Phoneme-Level Mispronunciation Screening in Polish-Speaking Children with an Explainable Assistant
Pith reviewed 2026-06-25 21:52 UTC · model grok-4.3
The pith
A wav2vec2 CTC recognizer screens sibilant substitutions in Polish children at 88.7 percent exact sequence match.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The recognizer achieves 88.7 percent exact sequence match on 559 utterances from ten unseen children; when a mismatch is declared only on emission of substitution-evidence bracketed tokens at the target segment, the resulting screen yields 72.9 percent precision, 61.4 percent recall, F1 of 0.67, and 2.7 percent false alarms on target-correct items, supporting use for conservative screening rather than diagnosis.
What carries the argument
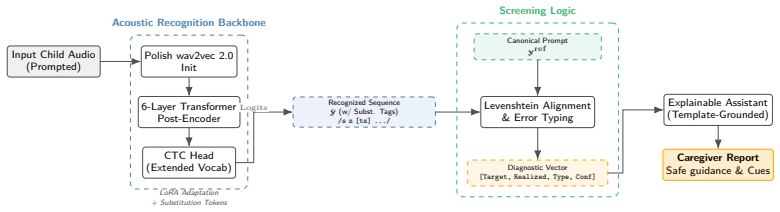
wav2vec2-based CTC token recognizer coupled with alignment-based error typing that emits substitution-evidence bracketed tokens to flag mismatches at target segments.
If this is right
- The pipeline supplies a lightweight, non-diagnostic filter that can run on consumer devices for early identification of sibilant errors.
- Safety boundaries built into the caregiver assistant limit over-interpretation and route uncertain cases to clinicians.
- A clinician-in-the-loop validation plan is required before any deployment beyond the reported test set.
- The approach is language-specific to Polish sibilant contrasts and is not claimed to generalize without retraining.
Where Pith is reading between the lines
- Extending the same token-bracketing method to other consonant classes or languages could test whether the low false-alarm property holds beyond sibilants.
- Embedding the assistant in a mobile app would allow population-level data collection on prevalence of specific substitutions in Polish preschoolers.
- Pairing the screen with short parent questionnaires could further reduce false alarms while preserving the conservative design.
Load-bearing premise
Alignment-based error typing and substitution-evidence tokens distinguish true mispronunciations from recognizer mistakes on unseen children without population-specific biases or post-hoc fixes in the ten-child test set.
What would settle it
Independent phonetic transcription by multiple speech therapists on a new set of at least 500 utterances from 20 additional Polish-speaking children, checking whether precision falls below 60 percent or false-alarm rate rises above 5 percent.
Figures
read the original abstract
Early identification of speech sound errors in children is often limited by access to specialists, motivating lightweight screening tools that can operate outside the clinic. We present a screening pipeline for Polish-speaking children focused on sibilant substitutions, coupling a wav2vec2-based CTC token recognizer with alignment-based error typing and a template-grounded caregiver assistant for screening, not diagnosis. On a held-out test set of 10 unseen children comprising 559 utterances, the recognizer achieves 88.7 percent exact sequence match. As a conservative screening proxy, we flag a mismatch when the system emits substitution-evidence bracketed tokens at the target segment, yielding 72.9 percent precision, 61.4 percent recall, F1 = 0.67, and a 2.7 percent false-alarm rate on target-correct items. We describe the assistant's safety boundaries and outline a clinician-in-the-loop validation plan for future deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a screening pipeline for sibilant substitutions in Polish-speaking children that couples a wav2vec2-based CTC token recognizer with alignment-based error typing and a template-grounded explainable caregiver assistant. On a held-out test set of 559 utterances from 10 unseen children, the recognizer reports 88.7% exact sequence match; mismatches are flagged via substitution-evidence bracketed tokens at target segments to yield 72.9% precision, 61.4% recall, F1=0.67, and 2.7% false-alarm rate on target-correct items. The work emphasizes conservative screening (not diagnosis) and outlines a clinician-in-the-loop validation plan.
Significance. If the alignment proxy reliably isolates true mispronunciations from CTC errors, the pipeline could address limited specialist access by enabling lightweight, explainable screening for Polish children. Strengths include evaluation on utterances from unseen children and explicit safety boundaries for the assistant. The conservative design (flagging only substitution-evidence tokens) supports its intended use case. The small test-set size, however, constrains claims about robustness across Polish-speaking populations.
major comments (2)
- [Experimental results / held-out test set] Held-out test set (abstract and experimental results): The screening metrics (F1=0.67, 2.7% false-alarm rate) rest on ground-truth labels from only 10 children (559 utterances) with no reported selection criteria, demographic matching to training data, or inter-annotator agreement. This directly affects whether the 11.3% non-exact matches are correctly typed as substitutions rather than model errors.
- [Error typing and proxy definition] Alignment-based error typing (abstract and methods): The proxy assumes substitution-evidence bracketed tokens at target segments indicate true mispronunciations, yet no error analysis or isolation procedure is described to show that the 11.3% CTC errors do not trigger false substitution flags on target-correct items. This is load-bearing for the reported false-alarm rate and F1 score.
minor comments (1)
- [Abstract] The abstract would be strengthened by a one-sentence summary of training-set size, fine-tuning procedure, or Polish-specific acoustic adaptations to contextualize the 88.7% exact-match figure.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. The comments correctly identify key limitations in the current presentation of the held-out evaluation and the error-typing proxy. We address both points below, agree that clarifications and additional analysis are warranted, and will revise the manuscript accordingly while preserving the conservative screening framing already present in the work.
read point-by-point responses
-
Referee: [Experimental results / held-out test set] Held-out test set (abstract and experimental results): The screening metrics (F1=0.67, 2.7% false-alarm rate) rest on ground-truth labels from only 10 children (559 utterances) with no reported selection criteria, demographic matching to training data, or inter-annotator agreement. This directly affects whether the 11.3% non-exact matches are correctly typed as substitutions rather than model errors.
Authors: We agree that the small test-set size (10 unseen children) and lack of reported selection criteria, demographic details, and inter-annotator agreement constitute a genuine limitation that constrains generalizability claims. The 559 utterances were collected from children not seen in training to demonstrate speaker-independent behavior, but we did not include explicit selection criteria or matching information in the manuscript. The ground-truth labels were produced by a single experienced speech-language pathologist; no inter-annotator agreement was computed. We will revise the experimental-results section to (a) describe the data-collection protocol and any available demographic information, (b) explicitly state that labels come from a single annotator, and (c) reiterate the conservative screening (not diagnostic) intent together with the planned clinician-in-the-loop validation. These additions will not alter the reported numbers but will make the evidential basis clearer. revision: partial
-
Referee: [Error typing and proxy definition] Alignment-based error typing (abstract and methods): The proxy assumes substitution-evidence bracketed tokens at target segments indicate true mispronunciations, yet no error analysis or isolation procedure is described to show that the 11.3% CTC errors do not trigger false substitution flags on target-correct items. This is load-bearing for the reported false-alarm rate and F1 score.
Authors: The alignment-based proxy was deliberately designed to be conservative: a flag is raised only when substitution-evidence bracketed tokens appear at the target segment, which produced the observed 2.7 % false-alarm rate on target-correct items. Nevertheless, the referee is correct that we provide no explicit error analysis separating CTC decoding mistakes from genuine mispronunciations within the 11.3 % non-exact matches. We will add a dedicated error-analysis subsection that manually inspects a sample of the mismatches, quantifies how often CTC errors alone produce substitution-evidence tokens on correct targets, and discusses the implications for the reported precision, recall, and F1. This analysis will be performed on the existing test set and reported in the revision. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical report of a wav2vec2 CTC recognizer evaluated on held-out utterances from 10 unseen children. It states performance numbers (88.7% exact match, F1=0.67 on the proxy) directly from test-set comparison without any derivation chain, fitted parameters renamed as predictions, self-definitional quantities, or load-bearing self-citations of uniqueness theorems. The screening proxy is defined explicitly from the recognizer output tokens rather than being fitted and then re-predicted. No equations or ansatzes are smuggled via citation. This is a standard held-out evaluation with no reduction of claimed results to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Phoneme-Level Mispronunciation Screening in Polish-Speaking Children with an Explainable Assistant
Introduction Speech sound disorders (SSDs) are among the most common developmental communication difficulties in early childhood and, when persistent, can affect intelligibility, participation, and later literacy-related outcomes [1]. In many settings, timely access to specialist assessment and therapy is constrained by limited capacity and long waiting t...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Each utterance is associated with (i) the orthographic prompt, (ii) a canonical token sequence, and (iii) a token-level transcription of the child’s production
Data We use a proprietary corpus of prompted Polish child speech licensed for research [6]. Each utterance is associated with (i) the orthographic prompt, (ii) a canonical token sequence, and (iii) a token-level transcription of the child’s production. Aggregate, privacy-preserving dataset description: • Participants: 201 children (107F/94M), age 4–8 year...
-
[3]
closest-match
Method 3.1. Token representation and substitution markers We represent pronunciations as sequences ofspace-delimited IPA-like tokensfor CTC training and decoding. Tokens are pri- marily phoneme-like segmental units; importantly, Polish af- fricates are represented as single tied symbols (e.g., >ts, >dz) in line with Polish phonology, even though they are ...
-
[4]
Experimental setup We train on 10,508 utterances and validate on 1,170 utterances, with a speaker-disjoint held-out test set containing 559 utter- ances from 10 unseen children. All splits share the samefixed prompt inventory(words and syllables) by design, reflecting the intended screening setting where a child is asked to repeat a pre- defined set of di...
-
[5]
Table 2 provides a compact set of baselines/ablations to contextualize the design choices (post-encoder and bracket supervision)
Results Table 1 summarizes headline recognition performance. Table 2 provides a compact set of baselines/ablations to contextualize the design choices (post-encoder and bracket supervision). We emphasize exact sequence match because a 1:1 match enables stable downstream alignment and error typing without addi- tional heuristics. Validation metrics were co...
-
[6]
at the start
Explainable assistant design The recognition and alignment modules provide token-level screening evidence, but caregiver value depends on present- ing it in a safe and interpretable form. The assistant con- sumes the screening vector[target, realized, type, position, confidence]and generates a short caregiver report grounded in clinician-authored template...
-
[7]
Discussion and limitations The results suggest that SSL-based token recognition can pro- vide a practical backbone for caregiver-oriented screening in Polish. By designing the pipeline around prompted contrasts and alignment to the canonical target, we avoid reliance on word-level language-model priors that may mask minimal- contrast errors [12]. The high...
-
[8]
The recognizer achieves 88.7% exact sequence match on unseen children, supporting stable token-to- token alignment
Conclusion We presented a phoneme-level mispronunciation screening loop for Polish-speaking children based on wav2vec2 token recog- nition, alignment-based screening, and a template-grounded caregiver-facing assistant. The recognizer achieves 88.7% exact sequence match on unseen children, supporting stable token-to- token alignment. We additionally report...
-
[9]
Speech therapy computer system for recording and analyzing multimodal articulation data using the 4D speaker model and deep learning (SpeechCAD)
Acknowledgments This work was supported by the National Centre for Research and Development (NCBR), Poland, under research project No. 0179/L-15/2024, entitled “Speech therapy computer system for recording and analyzing multimodal articulation data using the 4D speaker model and deep learning (SpeechCAD).” This study was approved by the Bioethics Committe...
2024
-
[10]
They were not used to produce a significant part of the manuscript
Generative AI Use Disclosure Generative AI tools were used to assist with language editing, polishing, and local wording. They were not used to produce a significant part of the manuscript. All authors reviewed, edited, and verified the final manuscript and remain responsible for its content
-
[11]
How should children with speech sound disorders be classified? a review and critical evaluation of current classification systems,
R. Waring and R. Knight, “How should children with speech sound disorders be classified? a review and critical evaluation of current classification systems,”International Journal of Language & Communication Disorders, vol. 48, no. 1, pp. 25–40, 2013
2013
-
[12]
Waiting lists and prioritization of children for services: Speech- language pathologists’ perspectives,
N. McGill, S. McLeod, K. Crowe, C. Wang, and S. C. Hopf, “Waiting lists and prioritization of children for services: Speech- language pathologists’ perspectives,”Journal of Communication Disorders, vol. 91, p. 106099, 2021
2021
-
[13]
Parents’ experiences of completing home practice for speech sound disorders,
E. Sugden, N. Munro, C. M. Trivette, E. Baker, and A. L. Williams, “Parents’ experiences of completing home practice for speech sound disorders,”Journal of Early Intervention, vol. 41, no. 2, pp. 159–181, 2019
2019
-
[14]
A perceptual study of polish fricatives, and its implications for historical sound change,
M. Zygis and J. Padgett, “A perceptual study of polish fricatives, and its implications for historical sound change,”Journal of Pho- netics, vol. 38, no. 2, pp. 207–226, 2010
2010
-
[15]
Hy- bridization of acoustic and visual features of polish sibilants produced by children for computer speech diagnosis,
A. Sage, Z. Miodonska, M. Krecichwost, and P. Badura, “Hy- bridization of acoustic and visual features of polish sibilants produced by children for computer speech diagnosis,”Sensors, vol. 24, no. 16, p. 5360, 2024
2024
-
[16]
Pavsig: Polish multichannel audio-visual child speech dataset with double-expert sigmatism diagnosis,
M. Krecichwost, Z. Miodonska, A. Sage, J. Trzaskalik, E. Kwas- niok, and P. Badura, “Pavsig: Polish multichannel audio-visual child speech dataset with double-expert sigmatism diagnosis,” Scientific Data, vol. 12, no. 1612, 2025
2025
-
[17]
Phonological level wav2vec2-based mispronunciation detection and diagnosis method,
M. Shahin, J. Epps, and B. Ahmed, “Phonological level wav2vec2-based mispronunciation detection and diagnosis method,”Speech Communication, vol. 173, no. 103249, 2025
2025
-
[18]
Mispronunciation detection and diagnosis using deep neural networks: a systematic review,
M. Lounis, B. Dendani, and H. Bahi, “Mispronunciation detection and diagnosis using deep neural networks: a systematic review,” Multimedia Tools and Applications, vol. 83, pp. 62 793––62 827, 2024
2024
-
[19]
Automatic analy- sis of pronunciations for children with speech sound disorders,
S. Dudy, S. Bedrick, M. Asgari, and A. Kain, “Automatic analy- sis of pronunciations for children with speech sound disorders,” Computer Speech & Language, vol. 50, pp. 62–84, 2018
2018
-
[20]
Auto- matic speech recognition (asr) for the diagnosis of pronunciation of speech sound disorders in korean children,
T. Ahn, Y . Hong, Y . Im, D. H. Kim, D. Kang, J. W. Jeong, J. W. Kim, M. J. Kim, A.-R. Cho, H. Nam, and D.-H. Jang, “Auto- matic speech recognition (asr) for the diagnosis of pronunciation of speech sound disorders in korean children,”Clinical Linguis- tics & Phonetics, vol. 39, no. 10, pp. 913–926, 2025
2025
-
[21]
Improving end-to-end models for children’s speech recognition,
T. Patel and O. Scharenborg, “Improving end-to-end models for children’s speech recognition,”Applied Sciences, vol. 14, no. 6, p. 2353, 2024
2024
-
[22]
Robust Speech Recognition via Large-Scale Weak Supervision
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large- scale weak supervision,” 2022. [Online]. Available: https: //arxiv.org/abs/2212.04356
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski, H. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” 2020. [Online]. Available: https://arxiv.org/abs/ 2006.11477
-
[24]
Hubert: Self-supervised speech rep- resentation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhut- dinov, and A. Mohamed, “Hubert: Self-supervised speech rep- resentation learning by masked prediction of hidden units,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 29, pp. 3451–3460, 2021
2021
-
[25]
End-to-end mispro- nunciation detection and diagnosis using transfer learning,
L. Peng, Y . Gao, R. Bao, Y . Li, and J. Zhang, “End-to-end mispro- nunciation detection and diagnosis using transfer learning,”Ap- plied Sciences, vol. 13, no. 11, p. 6793, 2023
2023
-
[26]
Leveraging asr and llms for automated scoring and feedback in children’s spoken language assessments,
N. Balaji Shankar, K. Zhang, A. Mai, M. Shi, A. Long, J. Wash- ington, R. Morris, and A. Alwan, “Leveraging asr and llms for automated scoring and feedback in children’s spoken language assessments,” in10th Workshop on Speech and Language Tech- nology in Education, 2025, pp. 1–5
2025
-
[27]
Con- nectionist temporal classification: Labelling unsegmented se- quence data with recurrent neural networks,
A. Graves, S. Fernández, F. Gomez, and J. Schmidhuber, “Con- nectionist temporal classification: Labelling unsegmented se- quence data with recurrent neural networks,” inProceedings of the 23rd International Conference on Machine Learning (ICML), 2006, pp. 369–376
2006
-
[28]
Lora: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” inInternational Conference on Learning Representations (ICLR),
-
[29]
LoRA: Low-Rank Adaptation of Large Language Models
[Online]. Available: https://arxiv.org/abs/2106.09685
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.