Erased, but Not Gone: Output Forgetting Is Not True Forgetting
Pith reviewed 2026-06-26 00:03 UTC · model grok-4.3
The pith
Output forgetting in machine unlearning often leaves structured representation mismatches relative to retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
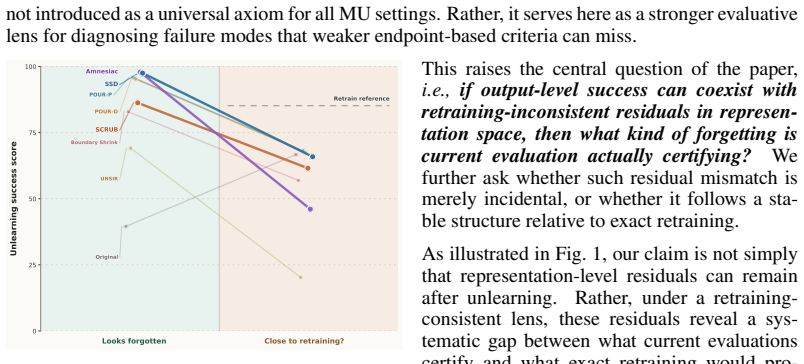
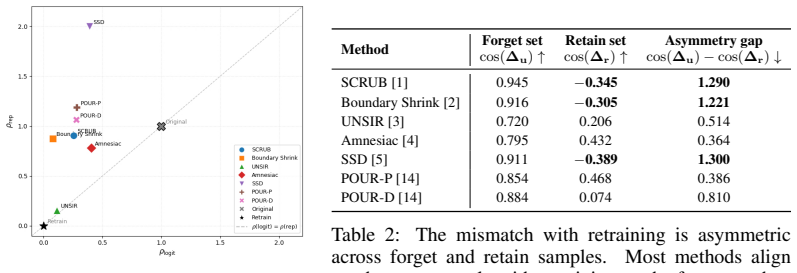
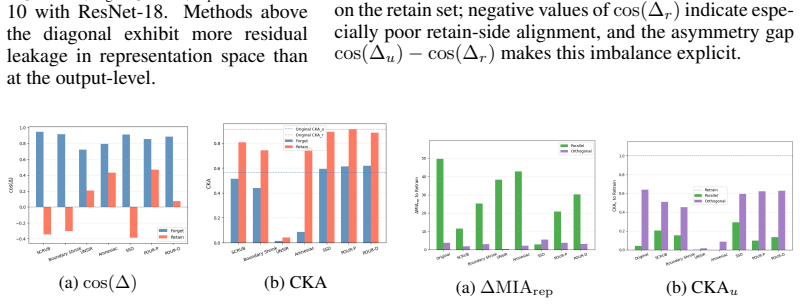
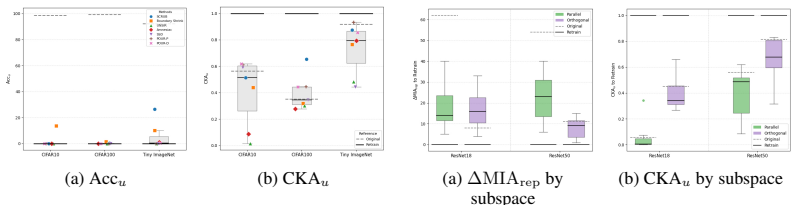
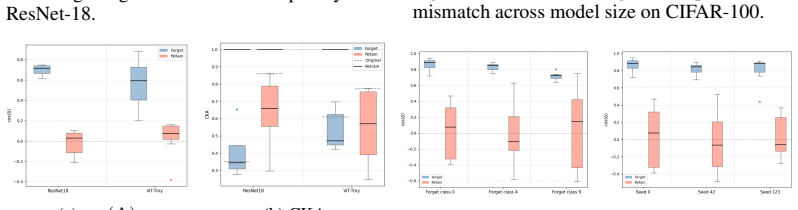
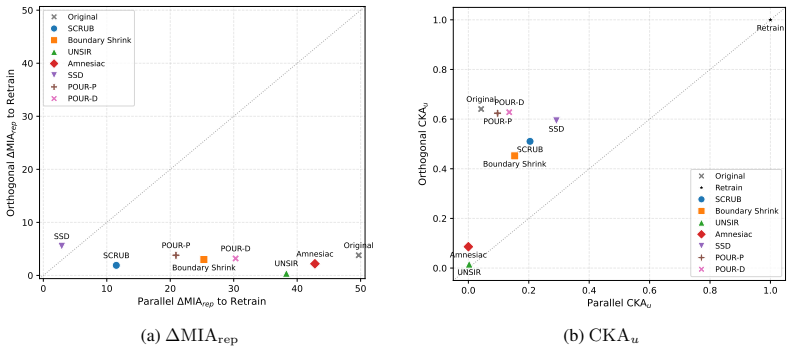
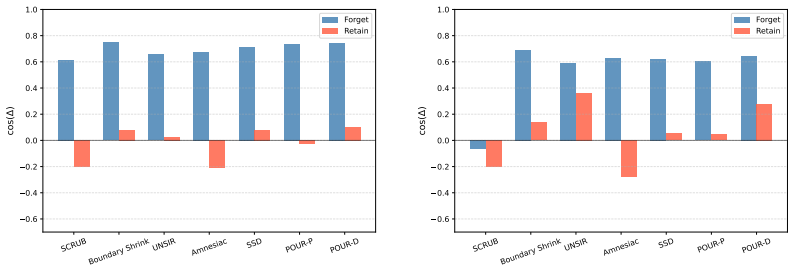
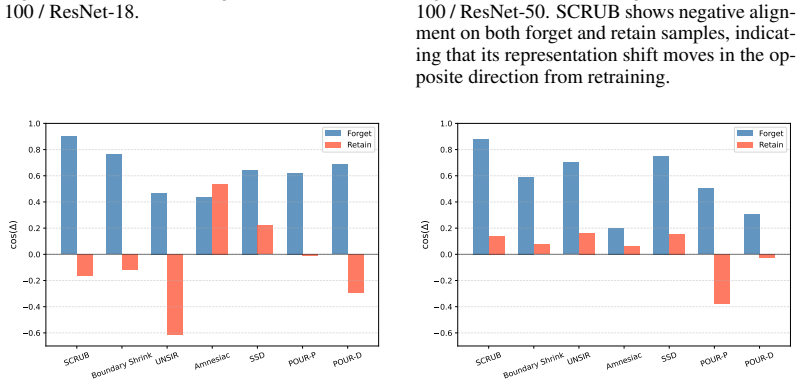
The central claim is that standard output-level evaluation can systematically overestimate unlearning success because output forgetting can coexist with retraining-inconsistent residuals in representation space. Under this lens, methods often partially align with retraining on forget samples, remain more inconsistent on retain samples, and leave residual discrepancy concentrated along retraining-related directions rather than diffuse.
What carries the argument
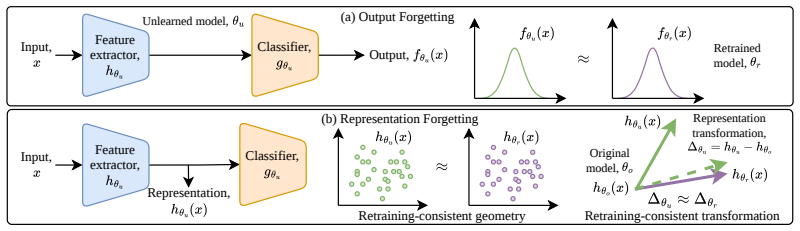
Retrain-consistent representation forgetting, which treats the model retrained from scratch without the forget data as the operational reference for correct forgetting in representation space.
If this is right
- Unlearned models show partial alignment with retraining on forget samples but greater inconsistency on retain samples.
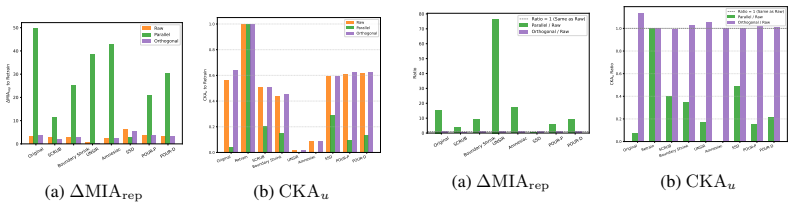
- Residual mismatches concentrate along retraining-related directions rather than appearing diffuse in representation space.
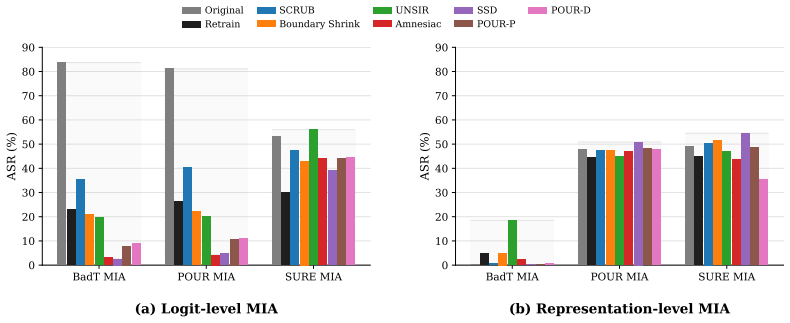
- Current methods often produce apparent output forgetting without achieving retraining-consistent forgetting.
- Standard evaluations based on output accuracy or logit-level inference can overestimate true unlearning progress.
Where Pith is reading between the lines
- Evaluation protocols may need to incorporate representation-space comparisons to the retrained reference to avoid overestimating forgetting.
- Applications requiring verifiable data removal, such as regulatory compliance, could be affected if only output metrics are used.
- Methods that directly optimize for reduced representation mismatch to retraining might address the identified gaps.
Load-bearing premise
The retrained model trained from scratch without the forget data serves as a valid operational reference for what correct forgetting should look like in representation space.
What would settle it
An empirical result showing that representation distances and directional alignments between unlearned models and the retrained reference are statistically indistinguishable from random or zero across multiple methods would falsify the claim of systematic overestimation.
Figures

read the original abstract
Machine unlearning (MU) is commonly judged by output forgetting, such as low forget-set accuracy or reduced logit-level membership inference. But if output-level success can coexist with retraining-inconsistent residuals in representation space, what kind of forgetting are current evaluations actually certifying? We study this question through retraining-consistent representation forgetting, using the retrained model (i.e., trained from scratch without the forget data) as an operational reference for correct forgetting. Across multiple unlearning methods, datasets, and models, our theoretical analysis and empirical results show that standard output-level evaluation can systematically overestimate the success of unlearning. Under this stronger lens, current methods often appear forgotten at the output layer while exhibiting a structured mismatch relative to retraining. They partially align with retraining on forget samples, remain more inconsistent on retain samples, and leave residual discrepancy concentrated along retraining-related directions rather than diffuse in representation space. This structured mismatch is characterized by forget/retain asymmetry, directional mismatch, and concentrated residuals along retraining-related directions. These results suggest that current MU is often evaluated for apparent forgetting rather than retraining-consistent forgetting. More broadly, retraining reveals what output forgetting hides.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard output-level metrics for machine unlearning (e.g., forget-set accuracy, logit-based membership inference) systematically overestimate success. Using the retrained model (trained from scratch on retain data only) as an operational reference for correct representation-space forgetting, the authors present theoretical analysis and empirical results across multiple unlearning methods, datasets, and models. They report that unlearned models exhibit structured mismatches: partial alignment with retraining on forget samples, greater inconsistency on retain samples, and residual discrepancy concentrated along retraining-related directions rather than diffuse.
Significance. If the empirical patterns hold, the work identifies a concrete limitation in current MU evaluation practices and motivates stronger, representation-consistent criteria. The multi-method, multi-dataset empirical component and the operational use of a retrained reference are strengths that make the overestimation claim testable and falsifiable.
major comments (2)
- [Abstract, §3] Abstract and §3 (theoretical analysis): the central claim that output forgetting 'overestimates success' is load-bearing on the premise that deviation from the retrained model's representations constitutes incomplete forgetting. The manuscript does not provide a formal argument or empirical test showing that no other representationally distinct trajectories can achieve effective forgetting (zero membership inference, no reconstruction) while differing from the retrained model; this assumption requires explicit justification or a counter-example analysis.
- [Empirical results (§4–5)] Empirical results section (likely §4–5): the reported forget/retain asymmetry and directional concentration are interpreted as evidence of incomplete forgetting, but the paper does not report whether these mismatches correlate with actual downstream risks (e.g., increased reconstruction success or membership inference beyond output level). Without that link, the structured mismatch alone does not yet demonstrate overestimation of unlearning success.
minor comments (2)
- [Methods] Notation for 'retraining-consistent representation forgetting' is introduced in the abstract but would benefit from an explicit definition or equation in the methods section to avoid ambiguity with standard representation similarity measures.
- [Figures] Figure captions should explicitly state the number of runs, random seeds, and statistical significance tests used for the reported asymmetries and directional concentrations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important areas for strengthening the justification of our central claim and the empirical linkage to downstream risks. We address each point below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (theoretical analysis): the central claim that output forgetting 'overestimates success' is load-bearing on the premise that deviation from the retrained model's representations constitutes incomplete forgetting. The manuscript does not provide a formal argument or empirical test showing that no other representationally distinct trajectories can achieve effective forgetting (zero membership inference, no reconstruction) while differing from the retrained model; this assumption requires explicit justification or a counter-example analysis.
Authors: We agree that the operational use of the retrained model as the reference for true forgetting requires explicit justification. In the revised manuscript, we will expand §3 with a formal argument establishing that retraining from scratch on the retain set is the unique trajectory guaranteeing removal of forget-set influence (as any representationally distinct model retains latent structure from the forget data). We will also include a brief discussion of why output-level success on alternative trajectories does not constitute complete forgetting under a representation-consistent definition. revision: yes
-
Referee: [Empirical results (§4–5)] Empirical results section (likely §4–5): the reported forget/retain asymmetry and directional concentration are interpreted as evidence of incomplete forgetting, but the paper does not report whether these mismatches correlate with actual downstream risks (e.g., increased reconstruction success or membership inference beyond output level). Without that link, the structured mismatch alone does not yet demonstrate overestimation of unlearning success.
Authors: We acknowledge this limitation in the current empirical presentation. In the revised version of §4–5, we will add correlation analyses between the reported representation mismatch metrics (forget/retain asymmetry and directional concentration) and downstream risks, specifically reconstruction attack success rates and advanced membership inference performance beyond output logits. This will directly link the observed structured mismatches to overestimation of unlearning success. revision: yes
Circularity Check
No significant circularity; retrained model serves as independent external reference
full rationale
The paper's core evaluation compares unlearned models against a separately trained retrained model (trained from scratch on data excluding the forget set). This reference is constructed independently of any unlearning method outputs or fitted parameters within the paper. No equations or claims reduce a 'prediction' or result to the inputs by construction, no self-citations are load-bearing for the central argument, and no ansatz or uniqueness theorem is smuggled in. The derivation chain is self-contained against this external benchmark, consistent with the low circularity expectation for papers using independent references.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The retrained model serves as the correct operational reference for true forgetting.
Reference graph
Works this paper leans on
-
[1]
Towards unbounded ma- chine unlearning.Advances in neural information processing systems, 36:1957–1987, 2023
Meghdad Kurmanji, Peter Triantafillou, Jamie Hayes, and Eleni Triantafillou. Towards unbounded ma- chine unlearning.Advances in neural information processing systems, 36:1957–1987, 2023
1957
-
[2]
Boundary unlearning: Rapid forget- ting of deep networks via shifting the decision boundary
Min Chen, Weizhuo Gao, Gaoyang Liu, Kai Peng, and Chen Wang. Boundary unlearning: Rapid forget- ting of deep networks via shifting the decision boundary. InProceedings of the IEEE/CVF Conference on CVPR, pages 7766–7775, 2023
2023
-
[3]
Fast yet effective ma- chine unlearning.IEEE transactions on neural networks and learning systems, 35(9):13046–13055, 2023
Ayush K Tarun, Vikram S Chundawat, Murari Mandal, and Mohan Kankanhalli. Fast yet effective ma- chine unlearning.IEEE transactions on neural networks and learning systems, 35(9):13046–13055, 2023
2023
-
[4]
Amnesiac machine learning
Laura Graves, Vineel Nagisetty, and Vijay Ganesh. Amnesiac machine learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 11516–11524, 2021
2021
-
[5]
Fast machine unlearning without retraining through selective synaptic dampening
Jack Foster, Stefan Schoepf, and Alexandra Brintrup. Fast machine unlearning without retraining through selective synaptic dampening. InProceedings of the AAAI Conference, volume 38, pages 12043–12051, 2024
2024
-
[6]
Member- ship inference attacks from first principles
Nicholas Carlini, Steve Chien, Milad Nasr, Shuang Song, Andreas Terzis, and Florian Tramer. Member- ship inference attacks from first principles. In2022 IEEE Symposium on Security and Privacy (SP), pages 1897–1914. IEEE, 2022
1914
-
[7]
Towards making systems forget with machine unlearning
Yinzhi Cao and Junfeng Yang. Towards making systems forget with machine unlearning. In2015 IEEE symposium on security and privacy, pages 463–480. IEEE, 2015
2015
-
[8]
Machine unlearning
Lucas Bourtoule, Varun Chandrasekaran, Christopher A Choquette-Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot. Machine unlearning. In2021 IEEE symposium on security and privacy (SP), pages 141–159. IEEE, 2021
2021
-
[9]
Machine unlearning: Solutions and challenges.IEEE Transactions on Emerging Topics in Computational Intelligence, 2024
Jie Xu, Zihan Wu, Cong Wang, and Xiaohua Jia. Machine unlearning: Solutions and challenges.IEEE Transactions on Emerging Topics in Computational Intelligence, 2024
2024
-
[10]
Making ai forget you: Data deletion in machine learning.Advances in neural information processing systems, 32, 2019
Antonio Ginart, Melody Guan, Gregory Valiant, and James Y Zou. Making ai forget you: Data deletion in machine learning.Advances in neural information processing systems, 32, 2019
2019
-
[11]
Can bad teaching induce forgetting? unlearning in deep networks using an incompetent teacher
Vikram S Chundawat, Ayush K Tarun, Murari Mandal, and Mohan Kankanhalli. Can bad teaching induce forgetting? unlearning in deep networks using an incompetent teacher. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 7210–7217, 2023
2023
-
[12]
Unrolling sgd: Understanding factors influencing machine unlearning
Anvith Thudi, Gabriel Deza, Varun Chandrasekaran, and Nicolas Papernot. Unrolling sgd: Understanding factors influencing machine unlearning. In2022 IEEE 7th EuroS&P, pages 303–319. IEEE, 2022
2022
-
[13]
Maverick: Collaboration-free federated unlearning for medical privacy
Win Kent Ong and Chee Seng Chan. Maverick: Collaboration-free federated unlearning for medical privacy. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 358–368. Springer, 2025
2025
-
[14]
Anjie Le, Can Peng, Yuyuan Liu, and J Alison Noble. Pour: A provably optimal method for unlearning representations via neural collapse.arXiv preprint arXiv:2511.19339, 2025
Pith/arXiv arXiv 2025
-
[15]
Eternal sunshine of the spotless net: Selective forgetting in deep networks
Aditya Golatkar, Alessandro Achille, and Stefano Soatto. Eternal sunshine of the spotless net: Selective forgetting in deep networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9304–9312, 2020
2020
-
[16]
Forgetting outside the box: Scrubbing deep networks of information accessible from input-output observations
Aditya Golatkar, Alessandro Achille, and Stefano Soatto. Forgetting outside the box: Scrubbing deep networks of information accessible from input-output observations. InEuropean Conference on Computer Vision, pages 383–398. Springer, 2020
2020
-
[17]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InInternational conference on machine learning, pages 3519–3529. PMlR, 2019
2019
-
[18]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
2009
-
[19]
Tiny imagenet visual recognition challenge.CS 231N, 7(7):3, 2015
Yann Le, Xuan Yang, et al. Tiny imagenet visual recognition challenge.CS 231N, 7(7):3, 2015
2015
-
[20]
Deep unlearning: Fast and efficient gradient-free class forgetting.Transactions on Machine Learning Research, 2024
Sangamesh Kodge, Gobinda Saha, and Kaushik Roy. Deep unlearning: Fast and efficient gradient-free class forgetting.Transactions on Machine Learning Research, 2024. 10
2024
-
[21]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Un- terthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
Pith/arXiv arXiv 2010
-
[22]
Membership inference attacks against machine learning models
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership inference attacks against machine learning models. In2017 IEEE symposium on security and privacy (SP), pages 3–18. IEEE, 2017
2017
-
[23]
Esc: Erasing space concept for knowledge deletion
Tae-Young Lee, Sundong Park, Minwoo Jeon, Hyoseok Hwang, and Gyeong-Moon Park. Esc: Erasing space concept for knowledge deletion. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5010–5019, 2025
2025
-
[24]
Learn to unlearn for deep neural networks: Minimizing unlearning interference with gradient projection
Tuan Hoang, Santu Rana, Sunil Gupta, and Svetha Venkatesh. Learn to unlearn for deep neural networks: Minimizing unlearning interference with gradient projection. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 4819–4828, 2024
2024
-
[25]
Antonio Almud ´evar and Alfonso Ortega. Representation unlearning: Forgetting through information compression.arXiv preprint arXiv:2601.21564, 2026
Pith/arXiv arXiv 2026
-
[26]
Qiuchen Zhang, Carl Yang, Jian Lou, Li Xiong, et al. Contrastive unlearning: A contrastive approach to machine unlearning.arXiv preprint arXiv:2401.10458, 2024
arXiv 2024
-
[27]
Jaewon Lee, Yongwoo Kim, and Donghyun Kim. Erase at the core: Representation unlearning for ma- chine unlearning.arXiv preprint arXiv:2602.05375, 2026
arXiv 2026
-
[28]
Duck: Distance-based unlearning via centroid kinematics.arXiv preprint arXiv:2312.02052, 2023
Marco Cotogni, Jacopo Bonato, Luigi Sabetta, Francesco Pelosin, and Alessandro Nicolosi. Duck: Distance-based unlearning via centroid kinematics.arXiv preprint arXiv:2312.02052, 2023
arXiv 2023
-
[29]
Selective unlearning via representation erasure using domain adversarial training
Nazanin Mohammadi Sepahvand, Eleni Triantafillou, Hugo Larochelle, Doina Precup, James J Clark, Daniel M Roy, and Gintare Karolina Dziugaite. Selective unlearning via representation erasure using domain adversarial training. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[30]
Tao Guo, Song Guo, Jiewei Zhang, Wenchao Xu, and Junxiao Wang. Efficient attribute unlearning: To- wards selective removal of input attributes from feature representations.arXiv preprint arXiv:2202.13295, 2022
arXiv 2022
-
[31]
Are we truly forgetting? a critical re-examination of machine unlearning evaluation protocols.Engineering Applications of Artificial Intelligence, 167:113785, 2026
Yongwoo Kim, Sungmin Cha, and Donghyun Kim. Are we truly forgetting? a critical re-examination of machine unlearning evaluation protocols.Engineering Applications of Artificial Intelligence, 167:113785, 2026
2026
-
[32]
An information theoretic evaluation metric for strong unlearning
Dongjae Jeon, Wonje Jeung, Taeheon Kim, Albert No, and Jonghyun Choi. An information theoretic evaluation metric for strong unlearning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 22173–22181, 2026
2026
-
[33]
Visualizing data using t-sne.Journal of machine learning research, 9(11), 2008
Laurens Van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of machine learning research, 9(11), 2008
2008
-
[34]
Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
Pith/arXiv arXiv 2023
-
[35]
Statistical mia: Rethinking membership inference attack for reliable unlearning auditing
Jialong Sun, Zeming Wei, Jiaxuan Zou, Jiacheng Gong, Guanheng Wang, Chengyang Dong, Jialong Li, and Bo Liu. Statistical mia: Rethinking membership inference attack for reliable unlearning auditing. arXiv preprint arXiv:2602.01150, 2026
Pith/arXiv arXiv 2026
-
[36]
Lotus: Large- scale machine unlearning with a taste of uncertainty
Christoforos N Spartalis, Theodoros Semertzidis, Efstratios Gavves, and Petros Daras. Lotus: Large- scale machine unlearning with a taste of uncertainty. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10046–10055, 2025
2025
-
[37]
Jiatong Yu, Yinghui He, Anirudh Goyal, and Sanjeev Arora. On the impossibility of retrain equivalence in machine unlearning.arXiv preprint arXiv:2510.16629, 2025. 11 A Proof of Theorem 1 Definition 2 motivates a retraining-consistent representation lens because output agreement alone does not determine the internal state of a model. A model may match the ...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.