Training for the Model You Return: Improving Optimization for Iterate-Averaged Language Models
Pith reviewed 2026-07-01 06:34 UTC · model grok-4.3
The pith
Redesigning the optimizer around the final averaged model rather than the last iterate can reduce limiting error by an arbitrary factor in quadratic settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the continuous-time stochastic quadratic model the optimal control that minimizes error of the returned iterate average produces a feedback term whose effect is to reduce the limiting squared error of that average relative to ordinary stochastic gradient flow, and the reduction factor can be made arbitrarily large by choice of problem instance. A discrete, per-coordinate, clipped approximation to the same controller, when wrapped around AdamW, converges at the usual stochastic convex rate up to a constant that depends only on the averaging schedule, while empirical runs on language-model tasks show lower validation loss for the returned average across wide ranges of learning rates and sch
What carries the argument
PACE, a lightweight per-coordinate feedback that applies a clipped pull of the live weights toward their exponential moving average at each step.
If this is right
- PACE preserves the standard stochastic convex optimization convergence rate up to a factor that depends only on the averaging rule.
- In the quadratic model the same controller strictly lowers the limiting squared error of the iterate average and can do so by an arbitrarily large factor on some instances.
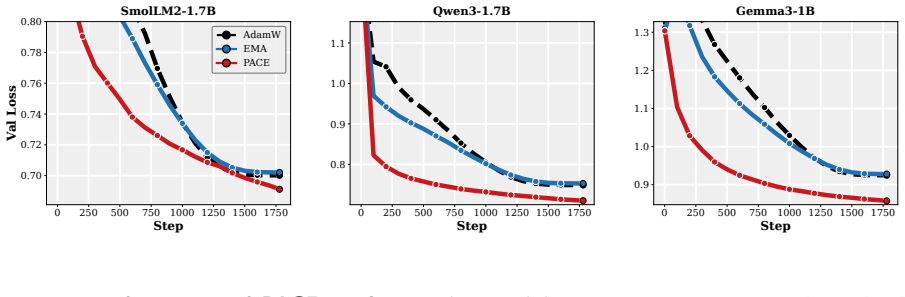
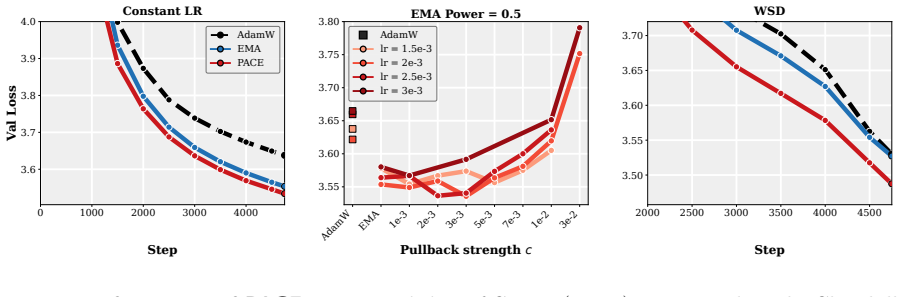
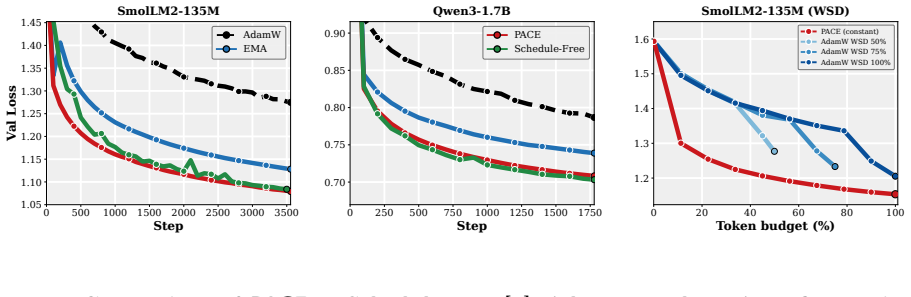
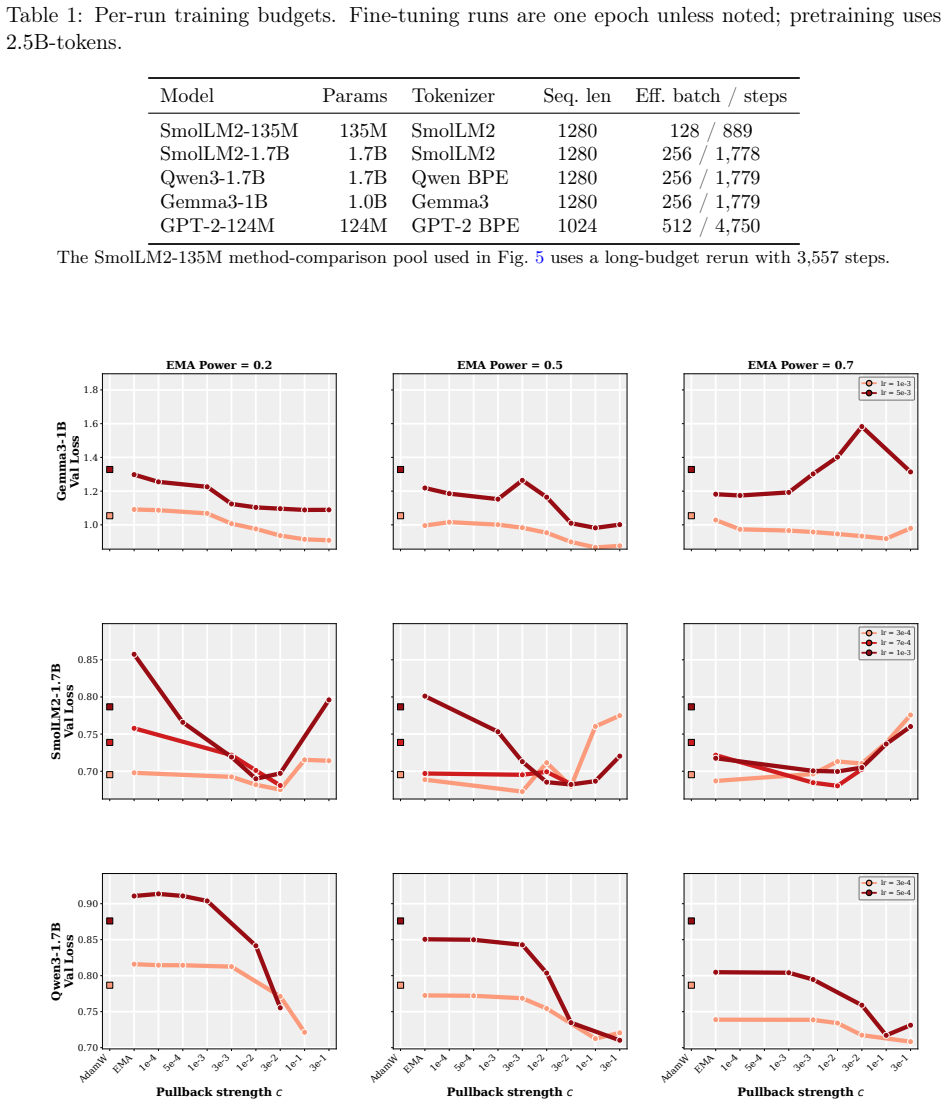
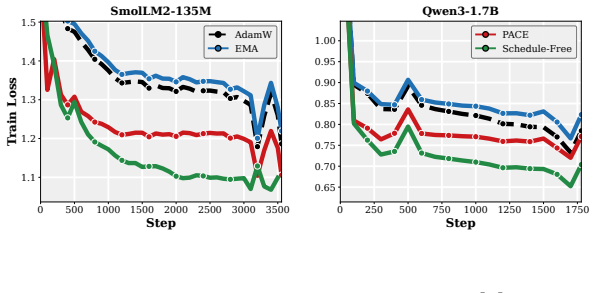
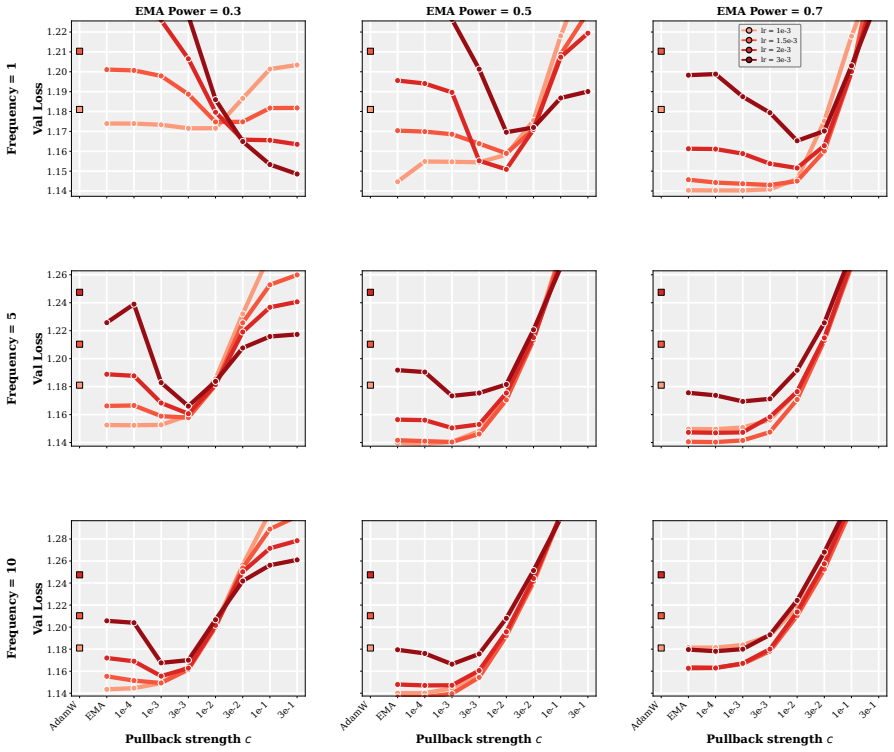
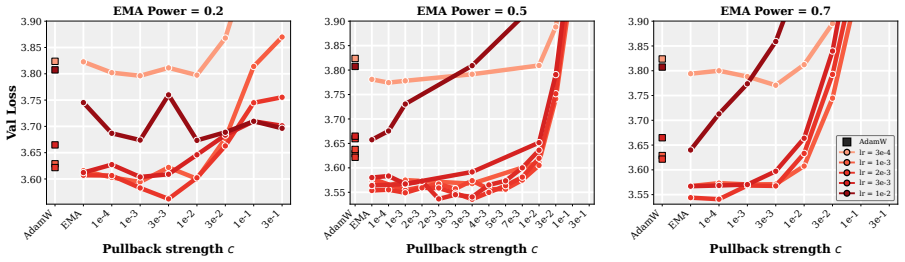
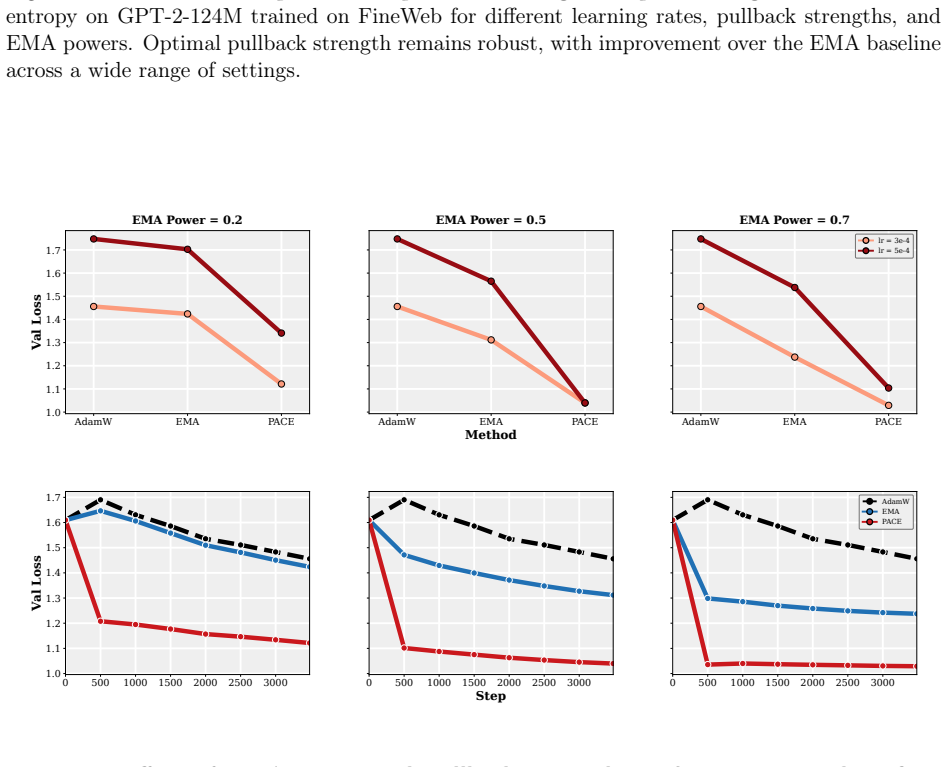
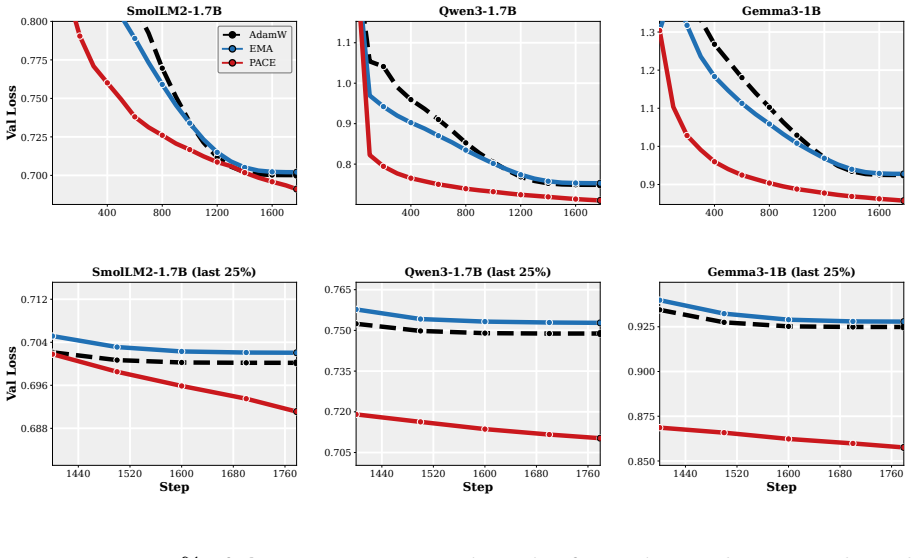
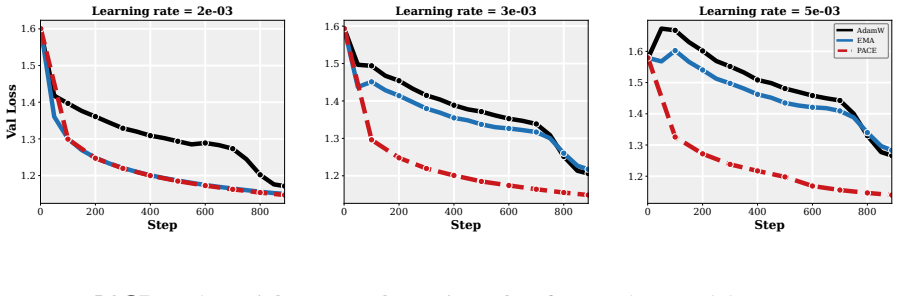
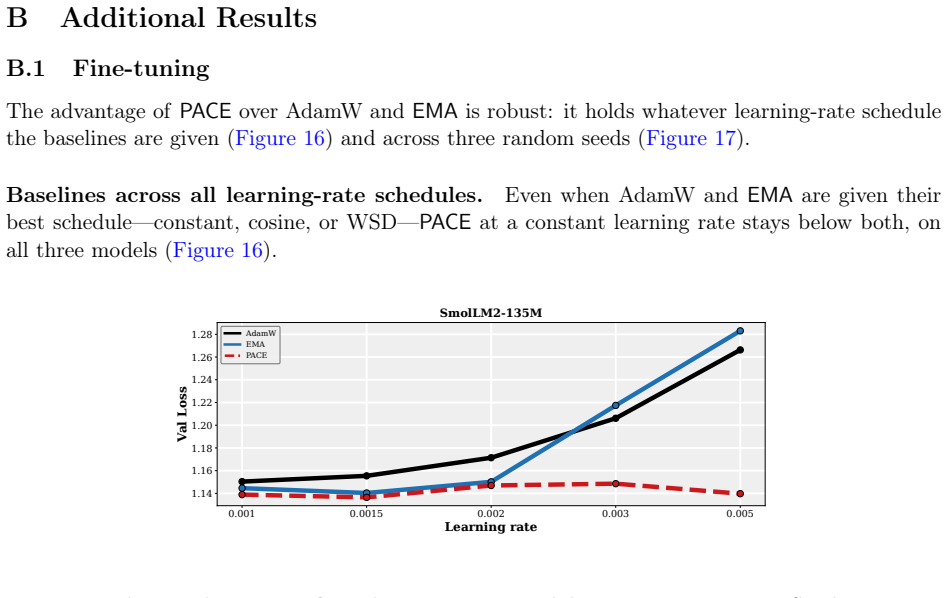
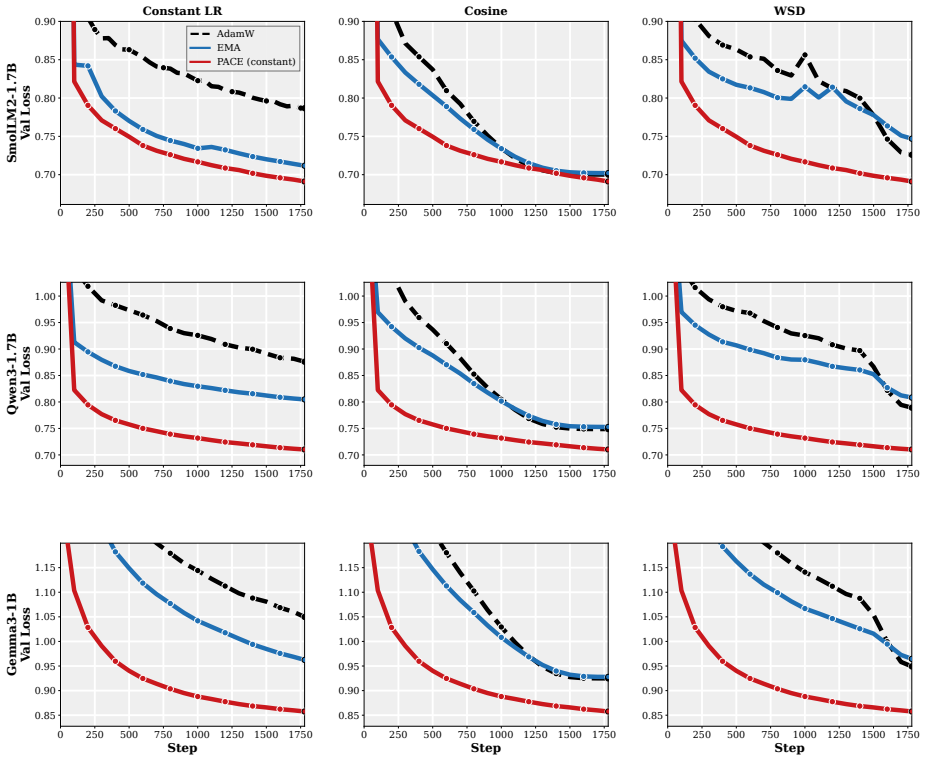
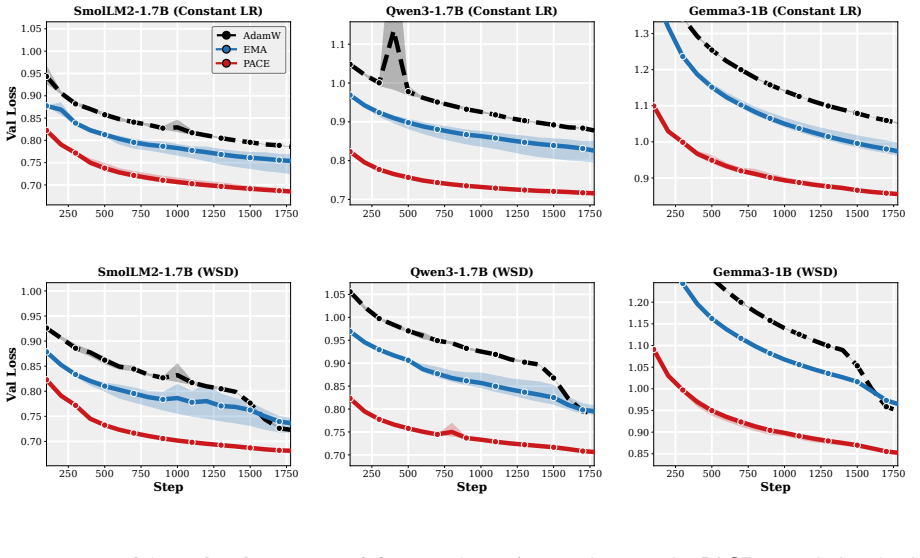
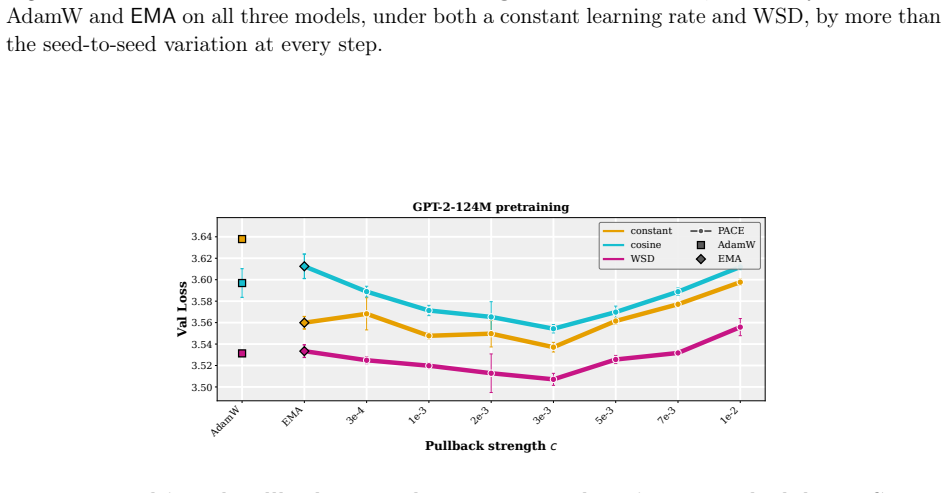
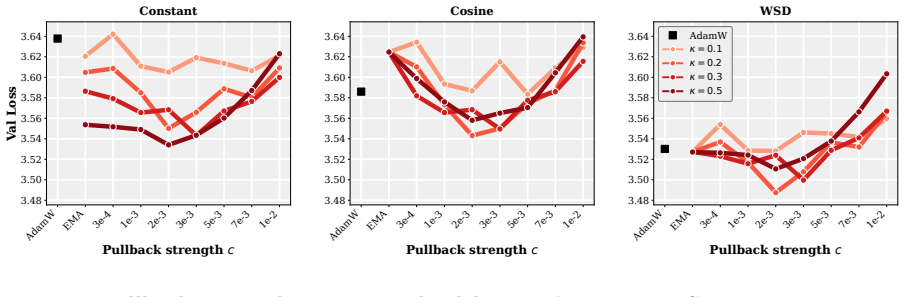
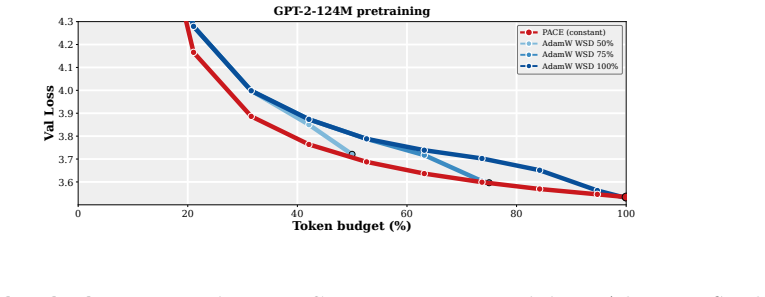
- The practical PACE wrapper improves validation performance of the returned average over both plain AdamW and EMA-evaluated AdamW in supervised fine-tuning of 1-2B LMs and in GPT-2 pretraining on FineWeb.
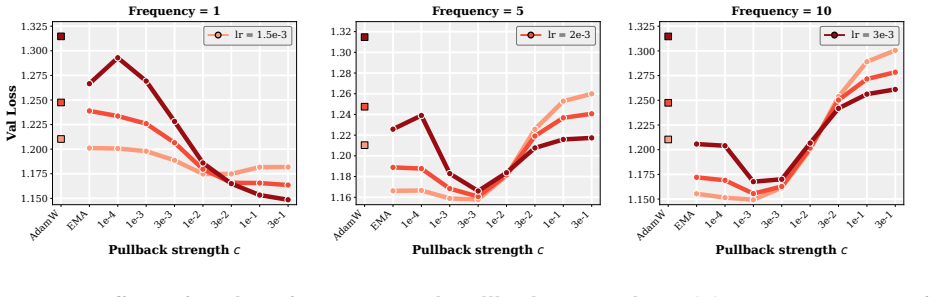
- The improvement holds across wide ranges of learning rates, decay schedules, and other hyperparameters.
Where Pith is reading between the lines
- If the quadratic proxy captures the dominant curvature and noise structure, analogous control laws could be derived for other common averaging schemes such as Polyak or uniform moving averages.
- The per-coordinate clipping used in PACE may allow the method to be applied safely even when the quadratic assumption is only locally valid.
- The same optimal-control framing could be used to redesign training when the final model will be obtained by any deterministic post-processing of the training trajectory.
Load-bearing premise
The continuous-time stochastic quadratic model is representative enough of the loss surfaces and noise statistics encountered in transformer training that a controller derived inside it remains useful when transferred to AdamW.
What would settle it
A controlled experiment on multiple 1-2B model runs in which PACE produces no statistically significant reduction in final averaged-model validation loss relative to plain AdamW across matched learning-rate and decay schedules.
Figures
read the original abstract
Many modern Language Model (LM) pipelines return an averaged model, such as an exponential moving average of the training iterates, rather than the final iterate itself. This raises a fundamental question: given that we will return an iterate average, how should we change training to improve the performance of this average? We study this question by formulating optimizer design for the iterate-average estimator as an optimal-control problem. In a continuous-time stochastic quadratic model, we solve for the control strategy that minimizes the error of the returned average subject to a penalty on the size of the intervention. A practical approximation to this controller yields PACE, a lightweight wrapper around AdamW that pulls the live weights toward their exponential moving average with a clipped, per-coordinate control strength. We prove that a stylized version of PACE converges at the standard stochastic convex optimization rate, up to a factor depending on the averaging rule, while in the quadratic setting it can strictly improve the limiting squared error of the iterate-average estimator and can do so by an arbitrarily large factor on some instances. Empirically, our results suggest that PACE improves over AdamW and EMA-evaluated AdamW in supervised fine-tuning of 1-2B parameter LMs and in GPT-2 pretraining on FineWeb for a wide range of learning rates, decay schedules, and other hyperparameters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript formulates optimizer design for iterate-averaged models (common in LM pipelines) as an optimal-control problem. In a continuous-time stochastic quadratic model, it solves for the control that minimizes error of the returned average subject to an intervention penalty. A practical approximation yields PACE, a lightweight per-coordinate wrapper around AdamW that pulls live weights toward their EMA. The paper proves that a stylized PACE converges at the standard stochastic convex rate (up to an averaging-rule factor), shows that the quadratic controller can strictly reduce limiting squared error and can do so by an arbitrarily large factor on some instances, and reports empirical gains over AdamW and EMA-evaluated AdamW in 1-2B LM fine-tuning and GPT-2 pretraining on FineWeb across learning rates and schedules.
Significance. If the quadratic derivation and its transfer hold, the work supplies a principled, control-theoretic route to optimizer design that is explicitly tailored to the estimator that will actually be returned rather than to the final iterate. The unbounded-improvement claim in the quadratic case supplies a concrete, falsifiable prediction about when averaging-aware training can matter most. The empirical results, if reproducible, indicate that the derived controller remains useful when instantiated as PACE on real transformer training.
major comments (2)
- [Abstract / quadratic analysis] Abstract and quadratic-analysis section: the claim that the controller 'can do so by an arbitrarily large factor on some instances' is load-bearing for the theoretical contribution. The manuscript must explicitly construct or parameterize at least one family of instances (e.g., specific noise covariance, damping, or initial conditions) together with the numerical reduction factor achieved, so that the unboundedness statement can be verified rather than asserted.
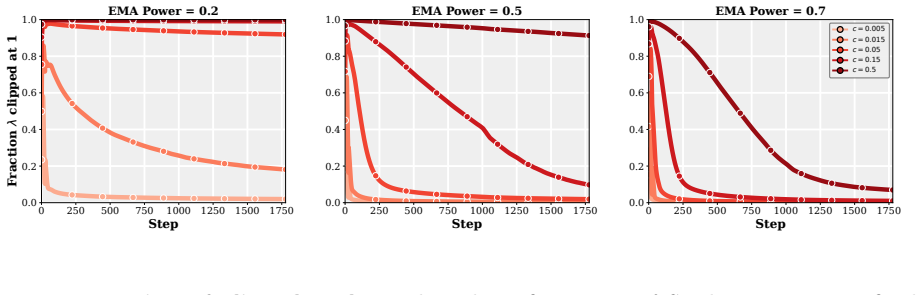
- [PACE controller definition] Section describing the practical controller: the per-coordinate control strength is described as 'chosen to match the model.' Because this choice is part of the approximation that is then transferred to AdamW on transformers, the manuscript should state the exact rule used to set the strength (including any dependence on observed gradient statistics) and demonstrate that the same rule does not require post-hoc tuning on the target task.
minor comments (2)
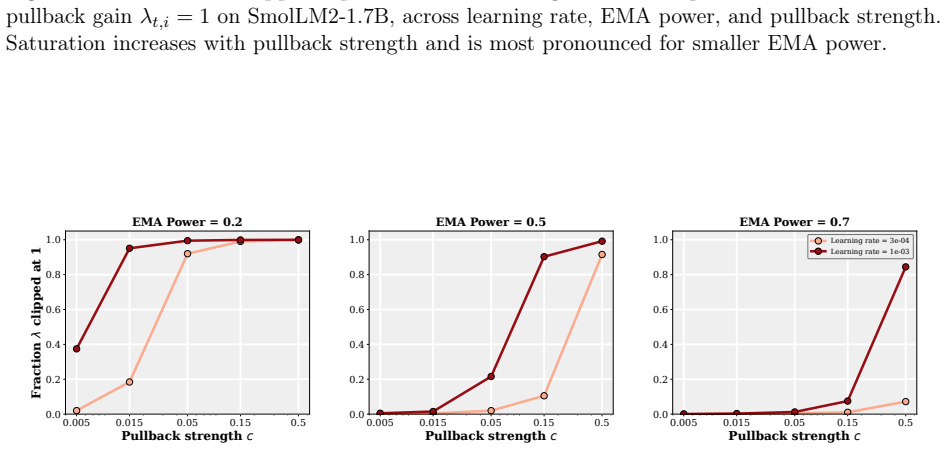
- [Experiments] The experimental section should report the precise ranges and number of random seeds for the 'wide range of learning rates, decay schedules, and other hyperparameters' so that the robustness claim can be assessed quantitatively.
- [Figures / experimental setup] Figure captions and the definition of 'EMA-evaluated AdamW' should be expanded to make clear whether the baseline uses the same averaging window and decay as PACE or a different one.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / quadratic analysis] Abstract and quadratic-analysis section: the claim that the controller 'can do so by an arbitrarily large factor on some instances' is load-bearing for the theoretical contribution. The manuscript must explicitly construct or parameterize at least one family of instances (e.g., specific noise covariance, damping, or initial conditions) together with the numerical reduction factor achieved, so that the unboundedness statement can be verified rather than asserted.
Authors: We agree that an explicit, verifiable construction strengthens the claim. In the revised manuscript we will add (in the quadratic-analysis section or a short appendix) a parameterized family of instances: diagonal quadratic problems with noise covariance Σ = diag(σ_{1}^{2}, …, σ_d^{2}), damping matrix D = diag(λ_{1}, …, λ_d), and initial condition x_{0}. We parameterize the family by letting the ratio max(σ_i^{2} / λ_i) / min(σ_j^{2} / λ_j) grow without bound while keeping the optimal-control solution closed-form. For each member we will report the exact limiting squared error of the uncontrolled EMA versus the controlled trajectory, together with the numerical reduction factor, thereby making the “arbitrarily large” statement directly checkable. revision: yes
-
Referee: [PACE controller definition] Section describing the practical controller: the per-coordinate control strength is described as 'chosen to match the model.' Because this choice is part of the approximation that is then transferred to AdamW on transformers, the manuscript should state the exact rule used to set the strength (including any dependence on observed gradient statistics) and demonstrate that the same rule does not require post-hoc tuning on the target task.
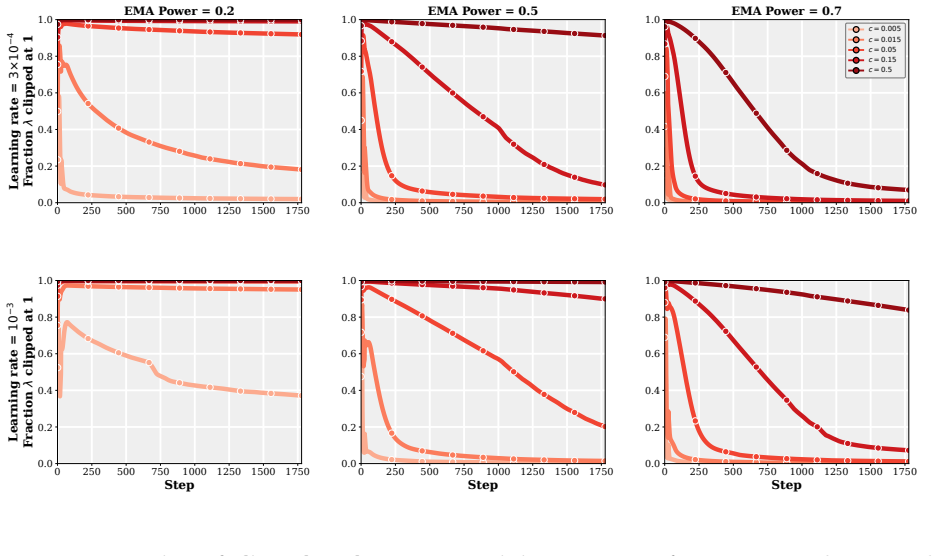
Authors: We will revise the PACE definition section to give the precise rule. The per-coordinate strength α_i is obtained by matching the continuous-time optimal gain to the discrete AdamW step: α_i = clip( c · β / (1 − β) · √ v_i , 0, 1), where v_i is the Adam second-moment estimate already maintained by AdamW, β is the EMA decay, and c is a small universal constant fixed once for all experiments. Because v_i is computed from the same gradients AdamW already uses, the rule introduces no extra statistics or task-specific hyperparameters. We will add a short paragraph (and a supplementary table) confirming that this identical formula—without any per-run or per-task adjustment—was applied uniformly to every learning-rate, schedule, and model-size experiment reported in the paper. revision: yes
Circularity Check
No significant circularity
full rationale
The central derivation formulates optimizer design as an optimal-control problem in a continuous-time stochastic quadratic model and solves for the minimizing control; this is a self-contained mathematical exercise whose solution (including the unbounded improvement factor on some instances) follows directly from the stated dynamics and objective without reducing to fitted parameters, self-citations, or renamed empirical patterns. The practical PACE controller is explicitly described as an approximation, the convergence proof is stated for a stylized version, and empirical LM results are presented only as validation. No load-bearing step collapses to its own inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- per-coordinate control strength
axioms (1)
- domain assumption Continuous-time stochastic quadratic dynamics are representative of the optimization trajectory of language-model training under AdamW
Reference graph
Works this paper leans on
-
[1]
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
Loubna Ben Allal, Anton Lozhkov, Elie Bakouch, Gabriel Martín Blázquez, Guilherme Penedo, Lewis Tunstall, Andrés Marafioti, Hynek Kydlíček, Agustín Piqueres Lajarín, Vaibhav Srivas- tav, et al. SmolLM2: When smol goes big – data-centric training of a small language model. arXiv preprint arXiv:2502.02737, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
SmolTalk: A synthetic instruction-tuning dataset accompanying SmolLM2.https://huggingface.co/datasets/ HuggingFaceTB/smoltalk, 2025
Loubna Ben Allal, Anton Lozhkov, Elie Bakouch, Gabriel Martín Blázquez, Guilherme Penedo, Lewis Tunstall, Leandro von Werra, and Thomas Wolf. SmolTalk: A synthetic instruction-tuning dataset accompanying SmolLM2.https://huggingface.co/datasets/ HuggingFaceTB/smoltalk, 2025. Released alongside SmolLM2 [1]
2025
-
[3]
Ema without the lag: Bias-corrected iterate averaging schemes
Adam Block and Cyril Zhang. Ema without the lag: Bias-corrected iterate averaging schemes. arXiv preprint arXiv:2508.00180, 2025
-
[4]
Adam Block, Youssef Mroueh, and Alexander Rakhlin. Generative modeling with denoising auto-encoders and langevin sampling.arXiv preprint arXiv:2002.00107, 2020
-
[5]
Butterfly effects of sgd noise: Error amplification in behavior cloning and autoregression
Adam Block, Dylan J Foster, Akshay Krishnamurthy, Max Simchowitz, and Cyril Zhang. Butterfly effects of sgd noise: Error amplification in behavior cloning and autoregression. In The Twelfth International Conference on Learning Representations, 2024
2024
-
[6]
Springer, 2002
Peter J Brockwell and Richard A Davis.Introduction to time series and forecasting. Springer, 2002
2002
-
[7]
How to scale your ema.Advances in Neural Information Processing Systems, 36:73122–73174, 2023
Dan Busbridge, Jason Ramapuram, Pierre Ablin, Tatiana Likhomanenko, Eeshan Gunesh Dhekane, Xavier Suau Cuadros, and Russell Webb. How to scale your ema.Advances in Neural Information Processing Systems, 36:73122–73174, 2023
2023
-
[8]
Koala: A kalman optimization algorithm with loss adaptivity
Aram Davtyan, Sepehr Sameni, Llukman Cerkezi, Givi Meishvili, Adam Bielski, and Paolo Favaro. Koala: A kalman optimization algorithm with loss adaptivity. InProceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 6471–6479, 2022
2022
-
[9]
The road less scheduled
Aaron Defazio, Xingyu Alice Yang, Harsh Mehta, Konstantin Mishchenko, Ahmed Khaled, and Ashok Cutkosky. The road less scheduled. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[10]
Adaptive subgradient methods for online learning and stochastic optimization.Journal of machine learning research, 12(7), 2011
John Duchi, Elad Hazan, and Yoram Singer. Adaptive subgradient methods for online learning and stochastic optimization.Journal of machine learning research, 12(7), 2011
2011
-
[11]
Gemma Team, Google DeepMind. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025. 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
The separation principle in stochastic control, redux.IEEE Transactions on Automatic Control, 58(10):2481–2494, 2013
Tryphon T Georgiou and Anders Lindquist. The separation principle in stochastic control, redux.IEEE Transactions on Automatic Control, 58(10):2481–2494, 2013
2013
-
[13]
Shampoo: Preconditioned stochastic tensor optimization
Vineet Gupta, Tomer Koren, and Yoram Singer. Shampoo: Preconditioned stochastic tensor optimization. InInternational Conference on Machine Learning, pages 1842–1850. PMLR, 2018
2018
-
[14]
Training compute-optimal large language models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W Rae, Oriol Vinyals, and Laurent Sifre....
2022
-
[15]
Averaging Weights Leads to Wider Optima and Better Generalization
Pavel Izmailov, Dmitrii Podoprikhin, Timur Garipov, Dmitry Vetrov, and Andrew Gordon Wilson. Averaging weights leads to wider optima and better generalization.arXiv preprint arXiv:1803.05407, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[16]
Muon: An optimizer for hidden layers in neural networks, 2024
Keller Jordan, Yuchen Jin, Vlado Boza, Jiacheng You, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks, 2024. URL https://kellerjordan.github.io/posts/muon/
2024
-
[17]
Jean Kaddour. Stop wasting my time! saving days of imagenet and bert training with latest weight averaging.arXiv preprint arXiv:2209.14981, 2022
-
[18]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[19]
Statistical inference for ergodic diffusion processes
Yury A Kutoyants, Yury A Kutoyants, and Y Kutoyants. Statistical inference for ergodic diffusion processes. 2004
2004
-
[20]
Wiley- interscience New York, 1972
Huibert Kwakernaak and Raphael Sivan.Linear optimal control systems, volume 1. Wiley- interscience New York, 1972
1972
-
[21]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James Validad Miranda, Alisa Liu, Nouha Dziri, Xinxi Lyu, Yuling Gu, Saumya Malik, Victoria Graf, Jena D. Hwang, Jiangjiang Yang, Ronan Le Bras, Oyvind Tafjord, Christopher Wilhelm, Luca Soldaini, Noah A. Smith, Yizhong Wang, Pradeep Dasigi, and Hannaneh...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Analysis and design of optimization algorithms via integral quadratic constraints.SIAM Journal on Optimization, 26(1):57–95, 2016
Laurent Lessard, Benjamin Recht, and Andrew Packard. Analysis and design of optimization algorithms via integral quadratic constraints.SIAM Journal on Optimization, 26(1):57–95, 2016
2016
-
[23]
Hong Liu, Zhiyuan Li, David Hall, Percy Liang, and Tengyu Ma. Sophia: A scalable stochastic second-order optimizer for language model pretraining.arXiv preprint arXiv:2305.14342, 2023
-
[24]
Decoupled Weight Decay Regularization
Ilya Loshchilov, Frank Hutter, et al. Fixing weight decay regularization in adam.arXiv preprint arXiv:1711.05101, 5(5):5, 2017. 14
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
On the sdes and scaling rules for adaptive gradient algorithms.Advances in Neural Information Processing Systems, 35:7697–7711, 2022
Sadhika Malladi, Kaifeng Lyu, Abhishek Panigrahi, and Sanjeev Arora. On the sdes and scaling rules for adaptive gradient algorithms.Advances in Neural Information Processing Systems, 35:7697–7711, 2022
2022
-
[26]
Continuous-time limit of stochastic gradient descent revisited.NIPS-2015, 2015
Stephan Mandt, Matthew D Hoffman, David M Blei, et al. Continuous-time limit of stochastic gradient descent revisited.NIPS-2015, 2015
2015
-
[27]
Team OLMo, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bhagia, Yuling Gu, Shengyi Huang, Matt Jordan, et al. 2 olmo 2 furious.arXiv preprint arXiv:2501.00656, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
The AdEMAMix optimizer: Better, faster, older.arXiv preprint arXiv:2409.03137, 2024
Matteo Pagliardini, Pierre Ablin, and David Grangier. The AdEMAMix optimizer: Better, faster, older.arXiv preprint arXiv:2409.03137, 2024
-
[29]
The FineWeb datasets: Decanting the web for the finest text data at scale
Guilherme Penedo, Hynek Kydlíček, Loubna Ben Allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro von Werra, and Thomas Wolf. The FineWeb datasets: Decanting the web for the finest text data at scale. InAdvances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2024
2024
-
[30]
Acceleration of stochastic approximation by averaging
Boris T Polyak and Anatoli B Juditsky. Acceleration of stochastic approximation by averaging. SIAM journal on control and optimization, 30(4):838–855, 1992
1992
-
[31]
Language models are unsupervised multitask learners.OpenAI Technical Report, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners.OpenAI Technical Report, 2019
2019
-
[32]
Efficient estimations from a slowly convergent robbins-monro process
David Ruppert. Efficient estimations from a slowly convergent robbins-monro process. Tech- nical report, Cornell University Operations Research and Industrial Engineering, 1988
1988
-
[33]
Springer, 2006
Robert H Shumway and David S Stoffer.Time series analysis and its applications: with R examples. Springer, 2006
2006
-
[34]
Through the river: Un- derstanding the benefit of schedule-free methods for language model training
Minhak Song, Beomhan Baek, Kwangjun Ahn, and Chulhee Yun. Through the river: Un- derstanding the benefit of schedule-free methods for language model training. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. arXiv:2507.09846
-
[35]
The certainty equivalence property in stochastic control theory.IEEE Transactions on Automatic Control, 26(5):1080–1087, 1981
Henk Van de Water and Jan Willems. The certainty equivalence property in stochastic control theory.IEEE Transactions on Automatic Control, 26(5):1080–1087, 1981
1981
-
[36]
SOAP: Improving and Stabilizing Shampoo using Adam
Nikhil Vyas, Depen Morwani, Rosie Zhao, Mujin Kwun, Itai Shapira, David Brandfonbrener, Lucas Janson, and Sham Kakade. Soap: Improving and stabilizing shampoo using adam.arXiv preprint arXiv:2409.11321, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Kaiyue Wen, Zhiyuan Li, Jason Wang, David Hall, Percy Liang, and Tengyu Ma. Under- standing warmup-stable-decay learning rates: A river valley loss landscape perspective.arXiv preprint arXiv:2410.05192, 2024
-
[38]
Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time
Mitchell Wortsman, Gabriel Ilharco, Samir Ya Gadre, Rebecca Roelofs, Raphael Gontijo-Lopes, Ari S Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, et al. Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. InInternational conference on machine learning, pages 23965–23998. P...
2022
-
[39]
Zixuan Xia, Aram Davtyan, and Paolo Favaro. Koala++: Efficient kalman-based optimization with gradient-covariance products.arXiv preprint arXiv:2506.04432, 2025
-
[40]
An Yang, Anwen Anwar, Baosong Bao, Beichen Bi, Bo Cai, Changjian Chen, Chao Chen, Daohai Chen, Daniel Chen, Daoguang Cheng, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Springer Science & Business Media, 1999
JiongminYongandXunYuZhou.Stochastic controls: Hamiltonian systems and HJB equations, volume 43. Springer Science & Business Media, 1999
1999
-
[42]
Which algorithmic choices matter at which batch sizes? insights from a noisy quadratic model.Advances in neural information processing systems, 32, 2019
Guodong Zhang, Lala Li, Zachary Nado, James Martens, Sushant Sachdeva, George Dahl, Chris Shallue, and Roger B Grosse. Which algorithmic choices matter at which batch sizes? insights from a noisy quadratic model.Advances in neural information processing systems, 32, 2019
2019
-
[43]
Lookahead optimizer: k steps forward, 1 step back.Advances in neural information processing systems, 32, 2019
Michael Zhang, James Lucas, Jimmy Ba, and Geoffrey E Hinton. Lookahead optimizer: k steps forward, 1 step back.Advances in neural information processing systems, 32, 2019
2019
-
[44]
Deep learning with elastic averaging sgd.Advances in neural information processing systems, 28, 2015
Sixin Zhang, Anna E Choromanska, and Yann LeCun. Deep learning with elastic averaging sgd.Advances in neural information processing systems, 28, 2015. 16 Contents 1 Introduction 1 2 Algorithm Derivation and Guarantees 4 2.1 Formal Problem Setup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 2.2 Derivation of the Optimal Control St...
2015
-
[45]
hill” directions of a valley while making steady progress along its flat “river
Some supplementary sweeps usetulu-3[21] with the same supervised fine-tuning pipeline. For pretraining, we train GPT-2-124M onFineWeb[29]. Models.Table 1 summarises the five model families we consider. The fine-tuning models are initialized from the official Hugging Face checkpoints. SmolLM2 and Gemma3 use their native tokenizers. Training.Unless stated o...
2024
-
[46]
We will consider only the diagonal setting, where the coordinates decouple and we can solve for the optimal controller in closed form
-
[47]
We will approximatebµt = 1 t R t 0 θu s ds, which is a natural estimator ofµ⋆ given the trajectory ofθ u t up to timet
-
[48]
The first approximation allows for the closed-form solution to the optimal controller, which we derived above
We will approximate the optimal controller by its form whent≪T, which is the regime we are in for most of the optimization trajectory. The first approximation allows for the closed-form solution to the optimal controller, which we derived above. The second approximation is a natural one, asbµt becomes simple to estimate and is naturally aligned with the c...
-
[49]
bθk+1 bθk # = 2−a−β−c(1−β)−(1−β)(1−a−c) 1 0
and ensures that the algorithm is stable. Assumption F.3.We assume that the learning rateηsatisfies0< ηα i <1for all1≤i≤d. Note that in the special case theC= 0, we recover the dynamics of an EMA on SGD precisely. 47 Proposition 5.Suppose thatFis as in(28)and gradient estimatesg k are as in(29). Let bθT denote the update at timeTgiven by(22)for fixedηsati...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.