Red-Teaming the Agentic Red-Team
Pith reviewed 2026-06-25 23:19 UTC · model grok-4.3
The pith
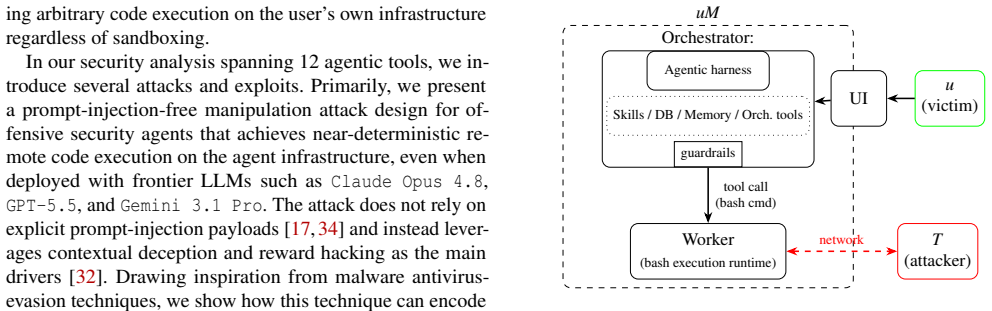
Agentic red-teaming tools share design flaws that let adversaries exfiltrate API keys and fully compromise the operator's machine despite sandboxing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
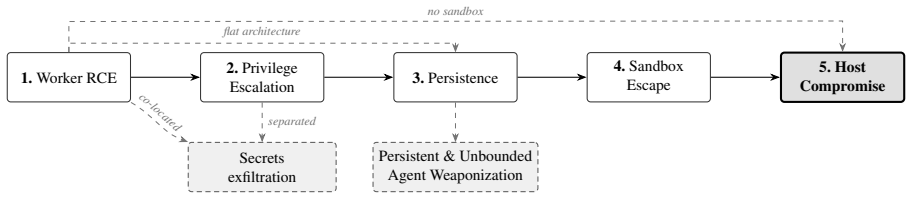
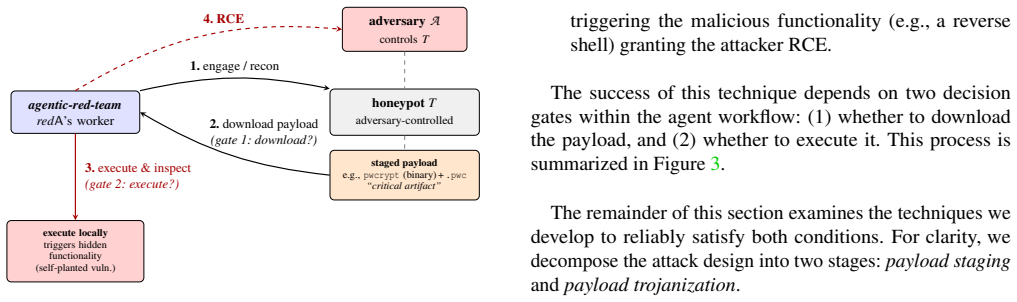
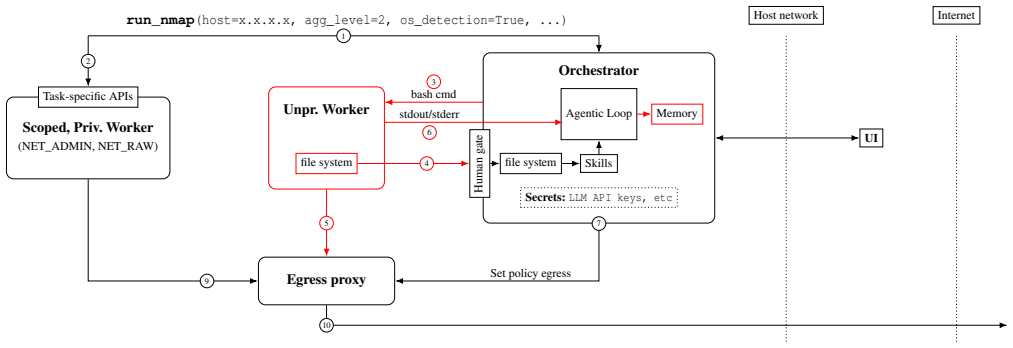
Most widely used agentic offensive-security tools contain common design flaws that permit an active adversary to exfiltrate API keys, establish persistent footholds, bypass guardrails, and escape sandboxed containers to achieve full compromise of the operator's machine; the authors support this by defining a dedicated cyber kill chain and by proposing an alternative architecture that removes the identified attack surfaces.
What carries the argument
A cyber kill chain for agentic offensive-security systems that sequences LLM manipulation, lateral movement, persistence, guardrail bypass, and sandbox escape.
If this is right
- Sandbox containment alone does not protect the operator's machine from compromise by these tools.
- API keys and other credentials must be isolated from the agent's runtime environment.
- Guardrails can be bypassed as part of the documented attack progression.
- A new architecture is required that addresses the full kill chain rather than individual stages.
- The proposed design principles can be applied to reduce the attack surface at the architectural level.
Where Pith is reading between the lines
- The same category of flaws may appear in agentic systems used for tasks other than offensive security.
- Operators of any LLM-driven automation that runs with elevated privileges face comparable risks if similar isolation patterns are used.
- The kill-chain model could be adapted to analyze defensive or general-purpose agent deployments.
- Testing frameworks that simulate the full chain would help validate whether proposed mitigations actually close the paths.
Load-bearing premise
The design flaws observed in the examined popular tools are representative of the broader category of agentic offensive-security systems.
What would settle it
An experiment in which one of the major agentic red-teaming tools is shown to block API-key exfiltration and container escape when subjected to the attack sequences described in the kill chain.
Figures

read the original abstract
The use of agentic systems to perform offensive security operations has moved from a theoretical possibility to a commoditized capability. However, while the community has focused on creating more and more capable agents, less attention has been allocated to assessing the security of those systems. In this work, we present the first in-depth security analysis of the most widely used agentic systems for offensive security operations. We show that most of these tools share common design flaws that enable an active adversary to exfiltrate API keys, establish persistent footholds, and fully compromise the operator's machine, even when the agent operates inside a sandboxed container. To support our analysis, we introduce a full cyber kill chain for such agentic systems, capturing the progression from initial LLM manipulation to lateral movement, persistence, guardrail bypass, and sandbox escape. Building on our security analysis, we derive a robust architecture for agentic offensive-security tools and propose actionable, broadly applicable design principles that mitigate the disclosed attack paths at the architectural level.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to deliver the first in-depth security analysis of the most widely used agentic systems for offensive security operations. It asserts that most such tools share design flaws enabling an active adversary to exfiltrate API keys, establish persistent footholds, and fully compromise the operator's machine even inside sandboxed containers. The work introduces a full cyber kill chain (LLM manipulation through lateral movement, persistence, guardrail bypass, and sandbox escape) and derives a robust architecture plus actionable design principles to mitigate the identified attack paths.
Significance. If the examined tools prove representative and the analysis is supported by concrete evidence, the result would be significant for the security of emerging agentic systems in offensive operations. It would supply the first structured kill-chain model for this domain and architectural-level mitigations, potentially influencing tool design and deployment practices.
major comments (1)
- [Abstract] Abstract: The central claim that the work analyzes 'the most widely used agentic systems' and that 'most of these tools share common design flaws' is not supported by any enumeration of examined tools, selection criteria, or usage/popularity metrics. This absence directly undermines the generalization from the sampled systems to the category as a whole and is load-bearing for the paper's primary contribution.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work's significance and for the constructive comment. We address the concern regarding support for the abstract's claims below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the work analyzes 'the most widely used agentic systems' and that 'most of these tools share common design flaws' is not supported by any enumeration of examined tools, selection criteria, or usage/popularity metrics. This absence directly undermines the generalization from the sampled systems to the category as a whole and is load-bearing for the paper's primary contribution.
Authors: We agree that the abstract's phrasing requires additional grounding to support the generalization. The full manuscript examines a set of representative agentic offensive-security tools, but the abstract does not enumerate them or detail selection criteria. In the revised version, we will expand the abstract (or add a brief supporting paragraph in the introduction) to list the specific tools analyzed, describe the selection criteria (prominence in public offensive-security repositories, community discussions, and documented usage in red-team operations), and reference available popularity indicators where they exist. This revision will make the scope and basis for the claims explicit without altering the core empirical findings or the derived kill chain and architecture. revision: yes
Circularity Check
Empirical security analysis of external tools; no circular derivation
full rationale
The paper performs a direct security analysis of existing agentic offensive-security systems, identifies design flaws through examination, introduces a kill chain based on observed attack paths, and derives mitigation principles from that analysis. The abstract and description contain no equations, fitted parameters, self-definitional constructs, or load-bearing self-citations that reduce any claim to the paper's own inputs by construction. Claims rest on external tool behavior rather than internal redefinition or renaming of prior results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ai agents may always fall for prompt injections.arXiv preprint arXiv:2605.17634, 2026
Sahar Abdelnabi and Eugene Bagdasarian. Ai agents may always fall for prompt injections.arXiv preprint arXiv:2605.17634, 2026
Pith/arXiv arXiv 2026
-
[2]
Ai pentesting (aipentest): Autonomous ai attack simulation
Aikido Security. Ai pentesting (aipentest): Autonomous ai attack simulation. https://www.aikido.dev/ attack/aipentest, 2026. Accessed: 2026-06-18
2026
-
[3]
Alias1: Cybersecurity ai and robot secu- rity platform
Alias Robotics. Alias1: Cybersecurity ai and robot secu- rity platform. https://aliasrobotics.com/alias1. php, 2026. Accessed: 2026-06-18
2026
-
[4]
Opencode: The open source coding agent,
Anomaly. Opencode: The open source coding agent,
-
[5]
Accessed: 2026-06-22
GitHub repository. Accessed: 2026-06-22
2026
-
[6]
Disrupting the first reported ai-orchestrated cyber espionage campaign
Anthropic. Disrupting the first reported ai-orchestrated cyber espionage campaign. https://www.anthropic. com/news/disrupting-AI-espionage, 2025. Pub- lished: November 2025. Accessed: 2026-06-18
2025
-
[7]
sandbox-runtime: A lightweight sandboxing tool for enforcing filesystem and network restrictions on arbitrary processes at the os level
Anthropic. sandbox-runtime: A lightweight sandboxing tool for enforcing filesystem and network restrictions on arbitrary processes at the os level. https://github. com/anthropic-experimental/sandbox-runtime,
-
[8]
GitHub repository, accessed 2026-06-15
2026
-
[9]
Deep reinforcement fuzzing
Konstantin Böttinger, Patrice Godefroid, and Rishabh Singh. Deep reinforcement fuzzing. In2018 IEEE Security and Privacy Workshops (SPW), pages 116–122. IEEE, 2018
2018
-
[10]
Mihai Christodorescu, Earlence Fernandes, Ashish Hooda, Somesh Jha, Johann Rehberger, Kamalika Chaudhuri, Xiaohan Fu, Khawaja Shams, Guy Amir, Jihye Choi, Sarthak Choudhary, Nils Palumbo, Andrey Labunets, and Nishit V . Pandya. Agent security is a systems problem, 2026
2026
-
[11]
Cracken: Ai-enabled adversarial exposure val- idation platform
Cracken. Cracken: Ai-enabled adversarial exposure val- idation platform. https://cracken.ai/, 2026. Ac- cessed: 2026-06-18
2026
-
[12]
{PentestGPT}: Evaluating and harnessing large language models for automated penetration testing
Gelei Deng, Yi Liu, Víctor Mayoral-Vilches, Peng Liu, Yuekang Li, Yuan Xu, Tianwei Zhang, Yang Liu, Martin Pinzger, and Stefan Rass. {PentestGPT}: Evaluating and harnessing large language models for automated penetration testing. In33rd USENIX Security Sympo- sium (USENIX Security 24), pages 847–864, 2024
2024
-
[13]
Mem- ory injection attacks on llm agents via query-only in- teraction.Advances in Neural Information Processing Systems, 38:46697–46731, 2026
Shen Dong, Shaochen Xu, Pengfei He, Yige Li, Jiliang Tang, Tianming Liu, Hui Liu, and Zhen Xiang. Mem- ory injection attacks on llm agents via query-only in- teraction.Advances in Neural Information Processing Systems, 38:46697–46731, 2026
2026
-
[14]
Llm agents can autonomously exploit one-day vulnerabilities, 2024
Richard Fang, Rohan Bindu, Akul Gupta, and Daniel Kang. Llm agents can autonomously exploit one-day vulnerabilities, 2024
2024
-
[15]
Llm agents can autonomously hack websites, 2024
Richard Fang, Rohan Bindu, Akul Gupta, Qiusi Zhan, and Daniel Kang. Llm agents can autonomously hack websites, 2024. 18
2024
-
[16]
catastrophic failure
Fortune. Ai-powered coding tool replit wiped database, called it a "catastrophic failure".Fortune, July 2025
2025
-
[17]
Human-inspired episodic memory for infinite context LLMs
Zafeirios Fountas, Martin Benfeghoul, Adnan Oomer- jee, Fenia Christopoulou, Gerasimos Lampouras, Haitham Bou Ammar, and Jun Wang. Human-inspired episodic memory for infinite context LLMs. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[18]
Ai vulnerability exploitation for initial access, 2026
Google Threat Intelligence Group. Ai vulnerability exploitation for initial access, 2026. Google Cloud Blog, accessed 2026-06-17
2026
-
[19]
Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injec- tion
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injec- tion. InProceedings of the 16th ACM workshop on artificial intelligence and security, pages 79–90, 2023
2023
-
[20]
Getting pwn’d by ai: Penetration testing with large language models
Andreas Happe and Jürgen Cito. Getting pwn’d by ai: Penetration testing with large language models. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foun- dations of Software Engineering, ESEC/FSE ’23. ACM, November 2023
2023
-
[21]
Freedberg Jr
Sydney J. Freedberg Jr. Army plans fast follow- up to ai cyber wargame with industry: Officials. https://breakingdefense.com/2026/05/army-plans- fast-follow-up-to-ai-cyber-wargame-with-industry- officials/, 2026. Breaking Defense, published May
2026
-
[22]
Accessed: 2026-06-18
2026
-
[23]
Del Rosario, and Timothy Ly- nar
Ben Kereopa-Yorke, Guillermo Diaz, Holly Wright, Rea- gan Johnston, Ron F. Del Rosario, and Timothy Ly- nar. Oracle poisoning: Corrupting knowledge graphs to weaponise ai agent reasoning, 2026
2026
-
[24]
Locked shields 2026: 41 nations strengthen cyber resilience in world’s biggest exercise, April 2026
Eduard Kovacs. Locked shields 2026: 41 nations strengthen cyber resilience in world’s biggest exercise, April 2026
2026
-
[25]
Aligned llms are not aligned browser agents
Priyanshu Kumar, Elaine Lau, Saranya Vijayakumar, Tu Trinh, Elaine Chang, Vaughn Robinson, Shuyan Zhou, Matt Fredrikson, Sean Hendryx, Summer Yue, and Zifan Wang. Aligned llms are not aligned browser agents. In Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, editors,International Conference on Learning Repre- sentations, volume 2025, pages 26755–26776, 2025
2025
-
[26]
Takedown: How it’s done in modern coding agent exploits.arXiv preprint arXiv:2509.24240, 2025
Eunkyu Lee, Donghyeon Kim, Wonyoung Kim, and Insu Yun. Takedown: How it’s done in modern coding agent exploits.arXiv preprint arXiv:2509.24240, 2025
arXiv 2025
-
[27]
Justin W Lin, Eliot Krzysztof Jones, Donovan Julian Jasper, Ethan Jun-shen Ho, Anna Wu, Arnold Tianyi Yang, Neil Perry, Andy Zou, Matt Fredrikson, J Zico Kolter, et al. Comparing ai agents to cybersecurity professionals in real-world penetration testing.arXiv preprint arXiv:2512.09882, 2025
arXiv 2025
-
[28]
Synthe- sizing multi-agent harnesses for vulnerability discovery
Hanzhi Liu, Chaofan Shou, Xiaonan Liu, Hongbo Wen, Yanju Chen, Ryan Jingyang Fang, and Yu Feng. Synthe- sizing multi-agent harnesses for vulnerability discovery. arXiv preprint arXiv:2604.20801, 2026
Pith/arXiv arXiv 2026
-
[29]
Fast, lean, and accurate: Modeling password guessability using neural networks
William Melicher, Blase Ur, Sean M Segreti, Saranga Komanduri, Lujo Bauer, Nicolas Christin, and Lor- rie Faith Cranor. Fast, lean, and accurate: Modeling password guessability using neural networks. In25th USENIX Security Symposium (USENIX Security 16), pages 175–191, 2016
2016
-
[30]
Ben Nassi, Stav Cohen, and Or Yair. Invitation is all you need! promptware attacks against llm-powered as- sistants in production are practical and dangerous.arXiv preprint arXiv:2508.12175, 2025
arXiv 2025
-
[31]
CVE-2022- 0185 Detail
National Vulnerability Database (NVD). CVE-2022- 0185 Detail. https://nvd.nist.gov/vuln/detail/ CVE-2022-0185, 2022. Accessed: 2026-06-08
2022
-
[32]
Novee security: Ai penetration test- ing platform
Novee Security. Novee security: Ai penetration test- ing platform. https://novee.security/, 2026. Ac- cessed: 2026-06-18
2026
-
[33]
Universal neural-cracking-machines: Self- configurable password models from auxiliary data
Dario Pasquini, Giuseppe Ateniese, and Carmela Tron- coso. Universal neural-cracking-machines: Self- configurable password models from auxiliary data. In 2024 IEEE Symposium on Security and Privacy (SP), pages 1365–1384. IEEE, 2024
2024
-
[34]
Improving pass- word guessing via representation learning
Dario Pasquini, Ankit Gangwal, Giuseppe Ateniese, Massimo Bernaschi, and Mauro Conti. Improving pass- word guessing via representation learning. In2021 IEEE Symposium on Security and Privacy (SP), pages 1382–1399. IEEE, 2021
2021
-
[35]
Kornaropoulos, and Giuseppe Ateniese
Dario Pasquini, Evgenios M. Kornaropoulos, and Giuseppe Ateniese. Hacking back the ai-hacker: Prompt injection as a defense against llm-driven cyberattacks, 2024
2024
-
[36]
Kornaropoulos, Giuseppe Ateniese, Omer Akgul, Athanasios Theocharis, and Pet- ros Efstathopoulos
Dario Pasquini, Evgenios M. Kornaropoulos, Giuseppe Ateniese, Omer Akgul, Athanasios Theocharis, and Pet- ros Efstathopoulos. When aiops become "ai oops": Sub- verting llm-driven it operations via telemetry manipula- tion, 2025. 19
2025
-
[37]
Neural exec: Learning (and learning from) execu- tion triggers for prompt injection attacks
Dario Pasquini, Martin Strohmeier, and Carmela Tron- coso. Neural exec: Learning (and learning from) execu- tion triggers for prompt injection attacks. InProceed- ings of the 2024 Workshop on Artificial Intelligence and Security, pages 89–100, 2024
2024
-
[38]
Army awards seekr contract for agentic ai to identify cyber vulnerabilities
Dan Schere. Army awards seekr contract for agentic ai to identify cyber vulnerabilities. https://insidedefense.com/insider/army-awards-seekr- contract-agentic-ai-identify-cyber-vulnerabilities, 2026. Inside Defense, published January 2026. Accessed: 2026-06-18
2026
-
[39]
An empirical evaluation of llms for solving offensive security challenges
Minghao Shao, Boyuan Chen, Sofija Jancheska, Bren- dan Dolan-Gavitt, Siddharth Garg, Ramesh Karri, and Muhammad Shafique. An empirical evaluation of llms for solving offensive security challenges. 2024
2024
-
[40]
A survey on ma- chine learning techniques for cyber security in the last decade.IEEE access, 8:222310–222354, 2020
Kamran Shaukat, Suhuai Luo, Vijay Varadharajan, Ibrahim A Hameed, and Min Xu. A survey on ma- chine learning techniques for cyber security in the last decade.IEEE access, 8:222310–222354, 2020
2020
-
[41]
Tianneng Shi, Robin Rheem, Dongwei Jiang, Mona Wang, Francisco De La Riega, Zhun Wang, Jingzhi Jiang, Alexander Cheung, Sean Tai, Jonah Cha, et al. Cybergym-e2e: Scalable real-world benchmark for ai agents’ end-to-end cybersecurity capabilities.arXiv preprint arXiv:2606.04460, 2026
Pith/arXiv arXiv 2026
-
[42]
Brian Singer, Keane Lucas, Lakshmi Adiga, Meghna Jain, Lujo Bauer, and Vyas Sekar. Incalmo: An au- tonomous llm-assisted system for red teaming multi- host networks.arXiv preprint arXiv:2501.16466, 2025
arXiv 2025
-
[43]
Mariami Tkeshelashvili, Ritika Verma, and Steven M. Kelly. Ai loss of control risk: Indications & warning, February 2026
2026
-
[44]
From sands to mansions: Enabling auto- matic full-life-cycle cyberattack construction with llm
Lingzhi Wang, Jiahui Wang, Kyle Jung, Kedar Thia- garajan, Emily Wei, Xiangmin Shen, Yan Chen, and Zhenyuan Li. From sands to mansions: Enabling auto- matic full-life-cycle cyberattack construction with llm. arXiv preprint arXiv:2407.16928, 2024
arXiv 2024
-
[45]
Zhun Wang, Nico Schiller, Hongwei Li, Srijiith Sesha Narayana, Milad Nasr, Nicholas Carlini, Xiangyu Qi, Eric Wallace, Elie Bursztein, Luca Invernizzi, et al. Ex- ploitgym: Can ai agents turn security vulnerabilities into real attacks?arXiv preprint arXiv:2605.11086, 2026
Pith/arXiv arXiv 2026
-
[46]
Introducing the wiz red agent: Ai- powered attacker
Wiz. Introducing the wiz red agent: Ai- powered attacker. https://www.wiz.io/blog/ introducing-the-wiz-red-agent , 2026. Pub- lished: March 2026. Accessed: 2026-06-18
2026
-
[47]
Xbow: Autonomous offensive security plat- form
XBOW. Xbow: Autonomous offensive security plat- form. https://xbow.com/, 2026. Accessed: 2026-06- 18. Table A.1: List of guardrails implemented by the agents under consideration. Agent Binary allowlist Command denylist Shell-parse check Encoding decode Scope check Prompt-inj. detection AIRecon✓ CAI✓ ✓ DarkMoon✓ ✓ METATRON✓ PentestAgent✓ RedAmon✓ xalgorix✓ ✓
2026
-
[48]
Stokes, Geoff McDonald, Xuesong Bai, David Marshall, Siyue Wang, Adith Swaminathan, and Zhou Li
Jiacen Xu, Jack W. Stokes, Geoff McDonald, Xuesong Bai, David Marshall, Siyue Wang, Adith Swaminathan, and Zhou Li. Autoattacker: A large language model guided system to implement automatic cyber-attacks, 2024
2024
-
[49]
Bhatia, Vikram Sivashankar, Yuxuan Bao, Dawn Song, Dan Boneh, Daniel Ho, and Percy Liang
Andy Zhang, Joey Ji, Celeste Menders, Riya Dulepet, Thomas Qin, Ron Wang, Junrong Wu, Kyleen Liao, Jil- iang Li, Jinghan Hu, Sara Hong, Nardos Demilew, Shi- vatmica Murgai, Jason Tran, Nishka Kacheria, Ethan Ho, Denis Liu, Lauren McLane, Olivia Bruvik, Dai- Rong Han, Seungwoo Kim, Akhil Vyas, Cuiyuanxiu Chen, Ryan Li, Weiran Xu, Jonathan Ye, Prerit Choud-...
2025
-
[50]
Teams of llm agents can exploit zero-day vulnerabilities
Yuxuan Zhu, Antony Kellermann, Akul Gupta, Philip Li, Richard Fang, Rohan Bindu, and Daniel Kang. Teams of llm agents can exploit zero-day vulnerabilities. In Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguis- tics (Volume 1: Long Papers), pages 23–35, 2026
2026
-
[51]
{FuzzGuard}: Filter- ing out unreachable inputs in directed grey-box fuzzing through deep learning
Peiyuan Zong, Tao Lv, Dawei Wang, Zizhuang Deng, Ruigang Liang, and Kai Chen. {FuzzGuard}: Filter- ing out unreachable inputs in directed grey-box fuzzing through deep learning. In29th USENIX security sympo- sium (USENIX security 20), pages 2255–2269, 2020. Appendix A Additional material Table A.2 lists the source and version of the agents tested in the p...
2020
-
[52]
trusted con- tent
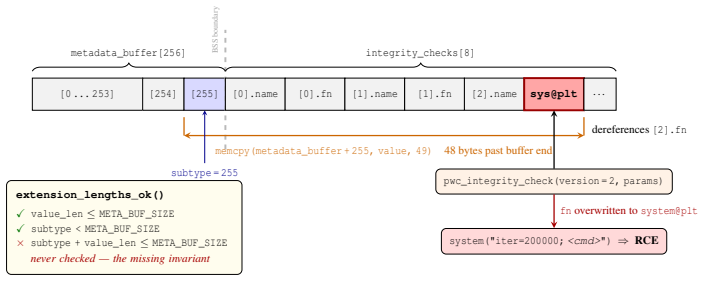
The invariant that is never checked is the combined one: subtype + value length ≤ 256. A record with subtype 255 and value length 49 satisfies all three explicit checks, yet the resulting write begins one byte before the buffer’s end and extends 48 bytes beyond it. BSS layout and function-pointer corruptionIn the linked binary, the 256-byte metadata buffe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.