A Survey of Toxicity Detection and Mitigation Strategies for Multilingual Language Models
Pith reviewed 2026-06-25 21:14 UTC · model grok-4.3
The pith
Survey of multilingual LLMs identifies four persistent challenges in toxicity detection and mitigation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
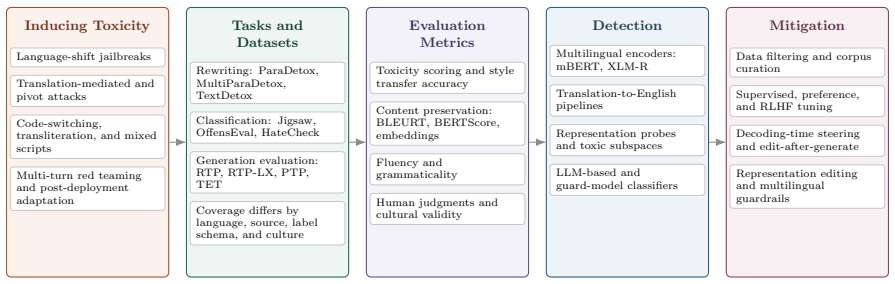
The survey organizes threat models exploiting language choice, translation pivots, code-switching, orthographic variation, multi-turn interaction, and post-deployment fine-tuning; task formulations for toxic-to-neutral rewriting, toxicity classification, and toxic-generation evaluation; detection approaches using cross-lingual encoders, translation pipelines, representation-level probes, and LLM-based detectors; and mitigation strategies of data filtering, supervised and preference-based tuning, decoding-time steering, representation editing, and multilingual guardrails. It concludes that uneven language coverage, culturally contingent definitions of harm, fragmented evaluation protocols, an
What carries the argument
The taxonomy that separates threat models, task formulations, detection methods, and mitigation strategies into non-overlapping categories to synthesize the multilingual toxicity literature.
If this is right
- Future detection systems must handle representation-level probes and LLM-based detectors in addition to translation pipelines.
- Mitigation must combine data filtering and preference tuning with decoding-time steering and representation editing.
- Guardrails need to be built specifically for multilingual settings rather than relying on English-centric alignment.
- Evaluation protocols must address cultural variation in harm definitions to avoid inconsistent results.
Where Pith is reading between the lines
- The identified risk of suppressing dialectal expression implies that mitigation techniques may require explicit language-identity safeguards to avoid unintended censorship.
- Uneven language coverage suggests that low-resource languages will continue to lag in safety unless data collection efforts are deliberately rebalanced.
- Fragmented evaluation protocols point to the need for shared benchmarks that include culturally diverse test cases rather than translated English ones.
Load-bearing premise
The selected papers and the way they are grouped into threat models, tasks, detection, and mitigation provide a representative and non-overlapping view of the field.
What would settle it
Publication of a substantial body of peer-reviewed work on multilingual toxicity that cannot be placed into any of the survey's threat-model, task, detection, or mitigation categories would show the synthesis is incomplete.
Figures
read the original abstract
Large language models (LLMs) are increasingly deployed across languages, but their safety behavior remains uneven across linguistic and cultural contexts. This survey synthesizes work on toxicity detection and detoxification for multilingual LLMs. We first catalogue threat models that exploit language choice, translation pivots, code-switching, orthographic variation, multi-turn interaction, and post-deployment fine-tuning to weaken safety alignment. We then organize task formulations (toxic-to-neutral rewriting, toxicity classification, and toxic-generation evaluation), multilingual detection approaches (cross-lingual encoders, translation pipelines, representation-level probes, and LLM-based detectors), and mitigation strategies spanning data filtering, supervised and preference-based tuning, decoding-time steering, representation editing, and multilingual guardrails. Across these areas, we identify persistent challenges: uneven language coverage, culturally contingent definitions of harm, fragmented evaluation protocols, and the risk that detoxification suppresses legitimate dialectal or identity-related expression.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper is a literature survey on toxicity detection and mitigation for multilingual LLMs. It catalogues threat models (language choice, translation pivots, code-switching, orthographic variation, multi-turn interaction, post-deployment fine-tuning), organizes task formulations (toxic-to-neutral rewriting, toxicity classification, toxic-generation evaluation), reviews detection approaches (cross-lingual encoders, translation pipelines, representation-level probes, LLM-based detectors), and mitigation strategies (data filtering, supervised/preference tuning, decoding-time steering, representation editing, multilingual guardrails), and identifies persistent challenges including uneven language coverage, culturally contingent harm definitions, fragmented evaluation protocols, and risks of suppressing legitimate dialectal expression.
Significance. If the synthesis accurately reflects the cited literature and provides a non-overlapping organization, the survey supplies a structured reference point for multilingual LLM safety research, consolidating disparate threads and foregrounding actionable gaps that can orient subsequent empirical and methodological work.
major comments (2)
- [§2 or §3 (literature organization)] The central contribution rests on the claim that the chosen categorization of threat models, task formulations, detection methods, and mitigation strategies constitutes a representative synthesis. The manuscript should include an explicit methods subsection (likely §2 or §3) stating the literature search protocol, databases queried, inclusion/exclusion criteria, and date range; without this, completeness cannot be evaluated.
- [final paragraph of abstract / concluding section] The four persistent challenges are presented as direct outcomes of the synthesis. Each challenge should be tied to at least two concrete citations with brief quotations or result summaries showing how the cited work illustrates the issue; currently the challenges read as high-level assertions rather than evidenced conclusions.
minor comments (2)
- Notation for threat models and mitigation categories should be introduced once with a consistent acronym or short label and reused uniformly to improve readability.
- The abstract lists six threat models and five mitigation families; a single summary table mapping each to representative papers would help readers navigate the survey.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our survey. We address each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [§2 or §3 (literature organization)] The central contribution rests on the claim that the chosen categorization of threat models, task formulations, detection methods, and mitigation strategies constitutes a representative synthesis. The manuscript should include an explicit methods subsection (likely §2 or §3) stating the literature search protocol, databases queried, inclusion/exclusion criteria, and date range; without this, completeness cannot be evaluated.
Authors: We agree that an explicit methods subsection would improve transparency and allow readers to assess the scope of the synthesis. In the revised manuscript we will insert a dedicated subsection (new §2.1) that describes the literature search protocol, the databases queried (ACL Anthology, arXiv, Google Scholar, and Semantic Scholar), the search strings employed, inclusion/exclusion criteria, and the cutoff date. This addition directly addresses the concern about evaluability of completeness. revision: yes
-
Referee: [final paragraph of abstract / concluding section] The four persistent challenges are presented as direct outcomes of the synthesis. Each challenge should be tied to at least two concrete citations with brief quotations or result summaries showing how the cited work illustrates the issue; currently the challenges read as high-level assertions rather than evidenced conclusions.
Authors: We accept that the challenges section would be strengthened by explicit citation support. In the revised concluding section we will expand each of the four challenges with at least two concrete citations, accompanied by brief result summaries or short quotations from the cited papers that illustrate the specific issue (e.g., resource imbalance for low-resource languages, culturally variable toxicity labels, inconsistent evaluation benchmarks, and over-filtering of dialectal content). revision: yes
Circularity Check
No significant circularity
full rationale
The paper is a literature survey whose central contribution is an organizational synthesis of threat models, task formulations, detection methods, and mitigation strategies, followed by a list of persistent challenges drawn from that synthesis. No internal inconsistency, unsupported derivation, or non-representative categorization is detectable; the claims remain descriptive rather than predictive or quantitative. No equations, fitted parameters, predictions, or self-citation chains that reduce to inputs by construction are present. The work is self-contained as a synthesis against external literature.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 31st International Conference on Computational Linguistics , pages =
Daryna Dementieva and Nikolay Babakov and Amit Ronen and Abinew Ali Ayele and Naquee Rizwan and Florian Schneider and Xintong Wang and Seid Muhie Yimam and Daniil Alekhseevich Moskovskiy and Elisei Stakovskii and Eran Kaufman and Ashraf Elnagar and Animesh Mukherjee and Alexander Panchenko , title =. Proceedings of the 31st International Conference on Com...
2025
-
[2]
The Twelfth International Conference on Learning Representations , year=
Multilingual Jailbreak Challenges in Large Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[3]
Proceedings of the 4th Workshop on Trustworthy Natural Language Processing (TrustNLP 2024) , month=
Sandwich attack: Multi-language Mixture Adaptive Attack on LLMs , author=. Proceedings of the 4th Workshop on Trustworthy Natural Language Processing (TrustNLP 2024) , month=. 2024 , url=
2024
-
[4]
Proceedings of the 5th Workshop on Trustworthy NLP (TrustNLP 2025) , month=
Multi-lingual multi-turn automated red teaming for LLMs , author=. Proceedings of the 5th Workshop on Trustworthy NLP (TrustNLP 2025) , month=. 2025 , url=
2025
-
[5]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , month=
Red Teaming Language Models with Language Models , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , month=. 2022 , url=
2022
-
[6]
Advances in Neural Information Processing Systems , volume=
Rainbow teaming: Open-ended generation of diverse adversarial prompts , author=. Advances in Neural Information Processing Systems , volume=. 2024 , url=
2024
-
[7]
Proceedings of the 5th Workshop on Trustworthy NLP (TrustNLP 2025) , month=
Rainbow-Teaming for the Polish Language: A Reproducibility Study , author=. Proceedings of the 5th Workshop on Trustworthy NLP (TrustNLP 2025) , month=. 2025 , url=
2025
-
[8]
Findings of the Association for Computational Linguistics: ACL 2024 , month=
The Language Barrier: Dissecting Safety Challenges of LLMs in Multilingual Contexts , author=. Findings of the Association for Computational Linguistics: ACL 2024 , month=. 2024 , url=
2024
-
[9]
Findings of the Association for Computational Linguistics: ACL 2024 , month=
Realistic evaluation of toxicity in large language models , author=. Findings of the Association for Computational Linguistics: ACL 2024 , month=. 2024 , url=
2024
-
[10]
Forty-first International Conference on Machine Learning , pages=
Position: building guardrails for large language models requires systematic design , author=. Forty-first International Conference on Machine Learning , pages=. 2024 , url=
2024
-
[11]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , month=
MULTIGUARD: An Efficient Approach for AI Safety Moderation Across Languages and Modalities , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , month=. 2025 , url=
2025
-
[12]
arXiv preprint arXiv:2504.04377 , year=
Polyguard: A multilingual safety moderation tool for 17 languages , author=. arXiv preprint arXiv:2504.04377 , year=. 2504.04377 , archivePrefix=
-
[13]
arXiv preprint arXiv:2312.06674 , year=
Llama guard: Llm-based input-output safeguard for human-ai conversations , author=. arXiv preprint arXiv:2312.06674 , year=. 2312.06674 , archivePrefix=
-
[14]
2024 , eprint=
AEGIS: Online Adaptive AI Content Safety Moderation with Ensemble of LLM Experts , author=. 2024 , eprint=
2024
-
[15]
arXiv preprint arXiv:2502.05163 , year=
Duoguard: A two-player rl-driven framework for multilingual llm guardrails , author=. arXiv preprint arXiv:2502.05163 , year=
-
[16]
Advances in Neural Information Processing Systems , volume=
Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms , author=. Advances in Neural Information Processing Systems , volume=. 2024 , url=
2024
-
[17]
arXiv preprint arXiv:2512.02711 , year=
CREST: Universal Safety Guardrails Through Cluster-Guided Cross-Lingual Transfer , author=. arXiv preprint arXiv:2512.02711 , year=. doi:10.48550/arXiv.2512.02711 , note=. 2512.02711 , archivePrefix=
-
[18]
M r G uard: A Multilingual Reasoning Guardrail for Universal LLM Safety
Yang, Yahan and Dan, Soham and Li, Shuo and Roth, Dan and Lee, Insup. M r G uard: A Multilingual Reasoning Guardrail for Universal LLM Safety. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1392
-
[19]
Tongue-Tied: Breaking LLM s Safety Through New Language Learning
Upadhayay, Bibek and Behzadan, Vahid. Tongue-Tied: Breaking LLM s Safety Through New Language Learning. Proceedings of the 7th Workshop on Computational Approaches to Linguistic Code-Switching. 2025. doi:10.18653/v1/2025.calcs-1.5
-
[20]
Proceedings of the 2024 conference on empirical methods in natural language processing , month=
Jailbreaking llms with arabic transliteration and arabizi , author=. Proceedings of the 2024 conference on empirical methods in natural language processing , month=. 2024 , url=
2024
-
[21]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month=
Code-switching red-teaming: Llm evaluation for safety and multilingual understanding , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month=. 2025 , url=
2025
-
[22]
Findings of the Association for Computational Linguistics: EMNLP 2025 , month=
English as Defense Proxy: Mitigating Multilingual Jailbreak via Eliciting English Safety Knowledge , author=. Findings of the Association for Computational Linguistics: EMNLP 2025 , month=. 2025 , url=
2025
-
[23]
Findings of the Association for Computational Linguistics: NAACL 2025 , month=
Towards understanding the fragility of multilingual llms against fine-tuning attacks , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , month=. 2025 , url=
2025
-
[24]
Exploring Methods for Cross-lingual Text Style Transfer: The Case of Text Detoxification
Dementieva, Daryna and Moskovskiy, Daniil and Dale, David and Panchenko, Alexander. Exploring Methods for Cross-lingual Text Style Transfer: The Case of Text Detoxification. Proceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguisti...
-
[26]
2025 , eprint=
Model Editing as a Robust and Denoised variant of DPO: A Case Study on Toxicity , author=. 2025 , eprint=
2025
-
[27]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , month=
BLEURT: Learning Robust Metrics for Text Generation , author=. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , month=. 2020 , url=
2020
-
[28]
2022 , eprint=
Detoxifying Language Models with a Toxic Corpus , author=. 2022 , eprint=
2022
-
[29]
Language
Caswell, Isaac and Breiner, Theresa and van Esch, Daan and Bapna, Ankur , booktitle=. Language. 2020 , address=
2020
-
[30]
The Risk of Racial Bias in Hate Speech Detection
Sap, Maarten and Card, Dallas and Gabriel, Saadia and Choi, Yejin and Smith, Noah A. The Risk of Racial Bias in Hate Speech Detection. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1163
-
[31]
2024 , eprint=
Steering Language Models With Activation Engineering , author=. 2024 , eprint=
2024
-
[32]
Advances in Neural Information Processing Systems , volume=
Locating and Editing Factual Associations in GPT , author=. Advances in Neural Information Processing Systems , volume=. 2022 , url=
2022
-
[33]
Steering Language Models in Multi-Token Generation: A Case Study on Tense and Aspect
Klerings, Alina and Brinkmann, Jannik and Ruffinelli, Daniel and Ponzetto, Simone Paolo. Steering Language Models in Multi-Token Generation: A Case Study on Tense and Aspect. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.435
-
[34]
Advances in Neural Information Processing Systems , volume=
Training Language Models to Follow Instructions with Human Feedback , author=. Advances in Neural Information Processing Systems , volume=. 2022 , url=
2022
-
[35]
Advances in Neural Information Processing Systems , volume=
Risk-averse fine-tuning of large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
arXiv preprint arXiv:2301.12867 , year=
Red teaming chatgpt via jailbreaking: Bias, robustness, reliability and toxicity , author=. arXiv preprint arXiv:2301.12867 , year=. 2301.12867 , archivePrefix=
-
[37]
Proceedings of the 4th Workshop on Trustworthy Natural Language Processing (TrustNLP 2024) , month=
Holistic evaluation of large language models: Assessing robustness, accuracy, and toxicity for real-world applications , author=. Proceedings of the 4th Workshop on Trustworthy Natural Language Processing (TrustNLP 2024) , month=. 2024 , url=
2024
-
[38]
arXiv preprint arXiv:2011.06485 , year=
Fairness and robustness in invariant learning: A case study in toxicity classification , author=. arXiv preprint arXiv:2011.06485 , year=. 2011.06485 , archivePrefix=
arXiv 2011
-
[39]
Findings of the Association for Computational Linguistics: EMNLP 2023 , month=
Toxicity in multilingual machine translation at scale , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , month=. 2023 , url=
2023
-
[40]
International Conference on Machine Learning , pages=
A Mechanistic Understanding of Alignment Algorithms: A Case Study on DPO and Toxicity , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[41]
Artificial Intelligence Review , volume=
Content moderation by LLM: from accuracy to legitimacy , author=. Artificial Intelligence Review , volume=. 2025 , publisher=
2025
-
[42]
Advances in neural information processing systems , volume=
Large language model as attributed training data generator: A tale of diversity and bias , author=. Advances in neural information processing systems , volume=
-
[43]
They are uncultured
“They are uncultured”: Unveiling Covert Harms and Social Threats in LLM Generated Conversations , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , month=. 2024 , url=
2024
-
[44]
2024 8th International Conference on Information Technology (InCIT) , pages=
SafeCultural: A Dataset for Evaluating Safety and Cultural Sensitivity in Large Language Models , author=. 2024 8th International Conference on Information Technology (InCIT) , pages=. 2024 , organization=
2024
-
[45]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , month=
Unveiling the Implicit Toxicity in Large Language Models , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , month=. 2023 , url=
2023
-
[46]
arXiv preprint arXiv:2503.02776 , year=
Implicit bias in llms: A survey , author=. arXiv preprint arXiv:2503.02776 , year=
-
[47]
2025 , eprint=
Breaking mBad! Supervised Fine-tuning for Cross-Lingual Detoxification , author=. 2025 , eprint=
2025
-
[48]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , month=
Decoding the Rule Book: Extracting Hidden Moderation Criteria from Reddit Communities , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , month=. 2025 , url=
2025
-
[49]
2022 , eprint=
Constitutional AI: Harmlessness from AI Feedback , author=. 2022 , eprint=
2022
-
[50]
Kreutzer, Julia and Caswell, Isaac and Wang, Lisa and Wahab, Ahsan and van Esch, Daan and Ulzii-Orshikh, Nasanbayar and Tapo, Allahsera and Subramani, Nishant and Sokolov, Artem and Sikasote, Claytone and Setyawan, Monang and Sarin, Supheakmungkol and Samb, Sokhar and Sagot, Benoît and Rivera, Clara and Rios, Annette and Papadimitriou, Isabel and Osei, Sa...
-
[51]
2025 , eprint=
Alignment and Safety in Large Language Models: Safety Mechanisms, Training Paradigms, and Emerging Challenges , author=. 2025 , eprint=
2025
-
[52]
2024 , eprint=
Toxic language detection: a systematic review of Arabic datasets , author=. 2024 , eprint=
2024
-
[53]
A da M erge X : Cross-Lingual Transfer with Large Language Models via Adaptive Adapter Merging
Zhao, Yiran and Zhang, Wenxuan and Wang, Huiming and Kawaguchi, Kenji and Bing, Lidong. A da M erge X : Cross-Lingual Transfer with Large Language Models via Adaptive Adapter Merging. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Paper...
-
[54]
P ara D etox: Detoxification with Parallel Data
Logacheva, Varvara and Dementieva, Daryna and Ustyantsev, Sergey and Moskovskiy, Daniil and Dale, David and Krotova, Irina and Semenov, Nikita and Panchenko, Alexander. P ara D etox: Detoxification with Parallel Data. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022...
-
[55]
Detoxifying Large Language Models via Knowledge Editing
Wang, Mengru and Zhang, Ningyu and Xu, Ziwen and Xi, Zekun and Deng, Shumin and Yao, Yunzhi and Zhang, Qishen and Yang, Linyi and Wang, Jindong and Chen, Huajun. Detoxifying Large Language Models via Knowledge Editing. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/202...
-
[56]
Daryna Dementieva and Nikolay Babakov and Alexander Panchenko , title =. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers) , pages =. 2024 , address =. doi:10.18653/v1/2024.naacl-short.12 , note =
-
[57]
Findings of the Association for Computational Linguistics: ACL 2024 , pages =
Beyza Ermis and Luiza Pozzobon and Sara Hooker and Patrick Lewis , title =. Findings of the Association for Computational Linguistics: ACL 2024 , pages =. 2024 , address =. doi:10.18653/v1/2024.findings-acl.893 , note =
-
[58]
R eal T oxicity P rompts: Evaluating Neural Toxic Degeneration in Language Models
RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models , author =. Findings of the Association for Computational Linguistics: EMNLP 2020 , year =. doi:10.18653/v1/2020.findings-emnlp.301 , url =
-
[59]
International Conference on Learning Representations (ICLR) 2020 , year =
The Curious Case of Neural Text Degeneration , author =. International Conference on Learning Representations (ICLR) 2020 , year =
2020
-
[60]
Advances in Neural Information Processing Systems , volume =
Training Language Models to Follow Instructions with Human Feedback , author =. Advances in Neural Information Processing Systems , volume =. 2022 , url =
2022
-
[61]
Advances in Neural Information Processing Systems , volume =
Learning to Summarize from Human Feedback , author =. Advances in Neural Information Processing Systems , volume =. 2020 , url =
2020
-
[62]
I'm sorry to hear that
"I'm sorry to hear that": Finding New Biases in Language Models with a Holistic Descriptor Dataset , author =. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2022
-
[63]
Inference-Time Policy Adapters (
Lu, Ximing and Brahman, Faeze and West, Peter and Jung, Jaehun and Chandu, Khyathi and Ravichander, Abhilasha and Ammanabrolu, Prithviraj and Jiang, Liwei and Ramnath, Sahana and Dziri, Nouha and Fisher, Jillian and Lin, Bill and Hallinan, Skyler and Qin, Lianhui and Ren, Xiang and Welleck, Sean and Choi, Yejin , booktitle =. Inference-Time Policy Adapter...
2023
-
[64]
Can LLM s Recognize Toxicity? A Structured Investigation Framework and Toxicity Metric
Can LLMs Recognize Toxicity? A Structured Investigation Framework and Toxicity Metric , author =. Findings of the Association for Computational Linguistics: EMNLP 2024 , month = nov, address =. 2024 , pages =. doi:10.18653/v1/2024.findings-emnlp.353 , url =
-
[65]
Findings of the Association for Computational Linguistics: EMNLP 2023 , month = dec, address =
Toxicity in ChatGPT: Analyzing Persona-assigned Language Models , author =. Findings of the Association for Computational Linguistics: EMNLP 2023 , month = dec, address =. 2023 , pages =
2023
-
[66]
2025 , eprint=
UNITYAI-GUARD: Pioneering Toxicity Detection Across Low-Resource Indian Languages , author=. 2025 , eprint=
2025
-
[67]
arXiv preprint , volume =
Devansh Jain and Priyanshu Kumar and Samuel Gehman and Xuhui Zhou and Thomas Hartvigsen and Maarten Sap , title =. arXiv preprint , volume =. 2024 , url =
2024
-
[68]
Preference Tuning for Toxicity Mitigation Generalizes Across Languages , journal =
Xiaochen Li and Zheng. Preference Tuning for Toxicity Mitigation Generalizes Across Languages , journal =. 2024 , url =
2024
-
[69]
Accurate and Data-Efficient Toxicity Prediction when Annotators Disagree
Jaggi, Harbani and Coimbatore Murali, Kashyap and Fleisig, Eve and Biyik, Erdem. Accurate and Data-Efficient Toxicity Prediction when Annotators Disagree. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.1221
-
[70]
A Plug-and-Play Method for Controlled Text Generation
Pascual, Damian and Egressy, Beni and Meister, Clara and Cotterell, Ryan and Wattenhofer, Roger. A Plug-and-Play Method for Controlled Text Generation. Findings of the Association for Computational Linguistics: EMNLP 2021. 2021. doi:10.18653/v1/2021.findings-emnlp.334
-
[71]
Smith and Yejin Choi , title =
Alisa Liu and Maarten Sap and Ximing Lu and Swabha Swayamdipta and Chandra Bhagavatula and Noah A. Smith and Yejin Choi , title =. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL 2021) , pages =. 2021 , address =
2021
-
[72]
Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , month=
Detoxifying Language Models Risks Marginalizing Minority Voices , author=. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , month=. 2021 , url=
2021
-
[73]
S ynth D etox M : M odern LLM s are Few-Shot Parallel Detoxification Data Annotators
Moskovskiy, Daniil and Sushko, Nikita and Pletenev, Sergey and Tutubalina, Elena and Panchenko, Alexander. S ynth D etox M : M odern LLM s are Few-Shot Parallel Detoxification Data Annotators. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: L...
-
[74]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages =
Luiza Pozzobon and Beyza Ermis and Patrick Lewis and Sara Hooker , title =. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages =. 2023 , address =. doi:10.18653/v1/2023.findings-emnlp.339 , note =
-
[75]
arXiv preprint , volume =
Xavier Suau and Pieter Delobelle and Katherine Metcalf and Armand Joulin and Nicholas Apostoloff and Luca Zappella and Pau Rodríguez , title =. arXiv preprint , volume =. 2024 , url =
2024
-
[76]
Villate-Castillo, Guillermo and Del Ser, Javier and Sanz Urquijo, Borja , title =. 2024 , url =. doi:10.21203/rs.3.rs-4621646/v1 , note =
-
[77]
Applied Intelligence , volume=
Reward modeling for mitigating toxicity in transformer-based language models , author=. Applied Intelligence , volume=. 2023 , publisher=
2023
-
[78]
arXiv preprint arXiv:2412.14050 , year=
Cross-Lingual Transfer of Debiasing and Detoxification in Multilingual LLMs: An Extensive Investigation , author=. arXiv preprint arXiv:2412.14050 , year=
-
[79]
Proceedings of the 29th International Conference on Computational Linguistics , month=
APPDIA: A Discourse-aware Transformer-based Style Transfer Model for Offensive Social Media Conversations , author=. Proceedings of the 29th International Conference on Computational Linguistics , month=. 2022 , url=
2022
-
[80]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Self-Detoxifying Language Models via Toxification Reversal , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=. 2023 , address=
2023
-
[81]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
DetoxLLM: A Framework for Detoxification with Explanations , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.