Stabilizing black-box algorithms through task-oriented randomization
Pith reviewed 2026-06-25 20:45 UTC · model grok-4.3
The pith
Task-oriented randomization stabilizes black-box model outputs by adapting its strategy to the input data's generative mechanisms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a task-oriented randomization methodology, which adaptively tailors its strategy to the underlying generative mechanisms of the input data, provides a comprehensive suite of stability guarantees for black-box models, including analysis of the stability-exploration trade-off and an extension to top-k ranking problems.
What carries the argument
task-oriented randomization methodology that adaptively tailors its strategy to the underlying generative mechanisms of the input data
If this is right
- Black-box models receive explicit stability guarantees even when inputs follow unknown or complex distributions.
- The stability-exploration trade-off is quantified so practitioners can choose operating points based on application needs.
- The same framework applies directly to top-k ranking tasks as used in large language model settings.
- Prior information about data structure can be leveraged without retraining or inspecting the black-box internals.
Where Pith is reading between the lines
- The approach could reduce variance in deployed systems where retraining the black-box is costly or impossible.
- Similar adaptive randomization might address stability in other sequential decision settings beyond ranking.
- If the generative mechanism changes over time, the method would require periodic re-identification to maintain guarantees.
Load-bearing premise
The method can reliably detect and adapt to the generative mechanisms of unstructured input data while using any available prior information.
What would settle it
Numerical simulations or the real-world dataset application showing that the proposed randomization produces no measurable improvement in output stability over standard non-adaptive randomization.
Figures
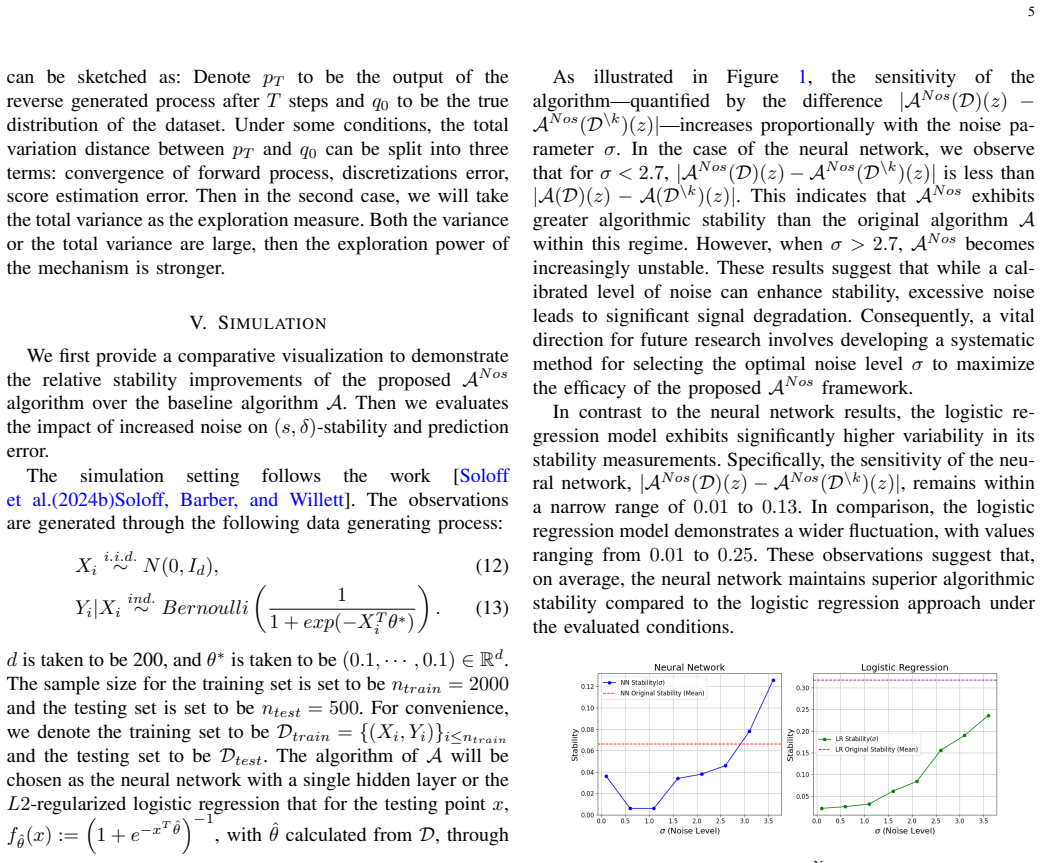
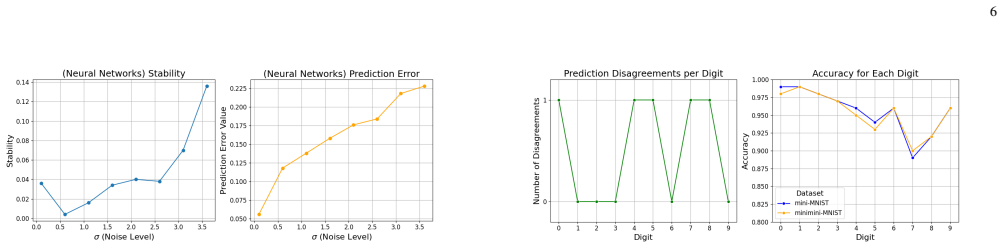
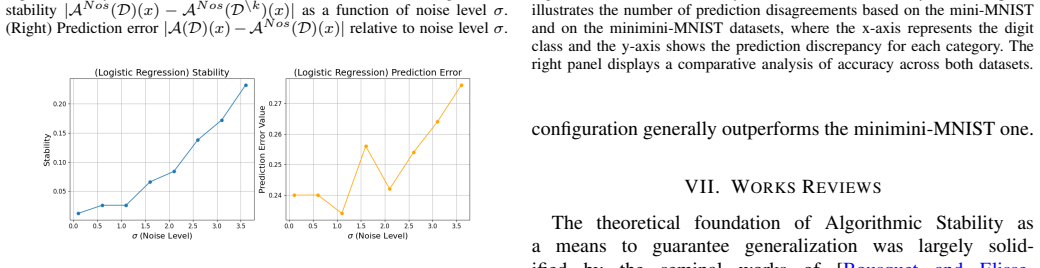
read the original abstract
As black-box models become foundational to modern research, ensuring their stability is paramount for the realization of trustworthy artificial intelligence. The inherent diversity of inputs - ranging from structured Gaussian distributions to complex data with unknown structures - poses a significant challenge: how to stabilize black-box outputs while effectively leveraging available prior information. This paper introduces a task-oriented randomization methodology that adaptively tailors its strategy to the underlying generative mechanisms of the input data, specifically addressing unstructured complexities. A comprehensive suite of stability guarantees is proposed. Beyond establishing rigorous theoretical foundations for stability, the research provides a detailed analysis of the intrinsic trade-off between stability and exploration. Motivated by the architecture of Large Language Models, the framework is further extended to top-k ranking problems. The validity and effectiveness of the proposal are demonstrated through extensive numerical simulations and applications to the real-world dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a task-oriented randomization methodology that adaptively tailors randomization strategies to the underlying generative mechanisms of input data (structured or unstructured) in order to stabilize black-box model outputs. It claims a comprehensive suite of stability guarantees, provides an analysis of the stability-exploration trade-off, extends the framework to top-k ranking problems motivated by LLM architectures, and validates the approach via numerical simulations and a real-world dataset application.
Significance. If the central claims hold with rigorous derivations, the work would supply a principled, adaptive approach to stabilizing black-box algorithms across data types while explicitly treating the stability-exploration trade-off; this could be useful for trustworthy AI, especially in ranking settings. The explicit handling of unstructured data complexities and the provision of guarantees (if machine-checked or parameter-free) would be strengths.
major comments (2)
- [§3] §3 (Methodology for unstructured data): the identification of generative mechanisms for unstructured inputs is described only at a high level with no concrete estimator, parametric form, non-parametric procedure, or oracle assumption supplied. Because the subsequent randomization and all stability guarantees are conditioned on successful adaptation, this step is load-bearing; without it or a robustness analysis under misspecification, the guarantees do not follow.
- [Theoretical results] Theoretical results section (stability guarantees): no derivations, explicit assumptions, or error bounds are visible even in outline form; the abstract asserts 'rigorous theoretical foundations' but the absence of any displayed equations or proof sketches prevents evaluation of whether the guarantees are non-vacuous or circular.
minor comments (2)
- [Abstract] Abstract: the phrase 'comprehensive suite of stability guarantees' is vague; replace with explicit references to the theorem numbers that establish each guarantee.
- [Experiments] Experiments: the description of 'extensive numerical simulations' and the real-world dataset lacks details on sample sizes, number of repetitions, or error bars, making reproducibility difficult.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important areas where the manuscript can be strengthened for clarity and rigor. We respond to each major comment below and will revise the manuscript to address them.
read point-by-point responses
-
Referee: [§3] §3 (Methodology for unstructured data): the identification of generative mechanisms for unstructured inputs is described only at a high level with no concrete estimator, parametric form, non-parametric procedure, or oracle assumption supplied. Because the subsequent randomization and all stability guarantees are conditioned on successful adaptation, this step is load-bearing; without it or a robustness analysis under misspecification, the guarantees do not follow.
Authors: We agree that the current presentation in §3 is insufficiently concrete and that this step is load-bearing for the guarantees. In the revised manuscript we will specify a non-parametric estimator based on kernel mean embedding and maximum mean discrepancy for identifying generative mechanisms of unstructured inputs, include both parametric and non-parametric options with explicit oracle assumptions for the ideal case, and add a robustness analysis quantifying the effect of misspecification on the subsequent randomization and stability bounds. revision: yes
-
Referee: [Theoretical results] Theoretical results section (stability guarantees): no derivations, explicit assumptions, or error bounds are visible even in outline form; the abstract asserts 'rigorous theoretical foundations' but the absence of any displayed equations or proof sketches prevents evaluation of whether the guarantees are non-vacuous or circular.
Authors: The full derivations appear in the appendix, but we acknowledge that the main text lacks sufficient outline, assumptions, and error bounds to allow immediate evaluation. In the revision we will move key assumptions, error bounds, and proof sketches into the main theoretical results section (with displayed equations) while retaining the complete proofs in the appendix, ensuring the guarantees can be assessed as non-vacuous. revision: yes
Circularity Check
No circularity; no derivation chain or equations present to inspect.
full rationale
The abstract and provided text describe a methodological proposal for task-oriented randomization without any equations, derivations, fitted parameters, or self-citations that could form a load-bearing chain. No steps match the enumerated circularity patterns because there are no mathematical reductions to inspect. The paper's claims are presented as a new framework rather than derived from its own inputs by construction. This is the expected honest non-finding when the manuscript supplies no explicit derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Journal of machine learning research , volume=
Stability and generalization , author=. Journal of machine learning research , volume=
-
[2]
IEEE transactions on knowledge and data engineering , volume=
A survey on generative diffusion models , author=. IEEE transactions on knowledge and data engineering , volume=. 2024 , publisher=
2024
-
[3]
arXiv preprint arXiv:2209.11215 , year=
Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions , author=. arXiv preprint arXiv:2209.11215 , year=
-
[4]
IEEE transactions on pattern analysis and machine intelligence , volume=
Diffusion models in vision: A survey , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2023 , publisher=
2023
-
[5]
Advances in neural information processing systems , volume=
Diffusion models beat gans on image synthesis , author=. Advances in neural information processing systems , volume=
-
[6]
Theory of cryptography conference , pages=
Calibrating noise to sensitivity in private data analysis , author=. Theory of cryptography conference , pages=. 2006 , organization=
2006
-
[7]
Foundations and trends
The algorithmic foundations of differential privacy , author=. Foundations and trends. 2014 , publisher=
2014
-
[8]
Proceedings of the forty-seventh annual ACM symposium on Theory of computing , pages=
Preserving statistical validity in adaptive data analysis , author=. Proceedings of the forty-seventh annual ACM symposium on Theory of computing , pages=
-
[9]
Efron and R
B. Efron and R. Tibshirani , title =. Statistical Science , number =. 1986 , doi =
1986
-
[10]
Breakthroughs in statistics: Methodology and distribution , pages=
Bootstrap methods: another look at the jackknife , author=. Breakthroughs in statistics: Methodology and distribution , pages=. 1992 , publisher=
1992
-
[11]
1982 , publisher=
The jackknife, the bootstrap and other resampling plans , author=. 1982 , publisher=
1982
-
[12]
2021 , publisher=
Computer age statistical inference, student edition: algorithms, evidence, and data science , author=. 2021 , publisher=
2021
-
[13]
, author=
Stability of Randomized Learning Algorithms. , author=. Journal of Machine Learning Research , volume=
-
[14]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[15]
arXiv preprint arXiv:2506.02257 , year=
Assumption-free stability for ranking problems , author=. arXiv preprint arXiv:2506.02257 , year=
-
[16]
The Annals of Statistics , pages=
Large sample confidence regions based on subsamples under minimal assumptions , author=. The Annals of Statistics , pages=. 1994 , publisher=
1994
-
[17]
Journal of the American Statistical association , volume=
The stationary bootstrap , author=. Journal of the American Statistical association , volume=. 1994 , publisher=
1994
-
[18]
1999 , publisher =
Subsampling , author =. 1999 , publisher =
1999
-
[19]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[20]
International conference on machine learning , pages=
Deep unsupervised learning using nonequilibrium thermodynamics , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[21]
Soloff and Rina Foygel Barber and Rebecca Willett , title =
Jake A. Soloff and Rina Foygel Barber and Rebecca Willett , title =. Journal of Machine Learning Research , year =
-
[22]
Advances in Neural Information Processing Systems , volume=
Building a stable classifier with the inflated argmax , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
arXiv preprint arXiv:2405.09511 , year=
Stability via resampling: statistical problems beyond the real line , author=. arXiv preprint arXiv:2405.09511 , year=
-
[24]
arXiv preprint arXiv:2010.02502 , year=
Denoising diffusion implicit models , author=. arXiv preprint arXiv:2010.02502 , year=
Pith/arXiv arXiv 2010
-
[25]
arXiv preprint arXiv:2011.13456 , year=
Score-based generative modeling through stochastic differential equations , author=. arXiv preprint arXiv:2011.13456 , year=
Pith/arXiv arXiv 2011
-
[26]
ACM computing surveys , volume=
Diffusion models: A comprehensive survey of methods and applications , author=. ACM computing surveys , volume=. 2023 , publisher=
2023
-
[27]
Computer Standards & Interfaces , volume=
Local differential privacy and its applications: A comprehensive survey , author=. Computer Standards & Interfaces , volume=. 2024 , publisher=
2024
-
[28]
Proceedings of the National Academy of Sciences , volume=
Veridical data science , author=. Proceedings of the National Academy of Sciences , volume=. 2020 , publisher=. doi:10.1073/pnas.1901326117 , URL =
-
[29]
2024 , publisher=
Veridical Data Science: The Practice of Responsible Data Analysis and Decision Making , author=. 2024 , publisher=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.