Dimensionality Reduction of QAOA Parameter Space with Kernel PCA for Max-Cut
Pith reviewed 2026-06-26 21:05 UTC · model grok-4.3
The pith
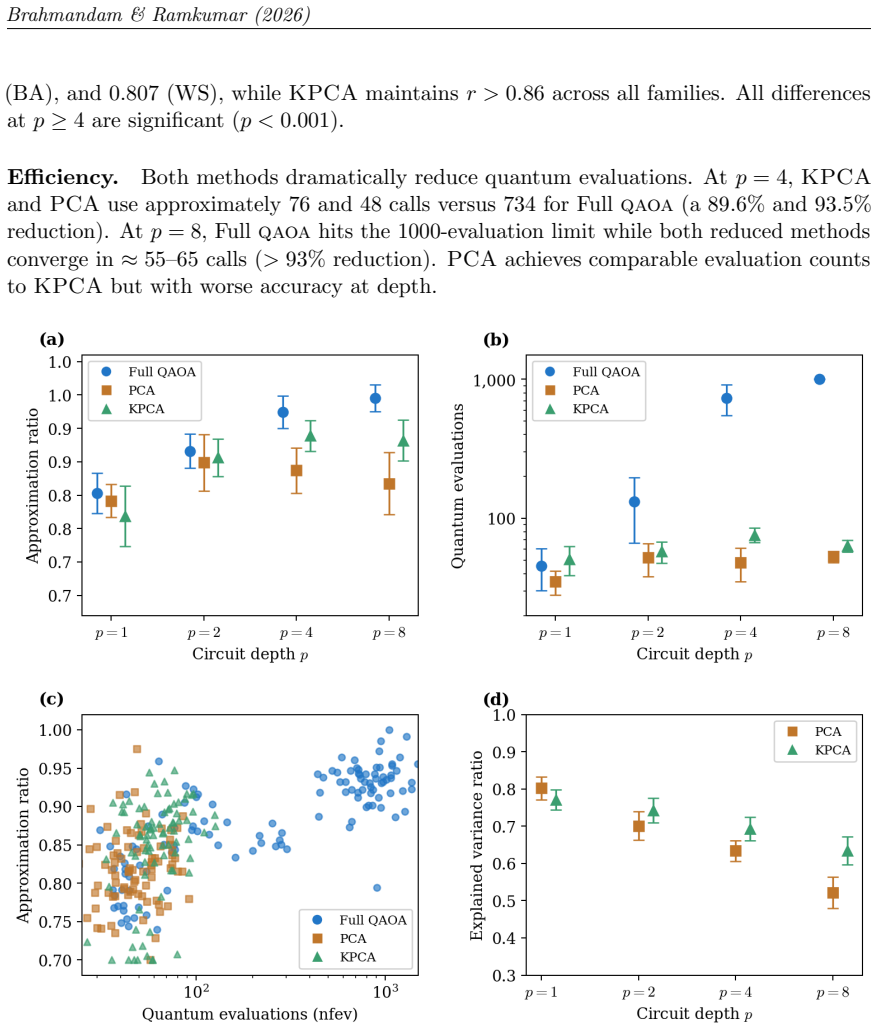
Kernel PCA captures the nonlinear QAOA parameter manifold at depth 8 better than linear PCA, keeping approximation ratios above 0.86 on Max-Cut while cutting circuit evaluations by over 93 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
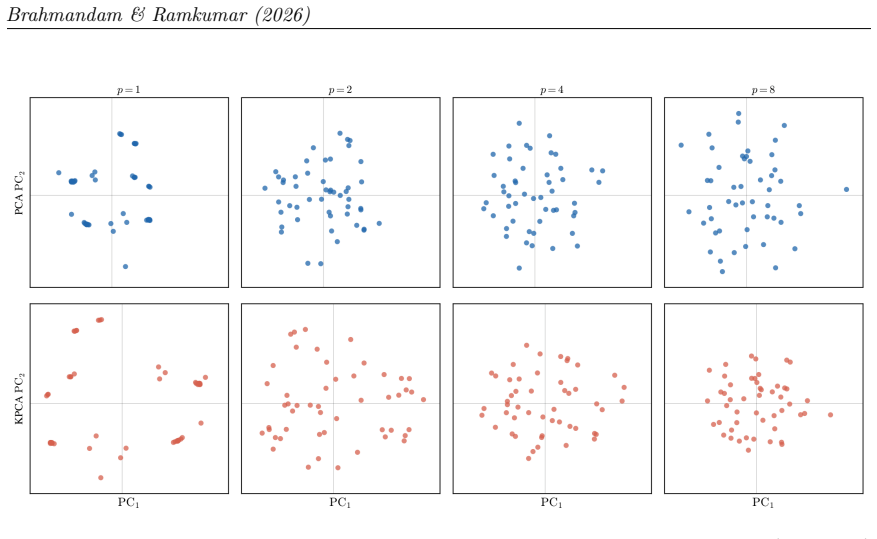
Kernel Principal Component Analysis with a radial basis function kernel provides a nonlinear dimensionality reduction of the QAOA parameter space that outperforms linear PCA at circuit depths up to 8. When trained on 200 graphs each from the Erdos-Renyi, Barabasi-Albert, and Watts-Strogatz families with 7-10 nodes, the KPCA model produces approximation ratios above 0.86 on 30 unseen 12-node test graphs at depth 8, while PCA falls to 0.81-0.83; both approaches reduce the number of quantum circuit evaluations by more than 93 percent relative to full-parameter optimization.
What carries the argument
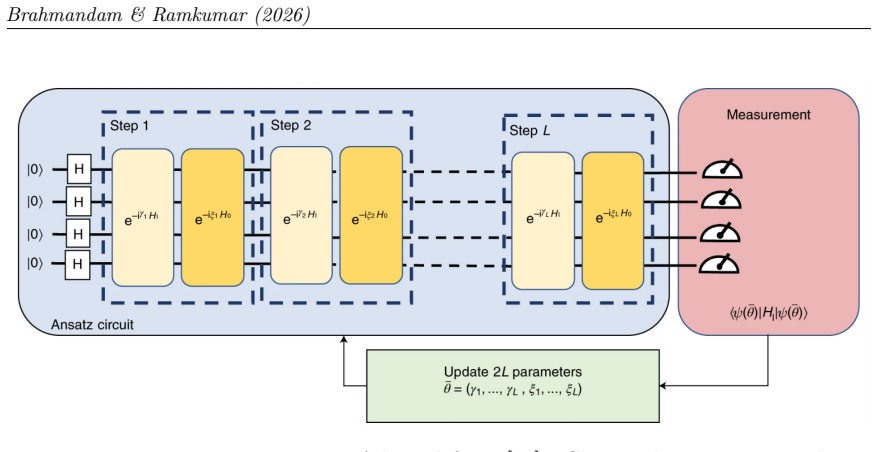
Kernel Principal Component Analysis (KPCA) with radial basis function kernel, which maps QAOA parameters into a higher-dimensional space to extract nonlinear principal components for reduced optimization.
If this is right
- At depth 8, KPCA maintains approximation ratios above 0.86 across all three graph families while PCA performance declines.
- Both KPCA and PCA reduce the required quantum circuit evaluations by more than 93 percent compared with unrestricted parameter optimization.
- A model trained on smaller graphs transfers to larger graphs within the same families at depths 1 through 8.
- Nonlinear kernel methods capture the QAOA parameter manifold structure more effectively once circuit depth makes the landscape sufficiently curved.
Where Pith is reading between the lines
- Kernel-based reduction could be tested on other variational algorithms such as VQE that encounter similarly nonlinear parameter landscapes.
- The depth-dependent growth in nonlinearity implies that kernel or manifold-learning methods may become necessary for QAOA beyond depth 8.
- Training across multiple graph ensembles may allow the reduced space to support optimization on graphs drawn from different distributions than the training set.
Load-bearing premise
The QAOA parameter manifold on these graph families becomes nonlinear at depth 8 in a way that an RBF-kernel model trained on 7-10 node instances will generalize to 12-node graphs without significant distribution shift.
What would settle it
On the 12-node test set at depth 8, if KPCA-reduced optimization produces approximation ratios at or below the 0.81-0.83 range achieved by PCA, the claimed superiority of the nonlinear reduction would not hold.
Figures
read the original abstract
The Quantum Approximate Optimization Algorithm (QAOA) is a leading variational algorithm for combinatorial optimization on near term quantum devices. As circuit depth increases, the number of optimization parameters grows, making the search landscape increasingly nonlinear and difficult to optimize. Previous studies have shown that optimal QAOA parameters often lie on a low dimensional manifold that can be approximated using Principal Component Analysis (PCA) at shallow circuit depths. However, the effectiveness of PCA decreases at higher depths because the underlying parameter manifold becomes increasingly nonlinear. In this work, we investigate Kernel Principal Component Analysis (KPCA) with a radial basis function kernel as a nonlinear dimensionality reduction technique for QAOA parameter optimization. The model is trained using 200 graphs from each of 3 graph families, namely Erdos-Renyi, Barabasi-Albert, and Watts-Strogatz, with graph sizes ranging from 7 to 10 nodes. Performance is evaluated on 30 test graphs containing 12 nodes at circuit depths 1, 2, 4, and 8. Experimental results demonstrate that KPCA consistently outperforms PCA at deeper circuit depths across all graph families. At depth 8, KPCA achieves approximation ratios above 0.86, while PCA declines to approximately 0.81 to 0.83. Both methods reduce the number of quantum circuit evaluations by more than 93 percent relative to unrestricted QAOA optimization. These findings suggest that nonlinear kernel methods more effectively capture the structure of the QAOA parameter manifold and provide a practical approach for scaling variational quantum optimization to deeper circuits.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Kernel PCA (RBF kernel) as a nonlinear dimensionality reduction method for QAOA parameters in Max-Cut, trained on optimal parameters from 200 graphs each of Erdos-Renyi, Barabasi-Albert, and Watts-Strogatz families (sizes 7-10 nodes) and evaluated on 30 held-out 12-node graphs at depths 1, 2, 4, and 8. It claims KPCA outperforms linear PCA at depth 8 (approximation ratios >0.86 vs. 0.81-0.83) while both techniques reduce quantum circuit evaluations by >93% relative to full optimization.
Significance. If the generalization from small to larger graphs holds and the empirical gains are robust, the work would show that kernel methods can capture nonlinear structure in QAOA parameter manifolds at moderate depths, offering a practical route to reduce optimization cost for deeper variational circuits without sacrificing solution quality.
major comments (2)
- [Abstract and Experimental Results] The manuscript reports approximation ratios and reduction percentages in the abstract and results but supplies no information on training procedure, RBF kernel hyperparameter selection, how optimal training parameters were obtained, graph generation parameters, or statistical error bars; without these the central performance claim at depth 8 cannot be assessed or reproduced.
- [Methods and Results (generalization claim)] The evaluation relies on an unverified assumption that an RBF-KPCA model fitted to 7-10 node instances produces faithful components for 12-node test graphs; because QAOA landscapes are known to vary with graph size and density, any manifold shift would misalign the learned components and render the reported KPCA advantage an artifact of in-distribution training rather than a general reduction technique.
minor comments (2)
- Notation for the reduced parameter space and the precise mapping from KPCA components back to QAOA angles is not defined, making it difficult to understand how the low-dimensional optimization is performed.
- The paper should cite prior work on linear PCA for QAOA parameters and on the size dependence of QAOA landscapes to situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and Experimental Results] The manuscript reports approximation ratios and reduction percentages in the abstract and results but supplies no information on training procedure, RBF kernel hyperparameter selection, how optimal training parameters were obtained, graph generation parameters, or statistical error bars; without these the central performance claim at depth 8 cannot be assessed or reproduced.
Authors: We agree that these details are required for reproducibility and evaluation of the depth-8 claims. In the revised manuscript we will expand the Methods and Experimental Setup sections to describe: (i) the classical optimizer and convergence criteria used to obtain the optimal training parameters, (ii) the precise generation parameters for each graph family (edge probability for Erdős–Rényi, attachment parameter for Barabási–Albert, rewiring probability for Watts–Strogatz), (iii) the procedure for selecting the RBF kernel hyperparameter (grid search or cross-validation on a validation subset), and (iv) mean approximation ratios together with standard deviations or error bars computed over the 30 test graphs. These additions will allow readers to reproduce and assess the reported performance. revision: yes
-
Referee: [Methods and Results (generalization claim)] The evaluation relies on an unverified assumption that an RBF-KPCA model fitted to 7-10 node instances produces faithful components for 12-node test graphs; because QAOA landscapes are known to vary with graph size and density, any manifold shift would misalign the learned components and render the reported KPCA advantage an artifact of in-distribution training rather than a general reduction technique.
Authors: We acknowledge that QAOA parameter manifolds can shift with graph size and density, and that we did not perform an explicit verification of component alignment across the 7–10 to 12 node transition. The training design—600 graphs spanning three structurally distinct families over a 7–10 node range—was chosen to promote robustness, and the held-out 12-node results show KPCA retaining an advantage over PCA at depth 8. Nevertheless, we will add an explicit discussion of this generalization assumption, its potential limitations, and directions for future validation on larger size gaps. We therefore treat the revision as partial: the core empirical claim stands on the reported held-out performance, while the manuscript will be updated to address the referee’s concern directly. revision: partial
Circularity Check
No significant circularity; results are empirical comparisons on held-out graphs
full rationale
The paper reports experimental comparisons of KPCA vs PCA on 12-node test graphs after training on 7-10 node instances. No equations, derivations, or predictions are claimed that reduce by construction to quantities fitted from the evaluation data. The central claims (approximation ratios >0.86 for KPCA at depth 8, >93% fewer evaluations) are direct measurements on separate test instances and do not rely on self-definitional steps, fitted-input predictions, or load-bearing self-citations that collapse the result to its inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Quantum optimization for real-world applications: A survey
Md Nasir Islam et al. Quantum optimization for real-world applications: A survey. IEEE Transactions on Quantum Engineering, 2024
2024
-
[2]
Applications of quantum algorithms to combinatorial optimization
Fakhrul Kazi et al. Applications of quantum algorithms to combinatorial optimization. Journal of Quantum Computing, 2025
2025
-
[3]
Leo Zhou, Sheng-Tao Wang, Soonwon Choi, Hannes Pichler, and Mikhail D. Lukin. Quantum approximate optimization algorithm: Performance, mechanism, and imple- mentation on near-term devices.Physical Review X, 10:021067, 2020
2020
-
[4]
Richard M. Karp. Reducibility among combinatorial problems.Complexity of Computer Computations, pages 85–103, 1972
1972
-
[5]
Goemans and David P
Michel X. Goemans and David P. Williamson. Improved approximation algorithms for maximum cut and satisfiability problems using semidefinite programming.Journal of the ACM, 42:1115–1145, 1995
1995
-
[6]
A Quantum Approximate Optimization Algorithm
Edward Farhi, Jeffrey Goldstone, and Sam Gutmann. A quantum approximate opti- mization algorithm. 2014. doi: 10.48550/arXiv.1411.4028
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1411.4028 2014
-
[7]
Quantum computing in the nisq era and beyond.Quantum, 2:79, 2018
John Preskill. Quantum computing in the nisq era and beyond.Quantum, 2:79, 2018
2018
-
[8]
General parameter- shift rules for quantum gradients.Quantum, 6:670, 2022
David Wierichs, Josh Izaac, Shahnawaz Wang, and Francisca Wilde. General parameter- shift rules for quantum gradients.Quantum, 6:670, 2022
2022
-
[9]
Akshay, D
V. Akshay, D. Rabinovich, E. Viterbo, and Z. Song. Parameter concentrations in quantum approximate optimization.Physical Review A, 104:012418, 2021
2021
-
[10]
Transferability of graph neural networks using graphon neural networks with generalization guarantees
Alexei Galda, Xiaoyuan Liu, Dima Lykov, Yuri Alexeev, and Ilya Safro. Transferability of graph neural networks using graphon neural networks with generalization guarantees. 2023
2023
-
[11]
Akshay, et al
Mark Eichenseher, V. Akshay, et al. Parameter transfer in quantum approximate optimization.Nature Physics, 2025
2025
-
[12]
Obstacles to variational quantum optimization from symmetry protection.Nature Physics, 17: 452–456, 2021
Sergei Bravyi, Alexander Chowdhury, David Mesirov, and Colin Tomlin. Obstacles to variational quantum optimization from symmetry protection.Nature Physics, 17: 452–456, 2021
2021
-
[13]
Qaoa-pca: Enhancing efficiency in the quantum approximate optimization algorithm via principal component analysis
Owain Parry and Phil McMinn. Qaoa-pca: Enhancing efficiency in the quantum approximate optimization algorithm via principal component analysis. 2025
2025
-
[14]
Exploiting symmetry reduces the cost of training qaoa.IEEE Transactions on Quantum Engineering, 2:1–24, 2021
Ruslan Shaydulin, Ilya Safro, and Jeffrey Larson. Exploiting symmetry reduces the cost of training qaoa.IEEE Transactions on Quantum Engineering, 2:1–24, 2021
2021
-
[15]
Nakanishi, Keisuke Fujii, and Seiichiro Todo
Ken M. Nakanishi, Keisuke Fujii, and Seiichiro Todo. Sequential minimal optimization for quantum-classical hybrid algorithms.Physical Review Research, 2:043158, 2020. 9 Brahmandam & Ramkumar (2026)
2020
-
[16]
Nonlinear component analysis as a kernel eigenvalue problem.Neural Computation, 10:1299–1319, 1998
Bernhard Sch¨ olkopf, Alexander Smola, and Klaus-Robert M¨ uller. Nonlinear component analysis as a kernel eigenvalue problem.Neural Computation, 10:1299–1319, 1998
1998
-
[17]
The quantum approximate optimization algorithm and the sherrington-kirkpatrick model at infinite size.Quantum, 6:863, 2022
Edward Farhi and Sam Gutmann. The quantum approximate optimization algorithm and the sherrington-kirkpatrick model at infinite size.Quantum, 6:863, 2022
2022
-
[18]
Daniel Stilck Fran¸ ca and Raul Garc´ ıa-Patr´ on. Limitations of optimization algorithms on noisy quantum devices.Nature Physics, 17(11):1221–1227, 2021. doi: 10.1038/ s41567-021-01356-3. URLhttps://doi.org/10.1038/s41567-021-01356-3
-
[19]
On the influence of the kernel on the consistency of support vector machines.Journal of Machine Learning Research, 2:67–93, 2001
Ingo Steinwart. On the influence of the kernel on the consistency of support vector machines.Journal of Machine Learning Research, 2:67–93, 2001
2001
-
[20]
Functions of positive and negative type and their connection with the theory of integral equations.Philosophical Transactions of the Royal Society A, 209: 415–446, 1909
James Mercer. Functions of positive and negative type and their connection with the theory of integral equations.Philosophical Transactions of the Royal Society A, 209: 415–446, 1909
1909
-
[21]
Borgwardt, Malte J
Arthur Gretton, Karsten M. Borgwardt, Malte J. Rasch, Bernhard Sch¨ olkopf, and Alexander J. Smola. A kernel two-sample test.Journal of Machine Learning Research, 13:723–773, 2012
2012
-
[22]
Bakir, Jason Weston, and Bernhard Sch¨ olkopf
G¨ okhan H. Bakir, Jason Weston, and Bernhard Sch¨ olkopf. Learning to find pre-images. InAdvances in Neural Information Processing Systems, pages 449–456, 2004
2004
-
[23]
On random graphs.Publicationes Mathematicae, 6: 290–297, 1959
Paul Erd˝ os and Alfr´ ed R´ enyi. On random graphs.Publicationes Mathematicae, 6: 290–297, 1959
1959
-
[24]
Emergence of scaling in random networks
Albert-L´ aszl´ o Barab´ asi and R´ eka Albert. Emergence of scaling in random networks. Science, 286:509–512, 1999
1999
-
[25]
Watts and Steven H
Duncan J. Watts and Steven H. Strogatz. Collective dynamics of small-world networks. Nature, 393:440–442, 1998
1998
-
[26]
Qiskit: An open-source framework for quantum computing
Abraham Asfaw et al. Qiskit: An open-source framework for quantum computing. Zenodo, 2021. doi: 10.5281/zenodo.2573505. 10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.