Memory Retrieval in Visuomotor Policies for Long-Horizon Robot Control
Pith reviewed 2026-06-25 23:49 UTC · model grok-4.3
The pith
HALO retrieves task-relevant information from up to eight minutes of past experience using attention and vision-language guidance for long-horizon robot control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
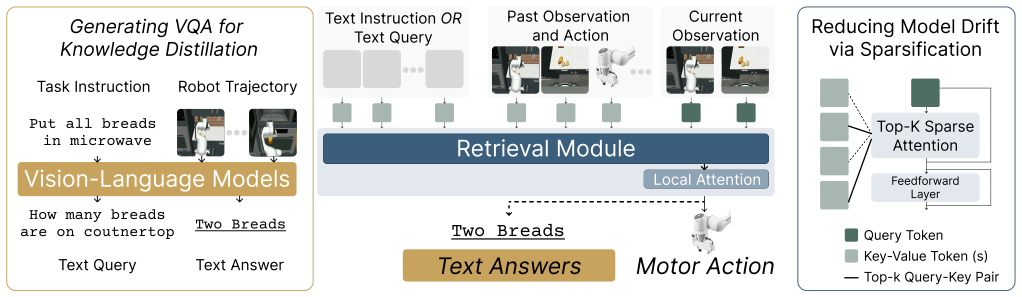
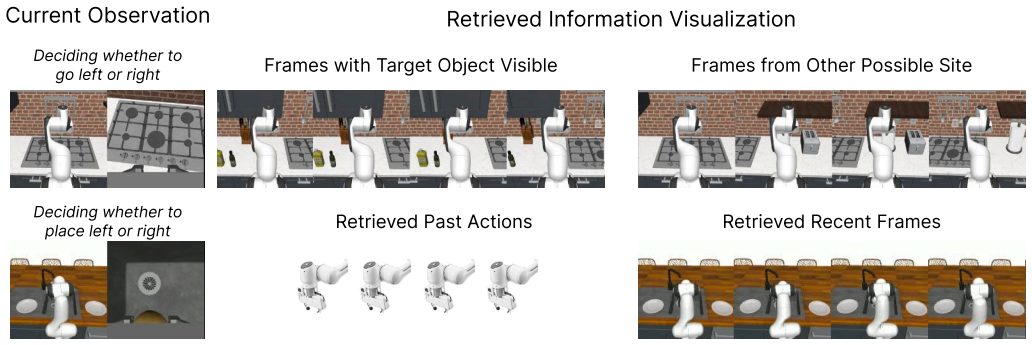
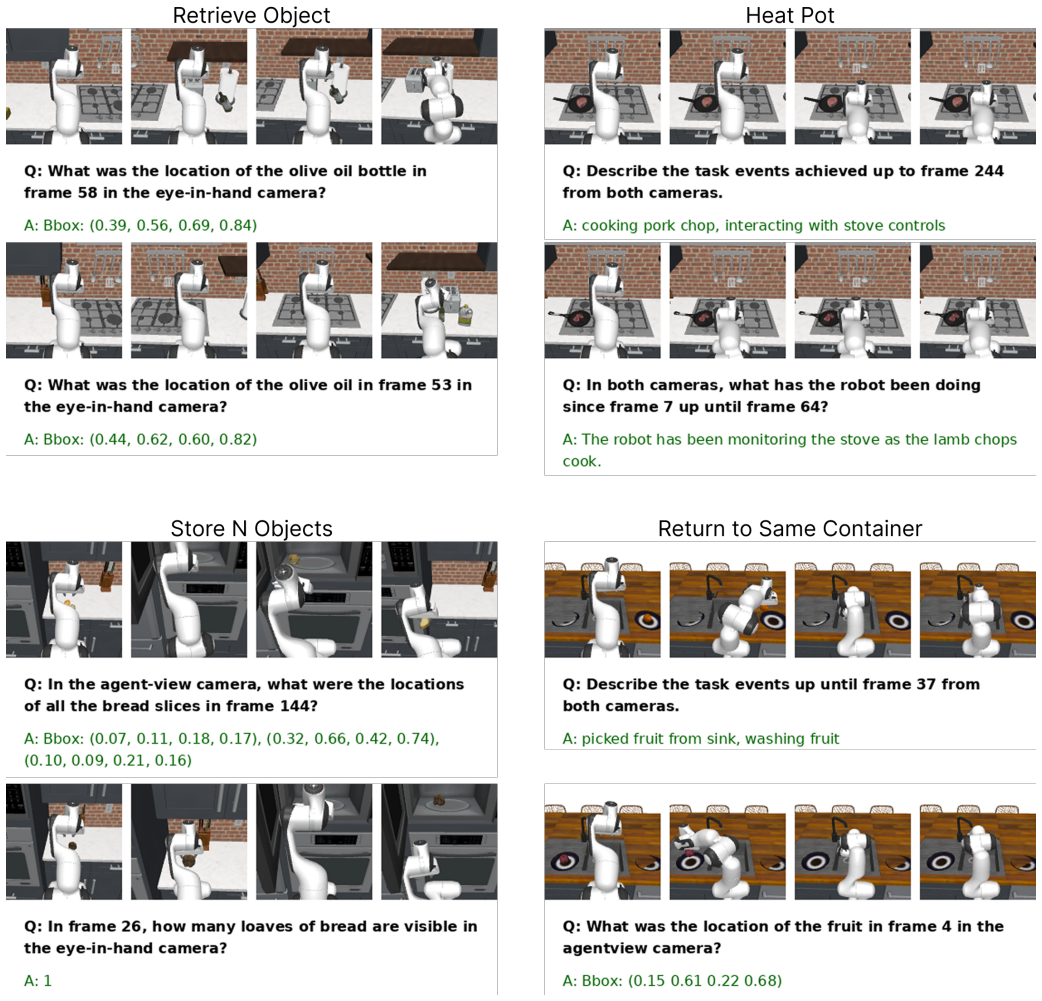
HALO is a visuomotor policy with an attention-based memory retrieval mechanism for long-horizon control. It distills vision-language model priors into the policy by generating memory-dependent question-answer pairs from demonstration trajectories and training jointly with a video question-answering objective. It further employs sparse attention that restricts retrieval to only the most relevant parts of the history, thereby reducing the impact of accumulated errors during closed-loop control.
What carries the argument
Attention-based memory retrieval mechanism that distills VLM priors through memory-dependent QA pair generation and joint video QA training, combined with sparse attention over history.
If this is right
- The policy can reliably retrieve diverse past information such as object locations, completed subtasks, and appliance states from histories up to eight minutes long.
- Spurious correlations between past observations and actions are suppressed during imitation learning.
- Accumulated prediction errors in memory produce less model drift and fewer cascading failures in closed-loop execution.
- Long-horizon control becomes feasible in partially observable environments without task-specific hand-designed memory rules.
Where Pith is reading between the lines
- The same QA-distillation approach could be tested on non-robotic sequential tasks that require recalling sparse facts from long histories.
- Real-robot deployment would likely expose whether the sparse attention pattern remains stable when sensor noise and actuation delays differ from simulation.
- Extending the method to combine multiple memory sources, such as language instructions and visual history, remains an open direction left implicit by the work.
Load-bearing premise
Generating memory-dependent question-answer pairs from demonstration trajectories and jointly training with a video question-answering objective will steer retrieval toward task-relevant information and suppress spurious correlations.
What would settle it
A controlled comparison in which the video QA training objective produces no measurable increase in retrieval of task-relevant history segments or no reduction in long-horizon task failures would falsify the central claim.
Figures





read the original abstract
General-purpose robots operating in partially observable environments, such as homes, require memory to support autonomy. They must recall diverse information from the past, such as where objects were placed, which tasks a human partner has completed, and when an appliance was turned on. Achieving this versatility requires a general memory retrieval mechanism. Transformer architectures that use attention over long contexts for memory retrieval provide a promising approach, as they learn retrieval from data rather than relying on task-specific or hand-designed rules. However, directly incorporating them into imitation learning from offline data introduces two key challenges: (1) the policy may learn spurious correlations between past information and predicted actions, and (2) errors accumulate in memory due to prediction inaccuracies and their compounding interactions with the environment, causing model drift and cascading failures. To address both challenges, we introduce HALO, a visuomotor policy with an attention-based memory retrieval mechanism for long-horizon control. First, to suppress spurious correlations, HALO distills vision-language model (VLM) priors into the policy. It generates memory-dependent question--answer pairs from demonstration trajectories and trains jointly with a video question--answering objective, steering retrieval toward task-relevant information. Second, to reduce the impact of accumulated errors in memory during closed-loop control, HALO uses sparse attention that restricts retrieval to only the most relevant parts of the history. Together, these components enable more reliable long-horizon control by guiding the policy to retrieve task-relevant information from up to eight minutes of past experience. Project website: https://robin-lab.cs.utexas.edu/HALO
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HALO, a visuomotor policy with attention-based memory retrieval for long-horizon robot control in partially observable settings. It claims to address two challenges in imitation learning from offline data: (1) spurious correlations between past observations and actions, mitigated by distilling VLM priors via generation of memory-dependent QA pairs from demonstrations followed by joint training with a video QA objective; and (2) error accumulation and model drift, mitigated by sparse attention that restricts retrieval to the most relevant history segments. The components are asserted to enable reliable retrieval from up to eight minutes of past experience.
Significance. If the empirical validation confirms that the VLM distillation and sparse attention reliably steer retrieval away from spurious correlations and limit drift in closed-loop execution, the work would offer a concrete architectural path toward general-purpose memory mechanisms in robotics without task-specific rules. The proposal to leverage VLM-generated QA pairs for guiding attention is a notable idea that could generalize across domains; the sparse attention component directly targets a known failure mode in long-context transformers for control.
major comments (1)
- [§3 (Method, VLM distillation subsection)] §3 (Method, VLM distillation subsection): The central claim that joint training on memory-dependent QA pairs 'steers retrieval toward task-relevant information' and suppresses spurious correlations is not supported by a mechanism that breaks the degeneracy noted in the skeptic analysis. Because the QA pairs are generated from the identical demonstration trajectories used for the imitation loss, any spurious correlation present in the offline data can simultaneously minimize both objectives; the manuscript provides no negative examples, causal regularization term, held-out spurious probes, or attention-map analysis demonstrating that the QA objective forces attention weights to become task-causal rather than data-correlational.
minor comments (2)
- [Abstract] Abstract: The quantitative gains (e.g., success rates, horizon lengths, ablation deltas) are asserted but not summarized; including one or two key metrics would strengthen the claim that the components 'enable more reliable long-horizon control.'
- [§4 (Experiments)] §4 (Experiments): The description of the sparse attention implementation would benefit from an explicit equation or pseudocode showing how the top-k selection interacts with the transformer layers during closed-loop rollouts.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying the need for stronger mechanistic evidence on the VLM distillation component. We address the major comment below.
read point-by-point responses
-
Referee: [§3 (Method, VLM distillation subsection)] §3 (Method, VLM distillation subsection): The central claim that joint training on memory-dependent QA pairs 'steers retrieval toward task-relevant information' and suppresses spurious correlations is not supported by a mechanism that breaks the degeneracy noted in the skeptic analysis. Because the QA pairs are generated from the identical demonstration trajectories used for the imitation loss, any spurious correlation present in the offline data can simultaneously minimize both objectives; the manuscript provides no negative examples, causal regularization term, held-out spurious probes, or attention-map analysis demonstrating that the QA objective forces attention weights to become task-causal rather than data-correlational.
Authors: We agree that the current manuscript does not contain attention-map visualizations, held-out spurious probes, or explicit negative-example analysis to demonstrate that the QA objective alters attention weights toward task-causal rather than purely correlational patterns. The VLM-generated QA pairs are produced from the same trajectories, so the joint objective alone does not provably eliminate all degeneracies that could be satisfied by both losses. We will therefore add (i) attention-map comparisons between the imitation-only and joint-training models on held-out sequences containing known spurious cues and (ii) quantitative probes that measure retrieval accuracy on memory-dependent questions when spurious correlations are deliberately introduced. These additions will be included in the revised manuscript. revision: yes
Circularity Check
No circularity: architectural proposal validated empirically
full rationale
The paper introduces HALO as a visuomotor policy architecture that adds VLM-based QA distillation from demonstration trajectories plus sparse attention. The abstract and description frame these as design choices intended to steer retrieval and limit error accumulation; no equations, fitted parameters, or self-citations are presented that reduce the central performance claim to a tautological re-expression of the inputs. The method is self-contained against external benchmarks (imitation learning on long-horizon tasks) and does not invoke uniqueness theorems or rename known results. This is the common case of an honest architectural proposal whose validity rests on empirical results rather than internal reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption VLM priors transferred through joint QA training will steer memory retrieval toward task-relevant information without introducing new spurious correlations
- domain assumption Restricting attention to the most relevant history segments will reduce the impact of accumulated prediction errors during closed-loop execution
invented entities (1)
-
HALO policy architecture
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Haus- man, et al. Do as i can, not as i say: Grounding language in robotic affordances.arXiv preprint arXiv:2204.01691, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Scaling short-term memory of visuomo- tor policies for long-horizon tasks, 2026
Anonymous. Scaling short-term memory of visuomo- tor policies for long-horizon tasks, 2026. URL https: //openreview.net/forum?id=5SMNtmJFGa
2026
-
[3]
Remembr: Building and reasoning over long-horizon spatio-temporal memory for robot naviga- tion
Abrar Anwar, John Welsh, Joydeep Biswas, Soha Pouya, and Yan Chang. Remembr: Building and reasoning over long-horizon spatio-temporal memory for robot naviga- tion. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 2838–2845. IEEE, 2025
2025
-
[4]
Optimal control of markov processes with incomplete state information i.Journal of mathe- matical analysis and applications, 10:174–205, 1965
Karl Johan ˚Astr¨om. Optimal control of markov processes with incomplete state information i.Journal of mathe- matical analysis and applications, 10:174–205, 1965
1965
-
[5]
Human memory: A proposed system and its control processes
Richard C Atkinson and Richard M Shiffrin. Human memory: A proposed system and its control processes. In Psychology of learning and motivation, volume 2, pages 89–195. Elsevier, 1968
1968
-
[6]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E Peters, and Arman Cohan. Long- former: The long-document transformer.arXiv preprint arXiv:2004.05150, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[7]
Credit assignment through time: Alternatives to backpropagation.Advances in neural information processing systems, 6, 1993
Yoshua Bengio and Paolo Frasconi. Credit assignment through time: Alternatives to backpropagation.Advances in neural information processing systems, 6, 1993
1993
-
[8]
Sparks of Artificial General Intelligence: Early experiments with GPT-4
S ´ebastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. Sparks of artificial general intelligence: Early experiments with gpt-4.arXiv preprint arXiv:2303.12712, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoub- hik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts. arXiv preprint arXiv:2511.16719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Neural network models for pattern recognition and associative memory.Neural networks, 2 (4):243–257, 1989
Gail A Carpenter. Neural network models for pattern recognition and associative memory.Neural networks, 2 (4):243–257, 1989
1989
-
[11]
Generating Long Sequences with Sparse Transformers
Rewon Child. Generating long sequences with sparse transformers.arXiv preprint arXiv:1904.10509, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[12]
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V Le, and Ruslan Salakhutdinov. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv preprint arXiv:1901.02860, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[13]
Causal confusion in imitation learning.Advances in neural information processing systems, 32, 2019
Pim De Haan, Dinesh Jayaraman, and Sergey Levine. Causal confusion in imitation learning.Advances in neural information processing systems, 32, 2019
2019
-
[14]
Vishnu Sashank Dorbala, Gunnar Sigurdsson, Robinson Piramuthu, Jesse Thomason, and Gaurav S Sukhatme. Clip-nav: Using clip for zero-shot vision-and-language navigation.arXiv preprint arXiv:2211.16649, 2022
-
[15]
Danny Driess, Jost Tobias Springenberg, Brian Ichter, Lili Yu, Adrian Li-Bell, Karl Pertsch, Allen Z Ren, Homer Walke, Quan Vuong, Lucy Xiaoyang Shi, et al. Knowledge insulating vision-language-action models: Train fast, run fast, generalize better.arXiv preprint arXiv:2505.23705, 2025
-
[16]
Haoquan Fang, Markus Grotz, Wilbert Pumacay, Yi Ru Wang, Dieter Fox, Ranjay Krishna, and Jiafei Duan. Sam2act: Integrating visual foundation model with a memory architecture for robotic manipulation.arXiv preprint arXiv:2501.18564, 2025
-
[17]
Scene memory transformer for embodied agents in long-horizon tasks
Kuan Fang, Alexander Toshev, Li Fei-Fei, and Silvio Savarese. Scene memory transformer for embodied agents in long-horizon tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 538–547, 2019
2019
-
[18]
Gpt-3: Its nature, scope, limits, and consequences.Minds and machines, 30(4):681–694, 2020
Luciano Floridi and Massimo Chiriatti. Gpt-3: Its nature, scope, limits, and consequences.Minds and machines, 30(4):681–694, 2020
2020
-
[19]
Alex Graves, Greg Wayne, and Ivo Danihelka. Neural turing machines.arXiv preprint arXiv:1410.5401, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[20]
Hybrid computing using a neural network with dynamic external memory.Nature, 538(7626):471–476, 2016
Alex Graves, Greg Wayne, Malcolm Reynolds, Tim Harley, Ivo Danihelka, Agnieszka Grabska-Barwi ´nska, Sergio G ´omez Colmenarejo, Edward Grefenstette, Tiago Ramalho, John Agapiou, et al. Hybrid computing using a neural network with dynamic external memory.Nature, 538(7626):471–476, 2016
2016
-
[21]
Mamba: Linear-time sequence modeling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. InFirst conference on language modeling, 2024
2024
-
[22]
Jiayuan Gu, Sean Kirmani, Paul Wohlhart, Yao Lu, Montserrat Gonzalez Arenas, Kanishka Rao, Wenhao Yu, Chuyuan Fu, Keerthana Gopalakrishnan, Zhuo Xu, et al. Rt-trajectory: Robotic task generalization via hindsight trajectory sketches.arXiv preprint arXiv:2311.01977, 2023
-
[23]
Open-vocabulary object retrieval
Sergio Guadarrama, Erik Rodner, Kate Saenko, Ning Zhang, Ryan Farrell, Jeff Donahue, and Trevor Darrell. Open-vocabulary object retrieval. InRobotics: science and systems, volume 2, page 6, 2014
2014
-
[24]
Cross- mae: Cross-modality masked autoencoders for region- aware audio-visual pre-training
Yuxin Guo, Siyang Sun, Shuailei Ma, Kecheng Zheng, Xiaoyi Bao, Shijie Ma, Wei Zou, and Yun Zheng. Cross- mae: Cross-modality masked autoencoders for region- aware audio-visual pre-training. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26721–26731, 2024
2024
-
[25]
Long short- term memory.Neural computation, 9(8):1735–1780, 1997
Sepp Hochreiter and J ¨urgen Schmidhuber. Long short- term memory.Neural computation, 9(8):1735–1780, 1997
1997
-
[26]
Context rot: How increasing input tokens impacts llm perfor- mance
Kelly Hong, Anton Troynikov, and Jeff Huber. Context rot: How increasing input tokens impacts llm perfor- mance. Technical report, Chroma Research, July 2025. URL https://research.trychroma.com/context-rot. Techni- cal Report
2025
-
[27]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt- 4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Retrieval-augmented generation for knowledge- intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K¨uttler, Mike Lewis, Wen-tau Yih, Tim Rockt ¨aschel, et al. Retrieval-augmented generation for knowledge- intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
2020
-
[29]
Peiqi Liu, Yaswanth Orru, Jay Vakil, Chris Paxton, Nur Muhammad Mahi Shafiullah, and Lerrel Pinto. Ok- robot: What really matters in integrating open-knowledge models for robotics.arXiv preprint arXiv:2401.12202, 2024
-
[30]
Rt-affordance: Affordances are versatile intermedi- ate representations for robot manipulation
Soroush Nasiriany, Sean Kirmani, Tianli Ding, Laura Smith, Yuke Zhu, Danny Driess, Dorsa Sadigh, and Ted Xiao. Rt-affordance: Affordances are versatile intermedi- ate representations for robot manipulation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 8249–8257. IEEE, 2025
2025
-
[31]
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
Zihan Qiu, Zekun Wang, Bo Zheng, Zeyu Huang, Kaiyue Wen, Songlin Yang, Rui Men, Le Yu, Fei Huang, Suozhi Huang, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Gated attention for large language models: Non-linearity, sparsity, and attention-sink-free, 2025. URL https://arxiv. org/abs/2505.06708
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
A reduction of imitation learning and structured prediction to no-regret online learning
St ´ephane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the fourteenth international conference on artificial intelli- gence and statistics, pages 627–635. JMLR Workshop and Conference Proceedings, 2011
2011
-
[33]
Grad-cam: Visual explanations from deep net- works via gradient-based localization
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep net- works via gradient-based localization. InProceedings of the IEEE international conference on computer vision, pages 618–626, 2017
2017
-
[34]
Bumble: Unifying reasoning and acting with vision-language models for building- wide mobile manipulation
Rutav Shah, Albert Yu, Yifeng Zhu, Yuke Zhu, and Roberto Mart ´ın-Mart´ın. Bumble: Unifying reasoning and acting with vision-language models for building- wide mobile manipulation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 13337–13345. IEEE, 2025
2025
-
[35]
Kele Shao, Keda Tao, Kejia Zhang, Sicheng Feng, Mu Cai, Yuzhang Shang, Haoxuan You, Can Qin, Yang Sui, and Huan Wang. When tokens talk too much: A survey of multimodal long-context token compres- sion across images, videos, and audios.arXiv preprint arXiv:2507.20198, 2025
-
[36]
MemoryVLA: Perceptual-Cognitive Memory in Vision-Language-Action Models for Robotic Manipulation
Hao Shi, Bin Xie, Yingfei Liu, Lin Sun, Fengrong Liu, Tiancai Wang, Erjin Zhou, Haoqiang Fan, Xi- angyu Zhang, and Gao Huang. Memoryvla: Perceptual- cognitive memory in vision-language-action models for robotic manipulation.arXiv preprint arXiv:2508.19236, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Cliport: What and where pathways for robotic manipulation
Mohit Shridhar, Lucas Manuelli, and Dieter Fox. Cliport: What and where pathways for robotic manipulation. In Conference on robot learning, pages 894–906. PMLR, 2022
2022
-
[38]
Llm- planner: Few-shot grounded planning for embodied agents with large language models
Chan Hee Song, Jiaman Wu, Clayton Washington, Brian M Sadler, Wei-Lun Chao, and Yu Su. Llm- planner: Few-shot grounded planning for embodied agents with large language models. InProceedings of the IEEE/CVF international conference on computer vision, pages 2998–3009, 2023
2023
-
[39]
Feedback in imitation learning: The three regimes of covariate shift
Jonathan Spencer, Sanjiban Choudhury, Arun Venkatra- man, Brian Ziebart, and J Andrew Bagnell. Feedback in imitation learning: The three regimes of covariate shift. arXiv preprint arXiv:2102.02872, 2021
-
[40]
Memer: Scaling up memory for robot control via experience retrieval, 2025
Ajay Sridhar, Jennifer Pan, Satvik Sharma, and Chelsea Finn. Memer: Scaling up memory for robot control via experience retrieval, 2025. URL https://arxiv.org/abs/ 2510.20328
-
[41]
End-to-end memory networks.Advances in neural infor- mation processing systems, 28, 2015
Sainbayar Sukhbaatar, Jason Weston, Rob Fergus, et al. End-to-end memory networks.Advances in neural infor- mation processing systems, 28, 2015
2015
-
[42]
Mem: Multi-scale embodied memory for vision language action models
Marcel Torne, Karl Pertsch, Homer Walke, Kyle Vedder, Suraj Nair, Brian Ichter, Allen Z Ren, Haohuan Wang, Jiaming Tang, Kyle Stachowicz, et al. Mem: Multi-scale embodied memory for vision language action models. arXiv preprint arXiv:2603.03596, 2026
-
[43]
Episodic and semantic memory
Endel Tulving et al. Episodic and semantic memory. Organization of memory, 1(381-403):1, 1972
1972
-
[44]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[45]
Fighting copycat agents in behav- ioral cloning from observation histories.Advances in Neural Information Processing Systems, 33:2564–2575, 2020
Chuan Wen, Jierui Lin, Trevor Darrell, Dinesh Jayara- man, and Yang Gao. Fighting copycat agents in behav- ioral cloning from observation histories.Advances in Neural Information Processing Systems, 33:2564–2575, 2020
2020
-
[46]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chen- gen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Big bird: Transformers for longer sequences
Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, et al. Big bird: Transformers for longer sequences. Advances in neural information processing systems, 33: 17283–17297, 2020
2020
-
[48]
Chatvla: Unified multimodal understanding and robot control with vision- language-action model
Zhongyi Zhou, Yichen Zhu, Minjie Zhu, Junjie Wen, Ning Liu, Zhiyuan Xu, Weibin Meng, Yaxin Peng, Chaomin Shen, Feifei Feng, et al. Chatvla: Unified multimodal understanding and robot control with vision- language-action model. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 5377–5395, 2025. VII. APPENDIX A. ...
2025
-
[49]
Use the task description, and summary of task events to understand the scene in the current episode
Identify events relevant to the task. Use the task description, and summary of task events to understand the scene in the current episode. Using these information, describe what plausibly happens in the task for each of the given QUERY- FRAME INDEXES
-
[50]
In the eye-in-hand camera, how many sponges were there in frame 19?
Write ONE memory-based query important for the task for each of the given QUERY-FRAME INDEXES The question must require recalling earlier information provided in the prompt for each of the given QUERY-FRAME INDEXES. It may include: - object location seen earlier in the QUERY-FRAME INDEX (e.g., bounding box coordinates, etc.) - number of objects of a parti...
-
[51]
results" field with a list of dictionaries, each containing the three required fields for each of the specified QUERY-FRAME INDEX: json{{
Answer the query Provide the single best answer using only the provided information provided for each of the given QUERY-FRAME INDEXES and your event notes. The answer should be appropriate for the referenced QUERY-FRAME INDEX and the camera. If there’s no answer, provide N/A The answer should be concise using very few words. Make sure if there are multip...
-
[52]
Task alignment: Do query, instruction, and answer all help in solving the task as described in the task instruction and task description?
-
[53]
Grounding: Is the answer specific and consistent with the episode’s referenced frame(s) indices and camera(s)? Is the answer correct? Verify for both
-
[54]
Memory dependence: Does the query REQUIRE recalling earlier information about the visible objects in the scene, their locations, robot actions, etc
-
[55]
Instruction quality: Does the instruction briefly prime what to remember? Answer should be correct for high scores 3--5, both inclusive. Scoring (integers only, 1--5): 5 = Excellent: query and answer clearly help in solving the task, grounded and answers are correct, memory-dependent question 4 = Good: query and answer help in solving the task; grounding ...
-
[56]
The task information: a task instruction, task’s detailed description, and a list of information provided per-frame and per-camera about the visible objects in the scene, their locations, robot actions, etc
-
[57]
id": "<integer>
Then a bundle of candidate items: [ {{ "id": "<integer>", "query": "<string>", "answer": "<string>", }}, ... ] STRICT OUTPUT FORMAT (no prose, no extra fields in the JSON). Mention one entry per ID for each entry in the candidate items. Do NOT skip any IDs: json{{ "results": [ {{"reasoning": "<explain briefly why it will be useful to remember for the task...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.