To Isolate or to Score? Model-Adaptive Assessment for Cost-Efficient Multi-Agent RAG
Pith reviewed 2026-06-25 22:43 UTC · model grok-4.3
The pith
For weaker models, simply isolating documents matches full multi-agent quality scoring in RAG.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
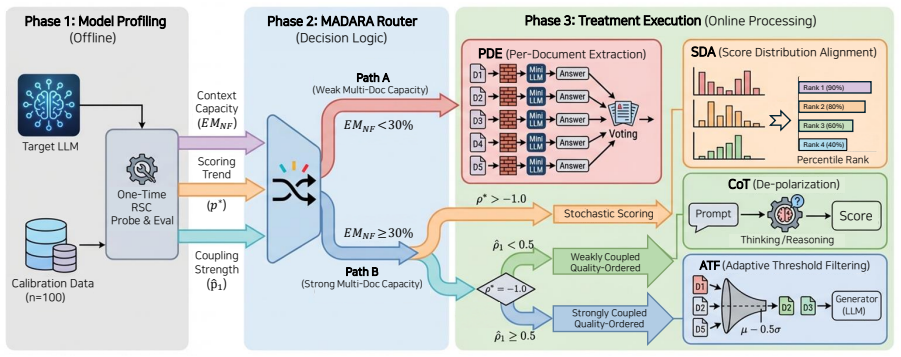
The paper establishes that for weaker baselines assessment-free isolation matches full multi-agent assessment, with gains up to 50 percentage points driven by resolving multi-document context confusion rather than by scoring quality. For strong baselines scoring quality becomes the operative factor, and Reasoning-Score Coupling is introduced as a label-free perturbation probe to classify this behavior. These observations are integrated into MADARA, a model-adaptive routing architecture whose diagnostic thresholds, derived from a single pilot model, generalize zero-shot across four unseen model families.
What carries the argument
MADARA, a model-adaptive routing architecture that selects between isolation and scoring using diagnostic thresholds derived from model behavior.
If this is right
- Weaker models can forgo quality scoring entirely and still obtain the full reported gains.
- Stronger models continue to require explicit scoring mechanisms for further improvement.
- Practitioners obtain a single lightweight pipeline that eliminates assessment overhead on weaker models.
- The same routing logic applies without retraining to multiple model families.
Where Pith is reading between the lines
- Isolation-first strategies may reduce cost in other multi-document retrieval settings that suffer from context mixing.
- The observed split between isolation and scoring could be tested on models outside the 7B-9B range to check scale dependence.
- Extending the probe to measure how isolation interacts with retrieval rank order could refine the routing rule.
Load-bearing premise
Thresholds tuned on one pilot model will correctly separate isolation versus scoring needs on four unrelated model families with no further adjustment.
What would settle it
Applying the MADARA thresholds derived from the pilot model to a fifth model family and finding that the predicted routing no longer aligns with the actual performance difference between isolation and full assessment.
Figures

read the original abstract
Multi-agent document assessment for retrieval-augmented generation is computationally expensive, driving practitioners toward smaller, deployable models whose assessment mechanisms remain poorly understood. We conduct a controlled study of training-free interventions on 7B-9B instruction-tuned models across diverse QA benchmarks, revealing a sharp dichotomy in how models benefit from assessment. For weaker baselines, the dominant mechanism is per-document isolation. Astoundingly, assessment-free isolation matches full multi-agent assessment, demonstrating that resolving multi-document context confusion, rather than scoring quality, drives outsized gains of up to 50 percentage points. Conversely, for strong baselines where scoring quality matters, we introduce Reasoning-Score Coupling, a label-free perturbation probe that classifies scoring behavior. Integrating these findings, we propose MADARA, a model-adaptive routing architecture. Crucially, MADARA's diagnostic thresholds derived from a single pilot model generalize zero-shot to four unseen model families, providing a robust, lightweight pipeline to eliminate computational overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a controlled study of training-free interventions on 7B-9B instruction-tuned models for multi-agent RAG document assessment. It claims a dichotomy: for weaker baselines, assessment-free per-document isolation matches full multi-agent assessment and yields gains up to 50 percentage points by resolving multi-document context confusion rather than scoring quality; for stronger baselines, scoring quality matters and is diagnosed via a new Reasoning-Score Coupling probe. These observations are integrated into MADARA, a model-adaptive routing architecture whose diagnostic thresholds, derived from a single pilot model, are reported to generalize zero-shot to four unseen model families.
Significance. If the zero-shot generalization and isolation-equivalence results hold under controlled conditions with reported error bars, the work would offer a practical, low-overhead pipeline for cost-efficient multi-agent RAG by avoiding unnecessary assessment on weaker models. The empirical scale of the reported gains and the model-adaptive claim are potentially impactful for deployment; the controlled multi-model study and label-free probe are strengths that support reproducibility if code and exact thresholds are released.
major comments (2)
- [§4] §4 (MADARA description) and associated results table: the central claim that diagnostic thresholds derived from one pilot model generalize zero-shot to four unseen model families is load-bearing for the routing architecture, yet the manuscript provides no explicit list of the pilot model, the four target families, the exact threshold values, or a cross-family validation table showing performance before/after any potential adjustment; without this, it is impossible to assess whether the generalization is robust or an artifact of the chosen quartet.
- [Results section] Results section on weaker baselines (isolation vs. assessment): the claim that assessment-free isolation matches full multi-agent assessment and drives up to 50pp gains is load-bearing for the dichotomy, but the manuscript does not report per-model error bars, statistical significance tests, or the precise definition of 'weaker' vs. 'strong' baselines used to partition the results; this undermines the assertion that context confusion resolution, rather than scoring, is the dominant mechanism.
minor comments (2)
- [Abstract] The abstract and introduction use 'astoundingly' and similar phrasing; these should be replaced with neutral quantitative language.
- [Methods] Notation for the Reasoning-Score Coupling probe is introduced without an equation or pseudocode; adding a short formal definition would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below. Both points identify missing details that are necessary to fully substantiate the claims; we will incorporate the requested information and clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [§4] §4 (MADARA description) and associated results table: the central claim that diagnostic thresholds derived from one pilot model generalize zero-shot to four unseen model families is load-bearing for the routing architecture, yet the manuscript provides no explicit list of the pilot model, the four target families, the exact threshold values, or a cross-family validation table showing performance before/after any potential adjustment; without this, it is impossible to assess whether the generalization is robust or an artifact of the chosen quartet.
Authors: We agree that an explicit enumeration of the pilot model, the four target families, the precise threshold values, and a cross-family validation table is required to allow readers to evaluate the zero-shot generalization. In the revision we will add a dedicated table (and accompanying text in §4) that lists: (i) the specific pilot model used to derive the thresholds, (ii) the four unseen model families, (iii) the exact numerical threshold values, and (iv) before/after performance metrics for each family under the MADARA routing policy. This addition will make the generalization claim directly verifiable. revision: yes
-
Referee: [Results section] Results section on weaker baselines (isolation vs. assessment): the claim that assessment-free isolation matches full multi-agent assessment and drives up to 50pp gains is load-bearing for the dichotomy, but the manuscript does not report per-model error bars, statistical significance tests, or the precise definition of 'weaker' vs. 'strong' baselines used to partition the results; this undermines the assertion that context confusion resolution, rather than scoring, is the dominant mechanism.
Authors: We concur that per-model error bars, formal significance testing, and an explicit operational definition of the 'weaker' versus 'strong' partition are needed to support the reported dichotomy. In the revised results section we will: (i) report per-model standard errors or confidence intervals on all isolation-versus-assessment comparisons, (ii) add statistical significance tests (paired t-tests or Wilcoxon signed-rank tests, as appropriate) for the key contrasts, and (iii) state the precise criterion used to label a baseline as 'weaker' or 'strong' (e.g., a performance threshold on the no-assessment baseline). These changes will strengthen the empirical grounding of the mechanism claim. revision: yes
Circularity Check
No significant circularity; claims are empirical observations
full rationale
The paper presents its key results—including the equivalence of assessment-free isolation to full multi-agent assessment for weaker baselines and the zero-shot generalization of pilot-derived thresholds to four unseen model families—as direct empirical findings from controlled experiments on QA benchmarks. No equations, fitted parameters renamed as predictions, self-citations, or ansatzes are invoked in the abstract or described claims to create definitional equivalence or load-bearing reduction to inputs. The derivation chain remains self-contained against external benchmarks, with the reported generalization treated as an observation rather than a constructed tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension , author=. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[2]
Quantifying Language Models' Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting , author=. arXiv preprint arXiv:2310.11324 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Proceedings of the 2022 conference of the north american chapter of the association for computational linguistics: Human language technologies , pages=
Do prompt-based models really understand the meaning of their prompts? , author=. Proceedings of the 2022 conference of the north american chapter of the association for computational linguistics: Human language technologies , pages=
2022
-
[4]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[6]
Proceedings of the 16th conference of the european chapter of the association for computational linguistics: main volume , pages=
Leveraging passage retrieval with generative models for open domain question answering , author=. Proceedings of the 16th conference of the european chapter of the association for computational linguistics: main volume , pages=
-
[7]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Replug: Retrieval-augmented black-box language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[8]
Transactions of the association for computational linguistics , volume=
Lost in the middle: How language models use long contexts , author=. Transactions of the association for computational linguistics , volume=
-
[9]
International conference on learning representations , volume=
Self-rag: Learning to retrieve, generate, and critique through self-reflection , author=. International conference on learning representations , volume=
-
[10]
Corrective retrieval augmented generation , author=
-
[11]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Main-rag: Multi-agent filtering retrieval-augmented generation , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[12]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Astute rag: Overcoming imperfect retrieval augmentation and knowledge conflicts for large language models , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[13]
arXiv preprint arXiv:2505.20096 , year=
Ma-rag: Multi-agent retrieval-augmented generation via collaborative chain-of-thought reasoning , author=. arXiv preprint arXiv:2505.20096 , year=
-
[14]
Forty-first international conference on machine learning , year=
Improving factuality and reasoning in language models through multiagent debate , author=. Forty-first international conference on machine learning , year=
-
[15]
arXiv preprint arXiv:2504.13079 , year=
Retrieval-augmented generation with conflicting evidence , author=. arXiv preprint arXiv:2504.13079 , year=
-
[16]
Demystifying Multi-Agent Debate: The Role of Confidence and Diversity
Demystifying Multi-Agent Debate: The Role of Confidence and Diversity , author=. arXiv preprint arXiv:2601.19921 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
The Thirteenth International Conference on Learning Representations , year=
Breaking mental set to improve reasoning through diverse multi-agent debate , author=. The Thirteenth International Conference on Learning Representations , year=
-
[18]
Proceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval , pages=
Reciprocal rank fusion outperforms condorcet and individual rank learning methods , author=. Proceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval , pages=
-
[19]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[20]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th symposium on operating systems principles , pages=
-
[22]
arXiv preprint arXiv:2506.08500 , year=
Dragged into conflicts: Detecting and addressing conflicting sources in search-augmented llms , author=. arXiv preprint arXiv:2506.08500 , year=
-
[23]
The Twelfth International Conference on Learning Representations , year=
Adaptive chameleon or stubborn sloth: Revealing the behavior of large language models in knowledge conflicts , author=. The Twelfth International Conference on Learning Representations , year=
-
[24]
Transactions of the Association for Computational Linguistics , volume=
Natural questions: a benchmark for question answering research , author=. Transactions of the Association for Computational Linguistics , volume=. 2019 , publisher=
2019
-
[25]
Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) , pages=
FEVER: a large-scale dataset for fact extraction and VERification , author=. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) , pages=
2018
-
[26]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Removal of hallucination on hallucination: Debate-augmented RAG , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[27]
arXiv preprint arXiv:2510.11822 , year=
Beyond consensus: Mitigating the agreeableness bias in llm judge evaluations , author=. arXiv preprint arXiv:2510.11822 , year=
-
[28]
arXiv preprint arXiv:2407.18370 , year=
Trust or escalate: Llm judges with provable guarantees for human agreement , author=. arXiv preprint arXiv:2407.18370 , year=
-
[29]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
InfoGain-RAG: Boosting Retrieval-Augmented Generation through Document Information Gain-based Reranking and Filtering , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[30]
arXiv preprint arXiv:2509.11035 , year=
Free-mad: Consensus-free multi-agent debate , author=. arXiv preprint arXiv:2509.11035 , year=
-
[31]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Adaptive-rag: Learning to adapt retrieval-augmented large language models through question complexity , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[32]
RouteLLM: Learning to Route LLMs with Preference Data
Routellm: Learning to route llms with preference data , author=. arXiv preprint arXiv:2406.18665 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
Encouraging divergent thinking in large language models through multi-agent debate , author=. Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
2024
-
[34]
arXiv preprint arXiv:2311.17371 , year=
Should we be going mad? a look at multi-agent debate strategies for llms , author=. arXiv preprint arXiv:2311.17371 , year=
-
[35]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
CONSENSAGENT: Towards efficient and effective consensus in multi-agent LLM interactions through sycophancy mitigation , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[36]
arXiv preprint arXiv:2504.13534 , pages=
Cot-rag: Integrating chain of thought and retrieval-augmented generation to enhance reasoning in large language models , author=. arXiv preprint arXiv:2504.13534 , pages=
-
[37]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
What makes a good reasoning chain? uncovering structural patterns in long chain-of-thought reasoning , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[38]
Advances in Neural Information Processing Systems , volume=
Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
Measuring Faithfulness in Chain-of-Thought Reasoning
Measuring faithfulness in chain-of-thought reasoning , author=. arXiv preprint arXiv:2307.13702 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Faithful chain-of-thought reasoning , author=. Proceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[41]
arXiv preprint arXiv:2511.10375 , year=
TruthfulRAG: Resolving Factual-level Conflicts in Retrieval-Augmented Generation with Knowledge Graphs , author=. arXiv preprint arXiv:2511.10375 , year=
-
[42]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma 2: Improving open language models at a practical size , author=. arXiv preprint arXiv:2408.00118 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Measuring chain of thought faithfulness by unlearning reasoning steps , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[44]
arXiv preprint arXiv:2406.10625 , year=
On the hardness of faithful chain-of-thought reasoning in large language models , author=. arXiv preprint arXiv:2406.10625 , year=
-
[45]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
From generation to judgment: Opportunities and challenges of llm-as-a-judge , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[46]
arXiv preprint arXiv:2501.15228 , year=
Improving retrieval-augmented generation through multi-agent reinforcement learning , author=. arXiv preprint arXiv:2501.15228 , year=
-
[47]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Knowledge conflicts for llms: A survey , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[48]
Transactions on Machine Learning Research , year=
Robust Answers, Fragile Logic: Probing the Decoupling Hypothesis in LLM Reasoning , author=. Transactions on Machine Learning Research , year=
-
[49]
Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG
Agentic retrieval-augmented generation: A survey on agentic rag , author=. arXiv preprint arXiv:2501.09136 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Making reasoning matter: Measuring and improving faithfulness of chain-of-thought reasoning , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[51]
Unsupervised Dense Information Retrieval with Contrastive Learning
Unsupervised dense information retrieval with contrastive learning , author=. arXiv preprint arXiv:2112.09118 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
ACM Transactions on Intelligent Systems and Technology , volume=
A comprehensive survey of small language models in the era of large language models: Techniques, enhancements, applications, collaboration with llms, and trustworthiness , author=. ACM Transactions on Intelligent Systems and Technology , volume=. 2025 , publisher=
2025
-
[53]
arXiv preprint arXiv:2409.15790 , year=
Small language models: Survey, measurements, and insights , author=. arXiv preprint arXiv:2409.15790 , year=
-
[54]
Tsinghua Science and Technology , volume=
Efficient Inference for Edge Large Language Models: A Survey , author=. Tsinghua Science and Technology , volume=. 2026 , publisher=
2026
-
[55]
arXiv preprint arXiv:2511.22334 , year=
Edge Deployment of Small Language Models, a comprehensive comparison of CPU, GPU and NPU backends , author=. arXiv preprint arXiv:2511.22334 , year=
-
[56]
arXiv preprint arXiv:2511.00505 , year=
Zero-RAG: Towards Retrieval-Augmented Generation with Zero Redundant Knowledge , author=. arXiv preprint arXiv:2511.00505 , year=
-
[57]
ACM Transactions on Information Systems , volume=
U-niah: Unified rag and llm evaluation for long context needle-in-a-haystack , author=. ACM Transactions on Information Systems , volume=. 2026 , publisher=
2026
-
[58]
arXiv preprint arXiv:2510.05381 (2025)
Context length alone hurts LLM performance despite perfect retrieval , author=. arXiv preprint arXiv:2510.05381 , year=
-
[59]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[60]
2022 , publisher=
Trivedi, Harsh and Balasubramanian, Niranjan and Khot, Tushar and Sabharwal, Ashish , journal=. 2022 , publisher=
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.