EERLoss: A Novel Loss Function for Training Deep Biometric Models. A Case Study in Keystroke Dynamics
Pith reviewed 2026-06-26 00:25 UTC · model grok-4.3
The pith
EERLoss approximates the Equal Error Rate in a subdifferentiable way to train deep biometric models directly on the target metric.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that EERLoss is a subdifferentiable, arbitrarily accurate approximation to the Equal Error Rate for use as a loss in training deep biometric models. In the case study of keystroke dynamics verification on the KVC-onGoing benchmark, models trained with EERLoss achieve better results than those trained with prior losses and show up to approximately 30% relative reduction in EER compared to the previous state of the art.
What carries the argument
EERLoss, a subdifferentiable approximation to EER that enables direct gradient-based optimization of the Equal Error Rate.
If this is right
- EERLoss outperforms state-of-the-art loss functions in ablation studies on keystroke dynamics.
- It leads to substantially faster convergence, reducing training cost.
- Applying it to the KVC-winning architecture produces significant EER improvements.
- The loss framework supports optimization at any chosen operating point on the DET curve.
Where Pith is reading between the lines
- The method may apply to other biometric modalities with similar variability issues.
- Direct EER optimization could simplify system design by reducing the gap between training and deployment metrics.
- Faster convergence might allow for more extensive hyperparameter searches or larger models within the same compute budget.
- If the approximation holds, it could inspire similar differentiable proxies for other threshold-based metrics in machine learning.
Load-bearing premise
The approximation of EER must be close enough to the true value that gradient descent on the approximation improves the actual EER without being misled by approximation errors.
What would settle it
If a model trained using EERLoss shows a decreasing loss value but no corresponding decrease in the true Equal Error Rate computed on a separate test set, this would indicate the approximation is not guiding effective optimization.
Figures
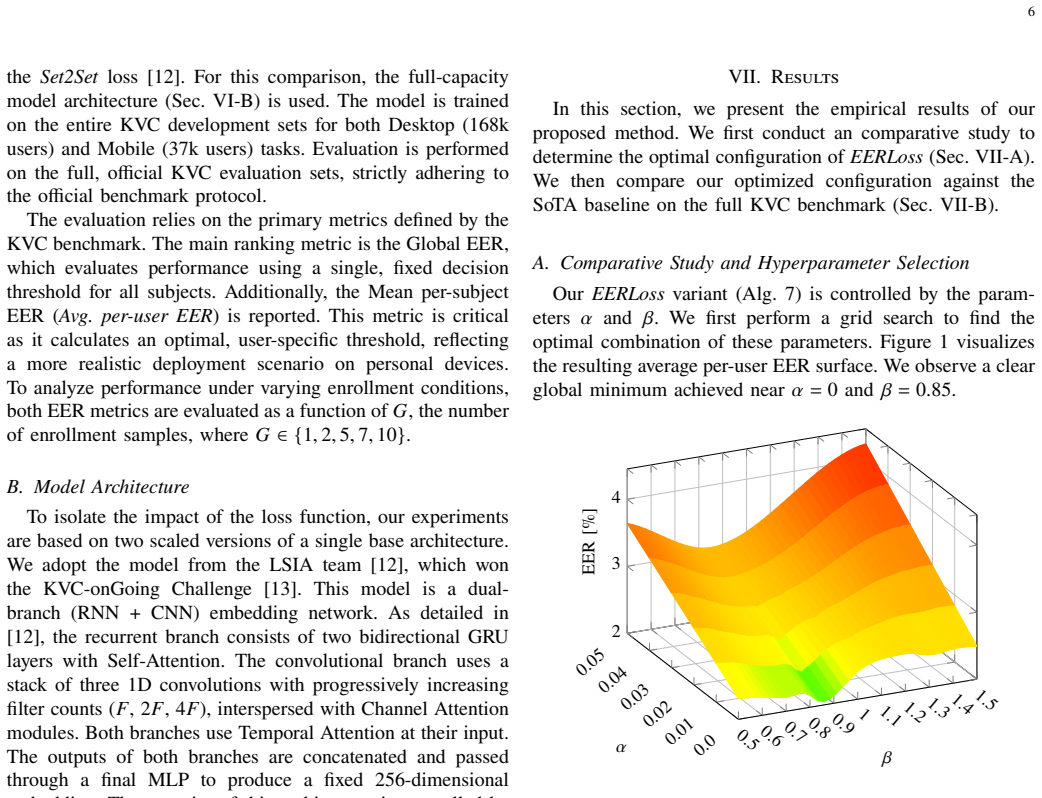
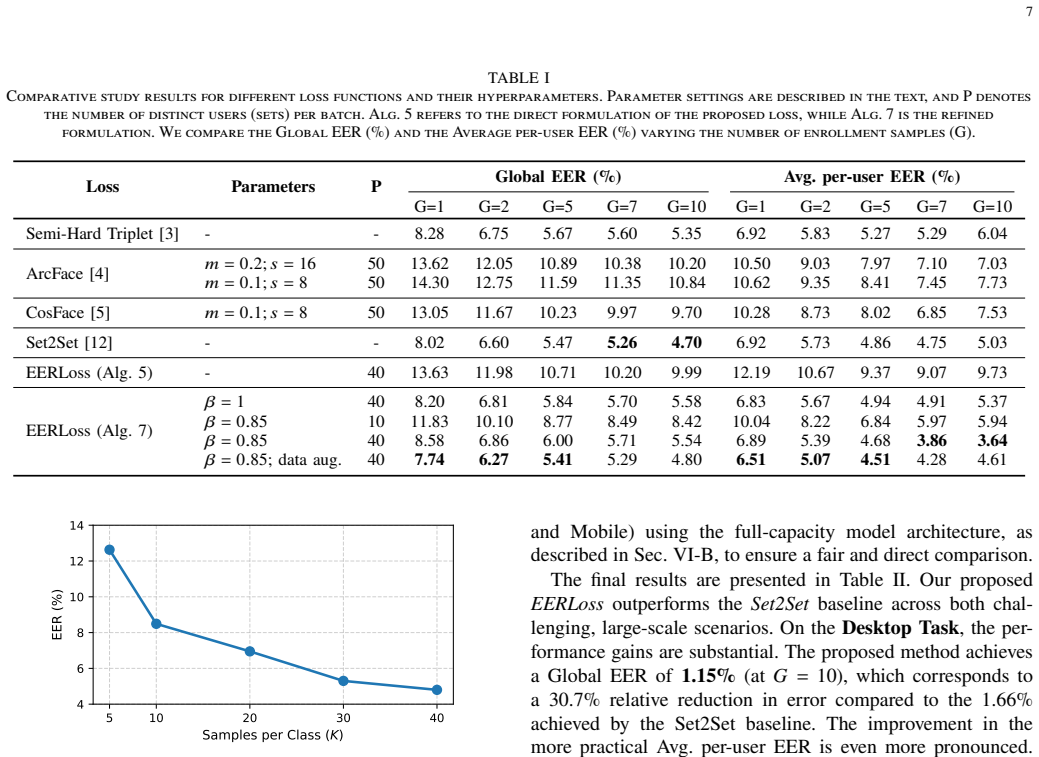
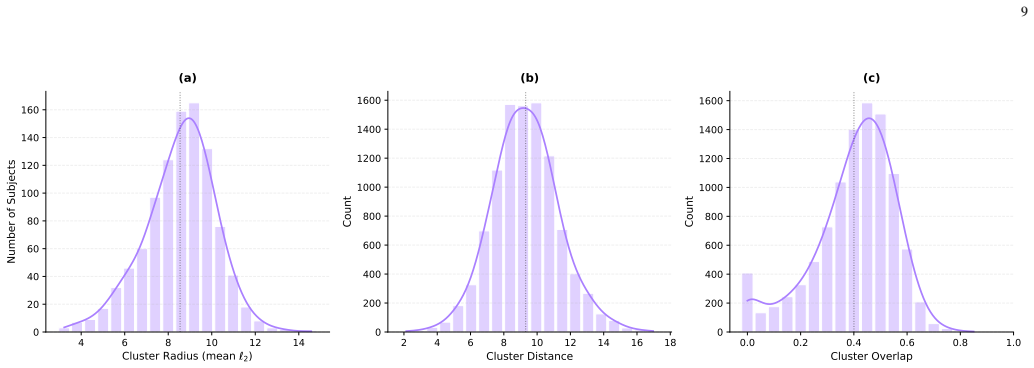

read the original abstract
Deep learning approaches to biometric verification are commonly trained by optimizing indirect objectives, creating a misalignment between the optimization process and the primary evaluation metric, typically the Equal Error Rate (EER). This paper introduces EERLoss: a subdifferentiable, arbitrarily accurate approximation to EER for training deep biometric models. Furthermore, this framework has the potential to be adapted to optimize any specific operating point on the DET curve, enhancing its generalizability. To validate this approach, EERLoss is evaluated on a particularly demanding behavioral biometric modality: keystroke dynamics verification. This task is characterized by its high intra-class and low inter-class variability. Experiments are conducted on the large-scale KVC-onGoing benchmark, incorporating data from over 185,000 subjects across different scenarios. A comprehensive ablation study initially demonstrates the superiority of EERLoss in comparison to existing state-of-the-art loss functions. It also converges substantially faster compared to other losses, reducing the overall training cost. Additionally, a comparison is made between the proposed loss and the KVC-winning architecture by re-training it with EERLoss, demonstrating that the proposed approach significantly outperforms the original SoTA, achieving a relative EER reduction of up to approx. 30\%. This improvement on a challenging, large-scale benchmark validates the effectiveness of EERLoss as a task-aligned training objective specifically suited for high-variance biometric traits.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EERLoss, a subdifferentiable and arbitrarily accurate approximation to the Equal Error Rate (EER) intended as a training objective for deep biometric verification models. It evaluates the approach on keystroke dynamics verification using the large-scale KVC-onGoing benchmark (185k+ subjects), reporting ablation superiority over existing losses, faster convergence, and up to ~30% relative EER reduction when re-training the prior KVC-winning architecture.
Significance. If the approximation's gradients reliably improve the true (non-differentiable) EER without exploiting surrogate artifacts, the result would be significant for biometric model training by closing the gap between optimization objective and evaluation metric. The large subject count and cross-scenario evaluation on a high-variance modality provide a strong empirical test bed; explicit credit is due for the scale of the benchmark and the direct comparison against the prior winning architecture.
major comments (2)
- [Abstract] Abstract: the central claim that EERLoss yields gradients that improve true EER (rather than approximation artifacts) rests on experimental outcomes whose controls are not visible; no ablation on the accuracy hyperparameter, no surrogate-true alignment analysis, and no verification that the reported EER protocol matches the loss definition are provided, which is load-bearing for the 30% relative improvement assertion.
- [Abstract] Abstract: the assertion of an 'arbitrarily accurate' subdifferentiable approximation is presented without derivation details, error bounds, or analysis of bias growth with model capacity/training steps, leaving open whether optimization drives the surrogate down while true EER plateaus.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of the presentation and validation of EERLoss. We address each major comment below and will revise the manuscript to provide the requested controls, derivations, and analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that EERLoss yields gradients that improve true EER (rather than approximation artifacts) rests on experimental outcomes whose controls are not visible; no ablation on the accuracy hyperparameter, no surrogate-true alignment analysis, and no verification that the reported EER protocol matches the loss definition are provided, which is load-bearing for the 30% relative improvement assertion.
Authors: We agree that explicit controls are needed to support the claim that gradients improve the true EER. In the revised version we will add an ablation on the accuracy hyperparameter, include a surrogate-true EER alignment plot over training, and explicitly document that the loss definition matches the EER protocol used in the KVC-onGoing benchmark (standard threshold sweep on the DET curve). These additions will be placed in the experimental section and will directly address the load-bearing nature of the 30% relative improvement result. revision: yes
-
Referee: [Abstract] Abstract: the assertion of an 'arbitrarily accurate' subdifferentiable approximation is presented without derivation details, error bounds, or analysis of bias growth with model capacity/training steps, leaving open whether optimization drives the surrogate down while true EER plateaus.
Authors: The current manuscript states the subdifferentiable approximation property but does not supply the requested supporting material. We will revise the method section to include the full derivation, analytic error bounds on the approximation, and an empirical study of bias as a function of model capacity and training steps. This analysis will also examine whether the surrogate and true EER remain aligned throughout optimization. revision: yes
Circularity Check
EERLoss derivation is self-contained; no circular reductions to inputs or self-citations.
full rationale
The paper defines EERLoss as a subdifferentiable approximation to the non-differentiable EER metric and validates it via ablation and re-training experiments on the external KVC-onGoing benchmark (185k+ subjects). No equations, parameters, or claims in the provided text reduce the reported EER gains to quantities fitted from the same runs or to self-citations. The central claim rests on independent experimental comparison rather than definitional equivalence or load-bearing self-reference.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Biometrics: A Tool for Informa- tion Security,
A. K. Jain, A. Ross, and S. Pankanti, “Biometrics: A Tool for Informa- tion Security,”IEEE Transactions on information forensics and security, 2006
2006
-
[2]
Learning a Similarity Metric Discriminatively, with Application to Face Verification,
S. Chopra, R. Hadsell, and Y. LeCun, “Learning a Similarity Metric Discriminatively, with Application to Face Verification,” inIn Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2005
2005
-
[3]
Learning a Distance Metric from Relative Comparisons,
M. Schultz and T. Joachims, “Learning a Distance Metric from Relative Comparisons,”Advances in neural information processing systems, 2003
2003
-
[4]
Arcface: Additive Angular Margin Loss for Deep Face Recognition,
J. Deng, J. Guo, N. Xueet al., “Arcface: Additive Angular Margin Loss for Deep Face Recognition,” inIn Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019
2019
-
[5]
Cosface: Large Margin Cosine Loss for Deep Face Recognition,
H. Wang, Y. Wang, Z. Zhouet al., “Cosface: Large Margin Cosine Loss for Deep Face Recognition,” inIn Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2018
2018
-
[6]
Adaface: Quality adaptive margin for face recognition,
M. Kim, A. K. Jain, and X. Liu, “Adaface: Quality adaptive margin for face recognition,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022
2022
-
[7]
Keystroke Dynamics: Concepts, Techniques, and Applications,
R. Shadman, A. A. Wahab, M. Mannoet al., “Keystroke Dynamics: Concepts, Techniques, and Applications,”ACM Computing Surveys, 2025
2025
-
[8]
M-GaitFormer:MobileBiometric Gait Verification Using Transformers,
P.Delgado-Santos,R.Tolosanaetal.,“M-GaitFormer:MobileBiometric Gait Verification Using Transformers,”Engineering Applications of Artificial Intelligence, 2023
2023
-
[9]
DeepSign: Deep On-Line Signature Verification,
R. Tolosana, R. Vera-Rodriguez, J. Fierrezet al., “DeepSign: Deep On-Line Signature Verification,”IEEE Transactions on Biometrics, Behavior, and Identity Science, 2021
2021
-
[10]
Signature Biometrics,
E. Maioranaet al., “Signature Biometrics,” inEncyclopedia of Cryptog- raphy, Security and Privacy. Springer, 2025. 11
2025
-
[11]
A Comprehensive Survey of Loss Functions and Metrics in Deep Learn- ing,
J. Terven, D.-M. Cordova-Esparza, J.-A. Romero-Gonzalezet al., “A Comprehensive Survey of Loss Functions and Metrics in Deep Learn- ing,”Artificial Intelligence Review, 2025
2025
-
[12]
Type2Branch: Keystroke Biometrics Based on a Dual-Branch Architecture With Atten- tion Mechanisms and Set2set Loss,
N. Gonzalez, G. Stragapede, R. Vera-Rodriguezet al., “Type2Branch: Keystroke Biometrics Based on a Dual-Branch Architecture With Atten- tion Mechanisms and Set2set Loss,”IEEE Transactions on Information Forensics and Security, 2025
2025
-
[13]
KVC-onGoing: Keystroke Verification Challenge,
G. Stragapede, R. Vera-Rodriguez, R. Tolosanaet al., “KVC-onGoing: Keystroke Verification Challenge,”Pattern Recognition, 2025
2025
-
[14]
Observations on Typing from 136 Million Keystrokes,
V. Dhakal, A. M. Feit, P. O. Kristenssonet al., “Observations on Typing from 136 Million Keystrokes,” inIn Proc. of the 2018 CHI Conference on Human Factors in Computing Systems, 2018
2018
-
[15]
How do People Type on Mobile Devices?ObservationsfromaStudywith37,000Volunteers,
K. Palin, A. M. Feit, S. Kimet al., “How do People Type on Mobile Devices?ObservationsfromaStudywith37,000Volunteers,”inInProc. of the 21st International Conference on Human-Computer Interaction with Mobile Devices and Services, 2019
2019
-
[16]
GREYC Keystroke: A Benchmark for Keystroke Dynamics Biometric Systems,
R. Giot, M. El-Abed, and C. Rosenberger, “GREYC Keystroke: A Benchmark for Keystroke Dynamics Biometric Systems,” inIn Proc. IEEE International Conference on Biometrics: Theory, Applications, and Systems, 2009
2009
-
[17]
RHU Keystroke: A Mobile- Based Benchmark for Keystroke Dynamics Systems,
M. El-Abed, M. Dafer, and R. El Khayat, “RHU Keystroke: A Mobile- Based Benchmark for Keystroke Dynamics Systems,”Proceedings - International Carnahan Conference on Security Technology, 2014
2014
-
[18]
Shared Dataset on Natural Human- Computer Interaction to Support Continuous Authentication Research,
C. Murphy, J. Huang, D. Houet al., “Shared Dataset on Natural Human- Computer Interaction to Support Continuous Authentication Research,” inIn Proc. IEEE International Joint Conference on Biometrics, 2017
2017
-
[19]
BeCAPTCHA: Behavioral Bot Detection using Touchscreen and Mobile Sensors benchmarked on HuMIdb,
A. Acien, A. Morales, J. Fierrezet al., “BeCAPTCHA: Behavioral Bot Detection using Touchscreen and Mobile Sensors benchmarked on HuMIdb,”Engineering Applications of Artificial Intelligence, 2021
2021
-
[20]
SetMargin Loss Applied to Deep Keystroke Biometrics with Circle Packing Interpretation,
A. Morales, J. Fierrez, A. Acienet al., “SetMargin Loss Applied to Deep Keystroke Biometrics with Circle Packing Interpretation,”Pattern Recognition, 2022
2022
-
[21]
Large Scale Online Learning of Image Similarity Through Ranking
G. Chechik, V. Sharma, U. Shalitet al., “Large Scale Online Learning of Image Similarity Through Ranking.”Journal of Machine Learning Research, vol. 11, no. 3, 2010
2010
-
[22]
Learning Face Representation from Scratch
D. Yi, Z. Lei, S. Liao, and S. Z. Li, “Learning Face Representation from Scratch,”arXiv preprint arXiv:1411.7923, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[23]
Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments,
G. B. Huang, M. Mattar, T. Berg, and E. Learned-Miller, “Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments,” inWorkshop on faces in’Real-Life’Images: detection, alignment, and recognition, 2008. XI. Biography Section Nahuel Gonzálezreceived his Ph.D. degree in Com- puting Science from Universidad Nacional de...
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.