Forget to Improve: On-Device LLM-Agent Continual Learning via Budget-Curated Memory
Pith reviewed 2026-06-25 23:58 UTC · model grok-4.3
The pith
A net-value-per-byte score lets on-device LLM agents forget low-value memory entries to cut footprint, energy, uplink and poisoning while preserving or raising accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
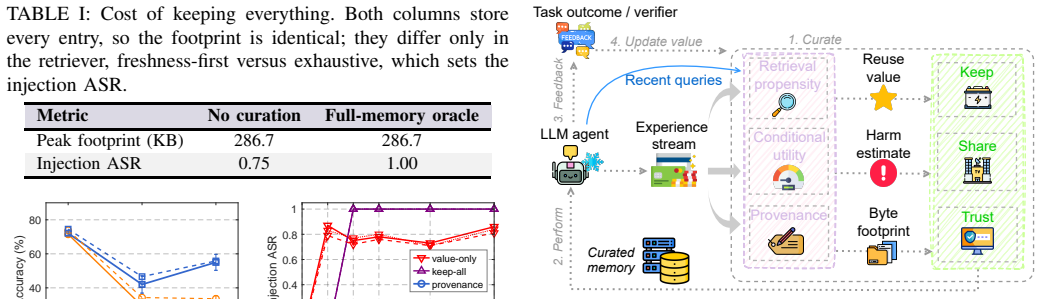
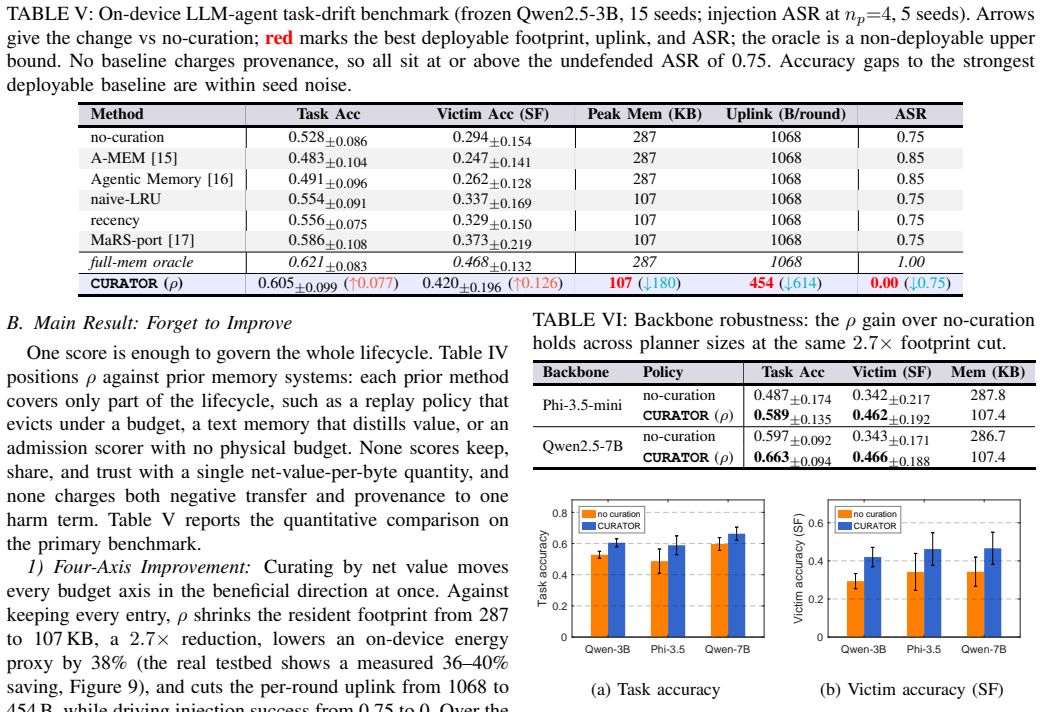
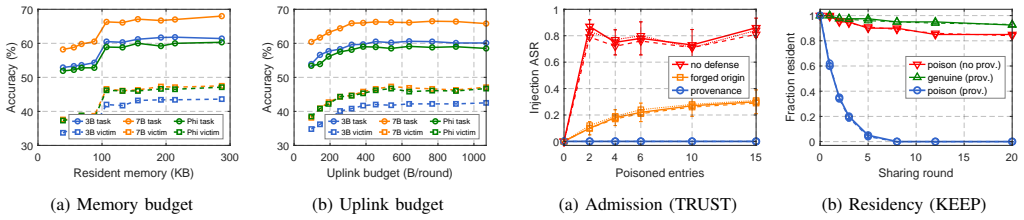
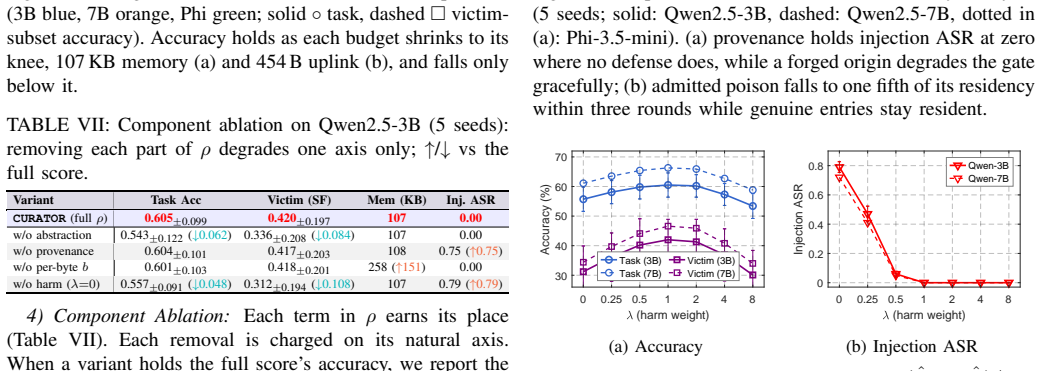
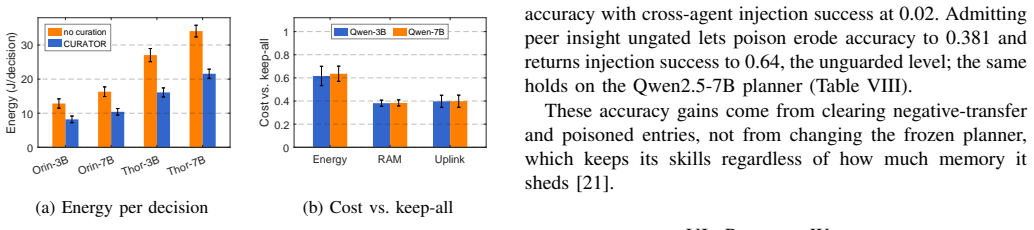
Curating an agent's experience memory by a single net-value-per-byte score (value minus harm) simultaneously governs KEEP, SHARE and TRUST decisions; this budget-driven curation reduces memory footprint 2.7 times, uplink traffic 2.4 times and injection success from 0.75 to zero while raising accuracy on poisoned or stale cases, demonstrating that deliberate forgetting by net value improves rather than weakens the agent.
What carries the argument
The net-value-per-byte score that computes value minus harm for each memory entry and serves as the single ruler for keep, share and trust decisions under explicit RAM, energy and uplink budgets.
If this is right
- Memory footprint falls 2.7 times while accuracy on clean and corrupted tasks stays the same or rises.
- Uplink volume falls 2.4 times because only net-positive insights are transmitted.
- Successful injection attacks drop from 0.75 to zero because low-value or harmful entries are never retained or shared.
- Energy consumption on the device decreases because fewer bytes are stored and retrieved.
- Forgetting entries by net value improves continual-learning performance rather than degrading it.
Where Pith is reading between the lines
- The same score could be used to decide which entries to compress or quantize on even tighter devices.
- If provenance metadata itself consumes bytes, the net-value calculation would need to include that overhead to remain consistent.
- The approach may generalize to any continual-learning system whose memory is both capacity-constrained and security-exposed.
- Heterogeneous device fleets could share the same scoring rule without per-device retuning if the value and harm estimates remain device-agnostic.
Load-bearing premise
That a single net-value-per-byte score can be computed accurately enough to serve as the sole curator for keep, share and trust decisions across changing tasks and heterogeneous devices.
What would settle it
On the same Jetson testbed with the same task-drift benchmarks, run the agent with and without the net-value curator; if accuracy on poisoned or stale cases falls or injection success rises above zero, the central claim is false.
Figures

read the original abstract
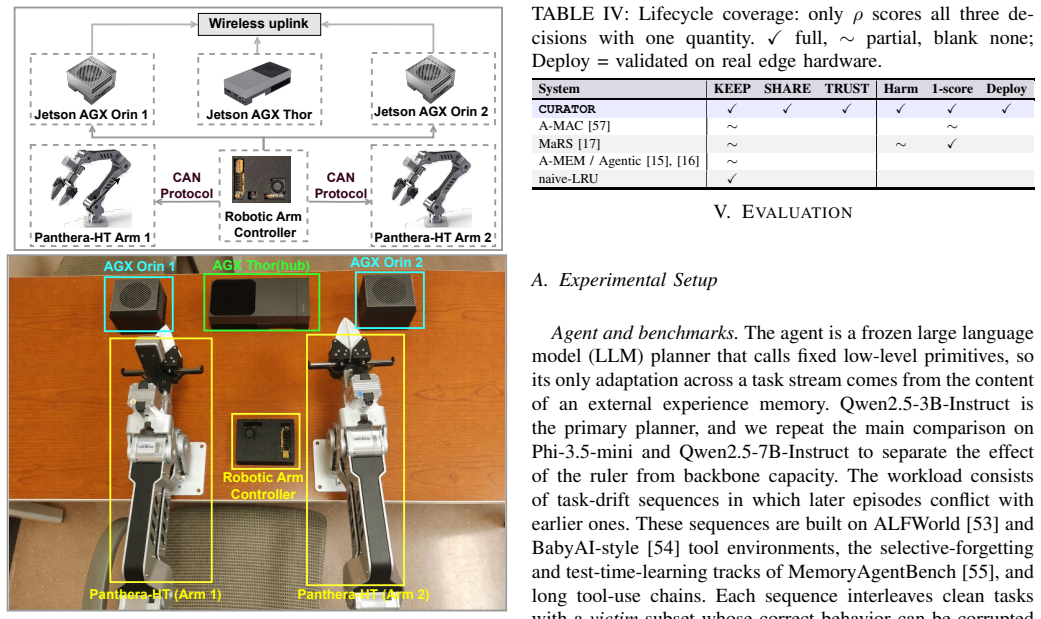
On-device language-model agents improve by accumulating experience in retrieved memory rather than by updating weights. This memory is hard-bounded and exposed: it consumes RAM and energy, reaches peers through a thin uplink, and becomes an attack surface because it is writable by what the agent reads. Existing systems each cover one part of this problem: agentic memories grow without a budget, on-device methods keep entries by success alone, and poisoning is studied mainly as an attack rather than as a memory-governance problem. We propose \sys{}, a single net-value-per-byte score that governs an agent's experience-memory lifecycle. The main idea is to let the budget act as the curator: each entry is scored as value minus harm, per byte, so one ruler decides what to keep, share, and trust. \sys{} makes three decisions: (1) \textbf{KEEP} evicts low-value bytes under the RAM and energy budget; (2) \textbf{SHARE} sends an insight only when its value exceeds its uplink cost; and (3) \textbf{TRUST} gates a peer entry by provenance. On language-model-agent task-drift benchmarks and a real heterogeneous Jetson testbed with two robot-arm nodes and a hub, \sys{} reduces memory by $2.7\times$ and uplink by $2.4\times$, drives injection success from 0.75 to zero, and raises accuracy on cases corrupted by poison or stale memory. Curating by net value reduces footprint, energy, uplink, and injection success together without reducing accuracy. In this setting, forgetting by net value improves the agent rather than weakening it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes \sys{}, a system for on-device LLM-agent continual learning that curates experience memory using a single net-value-per-byte score (value minus harm) to govern KEEP (evict under RAM/energy budget), SHARE (send only if value exceeds uplink cost), and TRUST (gate peer entries by provenance) decisions. On task-drift benchmarks and a heterogeneous Jetson testbed with robot-arm nodes, it claims 2.7× memory reduction, 2.4× uplink reduction, injection success driven to zero, and preserved or improved accuracy compared to baselines that grow memory without budget or keep by success alone.
Significance. If the net-value estimation procedure can be shown to be reliable, device-independent, and non-circular under task drift, the approach would provide a unified, budget-driven mechanism for simultaneously addressing memory footprint, energy, communication cost, and poisoning resistance in on-device agents without sacrificing task performance; this would be a notable contribution to continual learning and secure on-device AI.
major comments (2)
- [Abstract] Abstract: the central claim that a single net-value-per-byte score governs keep/share/trust decisions and produces the reported gains (2.7× memory, 2.4× uplink, injection success → 0, accuracy preserved) rests on the ability to compute value and harm accurately on-device, yet the abstract (and by extension the method) provides no description of the estimation procedure, no equations, no baselines, no error bars, and no experimental protocol for how value/harm are obtained or how accuracy is measured under poison/stale memory.
- [Abstract] The weakest assumption (single scalar sufficient across changing tasks and heterogeneous devices) is load-bearing for all empirical claims; without evidence that the estimators remain accurate under drift or device variation, the reported improvements cannot be attributed to the net-value curator rather than to unstated heuristics or oracles.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for greater clarity in the abstract regarding the net-value estimation. We address each point below and will revise the manuscript to strengthen the presentation of our method and evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that a single net-value-per-byte score governs keep/share/trust decisions and produces the reported gains (2.7× memory, 2.4× uplink, injection success → 0, accuracy preserved) rests on the ability to compute value and harm accurately on-device, yet the abstract (and by extension the method) provides no description of the estimation procedure, no equations, no baselines, no error bars, and no experimental protocol for how value/harm are obtained or how accuracy is measured under poison/stale memory.
Authors: We agree the abstract is too condensed and omits key details on estimation. The full manuscript (Section 3) provides the net-value-per-byte equations, the on-device LLM-based estimation procedure for value and harm, the baselines compared, error bars from repeated runs, and the protocol for accuracy measurement under poison and stale memory on the task-drift benchmarks. We will revise the abstract to include a concise description of the estimation approach along with a pointer to the detailed sections and experimental protocol. revision: yes
-
Referee: [Abstract] The weakest assumption (single scalar sufficient across changing tasks and heterogeneous devices) is load-bearing for all empirical claims; without evidence that the estimators remain accurate under drift or device variation, the reported improvements cannot be attributed to the net-value curator rather than to unstated heuristics or oracles.
Authors: The reported results are obtained exactly on task-drift benchmarks and a heterogeneous Jetson testbed with robot-arm nodes, where the net-value curator produces the stated gains while preserving accuracy; this constitutes direct empirical support that the single scalar functions under the tested drift and device conditions. We will add a short analysis subsection quantifying estimator stability (value/harm correlation with ground-truth task performance) across drift episodes and device types to make this attribution explicit. revision: partial
Circularity Check
No circularity; conceptual proposal with no derivations or self-referential reductions shown.
full rationale
The manuscript introduces a net-value-per-byte score as the governing mechanism for KEEP/SHARE/TRUST decisions but supplies no equations, formal derivations, or parameter-fitting procedures. All claims rest on empirical benchmark outcomes rather than any chain that reduces a prediction or uniqueness result to its own inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, and the score is presented as a design choice rather than a derived quantity. This is the normal case of a self-contained empirical proposal with no detectable circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- value and harm estimators
Reference graph
Works this paper leans on
-
[1]
Apple Intelligence Foundation Language Models: Tech Report 2025,
Apple, “Apple Intelligence Foundation Language Models: Tech Report 2025,” arXiv preprint arXiv:2507.13575, 2025
arXiv 2025
-
[2]
Gemini: A Family of Highly Capable Multi- modal Models,
Gemini Team, Google, “Gemini: A Family of Highly Capable Multi- modal Models,” arXiv preprint arXiv:2312.11805, 2023
Pith/arXiv arXiv 2023
-
[3]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone,
Microsoft, “Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone,” arXiv preprint arXiv:2404.14219, 2024
Pith/arXiv arXiv 2024
-
[4]
Llama Team, Meta AI, “The Llama 3 Herd of Models,” arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[5]
Qwen Team, Alibaba, “Qwen2.5 Technical Report,” arXiv preprint arXiv:2412.15115, 2024
Pith/arXiv arXiv 2024
-
[6]
X. Wang, Q. Li, and W. Jia, “Cognitive Edge Computing: A Comprehen- sive Survey on Optimizing Large Models and AI Agents for Pervasive Deployment,” arXiv preprint arXiv:2501.03265, 2025
arXiv 2025
-
[7]
On- Device Language Models: A Comprehensive Review,
J. Xu, Z. Li, W. Chen, Q. Wang, X. Gao, Q. Cai, and Z. Ling, “On- Device Language Models: A Comprehensive Review,” arXiv preprint arXiv:2409.00088, 2024
arXiv 2024
-
[8]
Reinforcement Learning- Based Energy-Aware Coverage Path Planning for Precision Agriculture,
B. Wu, Z. Ding, L. Ostigaard, and J. Huang, “Reinforcement Learning- Based Energy-Aware Coverage Path Planning for Precision Agriculture,” in2025 ACM Research on Adaptive and Convergent Systems (RACS). ACM, 2025, pp. 1–8
2025
-
[9]
Task-Oriented Communications for Visual Navigation with Edge-Aerial Collaboration in Low Altitude Economy,
Z. Fang, Z. Liu, J. Wang, S. Hu, Y . Guo, Y . Deng, and Y . Fang, “Task-Oriented Communications for Visual Navigation with Edge-Aerial Collaboration in Low Altitude Economy,” inProc. IEEE Global Com- munications Conference (GLOBECOM), 2026
2026
-
[10]
R- ACP: Real-Time Adaptive Collaborative Perception Leveraging Robust Task-Oriented Communications,
Z. Fang, J. Wang, Y . Ma, Y . Tao, Y . Deng, X. Chen, and Y . Fang, “R- ACP: Real-Time Adaptive Collaborative Perception Leveraging Robust Task-Oriented Communications,”IEEE Journal on Selected Areas in Communications, 2025
2025
-
[11]
When Continual Learning Moves to Memory: A Study of Experience Reuse in LLM Agents,
Q. Hu, Q. Long, and W. Wang, “When Continual Learning Moves to Memory: A Study of Experience Reuse in LLM Agents,” arXiv preprint arXiv:2604.27003, 2026
Pith/arXiv arXiv 2026
-
[12]
PoisonedRAG: Knowledge Cor- ruption Attacks to Retrieval-Augmented Generation of Large Language Models,
W. Zou, R. Geng, B. Wang, and J. Jia, “PoisonedRAG: Knowledge Cor- ruption Attacks to Retrieval-Augmented Generation of Large Language Models,” inProceedings of the USENIX Security Symposium, 2025
2025
-
[13]
MemoryGraft: Persistent Compromise of LLM Agents via Poisoned Experience Retrieval,
S. S. Srivastava and H. He, “MemoryGraft: Persistent Compromise of LLM Agents via Poisoned Experience Retrieval,” arXiv preprint arXiv:2512.16962, 2025
arXiv 2025
-
[14]
S. Kim and J. Kim, “SPRInG: Continual LLM Personalization via Selective Parametric Adaptation and Retrieval-Interpolated Generation,” arXiv preprint arXiv:2601.09974, 2026
arXiv 2026
-
[15]
A-MEM: Agentic Memory for LLM Agents,
W. Xu, Z. Liang, K. Mei, H. Gao, J. Tan, and Y . Zhang, “A-MEM: Agentic Memory for LLM Agents,” inAdvances in Neural Information Processing Systems, 2025
2025
-
[16]
Y . Yu, L. Yao, Y . Xie, Q. Tan, J. Feng, Y . Li, and L. Wu, “Agentic Mem- ory: Learning Unified Long-Term and Short-Term Memory Management for Large Language Model Agents,” arXiv preprint arXiv:2601.01885, 2026
Pith/arXiv arXiv 2026
-
[17]
S. Alqithami, “Forgetful but Faithful: A Cognitive Memory Architecture and Benchmark for Privacy-Aware Generative Agents,” arXiv preprint arXiv:2512.12856, 2025
arXiv 2025
-
[18]
Inference-Time Budget Control for LLM Search Agents,
Z. Fang, S. F. Hu, Z. Chang, Y . Guo, Y . Tao, H. Liu, M. Ruan, J. Huang, and Y . Fang, “Inference-Time Budget Control for LLM Search Agents,” arXiv preprint arXiv:2605.05701, 2026
Pith/arXiv arXiv 2026
-
[19]
C. Lam, J. Li, L. Zhang, and K. Zhao, “Governing Evolving Memory in LLM Agents: Risks, Mechanisms, and the Stability and Safety Governed Memory (SSGM) Framework,” arXiv preprint arXiv:2603.11768, 2026
Pith/arXiv arXiv 2026
-
[20]
Zombie Agents: Persistent Control of Self-Evolving LLM Agents via Self-Reinforcing Injections,
X. Yang, Y . He, S. Ji, B. Hooi, and J. S. Dong, “Zombie Agents: Persistent Control of Self-Evolving LLM Agents via Self-Reinforcing Injections,” arXiv preprint arXiv:2602.15654, 2026
arXiv 2026
-
[21]
H. Liu, C. Kim, B. Liu, M. Liu, and Y . Zhu, “Pretrained Vision- Language-Action Models are Surprisingly Resistant to Forgetting in Continual Learning,” arXiv preprint arXiv:2603.03818, 2026
arXiv 2026
-
[22]
Generative Agents: Interactive Simulacra of Human Behavior,
J. S. Park, J. C. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein, “Generative Agents: Interactive Simulacra of Human Behavior,” inProceedings of the ACM Symposium on User Interface Software and Technology, 2023
2023
-
[23]
EvoTest: Evolutionary Test-Time Learning for Self-Improving Agentic Systems,
Y . He, J. Liu, Y . Liu, Y . Li, T. Cao, Z. Hu, X. Xu, and B. Hooi, “EvoTest: Evolutionary Test-Time Learning for Self-Improving Agentic Systems,” inInternational Conference on Learning Representations, 2026
2026
-
[24]
A Review of Continual Learning in Edge AI,
B. Wu, Z. Ding, and J. Huang, “A Review of Continual Learning in Edge AI,”IEEE Transactions on Network Science and Engineering, vol. 13, pp. 6571–6588, 2026
2026
-
[25]
Lifecycle-Aware Federated Continual Learning in Mobile Autonomous Systems,
B. Wu and J. Huang, “Lifecycle-Aware Federated Continual Learning in Mobile Autonomous Systems,” arXiv preprint arXiv:2604.20745, 2026
Pith/arXiv arXiv 2026
-
[26]
From Alpha to Omega: Lifecycle- Aware Forgetting Defense in Federated Continual Learning for Planetary Exploration,
B. Wu, J. Huang, and Y . Zhao, “From Alpha to Omega: Lifecycle- Aware Forgetting Defense in Federated Continual Learning for Planetary Exploration,” inProceedings of the IEEE International Conference on Distributed Computing Systems (ICDCS), 2026
2026
-
[27]
PRISM: Exposing and Resolving Spurious Isolation in Federated Multimodal Continual Learning,
B. Wu, Z. Ding, and J. Huang, “PRISM: Exposing and Resolving Spurious Isolation in Federated Multimodal Continual Learning,” arXiv preprint arXiv:2605.01061, 2026
Pith/arXiv arXiv 2026
-
[28]
Cambricon-LLM: A Chiplet-Based Hybrid Architecture for On-Device Inference of 70B LLM,
Z. Yu, S. Liang, T. Ma, Y . Cai, Z. Nan, D. Huang, X. Song, Y . Hao, J. Zhang, T. Zhi, Y . Zhao, Z. Du, X. Hu, Q. Guo, and T. Chen, “Cambricon-LLM: A Chiplet-Based Hybrid Architecture for On-Device Inference of 70B LLM,” inProceedings of the IEEE/ACM International Symposium on Microarchitecture, 2024, pp. 1474–1488
2024
-
[29]
EdgeMoE: Empowering Sparse Large Language Models on Mobile Devices,
R. Yi, L. Guo, S. Wei, A. Zhou, S. Wang, and M. Xu, “EdgeMoE: Empowering Sparse Large Language Models on Mobile Devices,”IEEE Transactions on Mobile Computing, vol. 24, no. 8, pp. 7059–7073, 2025
2025
-
[30]
B. Wu, Z. Ding, and J. Huang, “RELIEF: Turning Missing Modalities into Training Acceleration for Federated Learning on Heterogeneous IoT Edge,” arXiv preprint arXiv:2604.04243, 2026
Pith/arXiv arXiv 2026
-
[31]
Z. Ding, B. Wu, J. Huang, and S. Mao, “Application-Aware Twin-in- the-Loop Planning for Federated Split Learning over Wireless Edge Networks,” arXiv preprint arXiv:2604.26105, 2026
Pith/arXiv arXiv 2026
-
[32]
A Stochastic Geometry-Based Analysis of SWIPT-Assisted Underlaid Device-to-Device Energy Har- vesting,
C.-C. Xing, Z. Ding, and J. Huang, “A Stochastic Geometry-Based Analysis of SWIPT-Assisted Underlaid Device-to-Device Energy Har- vesting,”SIGAPP Appl. Comput. Rev., vol. 25, no. 4, pp. 18–34, 2026
2026
-
[33]
A Fault-Tolerant and Energy-Efficient Design of a Network Switch Based on a Quantum- Based Nano-Communication Technique,
D. Pan, B.-N. Wu, Y .-L. Sun, and Y .-P. Xu, “A Fault-Tolerant and Energy-Efficient Design of a Network Switch Based on a Quantum- Based Nano-Communication Technique,”Sustainable Computing: In- formatics and Systems, vol. 37, p. 100827, 2023
2023
-
[34]
LLM in a Flash: Efficient Large Language Model Inference with Limited Memory,
K. Alizadeh, S. I. Mirzadeh, D. Belenko, S. K. Khatamifard, M. Cho, C. C. Del Mundo, M. Rastegari, and M. Farajtabar, “LLM in a Flash: Efficient Large Language Model Inference with Limited Memory,” in Proceedings of the Annual Meeting of the Association for Computational Linguistics, 2024, pp. 12 562–12 584
2024
-
[35]
Agent Memory Below the Prompt: Persistent Q4 KV Cache for Multi-Agent LLM Inference on Edge Devices,
Y . P. Shkolnikov, “Agent Memory Below the Prompt: Persistent Q4 KV Cache for Multi-Agent LLM Inference on Edge Devices,” arXiv preprint arXiv:2603.04428, 2026
arXiv 2026
-
[36]
Enhancing Vehic- ular Platooning With Wireless Federated Learning: A Resource-Aware Control Framework,
B. Wu, J. Huang, Q. Duan, L. Dong, and Z. Cai, “Enhancing Vehic- ular Platooning With Wireless Federated Learning: A Resource-Aware Control Framework,”IEEE/ACM Transactions on Networking, pp. 1–1, 2025
2025
-
[37]
A Fast UA V Tra- jectory Planning Framework in RIS-Assisted Communication Systems With Accelerated Learning via Multithreading and Federating,
J. Huang, B. Wu, Q. Duan, L. Dong, and S. Yu, “A Fast UA V Tra- jectory Planning Framework in RIS-Assisted Communication Systems With Accelerated Learning via Multithreading and Federating,”IEEE Transactions on Mobile Computing, pp. 1–16, 2025
2025
-
[38]
Prioritized Information Bottleneck Theoretic Framework With Distributed Online Learning for Edge Video Analytics,
Z. Fang, S. Hu, J. Wang, Y . Deng, X. Chen, and Y . Fang, “Prioritized Information Bottleneck Theoretic Framework With Distributed Online Learning for Edge Video Analytics,”IEEE Transactions on Networking, pp. 1–17, 2025
2025
-
[39]
AgentPoison: Red- teaming LLM Agents via Poisoning Memory or Knowledge Bases,
Z. Chen, Z. Xiang, C. Xiao, D. Song, and B. Li, “AgentPoison: Red- teaming LLM Agents via Poisoning Memory or Knowledge Bases,” in Advances in Neural Information Processing Systems, 2024
2024
-
[40]
SCALE: Sensitivity-Aware Federated Unlearning with Information Freshness Optimization for Mobile Edge Computing,
Z. Ding, B. Wu, and J. Huang, “SCALE: Sensitivity-Aware Federated Unlearning with Information Freshness Optimization for Mobile Edge Computing,” inProceedings of the IEEE International Conference on Distributed Computing Systems (ICDCS), 2026
2026
-
[41]
EASE: Federated Multimodal Unlearning via Entanglement- Aware Anchor Closure,
——, “EASE: Federated Multimodal Unlearning via Entanglement- Aware Anchor Closure,” arXiv preprint arXiv:2605.00733, 2026
Pith/arXiv arXiv 2026
-
[42]
Securing Smart Agriculture with Communication-Efficient Federated Unlearning,
U. Pudasaini, Z. Ding, and J. Huang, “Securing Smart Agriculture with Communication-Efficient Federated Unlearning,” in2026 IEEE International Conference on High Performance Switching and Routing (HPSR). IEEE, 2026, pp. 1–8
2026
-
[43]
Memory Poisoning Attack and Defense on Memory Based LLM-Agents,
S. B. Devarangadi, I. Sinha, P. Maheshwari, S. Todmal, S. Mallik, and S. M. Mishra, “Memory Poisoning Attack and Defense on Memory Based LLM-Agents,” arXiv preprint arXiv:2601.05504, 2026
arXiv 2026
-
[44]
Learning to Defend: A Multi-Agent Reinforcement Learning Framework for Stackelberg Security Game in Mobile Edge Computing,
Z. Ding, J. Huang, and J. Qi, “Learning to Defend: A Multi-Agent Reinforcement Learning Framework for Stackelberg Security Game in Mobile Edge Computing,” inInternational Conference on Computing, Networking and Communications (ICNC). IEEE, 2026
2026
-
[45]
“X of Information
B. Wu, J. Huang, and S. Yu, ““X of Information” Continuum: A Survey on AI-Driven Multi-Dimensional Metrics for Next-Generation Net- worked Systems,”IEEE Communications Surveys & Tutorials, vol. 28, pp. 5307–5344, 2026
2026
-
[46]
AoI-Aware Resource Management for Smart Health via Deep Reinforcement Learning,
B. Wu, Z. Cai, W. Wu, and X. Yin, “AoI-Aware Resource Management for Smart Health via Deep Reinforcement Learning,”IEEE Access, 2023
2023
-
[47]
Real-Time Intelligent Healthcare Enabled by Federated Digital Twins With AoI Optimization,
B. Wu, J. Huang, and Q. Duan, “Real-Time Intelligent Healthcare Enabled by Federated Digital Twins With AoI Optimization,”IEEE Network, vol. 40, no. 2, pp. 184–191, 2026
2026
-
[48]
Kellerer, U
H. Kellerer, U. Pferschy, and D. Pisinger,Knapsack Problems. Springer, 2004
2004
-
[49]
M. J. Neely,Stochastic Network Optimization with Application to Communication and Queueing Systems. Morgan & Claypool, 2010
2010
-
[50]
Model-Free Cooperative Optimal Output Regulation for Linear Discrete-Time Multi-Agent Systems Using Reinforcement Learning,
B. Wu and W. Wu, “Model-Free Cooperative Optimal Output Regulation for Linear Discrete-Time Multi-Agent Systems Using Reinforcement Learning,”Mathematical Problems in Engineering, vol. 2023, no. 1, p. 6350647, 2023
2023
-
[51]
FedTD3: An Accelerated Learning Approach for UA V Trajectory Planning,
B. Wu, J. Huang, and Q. Duan, “FedTD3: An Accelerated Learning Approach for UA V Trajectory Planning,” inInternational Conference on Wireless Artificial Intelligent Computing Systems and Applications (WASA). Springer, 2025, pp. 13–24
2025
-
[52]
A Dual- Level Game-Theoretic Approach for Collaborative Learning in UA V- Assisted Heterogeneous Vehicle Networks,
Z. Ding, J. Huang, Q. Duan, C. Zhang, Y . Zhao, and S. Gu, “A Dual- Level Game-Theoretic Approach for Collaborative Learning in UA V- Assisted Heterogeneous Vehicle Networks,” in2025 IEEE International Performance, Computing, and Communications Conference (IPCCC). IEEE, 2025, pp. 1–8
2025
-
[53]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning,
M. Shridhar, X. Yuan, M.-A. C ˆot´e, Y . Bisk, A. Trischler, and M. Hausknecht, “ALFWorld: Aligning Text and Embodied Environments for Interactive Learning,” inInternational Conference on Learning Representations, 2021
2021
-
[54]
BabyAI: A Platform to Study the Sample Efficiency of Grounded Language Learning,
M. Chevalier-Boisvert, D. Bahdanau, S. Lahlou, L. Willems, C. Saharia, T. H. Nguyen, and Y . Bengio, “BabyAI: A Platform to Study the Sample Efficiency of Grounded Language Learning,” inInternational Conference on Learning Representations, 2019
2019
-
[55]
Evaluating Memory in LLM Agents via Incremental Multi-Turn Interactions,
Y . Hu, Y . Wang, and J. McAuley, “Evaluating Memory in LLM Agents via Incremental Multi-Turn Interactions,” inInternational Conference on Learning Representations, 2026
2026
-
[56]
Memory Injection Attacks on LLM Agents via Query-Only Interac- tion,
S. Dong, S. Xu, P. He, Y . Li, J. Tang, T. Liu, H. Liu, and Z. Xiang, “Memory Injection Attacks on LLM Agents via Query-Only Interac- tion,” arXiv preprint arXiv:2503.03704, 2025
arXiv 2025
-
[57]
Adaptive Memory Admission Control for LLM Agents,
G. Zhang, W. Jiang, X. Wang, A. Behr, K. Zhao, J. Friedman, X. Chu, and A. Anoun, “Adaptive Memory Admission Control for LLM Agents,” arXiv preprint arXiv:2603.04549, 2026
arXiv 2026
-
[58]
MemGPT: Towards LLMs as Operating Systems,
C. Packer, S. Wooders, K. Lin, V . Fang, S. G. Patil, I. Stoica, and J. E. Gonzalez, “MemGPT: Towards LLMs as Operating Systems,” arXiv preprint arXiv:2310.08560, 2023
Pith/arXiv arXiv 2023
-
[59]
MemoryBank: Enhanc- ing Large Language Models with Long-Term Memory,
W. Zhong, L. Guo, Q. Gao, H. Ye, and Y . Wang, “MemoryBank: Enhanc- ing Large Language Models with Long-Term Memory,” inProceedings of the AAAI Conference on Artificial Intelligence, 2024, pp. 19 724– 19 731
2024
-
[60]
Shared Spatial Memory Through Predictive Coding,
Z. Fang, Y . Guo, J. Wang, Y . Zhang, H. An, Y . Wang, and Y . Fang, “Shared Spatial Memory Through Predictive Coding,” arXiv preprint arXiv:2511.04235, 2025
arXiv 2025
-
[61]
RAIE: Region-Aware Incremental Preference Editing with LoRA for LLM- based Recommendation,
J. Zeng, Y . Qi, H. Li, C. Li, Z. Lyu, L. Cui, and L. Bai, “RAIE: Region-Aware Incremental Preference Editing with LoRA for LLM- based Recommendation,” inProceedings of the ACM Web Conference, 2026
2026
-
[62]
Overcoming Catastrophic Forgetting in Neural Networks,
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska, D. Hassabis, C. Clopath, D. Kumaran, and R. Hadsell, “Overcoming Catastrophic Forgetting in Neural Networks,”Proceedings of the Na- tional Academy of Sciences, vol. 114, no. 13, pp. 3521–3526, 2017
2017
-
[63]
HiDe-PET: Continual Learning via Hierarchical Decomposition of Parameter-Efficient Tun- ing,
L. Wang, J. Xie, X. Zhang, H. Su, and J. Zhu, “HiDe-PET: Continual Learning via Hierarchical Decomposition of Parameter-Efficient Tun- ing,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 8, pp. 6687–6702, 2025
2025
-
[64]
ShadowCoT: Cognitive Hijacking for Stealthy Reasoning Backdoors in LLMs,
G. Zhao, H. Wu, X. Zhang, and A. V . Vasilakos, “ShadowCoT: Cognitive Hijacking for Stealthy Reasoning Backdoors in LLMs,”IEEE Transac- tions on Information Forensics and Security, vol. 21, pp. 4625–4639, 2026
2026
-
[65]
Traceback of Poisoning Attacks to Retrieval-Augmented Generation,
B. Zhang, H. Xin, M. Fang, Z. Liu, B. Yi, T. Li, and Z. Liu, “Traceback of Poisoning Attacks to Retrieval-Augmented Generation,” inProceedings of the ACM Web Conference, 2025, pp. 2085–2097
2025
-
[66]
Retrieval- Augmented Generation with Estimation of Source Reliability,
J. Hwang, J. Park, H. Park, D.-W. Kim, S. Park, and J. Ok, “Retrieval- Augmented Generation with Estimation of Source Reliability,” inPro- ceedings of the Conference on Empirical Methods in Natural Language Processing, 2025, pp. 34 267–34 291
2025
-
[67]
Learning in the Null Space: Small Singular Values for Continual Learning,
C. A. Pham, P. Vepakomma, and S. Horv ´ath, “Learning in the Null Space: Small Singular Values for Continual Learning,” inProceedings of the Conference on Parsimony and Learning, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.