Enforcing Human-like Kinematics in Dexterous Piano Playing via Adversarial Posture Regularization
Pith reviewed 2026-06-26 07:48 UTC · model grok-4.3
The pith
Adversarial posture matching to casual human data produces more natural hand shapes in reinforcement-learned dexterous piano playing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
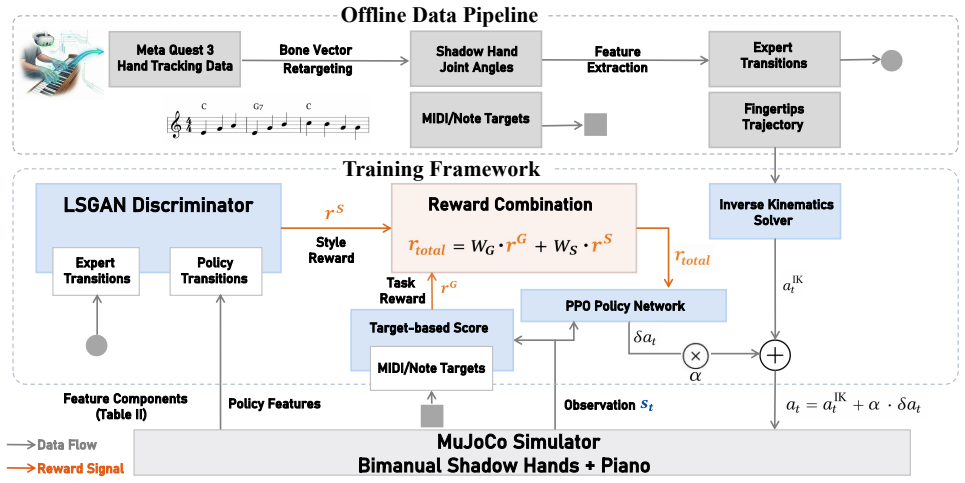
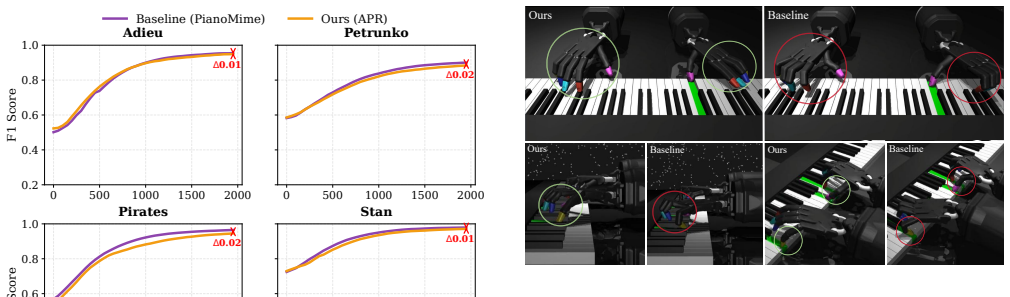
By matching the distribution of the posture of the policy with the human prior through an adversarial objective, APR encourages more human-like hand shapes. The method uses unstructured casual human playing data collected with a Meta Quest 3 and retargeted to the Shadow Hand, achieving significantly better performance than prior methods on cPSI, BSE, and FAC metrics as well as in visual quality.
What carries the argument
Adversarial Posture Regularization (APR), an adversarial objective that aligns the policy's posture distribution with a human prior extracted from casual playing data.
If this is right
- Policies trained with APR outperform baselines on all reported human-likeness metrics while retaining task performance.
- The method removes the need for expensive song-specific expert motion capture.
- Retargeted consumer-grade hand tracking data suffices as the human prior.
- Visual inspection confirms reduced overextension and more plausible finger configurations.
Where Pith is reading between the lines
- The same distributional regularization could be applied to other high-DoF dexterous tasks such as object manipulation or tool use where human kinematic priors exist but aligned demonstrations do not.
- If the human prior is biased toward casual rather than virtuoso playing, APR might trade some technical speed for natural appearance; testing on faster passages would reveal this trade-off.
- Because APR operates on posture distributions rather than per-timestep imitation, it may combine with existing task-reward or inverse-kinematics methods without requiring full trajectory matching.
Load-bearing premise
A small amount of unstructured casual human playing data, after retargeting, supplies a representative prior for human-like postures across the full range of piano configurations.
What would settle it
Train the same piano-playing policies with and without APR on a held-out set of songs, then measure whether the APR versions still exhibit statistically lower rates of joint overextension or unnatural finger spreading on those songs.
Figures


read the original abstract
Reinforcement learning can train bimanual dexterous hands to play piano in physics simulation with high note accuracy, but for high-DoF dexterous hands, relying solely on task rewards or IK inversion often leads to unnatural postures and joint overextension. We propose \textit{Adversarial Posture Regularization (APR)}. It avoids expensive, song-aligned expert demonstration data and instead uses a small amount of casual human playing data. By matching the distribution of the posture of the policy with the human prior through an adversarial objective, APR encourages more human-like hand shapes. Meanwhile, we collect and release unstructured hand motion data of piano playing using a consumer-grade Meta Quest 3, and retarget the key motion information to the Shadow Hand. Finally, we achieve significantly better performance than prior methods on all three human-likeness metrics (cPSI, BSE, and FAC) as well as in visual quality. Project repository: https://github.com/APRProject/APRPianist.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Adversarial Posture Regularization (APR) to train bimanual dexterous hands for piano playing in physics simulation. It collects a small amount of unstructured casual human playing data using a Meta Quest 3, retargets the motion to the Shadow Hand, and uses an adversarial objective to match the policy posture distribution to this human prior, thereby encouraging human-like hand shapes without requiring song-aligned expert demonstrations. The authors report significantly improved performance over prior methods on the human-likeness metrics cPSI, BSE, and FAC as well as in visual quality.
Significance. If the central claim holds, the work would be significant for dexterous manipulation because it demonstrates a practical route to kinematic regularization using limited consumer-grade unstructured data rather than expensive aligned demonstrations. The public release of the retargeted piano-playing hand motion dataset is a concrete strength that supports reproducibility and further research. The method could extend to other high-DoF tasks where natural postures matter.
major comments (2)
- [Data collection] Data collection section: the claim that the adversarial prior supplies a sufficiently dense and unbiased distribution for all task-relevant piano configurations is load-bearing. The manuscript provides no quantitative coverage analysis (joint-angle histograms, velocity profiles, or posture-space occupancy) showing that the small casual Quest-3 recordings, after retargeting, span the full DoF range and configurations required by the evaluated pieces; incomplete coverage would allow the discriminator to leave unnatural in-support modes unregularized or pull the policy toward the limited modes present in the data.
- [Experiments] Experiments section (result tables): the abstract asserts 'significantly better performance' on cPSI, BSE, and FAC, yet the manuscript must report the actual metric values, standard deviations, number of runs, and direct comparison to the strongest baselines together with note-accuracy numbers to confirm that the regularization does not trade off task performance; without these numbers the magnitude and robustness of the claimed gains cannot be assessed.
minor comments (1)
- [Abstract] Abstract: the description of the collected data would be clearer if it stated the total duration, number of subjects, and number of distinct hand configurations captured.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Data collection] Data collection section: the claim that the adversarial prior supplies a sufficiently dense and unbiased distribution for all task-relevant piano configurations is load-bearing. The manuscript provides no quantitative coverage analysis (joint-angle histograms, velocity profiles, or posture-space occupancy) showing that the small casual Quest-3 recordings, after retargeting, span the full DoF range and configurations required by the evaluated pieces; incomplete coverage would allow the discriminator to leave unnatural in-support modes unregularized or pull the policy toward the limited modes present in the data.
Authors: We agree that a quantitative coverage analysis is important to support the load-bearing claim. The current manuscript does not include such analysis. In the revised manuscript, we will add joint-angle histograms, velocity profiles, and posture-space occupancy metrics to demonstrate the coverage of the collected and retargeted data. revision: yes
-
Referee: [Experiments] Experiments section (result tables): the abstract asserts 'significantly better performance' on cPSI, BSE, and FAC, yet the manuscript must report the actual metric values, standard deviations, number of runs, and direct comparison to the strongest baselines together with note-accuracy numbers to confirm that the regularization does not trade off task performance; without these numbers the magnitude and robustness of the claimed gains cannot be assessed.
Authors: We acknowledge that detailed statistical reporting is required for assessing the results. We will revise the experiments section to include the actual metric values with standard deviations, specify the number of runs, provide direct comparisons to the strongest baselines, and report note-accuracy numbers to show that task performance is not traded off. revision: yes
Circularity Check
No significant circularity; method applies standard adversarial matching to external human data
full rationale
The paper's central approach uses a small set of unstructured casual human playing data (collected via Meta Quest 3 and retargeted) as an independent prior. An adversarial objective then matches the policy posture distribution to this prior. No equations, derivations, or self-citations are shown that reduce the claimed improvements on cPSI, BSE, or FAC metrics to a quantity defined by the method itself or to a fitted input renamed as prediction. The human data and evaluation metrics are external to the regularization step, so the derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Reinforcement learning policies trained with task rewards alone produce unnatural postures for high-DoF hands.
- domain assumption Casual human playing data collected with consumer hardware can serve as a usable prior for human-like hand shapes after retargeting.
Reference graph
Works this paper leans on
-
[1]
Cooperative dual-arm control for heavy object manipulation based on hierarchical quadratic pro- gramming,
M. Dio, A. V ¨olz, and K. Graichen, “Cooperative dual-arm control for heavy object manipulation based on hierarchical quadratic pro- gramming,” in2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023, pp. 643–648
2023
-
[2]
Speedfolding: Learning efficient bimanual folding of garments,
Y . Avigal, L. Berscheid, T. Asfour, T. Kr ¨oger, and K. Goldberg, “Speedfolding: Learning efficient bimanual folding of garments,” in 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2022, pp. 1–8
2022
-
[3]
Robopianist: Dexterous piano playing with deep reinforcement learning,
K. Zakka, P. Wu, L. Smith, N. Gileadi, T. Howell, X. B. Peng, S. Singh, Y . Tassa, P. Florence, A. Zenget al., “Robopianist: Dexterous piano playing with deep reinforcement learning,” inConference on Robot Learning. PMLR, 2023, pp. 2975–2994
2023
-
[4]
Mujoco: A physics engine for model-based control,
E. Todorov, T. Erez, and Y . Tassa, “Mujoco: A physics engine for model-based control,” in2012 IEEE/RSJ international conference on intelligent robots and systems. IEEE, 2012, pp. 5026–5033
2012
-
[5]
Defining and characterizing reward gaming,
J. Skalse, N. Howe, D. Krasheninnikov, and D. Krueger, “Defining and characterizing reward gaming,”Advances in Neural Information Processing Systems, vol. 35, pp. 9460–9471, 2022
2022
-
[6]
Pink: Python inverse kinematics based on pinocchio,
S. Caron, Y . de Mont-Marin, R. Budhiraja, and S. H. Bang, “Pink: Python inverse kinematics based on pinocchio,” https://github.com/ stephane-caron/pink, 2024, gitHub repository, accessed 2026-03-01
2024
-
[7]
Pianomime: Learning a generalist, dexterous piano player from internet demonstrations,
C. Qian, J. Urain, K. Zakka, and J. Peters, “Pianomime: Learning a generalist, dexterous piano player from internet demonstrations,” in Conference on Robot Learning. PMLR, 2025, pp. 1194–1215
2025
-
[8]
Mediapipe hands: On-device real-time hand tracking,
F. Zhang, V . Bazarevsky, A. Vakunov, A. Tkachenka, G. Sung, C.-L. Chang, and M. Grundmann, “Mediapipe hands: On-device real-time hand tracking,”arXiv preprint arXiv:2006.10214, 2020
-
[9]
Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations
A. Rajeswaran, V . Kumar, A. Gupta, G. Vezzani, J. Schulman, E. Todorov, and S. Levine, “Learning complex dexterous manipulation with deep reinforcement learning and demonstrations,”arXiv preprint arXiv:1709.10087, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[10]
Non-parametric self-identification and model predictive control of dexterous in-hand manipulation,
P. Chanrungmaneekul, K. Ren, J. T. Grace, A. M. Dollar, and K. Hang, “Non-parametric self-identification and model predictive control of dexterous in-hand manipulation,” in2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023, pp. 8743–8750
2023
-
[11]
Contact-implicit trajectory optimization for dynamic object manipula- tion,
J.-P. Sleiman, J. Carius, R. Grandia, M. Wermelinger, and M. Hutter, “Contact-implicit trajectory optimization for dynamic object manipula- tion,” in2019 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, 2019, pp. 6814–6821
2019
-
[12]
Learning dexterous in-hand manipulation,
O. M. Andrychowicz, B. Baker, M. Chociej, R. Jozefowicz, B. Mc- Grew, J. Pachocki, A. Petron, M. Plappert, G. Powell, A. Rayet al., “Learning dexterous in-hand manipulation,”The International Journal of Robotics Research, vol. 39, no. 1, pp. 3–20, 2020
2020
-
[13]
T. Silver, K. Allen, J. Tenenbaum, and L. Kaelbling, “Residual policy learning,”arXiv preprint arXiv:1812.06298, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
Residual Reinforcement Learning for Robot Control
T. Johannink, S. Bahl, A. Nair, J. Luo, A. Kumar, M. Loskyll, J. A. Ojea, E. Solowjow, and S. Levine, “Residual reinforcement learning for robot control,”arXiv preprint arXiv:1812.03201, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[15]
Rp1m: A large-scale motion dataset for piano playing with bi-manual dexterous robot hands,
Y . Zhao, L. Chen, J. Schneider, Q. Gao, J. Kannala, B. Sch ¨olkopf, J. Pajarinen, and D. B ¨uchler, “Rp1m: A large-scale motion dataset for piano playing with bi-manual dexterous robot hands,”arXiv preprint arXiv:2408.11048, 2024
-
[16]
Dexterous robotic piano playing at scale,
L. Chen, Y . Zhao, J. Schneider, Q. Gao, S. Guist, C. Qian, J. Kannala, B. Sch ¨olkopf, J. Pajarinen, and D. B ¨uchler, “Dexterous robotic piano playing at scale,”arXiv preprint arXiv:2511.02504, 2025
-
[17]
Pandora: Diffusion policy learning for dexterous robotic piano playing,
Y . Huang, R. Li, and Z. Tu, “Pandora: Diffusion policy learning for dexterous robotic piano playing,”arXiv preprint arXiv:2503.14545, 2025
-
[18]
Hand gesture teleoperation for dexterous manipulators in space station by using monocular hand motion capture,
Q. Gao, J. Li, Y . Zhu, S. Wang, J. Liufu, and J. Liu, “Hand gesture teleoperation for dexterous manipulators in space station by using monocular hand motion capture,”Acta astronautica, vol. 204, pp. 630– 639, 2023
2023
-
[19]
A large calibrated database of hand movements and grasps kinematics,
N. J. Jarque-Bou, M. Atzori, and H. M ¨uller, “A large calibrated database of hand movements and grasps kinematics,”Scientific data, vol. 7, no. 1, p. 12, 2020
2020
-
[20]
Openvr: Teleoperation for manipulation,
A. George, A. Bartsch, and A. B. Farimani, “Openvr: Teleoperation for manipulation,”SoftwareX, vol. 29, p. 102054, 2025
2025
-
[21]
Generative adversarial imitation learning,
J. Ho and S. Ermon, “Generative adversarial imitation learning,” Advances in neural information processing systems, vol. 29, 2016
2016
-
[22]
Amp: Adversarial motion priors for stylized physics-based character con- trol,
X. B. Peng, Z. Ma, P. Abbeel, S. Levine, and A. Kanazawa, “Amp: Adversarial motion priors for stylized physics-based character con- trol,”ACM Transactions on Graphics (ToG), vol. 40, no. 4, pp. 1–20, 2021
2021
-
[23]
Ase: Large- scale reusable adversarial skill embeddings for physically simulated characters,
X. B. Peng, Y . Guo, L. Halper, S. Levine, and S. Fidler, “Ase: Large- scale reusable adversarial skill embeddings for physically simulated characters,”ACM Transactions On Graphics (TOG), vol. 41, no. 4, pp. 1–17, 2022
2022
-
[24]
Learning agile robotic locomotion skills by imitating animals. arxiv 2020,
X. B. Peng, E. Coumans, T. Zhang, T.-W. Lee, J. Tan, and S. Levine, “Learning agile robotic locomotion skills by imitating animals,”arXiv preprint arXiv:2004.00784, 2020
-
[25]
Least squares generative adversarial networks,
X. Mao, Q. Li, H. Xie, R. Y . Lau, Z. Wang, and S. Paul Smolley, “Least squares generative adversarial networks,” inProceedings of the IEEE international conference on computer vision, 2017, pp. 2794–2802
2017
-
[26]
Physics-based dex- terous manipulations with estimated hand poses and residual rein- forcement learning,
G. Garcia-Hernando, E. Johns, and T.-K. Kim, “Physics-based dex- terous manipulations with estimated hand poses and residual rein- forcement learning,” in2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 9561–9568
2020
-
[27]
Generative adversarial nets,
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial nets,” Advances in neural information processing systems, vol. 27, 2014
2014
-
[28]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
Deepmimic: Example-guided deep reinforcement learning of physics-based char- acter skills,
X. B. Peng, P. Abbeel, S. Levine, and M. Van de Panne, “Deepmimic: Example-guided deep reinforcement learning of physics-based char- acter skills,”ACM Transactions On Graphics (TOG), vol. 37, no. 4, pp. 1–14, 2018
2018
-
[30]
Human hand posture reconstruction for a visual control of an anthropomorphic robotic hand,
I. Infantino, “Human hand posture reconstruction for a visual control of an anthropomorphic robotic hand,” 2003
2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.