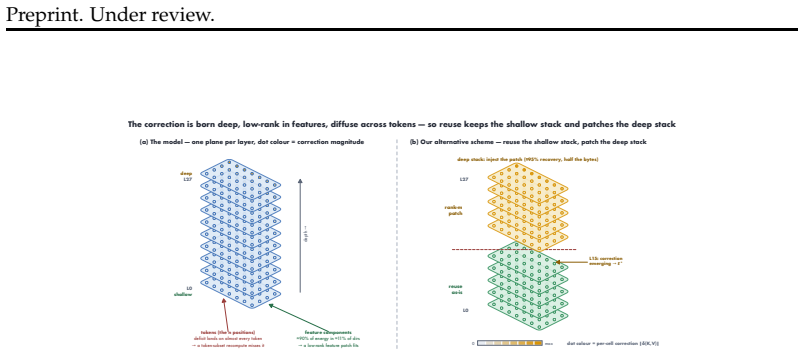
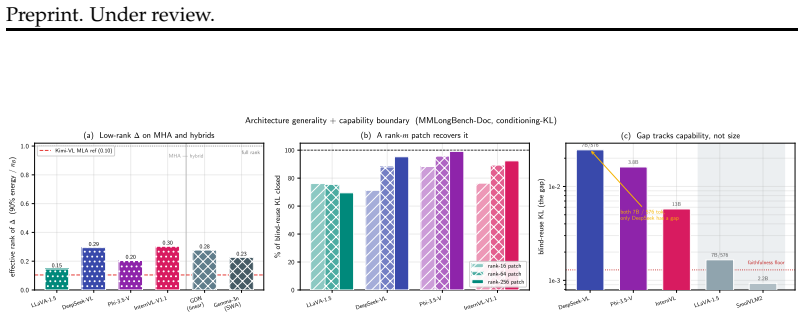
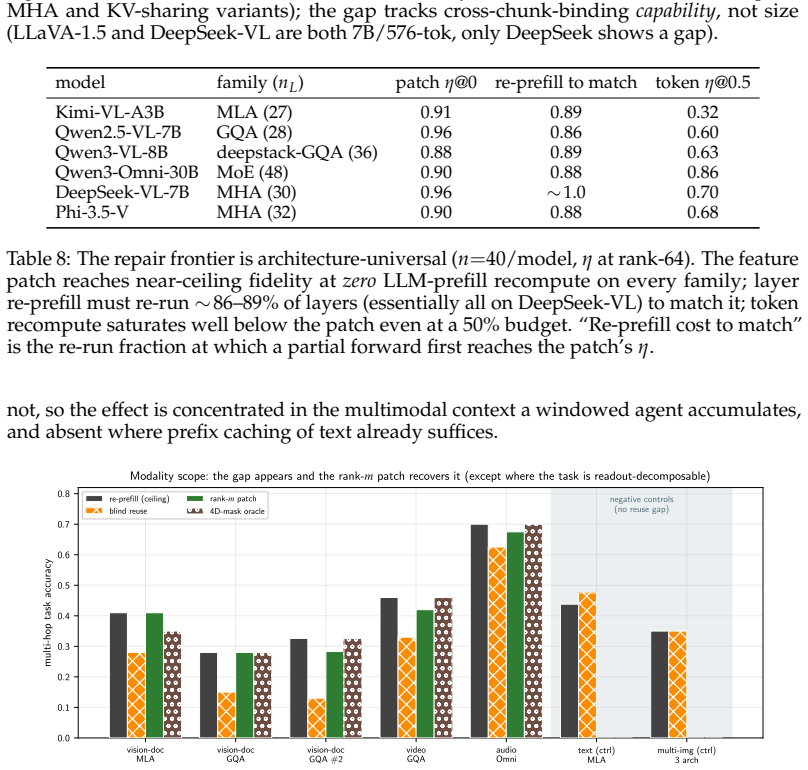
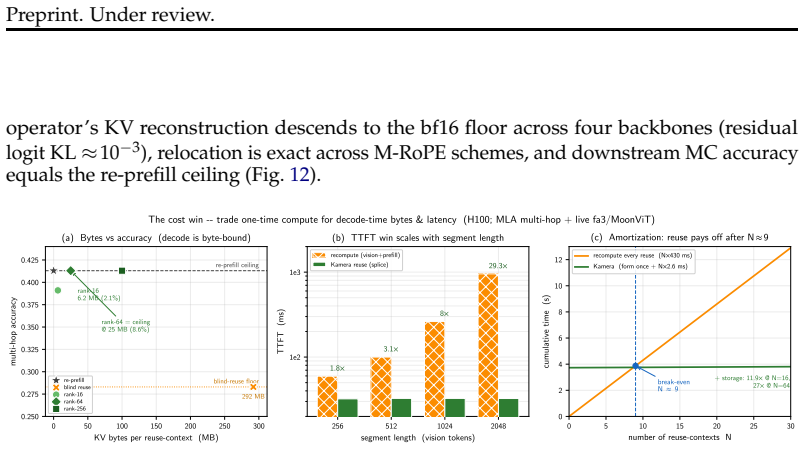
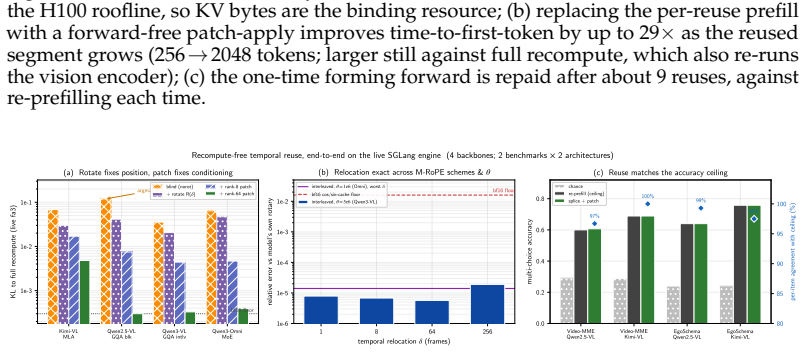
The central claim is that the information lost when a cached chunk is read at a new position is precisely the cross-chunk conditioning absorbed from its neighbors, which manifests as a diffuse low-rank residue concentrated in deeper layers. This residue is recovered by storing a small rank-m conditioning patch with each position-free chunk; reuse then reduces to one operator consisting of exact RoPE re-rotation plus application of the patch. The resulting mechanism supports three window operations at low cost: arbitrary reordering of a cached set, relocation of surviving chunks in a sliding window, and rehydration of an evicted chunk, all without re-encoding. A rank-m patch restores full tas
What carries the argument
the low-rank conditioning patch stored with each position-free chunk, which restores the diffuse cross-chunk residue after exact RoPE re-rotation
If this is right
- Cached chunks can be placed in any order using the same patch and rotation operator.
- Surviving chunks in a sliding window relocate via rotation alone with zero re-encoding.
- An evicted chunk is rehydrated for recall by its stored patch without re-encoding.
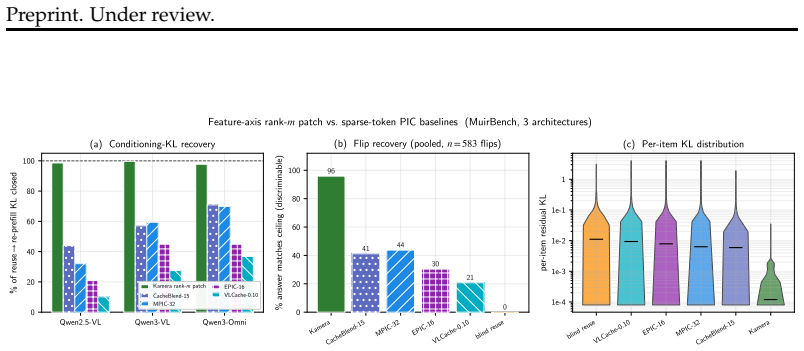
- Full task accuracy on MM-NIAH and two-page doc-QA is recovered at a fraction of the KV footprint.
- The patch reconstructs re-prefill KV values to within bf16 rounding in a production kernel across six backbones.
Where Pith is reading between the lines
- The same low-rank residue pattern may appear in single-modal long-context settings, allowing the patch technique to transfer without multimodal-specific changes.
- Savings would be largest in video and streaming workloads where the conditioning signal is described as strongest.
- The patch could be combined with existing KV compression methods such as quantization to compound memory reductions.
- Testing whether the required rank m grows with context length would clarify the scaling behavior of the residue.
- The method leaves open whether the patch itself can be further compressed or shared across similar chunks.
Load-bearing premise
The cross-chunk conditioning loss is a diffuse low-rank residue concentrated in deep layers that can be fully restored by a small training-free patch stored with each chunk, without requiring model changes or re-encoding.
What would settle it
Apply the rank-m patch versus full re-prefill on MM-NIAH across the two attention families and check whether multi-hop accuracy matches within bf16 rounding error; failure to match falsifies the restoration claim.
Figures
read the original abstract
Multimodal agents repeatedly re-examine the same video frames, UI screenshots, and rendered artifacts as their context window slides and reasoning iterates, yet every look-back re-encodes from scratch, because prefix caches serve reuse only at a fixed leading position. We show this recompute is avoidable, and identify exactly what naive KV reuse loses: the cross-chunk conditioning a chunk absorbs from its neighbours. This loss is asymmetric. The direct readout of a cached chunk is recovered exactly and for free by the standard state-merge. What remains is a diffuse, low-rank residue concentrated in deep layers, invisible to single-hop retrieval but precisely what multi-hop reasoning binds on. Blind reuse therefore leaves single-hop recall intact while halving multi-hop accuracy; this is the failure mode prior position-independent caches, designed for single-context or single-image reuse, do not address. We repair it with a small, training-free low-rank conditioning patch stored alongside each position-free chunk. Reuse reduces to one operator across MLA, GQA, and MHA: exact RoPE re-rotation to any target position, plus the patch that restores cross-chunk binding. This makes three window operations cheap: reorder (one patch serves every ordering of a cached set), sliding-window survival (surviving chunks relocate via rotation only, zero re-encode), and recall (an evicted chunk is rehydrated by its patch, never re-encoded). A rank-m patch recovers full task accuracy on cross-chunk-binding benchmarks, MM-NIAH across two attention families and two-page doc-QA, at a fraction of the KV footprint, and reconstructs re-prefill KV to within bf16 rounding in a production SGLang kernel across six backbones. The conditioning signal is strongest in redundant vision and video streams, making our solution most impactful where multimodal agents spend their recompute budget.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that naive KV-cache reuse in multimodal models loses an asymmetric, diffuse low-rank cross-chunk conditioning residue concentrated in deep layers; this residue can be restored by a small training-free rank-m patch stored with each position-free chunk. Reuse then reduces to RoPE re-rotation plus the patch, enabling cheap reorder, sliding-window survival, and recall. The authors report that a rank-m patch recovers full task accuracy on cross-chunk-binding benchmarks and MM-NIAH (across two attention families and two-page doc-QA), reconstructs re-prefill KV to within bf16 rounding in a production SGLang kernel across six backbones, and is most impactful on redundant vision/video streams.
Significance. If the central empirical claims hold, the work would provide a practical, training-free mechanism for KV-cache reuse in multimodal agents that repeatedly re-examine the same visual content, potentially reducing recompute at a fraction of the KV footprint while preserving multi-hop reasoning accuracy.
major comments (2)
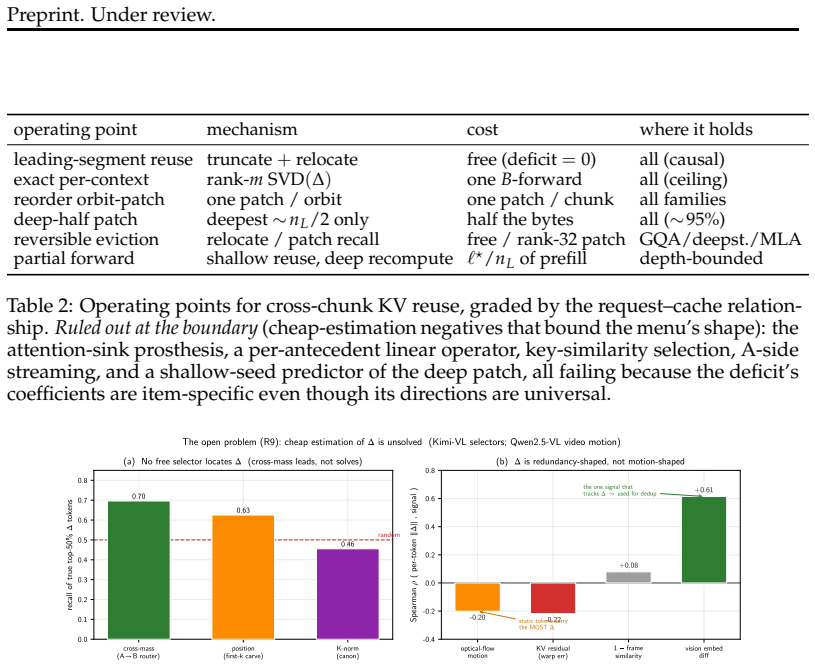
- [Abstract] Abstract: the claim that the lost cross-chunk conditioning is a 'diffuse, low-rank residue' restorable by a single fixed patch per chunk is load-bearing for the reuse guarantee. Because the residue is defined as conditioning absorbed from neighbors, a patch computed once and stored with the chunk must be independent of any particular neighbor set; the manuscript must demonstrate (via explicit construction or ablation) that this residue does not vary materially with neighbor identity or content, otherwise the patch cannot restore binding for arbitrary reorderings without re-encoding.
- [Abstract] Abstract: the reported recovery of 'full task accuracy' on MM-NIAH and cross-chunk-binding tasks is presented without reference to the precise experimental protocol, baseline definitions, or controls for position-dependent effects; this makes it impossible to assess whether the patch truly isolates the claimed low-rank residue or whether the result depends on the specific neighbor sets used during patch computation.
minor comments (2)
- The abstract states results 'across six backbones' and 'two attention families' but does not name them or provide the corresponding tables/figures; adding an explicit list or reference would improve clarity.
- Notation for the patch (rank m, storage format) is introduced without a dedicated equation or pseudocode block in the provided abstract; a short formal definition would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each major point below with clarifications drawn from the manuscript and indicate revisions to strengthen the presentation of independence and experimental details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the lost cross-chunk conditioning is a 'diffuse, low-rank residue' restorable by a single fixed patch per chunk is load-bearing for the reuse guarantee. Because the residue is defined as conditioning absorbed from neighbors, a patch computed once and stored with the chunk must be independent of any particular neighbor set; the manuscript must demonstrate (via explicit construction or ablation) that this residue does not vary materially with neighbor identity or content, otherwise the patch cannot restore binding for arbitrary reorderings without re-encoding.
Authors: The manuscript demonstrates independence via the reorder experiments, where one fixed patch per chunk supports arbitrary reorderings of a cached set while recovering full accuracy. This outcome would be impossible if the residue varied materially with specific neighbor identities or content. The patch is constructed as the low-rank component of the absorbed conditioning in a position-invariant manner (detailed in the methods), and the SGLang kernel reconstruction to bf16 precision across backbones further supports generality. To make the independence explicit as requested, we will add an ablation varying neighbor sets at patch computation time and report the resulting variance. revision: yes
-
Referee: [Abstract] Abstract: the reported recovery of 'full task accuracy' on MM-NIAH and cross-chunk-binding tasks is presented without reference to the precise experimental protocol, baseline definitions, or controls for position-dependent effects; this makes it impossible to assess whether the patch truly isolates the claimed low-rank residue or whether the result depends on the specific neighbor sets used during patch computation.
Authors: The abstract is a summary; the full protocols (patch computation on chunks with a fixed neighbor set during precomputation, baselines of naive reuse without patch versus full re-prefill, and position controls via exact RoPE re-rotation) appear in Section 4 and Appendix B, along with results across two attention families. These controls isolate the residue effect. We will revise the abstract to reference the experimental section and briefly note the protocol and position controls. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's core argument identifies an empirical loss (asymmetric cross-chunk conditioning residue in deep layers) from naive KV reuse and repairs it via a training-free low-rank patch. No equations or claims in the provided text reduce the patch effect or accuracy recovery to a quantity defined by the result itself, a fitted input renamed as prediction, or a self-citation chain. The derivation remains self-contained, with the central claim resting on direct experimental validation across benchmarks and kernels rather than internal redefinition.
Axiom & Free-Parameter Ledger
free parameters (1)
- patch rank m
invented entities (1)
-
low-rank conditioning patch
no independent evidence
Reference graph
Works this paper leans on
-
[1]
and Ermon, Stefano and Rudra, Atri and R
Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R. Flash. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[2]
Dao, Tri , booktitle=. Flash
-
[3]
Efficient memory management for large language model serving with pagedattention
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph and Zhang, Hao and Stoica, Ion , title =. Proceedings of the 29th Symposium on Operating Systems Principles , pages =. 2023 , isbn =. doi:10.1145/3600006.3613165 , abstract =
-
[4]
and Barrett, Clark and Sheng, Ying , title =
Zheng, Lianmin and Yin, Liangsheng and Xie, Zhiqiang and Sun, Chuyue and Huang, Jeff and Yu, Cody Hao and Cao, Shiyi and Kozyrakis, Christos and Stoica, Ion and Gonzalez, Joseph E. and Barrett, Clark and Sheng, Ying , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[5]
Patel, Pratyush and Choukse, Esha and Zhang, Chaojie and Shah, Aashaka and Goiri, \'. Splitwise: Efficient Generative. Proceedings of the 51st Annual International Symposium on Computer Architecture , pages =. 2025 , isbn =. doi:10.1109/ISCA59077.2024.00019 , abstract =
-
[6]
Proceedings of the 18th USENIX Conference on Operating Systems Design and Implementation , articleno =
Zhong, Yinmin and Liu, Shengyu and Chen, Junda and Hu, Jianbo and Zhu, Yibo and Liu, Xuanzhe and Jin, Xin and Zhang, Hao , title =. Proceedings of the 18th USENIX Conference on Operating Systems Design and Implementation , articleno =. 2024 , isbn =
2024
-
[7]
Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =
Shah, Jay and Bikshandi, Ganesh and Zhang, Ying and Thakkar, Vijay and Ramani, Pradeep and Dao, Tri , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[8]
2025 , url=
Shang Yang and Junxian Guo and Haotian Tang and Qinghao Hu and Guangxuan Xiao and Jiaming Tang and Yujun Lin and Zhijian Liu and Yao Lu and Song Han , booktitle=. 2025 , url=
2025
-
[9]
Proceedings of the Twentieth European Conference on Computer Systems , pages =
Yao, Jiayi and Li, Hanchen and Liu, Yuhan and Ray, Siddhant and Cheng, Yihua and Zhang, Qizheng and Du, Kuntai and Lu, Shan and Jiang, Junchen , title =. Proceedings of the Twentieth European Conference on Computer Systems , pages =. 2025 , isbn =. doi:10.1145/3689031.3696098 , abstract =
-
[10]
Bin Yang and Qiuyu Leng and Jun Zeng and Zhenhua Wu , year=. 2510.10129 , archivePrefix=
-
[11]
Yang, Zebin and Xie, Tong and Lu, Baotong and Liu, Shaoshan and Yu, Bo and Li, Meng , journal=
-
[12]
Jingbo Yang and Bairu Hou and Wei Wei and Yujia Bao and Shiyu Chang , journal=
-
[13]
Proceedings of the 42nd International Conference on Machine Learning , articleno =
Hu, Junhao and Huang, Wenrui and Wang, Weidong and Wang, Haoyi and Hu, Tiancheng and Zhang, Qin and Feng, Hao and Chen, Xusheng and Shan, Yizhou and Xie, Tao , title =. Proceedings of the 42nd International Conference on Machine Learning , articleno =. 2025 , publisher =
2025
-
[14]
2025 , url=
Junhao Hu and Wenrui Huang and Weidong Wang and Haoyi Wang and tiancheng hu and zhang qin and Hao Feng and Xusheng Chen and Yizhou Shan and Tao Xie , booktitle=. 2025 , url=
2025
-
[15]
Qin, Shengling and Yu, Hao and Wu, Chenxin and Li, Zheng and Cao, Yizhong and Zhuge, Zhengyang and Zhou, Yuxin and Yao, Wentao and Zhang, Yi and Wang, Zhengheng and Bai, Shuai and Zhang, Jianwei and Lin, Junyang , journal=
-
[16]
Hao Kang and Qingru Zhang and Souvik Kundu and Geonhwa Jeong and Zaoxing Liu and Tushar Krishna and Tuo Zhao , year=. 2403.05527 , archivePrefix=
-
[17]
Abdelfattah , year=
Chi-Chih Chang and Wei-Cheng Lin and Chien-Yu Lin and Yash Akhauri and Hung-Yueh Chiang and Xilai Dai and Huiqiang Jiang and Yucheng Li and Kai-Chiang Wu and Luis Ceze and Mohamed S. Abdelfattah , year=. x
-
[18]
2026 , eprint=
Semantic Cache Distillation: Efficient State Transfer via Reuse and Selective Patching , author=. 2026 , eprint=
2026
-
[19]
Lin, Ji and Tang, Jiaming and Tang, Haotian and Yang, Shang and Xiao, Guangxuan and Han, Song , title =. GetMobile: Mobile Comp. and Comm. , month = jan, pages =. 2025 , issue_date =. doi:10.1145/3714983.3714987 , abstract =
-
[20]
2023 , url=
Elias Frantar and Saleh Ashkboos and Torsten Hoefler and Dan Alistarh , booktitle=. 2023 , url=
2023
-
[21]
Proceedings of the 40th International Conference on Machine Learning , articleno =
Xiao, Guangxuan and Lin, Ji and Seznec, Mickael and Wu, Hao and Demouth, Julien and Han, Song , title =. Proceedings of the 40th International Conference on Machine Learning , articleno =. 2023 , publisher =
2023
-
[22]
2024 , url=
Zirui Liu and Jiayi Yuan and Hongye Jin and Shaochen Zhong and Zhaozhuo Xu and Vladimir Braverman and Beidi Chen and Xia Hu , booktitle=. 2024 , url=
2024
-
[23]
and Shao, Yakun Sophia and Keutzer, Kurt and Gholami, Amir , title =
Hooper, Coleman and Kim, Sehoon and Mohammadzadeh, Hiva and Mahoney, Michael W. and Shao, Yakun Sophia and Keutzer, Kurt and Gholami, Amir , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[24]
Lin*, Yujun and Tang*, Haotian and Yang*, Shang and Zhang, Zhekai and Xiao, Guangxuan and Gan, Chuang and Han, Song , journal=
-
[25]
2024 , eprint=
Efficient Streaming Language Models with Attention Sinks , author=. 2024 , eprint=
2024
-
[26]
CoRR , volume=
Zhongwei Wan and Ziang Wu and Che Liu and Jinfa Huang and Zhihong Zhu and Peng Jin and Longyue Wang and Li Yuan , title=. CoRR , volume=. 2024 , cdate=
2024
-
[27]
Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
Zhang, Zhenyu and Sheng, Ying and Zhou, Tianyi and Chen, Tianlong and Zheng, Lianmin and Cai, Ruisi and Song, Zhao and Tian, Yuandong and R\'. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[28]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Tang, Jiaming and Zhao, Yilong and Zhu, Kan and Xiao, Guangxuan and Kasikci, Baris and Han, Song , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[29]
Guangxuan Xiao and Jiaming Tang and Jingwei Zuo and Junxian Guo and Shang Yang and Haotian Tang and Yao Fu and Song Han , year=. 2410.10819 , archivePrefix=
-
[30]
Proceedings of the 42nd International Conference on Machine Learning , articleno =
Sun, Hanshi and Chang, Li-Wen and Bao, Wenlei and Zheng, Size and Zheng, Ningxin and Liu, Xin and Dong, Harry and Chi, Yuejie and Chen, Beidi , title =. Proceedings of the 42nd International Conference on Machine Learning , articleno =. 2025 , publisher =
2025
-
[31]
2024 , eprint=
MagicPIG: LSH Sampling for Efficient LLM Generation , author=. 2024 , eprint=
2024
-
[32]
Su, Jianlin and Ahmed, Murtadha and Lu, Yu and Pan, Shengfeng and Bo, Wen and Liu, Yunfeng , title =. 2024 , issue_date =. doi:10.1016/j.neucom.2023.127063 , journal =
-
[33]
2023 , url=
Joshua Ainslie and James Lee-Thorp and Michiel de Jong and Yury Zemlyanskiy and Federico Lebron and Sumit Sanghai , booktitle=. 2023 , url=
2023
-
[34]
Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
Liu, Haotian and Li, Chunyuan and Wu, Qingyang and Lee, Yong Jae , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[35]
Improved Baselines with Visual Instruction Tuning , year=
Liu, Haotian and Li, Chunyuan and Li, Yuheng and Lee, Yong Jae , booktitle=. Improved Baselines with Visual Instruction Tuning , year=
-
[36]
Feng Li and Renrui Zhang and Hao Zhang and Yuanhan Zhang and Bo Li and Wei Li and Zejun Ma and Chunyuan Li , year=. 2407.07895 , archivePrefix=
-
[37]
2025 , url=
Bo Li and Yuanhan Zhang and Dong Guo and Renrui Zhang and Feng Li and Hao Zhang and Kaichen Zhang and Peiyuan Zhang and Yanwei Li and Ziwei Liu and Chunyuan Li , journal=. 2025 , url=
2025
-
[38]
Ji Lin and Hongxu Yin and Wei Ping and Yao Lu and Pavlo Molchanov and Andrew Tao and Huizi Mao and Jan Kautz and Mohammad Shoeybi and Song Han , year=. 2312.07533 , archivePrefix=
-
[39]
Ruyi Xu and Guangxuan Xiao and Yukang Chen and Liuning He and Kelly Peng and Yao Lu and Song Han , year=. 2510.09608 , archivePrefix=
-
[40]
Fei Wang and Xingyu Fu and James Y. Huang and Zekun Li and Qin Liu and Xiaogeng Liu and Mingyu Derek Ma and Nan Xu and Wenxuan Zhou and Kai Zhang and Tianyi Lorena Yan and Wenjie Jacky Mo and Hsiang-Hui Liu and Pan Lu and Chunyuan Li and Chaowei Xiao and Kai-Wei Chang and Dan Roth and Sheng Zhang and Hoifung Poon and Muhao Chen , year=. 2406.09411 , archi...
-
[41]
2024 , url=
Song Dingjie and Shunian Chen and Guiming Hardy Chen and Fei Yu and Xiang Wan and Benyou Wang , booktitle=. 2024 , url=
2024
-
[42]
The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
Needle In A Multimodal Haystack , author=. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[43]
2024 , url=
Yubo Ma and Yuhang Zang and Liangyu Chen and Meiqi Chen and Yizhu Jiao and Xinze Li and Xinyuan Lu and Ziyu Liu and Yan Ma and Xiaoyi Dong and Pan Zhang and Liangming Pan and Yu-Gang Jiang and Jiaqi Wang and Yixin Cao and Aixin Sun , booktitle=. 2024 , url=
2024
-
[44]
Chaoyou Fu and Yuhan Dai and Yongdong Luo and Lei Li and Shuhuai Ren and Renrui Zhang and Zihan Wang and Chenyu Zhou and Yunhang Shen and Mengdan Zhang and Peixian Chen and Yanwei Li and Shaohui Lin and Sirui Zhao and Ke Li and Tong Xu and Xiawu Zheng and Enhong Chen and Caifeng Shan and Ran He and Xing Sun , year=. 2405.21075 , archivePrefix=
-
[45]
Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
Mangalam, Karttikeya and Akshkulakov, Raiymbek and Malik, Jitendra , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[46]
2025 , eprint=
Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces , author=. 2025 , eprint=
2025
-
[47]
Harsh Trivedi and Niranjan Balasubramanian and Tushar Khot and Ashish Sabharwal , title =. CoRR , volume =. 2021 , url =. 2108.00573 , timestamp =
arXiv 2021
-
[48]
Yuhan Liu and Yuyang Huang and Jiayi Yao and Shaoting Feng and Zhuohan Gu and Kuntai Du and Hanchen Li and Yihua Cheng and Junchen Jiang and Shan Lu and Madan Musuvathi and Esha Choukse , year=. 2411.02820 , archivePrefix=
-
[49]
Kunxi Li and Yufan Xiong and Zhonghua Jiang and Yiyun Zhou and Zhaode Wang and Chengfei Lv and Shengyu Zhang , year=. 2511.05534 , archivePrefix=
-
[50]
Siyu Xu and Yunke Wang and Chenghao Xia and Dihao Zhu and Tao Huang and Chang Xu , year=. 2502.02175 , archivePrefix=
-
[51]
Chen Shi and Jinrui Xu and Shaoshuai Shi and Kehua Sheng and Bo Zhang and Li Jiang , year=. 2605.28544 , archivePrefix=
-
[52]
Haowei Zhang and Shudong Yang and Jinlan Fu and See-Kiong Ng and Xipeng Qiu , year=. 2601.14724 , archivePrefix=
-
[53]
Yanlai Yang and Zhuokai Zhao and Satya Narayan Shukla and Aashu Singh and Shlok Kumar Mishra and Lizhu Zhang and Mengye Ren , year=. 2508.15717 , archivePrefix=
-
[54]
Zikang Liu and Junyi Li and Wayne Xin Zhao and Dawei Gao and Yaliang Li and Ji-rong Wen , year=. 2510.00413 , archivePrefix=
-
[55]
2025 , eprint=
Embodied VideoAgent: Persistent Memory from Egocentric Videos and Embodied Sensors Enables Dynamic Scene Understanding , author=. 2025 , eprint=
2025
-
[56]
Shen, Haozhan and Zhao, Kangjia and Zhao, Tiancheng and Xu, Ruochen and Zhang, Zilun and Zhu, Mingwei and Yin, Jianwei. Z oom E ye: Enhancing Multimodal LLM s with Human-Like Zooming Capabilities through Tree-Based Image Exploration. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.335
-
[57]
Wang, Xiaohan and Zhang, Yuhui and Zohar, Orr and Yeung-Levy, Serena , title =. Computer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part LXXX , pages =. 2024 , isbn =. doi:10.1007/978-3-031-72989-8_4 , abstract =
-
[58]
He, Hongliang and Yao, Wenlin and Ma, Kaixin and Yu, Wenhao and Dai, Yong and Zhang, Hongming and Lan, Zhenzhong and Yu, Dong. W eb V oyager: Building an End-to-End Web Agent with Large Multimodal Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.371
-
[59]
Modular Visual Question Answering via Code Generation
Subramanian, Sanjay and Narasimhan, Medhini and Khangaonkar, Kushal and Yang, Kevin and Nagrani, Arsha and Schmid, Cordelia and Zeng, Andy and Darrell, Trevor and Klein, Dan. Modular Visual Question Answering via Code Generation. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2023. doi:10....
-
[60]
Haoxuan You and Rui Sun and Zhecan Wang and Long Chen and Gengyu Wang and Hammad Ayyubi and Kai-Wei Chang and Shih-Fu Chang , booktitle=. Ideal. 2023 , url=
2023
- [61]
-
[62]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Zheng, Boyuan and Gou, Boyu and Kil, Jihyung and Sun, Huan and Su, Yu , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[63]
Jaemin Cho and Debanjan Mahata and Ozan Irsoy and Yujie He and Mohit Bansal , year=. 2411.04952 , archivePrefix=
-
[64]
Shenghao Fu and Qize Yang and Yuan-Ming Li and Xihan Wei and Xiaohua Xie and Wei-Shi Zheng , year=. 2509.24786 , archivePrefix=
-
[65]
Zhang, Shuoshuo and Li, Zijian and Zhang, Yizhen and Fu, Jingjing and Song, Lei and Bian, Jiang and Zhang, Jun and Yang, Yujiu and Wang, Rui , journal=
-
[66]
Yuanlei Zheng and Pei Fu and Hang Li and Ziyang Wang and Yuyi Zhang and Wenyu Ruan and Xiaojin Zhang and Zhongyu Wei and Zhenbo Luo and Jian Luan and Wei Chen and Xiang Bai , year=. 2604.13731 , archivePrefix=
-
[67]
arXiv preprint arXiv:2505.18079 , year=
Deep Video Discovery: Agentic Search with Tool Use for Long-form Video Understanding , author=. arXiv preprint arXiv:2505.18079 , year=
-
[68]
Shuai Bai and Keqin Chen and Xuejing Liu and Jialin Wang and Wenbin Ge and others , year=. 2502.13923 , archivePrefix=
-
[69]
Shuai Bai and Yuxuan Cai and Ruizhe Chen and Keqin Chen and Xionghui Chen and others , year=. 2511.21631 , archivePrefix=
-
[70]
Jin Xu and Zhifang Guo and Hangrui Hu and Yunfei Chu and Xiong Wang and others , year=. 2509.17765 , archivePrefix=
-
[71]
Haoyu Lu and Wen Liu and Bo Zhang and Bingxuan Wang and Kai Dong and Bo Liu and Jingxiang Sun and Tongzheng Ren and Zhuoshu Li and Hao Yang and Yaofeng Sun and Chengqi Deng and Hanwei Xu and Zhenda Xie and Chong Ruan , year=. 2403.05525 , archivePrefix=
-
[72]
Zhiyu Wu and Xiaokang Chen and Zizheng Pan and Xingchao Liu and Wen Liu and Damai Dai and Huazuo Gao and Yiyang Ma and Chengyue Wu and Bingxuan Wang and Zhenda Xie and Yu Wu and Kai Hu and Jiawei Wang and Yaofeng Sun and Yukun Li and Yishi Piao and Kang Guan and Aixin Liu and Xin Xie and Yuxiang You and Kai Dong and Xingkai Yu and Haowei Zhang and Liang Z...
-
[73]
Jinguo Zhu and Weiyun Wang and Zhe Chen and Zhaoyang Liu and Shenglong Ye and others , year=. 2504.10479 , archivePrefix=
-
[74]
2024 , volume=
Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and Li, Bin and Luo, Ping and Lu, Tong and Qiao, Yu and Dai, Jifeng , booktitle=. 2024 , volume=
2024
-
[75]
Marah Abdin and Jyoti Aneja and Hany Awadalla and Ahmed Awadallah and Ammar Ahmad Awan and others , year=. 2404.14219 , archivePrefix=
-
[76]
Andr. Smol. Second Conference on Language Modeling , year=
-
[77]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.