Catastrophic Compositional Generation: Why Vanilla Diffusion Models Fail to Extrapolate
Pith reviewed 2026-06-26 08:34 UTC · model grok-4.3
The pith
Vanilla diffusion models fail to generate from out-of-distribution compositional targets even with inference corrections.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
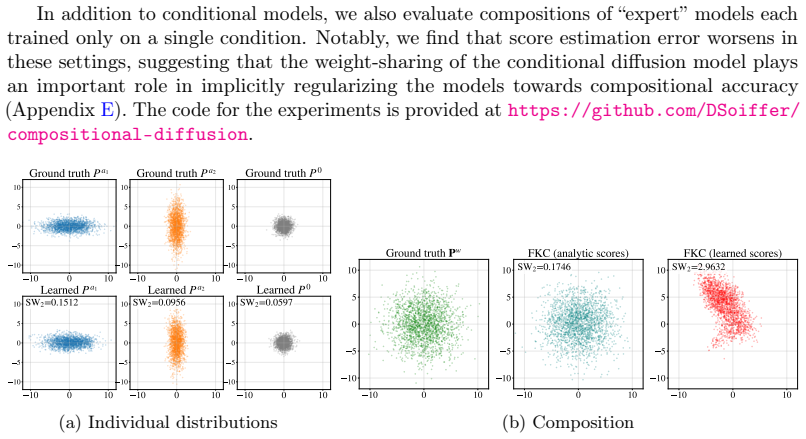
The authors conjecture that no inference-time technique can efficiently produce samples from the target distribution in certain well-motivated settings for compositional generation with vanilla conditional diffusion models. This is because when the target distribution is out-of-distribution with respect to the sources, score estimation error dominates and leads to catastrophic failure, whereas methods like Feynman-Kac correction can address approximation error but not this more fundamental issue.
What carries the argument
The comparison between score estimation error and inference-time approximation error in the context of out-of-distribution compositional targets for conditional diffusion models.
If this is right
- Recent inference-time methods cannot overcome the failure for OOD targets.
- Score estimation error is the primary barrier to successful extrapolation.
- A different approach to compositional generation is required.
- The failure is observed in both synthetic and realistic data experiments.
Where Pith is reading between the lines
- Diffusion models may need modifications to their training to better estimate scores for potential compositions.
- This issue could extend to other conditional generative models facing similar extrapolation demands.
- Researchers might investigate hybrid methods that combine diffusion with other techniques to mitigate the error.
Load-bearing premise
The assumption that the target distribution is out-of-distribution with respect to the sources in a manner that makes score estimation error dominate the approximation error.
What would settle it
Finding or constructing an inference-time technique that efficiently generates accurate samples from the compositional target using a vanilla model trained only on the source conditions would falsify the main conjecture.
Figures


read the original abstract
The task of compositional generation involves using a conditional generative model, trained only on a subset of the possible conditions, to produce samples from compositionally-defined target distributions such as a geometric combination of the source distributions. In this work, we argue that this task is often infeasible for vanilla conditional diffusion models: we conjecture that no inference-time technique can efficiently produce samples from the target distribution in certain well-motivated settings. This idea is supported by theory-guided generalization arguments and carefully-designed experiments on both synthetic and realistic data. In particular, while recent methods such as Feynman-Kac correction reduce inference-time approximation error, our results show that score estimation error has a more catastrophic effect on performance when the target distribution is out-of-distribution with respect to the sources, highlighting the need for a different approach to this task.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
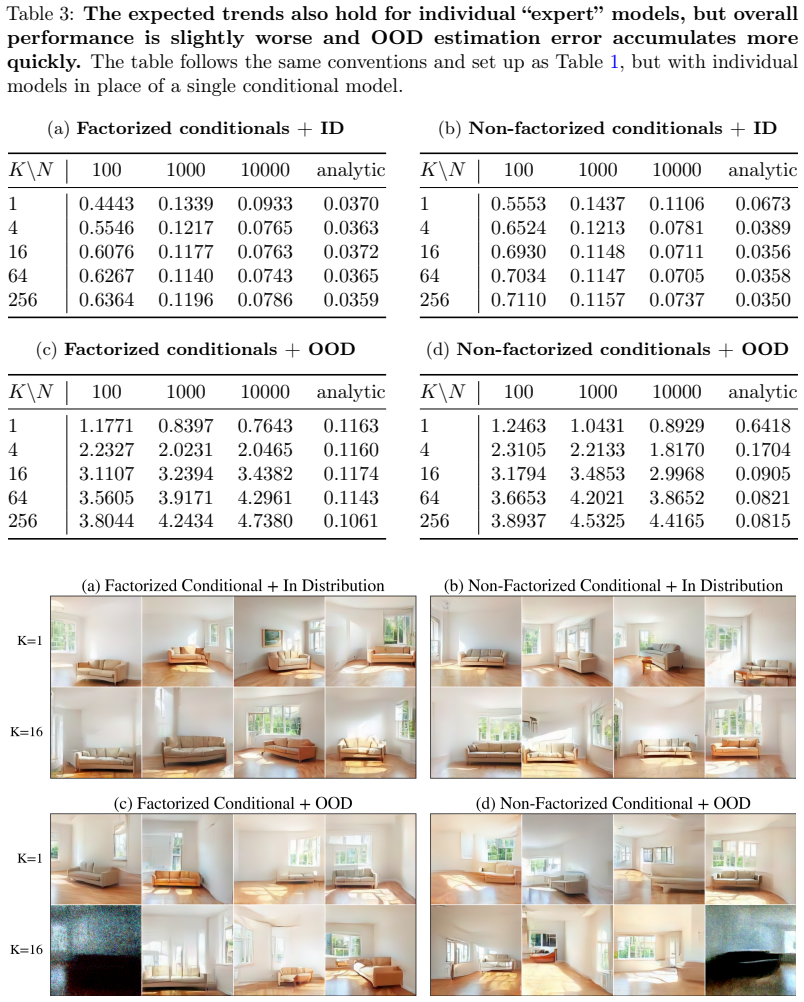
Summary. The paper claims that compositional generation with vanilla conditional diffusion models is often infeasible for out-of-distribution targets: no inference-time technique can efficiently sample from the target distribution in certain well-motivated settings. This is supported by theory-guided generalization arguments showing that score estimation error dominates approximation error, together with experiments on synthetic and realistic data demonstrating catastrophic performance degradation when the target lies outside the convex hull of the training conditions.
Significance. If the central conjecture holds, the work identifies a fundamental limitation of score-based models under compositional extrapolation, with direct implications for applications that require combining learned factors in novel ways. The distinction between score-estimation and inference-time approximation errors, together with the use of both synthetic controls and realistic datasets, supplies a concrete diagnostic that future methods must address.
major comments (3)
- [§3.2] §3.2, generalization argument: the claim that score estimation error produces catastrophic failure rests on an informal extrapolation of the score mismatch outside the training support, but no explicit bound (e.g., on total variation or Wasserstein distance) is derived that quantifies when this error necessarily overwhelms any polynomial-time inference correction.
- [§4.3] §4.3, realistic-data experiments: the reported performance gap between in-distribution and compositional targets is large, yet the manuscript does not report the magnitude of the score-estimation error (e.g., via held-out score matching loss on the target) separately from the sampling procedure, making it impossible to confirm that score error, rather than other implementation factors, is the dominant cause.
- [Abstract and §5] Abstract and §5: the conjecture that 'no inference-time technique' can succeed is supported only by experiments on a small set of existing correctors (including Feynman-Kac); a general impossibility argument or a broader set of baselines would be required to substantiate the universal claim.
minor comments (2)
- [§2] Notation for the compositional operator (geometric combination) is introduced without an explicit equation reference in the early sections; adding a numbered definition would improve readability.
- [Figure 3] Figure 3 caption does not state the number of random seeds or the precise OOD exclusion rule used to generate the target distribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify the scope of our theoretical claims, the isolation of error sources in experiments, and the evidential basis for our conjecture. We address each major comment below.
read point-by-point responses
-
Referee: [§3.2] §3.2, generalization argument: the claim that score estimation error produces catastrophic failure rests on an informal extrapolation of the score mismatch outside the training support, but no explicit bound (e.g., on total variation or Wasserstein distance) is derived that quantifies when this error necessarily overwhelms any polynomial-time inference correction.
Authors: We agree that the argument in §3.2 relies on an informal extrapolation of score mismatch behavior outside the training support rather than a derived explicit bound on distances such as total variation or Wasserstein. The section uses theory-guided intuition from score-matching generalization but stops short of a quantitative result showing dominance over any polynomial-time correction. In revision we will explicitly label the argument as heuristic and add a brief discussion of why obtaining such bounds remains challenging for out-of-distribution targets. revision: yes
-
Referee: [§4.3] §4.3, realistic-data experiments: the reported performance gap between in-distribution and compositional targets is large, yet the manuscript does not report the magnitude of the score-estimation error (e.g., via held-out score matching loss on the target) separately from the sampling procedure, making it impossible to confirm that score error, rather than other implementation factors, is the dominant cause.
Authors: The observation is correct: §4.3 reports end-to-end sampling degradation but does not separately tabulate held-out score-matching loss on the compositional targets. We will add this diagnostic in the revision (computing the loss on held-out OOD conditions where the model architecture permits direct evaluation) to more cleanly separate score-estimation error from inference-time effects. revision: yes
-
Referee: [Abstract and §5] Abstract and §5: the conjecture that 'no inference-time technique' can succeed is supported only by experiments on a small set of existing correctors (including Feynman-Kac); a general impossibility argument or a broader set of baselines would be required to substantiate the universal claim.
Authors: The conjecture is framed as such in the manuscript and rests on the combination of the score-error dominance argument plus empirical failure of the tested correctors. We do not supply a general impossibility theorem, which would require a substantially different proof strategy. In revision we will expand the set of inference-time baselines evaluated and adjust the abstract and §5 wording to read “existing inference-time techniques” while retaining the conjecture language, thereby aligning the claim more precisely with the evidence presented. revision: partial
Circularity Check
No circularity: claims rest on external generalization arguments and experiments
full rationale
The paper advances a conjecture that vanilla conditional diffusion models cannot efficiently sample from certain compositional OOD targets, supported by theory-guided generalization arguments plus experiments on synthetic and realistic data. No derivation reduces a claimed prediction to a fitted parameter by construction, no self-citation is invoked as a uniqueness theorem, and no ansatz is smuggled via prior work. The distinction between score estimation error and inference-time approximation error is presented as an empirical observation rather than a definitional identity. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Under submission to AISTATS 2026 , year=
A unifying framework for unsupervised concept extraction , author=. Under submission to AISTATS 2026 , year=
2026
-
[2]
International Conference on Machine Learning , year=
On linear identifiability of learned representations , author=. International Conference on Machine Learning , year=
-
[3]
Nonlinear
Hyvarinen, Aapo and Sasaki, Hiroaki and Turner, Richard , booktitle=. Nonlinear
-
[4]
Advances in Neural Information Processing Systems , year=
Linear causal representation learning from unknown multi-node interventions , author=. Advances in Neural Information Processing Systems , year=
-
[5]
Advances in Neural Information Processing Systems , year=
Concept algebra for (score-based) text-controlled generative models , author=. Advances in Neural Information Processing Systems , year=
-
[6]
arXiv preprint arXiv:2006.07691 , year=
Synthetic interventions , author=. arXiv preprint arXiv:2006.07691 , year=
arXiv 2006
-
[7]
Conference on Causal Learning and Reasoning , year=
Causal imputation via synthetic interventions , author=. Conference on Causal Learning and Reasoning , year=
-
[8]
International Conference on Machine Learning , pages=
A kernelized Stein discrepancy for goodness-of-fit tests , author=. International Conference on Machine Learning , pages=. 2016 , organization=
2016
-
[9]
Forty-second International Conference on Machine Learning , year=
Mechanisms of Projective Composition of Diffusion Models , author=. Forty-second International Conference on Machine Learning , year=
-
[10]
International Conference on Machine Learning , pages=
Linear causal disentanglement via interventions , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[11]
Boffi and Eric Vanden-Eijnden , title =
Michael Albergo and Nicholas M. Boffi and Eric Vanden-Eijnden , title =. Journal of Machine Learning Research , year =
-
[12]
arXiv preprint arXiv:2011.13456 , year=
Score-based generative modeling through stochastic differential equations , author=. arXiv preprint arXiv:2011.13456 , year=
Pith/arXiv arXiv 2011
-
[13]
Advances In Neural Information Processing Systems , volume=
Elucidating the design space of diffusion-based generative models , author=. Advances In Neural Information Processing Systems , volume=
-
[14]
arXiv preprint arXiv:2305.16860 , year=
Error bounds for flow matching methods , author=. arXiv preprint arXiv:2305.16860 , year=
-
[15]
International Conference on Machine Learning , pages=
Improved analysis of score-based generative modeling: User-friendly bounds under minimal smoothness assumptions , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[16]
Advances in Neural Information Processing Systems , volume=
Learning mixtures of gaussians using the ddpm objective , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
arXiv preprint arXiv:2401.17958 , year=
Convergence analysis for general probability flow odes of diffusion models in wasserstein distances , author=. arXiv preprint arXiv:2401.17958 , year=
-
[18]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Unraveling the smoothness properties of diffusion models: A gaussian mixture perspective , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[19]
International Conference on Machine Learning , pages=
Reduce, reuse, recycle: Compositional generation with energy-based diffusion models and mcmc , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[20]
arXiv preprint arXiv:2505.13740 , year=
Improving compositional generation with diffusion models using lift scores , author=. arXiv preprint arXiv:2505.13740 , year=
-
[21]
European Conference on Computer Vision , pages=
Compositional visual generation with composable diffusion models , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[22]
Advances in Neural Information Processing Systems , volume=
Conceptmix: A compositional image generation benchmark with controllable difficulty , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
arXiv preprint arXiv:2504.18522 , year=
Representation learning for distributional perturbation extrapolation , author=. arXiv preprint arXiv:2504.18522 , year=
-
[24]
The Superposition of Diffusion Models Using the It \^
Skreta, Marta and Atanackovic, Lazar and Bose, Avishek Joey and Tong, Alexander and Neklyudov, Kirill , journal=. The Superposition of Diffusion Models Using the It \^
-
[25]
Forty-second International Conference on Machine Learning , year=
Feynman-Kac Correctors in Diffusion: Annealing, Guidance, and Product of Experts , author=. Forty-second International Conference on Machine Learning , year=
-
[26]
The Fourteenth International Conference on Learning Representations , year=
DriftLite: Lightweight Drift Control for Inference-Time Scaling of Diffusion Models , author=. The Fourteenth International Conference on Learning Representations , year=
-
[27]
ICML 2026 Workshop on Structured Probabilistic Inference
Enhanced Diffusion Sampling: Efficient Rare Event Sampling and Free Energy Calculation with Diffusion Models , author=. ICML 2026 Workshop on Structured Probabilistic Inference
2026
-
[28]
arXiv preprint arXiv:2602.24201 , year=
Flow-Based Density Ratio Estimation for Intractable Distributions with Applications in Genomics , author=. arXiv preprint arXiv:2602.24201 , year=
-
[29]
International Conference on Artificial Intelligence and Statistics , pages=
General identifiability and achievability for causal representation learning , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2024 , organization=
2024
-
[30]
Journal of Machine Learning Research , volume=
Score-based causal representation learning: Linear and general transformations , author=. Journal of Machine Learning Research , volume=
-
[31]
Advances in Neural Information Processing Systems , volume=
Identifiability guarantees for causal disentanglement from soft interventions , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
Advances in Neural Information Processing Systems , volume=
Learning linear causal representations from interventions under general nonlinear mixing , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
International Conference on Machine Learning , pages=
Interventional causal representation learning , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[34]
Neurosymbolic AI: Foundations and Applications , pages=
Causal Representation Learning , author=. Neurosymbolic AI: Foundations and Applications , pages=. 2026 , publisher=
2026
-
[35]
DAGM German Conference on Pattern Recognition , pages=
Learning robust models using the principle of independent causal mechanisms , author=. DAGM German Conference on Pattern Recognition , pages=. 2021 , organization=
2021
-
[36]
International Conference on Learning Representations , year=
Score-Based Generative Modeling through Stochastic Differential Equations , author=. International Conference on Learning Representations , year=
-
[37]
NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications , year=
Classifier-Free Diffusion Guidance , author=. NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications , year=
2021
-
[38]
arXiv preprint arXiv:2207.12598 , year=
Classifier-free diffusion guidance , author=. arXiv preprint arXiv:2207.12598 , year=
-
[39]
and Cappe, O
Douc, R. and Cappe, O. , booktitle=. Comparison of resampling schemes for particle filtering , year=
-
[40]
Applied Stochastic Differential Equations , publisher=
Särkkä, Simo and Solin, Arno , year=. Applied Stochastic Differential Equations , publisher=
-
[41]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Clevr: A diagnostic dataset for compositional language and elementary visual reasoning , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[42]
Advances in Neural Information Processing Systems , volume=
Diffusion models beat gans on image synthesis , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
arXiv preprint arXiv:1412.6980 , year=
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
-
[44]
POT Python Optimal Transport (version 0.9.5) , url =
Flamary, R. POT Python Optimal Transport (version 0.9.5) , url =
-
[45]
POT: Python Optimal Transport , journal =
R. POT: Python Optimal Transport , journal =. 2021 , volume =
2021
-
[46]
Denoising Diffusion Probabilistic Models , volume =
Ho, Jonathan and Jain, Ajay and Abbeel, Pieter , booktitle =. Denoising Diffusion Probabilistic Models , volume =
-
[47]
Nature Biotechnology , year =
TxPert: using multiple knowledge graphs for prediction of transcriptomic perturbation effects , author =. Nature Biotechnology , year =
-
[48]
bioRxiv , year =
Modeling and predicting single-cell multi-gene perturbation responses with scLAMBDA , author =. bioRxiv , year =
-
[49]
Nature Biotechnology , volume =
Predicting transcriptional outcomes of novel multigene perturbations with GEARS , author =. Nature Biotechnology , volume =
-
[50]
and Califano, Andrea and Cool, Jonah and Dernburg, Abby F
Bunne, Charlotte and Roohani, Yusuf and Rosen, Yanay and Gupta, Ankit and Zhang, Xikun and Roed, Marcel and Alexandrov, Theo and AlQuraishi, Mohammed and Brennan, Patricia and Burkhardt, Daniel B. and Califano, Andrea and Cool, Jonah and Dernburg, Abby F. and Ewing, Kirsty and Fox, Emily B. and Haury, Matthias and Herr, Amy E. and Horvitz, Eric and Hsu, P...
-
[51]
arXiv preprint arXiv:2505.14613 , year =
Virtual Cells: Predict, Explain, Discover , author =. arXiv preprint arXiv:2505.14613 , year =
-
[52]
Nature Methods , volume =
scGen predicts single-cell perturbation responses , author =. Nature Methods , volume =
-
[53]
Molecular Systems Biology , volume =
Predicting cellular responses to complex perturbations in high-throughput screens , author =. Molecular Systems Biology , volume =
-
[54]
Nature Methods , volume =
Learning single-cell perturbation responses using neural optimal transport , author =. Nature Methods , volume =
-
[55]
Advances in Neural Information Processing Systems , year =
Predicting Cellular Responses to Novel Drug Perturbations at a Single-Cell Resolution , author =. Advances in Neural Information Processing Systems , year =. 2204.13545 , archivePrefix =
-
[56]
Perez, Ethan and Strub, Florian and de Vries, Harm and Dumoulin, Vincent and Courville, Aaron , title =. Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence , articleno =. 2018 , isbn =
2018
-
[57]
Journal of Machine Learning Research , volume =
Estimation of Non-Normalized Statistical Models by Score Matching , author =. Journal of Machine Learning Research , volume =
-
[58]
Neural Computation , volume =
A Connection Between Score Matching and Denoising Autoencoders , author =. Neural Computation , volume =
-
[59]
Nature Communications , year =
Predicting transcriptional responses to novel chemical perturbations using deep generative learning , author =. Nature Communications , year =
-
[60]
2024 , eprint=
Automated Discovery of Pairwise Interactions from Unstructured Data , author=. 2024 , eprint=
2024
-
[61]
NeurIPS 2025 2nd Workshop on Multi-modal Foundation Models and Large Language Models for Life Sciences , year=
Predicting cellular responses to perturbation across diverse contexts with State , author=. NeurIPS 2025 2nd Workshop on Multi-modal Foundation Models and Large Language Models for Life Sciences , year=
2025
-
[62]
Nature Methods , volume =
Deep-learning-based gene perturbation effect prediction does not yet outperform simple linear baselines , author =. Nature Methods , volume =
-
[63]
Bioinformatics , volume =
Simple controls exceed best deep learning algorithms and reveal foundation model effectiveness for predicting genetic perturbations , author =. Bioinformatics , volume =
-
[64]
2025 , eprint=
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space , author=. 2025 , eprint=
2025
-
[65]
2024 , howpublished=
Black Forest Labs , title=. 2024 , howpublished=
2024
-
[66]
GitHub repository , howpublished =
Patrick von Platen and Suraj Patil and Anton Lozhkov and Pedro Cuenca and Nathan Lambert and Kashif Rasul and Mishig Davaadorj and Dhruv Nair and Sayak Paul and William Berman and Yiyi Xu and Steven Liu and Thomas Wolf , title =. GitHub repository , howpublished =. 2022 , publisher =
2022
-
[67]
Transactions on Machine Learning Research , issn=
Maxime Oquab and Timoth. Transactions on Machine Learning Research , issn=. 2024 , note=
2024
-
[68]
International Conference on Medical image computing and computer-assisted intervention , pages=
U-net: Convolutional networks for biomedical image segmentation , author=. International Conference on Medical image computing and computer-assisted intervention , pages=. 2015 , organization=
2015
-
[69]
International Conference on Machine Learning , pages=
Improved denoising diffusion probabilistic models , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[70]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Common diffusion noise schedules and sample steps are flawed , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[71]
International Conference on Learning Representations , year=
Progressive Distillation for Fast Sampling of Diffusion Models , author=. International Conference on Learning Representations , year=
-
[72]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[73]
The Eleventh International Conference on Learning Representations , year=
Building Normalizing Flows with Stochastic Interpolants , author=. The Eleventh International Conference on Learning Representations , year=
-
[74]
The Eleventh International Conference on Learning Representations , year=
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow , author=. The Eleventh International Conference on Learning Representations , year=
-
[75]
The Eleventh International Conference on Learning Representations , year=
Flow Matching for Generative Modeling , author=. The Eleventh International Conference on Learning Representations , year=
-
[76]
Proceedings of the IEEE , volume=
Toward causal representation learning , author=. Proceedings of the IEEE , volume=. 2021 , publisher=
2021
-
[77]
2017 , publisher=
Elements of causal inference: foundations and learning algorithms , author=. 2017 , publisher=
2017
-
[78]
Foundations of Computational Mathematics , volume=
Causal structure learning: A combinatorial perspective , author=. Foundations of Computational Mathematics , volume=. 2023 , publisher=
2023
-
[79]
arXiv preprint arXiv:2002.00107 , year=
Generative modeling with denoising auto-encoders and langevin sampling , author=. arXiv preprint arXiv:2002.00107 , year=
arXiv 2002
-
[80]
Advances in Neural Information Processing Systems , volume=
Slotdiffusion: Object-centric generative modeling with diffusion models , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.