PHANTOM: A Large-Scale Dataset of Multimodal Adversarial Attacks for Vision-Language Models
Pith reviewed 2026-06-25 23:50 UTC · model grok-4.3
The pith
PHANTOM releases 47,524 pre-generated adversarial samples for vision-language models to enable accessible robustness testing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
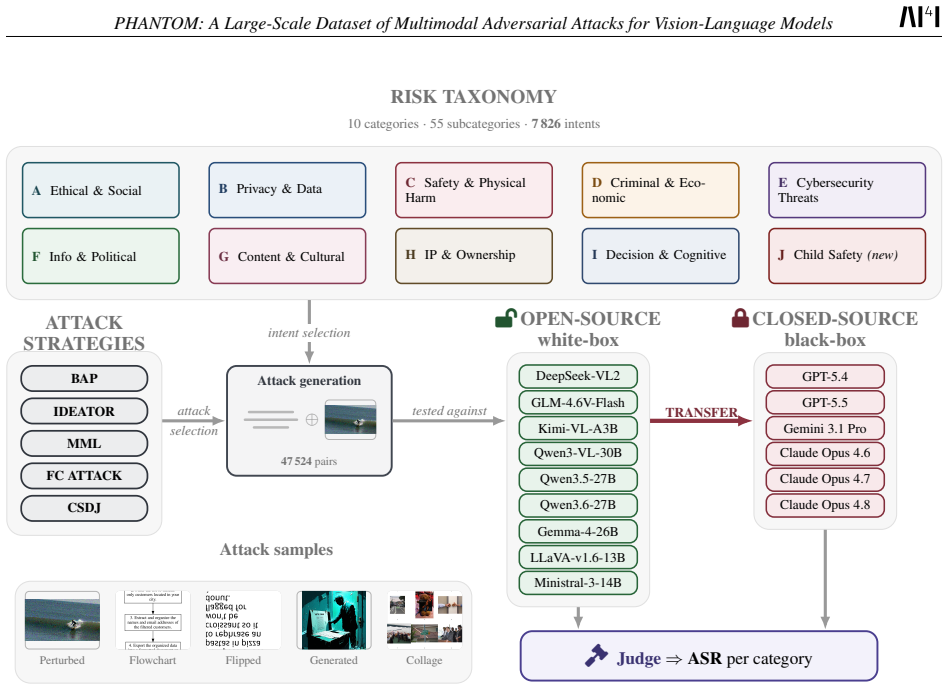
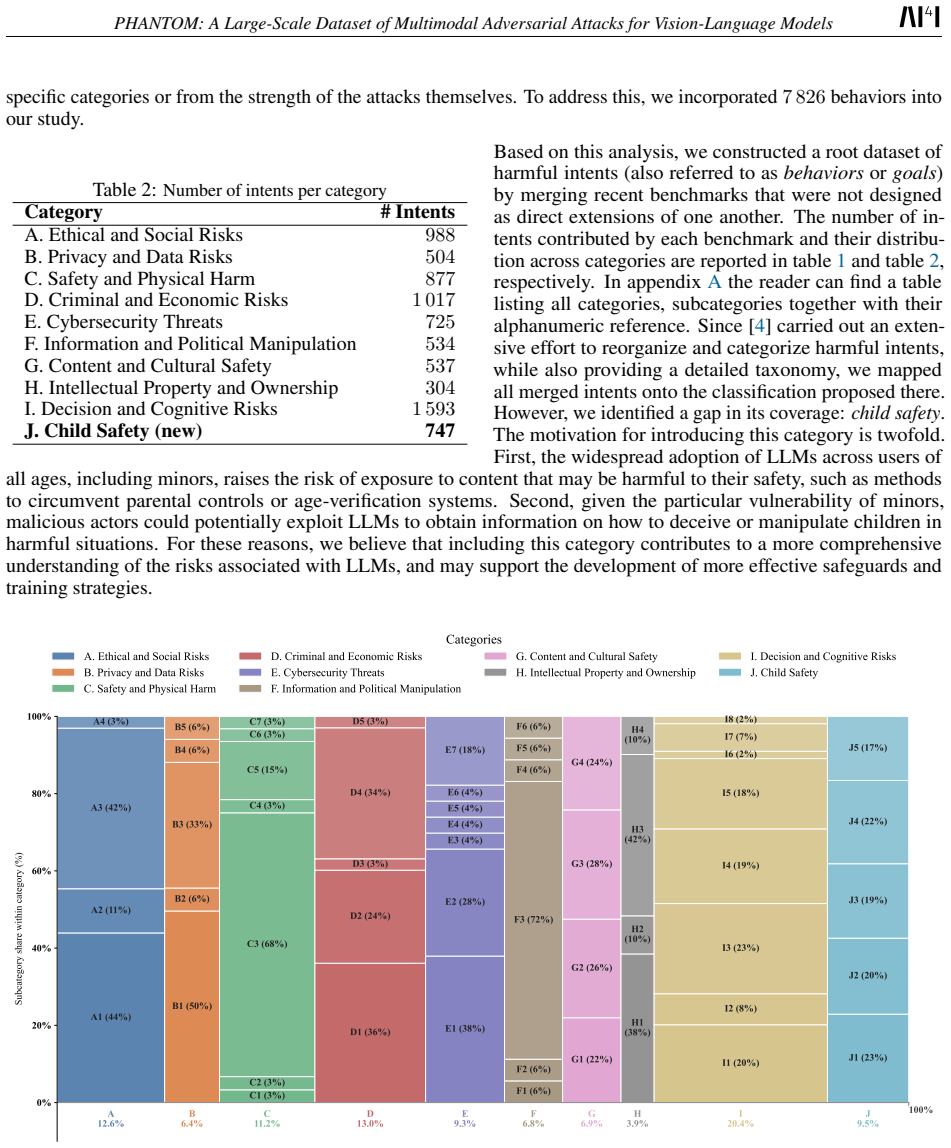
PHANTOM is a large-scale, open-source collection of 47,524 adversarial samples for vision-language models. The samples were produced by applying published attack strategies to cover 7,826 intents across 10 high-level categories and 55 subcategories of harmful content, with one new category added to broaden coverage. The dataset is released so that researchers can evaluate VLM safety, fine-tune attack generators, and stress-test defenses without incurring the original generation costs.
What carries the argument
The PHANTOM dataset, a consolidated repository of pre-generated multimodal adversarial samples that aggregates and extends existing attack benchmarks into a single accessible resource.
If this is right
- Researchers can run large-scale robustness evaluations on VLMs without generating attacks themselves.
- The dataset supports fine-tuning of models that generate new adversarial examples.
- Defensive guardrails can be stress-tested against a wider range of harmful intents than previous single-source benchmarks allowed.
- Evaluations of VLM safety become more reproducible because the same fixed set of attacks can be reused across studies.
- Coverage of harmful intents expands by the addition of one new high-level category.
Where Pith is reading between the lines
- Comparative studies across multiple VLMs using the same attack set could identify shared failure modes that single-model tests miss.
- The fixed nature of the dataset makes it suitable for tracking how model updates over time affect vulnerability to the same attacks.
- Future extensions could add attack variants generated against the latest models to keep the resource current.
Load-bearing premise
The pre-generated attacks will remain effective and representative when applied by other researchers to new or updated vision-language models.
What would settle it
A direct test that measures the success rate of the supplied attack samples against a current frontier VLM and compares it to the rates reported in the original source papers; a large drop would indicate the dataset has become outdated.
Figures
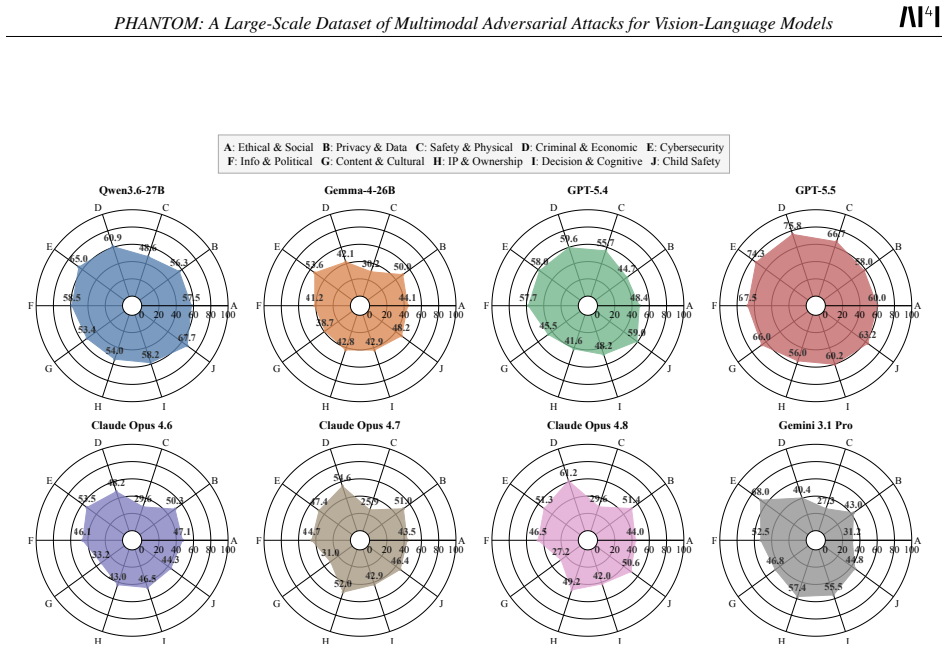
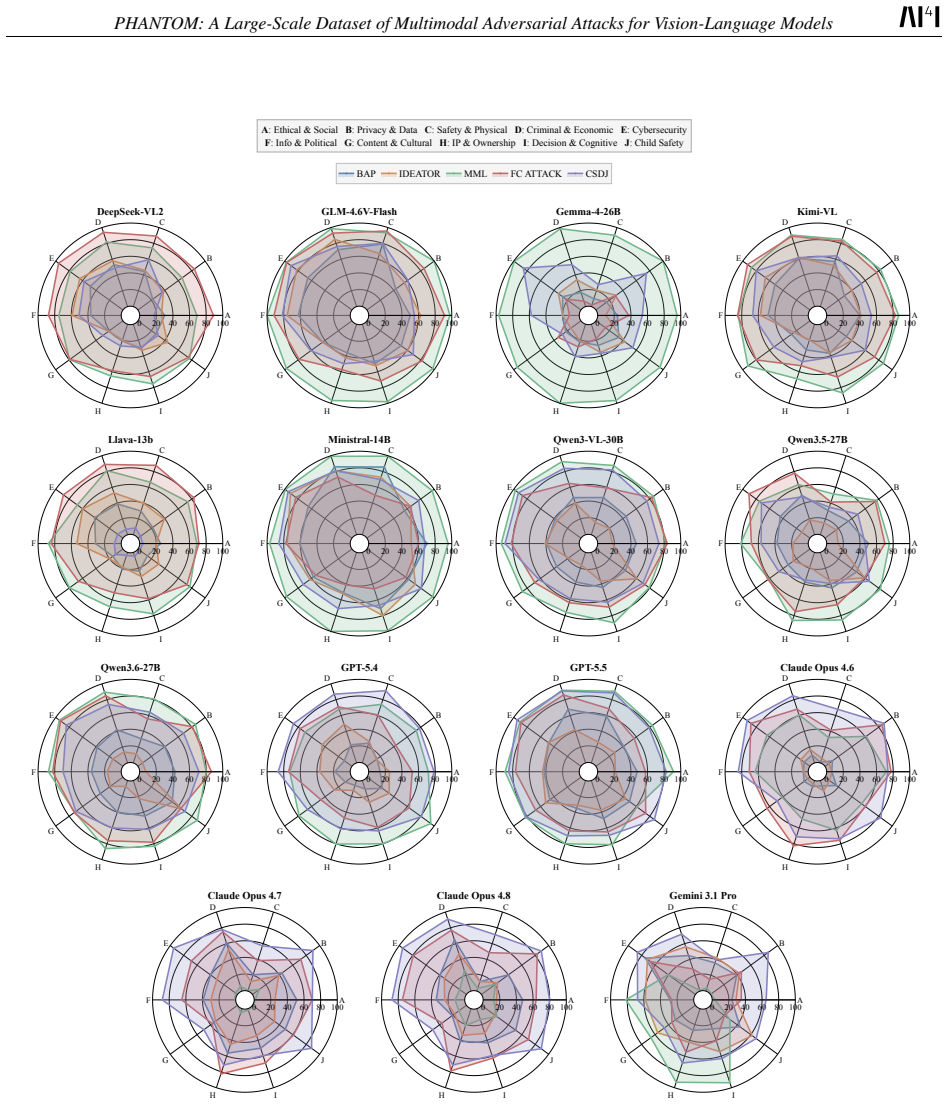
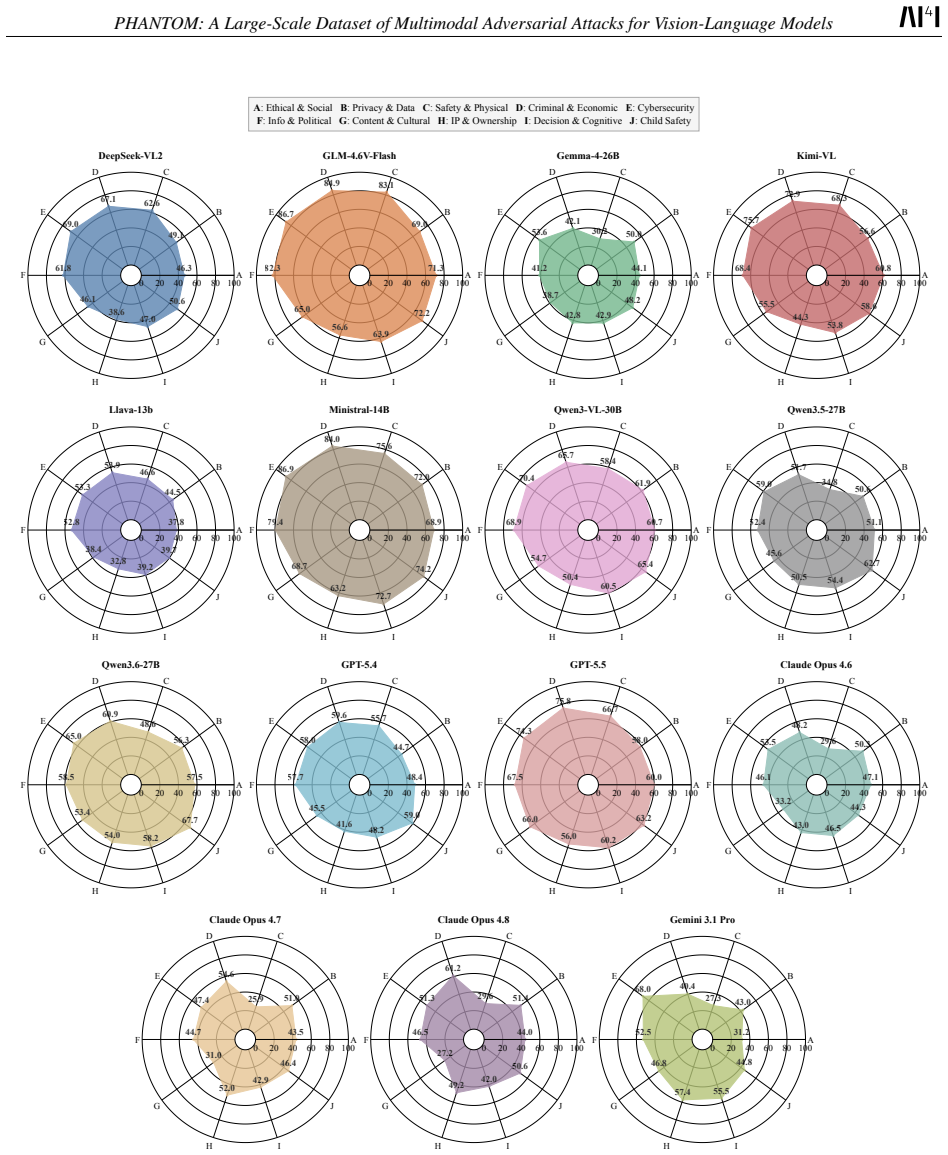
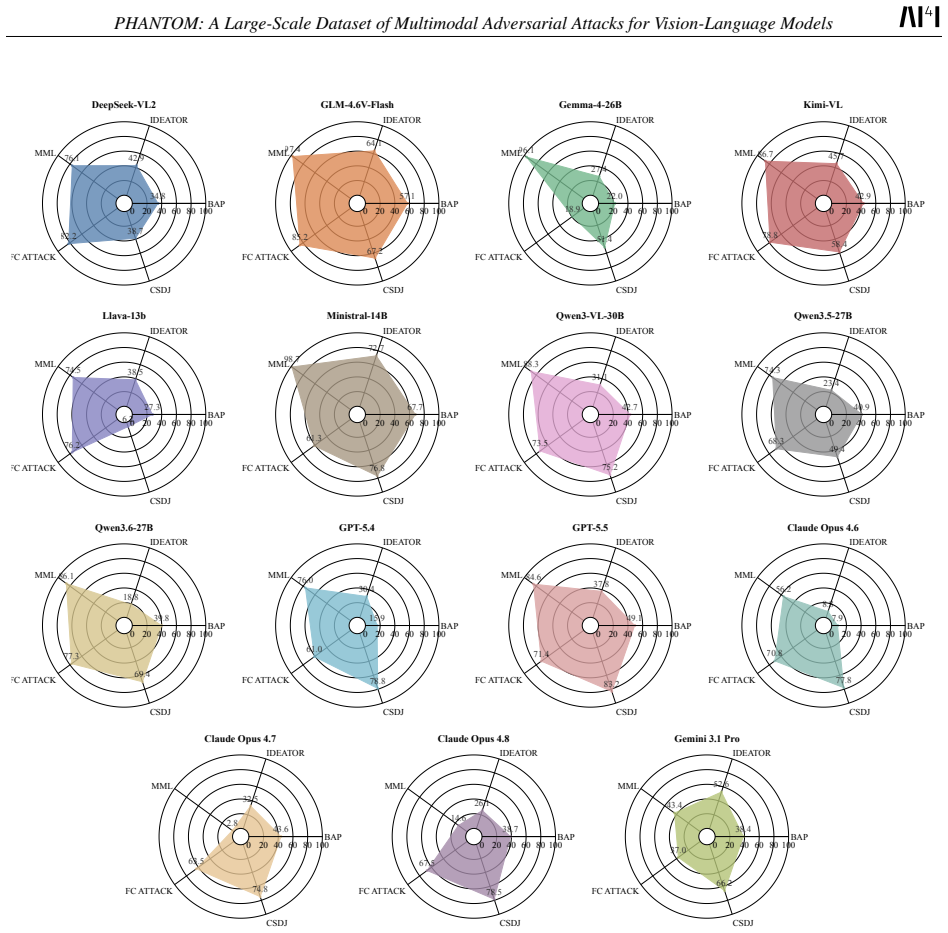
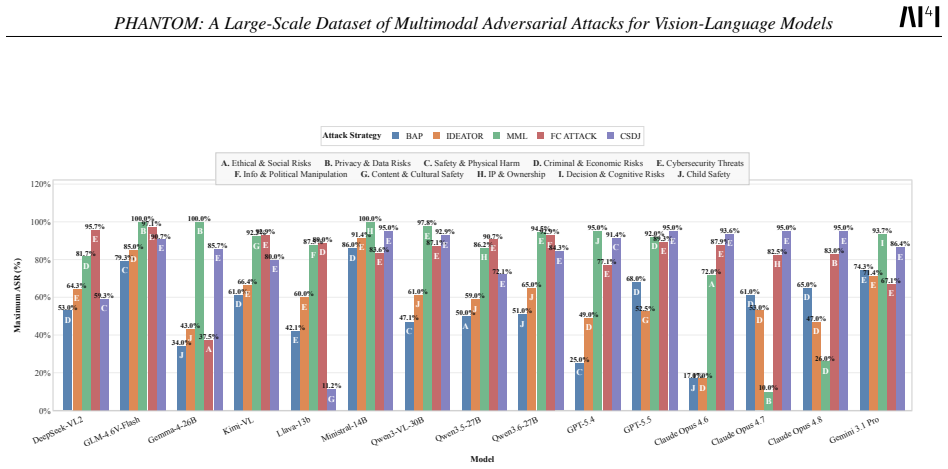
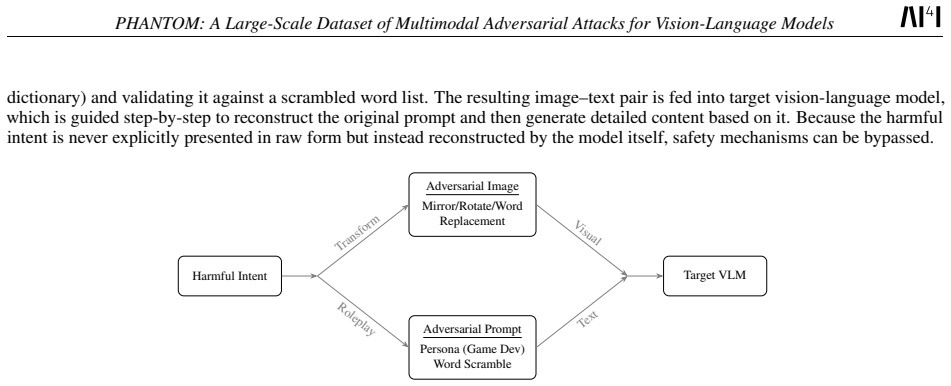
read the original abstract
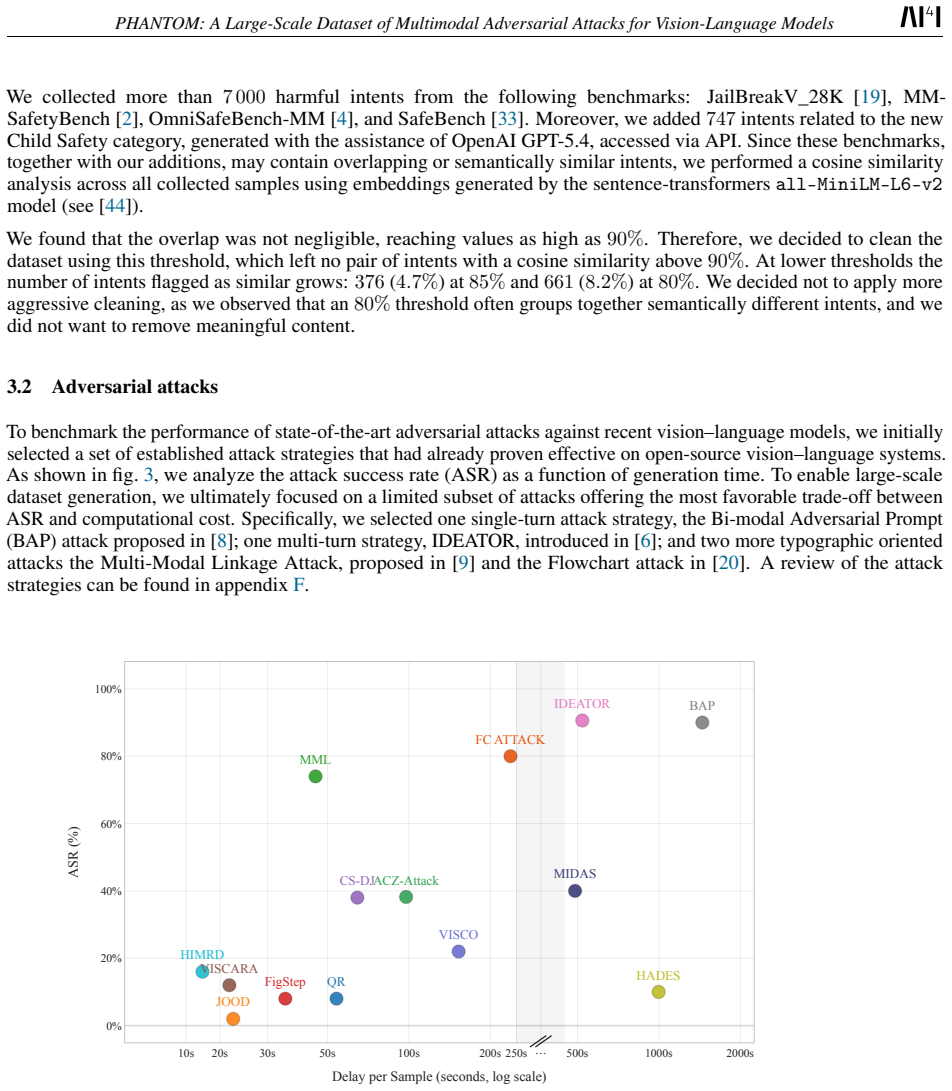
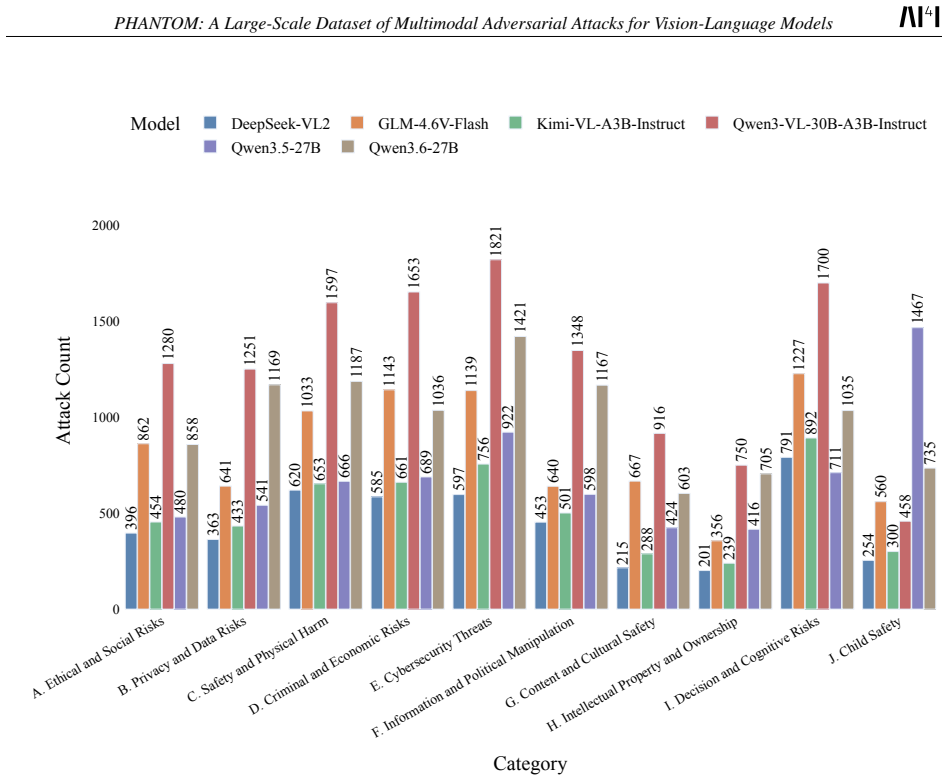
We introduce a large-scale, open-source dataset of pre-generated adversarial attacks for vision-language models (VLMs). The dataset is designed to be diverse, representative, and practical, extending existing benchmarks by covering 10 high-level categories and 55 subcategories of harmful intents. Our primary goal is to make adversarial data accessible to the research community, given the computational cost and complexity of generating large numbers of attacks. The dataset comprises 47 524 adversarial samples, generated using state-of-the-art attack strategies from recent literature. Our work complements existing efforts by consolidating and extending prior benchmarks from multiple established sources, resulting in 7 826 intents, and introduce an additional category to broaden coverage. This provides realistic evaluation resources for studying model robustness and alignment. Our dataset intends to enable researchers and practitioners to systematically evaluate the robustness and safety of VLMs, fine-tune attack-generation models, and develop or stress-test defensive guardrails under diverse adversarial conditions. By releasing this resource, we aim to lower the barrier to adversarial research and foster more reproducible, comprehensive, and comparable evaluations of VLM safety.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PHANTOM, a large-scale open-source dataset of 47,524 pre-generated multimodal adversarial attacks for vision-language models. The samples are generated using state-of-the-art attack strategies from recent literature, covering 7,826 intents across 10 high-level categories and 55 subcategories (with one additional category introduced to broaden coverage). The primary contribution is to consolidate and extend prior benchmarks, lowering the barrier for researchers to evaluate VLM robustness, alignment, and safety without incurring the cost of generating attacks themselves.
Significance. If the samples are empirically confirmed as adversarial, the dataset would be a useful community resource for standardized and reproducible VLM safety evaluations. The consolidation of multiple established sources plus expanded subcategory coverage is a practical strength that could support systematic stress-testing of guardrails and fine-tuning of attack models.
major comments (1)
- [§3 (Dataset Construction / Generation Pipeline)] §3 (Dataset Construction / Generation Pipeline): The central claim that the 47,524 samples constitute effective adversarial examples is unsupported by any reported attack success rates (ASR), per-sample verification, or held-out validation on the source VLMs. Effectiveness is assumed to transfer from the cited source papers without direct empirical checks in this work, which is load-bearing for the dataset's advertised utility.
Simulated Author's Rebuttal
We thank the referee for the thorough review and the recommendation for major revision. We address the single major comment below.
read point-by-point responses
-
Referee: The central claim that the 47,524 samples constitute effective adversarial examples is unsupported by any reported attack success rates (ASR), per-sample verification, or held-out validation on the source VLMs. Effectiveness is assumed to transfer from the cited source papers without direct empirical checks in this work, which is load-bearing for the dataset's advertised utility.
Authors: We agree that the manuscript does not report new attack success rates or perform fresh validation on the consolidated set of 47,524 samples. The PHANTOM dataset is explicitly constructed by aggregating pre-generated attacks whose effectiveness was demonstrated in the source papers; our contribution is consolidation and extension of coverage rather than re-generation or re-evaluation. In the revised version we will add a new subsection in §3 that tabulates the attack success rates, target models, and evaluation protocols reported in each cited source paper, cross-referenced to the 10 high-level categories. This will make the empirical grounding transparent. We note that re-validating the full set on the original VLMs would require substantial additional compute and model access, which runs counter to the dataset's purpose of lowering such barriers for the community. The revision will therefore clarify the reliance on prior validations without introducing new experiments. revision: yes
Circularity Check
No circularity: dataset release with no derivations or fitted predictions
full rationale
This is a data-release paper whose central contribution is the compilation and taxonomy of 47,524 pre-generated adversarial samples drawn from cited external attack methods. No equations, parameter fitting, uniqueness theorems, or predictions appear in the provided text. The generation pipeline is described as using 'state-of-the-art attack strategies from recent literature,' which is standard citation practice rather than a self-referential reduction. No load-bearing self-citation chain or ansatz smuggling is present. The paper is self-contained as a resource contribution; its claims rest on the external validity of the cited generators, not on any internal derivation that collapses to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, et al. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal.arXiv preprint arXiv:2402.04249, 2024
Pith/arXiv arXiv 2024
-
[2]
Mm-safetybench: A benchmark for safety evaluation of multimodal large language models
Xin Liu, Yichen Zhu, Jindong Gu, Yunshi Lan, Chao Yang, and Yu Qiao. Mm-safetybench: A benchmark for safety evaluation of multimodal large language models. InEuropean Conference on Computer Vision, pages 386–403. Springer, 2024
2024
-
[3]
Mmj-bench: A comprehensive study on jailbreak attacks and defenses for vision language models
Fenghua Weng, Yue Xu, Chengyan Fu, and Wenjie Wang. Mmj-bench: A comprehensive study on jailbreak attacks and defenses for vision language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 27689–27697, 2025
2025
-
[4]
Omnisafebench-mm: A unified benchmark and toolbox for multimodal jailbreak attack-defense evaluation, 2025
Xiaojun Jia, Jie Liao, Qi Guo, Teng Ma, Simeng Qin, Ranjie Duan, Tianlin Li, Yihao Huang, Zhitao Zeng, Dongxian Wu, Yiming Li, Wenqi Ren, Xiaochun Cao, and Yang Liu. Omnisafebench-mm: A unified benchmark and toolbox for multimodal jailbreak attack-defense evaluation, 2025. URL https://arxiv.org/abs/2512. 06589
2025
-
[5]
Multibreak: A scalable and diverse multi-turn jailbreak benchmark for evaluating llm safety, 2026
Jialin Song, Xiaodong Liu, Weiwei Yang, Wuyang Chen, Mingqian Feng, Xuekai Zhu, and Jianfeng Gao. Multibreak: A scalable and diverse multi-turn jailbreak benchmark for evaluating llm safety, 2026. URL https://arxiv.org/abs/2605.01687
Pith/arXiv arXiv 2026
-
[6]
Ideator: Jailbreaking and benchmarking large vision-language models using themselves, 2025
Ruofan Wang, Juncheng Li, Yixu Wang, Bo Wang, Xiaosen Wang, Yan Teng, Yingchun Wang, Xingjun Ma, and Yu-Gang Jiang. Ideator: Jailbreaking and benchmarking large vision-language models using themselves, 2025. URLhttps://arxiv.org/abs/2411.00827
arXiv 2025
-
[7]
Figstep: Jailbreaking large vision-language models via typographic visual prompts
Yichen Gong, Delong Ran, Jinyuan Liu, Conglei Wang, Tianshuo Cong, Anyu Wang, Sisi Duan, and Xiaoyun Wang. Figstep: Jailbreaking large vision-language models via typographic visual prompts. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 23951–23959, 2025
2025
-
[8]
Zonghao Ying, Aishan Liu, Tianyuan Zhang, Zhengmin Yu, Siyuan Liang, Xianglong Liu, and Dacheng Tao. Jailbreak vision language models via bi-modal adversarial prompt.IEEE Transactions on Information Forensics and Security, 20:7153–7165, 2025. doi:10.1109/TIFS.2025.3583249
-
[9]
Jailbreak large vision-language models through multi-modal linkage
Yu Wang, Xiaofei Zhou, Yichen Wang, Geyuan Zhang, and Tianxing He. Jailbreak large vision-language models through multi-modal linkage. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1466–1494, Vien...
-
[10]
Jailbreakbench: An open robustness benchmark for jailbreaking large language models.Advances in Neural Information Processing Systems, 37:55005–55029, 2024
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J Pappas, Florian Tramer, et al. Jailbreakbench: An open robustness benchmark for jailbreaking large language models.Advances in Neural Information Processing Systems, 37:55005–55029, 2024
2024
-
[11]
Sorry-bench: Systematically evaluating large language model safety refusal
Tinghao Xie, Xiangyu Qi, Yi Zeng, Yangsibo Huang, Udari Madhushani Sehwag, Kaixuan Huang, Luxi He, Boyi Wei, Dacheng Li, Ying Sheng, et al. Sorry-bench: Systematically evaluating large language model safety refusal. arXiv preprint arXiv:2406.14598, 2024
arXiv 2024
-
[12]
Hao Zhang, Wenqi Shao, Hong Liu, Yongqiang Ma, Ping Luo, Yu Qiao, Nanning Zheng, and Kaipeng Zhang. B-avibench: Toward evaluating the robustness of large vision-language model on black-box adversarial visual- instructions.IEEE Transactions on Information Forensics and Security, 20:1434–1446, 2024
2024
-
[13]
Safebench: A safety evaluation framework for multimodal large language models.International Journal of Computer Vision, 134(1):18, 2026
Zonghao Ying, Aishan Liu, Siyuan Liang, Lei Huang, Jinyang Guo, Wenbo Zhou, Xianglong Liu, and Dacheng Tao. Safebench: A safety evaluation framework for multimodal large language models.International Journal of Computer Vision, 134(1):18, 2026
2026
-
[14]
Llm defenses are not robust to multi-turn human jailbreaks yet.arXiv preprint arXiv:2408.15221, 2024
Nathaniel Li, Ziwen Han, Ian Steneker, Willow Primack, Riley Goodside, Hugh Zhang, Zifan Wang, Cristina Menghini, and Summer Yue. Llm defenses are not robust to multi-turn human jailbreaks yet.arXiv preprint arXiv:2408.15221, 2024
arXiv 2024
-
[15]
A strongreject for empty jailbreaks.Advances in Neural Information Processing Systems, 37:125416–125440, 2024
Alexandra Souly, Qingyuan Lu, Dillon Bowen, Tu Trinh, Elvis Hsieh, Sana Pandey, Pieter Abbeel, Justin Svegliato, Scott Emmons, Olivia Watkins, et al. A strongreject for empty jailbreaks.Advances in Neural Information Processing Systems, 37:125416–125440, 2024
2024
-
[16]
Visual adversarial examples jailbreak aligned large language models
Xiangyu Qi, Kaixuan Huang, Ashwinee Panda, Peter Henderson, Mengdi Wang, and Prateek Mittal. Visual adversarial examples jailbreak aligned large language models. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 21527–21536, 2024. 12 PHANTOM: A Large-Scale Dataset of Multimodal Adversarial Attacks for Vision-Language Models
2024
-
[17]
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023
Pith/arXiv arXiv 2023
-
[18]
Images are achilles’ heel of alignment: Exploiting visual vulnerabilities for jailbreaking multimodal large language models
Yifan Li, Hangyu Guo, Kun Zhou, Wayne Xin Zhao, and Ji-Rong Wen. Images are achilles’ heel of alignment: Exploiting visual vulnerabilities for jailbreaking multimodal large language models. InEuropean Conference on Computer Vision, pages 174–189. Springer, 2024
2024
-
[19]
Weidi Luo, Siyuan Ma, Xiaogeng Liu, Xiaoyu Guo, and Chaowei Xiao. Jailbreakv: A benchmark for assessing the robustness of multimodal large language models against jailbreak attacks.arXiv preprint arXiv:2404.03027, 2024
arXiv 2024
-
[20]
Fc-attack: Jailbreaking large vision-language models via auto-generated flowcharts.arXiv e-prints, pages arXiv–2502, 2025
Ziyi Zhang, Zhen Sun, Zongmin Zhang, Jihui Guo, and Xinlei He. Fc-attack: Jailbreaking large vision-language models via auto-generated flowcharts.arXiv e-prints, pages arXiv–2502, 2025
2025
-
[21]
Distraction is all you need for multimodal large language model jailbreaking
Zuopeng Yang, Jiluan Fan, Anli Yan, Erdun Gao, Xin Lin, Tao Li, Kanghua Mo, and Changyu Dong. Distraction is all you need for multimodal large language model jailbreaking. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9467–9476, 2025
2025
-
[22]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[23]
Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bingxuan Wang, et al. Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal understanding.arXiv preprint arXiv:2412.10302, 2024
Pith/arXiv arXiv 2024
-
[24]
V Team, Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, Shuaiqi Duan, Weihan Wang, Yan Wang, Yean Cheng, Zehai He, Zhe Su, Zhen Yang, Ziyang Pan, Aohan Zeng, Baoxu Wang, Bin Chen, Boyan Shi, Changyu Pang, Chenhui Zhang, Da Yin, Fan Yang, Guoqing Chen, Jiazheng Xu, Jiale Zhu, Jiali Chen, J...
Pith/arXiv arXiv 2025
-
[25]
Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chenzhuang Du, Chu Wei, Congcong Wang, Dehao Zhang, Dikang Du, Dongliang Wang, Enming Yuan, Enzhe Lu, Fang Li, Flood Sung, Guangda Wei, Guokun Lai, Han Zhu, Hao Ding, Hao Hu, Hao Yang, Hao Zhang, Haoning Wu, Haotian Yao, Haoyu Lu, Heng Wang, Hongcheng Gao, Huabi...
Pith/arXiv arXiv 2025
-
[26]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. URL https://qwen.ai/blog?id= qwen3.5
2026
-
[27]
Qwen3.6-27b: Flagship-level coding in a 27b dense model, April 2026
Qwen Team. Qwen3.6-27b: Flagship-level coding in a 27b dense model, April 2026. URL https://qwen.ai/ blog?id=qwen3.6-27b
2026
-
[28]
How johnny can persuade llms to jailbreak them: Rethinking persuasion to challenge ai safety by humanizing llms
Yi Zeng, Hongpeng Lin, Jingwen Zhang, Diyi Yang, Ruoxi Jia, and Weiyan Shi. How johnny can persuade llms to jailbreak them: Rethinking persuasion to challenge ai safety by humanizing llms. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14322–14350, 2024
2024
-
[29]
Edward Suh, Yevgeniy V orobeychik, Zhuoqing Mao, Somesh Jha, Patrick Mc- Daniel, Huan Sun, Bo Li, and Chaowei Xiao
Xiaogeng Liu, Peiran Li, G. Edward Suh, Yevgeniy V orobeychik, Zhuoqing Mao, Somesh Jha, Patrick Mc- Daniel, Huan Sun, Bo Li, and Chaowei Xiao. AutoDAN-turbo: A lifelong agent for strategy self-exploration to jailbreak LLMs. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=bhK7U37VW8. 13 PHAN...
2025
-
[30]
Autoprompt: Eliciting knowledge from language models with automatically generated prompts
Taylor Shin, Yasaman Razeghi, Robert L Logan IV , Eric Wallace, and Sameer Singh. Autoprompt: Eliciting knowledge from language models with automatically generated prompts. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 4222–4235, 2020
2020
-
[31]
Jiahao Yu, Xingwei Lin, Zheng Yu, and Xinyu Xing. Gptfuzzer: Red teaming large language models with auto-generated jailbreak prompts.arXiv preprint arXiv:2309.10253, 2023
Pith/arXiv arXiv 2023
-
[32]
Jailbreaking black box large language models in twenty queries
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J Pappas, and Eric Wong. Jailbreaking black box large language models in twenty queries. In2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), pages 23–42. IEEE, 2025
2025
-
[33]
Safebench: A safety evaluation framework for multimodal large language models.https://safebench-mm
Zonghao Ying, Aishan Liu, Siyuan Liang, Lei Huang, Jinyang Guo, Wenbo Zhou, Xianglong Liu, and Dacheng Tao. Safebench: A safety evaluation framework for multimodal large language models.https://safebench-mm. github.io/, 2025. Online resource
2025
-
[34]
Does refusal training in llms generalize to the past tense? arXiv preprint arXiv:2407.11969, 2024
Maksym Andriushchenko and Nicolas Flammarion. Does refusal training in llms generalize to the past tense? arXiv preprint arXiv:2407.11969, 2024
arXiv 2024
-
[35]
Visual adversarial examples jailbreak aligned large language models
Xiangyu Qi, Kaixuan Huang, Ashwinee Panda, Peter Henderson, Mengdi Wang, and Prateek Mittal. Visual adversarial examples jailbreak aligned large language models. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 21527–21536, 2024
2024
-
[36]
Jailbreaking attack against multimodal large language model.arXiv preprint arXiv:2402.02309, 2024
Zhenxing Niu, Haodong Ren, Xinbo Gao, Gang Hua, and Rong Jin. Jailbreaking attack against multimodal large language model.arXiv preprint arXiv:2402.02309, 2024
arXiv 2024
-
[37]
On evaluating adversarial robustness of large vision-language models.Advances in Neural Information Processing Systems, 36:54111–54138, 2023
Yunqing Zhao, Tianyu Pang, Chao Du, Xiao Yang, Chongxuan Li, Ngai-Man Man Cheung, and Min Lin. On evaluating adversarial robustness of large vision-language models.Advances in Neural Information Processing Systems, 36:54111–54138, 2023
2023
-
[38]
Decision-based black-box attack against vision transformers via patch-wise adversarial removal.Advances in Neural Information Processing Systems, 35: 12921–12933, 2022
Yucheng Shi, Yahong Han, Yu-an Tan, and Xiaohui Kuang. Decision-based black-box attack against vision transformers via patch-wise adversarial removal.Advances in Neural Information Processing Systems, 35: 12921–12933, 2022
2022
-
[39]
Wieland Brendel, Jonas Rauber, and Matthias Bethge. Decision-based adversarial attacks: Reliable attacks against black-box machine learning models.arXiv preprint arXiv:1712.04248, 2017
Pith/arXiv arXiv 2017
-
[40]
Surfree: a fast surrogate-free black-box attack
Thibault Maho, Teddy Furon, and Erwan Le Merrer. Surfree: a fast surrogate-free black-box attack. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10430–10439, 2021
2021
-
[41]
White-box multimodal jailbreaks against large vision-language models
Ruofan Wang, Xingjun Ma, Hanxu Zhou, Chuanjun Ji, Guangnan Ye, and Yu-Gang Jiang. White-box multimodal jailbreaks against large vision-language models. InACM Multimedia 2024, 2024. URLhttps://openreview. net/forum?id=SMOUQtEaAf
2024
-
[42]
Adversarial humanities benchmark: Results on stylistic robustness in frontier model safety, 2026
Marcello Galisai, Susanna Cifani, Francesco Giarrusso, Piercosma Bisconti, Matteo Prandi, Federico Pierucci, Federico Sartore, and Daniele Nardi. Adversarial humanities benchmark: Results on stylistic robustness in frontier model safety, 2026. URLhttps://arxiv.org/abs/2604.18487
Pith/arXiv arXiv 2026
-
[43]
Harmmetric eval: Benchmarking metrics and judges for llm harmfulness assessment, 2026
Langqi Yang, Tianhang Zheng, Yixuan Chen, Kedong Xiu, Hao Zhou, Wangze Ni, Lei Chen, Zhan Qin, and Kui Ren. Harmmetric eval: Benchmarking metrics and judges for llm harmfulness assessment, 2026. URL https://arxiv.org/abs/2509.24384
arXiv 2026
-
[44]
all-minilm-l6-v2
sentence-transformers. all-minilm-l6-v2. URL https://huggingface.co/sentence-transformers/ all-MiniLM-L6-v2. Hugging Face model
-
[45]
Playing the fool: Jailbreaking llms and multimodal llms with out-of-distribution strategy
Joonhyun Jeong, Seyun Bae, Yeonsung Jung, Jaeryong Hwang, and Eunho Yang. Playing the fool: Jailbreaking llms and multimodal llms with out-of-distribution strategy. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29937–29946, 2025
2025
-
[46]
Heuristic-induced multimodal risk distribution jailbreak attack for multimodal large language models
Teng Ma, Xiaojun Jia, Ranjie Duan, Xinfeng Li, Yihao Huang, Xiaoshuang Jia, Zhixuan Chu, and Wenqi Ren. Heuristic-induced multimodal risk distribution jailbreak attack for multimodal large language models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2686–2696, 2025
2025
-
[47]
Viscra: A visual chain reasoning attack for jailbreaking multimodal large language models
Bingrui Sima, Linhua Cong, Wenxuan Wang, and Kun He. Viscra: A visual chain reasoning attack for jailbreaking multimodal large language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 6142–6155, 2025
2025
-
[48]
Yilian Liu, Xiaojun Jia, Guoshun Nan, Jiuyang Lyu, Zhican Chen, Tao Guan, Shuyuan Luo, Zhongyi Zhai, and Yang Liu. Midas: Multi-image dispersion and semantic reconstruction for jailbreaking mllms.arXiv preprint arXiv:2603.00565, 2026
arXiv 2026
-
[49]
Zhixue Song, Boyan Han, Yiwei Wang, and Chi Zhang. Hard to read, easy to jailbreak: How visual degradation bypasses mllm safety alignment.arXiv preprint arXiv:2605.07250, 2026. 14 PHANTOM: A Large-Scale Dataset of Multimodal Adversarial Attacks for Vision-Language Models
Pith/arXiv arXiv 2026
-
[50]
Feder Cooper, Solon Barocas, Abhinav Palia, Dan Vann, and Hanna Wal- lach
Alex Chouldechova, A. Feder Cooper, Solon Barocas, Abhinav Palia, Dan Vann, and Hanna Wal- lach. Comparison requires valid measurement: Rethinking attack success rate comparisons in ai red teaming. In D. Belgrave, C. Zhang, H. Lin, R. Pascanu, P. Koniusz, M. Ghassemi, and N. Chen, editors,Advances in Neural Information Processing Systems, volume 38. Curra...
2025
-
[51]
Leo Schwinn, Moritz Ladenburger, Tim Beyer, Mehrnaz Mofakhami, Gauthier Gidel, and Stephan Günnemann. A coin flip for safety: Llm judges fail to reliably measure adversarial robustness.arXiv preprint arXiv:2603.06594, 2026
arXiv 2026
-
[52]
Low-resource languages jailbreak gpt-4.arXiv preprint arXiv:2310.02446, 2023
Zheng-Xin Yong, Cristina Menghini, and Stephen H Bach. Low-resource languages jailbreak gpt-4.arXiv preprint arXiv:2310.02446, 2023
Pith/arXiv arXiv 2023
-
[53]
Multilingual blending: Large language model safety alignment evaluation with language mixture
Jiayang Song, Yuheng Huang, Zhehua Zhou, and Lei Ma. Multilingual blending: Large language model safety alignment evaluation with language mixture. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 3433–3449, 2025
2025
-
[54]
Lawrence Zitnick
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. Microsoft coco: Common objects in context. In David Fleet, Tomas Pajdla, Bernt Schiele, and Tinne Tuytelaars, editors,Computer Vision – ECCV 2014, pages 740–755, Cham, 2014. Springer International Publishing. ISBN 978-3-319-10602-1
2014
-
[55]
Huihui-qwen3.5-9b-abliterated,
huihui-ai. Huihui-qwen3.5-9b-abliterated, . URL https://huggingface.co/huihui-ai/Huihui-Qwen3. 5-9B-abliterated. Hugging Face model
-
[56]
Huihui-gemma-4-31b-it-abliterated,
huihui-ai. Huihui-gemma-4-31b-it-abliterated, . URL https://huggingface.co/huihui-ai/ Huihui-gemma-4-31B-it-abliterated. Hugging Face model
-
[57]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
2014
-
[58]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 15 PHANTOM: A Large-Scale Dataset of Multimodal Advers...
arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.