Dense Supervision Is Not Enough: The Readout Blind Spot in Looped Language Models
Pith reviewed 2026-06-27 04:25 UTC · model grok-4.3
The pith
Dense per-loop cross-entropy leaves hidden-state scale uncontrolled when readouts are scale-invariant.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
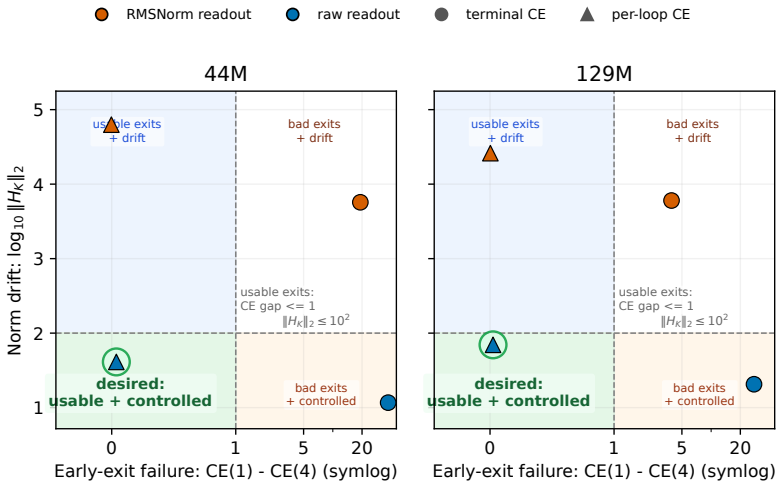
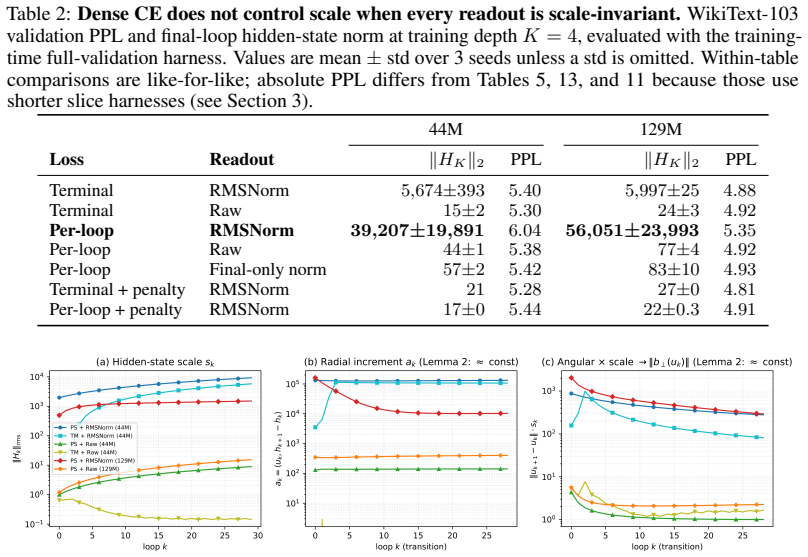
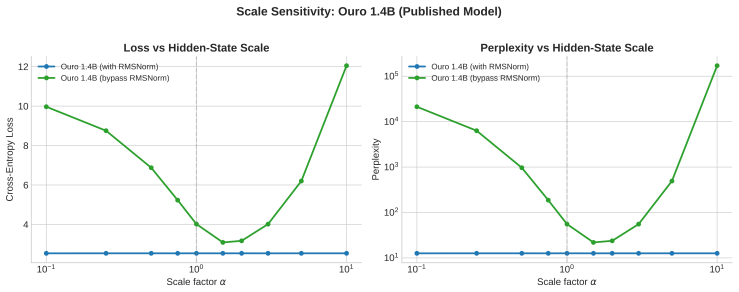
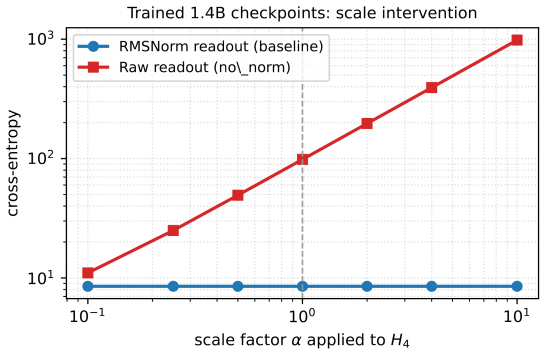
Dense per-loop cross-entropy through RMSNorm readouts drives final hidden-state norms into the thousands or tens of thousands in looped transformers without inter-loop normalization; scale-visible readouts and explicit norm penalties keep norms in the tens. The resulting design rule is that dense supervision trains exits while recurrent scale control requires either making scale visible to a loss or removing it from the loop.
What carries the argument
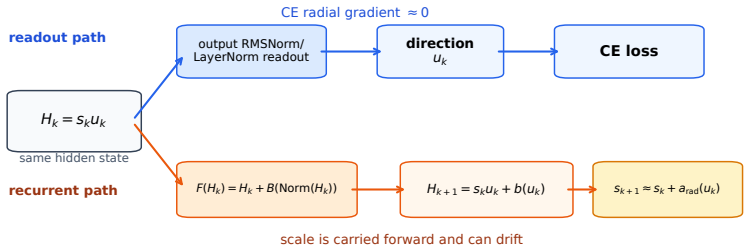
The readout blind spot created by scale-invariant functions such as RMSNorm, which hide radial scale from the immediate cross-entropy loss while pre-norm residual recurrence continues to carry and update that same scale.
If this is right
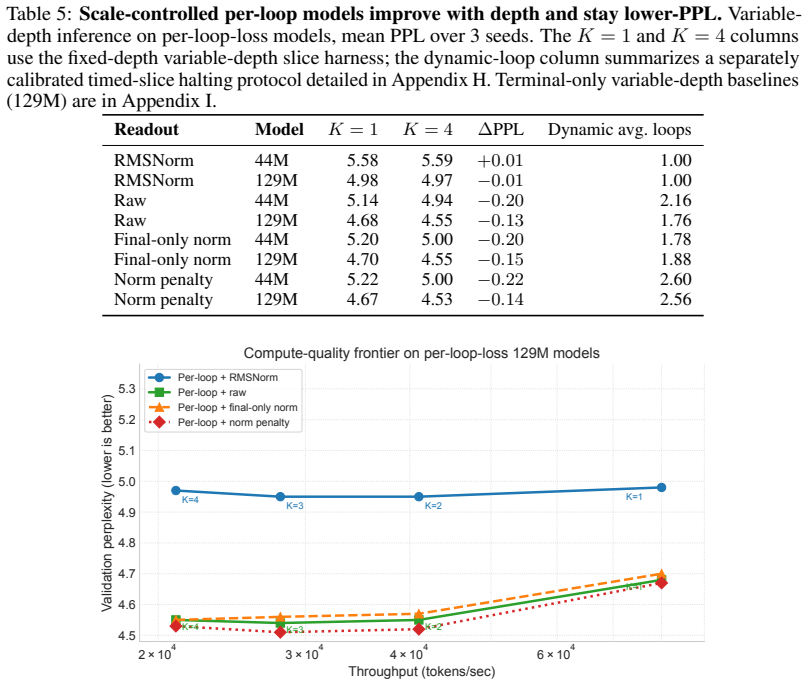
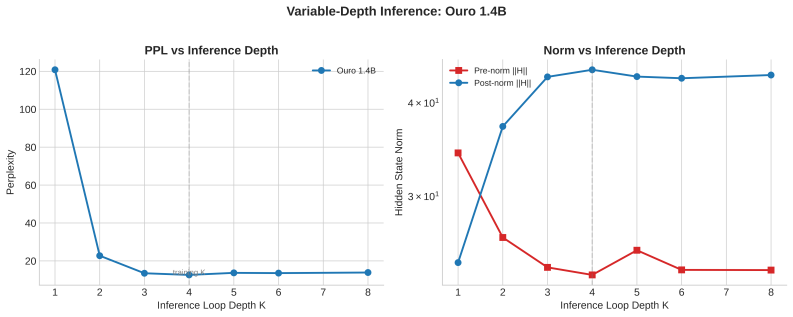
- Scale-controlled variants achieve lower perplexity at matched inference-depth operating points in variable-depth benchmarks.
- Per-loop loss can make early exits usable without controlling recurrent scale.
- Scale-removing recurrence serves as a complementary architectural fix to visible-scale readouts.
- Dense supervision alone is insufficient to control all variables active in the recurrent transition.
Where Pith is reading between the lines
- The same blind spot could appear in other recurrent or stateful architectures that combine invariant readouts with residual loops.
- Explicit norm penalties might generalize to other scale-related instabilities in deep recurrent networks.
- Variable-depth evaluation protocols could expose analogous supervision gaps in non-looped models that reuse internal states.
Load-bearing premise
Norm growth is caused specifically by the interaction of scale-invariant readouts with pre-norm residual recurrence rather than other training dynamics or initialization effects.
What would settle it
Training the same 44M and 129M looped models with scale-visible readouts and observing whether final hidden-state norms still reach thousands would directly test the claimed mechanism.
Figures
read the original abstract
Looped language models turn hidden states into runtime state: each state is decoded for prediction and fed back into future computation. This creates a basic supervision question: which state variables does cross-entropy actually control? We show that dense per-loop cross-entropy controls the variables exposed by the readout, not every variable active in the recurrent transition. Hidden-state scale gives a concrete failure mode. Scale-invariant readouts such as RMSNorm and LayerNorm hide radial scale from the immediate cross-entropy loss, while pre-norm residual recurrence continues to carry and update that same scale. Thus per-loop loss can make early exits usable without controlling recurrent scale. In 44M and 129M looped transformers without inter-loop normalization, per-loop cross-entropy through RMSNorm readouts still drives final hidden-state norms into the thousands or tens of thousands. Scale-visible readouts and explicit norm penalties keep norms in the tens, and scale-removing recurrence is the complementary architectural fix. The resulting design rule is simple: dense supervision trains exits; recurrent scale control requires either making scale visible to a loss or removing it from the loop. Consistent with this rule, scale-controlled variants achieve lower perplexity at matched inference-depth operating points in our variable-depth benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that dense per-loop cross-entropy in looped transformers fails to control hidden-state radial scale when readouts are scale-invariant (e.g., RMSNorm), because pre-norm residual recurrence continues to propagate and update that scale. In 44M and 129M models without inter-loop normalization, this produces final hidden-state norms in the thousands or tens of thousands; scale-visible readouts or explicit norm penalties keep norms in the tens. Scale-controlled variants also yield lower perplexity at matched inference depths. The resulting design rule is that supervision trains exits while recurrent scale requires either visibility to a loss or removal from the loop.
Significance. If the central empirical contrast holds, the work supplies a concrete, actionable principle for training looped and recurrent language models: standard dense supervision is insufficient for scale control in the recurrence. The demonstration on two model sizes and the link to improved variable-depth perplexity give the finding immediate engineering relevance for architectures that reuse hidden states across loops.
major comments (1)
- [Experimental results (abstract and §4)] The abstract reports that scale-visible readouts and explicit norm penalties keep norms in the tens while RMSNorm readouts produce norms in the thousands/tens of thousands, yet supplies no description of matched ablations that hold initialization scale, optimizer hyperparameters, inter-loop normalization absence, and all other recurrence details fixed while toggling only readout visibility or the penalty term. This isolation is load-bearing for attributing the observed norm growth specifically to the readout blind spot rather than other uncontrolled training dynamics.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for explicit experimental controls. The concern is valid: the current manuscript does not sufficiently document that the reported norm differences arise from toggling only readout visibility or the penalty term. We will revise the text to make the matched ablation design fully transparent.
read point-by-point responses
-
Referee: [Experimental results (abstract and §4)] The abstract reports that scale-visible readouts and explicit norm penalties keep norms in the tens while RMSNorm readouts produce norms in the thousands/tens of thousands, yet supplies no description of matched ablations that hold initialization scale, optimizer hyperparameters, inter-loop normalization absence, and all other recurrence details fixed while toggling only readout visibility or the penalty term. This isolation is load-bearing for attributing the observed norm growth specifically to the readout blind spot rather than other uncontrolled training dynamics.
Authors: The experiments were run with all listed factors held fixed: identical initialization scales, the same optimizer hyperparameters and schedule, no inter-loop normalization in any condition, and identical recurrence structure. The only differences were the readout (RMSNorm versus scale-visible alternatives such as a linear projection without normalization) or the addition of an explicit norm penalty. We will expand §4 with a dedicated paragraph enumerating these controls and will update the abstract to reference the matched setup. This revision will also include a short table summarizing the fixed versus varied elements across the three conditions. revision: yes
Circularity Check
No circularity: claims rest on empirical training runs
full rationale
The paper reports empirical observations from training 44M and 129M looped transformers under different readout and normalization conditions, showing norm growth under RMSNorm readouts versus controlled norms with scale-visible readouts or penalties. No derivation chain, equations, or predictions are presented that reduce to inputs by construction. No self-citations, ansatzes, or uniqueness theorems are invoked as load-bearing steps. The central claim is an experimental contrast, not a self-referential definition or fitted-input prediction, so the work is self-contained against its own benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cross-entropy loss applied per loop is the primary supervision signal for the hidden state in looped models.
Reference graph
Works this paper leans on
-
[1]
Pondernet: Learning to ponder.arXiv preprint arXiv:2107.05407,
Andrea Banino, Jan Balaguer, and Charles Blundell. Pondernet: Learning to ponder.arXiv preprint arXiv:2107.05407,
-
[2]
A mechanistic analysis of looped reasoning language models.arXiv preprint arXiv:2604.11791,
Hugh Blayney, Álvaro Arroyo, Johan Obando-Ceron, et al. A mechanistic analysis of looped reasoning language models.arXiv preprint arXiv:2604.11791,
-
[3]
Simply stabilizing the loop via fully looped transformer.arXiv preprint arXiv:2605.18797,
Rao Fu, Zixuan Yang, Jiankun Zhang, Jing Ma, Hechang Chen, Yu Li, and Yi Chang. Simply stabilizing the loop via fully looped transformer.arXiv preprint arXiv:2605.18797,
-
[4]
Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein
Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R. Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. Scaling up test-time compute with latent reasoning: A recurrent depth approach.arXiv preprint arXiv:2502.05171,
-
[5]
Elt: Elastic looped transformers for visual generation.arXiv preprint arXiv:2604.09168,
Sahil Goyal, Swayam Agrawal, Gautham Govind Anil, Prateek Jain, Sujoy Paul, and Aditya Kusupati. Elt: Elastic looped transformers for visual generation.arXiv preprint arXiv:2604.09168,
-
[6]
Adaptive computation time for recurrent neural networks.arXiv preprint arXiv:1603.08983,
10 Alex Graves. Adaptive computation time for recurrent neural networks.arXiv preprint arXiv:1603.08983,
-
[7]
Andrei Kanavalau, Carmen Amo Alonso, and Sanjay Lall. Gated normalization removal and scale anchoring in pre-norm transformers.arXiv preprint arXiv:2602.10408,
-
[8]
Harsh Kohli, Srinivasan Parthasarathy, Huan Sun, and Yuekun Yao. Loop, think, & generalize: Implicit reasoning in recurrent-depth transformers.arXiv preprint arXiv:2604.07822,
-
[9]
Stability and generalization in looped transformers.arXiv preprint arXiv:2604.15259,
Asher Labovich. Stability and generalization in looped transformers.arXiv preprint arXiv:2604.15259,
-
[10]
Ryan Lee, Jacob Biloki, Edward J. Hu, and Jonathan May. Sparse layers are critical to scaling looped language models.arXiv preprint arXiv:2605.09165,
-
[11]
Guilherme Penedo, Hynek Kydlíˇcek, Loubna Ben allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro V on Werra, and Thomas Wolf. The FineWeb datasets: Decanting the web for the finest text data at scale.arXiv preprint arXiv:2406.17557,
-
[12]
Hayden Prairie, Zachary Novack, Taylor Berg-Kirkpatrick, and Daniel Y . Fu. Parcae: Scaling laws for stable looped language models.arXiv preprint arXiv:2604.12946,
-
[13]
Kristian Schwethelm, Daniel Rueckert, and Georgios Kaissis. How much is one recurrence worth? iso-depth scaling laws for looped language models.arXiv preprint arXiv:2604.21106,
-
[14]
Sam Shleifer, Jason Weston, and Myle Ott. Normformer: Improved transformer pretraining with extra normalization.arXiv preprint arXiv:2110.09456,
-
[15]
LoopRPT: Reinforcement pre-training for looped language models.arXiv preprint arXiv:2603.19714,
Guo Tang, Shixin Jiang, Heng Chang, Nuo Chen, Yuhan Li, Huiming Fan, Jia Li, Ming Liu, and Bing Qin. LoopRPT: Reinforcement pre-training for looped language models.arXiv preprint arXiv:2603.19714,
-
[16]
Deepnet: Scaling transformers to 1,000 layers.arXiv preprint arXiv:2203.00555,
Hongyu Wang, Shuming Ma, Li Dong, Shaohan Huang, Dongdong Zhang, and Furu Wei. Deepnet: Scaling transformers to 1,000 layers.arXiv preprint arXiv:2203.00555,
-
[17]
Scaling latent reasoning via looped language models
Rui-Jie Zhu, Zixuan Wang, Kai Hua, et al. Scaling latent reasoning via looped language models. arXiv preprint arXiv:2510.25741,
-
[18]
We also ran a near-matched-token Ouro-scale check to ask whether the readout-side diagnostic survives in a larger implementation trained on a modern corpus
B 1.4B Scale Sanity Check The controlled 44M and 129M experiments isolate the mechanism. We also ran a near-matched-token Ouro-scale check to ask whether the readout-side diagnostic survives in a larger implementation trained on a modern corpus. This appendix reports that check. It should be read as scale evidence only: it is not a full 2×2 ablation, not ...
2024
-
[19]
Table 13:High halting speedup can reflect K-invariance rather than useful adaptive computa- tion.Calibrated logit-margin halting on per-loop-loss models, mean over 3 seeds, timed slice harness. Thresholds are tuned on a held-out calibration slice to keep dynamic perplexity (PPL) within 1% of fixed K= 4 ; the table reports a separate timed slice, so small ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.