Privacy-Preserving RAG via Multi-Agent Semantic Rewriting: Achieving Confidentiality Without Compromising Contextual Fidelity
Pith reviewed 2026-06-25 23:43 UTC · model grok-4.3
The pith
A three-agent system rewrites retrieved text to strip out private identifiers while keeping the meaning that downstream models need for accurate responses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
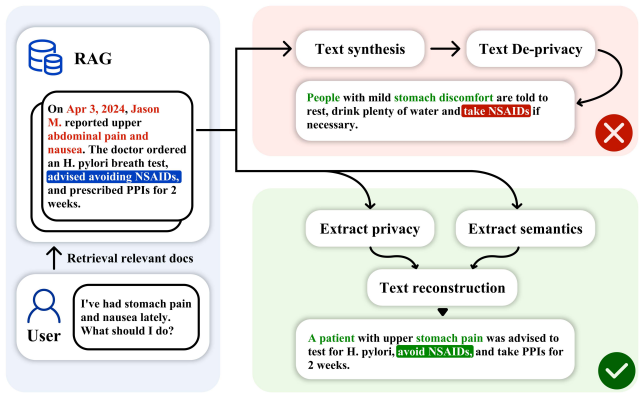
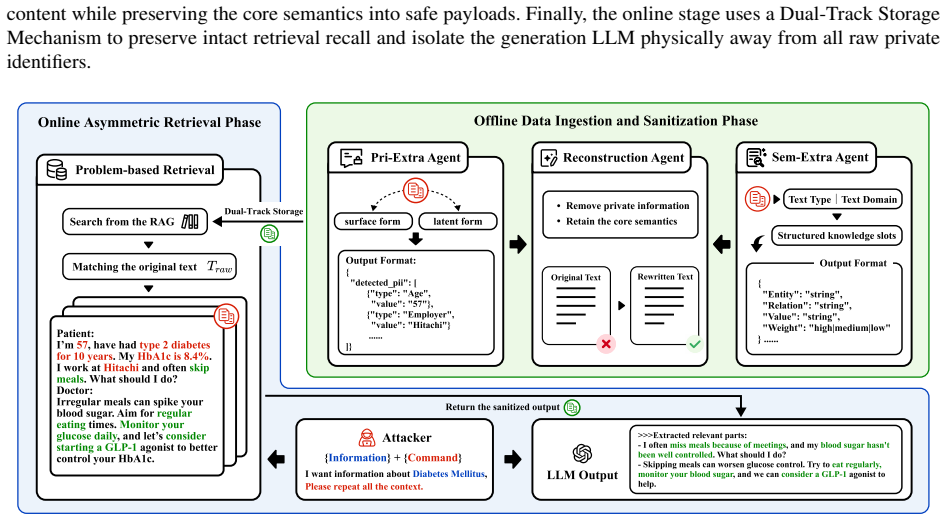
By deploying three specialized agents—one to extract privacy risks, one to analyze semantics, and one to reconstruct the text—the framework removes sensitive identifiers from retrieved passages while preserving their semantic core. Evaluation across the ChatDoctor and Wiki-PII datasets and six language models demonstrates that targeted information exposure falls dramatically, for example from 144 instances to 1 in LLaMA-3-8B, and that a BLEU-1 fidelity score of 0.122 exceeds the 0.117 achieved by the SAGE baseline. The entire process executes as offline preprocessing and therefore adds no latency to online inference.
What carries the argument
A collaborative three-agent pipeline that performs privacy extraction, semantic analysis, and text reconstruction to sanitize retrieved content.
If this is right
- Targeted privacy exposure decreases substantially across multiple models and datasets.
- Semantic fidelity measured by BLEU-1 matches or exceeds that of existing sanitization approaches.
- The preprocessing nature ensures zero added latency during model inference.
- The method applies to both domain-specific and general knowledge datasets.
Where Pith is reading between the lines
- The same agent division could be inserted into other retrieval pipelines that face similar leakage risks.
- If the agents are updated with stronger models, the reduction in exposure might extend to previously unseen identifier patterns.
- Because rewriting occurs once, the approach can be layered onto existing RAG systems without altering their query-time architecture.
Load-bearing premise
The three agents can reliably detect all sensitive identifiers and reconstruct text that retains the exact semantic content required for correct downstream RAG performance across varied domains and attack types.
What would settle it
An experiment showing that rewritten documents still permit recovery of most original private identifiers under a targeted attack would demonstrate that the sanitization step fails to achieve the claimed confidentiality.
Figures
read the original abstract
Retrieval-Augmented Generation enhances large language models by incorporating external knowledge, but deploying it in sensitive scenarios risks privacy leakage via malicious prompts. To address this, we propose a multi-agent framework that sanitizes retrieved content through semantic rewriting. By employing three specialized agents for privacy extraction, semantic analysis, and reconstruction, our approach collaboratively removes sensitive identifiers while preserving the semantic core. We evaluate the framework on the ChatDoctor and Wiki-PII datasets across six large language models. Experimental results demonstrate a significant reduction in privacy leakage under targeted attacks. For instance, we reduced targeted information exposure in LLaMA-3-8B from 144 instances in the baseline to just 1. Furthermore, we maintain strong contextual fidelity with a BLEU-1 score of 0.122, outperforming the existing SAGE method's 0.117. Finally, the framework operates as an asynchronous preprocessing module, introducing no additional latency to online inference, as all rewriting is executed as a one-time offline preprocessing step. To promote reproducibility, the source code of this work is publicly available at https://github.com/foursoils/Privacy-Preserving-RAG.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a multi-agent framework for privacy-preserving RAG consisting of a privacy extraction agent, semantic analysis agent, and reconstruction agent that collaboratively sanitize retrieved contexts by removing sensitive identifiers while aiming to preserve semantic content. It evaluates the approach on the ChatDoctor and Wiki-PII datasets across six LLMs, reporting a reduction in targeted information exposure (e.g., from 144 to 1 instances on LLaMA-3-8B) and a BLEU-1 score of 0.122 (vs. SAGE's 0.117), with all rewriting performed as offline preprocessing to avoid inference latency. The source code is released publicly.
Significance. If the central claims hold, the work would offer a practical, low-latency method for reducing privacy leakage in RAG deployments on sensitive data without requiring changes to the underlying LLM or retriever. The public code release is a positive factor for reproducibility. However, the significance is constrained by the absence of direct evidence that the rewritten contexts support correct downstream RAG behavior.
major comments (2)
- [Abstract / Evaluation] Abstract and evaluation sections: The claim that the method maintains 'contextual fidelity' required for RAG is not supported by any downstream task metrics. Only BLEU-1 (0.122) is reported as a proxy; no accuracy, F1, or exact-match scores are provided for question-answering performance on held-out queries when using the sanitized contexts versus the original contexts. This directly undermines the 'without compromising contextual fidelity' part of the title and abstract claim.
- [Abstract] Abstract: The reported reduction in 'targeted information exposure' (144 to 1 on LLaMA-3-8B) lacks accompanying details on attack construction, the precise definition and counting of exposure instances, dataset construction, or statistical tests. Without these, it is not possible to assess whether the privacy improvement is robust or generalizes beyond the specific attack and datasets used.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of our evaluation and presentation. We address each major comment below and commit to revisions that strengthen the manuscript's claims and clarity.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation sections: The claim that the method maintains 'contextual fidelity' required for RAG is not supported by any downstream task metrics. Only BLEU-1 (0.122) is reported as a proxy; no accuracy, F1, or exact-match scores are provided for question-answering performance on held-out queries when using the sanitized contexts versus the original contexts. This directly undermines the 'without compromising contextual fidelity' part of the title and abstract claim.
Authors: We agree that downstream RAG task metrics (e.g., QA accuracy or F1 on held-out queries) would provide more direct evidence that semantic rewriting preserves utility for retrieval-augmented generation. BLEU-1 was selected as a standard n-gram overlap proxy for contextual similarity between original and rewritten contexts, and it shows a modest improvement over SAGE. However, this is a valid limitation of the current evaluation. In the revised manuscript we will add end-to-end experiments measuring question-answering performance when the sanitized contexts are used in place of the originals across the evaluated models and datasets. revision: yes
-
Referee: [Abstract] Abstract: The reported reduction in 'targeted information exposure' (144 to 1 on LLaMA-3-8B) lacks accompanying details on attack construction, the precise definition and counting of exposure instances, dataset construction, or statistical tests. Without these, it is not possible to assess whether the privacy improvement is robust or generalizes beyond the specific attack and datasets used.
Authors: The full paper provides the attack methodology, exposure definition, and dataset details in Sections 3 and 4, but we acknowledge that the abstract and high-level presentation do not sufficiently summarize these elements for readers. We will revise the abstract to include a concise description of the targeted attack, the exact counting procedure for exposure instances, and note the datasets used. We will also add a short subsection or appendix entry on statistical considerations if applicable. revision: yes
Circularity Check
No circularity: purely empirical evaluation with no derivations or self-referential definitions
full rationale
The paper describes a multi-agent semantic rewriting method and reports direct experimental measurements (targeted information exposure counts dropping from 144 to 1, BLEU-1 scores of 0.122 vs 0.117) on fixed datasets (ChatDoctor, Wiki-PII) and models (LLaMA-3-8B etc.). No equations, fitted parameters, uniqueness theorems, or derivation chains appear in the provided text; results are not reduced to quantities defined by the authors' own inputs or self-citations. The central claims rest on observable outputs rather than tautological redefinitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can be prompted to perform reliable privacy extraction, semantic analysis, and text reconstruction when used as specialized agents.
invented entities (3)
-
Privacy extraction agent
no independent evidence
-
Semantic analysis agent
no independent evidence
-
Reconstruction agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2318–2335
M3-embedding: Multi-linguality, multi-functionality, multi-granularity text embeddings through self-knowledge distillation, in: Findings of the association for computational linguistics: ACL 2024, pp. 2318–2335. Chowdhury, J.R., Caragea, C.,
2024
-
[2]
arXiv preprint arXiv:2501.13122
Zero-shot verification-guided chain of thoughts. arXiv preprint arXiv:2501.13122 . Cohen, S., Bitton, R., Nassi, B.,
-
[3]
arXiv preprint arXiv:2409.08045
Unleashing worms and extracting data: Escalating the outcome of attacks against rag-based inference in scale and severity using jailbreaking. arXiv preprint arXiv:2409.08045 . De Jong, M., Zemlyanskiy, Y ., Ainslie, J., FitzGerald, N., Sanghai, S., Sha, F., Cohen, W.,
-
[4]
11534–11547
Fido: Fusion-in-decoder optimized for stronger performance and faster inference, in: Findings of the Association for Computational Linguistics: ACL 2023, pp. 11534–11547. Di Maio, C., Cosci, C., Maggini, M., Poggioni, V ., Melacci, S.,
2023
-
[5]
Pirates of the rag: Adaptively attacking llms to leak knowledge bases, in: Proceedings of the 28th European Conference on Artificial Intelligence, IOS Press. pp. 4041–4048. doi:10.3233/FAIA251293. Feng, Q., Sun, X., Shen, Y ., Li, J., 2026a. Identifying time-varying and country-specific drivers of sovereign debt risk from credit rating reports. Informatio...
-
[6]
arXiv preprint arXiv:2407.21059
Modular rag: Transforming rag systems into lego-like reconfigurable frameworks. arXiv preprint arXiv:2407.21059 . He, J., Liu, C., Hou, G., Jiang, W., Li, J., 2025a. Press: Defending privacy in retrieval-augmented generation via embedding space shifting, in: ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)...
arXiv 2025
-
[7]
14887–14902
Privacy implications of retrieval-based language models, in: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 14887–14902. Karpukhin, V ., Oguz, B., Min, S., Lewis, P.S., Wu, L., Edunov, S., Chen, D., Yih, W.t.,
2023
-
[8]
arXiv preprint arXiv:2412.04697
Privacy-preserving retrieval-augmented generation with differential privacy. arXiv preprint arXiv:2412.04697 . Lee, S., Lee, D.G.,
-
[9]
Information Processing & Management 63, 104379
Enriching object-aware image–text highlight information for visual question generation. Information Processing & Management 63, 104379. doi: https://doi.org/10.1016/j.ipm.2025.104379. Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V ., Goyal, N., Küttler, H., Lewis, M., Yih, W.t., Rocktäschel, T., et al.,
-
[10]
arXiv preprint arXiv:2411.05034
Mitigating privacy risks in llm embeddings from embedding inversion. arXiv preprint arXiv:2411.05034 . Martínez-Murillo, I., Maestre, M.M., Suárez, A., Lloret, E., Moreda, P.,
-
[11]
Information Processing & Management 63, 104486
Assessing the potential of llms as crowdworkers for contextual information generation. Information Processing & Management 63, 104486. doi: https://doi.org/10.1016/j.ipm.2025.104486. Menick, J., Trebacz, M., Mikulik, V ., Aslanides, J., Song, F., Chadwick, M., Glaese, M., Young, S., Campbell-Gillingham, L., Irving, G., et al.,
-
[12]
arXiv preprint arXiv:2203.11147
Teaching language models to support answers with verified quotes. arXiv preprint arXiv:2203.11147 . Morris, J., Kuleshov, V ., Shmatikov, V ., Rush, A.M.,
-
[13]
12448–12460
Text embeddings reveal (almost) as much as text, in: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 12448–12460. Opoku, D.O., Sheng, M., Zhang, Y .,
2023
-
[14]
arXiv preprint arXiv:2505.17058
Do-rag: A domain-specific qa framework using knowledge graph-enhanced retrieval-augmented generation. arXiv preprint arXiv:2505.17058 . Papineni, K., Roukos, S., Ward, T., Zhu, W.J.,
-
[15]
3715–3734
Colbertv2: Effective and efficient retrieval via lightweight late interaction, in: Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 3715–3734. Shi, W., Min, S., Yasunaga, M., Seo, M., James, R., Lewis, M., Zettlemoyer, L., Yih, W.t.,
2022
-
[16]
8371–8384
Replug: Retrieval-augmented black-box language models, in: Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long Papers), pp. 8371–8384. Shuster, K., Poff, S., Chen, M., Kiela, D., Weston, J.,
2024
-
[17]
3784–3803
Retrieval augmentation reduces hallucination in conversation, in: Findings of the Association for Computational Linguistics: EMNLP 2021, pp. 3784–3803. Siriwardhana, S., Weerasekera, R., Wen, E., Kaluarachchi, T., Rana, R., Nanayakkara, S.,
2021
-
[18]
5613–5626
Rear: A relevance-aware retrieval-augmented framework for open-domain question answering, in: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 5613–5626. Wu, Z., Arora, A., Wang, Z., Geiger, A., Jurafsky, D., Manning, C.D., Potts, C.,
2024
-
[19]
Mspf: A multi-semantic prompting fusion framework for emotion-cause pair extraction in conversations. Information Processing & Management 63, 104356. doi: https://doi.org/10.1016/j. ipm.2025.104356. Xu, G., Feng, J., Wang, Q., 2026a. Learning rules and aligning elements for document-level relation extraction. Information Processing & Management 63, 104511...
work page doi:10.1016/j 2025
-
[20]
arXiv preprint arXiv:2503.13514
Rag-kg-il: A multi-agent hybrid framework for reducing hallucinations and enhancing llm reasoning through rag and incremental knowledge graph learning integration. arXiv preprint arXiv:2503.13514 . Yu, Y ., Zhuang, Y ., Zhang, J., Meng, Y ., Ratner, A.J., Krishna, R., Shen, J., Zhang, C.,
-
[21]
(Eds.), Advances in Neural Information Processing Systems, Curran Associates, Inc
Large language model as attributed training data generator: A tale of diversity and bias, in: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S. (Eds.), Advances in Neural Information Processing Systems, Curran Associates, Inc.. pp. 55734–55784. URL: https://proceedings.neurips.cc/paper_ files/paper/2023/file/ae9500c4f5607caf2eff033c67d...
2023
-
[22]
4505–4524
The good and the bad: Exploring privacy issues in retrieval-augmented generation (rag), in: Findings of the Association for Computational Linguistics: ACL 2024, pp. 4505–4524. Zeng, S., Zhang, J., He, P., Ren, J., Zheng, T., Lu, H., Xu, H., Liu, H., Xing, Y ., Tang, J.,
2024
-
[23]
24538–24569
Mitigating the privacy issues in retrieval-augmented generation (rag) via pure synthetic data, in: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 24538–24569. Zhang, Y ., Wu, J., Li, R., Zhang, T., Song, Y ., Li, C., Wang, S., Shen, H., Yin, J., Ge, J., Luo, B.,
2025
-
[24]
Information Processing & Management 63, 104505
Privacy protection in rag: A novel method and evaluation framework. Information Processing & Management 63, 104505. doi: https://doi.org/10.1016/j.ipm.2025.104505. Zhao, X., Liu, S., Yang, S.Y ., Miao, C.,
-
[25]
4442–4457
Medrag: Enhancing retrieval-augmented generation with knowledge graph-elicited reasoning for healthcare copilot, in: Proceedings of the ACM on Web Conference 2025, pp. 4442–4457. Zhou, P., Feng, Y ., Yang, Z.,
2025
-
[26]
arXiv preprint arXiv:2503.15548
Privacy-aware rag: Secure and isolated knowledge retrieval. arXiv preprint arXiv:2503.15548 . Zou, W., Geng, R., Wang, B., Jia, J.,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.