MJEPA: A Simple and Scalable Joint-Embedding Predictive Architecture for Audio-Visual Learning
Pith reviewed 2026-06-25 23:55 UTC · model grok-4.3
The pith
MJEPA uses one unified encoder and a single predictive objective applied within and across audio and visual modalities to learn joint representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
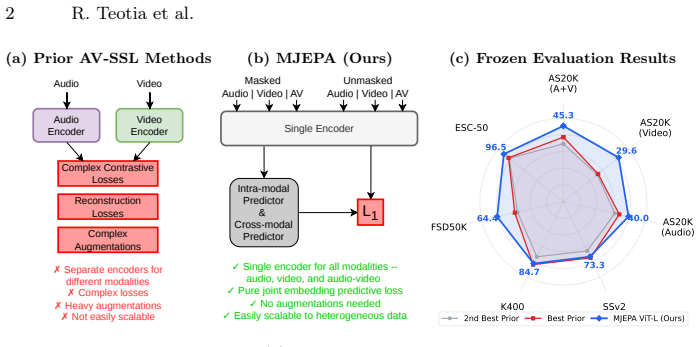
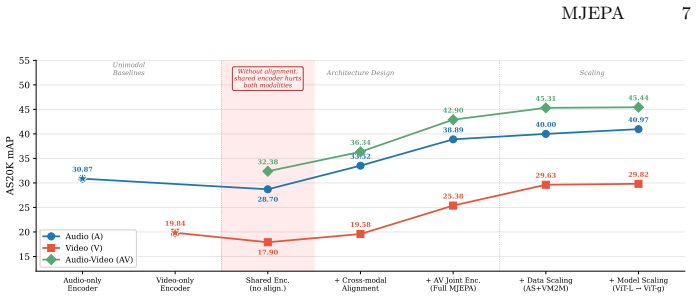
MJEPA demonstrates that a single shared encoder trained with one predictive objective applied both intra-modally and cross-modally produces audio-visual representations whose quality depends on the cross-modal component; without cross-modal prediction the shared encoder underperforms separate unimodal encoders, while with it each modality benefits from the other, yielding the reported gains on frozen audio benchmarks and competitive video results with far less video data.
What carries the argument
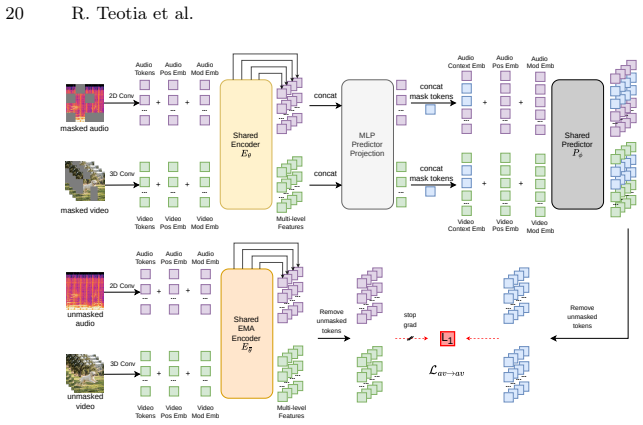
MJEPA: a joint-embedding predictive architecture that applies a single predictive objective both within and across modalities using one unified encoder for audio and video.
If this is right
- Removing cross-modal prediction from the shared encoder causes performance to drop below separate unimodal models.
- Adding cross-modal prediction allows each modality's representation to improve by using information from the other.
- The frozen ViT-g model improves AudioSet-20K mAP by more than 6.8 points over the best prior frozen baseline.
- The same model surpasses fully fine-tuned baselines on ESC-50 and FSD50K.
- Video benchmark results remain competitive while using approximately 10 times less video data than prior work.
Where Pith is reading between the lines
- The single-objective design may extend to other paired modalities such as text and image without new loss terms.
- Scalability could increase further if the same architecture is applied to larger unlabeled video corpora.
- The necessity of cross-modal prediction suggests that predictive rather than contrastive objectives may be the more natural route for modality synergy.
Load-bearing premise
The claim that cross-modal prediction is required for a shared encoder to exceed unimodal baselines assumes the ablation comparisons were run under otherwise identical conditions and with the same unimodal baselines.
What would settle it
A controlled experiment in which a shared encoder trained without the cross-modal prediction term matches or exceeds the unimodal baselines under identical data, optimizer, and schedule settings.
Figures

read the original abstract
Self-supervised learning from large-scale video data has emerged as a dominant paradigm for visual representation learning. Since audio and visual streams naturally co-occur in video data, extending this success to jointly learn from both modalities is a natural next step, yet it remains challenging. Existing audio-visual self-supervised methods rely on modality-specific encoders and complex combinations of contrastive or reconstruction objectives, limiting cross-modal synergy and scalability. Joint Embedding Predictive Architectures (JEPAs) offer a simple, modality-agnostic alternative, but have to date been applied primarily to individual modalities. We introduce MJEPA, a joint-embedding predictive architecture for audio-visual learning that uses a single, unified encoder for both modalities. Our approach uses only a single predictive objective, applied both within and across modalities. We show that cross-modal prediction is critical: without it, a shared encoder degrades below unimodal baselines; with it, each modality's representation benefits from the other. Our frozen ViT-g model outperforms the best prior frozen baseline by over 6.8 mAP on AudioSet-20K, surpasses fully finetuned models on ESC-50 and FSD50K, and is competitive on video benchmarks despite using 10x less video data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MJEPA, a joint-embedding predictive architecture for audio-visual self-supervised learning that employs a single unified ViT encoder and applies one predictive objective both within and across audio and visual modalities. It asserts that cross-modal prediction is essential, as a shared encoder without it falls below unimodal baselines, and reports that a frozen ViT-g model achieves over 6.8 mAP improvement on AudioSet-20K versus prior frozen baselines, exceeds fully finetuned models on ESC-50 and FSD50K, and remains competitive on video tasks while using 10x less video data.
Significance. If the ablation controls and performance numbers are substantiated with matched training conditions, the work would offer a notably simpler and more scalable alternative to existing audio-visual SSL approaches that rely on modality-specific encoders and mixed contrastive/reconstruction losses. The emphasis on a single predictive objective and the reported data efficiency could influence unified multimodal representation learning.
major comments (2)
- [results section / ablation experiments] The central claim that cross-modal prediction is critical (abstract; results section) rests on an ablation showing that a shared encoder without cross-modal prediction degrades below unimodal baselines. No details are provided on (a) the specific unimodal baselines (e.g., Audio-MAE, Video-MAE, or the identical ViT-g trained unimodally), (b) whether the ablated shared encoder still received the full intra-modal JEPA loss on both streams, or (c) whether optimizer, augmentations, masking schedules, and data were held identical. This control information is load-bearing for interpreting the degradation as evidence for cross-modal necessity rather than a training mismatch.
- [evaluation tables / experimental setup] The headline performance numbers (abstract; evaluation tables) are presented without accompanying error bars, dataset split details, or training hyperparameter parity statements for the reported comparisons. Given that the abstract already notes quantitative gains, the full experimental section must supply these to allow assessment of whether the 6.8 mAP gain and outperformance of finetuned models are robust.
minor comments (1)
- [abstract] The abstract states the method uses 'only a single predictive objective' but does not preview the precise form of the predictor or masking strategy; a one-sentence clarification would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on clarifying our ablation controls and experimental reporting. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [results section / ablation experiments] The central claim that cross-modal prediction is critical (abstract; results section) rests on an ablation showing that a shared encoder without cross-modal prediction degrades below unimodal baselines. No details are provided on (a) the specific unimodal baselines (e.g., Audio-MAE, Video-MAE, or the identical ViT-g trained unimodally), (b) whether the ablated shared encoder still received the full intra-modal JEPA loss on both streams, or (c) whether optimizer, augmentations, masking schedules, and data were held identical. This control information is load-bearing for interpreting the degradation as evidence for cross-modal necessity rather than a training mismatch.
Authors: We agree the ablation description requires more explicit controls to support the claim. The unimodal baselines are the identical ViT-g trained separately on audio-only and video-only streams using the same JEPA objective. The ablated shared-encoder condition (no cross-modal term) still applied the full intra-modal JEPA loss to both modalities. Optimizer, augmentations, masking schedules, and training data were identical across all conditions. In revision we will expand the ablation subsection with a dedicated paragraph and table listing these matched settings. revision: yes
-
Referee: [evaluation tables / experimental setup] The headline performance numbers (abstract; evaluation tables) are presented without accompanying error bars, dataset split details, or training hyperparameter parity statements for the reported comparisons. Given that the abstract already notes quantitative gains, the full experimental section must supply these to allow assessment of whether the 6.8 mAP gain and outperformance of finetuned models are robust.
Authors: We acknowledge that error bars, explicit split references, and hyperparameter parity statements improve interpretability. Standard dataset splits (AudioSet-20K balanced, ESC-50 5-fold, FSD50K official) are used and will be stated. Hyperparameters for comparisons follow the original papers where possible; we will add a short paragraph confirming parity. Because additional random seeds were not run for every baseline due to compute limits, we will report error bars only for the runs we performed and note this limitation; the 6.8 mAP figure will be presented with its observed variance. revision: partial
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper presents MJEPA as an empirical extension of prior JEPA work to audio-visual modalities using a unified encoder and single predictive objective. The abstract and provided text contain no equations, parameter fits, or derivations that reduce by construction to author-defined inputs (e.g., no self-definitional ratios, fitted inputs renamed as predictions, or ansatz smuggled via self-citation). The central claim that cross-modal prediction is critical is framed as an empirical ablation result rather than a mathematical necessity. No load-bearing self-citation chains, uniqueness theorems, or renamings of known results appear in the given content. The method is self-contained as an architectural proposal whose performance claims rest on external benchmarks rather than internal redefinitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W
Akbari, H., Yuan, L., Qian, R., Chuang, W.H., Chang, S.F., Cui, Y., Gong, B.: Vatt: Transformers for multimodal self-supervised learning from raw video, audio and text. In: Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W. (eds.) Advances in Neural Information Processing Systems. vol. 34, pp. 24206– 24221. Curran Associates, Inc. (2021),...
2021
-
[2]
In: The Thirteenth International Conference on Learning Representations (2025),https: //openreview.net/forum?id=odU59TxdiB
Alex, T., Atito, S., Mustafa, A., Awais, M., Jackson, P.J.B.: SSLAM: Enhancing self-supervised models with audio mixtures for polyphonic soundscapes. In: The Thirteenth International Conference on Learning Representations (2025),https: //openreview.net/forum?id=odU59TxdiB
2025
-
[3]
In: Proceedings of the IEEE International Conference on Computer Vision (ICCV) (Oct 2017)
Arandjelovic, R., Zisserman, A.: Look, listen and learn. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV) (Oct 2017)
2017
-
[4]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
Araujo, E., Rouditchenko, A., Gong, Y., Bhati, S., Thomas, S., Kingsbury, B., Kar- linsky, L., Feris, R., Glass, J.R.: Cav-mae sync: Improving contrastive audio-visual mask autoencoders via fine-grained alignment. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
2025
-
[5]
arXiv preprint arXiv:2506.09985 (2025)
Assran, M., Bardes, A., Fan, D., Garrido, Q., Howes, R., Komeili, M., Muckley, M., Rizvi, A., Roberts, C., Sinha, K., Zholus, A., Arnaud, S., Gejji, A., Martin, A., Robert Hogan, F., Dugas, D., Bojanowski, P., Khalidov, V., Labatut, P., Massa, F., Szafraniec, M., Krishnakumar, K., Li, Y., Ma, X., Chandar, S., Meier, F., LeCun, Y., Rabbat, M., Ballas, N.: ...
Pith/arXiv arXiv 2025
-
[6]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Assran, M., Duval, Q., Misra, I., Bojanowski, P., Vincent, P., Rabbat, M., LeCun, Y., Ballas, N.: Self-supervised learning from images with a joint-embedding predic- tive architecture. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 15619–15629 (2023)
2023
-
[7]
Baevski, A., Hsu, W.N., Xu, Q., Babu, A., Gu, J., Auli, M.: data2vec: A gen- eral framework for self-supervised learning in speech, vision and language (2022), https://arxiv.org/abs/2202.03555
arXiv 2022
-
[8]
Bardes, A., Garrido, Q., Ponce, J., Rabbat, M., LeCun, Y., Assran, M., Ballas, N.: Revisiting feature prediction for learning visual representations from video. arXiv:2404.08471 (2024)
Pith/arXiv arXiv 2024
-
[9]
Wavlm: Large-scale self-supervised pre-training for full stack speech processing,
Chen,S.,Wang,C.,Chen,Z.,Wu,Y.,Liu,S.,Chen,Z.,Li,J.,Kanda,N.,Yoshioka, T., Xiao, X., Wu, J., Zhou, L., Ren, S., Qian, Y., Qian, Y., Wu, J., Zeng, M., Yu, X., Wei, F.: Wavlm: Large-scale self-supervised pre-training for full stack speech processing. IEEE Journal of Selected Topics in Signal Processing16(6), 1505–1518 (Oct 2022).https://doi.org/10.1109/jstsp...
-
[10]
In: Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., Scarlett, J
Chen, S., Wu, Y., Wang, C., Liu, S., Tompkins, D., Chen, Z., Che, W., Yu, X., Wei, F.: BEATs: Audio pre-training with acoustic tokenizers. In: Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., Scarlett, J. (eds.) Proceed- ings of the 40th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 202, pp. 51...
2023
-
[11]
In: Interspeech 2024 (2024)
Dinkel, H., Yan, Z., Wang, Y., Zhang, J., Wang, Y., Wang, B.: Scaling up masked audio encoder learning for general audio classification. In: Interspeech 2024 (2024)
2024
-
[12]
Teotia et al
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: 16 R. Teotia et al. An image is worth 16x16 words: Transformers for image recognition at scale. ICLR (2021)
2021
-
[13]
Fei, Z., Fan, M., Huang, J.: A-jepa: Joint-embedding predictive architecture can listen (2024),https://arxiv.org/abs/2311.15830
arXiv 2024
-
[14]
IEEE/ACM Transactions on Audio, Speech, and Language Processing30, 829–852 (2022)
Fonseca, E., Favory, X., Pons, J., Font, F., Serra, X.: FSD50K: an open dataset of human-labeled sound events. IEEE/ACM Transactions on Audio, Speech, and Language Processing30, 829–852 (2022)
2022
-
[15]
In: 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Gemmeke, J.F., Ellis, D.P.W., Freedman, D., Jansen, A., Lawrence, W., Moore, R.C., Plakal, M., Ritter, M.: Audio set: An ontology and human-labeled dataset for audio events. In: 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 776–780 (2017).https://doi.org/10.1109/ ICASSP.2017.7952261
arXiv 2017
-
[16]
In: ICCV (2023)
Georgescu, M.I., Fonseca, E., Ionescu, R.T., Lucic, M., Schmid, C., Arnab, A.: Audio-Visual Masked Autoencoders. In: ICCV (2023)
2023
-
[17]
In: CVPR (2023)
Girdhar, R., El-Nouby, A., Liu, Z., Singh, M., Alwala, K.V., Joulin, A., Misra, I.: Imagebind: One embedding space to bind them all. In: CVPR (2023)
2023
-
[18]
Gong, Y., Chung, Y.A., Glass, J.: AST: Audio Spectrogram Transformer. In: Proc. Interspeech 2021. pp. 571–575 (2021).https://doi.org/10.21437/Interspeech. 2021-698
-
[19]
In: The Eleventh Inter- national Conference on Learning Representations (2023),https://openreview
Gong, Y., Rouditchenko, A., Liu, A.H., Harwath, D., Karlinsky, L., Kuehne, H., Glass, J.R.: Contrastive audio-visual masked autoencoder. In: The Eleventh Inter- national Conference on Learning Representations (2023),https://openreview. net/forum?id=QPtMRyk5rb
2023
-
[20]
Goyal, R., Kahou, S.E., Michalski, V., Materzyńska, J., Westphal, S., Kim, H., Haenel, V., Fruend, I., Yianilos, P., Mueller-Freitag, M., Hoppe, F., Thurau, C., Bax, I., Memisevic, R.: The "something something" video database for learning and evaluating visual common sense (2017),https://arxiv.org/abs/1706.04261
Pith/arXiv arXiv 2017
-
[21]
In: Advances in Neural Information Processing Systems
Grill, J.B., Strub, F., Altché, F., Tallec, C., Richemond, P.H., Buchatskaya, E., Doersch, C., Pires, B.A., Guo, Z.D., Azar, M.G., et al.: Bootstrap your own latent: A new approach to self-supervised learning. In: Advances in Neural Information Processing Systems. vol. 33, pp. 21271–21284 (2020)
2020
-
[22]
arXiv preprint arXiv:2111.06377 (2021)
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalable vision learners. arXiv preprint arXiv:2111.06377 (2021)
Pith/arXiv arXiv 2021
-
[23]
In: Thirty- seventh Conference on Neural Information Processing Systems (2023),https:// openreview.net/forum?id=OmTMaTbjac
Huang, P.Y., Sharma, V., Xu, H., Ryali, C., Fan, H., Li, Y., Li, S.W., Ghosh, G., Malik, J., Feichtenhofer, C.: MAVil: Masked audio-video learners. In: Thirty- seventh Conference on Neural Information Processing Systems (2023),https:// openreview.net/forum?id=OmTMaTbjac
2023
-
[24]
In: NeurIPS (2022)
Huang, P.Y., Xu, H., Li, J., Baevski, A., Auli, M., Galuba, W., Metze, F., Feicht- enhofer, C.: Masked autoencoders that listen. In: NeurIPS (2022)
2022
-
[25]
In: Salakhutdinov, R., Kolter, Z., Heller, K., Weller, A., Oliver, N., Scarlett,J.,Berkenkamp,F.(eds.)Proceedingsofthe41stInternationalConference on Machine Learning
Huh, M., Cheung, B., Wang, T., Isola, P.: Position: The platonic representation hypothesis. In: Salakhutdinov, R., Kolter, Z., Heller, K., Weller, A., Oliver, N., Scarlett,J.,Berkenkamp,F.(eds.)Proceedingsofthe41stInternationalConference on Machine Learning. Proceedings of Machine Learning Research, vol. 235, pp. 20617–20642. PMLR (21–27 Jul 2024),https:/...
2024
-
[26]
Kay, W., Carreira, J., Simonyan, K., Zhang, B., Hillier, C., Vijayanarasimhan, S., Viola, F., Green, T., Back, T., Natsev, P., Suleyman, M., Zisserman, A.: The kinetics human action video dataset (2017),https://arxiv.org/abs/1705.06950
Pith/arXiv arXiv 2017
-
[27]
In: Salakhutdinov, R., Kolter, Z., MJEPA 17 Heller, K., Weller, A., Oliver, N., Scarlett, J., Berkenkamp, F
Kim, J., Lee, H., Rho, K., Kim, J., Chung, J.S.: EquiAV: Leveraging equiv- ariance for audio-visual contrastive learning. In: Salakhutdinov, R., Kolter, Z., MJEPA 17 Heller, K., Weller, A., Oliver, N., Scarlett, J., Berkenkamp, F. (eds.) Proceed- ings of the 41st International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. ...
2024
-
[28]
2, 2022-06-27
LeCun, Y., et al.: A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27. Open Review62(1), 1–62 (2022)
2022
-
[29]
Lee, J.J., Yoon, S.W.: Can one modality model synergize training of other modality models? In: The Thirteenth International Conference on Learning Representations (2025),https://openreview.net/forum?id=5BXWhVbHAK
2025
-
[30]
arXiv preprint arXiv:2403.19638 (2024)
Lin, Y.B., Bertasius, G.: Siamese vision transformers are scalable audio-visual learners. arXiv preprint arXiv:2403.19638 (2024)
arXiv 2024
-
[31]
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization (2019),https: //arxiv.org/abs/1711.05101
Pith/arXiv arXiv 2019
-
[32]
In: ICCV (2019)
Miech, A., Zhukov, D., Alayrac, J.B., Tapaswi, M., Laptev, I., Sivic, J.: HowTo100M: Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips. In: ICCV (2019)
2019
-
[33]
Transactions on Ma- chineLearningResearch(2024),https://openreview.net/forum?id=a68SUt6zFt, featured Certification
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez, P., HAZIZA, D., Massa, F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W., Howes, R., Huang, P.Y., Li, S.W., Misra, I., Rabbat, M., Sharma, V., Synnaeve, G., Xu, H., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: DINOv2: Learning robust visual feat...
2024
-
[34]
ESC: Dataset for Environmental Sound Classification
Piczak, K.J.: ESC: Dataset for Environmental Sound Classification. In: Proceed- ings of the 23rd Annual ACM Conference on Multimedia. pp. 1015–1018. ACM Press (2015).https://doi.org/10.1145/2733373.2806390,http://dl.acm.org/ citation.cfm?doid=2733373.2806390
-
[35]
In: The Fourteenth International Conference on Learning Representations (2026),https://openreview.net/forum?id=FbY5Co2NWk
Rauch, L., Heinrich, R., Ghaffari, H., Miklautz, L., Moummad, I., Sick, B., Scholz, C.: Unmute the patch tokens: Rethinking probing in multi-label audio classifica- tion. In: The Fourteenth International Conference on Learning Representations (2026),https://openreview.net/forum?id=FbY5Co2NWk
2026
-
[36]
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A.C., Fei-Fei, L.: Imagenet large scale visual recognition challenge (2015),https://arxiv.org/abs/1409.0575
Pith/arXiv arXiv 2015
-
[37]
Sarkar, P., Etemad, A.: Xkd: Cross-modal knowledge distillation with domain alignment for video representation learning (2022)
2022
-
[38]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., Massa, F., Haziza, D., Wehrstedt, L., Wang, J., Darcet, T., Moutakanni, T., Sentana, L., Roberts, C., Vedaldi, A., Tolan, J., Brandt, J., Couprie, C., Mairal, J., Jégou, H., Labatut, P., Bojanowski, P.: Dinov3 (2025),https://ar...
Pith/arXiv arXiv 2025
-
[39]
In: NeurIPS (2022)
Tong, Z., Song, Y., Wang, J., Wang, L.: VideoMAE: Masked autoencoders are data-efficient learners for self-supervised video pre-training. In: NeurIPS (2022)
2022
-
[40]
Yang,X.,Yang,Y.,Jin,Z.,Cui,Z.,Wu,W.,Li,B.,Zhang,C.,Woodland,P.:Spear: A unified ssl framework for learning speech and audio representations (2026), https://arxiv.org/abs/2510.25955
Pith/arXiv arXiv 2026
-
[41]
In: International Conference on Learning Representations (2025) 18 R
Yu, S., Kwak, S., Jang, H., Jeong, J., Huang, J., Shin, J., Xie, S.: Representation alignment for generation: Training diffusion transformers is easier than you think. In: International Conference on Learning Representations (2025) 18 R. Teotia et al
2025
-
[42]
In: Kim, B., Yue, Y., Chaudhuri, S., Fragkiadaki, K., Khan, M., Sun, Y
Zhu, B., Lin, B., Ning, M., YAN, Y., Cui, J., HongFa, W., Pang, Y., Jiang, W., Zhang, J., Li, Z., Zhang, C., Li, Z., Liu, W., Li, Y.: Languagebind: Extend- ing video-language pretraining to n-modality by language-based semantic align- ment. In: Kim, B., Yue, Y., Chaudhuri, S., Fragkiadaki, K., Khan, M., Sun, Y. (eds.) International Conference on Learning ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.