Do vision-language models search like humans? Reasoning tokens as a reaction-time analog in classic visual-search paradigms
Pith reviewed 2026-06-25 22:57 UTC · model grok-4.3
The pith
Vision-language models reproduce several human visual-search signatures when reasoning-token count is treated as a reaction-time analog, yet reverse the target-present versus target-absent effort ordering and maintain enumeration accuracy w
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
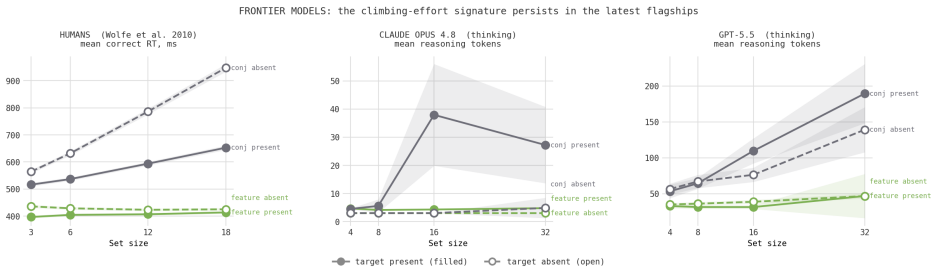
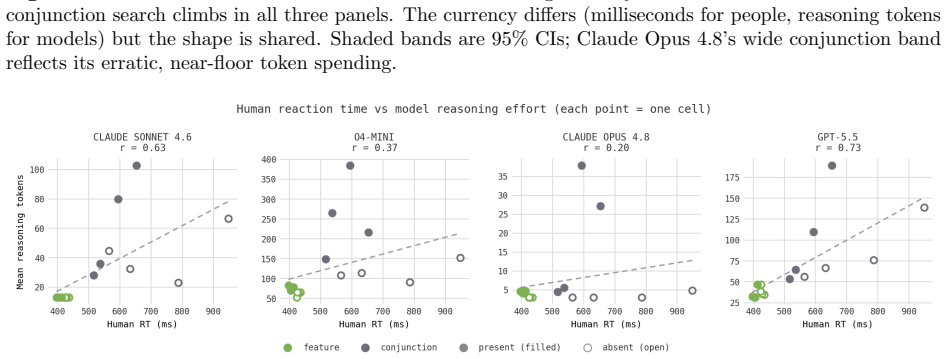
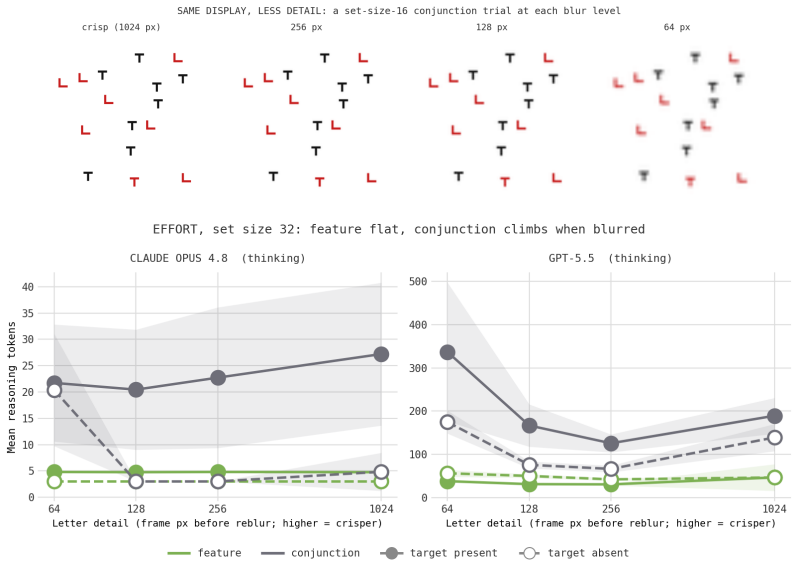
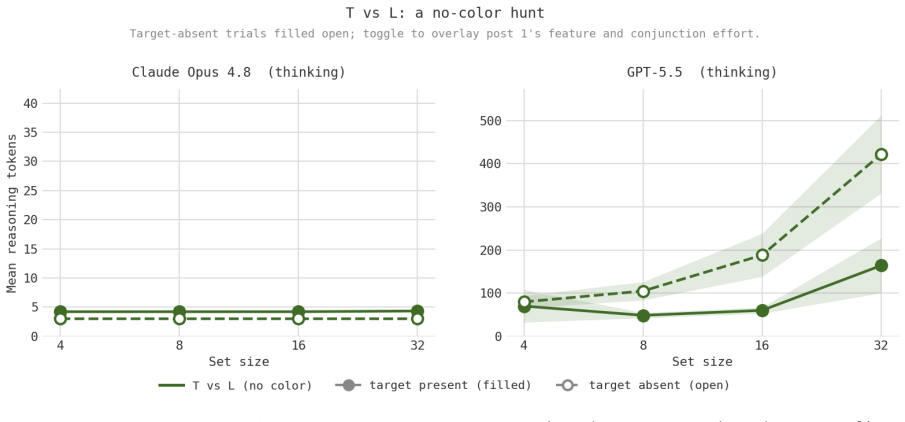
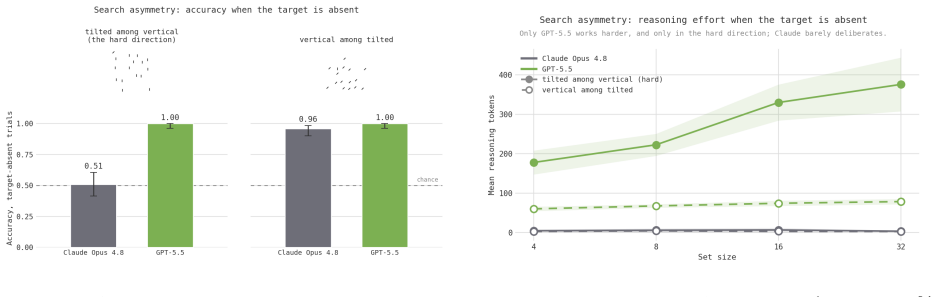
When reasoning-token usage per trial is measured on feature, conjunction, T-L, enumeration, and asymmetry displays and compared with human reaction-time data, token counts remain flat with set size in feature search but increase in conjunction search; this increase survives image enlargement; frontier models sustain accuracy where mid-tier models collapse; yet the target-present effort slope exceeds the target-absent slope (reversing humans) and enumeration accuracy remains high at set sizes where humans would lose count; a reasoning model with adaptive deliberation skips deliberation on detection tasks, turning the same search into an effort gradient in one model and an accuracy cliff in an
What carries the argument
Reasoning-token count per trial, used as a within-model analog of search effort to compare against human reaction times.
If this is right
- Feature search produces flat effort across set size while conjunction search produces rising effort, reproducing the human parallel-versus-serial distinction.
- Frontier models maintain high accuracy on conjunction tasks at set sizes where mid-tier models fall to chance.
- The conjunction-search cost survives enlargement of the stimuli, showing it is not explained by difficulty resolving small shapes.
- Target-present effort slopes exceed target-absent slopes, the opposite of the human ordering.
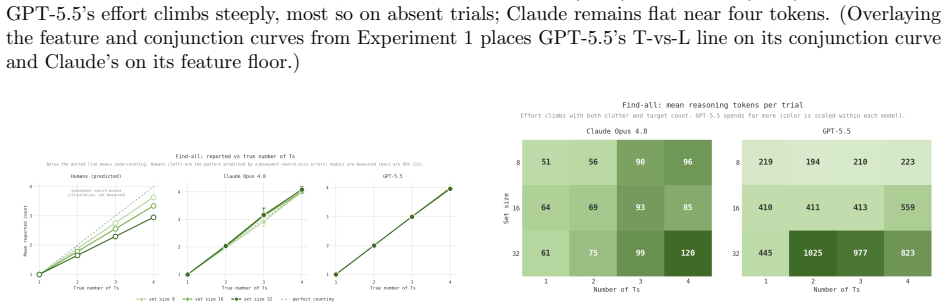
- Enumeration accuracy remains high at larger set sizes where human accuracy declines.
Where Pith is reading between the lines
- If token count genuinely indexes effort, models that can be instructed to vary deliberation depth might be used to test whether the same architecture can switch between effort-gradient and accuracy-cliff regimes on identical images.
- The reversed target-present versus absent ordering could be tested by measuring whether models continue exhaustive inspection after locating a target, unlike humans who terminate early.
- Applying the identical token-count method to other psychophysical tasks such as visual short-term memory or multiple-object tracking could reveal whether the observed search signatures generalize to other attention-like behaviors.
- The accuracy cliff in mid-tier models versus sustained performance in frontier models suggests a scale threshold at which internal representations become sufficient for serial-like search.
Load-bearing premise
The number of reasoning tokens a model spends per trial functions as a valid within-model analog of search effort that can be directly compared to human reaction times.
What would settle it
If the same models are forced to emit a fixed token budget on every trial, the set-size-dependent rise in token count for conjunction search should disappear while accuracy patterns remain unchanged.
Figures
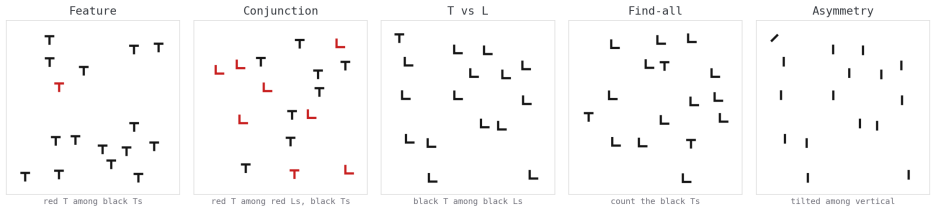

read the original abstract
Visual search has been one of the most productive paradigms in the study of visual attention: the way reaction time scales with the number of items distinguishes parallel, "pop-out" search from serial, attention-demanding search. I ask whether vision-language models (VLMs) exhibit the same behavioral signatures. I adapt four classic paradigms: feature versus conjunction search, spatial-configuration (T-vs-L) search, enumeration, and the tilted/vertical search asymmetry; and present them to current frontier and mid-tier models. Because a single model call has no reaction time, I use the number of reasoning ("thinking") tokens a model spends per trial as a within-model analog of search effort, and I compare against a large public human benchmark (Wolfe et al., 2010). The models reproduce several human signatures: feature search costs flat effort while conjunction effort climbs with set size; frontier models hold accuracy where mid-tier models collapse to chance; and a resolution control shows the conjunction cost is genuine search rather than difficulty resolving small shapes. They also diverge from humans in informative ways. The target-present effort slope exceeds the target-absent slope, reversing the human ordering; enumeration remains accurate where humans would lose count; and a reasoning model with adaptive deliberation declines to deliberate on detection tasks altogether, so that a single search expresses itself as an effort gradient in one model and as an accuracy cliff in another. I argue that psychophysical paradigms, applied behaviorally, are a sharp and inexpensive probe of machine visual cognition, and that the points of divergence are as informative as the points of agreement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper adapts classic visual search paradigms (feature vs. conjunction, T-vs-L, enumeration, search asymmetry) to frontier and mid-tier VLMs, using the count of reasoning tokens per trial as a within-model proxy for human reaction time. It compares results to the Wolfe et al. (2010) human benchmark and reports that models reproduce several signatures (flat feature-search effort, set-size-dependent conjunction effort, frontier models maintaining accuracy) while diverging in others (reversed target-present/absent slopes, preserved enumeration accuracy). A resolution control is cited to argue the conjunction cost reflects search rather than low-level resolution difficulty.
Significance. If the token-count measure can be shown to index visual search effort rather than output-generation length, the work supplies a low-cost, structured behavioral assay for probing machine visual cognition against established human benchmarks. The explicit comparison to a public human dataset and the documentation of both alignments and divergences constitute a useful contribution to the growing literature on model psychophysics.
major comments (3)
- [Abstract] Abstract: The central claim that reasoning-token count functions as a valid analog of search effort is load-bearing for all reported signatures, yet the text provides no ablation that holds output format and instruction constant while varying only visual-search demand; the resolution control rules out pixel-level difficulty but leaves linguistic or enumeration confounds unaddressed.
- [Abstract] Abstract: The reported qualitative matches to human patterns (flat feature-search cost, rising conjunction cost) are presented without quantitative slopes, error bars, statistical tests, or full methods, making it impossible to assess effect sizes or reproducibility against the Wolfe et al. (2010) benchmark.
- [Abstract] Abstract: The divergence that 'target-present effort slope exceeds the target-absent slope' reverses the canonical human ordering; without quantitative data or a stated statistical criterion, it is unclear whether this constitutes a reliable model-human difference or an artifact of token-count measurement.
minor comments (1)
- [Abstract] The abstract refers to 'a large public human benchmark (Wolfe et al., 2010)' but does not specify which exact conditions or dependent measures were extracted for comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and will revise the paper accordingly where the concerns identify gaps in the current presentation or controls.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that reasoning-token count functions as a valid analog of search effort is load-bearing for all reported signatures, yet the text provides no ablation that holds output format and instruction constant while varying only visual-search demand; the resolution control rules out pixel-level difficulty but leaves linguistic or enumeration confounds unaddressed.
Authors: We agree that an ablation isolating visual-search demand while holding output format and instruction fixed would provide stronger evidence. The existing resolution control varies visual complexity under the same search instruction, but does not fully rule out linguistic or enumeration-related token usage. In the revision we will add a control condition in which the model is instructed to enumerate all items without searching for a target, using identical output formatting and prompt structure, to directly compare token counts attributable to search versus enumeration. revision: yes
-
Referee: [Abstract] Abstract: The reported qualitative matches to human patterns (flat feature-search cost, rising conjunction cost) are presented without quantitative slopes, error bars, statistical tests, or full methods, making it impossible to assess effect sizes or reproducibility against the Wolfe et al. (2010) benchmark.
Authors: The abstract is intentionally concise, but the full manuscript reports quantitative slopes, error bars, and statistical comparisons against the Wolfe et al. benchmark in the Results section, with complete methods provided. To address the concern, we will revise the abstract to include key quantitative values (e.g., slopes and confidence intervals) and explicitly reference the statistical tests and methods section. revision: yes
-
Referee: [Abstract] Abstract: The divergence that 'target-present effort slope exceeds the target-absent slope' reverses the canonical human ordering; without quantitative data or a stated statistical criterion, it is unclear whether this constitutes a reliable model-human difference or an artifact of token-count measurement.
Authors: The full manuscript already contains the quantitative slopes and a direct statistical comparison of target-present versus target-absent slopes. We will revise the abstract to report these values explicitly and state the statistical criterion used to identify the reversal as a reliable difference. This will clarify that the divergence is not presented solely qualitatively. revision: yes
Circularity Check
No circularity: empirical comparison to external benchmark
full rationale
The paper performs a direct empirical test by feeding visual-search stimuli to VLMs and recording reasoning-token counts, then comparing the resulting set-size slopes and accuracy patterns against the independent Wolfe et al. 2010 human data set. No equations, fitted parameters, or self-citations appear in the derivation; the token-count proxy is introduced as a measurement choice rather than derived from the target patterns themselves. The reported signatures therefore stand or fall on the observed model outputs versus the external benchmark, with no reduction by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Number of reasoning tokens per trial measures search effort in a manner comparable to human reaction time
Reference graph
Works this paper leans on
-
[1]
Budny, N., Ghods, K., Campbell, D., Marjieh, R., Joshi, A., Kumar, S., Cohen, J. D., Webb, T. W., & Griffiths, T. L. (2025).Visual serial processing deficits explain divergences in human and VLM reasoning. arXiv. https://arxiv.org/abs/2509.25142
arXiv 2025
-
[2]
S., & Mitroff, S
Cain, M. S., & Mitroff, S. R. (2013). Memory for found targets interferes with subsequent performance in multiple-target visual search.Journal of Experimental Psychology: Human Perception and Performance,39(5), 1398–1408
2013
-
[3]
Campbell, D., Rane, S., Giallanza, T., De Sabbata, N., Ghods, K., Joshi, A., Ku, A., Frankland, S. M., Griffiths, T. L., Cohen, J. D., & Webb, T. (2024). Understanding the limits of vision language models through the lens of the binding problem.Advances in Neural Information Processing Systems,37. https://arxiv.org/abs/2411.00238 12
arXiv 2024
-
[4]
satisfaction of search
Fleck, M. S., Samei, E., & Mitroff, S. R. (2010). Generalized “satisfaction of search”: Adverse influences on dual-target search accuracy.Journal of Experimental Psychology: Applied,16(1), 60–71
2010
-
[5]
Fu, X., Hu, Y., Li, B., Feng, Y., Wang, H., Lin, X., Roth, D., Smith, N. A., Ma, W.-C., & Krishna, R. (2024). BLINK: Multimodal large language models can see but not perceive. InEuropean Conference on Computer Vision (ECCV). https://arxiv.org/abs/2404.12390
Pith/arXiv arXiv 2024
-
[6]
Hulleman, J., Lund, K., & Skarratt, P. A. (2020). Medium versus difficult visual search: How a quantitative change in the functional visual field leads to a qualitative difference in performance
2020
-
[7]
https://doi.org/10.3758/s13414-019- 01787-4
Attention, Perception, & Psychophysics,82(1), 118–139. https://doi.org/10.3758/s13414-019- 01787-4
-
[8]
M., Horowitz, T
Palmer, E. M., Horowitz, T. S., Torralba, A., & Wolfe, J. M. (2011). What are the shapes of response time distributions in visual search?Journal of Experimental Psychology: Human Perception and Performance,37(1), 58–71
2011
-
[9]
Rahmanzadehgervi, P., Bolton, L., Taesiri, M. R., & Nguyen, A. T. (2024). Vision language models are blind. InProceedings of the Asian Conference on Computer Vision (ACCV)(pp. 18–34). https://arxiv.org/abs/2407.06581
arXiv 2024
-
[10]
Treisman, A. M., & Gelade, G. (1980). A feature-integration theory of attention.Cognitive Psychology, 12(1), 97–136. https://doi.org/10.1016/0010-0285(80)90005-5
-
[11]
Treisman, A., & Gormican, S. (1988). Feature analysis in early vision: Evidence from search asymmetries.Psychological Review,95(1), 15–48. https://doi.org/10.1037/0033-295X.95.1.15
-
[12]
M., & Pylyshyn, Z
Trick, L. M., & Pylyshyn, Z. W. (1994). Why are small and large numbers enumerated differently? A limited-capacity preattentive stage in vision.Psychological Review,101(1), 80–102
1994
-
[13]
Ullman, S. (1984). Visual routines.Cognition,18(1–3), 97–159. https://doi.org/10.1016/0010- 0277(84)90023-4
-
[14]
H., Le, Q
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E. H., Le, Q. V., & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models.Advances in Neural Information Processing Systems,35
2022
-
[15]
Wolfe, J. M. (2021). Guided Search 6.0: An updated model of visual search.Psychonomic Bulletin & Review,28(4), 1060–1092
2021
-
[16]
M., Cave, K
Wolfe, J. M., Cave, K. R., & Franzel, S. L. (1989). Guided search: An alternative to the feature integration model for visual search.Journal of Experimental Psychology: Human Perception and Performance,15(3), 419–433
1989
-
[17]
Wolfe, J. M., Palmer, E. M., & Horowitz, T. S. (2010). Reaction time distributions constrain models of visual search.Vision Research,50(14), 1304–1311. https://doi.org/10.1016/j.visres.2009.11.002 13
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.