Listening makes Vision Clear for VLMs
Pith reviewed 2026-06-26 09:07 UTC · model grok-4.3
The pith
Prompt-side token attention with boundary filtering measures vision-language alignment in VLMs more accurately than answer-side attention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
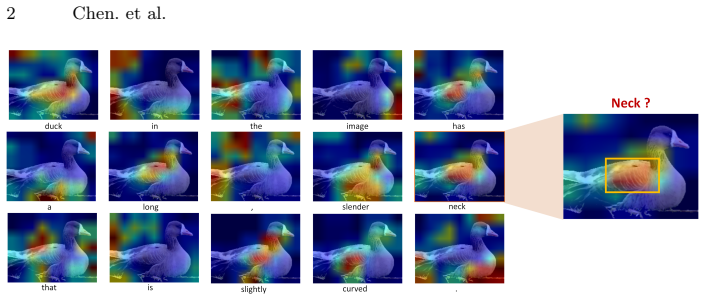
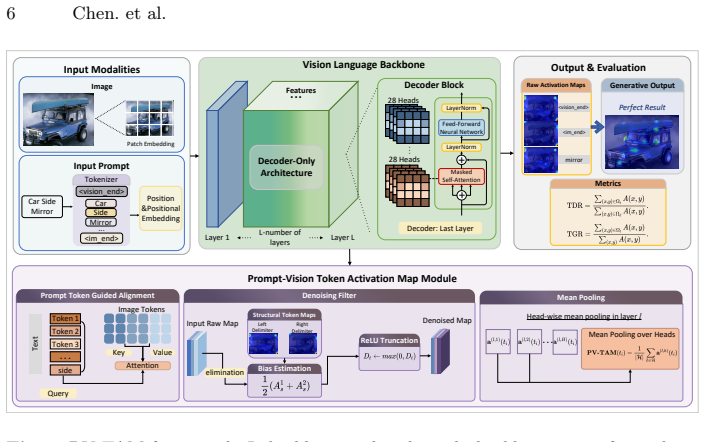
Answer-side attention distributions in VLMs suffer from decoding drift caused by previously generated tokens and from high attention on irrelevant regions induced by modality boundary markers. Prompt-Vision Token Activation Map extracts attention from prompt-side semantics, applies a filter to remove the boundary-marker bias, and evaluates alignment by the peak distribution of that attention rather than mask overlap alone, yielding consistently higher localization metrics than answer-side baselines.
What carries the argument
Prompt-Vision Token Activation Map (PV-TAM), which pulls attention weights from prompt tokens, filters modality boundary markers, and scores alignment via peak attention distribution between prompt semantics and visual regions.
If this is right
- PV-TAM raises both attention-based and IoU-style localization scores compared with answer-side baselines.
- The improvement holds across multiple vision-language datasets.
- The method supplies a consistency evaluation that avoids the accumulation of language priors during answer generation.
- Metrics that use peak attention distribution capture intensity of alignment better than overlap masks alone.
Where Pith is reading between the lines
- The same prompt-side filtering idea could be applied to other multimodal models that generate long outputs to reduce drift in their internal attention.
- PV-TAM scores might serve as an auxiliary loss during fine-tuning to encourage tighter prompt-visual coupling.
- Developers debugging VLM failures on visual questions could inspect the filtered prompt attention maps to locate where the model loses the intended region.
Load-bearing premise
Prompt-side attention after boundary-marker filtering truly sidesteps the distortions introduced by decoding drift and structural tokens.
What would settle it
A controlled test set with known ground-truth visual regions where answer-side attention metrics match human judgments of correct alignment more closely than PV-TAM metrics.
Figures

read the original abstract
Recent work typically assesses vision--language consistency using attention distributions of answer-side tokens. However, we observe that highest attention regions are not always consistent with the intended semantic token. This probably stems from decoding drift, where language priors from previously generated answer tokens accumulate and mismatch with visual attention. Besides the priors from previous answer tokens, we find that structural tokens, e.g., modality boundary markers, may encompass the entire context and generate high attention to areas unrelated to the target. To avoid these distortions and provide consistency evaluation for large VLMs, we adopt prompt-side semantics and propose Prompt-Vision Token Activation Map (PV-TAM). PV-TAM further incorporates a filter to remove systematic bias induced by modality boundary markers. Unlike traditional methods that evaluate overlap solely through masks while ignoring activation intensity, our metrics leverage the peak distribution of attention to measure the alignment between prompts and visual regions. In experiments, PV-TAM consistently improves both attention-based and IoU-style localization metrics over answer-side baselines on various datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Prompt-Vision Token Activation Map (PV-TAM) as a method to assess vision-language consistency in VLMs. It argues that answer-side token attention is distorted by decoding drift from language priors and by structural tokens such as modality boundary markers. PV-TAM instead uses filtered prompt-side token attention and defines new metrics based on peak attention distribution rather than mask overlap alone. Experiments are said to show consistent gains on both attention-based and IoU-style localization metrics over answer-side baselines across various datasets.
Significance. If the central premise holds, the work would supply a measurement procedure for VLM consistency that is free of fitted parameters and sidesteps answer-generation artifacts. This could strengthen evaluation protocols in the field. The manuscript positions the approach as an alternative procedure rather than a learned model, which is a positive feature.
major comments (2)
- [Abstract] Abstract: the claim that PV-TAM supplies a more accurate measure of vision-language consistency (rather than merely a numerically different one) rests on the premise that prompt-side attention after filtering aligns better with intended semantics; no human judgment study, downstream-task correlation, or controlled comparison against ground-truth localization masks is described to test this premise.
- [Abstract] Abstract: the reported 'consistent improvements' on attention-based and IoU-style metrics are asserted without any description of the datasets, baseline definitions, statistical tests, variance estimates, or error analysis, so the robustness of the central empirical claim cannot be assessed from the supplied evidence.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that PV-TAM supplies a more accurate measure of vision-language consistency (rather than merely a numerically different one) rests on the premise that prompt-side attention after filtering aligns better with intended semantics; no human judgment study, downstream-task correlation, or controlled comparison against ground-truth localization masks is described to test this premise.
Authors: The IoU-style metrics provide a controlled comparison against localization information, but we acknowledge that the manuscript does not include a human judgment study or downstream-task correlation to further validate the premise of improved semantic alignment. The argument for PV-TAM rests on the identified distortions in answer-side attention and the filtering mechanism. We will revise the abstract to moderate the phrasing around 'more accurate' and to clarify the role of the IoU-style evaluation. revision: partial
-
Referee: [Abstract] Abstract: the reported 'consistent improvements' on attention-based and IoU-style metrics are asserted without any description of the datasets, baseline definitions, statistical tests, variance estimates, or error analysis, so the robustness of the central empirical claim cannot be assessed from the supplied evidence.
Authors: The abstract is a concise summary; the full manuscript describes the datasets, baselines, and reports the metric results. We agree that adding statistical tests, variance estimates, and error analysis would strengthen the presentation of robustness. We will incorporate these elements in the revised manuscript and update the abstract to reference them. revision: yes
Circularity Check
No circularity; PV-TAM is an independent measurement procedure
full rationale
The paper proposes PV-TAM as a new prompt-side attention method with a modality-boundary filter to measure vision-language consistency, contrasting it with answer-side baselines. No equations, derivations, or self-citations are shown that reduce the proposed metrics or claims to quantities defined by fitted parameters from the same data, self-referential definitions, or load-bearing prior work by the authors. The method is presented as an alternative procedure whose value is evaluated empirically on datasets, without any reduction of outputs to inputs by construction. This is the common case of a self-contained methodological contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Juraf- sky, D., Chai, J., Schluter, N., Tetreault, J
Abnar, S., Zuidema, W.: Quantifying attention flow in transformers. In: Juraf- sky, D., Chai, J., Schluter, N., Tetreault, J. (eds.) Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. pp. 4190–4197. Asso- ciation for Computational Linguistics, Online (Jul 2020).https://doi.org/10. 18653/v1/2020.acl-main.385
2020
-
[2]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Agrawal, A., Batra, D., Parikh, D., Kembhavi, A.: Don’t just assume; look and answer: Overcoming priors for visual question answering. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 4971–4980 (2018)
2018
-
[3]
In: Interna- tional conference on machine learning
Ali, A., Schnake, T., Eberle, O., Montavon, G., M¨ uller, K.R., Wolf, L.: Xai for transformers: Better explanations through conservative propagation. In: Interna- tional conference on machine learning. pp. 435–451. PMLR (2022)
2022
-
[4]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
Pith/arXiv arXiv 2025
-
[5]
Advances in neural information pro- cessing systems28(2015)
Bengio, S., Vinyals, O., Jaitly, N., Shazeer, N.: Scheduled sampling for sequence prediction with recurrent neural networks. Advances in neural information pro- cessing systems28(2015)
2015
-
[6]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Chefer, H., Gur, S., Wolf, L.: Transformer interpretability beyond attention visu- alization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 782–791 (June 2021)
2021
-
[7]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, J., Wei, F., Zhao, J., Song, S., Wu, B., Peng, Z., Chan, S.H.G., Zhang, H.: Revisiting referring expression comprehension evaluation in the era of large multimodal models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 513–524 (2025)
2025
-
[8]
Chen, Y.C., Li, L., Yu, L., El Kholy, A., Ahmed, F., Gan, Z., Cheng, Y., Liu, J.: Uniter: Universal image-text representation learning. In: Computer Vision – ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXX. p. 104–120. Springer-Verlag, Berlin, Heidelberg (2020).https://doi. org/10.1007/978-3-030-58577-8_7
-
[9]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al.: Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 24185–24198 (2024)
2024
-
[10]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (October 2019)
Fong, R., Patrick, M., Vedaldi, A.: Understanding deep networks via extremal perturbations and smooth masks. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (October 2019)
2019
-
[11]
Gatis, D.: rembg: Remove image backgrounds.https://github.com/ danielgatis/rembg(2022)
2022
-
[12]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (July 2017) 16 Chen
Goyal, Y., Khot, T., Summers-Stay, D., Batra, D., Parikh, D.: Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (July 2017) 16 Chen. et al
2017
-
[13]
In: European Conference on Computer Vision
He, J., Yang, S., Yang, S., Kortylewski, A., Yuan, X., Chen, J.N., Liu, S., Yang, C., Yu, Q., Yuille, A.: Partimagenet: A large, high-quality dataset of parts. In: European Conference on Computer Vision. pp. 128–145. Springer (2022)
2022
-
[14]
In: International conference on machine learning
Jia, C., Yang, Y., Xia, Y., Chen, Y.T., Parekh, Z., Pham, H., Le, Q., Sung, Y.H., Li, Z., Duerig, T.: Scaling up visual and vision-language representation learning with noisy text supervision. In: International conference on machine learning. pp. 4904–4916. PMLR (2021)
2021
-
[15]
IEEE Transactions on Image Processing (2021)
Jiang, P.T., Zhang, C.B., Hou, Q., Cheng, M.M., Wei, Y.: Layercam: Exploring hierarchical class activation maps for localization. IEEE Transactions on Image Processing (2021)
2021
-
[16]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Kamath, A., Singh, M., LeCun, Y., Synnaeve, G., Misra, I., Carion, N.: Mdetr - modulated detection for end-to-end multi-modal understanding. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 1780– 1790 (October 2021)
2021
-
[17]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Kang, S., Kim, J., Kim, J., Hwang, S.J.: Your large vision-language model only needs a few attention heads for visual grounding. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 9339–9350 (2025)
2025
-
[18]
In: Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP)
Kazemzadeh, S., Ordonez, V., Matten, M., Berg, T.: Referitgame: Referring to objects in photographs of natural scenes. In: Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). pp. 787–798 (2014)
2014
-
[19]
Advances in Neural Information Processing Systems35, 9287–9301 (2022)
Li, C., Liu, H., Li, L., Zhang, P., Aneja, J., Yang, J., Jin, P., Hu, H., Liu, Z., Lee, Y.J., et al.: Elevater: A benchmark and toolkit for evaluating language-augmented visual models. Advances in Neural Information Processing Systems35, 9287–9301 (2022)
2022
-
[20]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Li, L.H., Zhang, P., Zhang, H., Yang, J., Li, C., Zhong, Y., Wang, L., Yuan, L., Zhang, L., Hwang, J.N., Chang, K.W., Gao, J.: Grounded language-image pre- training. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10965–10975 (June 2022)
2022
-
[21]
In: Computer Vision – ECCV 2020
Li, X., Yin, X., Li, C., Zhang, P., Hu, X., Zhang, L., Wang, L., Hu, H., Dong, L., Wei, F., Choi, Y., Gao, J.: Oscar: Object-semantics aligned pre-training for vision-language tasks. In: Computer Vision – ECCV 2020. p. 121–137. Springer International Publishing, Berlin, Heidelberg (2020).https://doi.org/10.1007/ 978-3-030-58577-8_8
2020
-
[22]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Li, Y., Wang, H., Ding, X., Wang, H., Li, X.: Token activation map to visually ex- plain multimodal llms. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 48–58 (October 2025)
2025
-
[23]
Automatica 11, 285–296 (1975)
Otsu, N.: A threshold selection method from gray-level histograms. Automatica 11, 285–296 (1975)
1975
-
[24]
In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition
Petsiuk, V., Jain, R., Manjunatha, V., Morariu, V.I., Mehra, A., Ordonez, V., Saenko, K.: Black-box explanation of object detectors via saliency maps. In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11443–11452 (2021)
2021
-
[25]
In: Proceedings of the IEEE International Conference on Computer Vision (ICCV) (December 2015)
Plummer, B.A., Wang, L., Cervantes, C.M., Caicedo, J.C., Hockenmaier, J., Lazeb- nik, S.: Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV) (December 2015)
2015
-
[26]
Pattern Recognition106, 107404 (2020) Listening makes Vision Clear for VLMs 17
Qin, X., Zhang, Z., Huang, C., Dehghan, M., Zaiane, O.R., Jagersand, M.: U 2- net: Going deeper with nested u-structure for salient object detection. Pattern Recognition106, 107404 (2020) Listening makes Vision Clear for VLMs 17
2020
-
[27]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , month =
Rohrbach, A., Hendricks, L.A., Burns, K., Darrell, T., Saenko, K.: Object hallu- cination in image captioning. In: Riloff, E., Chiang, D., Hockenmaier, J., Tsujii, J. (eds.) Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. pp. 4035–4045. Association for Computational Linguistics, Brussels, Belgium (Oct-Nov 2018).http...
-
[28]
In: Pro- ceedings of the 3rd Workshop on Neural Generation and Translation
Schmidt, F.: Generalization in generation: A closer look at exposure bias. In: Pro- ceedings of the 3rd Workshop on Neural Generation and Translation. pp. 157–167 (2019)
2019
-
[29]
In: Proceedings of the IEEE international conference on computer vision
Selvaraju, R.R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., Batra, D.: Grad- cam: Visual explanations from deep networks via gradient-based localization. In: Proceedings of the IEEE international conference on computer vision. pp. 618–626 (2017)
2017
-
[30]
In: Proceedings of the IEEE/CVF international conference on computer vision
Selvaraju, R.R., Lee, S., Shen, Y., Jin, H., Ghosh, S., Heck, L., Batra, D., Parikh, D.: Taking a hint: Leveraging explanations to make vision and language models more grounded. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 2591–2600 (2019)
2019
-
[31]
Serrano, S., Smith, N.A.: Is attention interpretable? In: Proceedings of the 57th annual meeting of the association for computational linguistics. pp. 2931–2951 (2019)
2019
-
[32]
Sharma, P., Ding, N., Goodman, S., Soricut, R.: Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 2556–2565. Association for Computational Linguistics, Melb...
-
[33]
arXiv preprint arXiv:1706.03825 (2017)
Smilkov, D., Thorat, N., Kim, B., Vi´ egas, F., Wattenberg, M.: Smoothgrad: re- moving noise by adding noise. arXiv preprint arXiv:1706.03825 (2017)
Pith/arXiv arXiv 2017
-
[34]
Advances in neural information pro- cessing systems30(2017)
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., Polosukhin, I.: Attention is all you need. Advances in neural information pro- cessing systems30(2017)
2017
-
[35]
arXiv preprint arXiv:2409.12191 (2024)
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024)
Pith/arXiv arXiv 2024
-
[36]
In: Inui, K., Jiang, J., Ng, V., Wan, X
Wiegreffe, S., Pinter, Y.: Attention is not not explanation. In: Inui, K., Jiang, J., Ng, V., Wan, X. (eds.) Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Con- ference on Natural Language Processing (EMNLP-IJCNLP). pp. 11–20. Asso- ciation for Computational Linguistics, Hong Kong, Ch...
-
[37]
In: Leibe, B., Matas, J., Sebe, N., Welling, M
Yu, L., Poirson, P., Yang, S., Berg, A.C., Berg, T.L.: Modeling context in referring expressions. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) Computer Vision – ECCV 2016. pp. 69–85. Springer International Publishing, Cham (2016)
2016
-
[38]
Advances in Neural Information Processing Systems35, 36067–36080 (2022)
Zhang, H., Zhang, P., Hu, X., Chen, Y.C., Li, L., Dai, X., Wang, L., Yuan, L., Hwang, J.N., Gao, J.: Glipv2: Unifying localization and vision-language under- standing. Advances in Neural Information Processing Systems35, 36067–36080 (2022)
2022
-
[39]
arXiv preprint arXiv:2602.13600 (2026) 18 Chen
Zhang, J., Liu, F., Du, C., Pang, T.: Adavboost: Mitigating hallucinations in lvlms via token-level adaptive visual attention boosting. arXiv preprint arXiv:2602.13600 (2026) 18 Chen. et al
Pith/arXiv arXiv 2026
-
[40]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhang, P., Li, X., Hu, X., Yang, J., Zhang, L., Wang, L., Choi, Y., Gao, J.: Vinvl: Revisiting visual representations in vision-language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5579–5588 (June 2021)
2021
-
[41]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhong, Y., Yang, J., Zhang, P., Li, C., Codella, N., Li, L.H., Zhou, L., Dai, X., Yuan, L., Li, Y., Gao, J.: Regionclip: Region-based language-image pretraining. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 16793–16803 (June 2022)
2022
-
[42]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., Torralba, A.: Learning deep fea- tures for discriminative localization. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 2921–2929 (2016)
2016
-
[43]
Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., Tian, H., Duan, Y., Su, W., Shao, J., Gao, Z., Cui, E., Wang, X., Cao, Y., Liu, Y., Wei, X., Zhang, H., Wang, H., Xu, W., Li, H., Wang, J., Deng, N., Li, S., He, Y., Jiang, T., Luo, J., Wang, Y., He, C., Shi, B., Zhang, X., Shao, W., He, J., Xiong, Y., Qu, W., Sun, P., Jiao, P., Lv, H., Wu, L., Zhang, ...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.