CORE-BREW: LLR-Based Soft Decoding for Robust Multi-Bit LLM Watermarking
Pith reviewed 2026-06-25 23:41 UTC · model grok-4.3
The pith
CORE-BREW derives closed-form per-token LLRs for soft-decision decoding in multi-bit LLM watermarks by targeting a fixed hit rate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
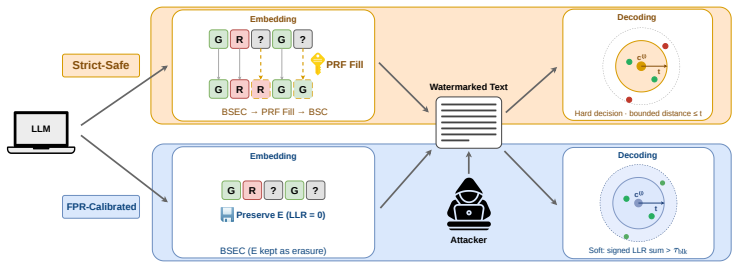
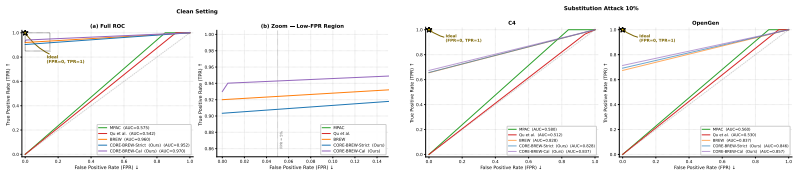
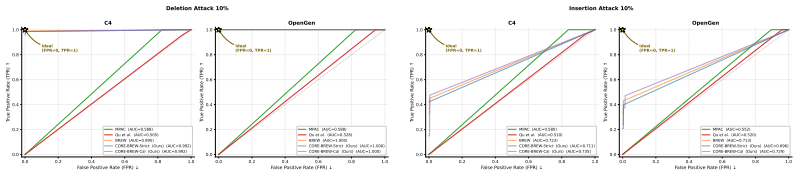
CORE-BREW calibrates the watermark channel by targeting a fixed hit rate p-star, yielding closed-form per-token log-likelihood ratios for principled soft-decision decoding. It supports Strict-Safe mode, which preserves the bounded-distance designated-codeword acceptance region, and FPR-Calibrated mode, which uses likelihood-based scoring together with lightweight list decoding. Experiments on open-source LLMs under token-level edits and paraphrasing show improved low-FPR discrimination and robustness over prior multi-bit watermarking baselines while maintaining comparable semantic quality.
What carries the argument
Constant-hit-rate embedding that produces per-token LLRs for soft decoding of the watermark.
If this is right
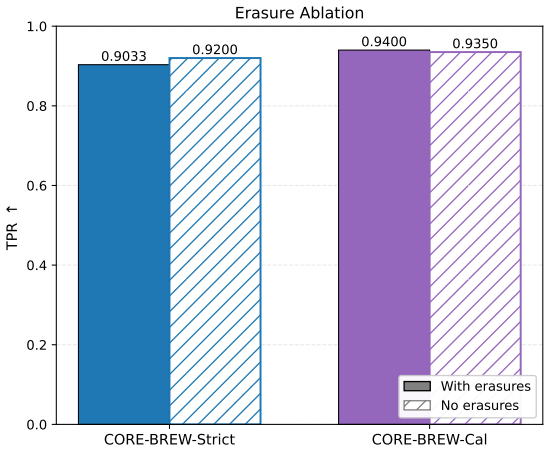
- Token reliability information can be retained and used rather than thrown away by hard decisions.
- Strict-Safe mode keeps the original acceptance region while FPR-Calibrated mode trades off detection thresholds explicitly.
- Low false-positive performance improves under both local edits and global paraphrasing.
- Semantic quality of the watermarked text stays comparable to unwatermarked baselines.
Where Pith is reading between the lines
- The same fixed-hit-rate calibration step could be applied to other embedding families to obtain analogous LLR expressions.
- Standard soft-decision algorithms from communication theory become directly usable once the LLRs are available.
- List decoding in the FPR-Calibrated mode opens a path to message-length scaling without exponential growth in search cost.
Load-bearing premise
A fixed target hit rate p-star produces accurate closed-form LLRs that remain reliable under token-level edits and paraphrasing without further adjustments.
What would settle it
A test in which the measured hit rate after paraphrasing deviates enough from p-star that the LLR decoder no longer outperforms hard-decision baselines at the target false-positive rate.
Figures

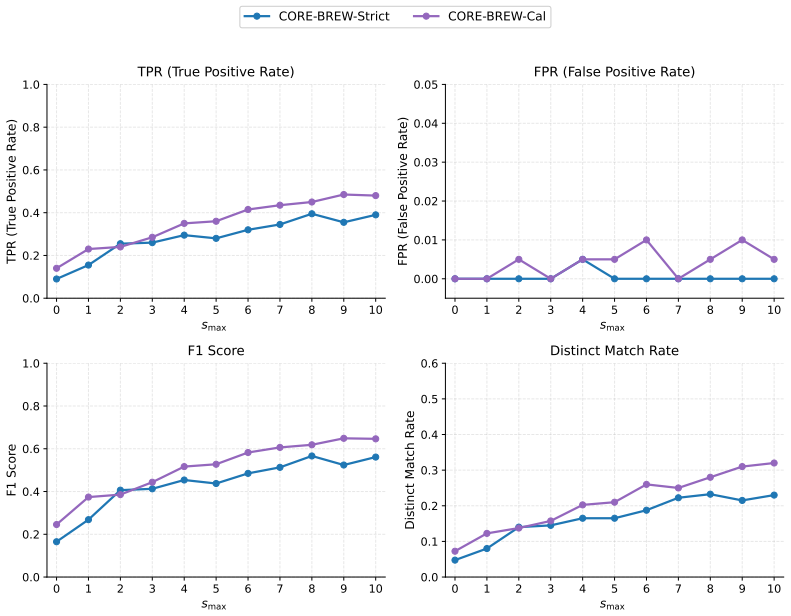
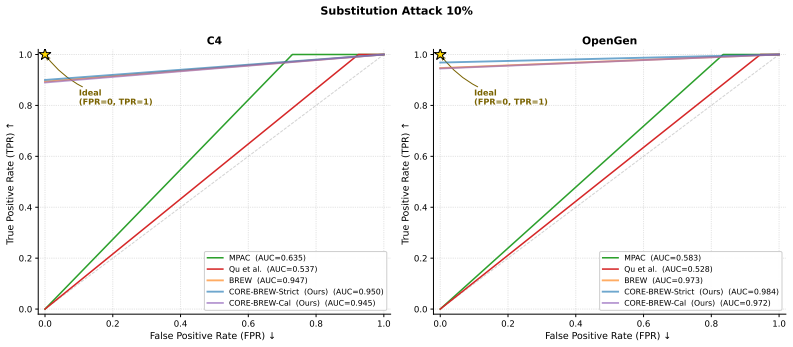
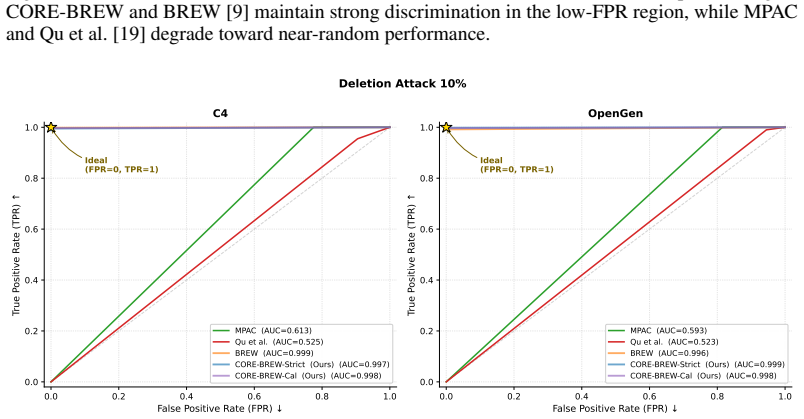
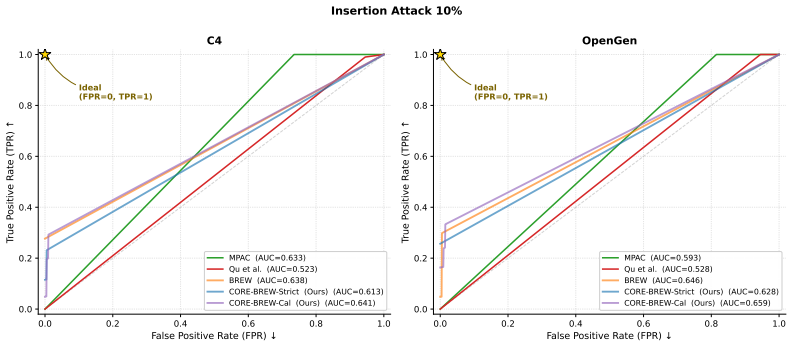
read the original abstract
Reliable provenance for LLM outputs requires multi-bit watermarks that remain robust under editing while maintaining strict false-positive control. Existing ECC-based LLM watermarks rely largely on hard-decision decoding, discarding token-level reliability information. We propose CORE-BREW, a Constant-hit-Rate Embedding extension of block-wise BREW for robust multi-bit watermarking. CORE-BREW calibrates the watermark channel by targeting a fixed hit rate p-star, yielding closed-form per-token log-likelihood ratios (LLRs) for principled soft-decision decoding. It supports two detection modes: Strict-Safe, which preserves the bounded-distance designated-codeword acceptance region, and FPR-Calibrated, which uses likelihood-based scoring and lightweight list decoding to characterize the FPR-TPR trade-off. Experiments on open-source LLMs under token-level edits and paraphrasing demonstrate improved low-FPR discrimination and robustness over prior multi-bit watermarking baselines while maintaining comparable semantic quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CORE-BREW, a constant-hit-rate extension of block-wise BREW watermarking for multi-bit LLM provenance. By targeting a fixed hit rate p-star during embedding, it derives closed-form per-token LLRs that enable soft-decision decoding. Two detection modes are supported: Strict-Safe (preserving bounded-distance acceptance) and FPR-Calibrated (likelihood scoring with list decoding). Experiments on open-source LLMs claim improved low-FPR discrimination and robustness to token edits and paraphrasing relative to prior multi-bit baselines, while preserving semantic quality.
Significance. If the LLR derivation remains valid under editing, the work supplies a principled soft-information channel model for multi-bit watermark detection that could tighten FPR-TPR trade-offs without sacrificing the designated-codeword guarantees of earlier hard-decision schemes.
major comments (2)
- [§3] §3 (CORE-BREW construction): the closed-form LLR expressions are obtained under the assumption that the per-token hit probability equals the design parameter p-star exactly and is stationary across tokens and contexts. Token-level edits and paraphrasing change both the token distribution and the effective embedding behavior, so the observed hit/miss statistics deviate from p-star; no explicit bound is supplied showing that the resulting LLR mismatch remains small enough to preserve the claimed FPR calibration.
- [§5] §5 (robustness experiments): the reported gains in low-FPR discrimination are shown only via aggregate ROC curves; the manuscript does not report the empirical per-token hit rates after each edit type, nor does it compare the LLRs computed from the nominal p-star against LLRs recomputed from the observed post-edit statistics, leaving open whether the soft-decision advantage survives the distribution shift.
minor comments (2)
- [Abstract] The abstract states that the scheme 'yields closed-form per-token log-likelihood ratios' but does not cite the equation number or subsection containing the derivation.
- [§4] Notation for the two detection modes (Strict-Safe vs. FPR-Calibrated) is introduced without a compact table summarizing the acceptance region, scoring function, and list-decoding parameters for each mode.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the importance of validating the LLR model under distribution shift. We respond to each major comment below.
read point-by-point responses
-
Referee: [§3] §3 (CORE-BREW construction): the closed-form LLR expressions are obtained under the assumption that the per-token hit probability equals the design parameter p-star exactly and is stationary across tokens and contexts. Token-level edits and paraphrasing change both the token distribution and the effective embedding behavior, so the observed hit/miss statistics deviate from p-star; no explicit bound is supplied showing that the resulting LLR mismatch remains small enough to preserve the claimed FPR calibration.
Authors: The closed-form LLRs are indeed derived under the modeling assumption that the constant-hit-rate embedding achieves exactly p-star on average. CORE-BREW enforces this target by construction via per-context adjustment of the embedding probability; the Strict-Safe detector does not use the LLR values at all and therefore inherits the same bounded-distance guarantees as the original BREW scheme. For the FPR-Calibrated detector we treat the nominal LLRs as an approximation. The current manuscript does not supply a formal bound on the mismatch induced by edits. In revision we will add an explicit statement of the stationarity assumption in §3 together with a short discussion of its implications. revision: partial
-
Referee: [§5] §5 (robustness experiments): the reported gains in low-FPR discrimination are shown only via aggregate ROC curves; the manuscript does not report the empirical per-token hit rates after each edit type, nor does it compare the LLRs computed from the nominal p-star against LLRs recomputed from the observed post-edit statistics, leaving open whether the soft-decision advantage survives the distribution shift.
Authors: We agree that reporting the post-edit hit-rate statistics and a direct comparison of nominal versus observed LLRs would strengthen the robustness claims. In the revised manuscript we will add a table (or supplementary figure) that lists the empirical per-token hit rates measured after each edit type and paraphrasing attack, together with the corresponding ROC curves obtained when LLRs are recomputed from the observed statistics. This will allow readers to assess how much of the reported soft-decision gain persists under the observed distribution shift. revision: yes
Circularity Check
No circularity: LLRs derived from explicit modeling assumption, not from fitted evaluation data
full rationale
The abstract presents targeting a fixed hit rate p-star as a deliberate design choice that directly yields closed-form LLRs under the assumed stationary channel model. This is a standard modeling step (LLR = log(p*/(1-p*)) for hit/miss) rather than a statistical fit to the same data later used for robustness evaluation. No equations or claims in the provided text reduce a 'prediction' or central result to its own inputs by construction. Experimental claims rest on external tests under edits/paraphrasing, not on self-referential definitions or self-citation chains. The derivation chain is self-contained against the stated assumptions.
Axiom & Free-Parameter Ledger
free parameters (1)
- p-star
Reference graph
Works this paper leans on
-
[1]
Watermarking language models with error correcting codes.arXiv preprint arXiv:2406.10281, 2024
Patrick Chao, Yan Sun, Edgar Dobriban, and Hamed Hassani. Watermarking language models with error correcting codes.arXiv preprint arXiv:2406.10281, 2024
arXiv 2024
-
[2]
D. Chase. Class of algorithms for decoding block codes with channel measurement information. IEEE Transactions on Information Theory, 18(1):170–182, 1972. doi: 10.1109/TIT.1972. 1054746
-
[3]
Pseudorandom error-correcting codes
Miranda Christ and Sam Gunn. Pseudorandom error-correcting codes. In Leonid Reyzin and Douglas Stebila, editors,Advances in Cryptology – CRYPTO 2024, pages 325–347, Cham,
2024
-
[4]
Springer Nature Switzerland
-
[5]
Cambridge University Press, 2001
Oded Goldreich.Foundations of Cryptography, Volume 1: Basic Tools. Cambridge University Press, 2001. ISBN 0-521-79172-3
2001
-
[6]
Wassily Hoeffding. Probability inequalities for sums of bounded random variables.Journal of the American Statistical Association, 58(301):13–30, 1963. URL https://doi.org/10. 1080/01621459.1963.10500830
arXiv 1963
-
[7]
The curious case of neural text degeneration
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The curious case of neural text degeneration. InInternational Conference on Learning Representations (ICLR 2020), 2020. URLhttps://openreview.net/forum?id=rygGQyrFvH
2020
-
[8]
An upper bound for the probability of a union.Journal of Applied Probability, 13(3):597–603, 1976
David Hunter. An upper bound for the probability of a union.Journal of Applied Probability, 13(3):597–603, 1976
1976
-
[9]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b, 2023. URL https://arxi...
Pith/arXiv arXiv 2023
-
[10]
Block-wise codeword embedding for reliable multi-bit text watermarking, 2026
Joeun Kim, HoEun Kim, Dongsup Jin, and Young-Sik Kim. Block-wise codeword embedding for reliable multi-bit text watermarking, 2026. URL https://arxiv.org/abs/2605.00348. 10
Pith/arXiv arXiv 2026
-
[11]
A watermark for large language models
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. A watermark for large language models. InProceedings of the 40th International Conference on Machine Learning (ICML 2023), pages 17061–17084. PMLR, 2023
2023
-
[12]
Paraphras- ing evades detectors of ai-generated text, but retrieval is an effective defense.Advances in Neural Information Processing Systems (NeurIPS 2023), 36:27469–27500, 2023
Kalpesh Krishna, Yixiao Song, Marzena Karpinska, John Wieting, and Mohit Iyyer. Paraphras- ing evades detectors of ai-generated text, but retrieval is an effective defense.Advances in Neural Information Processing Systems (NeurIPS 2023), 36:27469–27500, 2023
2023
-
[13]
Taku Kudo and John Richardson. SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In Eduardo Blanco and Wei Lu, editors, Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 66–71, Brussels, Belgium, November 2018. Association for Co...
work page internal anchor Pith review doi:10.18653/v1/d18-2012 2018
-
[14]
Costello.Error Control Coding: Fundamentals and Applications
Shu Lin and Daniel J. Costello.Error Control Coding: Fundamentals and Applications. Prentice Hall, Upper Saddle River, NJ, 2 edition, 2004. ISBN 0-13-042672-6. URL https://www.pearson.com/en-us/subject-catalog/p/error-control-coding/ P200000003536/9780130426727
2004
-
[15]
Manning, and Chelsea Finn
Eric Mitchell, Yoonho Lee, Alexander Khazatsky, Christopher D. Manning, and Chelsea Finn. Detectgpt: Zero-shot machine-generated text detection using probability curvature. In Proceedings of the 40th International Conference on Machine Learning (ICML 2023), pages 24950–24962. PMLR, 2023
2023
-
[16]
Morris, Eli Lifland, Jin Yong Yoo, and Yanjun Qi
John X. Morris, Eli Lifland, Jin Yong Yoo, and Yanjun Qi. Textattack: A framework for adversarial attacks, data augmentation, and adversarial training in nlp. InProceedings of the 2020 conference on empirical methods in natural language processing: System demonstrations, pages 119–126, 2020
2020
-
[17]
Leyi Pan, Aiwei Liu, Zhiwei He, Zitian Gao, Xuandong Zhao, Yijian Lu, Binglin Zhou, Shuliang Liu, Xuming Hu, Lijie Wen, Irwin King, and Philip S. Yu. MarkLLM: An open-source toolkit for LLM watermarking. In Delia Irazu Hernandez Farias, Tom Hope, and Manling Li, editors, Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processin...
-
[18]
Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics , year =
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. BLEU: a method for automatic evaluation of machine translation. In Pierre Isabelle, Eugene Charniak, and Dekang Lin, editors, Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL 2002), pages 311–318, Philadelphia, Pennsylvania, USA, July 2002. Association...
-
[19]
PyTorch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, An- dreas Kopf, Edward Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chil- amkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. PyTorch: An imperative style, high-perf...
2019
-
[20]
Provably robust multi-bit watermarking for {AI-generated} text
Wenjie Qu, Wengrui Zheng, Tianyang Tao, Dong Yin, Yanze Jiang, Zhihua Tian, Wei Zou, Jinyuan Jia, and Jiaheng Zhang. Provably robust multi-bit watermarking for {AI-generated} text. In34th USENIX Security Symposium (USENIX Security 25), pages 201–220, 2025
2025
-
[21]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020. 11
2020
-
[22]
Cambridge university press, 2008
Tom Richardson and Rudiger Urbanke.Modern coding theory. Cambridge university press, 2008
2008
-
[23]
Necessary and sufficient watermark for large language models.arXiv preprint arXiv:2310.00833, 2023
Yuki Takezawa, Ryoma Sato, Han Bao, Kenta Niwa, and Makoto Yamada. Necessary and sufficient watermark for large language models.arXiv preprint arXiv:2310.00833, 2023
arXiv 2023
-
[24]
John Wieting and Kevin Gimpel. ParaNMT-50M: Pushing the limits of paraphrastic sentence embeddings with millions of machine translations. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL), pages 451–462, 2018. URL https: //arxiv.org/abs/1711.05732
Pith/arXiv arXiv 2018
-
[25]
Transformers: State- of-the-art natural language processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, et al. Transformers: State- of-the-art natural language processing. InProceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations, pages 38–45, 2020
2020
-
[26]
Attacking neural text detectors.arXiv preprint arXiv:2002.11768, 2020
Max Wolff and Stuart Wolff. Attacking neural text detectors.arXiv preprint arXiv:2002.11768, 2020
arXiv 2002
-
[27]
A resilient and accessible distribution-preserving watermark for large language models
Yihan Wu, Zhengmian Hu, Junfeng Guo, Hongyang Zhang, and Heng Huang. A resilient and accessible distribution-preserving watermark for large language models. InProceedings of the 41st International Conference on Machine Learning (ICML 2024), volume 235 ofProceedings of Machine Learning Research, pages 53443–53470. PMLR, 2024
2024
-
[28]
Advancing beyond identification: Multi- bit watermark for large language models
KiYoon Yoo, Wonhyuk Ahn, and Nojun Kwak. Advancing beyond identification: Multi- bit watermark for large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 4031–4055, 2024
2024
-
[29]
OPT: Open pre-trained transformer language models.arXiv preprint arXiv:2205.01068, 2022
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. OPT: Open pre-trained transformer language models.arXiv preprint arXiv:2205.01068, 2022
Pith/arXiv arXiv 2022
-
[30]
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. BERTScore: Evaluating text generation with BERT, 2020. URLhttps://arxiv.org/abs/1904.09675
Pith/arXiv arXiv 2020
-
[31]
Xuandong Zhao, Prabhanjan Ananth, Lei Li, and Yu-Xiang Wang. Provable robust watermarking for AI-generated text. InProceedings of the 12th International Conference on Learning Representations (ICLR 2024), 2024. A Baseline Full Details A.1 Block-wise Designated-Codeword Watermarking This appendix summarizes the generic block-wise designated-codeword waterm...
arXiv 2024
-
[32]
Justification: The paper does not involve crowdsourcing, user studies, surveys, or research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.