Causal-rCM: A Unified Teacher-Forcing and Self-Forcing Open Recipe for Autoregressive Diffusion Distillation in Streaming Video Generation and Interactive World Models
Pith reviewed 2026-06-25 20:55 UTC · model grok-4.3
The pith
Causal-rCM combines teacher-forcing consistency models as initialization with self-forcing DMD refinement to distill autoregressive video diffusion models that generate high-quality streaming video in one or two steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
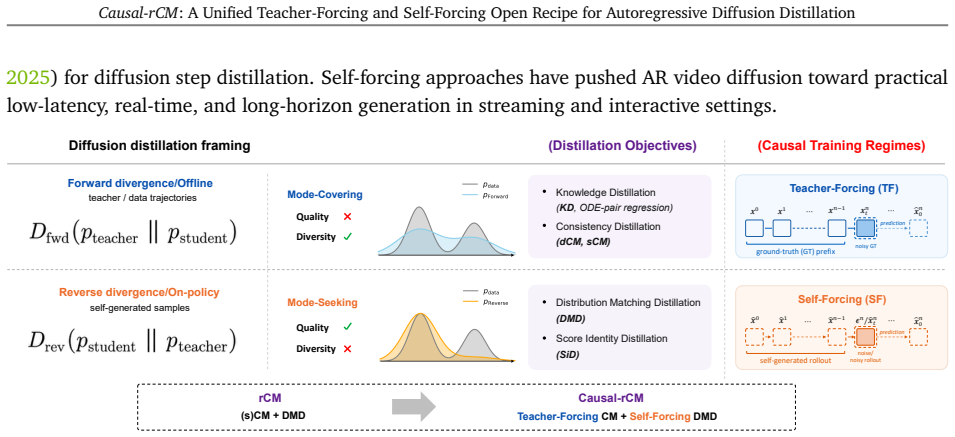
The core philosophy of complementarity between forward and reverse divergences carries over directly to the autoregressive setting, so that teacher-forcing CM serves as the best initialization complement to self-forcing DMD; this pairing, together with continuous-time CMs enabled by a custom-mask FlashAttention-2 JVP kernel, yields state-of-the-art streaming video generation in both frame-wise and chunk-wise regimes using only synthetic data and supports interactive world models on Cosmos 3.
What carries the argument
Causal-rCM, the unified recipe that pairs teacher-forcing continuous-time consistency models with self-forcing distribution matching distillation for causal autoregressive diffusion training.
If this is right
- Teacher-forcing CM initialization is currently the strongest complement to self-forcing DMD.
- Continuous-time CMs converge ten times faster than discrete-time CMs under the custom JVP kernel.
- The distilled 2-step Wan2.1-1.3B model attains 84.63 VBench-T2V with one or two sampling steps.
- The same recipe reaches state-of-the-art results in both frame-wise and chunk-wise streaming settings on synthetic data alone.
- Causal-rCM transfers to action-conditioned generation inside the Cosmos 3 omnimodal world model.
Where Pith is reading between the lines
- The same teacher-forcing plus self-forcing pairing could be tested on other autoregressive sequence domains such as audio or text.
- One- or two-step sampling opens the possibility of real-time interactive video world models on consumer hardware.
- Training entirely on synthetic data suggests that the method may scale without large curated video corpora.
- The custom JVP kernel technique may generalize to accelerate consistency training in other transformer architectures.
Load-bearing premise
The complementarity between forward and reverse divergences that worked in ordinary diffusion distillation also holds when the model must generate video autoregressively with causal attention.
What would settle it
A controlled run in which replacing teacher-forcing CM initialization with random or standard initialization produces equal or better final self-forcing DMD performance on the same autoregressive video backbone would falsify the claimed complementarity.
Figures


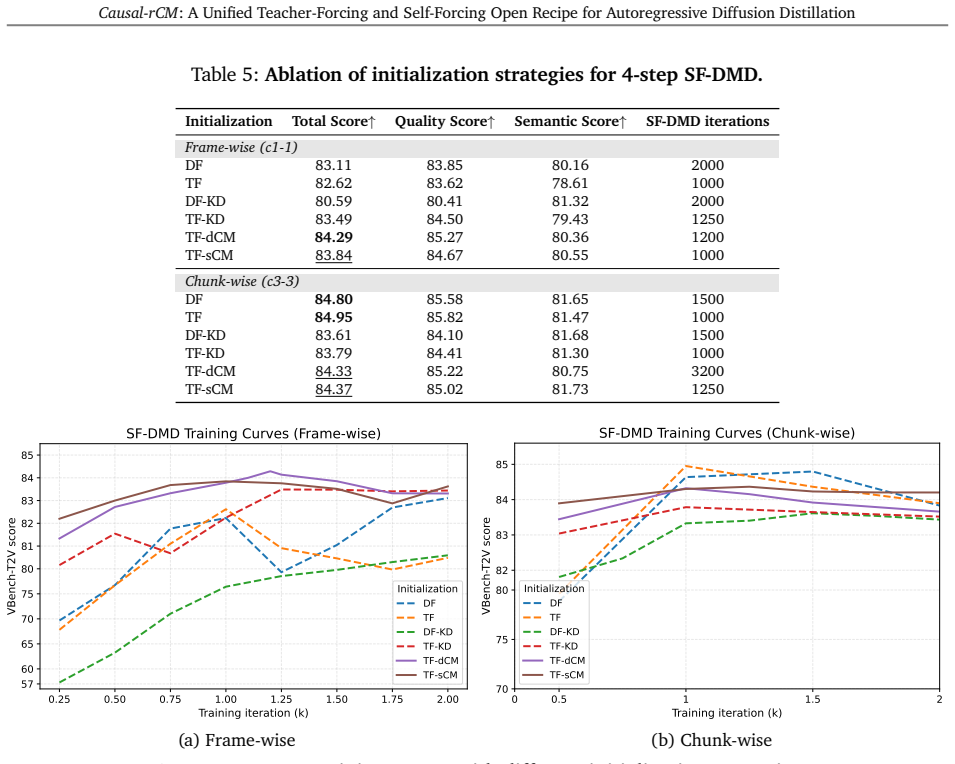


read the original abstract
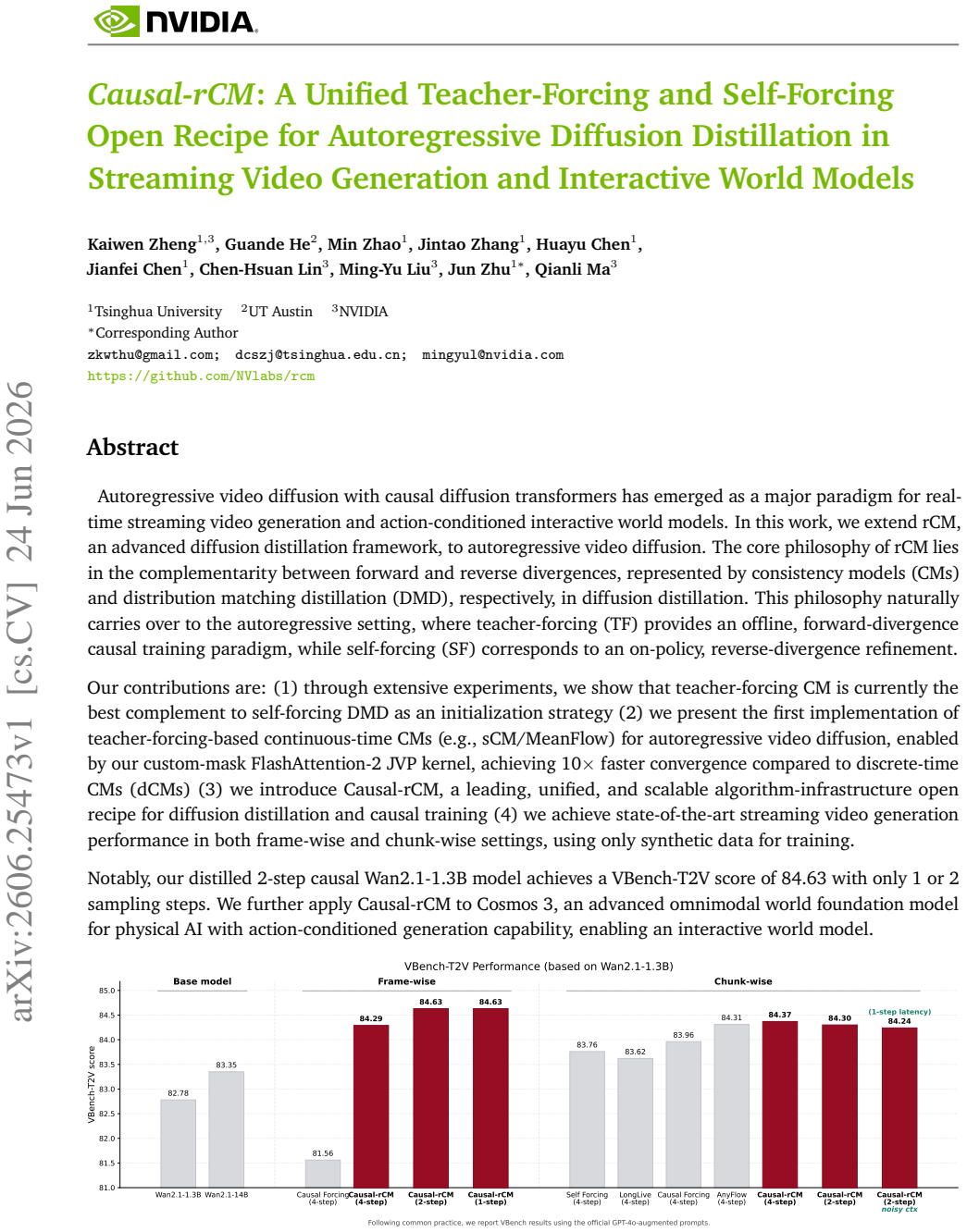
Autoregressive video diffusion with causal diffusion transformers has emerged as a major paradigm for real-time streaming video generation and action-conditioned interactive world models. In this work, we extend rCM, an advanced diffusion distillation framework, to autoregressive video diffusion. The core philosophy of rCM lies in the complementarity between forward and reverse divergences, represented by consistency models (CMs) and distribution matching distillation (DMD), respectively, in diffusion distillation. This philosophy naturally carries over to the autoregressive setting, where teacher-forcing (TF) provides an offline, forward-divergence causal training paradigm, while self-forcing (SF) corresponds to an on-policy, reverse-divergence refinement. Our contributions are: (1) through extensive experiments, we show that teacher-forcing CM is currently the best complement to self-forcing DMD as an initialization strategy (2) we present the first implementation of teacher-forcing-based continuous-time CMs (e.g., sCM/MeanFlow) for autoregressive video diffusion, enabled by our custom-mask FlashAttention-2 JVP kernel, achieving 10$\times$ faster convergence compared to discrete-time CMs (dCMs) (3) we introduce Causal-rCM, a leading, unified, and scalable algorithm-infrastructure open recipe for diffusion distillation and causal training (4) we achieve state-of-the-art streaming video generation performance in both frame-wise and chunk-wise settings, using only synthetic data for training. Notably, our distilled 2-step causal Wan2.1-1.3B model achieves a VBench-T2V score of 84.63 with only 1 or 2 sampling steps. We further apply Causal-rCM to Cosmos 3, an advanced omnimodal world foundation model for physical AI with action-conditioned generation capability, enabling an interactive world model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends the rCM diffusion distillation framework to autoregressive video diffusion, arguing that the complementarity between teacher-forcing consistency models (forward divergence) and self-forcing DMD (reverse divergence) naturally carries over to the causal setting. It introduces Causal-rCM as a unified recipe, implements continuous-time CMs with custom FlashAttention kernels for 10x faster convergence, and reports SOTA performance including a VBench-T2V score of 84.63 with 1-2 steps on a distilled 2-step causal Wan2.1-1.3B model, applied also to Cosmos 3 for interactive world models, all trained on synthetic data.
Significance. If the results hold, this provides a significant advance in efficient streaming video generation and action-conditioned world models by offering an open, scalable distillation method that achieves high performance with very few sampling steps. The emphasis on an open recipe is a strength for reproducibility in the field.
major comments (2)
- [Abstract] Abstract: The foundational claim that the rCM complementarity 'naturally carries over' to the autoregressive setting (with TF CM as best initialization for SF DMD) is presented without analysis of how causal masking, frame-wise conditioning, or self-forcing's sequential error accumulation affect the forward-reverse synergy or exposure bias; this assumption underpins all listed contributions and requires explicit justification beyond empirical assertion.
- [Abstract] Abstract: Performance claims including 10× faster convergence for continuous-time CMs and the VBench-T2V score of 84.63 are reported without reference to exact baselines, data splits, number of runs, or statistical tests, preventing verification of the SOTA and convergence assertions.
minor comments (1)
- [Abstract] Abstract: The phrase 'currently the best complement' is used without citing the specific ablation or comparison that establishes this ranking among possible initializations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight opportunities to strengthen the justification and clarity of our claims. We address each major comment below and will incorporate revisions in the next version of the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: The foundational claim that the rCM complementarity 'naturally carries over' to the autoregressive setting (with TF CM as best initialization for SF DMD) is presented without analysis of how causal masking, frame-wise conditioning, or self-forcing's sequential error accumulation affect the forward-reverse synergy or exposure bias; this assumption underpins all listed contributions and requires explicit justification beyond empirical assertion.
Authors: Our claim rests on the empirical demonstration through extensive experiments that teacher-forcing CM provides the strongest initialization for self-forcing DMD. We acknowledge that a more explicit analysis of causal masking, frame-wise conditioning, and exposure bias effects on the forward-reverse synergy would improve rigor. In the revised manuscript, we will add a dedicated discussion paragraph (with supporting ablation observations) addressing how these autoregressive factors preserve the complementarity. revision: yes
-
Referee: [Abstract] Abstract: Performance claims including 10× faster convergence for continuous-time CMs and the VBench-T2V score of 84.63 are reported without reference to exact baselines, data splits, number of runs, or statistical tests, preventing verification of the SOTA and convergence assertions.
Authors: We agree the abstract is too concise on these points. The body of the manuscript specifies the baselines (discrete-time CMs and prior distillation approaches), evaluation protocol on VBench-T2V, and synthetic data sources. We will revise the abstract to reference these details and note that convergence comparisons were obtained over repeated training runs. Full tables with any variance measures appear in the experiments section. revision: yes
Circularity Check
Empirical engineering paper with no derivation reducing to inputs
full rationale
The paper reports an extension of rCM to autoregressive video diffusion via teacher-forcing CM and self-forcing DMD, with all listed contributions (implementation of continuous-time CMs, Causal-rCM recipe, SOTA scores on VBench-T2V) resting on experimental outcomes and custom infrastructure rather than any closed-form derivation. The statement that rCM complementarity 'naturally carries over' is presented as a premise tested by 'extensive experiments' identifying TF CM as best initialization; no equations, fitted parameters renamed as predictions, or self-citation chains are shown that would make the central claims equivalent to their inputs by construction. The work is self-contained against external benchmarks such as VBench scores and is therefore scored at the default non-circularity level.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The complementarity between forward (consistency-model) and reverse (distribution-matching) divergences in rCM naturally carries over to the autoregressive video setting.
Reference graph
Works this paper leans on
-
[1]
World simulation with video foundation models for physical ai.arXiv preprint arXiv:2511.00062, 2025
Arslan Ali, Junjie Bai, Maciej Bala, Yogesh Balaji, Aaron Blakeman, Tiffany Cai, Jiaxin Cao, Tianshi Cao, Elizabeth Cha, Yu-Wei Chao, et al. World simulation with video foundation models for physical ai.arXiv preprint arXiv:2511.00062, 2025. 2
Pith/arXiv arXiv 2025
-
[2]
Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and Volodymyr Kuleshov
Marianne Arriola, Aaron Gokaslan, Justin T. Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and Volodymyr Kuleshov. Block diffusion: Interpolating between autoregressive and diffusion language models.arXiv preprint arXiv:2503.09573, 2025. 2
Pith/arXiv arXiv 2025
-
[3]
Fan Bao, Chendong Xiang, Gang Yue, Guande He, Hongzhou Zhu, Kaiwen Zheng, Min Zhao, Shilong Liu, Yaole Wang, and Jun Zhu. Vidu: a highly consistent, dynamic and skilled text-to-video generator with diffusion models.arXiv preprint arXiv:2405.04233, 2024. 2
arXiv 2024
-
[4]
Video generation models as world simulators
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, et al. Video generation models as world simulators. 2024.URL https://openai. com/research/video-generation-models-as-world-simulators, 3, 2024. 2
2024
-
[5]
Mode seeking meets mean seeking for fast long video generation.arXiv preprint arXiv:2602.24289, 2026
Shengqu Cai, Weili Nie, Chao Liu, Julius Berner, Lvmin Zhang, Nanye Ma, Hansheng Chen, Maneesh Agrawala, Leonidas Guibas, Gordon Wetzstein, et al. Mode seeking meets mean seeking for fast long video generation.arXiv preprint arXiv:2602.24289, 2026. 18
arXiv 2026
-
[6]
Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024
Boyuan Chen, Diego Martí Monsó, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024. 2
2024
-
[7]
Skyreels-v2: Infinite-length film generative model.arXiv preprint arXiv:2504.13074, 2025
Guibin Chen, Dixuan Lin, Jiangping Yang, Chunze Lin, Junchen Zhu, Mingyuan Fan, Hao Zhang, Sheng Chen, Zheng Chen, Chengcheng Ma, et al. Skyreels-v2: Infinite-length film generative model.arXiv preprint arXiv:2504.13074, 2025. 2
Pith/arXiv arXiv 2025
-
[8]
HanshengChen,KaiZhang,HaoTan,LeonidasGuibas,GordonWetzstein,andSaiBi. pi-flow: Policy-based few-step generation via imitation distillation.arXiv preprint arXiv:2510.14974, 2025. 18
arXiv 2025
-
[9]
Longlive2.0: An nvfp4 parallel infrastructure for long video generation.arXiv preprint arXiv,
Yukang Chen, Luozhou Wang, Wei Huang, Shuai Yang, Bohan Zhang, Yicheng Xiao, Ruihang Chu, Weian Mao, Qixin Hu, Shaoteng Liu, Yuyang Zhao, Huizi Mao, Ying-Cong Chen, Enze Xie, Xiaojuan Qi, and Song Han. Longlive2.0: An nvfp4 parallel infrastructure for long video generation.arXiv preprint arXiv,
-
[10]
Zhenglin Cheng, Peng Sun, Jianguo Li, and Tao Lin. Twinflow: Realizing one-step generation on large models with self-adversarial flows.arXiv preprint arXiv:2512.05150, 2025. 18
arXiv 2025
-
[11]
Juechu Dong, Boyuan Feng, Driss Guessous, Yanbo Liang, and Horace He. Flex attention: A programming model for generating optimized attention kernels.arXiv preprint arXiv:2412.05496, 2(3):4, 2024. 8
Pith/arXiv arXiv 2024
-
[12]
Jiaqi Feng, Justin Cui, Yuanhao Ban, and Cho-Jui Hsieh. One-forcing: Towards stable one-step autore- gressive video generation.arXiv preprint arXiv:2605.23458, 2026. 19
Pith/arXiv arXiv 2026
-
[13]
Vidarc: Embodied video diffusion model for closed-loop control.arXiv preprint arXiv:2512.17661, 2025
Yao Feng, Chendong Xiang, Xinyi Mao, Hengkai Tan, Zuyue Zhang, Shuhe Huang, Kaiwen Zheng, Haitian Liu, Hang Su, and Jun Zhu. Vidarc: Embodied video diffusion model for closed-loop control.arXiv preprint arXiv:2512.17661, 2025. 2
arXiv 2025
-
[14]
Yu Gao, Haoyuan Guo, Tuyen Hoang, Weilin Huang, Lu Jiang, Fangyuan Kong, Huixia Li, Jiashi Li, Liang Li, Xiaojie Li, et al. Seedance 1.0: Exploring the boundaries of video generation models.arXiv preprint arXiv:2506.09113, 2025. 2 20 Causal-rCM: A Unified Teacher-Forcing and Self-Forcing Open Recipe for Autoregressive Diffusion Distillation
Pith/arXiv arXiv 2025
-
[15]
Mean flows for one-step generative modeling.arXiv preprint arXiv:2505.13447, 2025
Zhengyang Geng, Mingyang Deng, Xingjian Bai, J Zico Kolter, and Kaiming He. Mean flows for one-step generative modeling.arXiv preprint arXiv:2505.13447, 2025. 3, 5, 17
Pith/arXiv arXiv 2025
-
[16]
Yuchao Gu, Guian Fang, Yuxin Jiang, Weijia Mao, Song Han, Han Cai, and Mike Zheng Shou. Anyflow: Any-step video diffusion model with on-policy flow map distillation.arXiv preprint arXiv:2605.13724,
-
[17]
FastVideo: A unified inference and post-training framework for accelerated video generation,
Hao-AI Lab. FastVideo: A unified inference and post-training framework for accelerated video generation,
-
[18]
URLhttps://github.com/hao-ai-lab/FastVideo. 11
-
[19]
Xianglong He, Chunli Peng, Zexiang Liu, Boyang Wang, Yifan Zhang, Qi Cui, Fei Kang, Biao Jiang, Mengyin An, Yangyang Ren, Baixin Xu, Hao-Xiang Guo, Kaixiong Gong, Size Wu, Wei Li, Xuchen Song, Yang Liu, Yangguang Li, and Yahui Zhou. Matrix-game 2.0: An open-source real-time and streaming interactive world model.arXiv preprint arXiv:2508.13009, 2025. 2, 3
Pith/arXiv arXiv 2025
-
[20]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 4
2020
-
[21]
Relic: Interactive video world model with long-horizon memory.arXiv preprint arXiv:2512.04040, 2025
Yicong Hong, Yiqun Mei, Chongjian Ge, Yiran Xu, Yang Zhou, Sai Bi, Yannick Hold-Geoffroy, Mike Roberts, Matthew Fisher, Eli Shechtman, Kalyan Sunkavalli, Feng Liu, Zhengqi Li, and Hao Tan. Relic: Interactive video world model with long-horizon memory.arXiv preprint arXiv:2512.04040, 2025. 2, 3, 12
arXiv 2025
-
[22]
simple diffusion: End-to-end diffusion for high resolution images
Emiel Hoogeboom, Jonathan Heek, and Tim Salimans. simple diffusion: End-to-end diffusion for high resolution images. InInternational Conference on Machine Learning, pages 13213–13232. PMLR, 2023. 15
2023
-
[23]
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009, 2025. 2, 3, 6, 7, 9, 11, 14, 18
Pith/arXiv arXiv 2025
-
[24]
Yubo Huang, Hailong Guo, Fangtai Wu, Weiqiang Wang, Shifeng Zhang, Shijie Huang, Qijun Gan, Lin Liu, Sirui Zhao, Enhong Chen, Jiaming Liu, and Steven Hoi. Live avatar: Streaming real-time audio-driven avatar generation with infinite length.arXiv preprint arXiv:2512.04677, 2025. 2, 3, 10
Pith/arXiv arXiv 2025
-
[25]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024. 14
2024
-
[26]
Hy-world 1.5: A systematic framework for interactive world modeling with real-time latency and geometric consistency.arXiv preprint, 2025
Team HunyuanWorld. Hy-world 1.5: A systematic framework for interactive world modeling with real-time latency and geometric consistency.arXiv preprint, 2025. 2
2025
-
[27]
Sam Ade Jacobs, Masahiro Tanaka, Chengming Zhang, Minjia Zhang, Shuaiwen Leon Song, Samyam Rajbhandari, and Yuxiong He. Deepspeed ulysses: System optimizations for enabling training of extreme long sequence transformer models.arXiv preprint arXiv:2309.14509, 2023. 11
Pith/arXiv arXiv 2023
-
[28]
Dengyang Jiang, Dongyang Liu, Zanyi Wang, Qilong Wu, Liuzhuozheng Li, Hengzhuang Li, Xin Jin, David Liu, Changsheng Lu, Zhen Li, et al. Distribution matching distillation meets reinforcement learning.arXiv preprint arXiv:2511.13649, 2025. 18
arXiv 2025
-
[29]
Pyramidal flow matching for efficient video generative modeling
Yang Jin, Zhicheng Sun, Ningyuan Li, Kun Xu, Hao Jiang, Nan Zhuang, Quzhe Huang, Yang Song, Yadong Mu, and Zhouchen Lin. Pyramidal flow matching for efficient video generative modeling. InInternational Conference on Learning Representations, volume 2025, pages 23378–23402, 2025. 2 21 Causal-rCM: A Unified Teacher-Forcing and Self-Forcing Open Recipe for A...
2025
-
[30]
Dongjun Kim, Chieh-Hsin Lai, Wei-Hsiang Liao, Naoki Murata, Yuhta Takida, Toshimitsu Uesaka, Yutong He, Yuki Mitsufuji, and Stefano Ermon. Consistency trajectory models: Learning probability flow ode trajectory of diffusion.arXiv preprint arXiv:2310.02279, 2023. 5
arXiv 2023
-
[31]
Youngrae Kim, Qixin Hu, C-C Jay Kuo, and Peter A Beerel. Memrope: Training-free infinite video generation via evolving memory tokens.arXiv preprint arXiv:2603.12513, 2026. 12
arXiv 2026
-
[32]
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 2
Pith/arXiv arXiv 2024
-
[33]
Haobo Li, Yanhong Zeng, Yunhong Lu, Jiapeng Zhu, Hao Ouyang, Qiuyu Wang, Ka Leong Cheng, Yujun Shen, and Zhipeng Zhang. Aad-1: Asymmetric adversarial distillation for one-step autoregressive video generation.arXiv preprint arXiv:2606.03972, 2026. 19
Pith/arXiv arXiv 2026
-
[34]
Haodong Li, Shaoteng Liu, Zhe Lin, and Manmohan Chandraker. Rolling sink: Bridging limited-horizon training and open-ended testing in autoregressive video diffusion.arXiv preprint arXiv:2602.07775, 2026. 12
Pith/arXiv arXiv 2026
-
[35]
Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026
Lin Li, Qihang Zhang, Yiming Luo, Shuai Yang, Ruilin Wang, Fei Han, Mingrui Yu, Zelin Gao, Nan Xue, Xing Zhu, et al. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026. 2
Pith/arXiv arXiv 2026
-
[36]
Diffusion adversarial post-training for one-step video generation
Shanchuan Lin, Xin Xia, Yuxi Ren, Ceyuan Yang, Xuefeng Xiao, and Lu Jiang. Diffusion adversarial post-training for one-step video generation. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 37959–37974. PMLR, 2025. 2, 3, 19
2025
-
[37]
Shanchuan Lin, Ceyuan Yang, Hao He, Jianwen Jiang, Yuxi Ren, Xin Xia, Yang Zhao, Xuefeng Xiao, and Lu Jiang. Autoregressive adversarial post-training for real-time interactive video generation.arXiv preprint arXiv:2506.09350, 2025. 2, 3, 7, 18, 19
arXiv 2025
-
[38]
Continuous adversarial flow models
Shanchuan Lin, Ceyuan Yang, Zhijie Lin, Hao Chen, and Haoqi Fan. Continuous adversarial flow models. arXiv preprint arXiv:2604.11521, 2026. 18
Pith/arXiv arXiv 2026
-
[39]
Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022. 4
Pith/arXiv arXiv 2022
-
[40]
Streaming autoregressive video generation via diagonal distillation
Jinxiu Liu, Xuanming Liu, Kangfu Mei, Yandong Wen, Ming-Hsuan Yang, and Weiyang Liu. Streaming autoregressive video generation via diagonal distillation. InICLR, 2026. 10
2026
-
[41]
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022. 4
Pith/arXiv arXiv 2022
-
[42]
Cheng Lu and Yang Song. Simplifying, stabilizing and scaling continuous-time consistency models.arXiv preprint arXiv:2410.11081, 2024. 3, 5, 17, 29
Pith/arXiv arXiv 2024
-
[43]
Maximum likelihood training for score-based diffusion odes by high order denoising score matching
Cheng Lu, Kaiwen Zheng, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Maximum likelihood training for score-based diffusion odes by high order denoising score matching. InInternational conference on machine learning, pages 14429–14460. PMLR, 2022. 17
2022
-
[44]
Eric Luhman and Troy Luhman. Knowledge distillation in iterative generative models for improved sampling speed.arXiv preprint arXiv:2101.02388, 2021. 8
Pith/arXiv arXiv 2021
-
[45]
Nvidia fastgen: Fast generation from diffusion models, 2026
Weili Nie, Julius Berner, Chao Liu, and Arash Vahdat. Nvidia fastgen: Fast generation from diffusion models, 2026. URLhttps://github.com/NVlabs/FastGen. 11 22 Causal-rCM: A Unified Teacher-Forcing and Self-Forcing Open Recipe for Autoregressive Diffusion Distillation
2026
-
[46]
Transition matching distillation for fast video generation.arXiv preprint arXiv:2601.09881, 2026
Weili Nie, Julius Berner, Nanye Ma, Chao Liu, Saining Xie, and Arash Vahdat. Transition matching distillation for fast video generation.arXiv preprint arXiv:2601.09881, 2026. 18, 19
arXiv 2026
-
[47]
Elucidating the exposure bias in diffusion models
Mang Ning, Mingxiao Li, Jianlin Su, Albert Ali Salah, and Itir Onal Ertugrul. Elucidating the exposure bias in diffusion models. InInternational Conference on Learning Representations, volume 2024, pages 15167–15189, 2024. 2
2024
-
[48]
Cosmos 3: Omnimodal world models for physical ai.arXiv preprint arXiv:2606.02800, 2026
NVIDIA. Cosmos 3: Omnimodal world models for physical ai.arXiv preprint arXiv:2606.02800, 2026. URLhttps://research.nvidia.com/labs/cosmos-lab/cosmos3/technical-report.pdf. 2, 16
Pith/arXiv arXiv 2026
-
[49]
Dogyun Park, Yanyu Li, Sergey Tulyakov, and Anil Kag. Eflow: Fast few-step video generator training from scratch via efficient solution flow.arXiv preprint arXiv:2603.27086, 2026. 19
arXiv 2026
-
[50]
Facm: Flow-anchored consistency models.arXiv preprint arXiv:2507.03738, 2025
Yansong Peng, Kai Zhu, Yu Liu, Pingyu Wu, Hebei Li, Xiaoyan Sun, and Feng Wu. Facm: Flow-anchored consistency models.arXiv preprint arXiv:2507.03738, 2025. 17
arXiv 2025
-
[51]
Yifan Pu, Yizeng Han, Zhiwei Tang, Jiasheng Tang, Fan Wang, Bohan Zhuang, and Gao Huang. Few-step distillation for text-to-image generation: A practical guide.arXiv preprint arXiv:2512.13006, 2025. 18
arXiv 2025
-
[52]
Advancing open-source world models.arXiv preprint arXiv:2601.20540, 2026
Robbyant Team, Zelin Gao, Qiuyu Wang, Yanhong Zeng, Jiapeng Zhu, Ka Leong Cheng, Yixuan Li, Hanlin Wang, Yinghao Xu, Shuailei Ma, Yihang Chen, Jie Liu, Yansong Cheng, Yao Yao, Jiayi Zhu, Yihao Meng, Kecheng Zheng, Qingyan Bai, Jingye Chen, Zehong Shen, Yue Yu, Xing Zhu, Yujun Shen, and Hao Ouyang. Advancing open-source world models.arXiv preprint arXiv:26...
Pith/arXiv arXiv 2026
-
[53]
Align your flow: Scaling continuous-time flow map distillation.arXiv preprint arXiv:2506.14603, 2025
Amirmojtaba Sabour, Sanja Fidler, and Karsten Kreis. Align your flow: Scaling continuous-time flow map distillation.arXiv preprint arXiv:2506.14603, 2025. 17
arXiv 2025
-
[54]
Simple and effective masked diffusion language models.arXiv preprint arXiv:2406.07524, 2024
Subham Sekhar Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T Chiu, Alexander Rush, and Volodymyr Kuleshov. Simple and effective masked diffusion language models.arXiv preprint arXiv:2406.07524, 2024. 2
arXiv 2024
-
[55]
Generalization in generation: A closer look at exposure bias
Florian Schmidt. Generalization in generation: A closer look at exposure bias. InProceedings of the 3rd Workshop on Neural Generation and Translation, pages 157–167, 2019. 2
2019
-
[56]
Seedance 2.0: Advancing video generation for world complexity
Team Seedance, De Chen, Liyang Chen, Xin Chen, Ying Chen, Zhuo Chen, Zhuowei Chen, Feng Cheng, Tianheng Cheng, Yufeng Cheng, et al. Seedance 2.0: Advancing video generation for world complexity. arXiv preprint arXiv:2604.14148, 2026. 2
Pith/arXiv arXiv 2026
-
[57]
Simplified and generalized masked diffusion for discrete data.arXiv preprint arXiv:2406.04329, 2024
Jiaxin Shi, Kehang Han, Zhe Wang, Arnaud Doucet, and Michalis K Titsias. Simplified and generalized masked diffusion for discrete data.arXiv preprint arXiv:2406.04329, 2024. 2
arXiv 2024
-
[58]
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020. 4
Pith/arXiv arXiv 2011
-
[59]
Consistency models
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. InInternational Conference on Machine Learning, pages 32211–32252. PMLR, 2023. 5
2023
-
[60]
Magi-1: Autoregressive video generation at scale.arXiv preprint arXiv:2505.13211, 2025
Hansi Teng, Hongyu Jia, Lei Sun, Lingzhi Li, Maolin Li, Mingqiu Tang, Shuai Han, Tianning Zhang, WQ Zhang, Weifeng Luo, et al. Magi-1: Autoregressive video generation at scale.arXiv preprint arXiv:2505.13211, 2025. 2
Pith/arXiv arXiv 2025
-
[61]
Flow map distillation without data.arXiv preprint arXiv:2511.19428, 2025
Shangyuan Tong, Nanye Ma, Saining Xie, and Tommi Jaakkola. Flow map distillation without data.arXiv preprint arXiv:2511.19428, 2025. 18 23 Causal-rCM: A Unified Teacher-Forcing and Self-Forcing Open Recipe for Autoregressive Diffusion Distillation
arXiv 2025
-
[62]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
Pith/arXiv arXiv 2025
-
[63]
Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation.Advances in neural information processing systems, 36:8406–8441, 2023
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation.Advances in neural information processing systems, 36:8406–8441, 2023. 6
2023
-
[64]
Tianhe Wu, Ruibin Li, Lei Zhang, and Kede Ma. Diversity-preserved distribution matching distillation for fast visual synthesis.arXiv preprint arXiv:2602.03139, 2026. 18
Pith/arXiv arXiv 2026
-
[65]
Longlive: Real-time interactive long video generation
Shuai Yang, Wei Huang, Ruihang Chu, Yicheng Xiao, Yuyang Zhao, Xianbang Wang, Muyang Li, Enze Xie, Yingcong Chen, Yao Lu, et al. Longlive: Real-time interactive long video generation. InICLR, 2026. 2, 14
2026
-
[66]
Data-regularized reinforcement learning for diffusion models at scale
Haotian Ye, Kaiwen Zheng, Jiashu Xu, Puheng Li, Huayu Chen, Jiaqi Han, Sheng Liu, Qinsheng Zhang, Hanzi Mao, Zekun Hao, et al. Data-regularized reinforcement learning for diffusion models at scale. arXiv preprint arXiv:2512.04332, 2025. 4
arXiv 2025
-
[67]
World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026. 2
Pith/arXiv arXiv 2026
-
[68]
Infinity-rope: Action- controllable infinite video generation emerges from autoregressive self-rollout
Hidir Yesiltepe, Tuna Meral, Adil Kaan Akan, Kaan Oktay, and Pinar Yanardag. Infinity-rope: Action- controllable infinite video generation emerges from autoregressive self-rollout. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 40256–40265, 2026. 12
2026
-
[69]
Jung Yi, Wooseok Jang, Paul Hyunbin Cho, Jisu Nam, Heeji Yoon, and Seungryong Kim. Deep forc- ing: Training-free long video generation with deep sink and participative compression.arXiv preprint arXiv:2512.05081, 2025. 12
arXiv 2025
-
[70]
Improved distribution matching distillation for fast image synthesis.Advances in neural information processing systems, 37:47455–47487, 2024
Tianwei Yin, Michaël Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, and Bill Freeman. Improved distribution matching distillation for fast image synthesis.Advances in neural information processing systems, 37:47455–47487, 2024. 2, 6, 9
2024
-
[71]
One-step diffusion with distribution matching distillation
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6613–6623, 2024. 2, 6
2024
-
[72]
From slow bidirectional to fast autoregressive video diffusion models
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22963–22974, 2025. 3
2025
-
[73]
Yuyang You, Yongzhi Li, Jiahui Li, Yadong Mu, Quan Chen, and Peng Jiang. Adaptive video distillation: Mitigating oversaturation and temporal collapse in few-step generation.arXiv preprint arXiv:2603.21864,
-
[74]
Magiattention: A distributed attention towards linear scalability for ultra-long context, heterogeneous mask training.https://github.com/SandAI-org/MagiAttention/,
Tao Zewei and Huang Yunpeng. Magiattention: A distributed attention towards linear scalability for ultra-long context, heterogeneous mask training.https://github.com/SandAI-org/MagiAttention/,
-
[75]
8, 30 24 Causal-rCM: A Unified Teacher-Forcing and Self-Forcing Open Recipe for Autoregressive Diffusion Distillation
-
[76]
Jintao Zhang, Haoxu Wang, Kai Jiang, Shuo Yang, Kaiwen Zheng, Haocheng Xi, Ziteng Wang, Hongzhou Zhu, Min Zhao, Ion Stoica, et al. Sla: Beyond sparsity in diffusion transformers via fine-tunable sparse- linear attention.arXiv preprint arXiv:2509.24006, 2025. 19
arXiv 2025
-
[77]
Jintao Zhang, Kaiwen Zheng, Kai Jiang, Haoxu Wang, Ion Stoica, Joseph E Gonzalez, Jianfei Chen, and Jun Zhu. Turbodiffusion: Accelerating video diffusion models by 100-200 times.arXiv preprint arXiv:2512.16093, 2025. 19
arXiv 2025
-
[78]
Sla2: Sparse-linear attention with learnable routing and qat.arXiv preprint arXiv:2602.12675, 2026
Jintao Zhang, Haoxu Wang, Kai Jiang, Kaiwen Zheng, Youhe Jiang, Ion Stoica, Jianfei Chen, Jun Zhu, and Joseph E Gonzalez. Sla2: Sparse-linear attention with learnable routing and qat.arXiv preprint arXiv:2602.12675, 2026. 19
arXiv 2026
-
[79]
Min Zhao, Hongzhou Zhu, Kaiwen Zheng, Zihan Zhou, Bokai Yan, Xinyuan Li, Xiao Yang, Chongxuan Li, and Jun Zhu. Causal forcing++: Scalable few-step autoregressive diffusion distillation for real-time interactive video generation.arXiv preprint arXiv:2605.15141, 2026. 18, 19
Pith/arXiv arXiv 2026
-
[80]
Pytorch fsdp: experiences on scaling fully sharded data parallel
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, et al. Pytorch fsdp: experiences on scaling fully sharded data parallel. arXiv preprint arXiv:2304.11277, 2023. 11
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.