A Zeroth-Order Deep Learning Method for Fully Nonlinear Parabolic Partial Differential Equations with Unknown Coefficients
Pith reviewed 2026-06-26 00:08 UTC · model grok-4.3
The pith
Zeroth-order derivative estimators from perturbed Monte Carlo trajectories enable model-free learning of solutions and derivatives for high-dimensional nonlinear parabolic PDEs using only simulators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
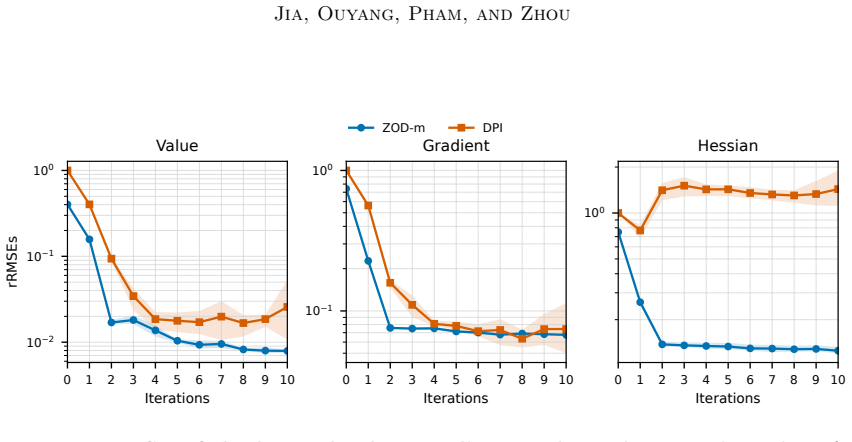
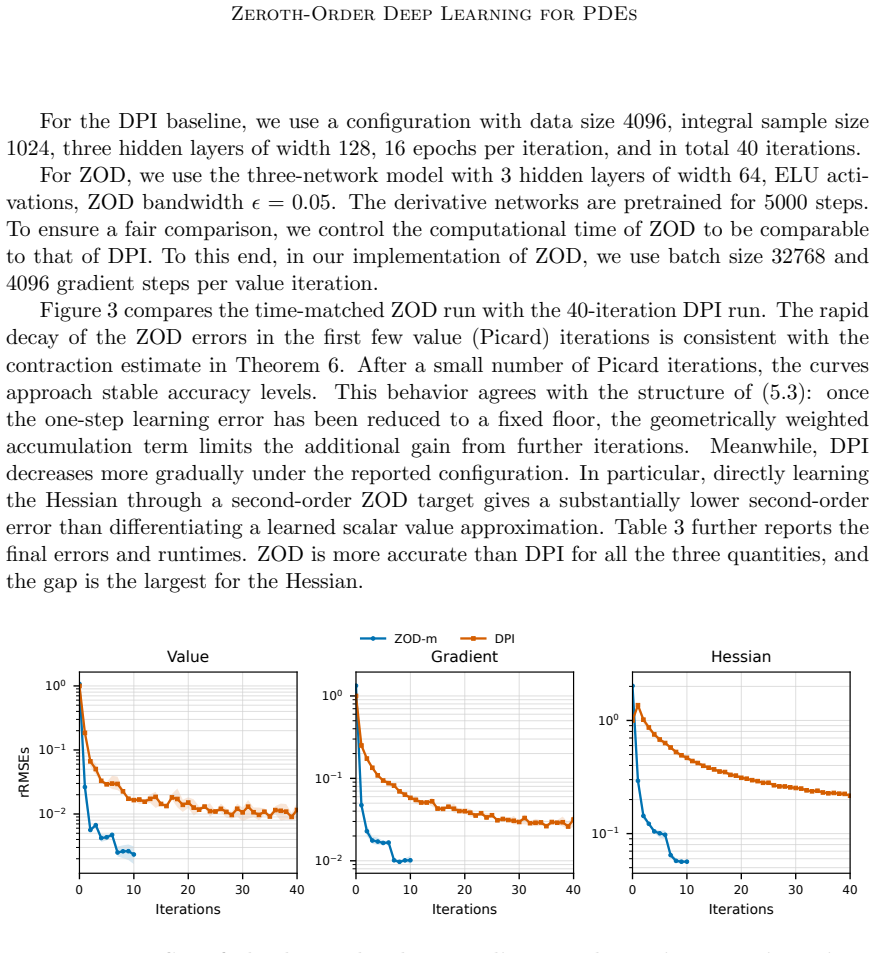
By introducing simulators as data-generating mechanisms and deriving zeroth-order derivative estimators from perturbed Monte Carlo trajectories, the method learns solutions and their derivatives for fully nonlinear parabolic PDEs under settings where PDE operators are accessible only through simulations and pointwise evaluations, with a bias-variance analysis for the estimators and non-asymptotic error bounds that separate discretization, approximation, statistical, and ZOD bias contributions while giving sample complexity in Sobolev space.
What carries the argument
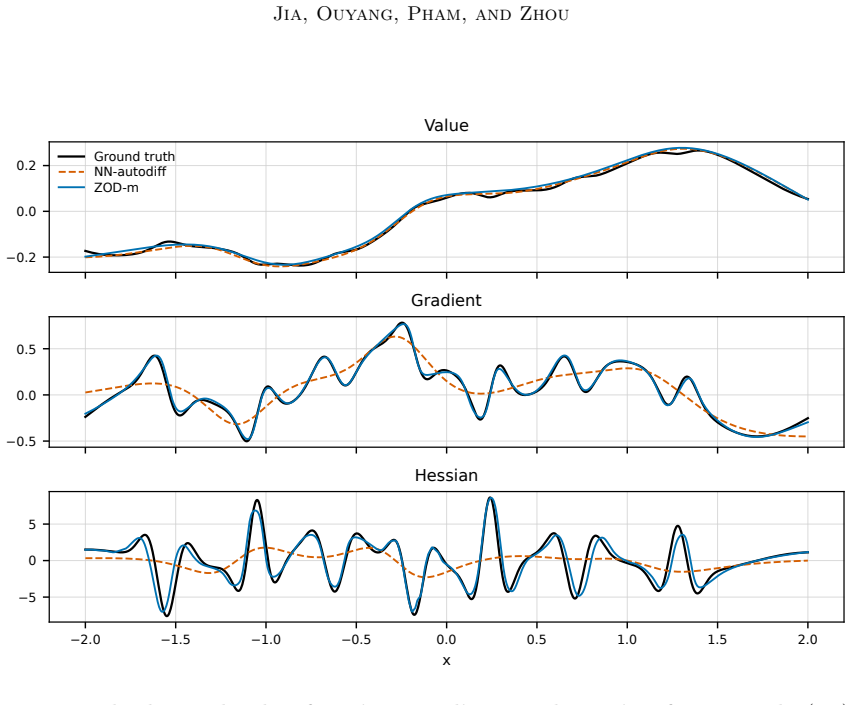
Zeroth-order derivative (ZOD) estimators derived from perturbed Monte Carlo trajectories, which generate targets for gradient and Hessian networks using only function evaluations in a fully model-free manner.
If this is right
- The method generates targets for the gradient and Hessian networks using only function evaluations from simulators.
- A bias-variance tradeoff analysis applies to the ZOD estimators.
- The total error decomposes into discretization error, approximation error, statistical error, and ZOD bias under the contraction assumption.
- Sample complexity is characterized for the learned representations in weighted Sobolev space up to second-order derivatives.
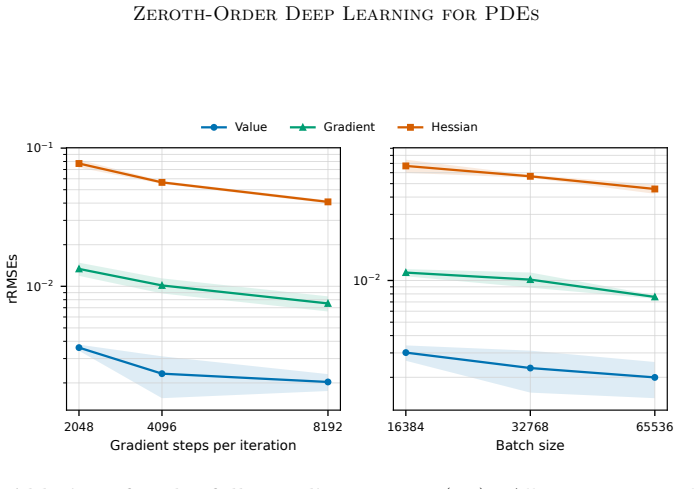
- Numerical tests demonstrate competitive performance in moderate and high dimensions.
Where Pith is reading between the lines
- The simulator-based framework could extend to other black-box settings such as continuous-time reinforcement learning without requiring known dynamics.
- Replacing automatic differentiation with ZOD estimators may reduce instability in high-dimensional derivative computations for PDE solvers.
- The error decomposition suggests targeted improvements by reducing ZOD bias through adjusted perturbation sizes in the Monte Carlo trajectories.
Load-bearing premise
The underlying PDE operator satisfies a standard contraction property.
What would settle it
Numerical experiments on a contractive PDE where the observed total error exceeds the bound by more than the sum of the four decomposed terms, or where performance degrades sharply when the contraction property is removed.
Figures
read the original abstract
High-dimensional partial differential equations (PDEs) with unknown coefficients arise widely in scientific machine learning, including continuous-time reinforcement learning, yet solving them efficiently in a data-driven way remains challenging. Existing deep learning solvers often rely on repeated automatic differentiation to evaluate differential operators, which can cause instability and amplify derivative errors in high dimensions, while probabilistic methods based on stochastic representations require explicit knowledge of the data-generating dynamics and therefore do not apply to black-box environments. We introduce two types of simulators as data-generating mechanisms, and take a ``representing-then-learning" approach that learns the solutions and their derivatives under settings where the underlying PDE operators are accessible only through simulations and pointwise evaluations. Our representation of derivatives relies on the zeroth-order derivative (ZOD) estimators derived from perturbed Monte Carlo trajectories. This fully model-free approach generates targets for the gradient and Hessian networks using only function evaluations. We provide a statistical learning analysis of the proposed approach, including a bias--variance tradeoff for ZODs. Assuming a standard contraction property of the underlying operator, we establish a non-asymptotic error bound that decomposes the total error into discretization error, approximation error, statistical error, and ZOD bias. Crucially, we derive the sample complexity of the learned representations in (weighted) Sobolev space, characterizing the error up to second-order derivatives. Numerical experiments illustrate the competitive performance of the method in moderate and high dimensions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a zeroth-order deep learning method for high-dimensional fully nonlinear parabolic PDEs with unknown coefficients, using two simulator types as data-generating mechanisms and a representing-then-learning approach. Derivatives are represented via ZOD estimators from perturbed Monte Carlo trajectories, enabling model-free learning from function evaluations only. The authors provide a statistical learning analysis with bias-variance tradeoff for ZODs and, assuming a standard contraction property of the operator, derive a non-asymptotic error bound decomposing total error into discretization, approximation, statistical, and ZOD bias terms, along with sample complexity results in weighted Sobolev space up to second-order derivatives. Numerical experiments demonstrate competitive performance in moderate and high dimensions.
Significance. If the contraction assumption holds and the bounds are rigorously derived without circularity, the work would provide a notable contribution to model-free solvers for black-box PDEs in scientific machine learning and continuous-time RL, addressing instabilities from automatic differentiation and the limitations of probabilistic methods requiring explicit dynamics. The explicit decomposition of errors and Sobolev-space sample complexity characterization would be strengths if supported by complete derivations.
major comments (2)
- [statistical learning analysis section / non-asymptotic error bound] The non-asymptotic error bound (stated in the abstract and established in the statistical learning analysis section) decomposes total error into discretization, approximation, statistical, and ZOD bias terms only under the assumption of a standard contraction property of the underlying operator. For fully nonlinear parabolic PDEs where the operator is accessible solely through simulators and pointwise evaluations with unknown coefficients, this property is not explicitly derived from the data-generating mechanism or verified, rendering the bound and the associated sample complexity in weighted Sobolev space conditional on an uncheckable hypothesis in the claimed black-box regime.
- [statistical learning analysis section] The ZOD bias analysis and bias-variance tradeoff (abstract and statistical learning analysis) are presented as part of the error decomposition, but without full derivations or explicit verification of how the contraction property interacts with the perturbed Monte Carlo trajectories in the black-box setting, the support for the central non-asymptotic claims cannot be fully assessed from the provided analysis.
minor comments (1)
- Notation for the two simulator types and the precise definition of the weighted Sobolev space should be clarified with explicit references to prior work on ZOD estimators to improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review of our manuscript. Below we respond point by point to the major comments on the statistical learning analysis and error bounds.
read point-by-point responses
-
Referee: [statistical learning analysis section / non-asymptotic error bound] The non-asymptotic error bound (stated in the abstract and established in the statistical learning analysis section) decomposes total error into discretization, approximation, statistical, and ZOD bias terms only under the assumption of a standard contraction property of the underlying operator. For fully nonlinear parabolic PDEs where the operator is accessible solely through simulators and pointwise evaluations with unknown coefficients, this property is not explicitly derived from the data-generating mechanism or verified, rendering the bound and the associated sample complexity in weighted Sobolev space conditional on an uncheckable hypothesis in the claimed black-box regime.
Authors: We agree that the non-asymptotic bound is derived under the standard contraction assumption on the operator. This assumption is ubiquitous in the analysis of fully nonlinear PDEs and continuous-time RL (ensuring uniqueness and convergence of the fixed-point iteration) and is stated explicitly in the manuscript. In the black-box regime the simulators define the operator only implicitly via pointwise evaluations, so an explicit derivation from the data-generating mechanism would require additional structure on the unknown coefficients, defeating the model-free objective. The assumption remains checkable numerically on concrete instances. We will add a clarifying remark on its role and typical verification in the revised version. revision: partial
-
Referee: [statistical learning analysis section] The ZOD bias analysis and bias-variance tradeoff (abstract and statistical learning analysis) are presented as part of the error decomposition, but without full derivations or explicit verification of how the contraction property interacts with the perturbed Monte Carlo trajectories in the black-box setting, the support for the central non-asymptotic claims cannot be fully assessed from the provided analysis.
Authors: The complete derivations of the ZOD bias, bias-variance tradeoff, and the full non-asymptotic error bound (including the manner in which the contraction controls error propagation through the operator applied to perturbed trajectories) appear in Section 4 and the appendix. Nevertheless, we accept that the interaction between the black-box simulators and the contraction could be spelled out more explicitly. We will revise the statistical learning section to include additional intermediate steps clarifying this interaction while preserving the model-free character of the approach. revision: yes
Circularity Check
No significant circularity; derivation conditional on external assumption
full rationale
The paper establishes its non-asymptotic error bound only after explicitly assuming a standard contraction property of the underlying operator, which is treated as an independent precondition rather than derived from the ZOD estimators, simulators, or any fitted quantities. No equations or steps in the provided text reduce the sample complexity result or the representing-then-learning approach to inputs by construction, and there are no self-citations invoked as load-bearing uniqueness theorems. The statistical analysis (bias-variance tradeoff, discretization/approximation/statistical/ZOD bias decomposition) therefore remains self-contained against the stated external benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption standard contraction property of the underlying operator
Reference graph
Works this paper leans on
-
[1]
Nature machine intelligence , volume=
Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators , author=. Nature machine intelligence , volume=. 2021 , publisher=
2021
-
[2]
Journal of Machine Learning Research , volume=
Reinforcement learning in continuous time and space: A stochastic control approach , author=. Journal of Machine Learning Research , volume=
-
[3]
Proceedings of Symposium of System Sciences and Control Theory , pages=
A nonlinear Feynman-Kac formula and applications , author=. Proceedings of Symposium of System Sciences and Control Theory , pages=. 1992 , organization=
1992
-
[4]
arXiv preprint arXiv:2010.08895 , year=
Fourier neural operator for parametric partial differential equations , author=. arXiv preprint arXiv:2010.08895 , year=
Pith/arXiv arXiv 2010
-
[5]
arXiv preprint arXiv:2104.05512 , year=
One-shot learning for solution operators of partial differential equations , author=. arXiv preprint arXiv:2104.05512 , year=
-
[6]
Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences , volume=
Learning partial differential equations for biological transport models from noisy spatio-temporal data , author=. Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences , volume=. 2020 , publisher=
2020
-
[7]
Representation theorems for backward stochastic differential equations , volume =
Ma, Jin and Zhang, Jianfeng , journal =. Representation theorems for backward stochastic differential equations , volume =
-
[8]
Estimating quadratic variation using realized variance , volume =
Barndorff-Nielsen, Ole E and Shephard, Neil , journal =. Estimating quadratic variation using realized variance , volume =
-
[9]
Econometric analysis of realized volatility and its use in estimating stochastic volatility models , volume =
Barndorff-Nielsen, Ole E and Shephard, Neil , journal =. Econometric analysis of realized volatility and its use in estimating stochastic volatility models , volume =
-
[10]
Journal of Machine Learning Research , volume=
q-Learning in continuous time , author=. Journal of Machine Learning Research , volume=
-
[11]
Nonparametric estimation of scalar diffusions based on low frequency data , volume =
Gobet, Emmanuel and Hoffmann, Marc and Rei. Nonparametric estimation of scalar diffusions based on low frequency data , volume =. The Annals of Statistics , number =
-
[12]
Policy evaluation and temporal-difference learning in continuous time and space: A martingale approach , volume =
Jia, Yanwei and Zhou, Xun Yu , journal =. Policy evaluation and temporal-difference learning in continuous time and space: A martingale approach , volume =
-
[13]
Journal of Machine Learning Research , volume=
Policy gradient and actor-critic learning in continuous time and space: Theory and algorithms , author=. Journal of Machine Learning Research , volume=
-
[14]
2014 , publisher=
Understanding Machine Learning: From Theory to Algorithms , author=. 2014 , publisher=
2014
-
[15]
2018 , publisher=
Foundations of Machine Learning , author=. 2018 , publisher=
2018
-
[16]
Error analysis of deep
Jiao, Yuling and Lai, Yanming and Lo, Yisu and Wang, Yang and Yang, Yunfei , journal=. Error analysis of deep. 2024 , publisher=
2024
-
[17]
Han, Jiequn and Hu, Wei and Long, Jihao and Zhao, Yue , year =. Deep. doi:10.48550/ARXIV.2409.08526 , abstract =
-
[18]
Stochastic Processes and their Applications , author =
On. Stochastic Processes and their Applications , author =. 2001 , pages =
2001
-
[19]
and Wellner, Jon A
Van Der Vaart, Aad W. and Wellner, Jon A. , year =. Weak
-
[20]
and Peng, S
Pardoux, E. and Peng, S. , editor =. Backward Stochastic Differential Equations and Quasilinear Parabolic Partial Differential Equations , booktitle =
-
[21]
2004 , publisher=
Glasserman, Paul , volume=. 2004 , publisher=
2004
-
[22]
Deep Neural networks for solving high-dimensional parabolic partial differential equations , author=. arXiv:2601.13256 , volume=. 2026 , publisher=
arXiv 2026
-
[23]
2018 , publisher=
Sirignano, Justin and Spiliopoulos, Kostas , journal=. 2018 , publisher=
2018
-
[24]
Journal of Computational Physics , volume=
Physics-informed neural neworks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations , author=. Journal of Computational Physics , volume=. 2019 , publisher=
2019
-
[25]
Deep backward schemes for high-dimensional nonlinear
Hur\'e, C\^ome and Pham, Huy\^en and Warin, Xavier , journal=. Deep backward schemes for high-dimensional nonlinear. 2020 , publisher=
2020
-
[26]
Proceedings of the National Academy of Sciences , volume=
Solving high-dimensional partial differential equations using deep learning , author=. Proceedings of the National Academy of Sciences , volume=. 2018 , publisher=
2018
-
[27]
Communication in Mathematical Statistics , volume=
Deep Learning-Based numerical methods for high dimensional parabolic partial differential equations and backward stochastic differential equations , author=. Communication in Mathematical Statistics , volume=. 2017 , publisher=
2017
-
[28]
Discrete and Continuous Dynamical Systems-B , volume=
An overview on deep learning-based approximation methods for partial differential equations , author=. Discrete and Continuous Dynamical Systems-B , volume=. 2023 , publisher=
2023
-
[29]
Machine Learning and Data Sciences for Financial Markets: A Guide to Contemporary Practices , author =
Neural networks-based algorithms for stochastic control and. Machine Learning and Data Sciences for Financial Markets: A Guide to Contemporary Practices , author =
-
[30]
Han, Jiequn and Hu, Wei and Long, Jihao and Zhao, Yue , journal=. Deep. 2026 , publisher=
2026
-
[31]
Differential learning methods for solving fully nonlinear
Lefebvre, William and Loeper, Gr\'egoire and Pham, Huy\^en , journal=. Differential learning methods for solving fully nonlinear. 2023 , publisher=
2023
-
[32]
SSRN 3591734 , volume=
Differential machine learning , author=. SSRN 3591734 , volume=. 2020 , publisher=
2020
-
[33]
Stochastic
Kunita, Hiroshi , year = 2019, series =. Stochastic
2019
-
[34]
, year = 2005, series =
Protter, Philip E. , year = 2005, series =. Stochastic
2005
-
[35]
Neural Networks , volume=
Approximation capabilities of multilayer feedforward networks , author=. Neural Networks , volume=. 1991 , publisher=
1991
-
[36]
Mathematics of Control, Signals, and Systems , volume=
Approximation by superpositions of a sigmoidal function , author=. Mathematics of Control, Signals, and Systems , volume=. 1989 , publisher=
1989
-
[37]
Advances in Neural Information Processing Systems , year=
Sobolev Training for Neural Networks , author=. Advances in Neural Information Processing Systems , year=
-
[38]
IEEE Transactions on Information Theory , volume=
Optimal rates for zero-order convex optimization: The power of two function evaluations , author=. IEEE Transactions on Information Theory , volume=
-
[39]
arXiv preprint arXiv:1703.03864 , year=
Evolution strategies as a scalable alternative to reinforcement learning , author=. arXiv preprint arXiv:1703.03864 , year=
-
[40]
NeurIPS , year=
Simple random search of static linear policies is competitive for reinforcement learning , author=. NeurIPS , year=
-
[41]
Spline Models for Observational Data , author=
-
[42]
Bernoulli , volume=
Doum. Bernoulli , volume=. 2025 , publisher=
2025
-
[43]
IMA Journal of Numerical Analysis , pages=
On the stability and convergence of physics informed neural networks , author=. IMA Journal of Numerical Analysis , pages=. 2025 , publisher=
2025
-
[44]
2026 , publisher=
Bonito, Andrea and DeVore, Ronald and Petrova, Guergana and Siegel, Jonathan W , journal=. 2026 , publisher=
2026
-
[45]
Neural Networks , volume=
Universal approximation of an unknown mapping and its derivatives using multilayer feedforward networks , author=. Neural Networks , volume=. 1990 , publisher=
1990
-
[46]
2014 , publisher=
Brownian Motion and Stochastic Calculus , author=. 2014 , publisher=
2014
-
[47]
1996 , address =
Bertsekas, Dimitri P and Tsitsiklis, John N , publisher =. 1996 , address =
1996
-
[48]
1998 , publisher=
Reinforcement Learning: An Introduction , author=. 1998 , publisher=
1998
-
[49]
1999 , publisher=
Yong, Jiongmin and Zhou, Xun Yu , volume=. 1999 , publisher=
1999
-
[50]
2009 , publisher=
Pham, Huy. 2009 , publisher=
2009
-
[51]
Fleming, Wendell H and Soner, H Mete , year=
-
[52]
Machine Learning , volume=
Approximation and estimation bounds for artificial neural networks , author=. Machine Learning , volume=. 1994 , publisher=
1994
-
[53]
The Annals of Statistics , pages=
Optimal global rates of convergence for nonparametric regression , author=. The Annals of Statistics , pages=. 1982 , publisher=
1982
-
[54]
Journal of The Royal Statistical Society Series B: Statistical Methodology , volume=
Smoothing spline Gaussian regression: More scalable computation via efficient approximation , author=. Journal of The Royal Statistical Society Series B: Statistical Methodology , volume=. 2004 , publisher=
2004
-
[55]
Journal of Machine Learning Research , volume=
Sobolev norm learning rates for regularized least-squares algorithms , author=. Journal of Machine Learning Research , volume=
-
[56]
Siegel, Jonathan W , journal=
-
[57]
Annales de L'Institut Henri Poincare Section (B) Probability and Statistics , volume=
Ba. Annales de L'Institut Henri Poincare Section (B) Probability and Statistics , volume=
-
[58]
, year = 2014, series =
Pavliotis, Grigorios A. , year = 2014, series =. Stochastic
2014
-
[59]
Mou, Wenlong and Zhu, Yuhua , journal=. On. 2025 , publisher=
2025
-
[60]
arXiv preprint arXiv:2502.04297 , year=
Statistical guarantees for continuous-time policy evaluation: Blessing of ellipticity and new tradeoffs , author=. arXiv preprint arXiv:2502.04297 , year=
-
[61]
arXiv preprint arXiv:2602.06930 , year=
Continuous-time reinforcement learning: Ellipticity enables model-free value function approximation , author=. arXiv preprint arXiv:2602.06930 , year=
-
[62]
Zhu, Yuhua and Zhang, Yuming and Zhang, Haoyu , journal=
-
[63]
2021 , publisher=
Zhou, Mo and Han, Jiequn and Lu, Jianfeng , journal=. 2021 , publisher=
2021
-
[64]
Machine Learning For Elliptic
Lu, Yiping and Chen, Haoxuan and Lu, Jianfeng and Ying, Lexing and Blanchet, Jose , booktitle=. Machine Learning For Elliptic
-
[65]
A priori generalization analysis of the deep
Lu, Yulong and Lu, Jianfeng and Wang, Min , booktitle=. A priori generalization analysis of the deep. 2021 , organization=
2021
-
[66]
The deep
E, Weinan and Yu, Bing , journal=. The deep. 2018 , publisher=
2018
-
[67]
Wang, Chuwei and Li, Shanda and He, Di and Wang, Liwei , journal=
-
[68]
International Conference on Artificial Intelligence and Statistics , pages=
Learning physics-informed neural networks without stacked back-propagation , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2023 , organization=
2023
-
[69]
Bias-variance trade-off in physics-informed neural networks with randomized smoothing for high-dimensional
Hu, Zheyuan and Yang, Zhouhao and Wang, Yezhen and Karniadakis, George E and Kawaguchi, Kenji , journal=. Bias-variance trade-off in physics-informed neural networks with randomized smoothing for high-dimensional. 2025 , publisher=
2025
-
[70]
Stochastic
Shi, Zekun and Hu, Zheyuan and Lin, Min and Kawaguchi, Kenji , journal=. Stochastic
-
[71]
and Bousquet, Olivier and Mendelson, Shahar , year = 2005, month = aug, journal =
Bartlett, Peter L. and Bousquet, Olivier and Mendelson, Shahar , year = 2005, month = aug, journal =. Local
2005
-
[72]
, year = 2019, month = feb, edition =
Wainwright, Martin J. , year = 2019, month = feb, edition =. High-
2019
-
[73]
Foundations of Computational Mathematics , volume=
Random gradient-free minimization of convex functions , author=. Foundations of Computational Mathematics , volume=. 2017 , publisher=
2017
-
[74]
Balasubramanian, Krishnakumar and Ghadimi, Saeed , year = 2022, month = feb, journal =. Zeroth-
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.