Leaking Circuit Secrets: Gradient Leakage Attacks on Graph Neural Networks
Pith reviewed 2026-06-25 21:07 UTC · model grok-4.3
The pith
Gradient leakage attacks on graph neural networks for circuit netlists can reveal gate types and hardware Trojan properties.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
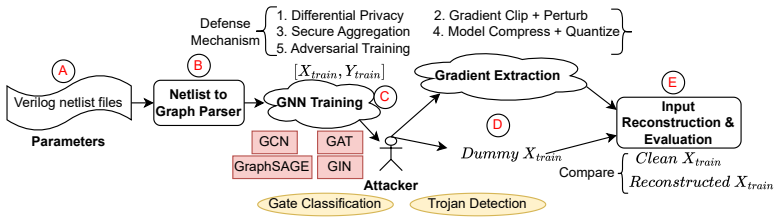
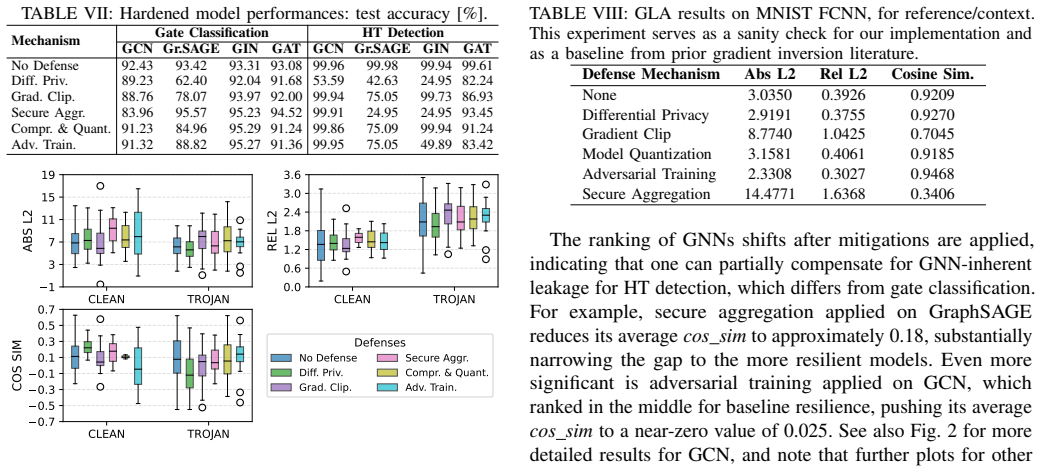
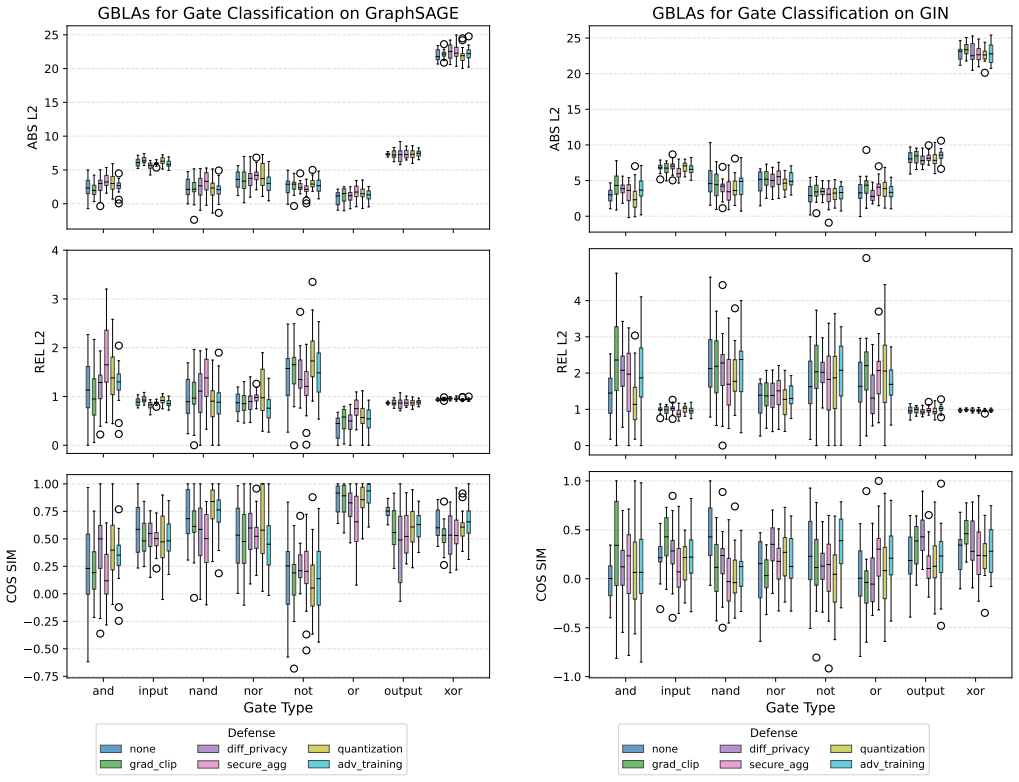
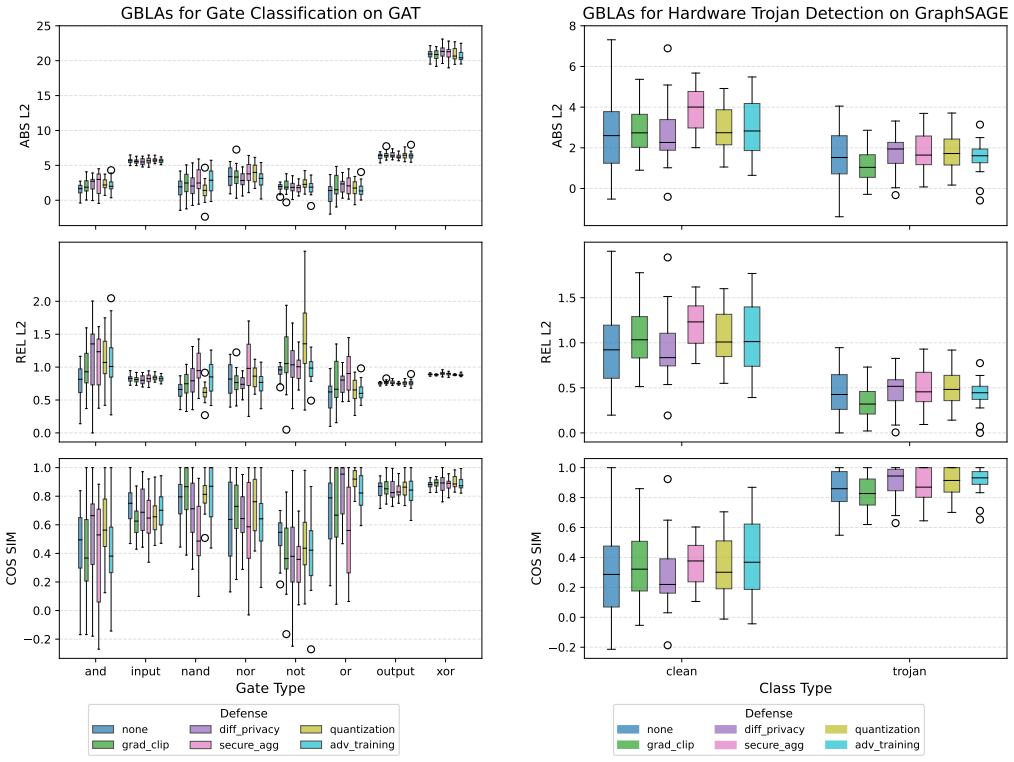
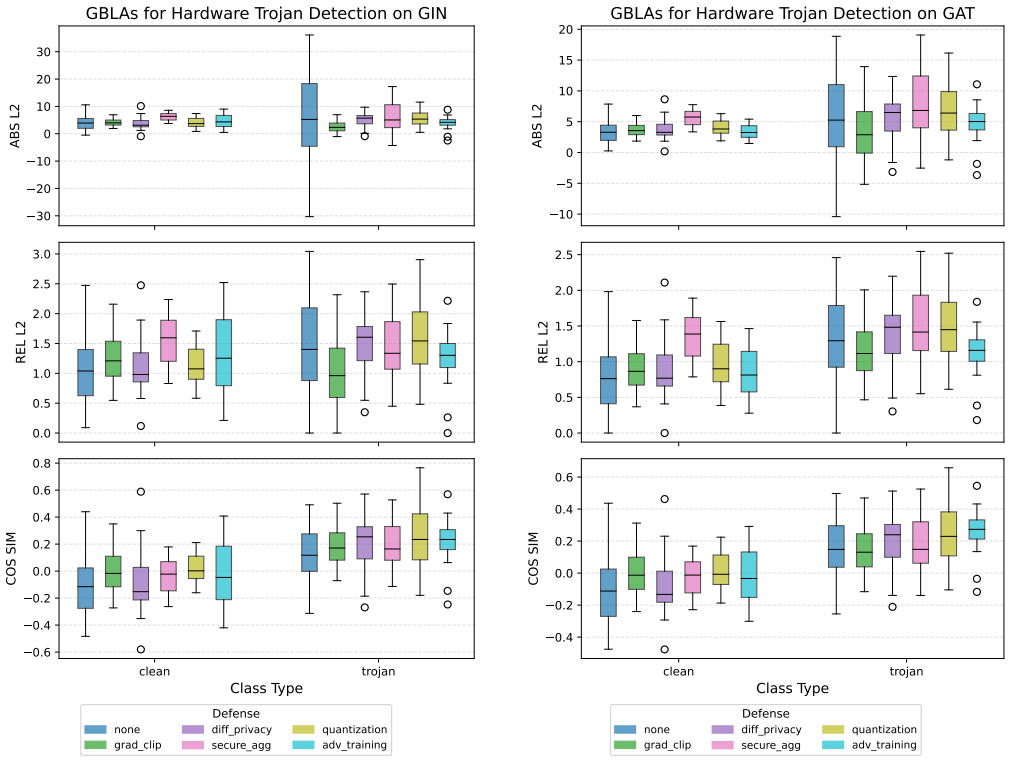
Gradient leakage attacks can expose sensitive information such as gate types and distinctive properties of hardware Trojans from GNNs trained on netlist benchmarks, which may assist adversaries in analyzing logic locking schemes or evading Trojan detection mechanisms. Risks are higher for attention-based models like GAT and lower for injective models like GIN. Standard defenses improve resilience only in specific settings and often trade off against model performance.
What carries the argument
Gradient leakage attacks that reconstruct sensitive input features from model gradients on graph representations of circuit netlists.
If this is right
- Adversaries could use recovered gate types to analyze and defeat logic locking schemes.
- Distinctive Trojan properties recovered via leakage could help evade existing Trojan detection methods.
- Attention-based GNN architectures leak more than injective aggregation architectures.
- Differential privacy, gradient clipping, and similar defenses only mitigate leakage in limited cases and can degrade task performance.
Where Pith is reading between the lines
- Circuit designers may need to select GNN architectures with privacy in mind rather than solely for accuracy.
- The leakage pattern observed here could appear in other graph-based hardware analysis tasks beyond the tested benchmarks.
- New defenses that preserve both privacy and accuracy for netlist graphs may be required beyond current general techniques.
Load-bearing premise
That the chosen state-of-the-art GNN architectures and standard netlist benchmarks adequately represent real-world circuit design and hardware-security threat models where gradient leakage would be practically exploitable.
What would settle it
An experiment showing that gradients leaked from these GNNs on realistic netlists allow no better than random reconstruction of gate types or Trojan properties would falsify the claim.
Figures
read the original abstract
As graph neural networks (GNNs) become standard tools for critical tasks in circuit design and analysis, their security and privacy risks require careful attention. Here, we present the first comprehensive evaluation of gradient leakage attacks (GLAs) on GNNs in circuit-design and hardware-security tasks, a practical threat that has been largely overlooked. We assess state-of-the-art (SOTA) GNNs, including GraphSAGE, GCN, GIN, and GAT, trained on standard netlist benchmarks (ISCAS'85, EPFL, and TrustHub), for their fundamental vulnerability to GLAs. We find that GLAs can expose sensitive information, such as gate types and distinctive properties of hardware Trojans, which may assist adversaries in analyzing logic locking schemes or evading Trojan detection mechanisms. Our analysis shows that these risks are influenced by architectural features, with attention mechanisms (GAT) exacerbating leakage, while injective aggregation (GIN) provides comparatively stronger resilience. We further evaluate several SOTA defense techniques, including differential privacy, gradient clipping, secure aggregation, model compression with quantization, and adversarial training. We find that these techniques improve resilience only in specific settings and can also compromise model performance. Overall, our work provides key insights toward privacy-preserving GNNs and highlights the need for more robust and efficient defenses. We release our full methodology and artifacts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the first comprehensive evaluation of gradient leakage attacks (GLAs) on GNNs (GraphSAGE, GCN, GIN, GAT) for circuit-design and hardware-security tasks. Trained on standard netlist benchmarks (ISCAS'85, EPFL, TrustHub), the GNNs are shown to leak sensitive information including gate types and hardware-Trojan properties via gradients, potentially aiding adversaries in logic-locking analysis or Trojan evasion. Architectural differences are reported (attention mechanisms increase leakage; injective aggregation improves resilience), and several SOTA defenses (differential privacy, gradient clipping, secure aggregation, quantization, adversarial training) are tested, with the finding that they help only in specific settings and can degrade model performance. The authors release full methodology and artifacts.
Significance. If the empirical claims hold, the work is significant for surfacing an overlooked privacy vector in GNN-based netlist analysis, an area of growing practical use. Explicit architecture comparisons and the multi-defense evaluation supply concrete guidance. The public release of methodology and artifacts is a clear strength that supports reproducibility. The overall significance is reduced by the narrow benchmark set and threat-model assumptions, which limit direct translation to contemporary industrial settings.
major comments (2)
- [§4 and §5] §4 (Experimental Setup) and §5 (Results): the central claim that GLAs expose actionable information for logic-locking or Trojan evasion rests on reconstruction fidelity observed only on the small, decades-old ISCAS'85/EPFL/TrustHub graphs; no scaling study or comparison against contemporary industrial netlists is provided, leaving open whether the reported leakage remains exploitable at realistic sizes and connectivity distributions.
- [§3] §3 (Threat Model): the implicit assumption that gradient access occurs during GNN training on proprietary netlists is not mapped to actual circuit-design workflows or access-control practices; without this mapping the security implications do not follow from the reported experiments.
minor comments (2)
- [§5] Notation for gate-type and Trojan-feature recovery metrics is introduced without an explicit equation or table reference in the main text; a single clarifying equation would improve readability.
- [§6] The abstract states that defenses 'can also compromise model performance,' but the corresponding tables do not report the magnitude of accuracy drop relative to the undefended baseline; adding these deltas would strengthen the comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point-by-point below, providing the strongest honest defense of the manuscript while acknowledging its limitations. Revisions have been made where the comments identify areas for improvement.
read point-by-point responses
-
Referee: [§4 and §5] §4 (Experimental Setup) and §5 (Results): the central claim that GLAs expose actionable information for logic-locking or Trojan evasion rests on reconstruction fidelity observed only on the small, decades-old ISCAS'85/EPFL/TrustHub graphs; no scaling study or comparison against contemporary industrial netlists is provided, leaving open whether the reported leakage remains exploitable at realistic sizes and connectivity distributions.
Authors: We agree that the evaluation is confined to the standard public benchmarks (ISCAS'85, EPFL, TrustHub) commonly used in GNN-for-circuits research, which are smaller than contemporary industrial netlists. These datasets were selected to ensure reproducibility and comparability with prior work on netlist analysis. The results demonstrate that leakage occurs on these graphs, supporting the core claim within the evaluated setting. We have added a dedicated Limitations subsection in the revised Discussion section that explicitly notes the benchmark-size constraint and the need for future studies on larger graphs with different connectivity distributions. A full scaling study could not be performed because large-scale proprietary netlists are not publicly available. revision: partial
-
Referee: [§3] §3 (Threat Model): the implicit assumption that gradient access occurs during GNN training on proprietary netlists is not mapped to actual circuit-design workflows or access-control practices; without this mapping the security implications do not follow from the reported experiments.
Authors: We have revised Section 3 to include an explicit mapping of the threat model to realistic circuit-design workflows. The updated text now describes concrete scenarios such as outsourced cloud-based GNN training for netlist classification, federated learning among design teams, and use of third-party ML services, where gradient access can occur despite typical access controls. These additions directly connect the experimental setup to practical security implications. revision: yes
- Performing scaling studies or direct comparisons on contemporary industrial netlists, which are proprietary and not publicly accessible.
Circularity Check
No circularity: purely empirical evaluation with no derivations or fitted predictions
full rationale
The paper contains no equations, derivations, parameter fitting, or self-citation chains that reduce claims to inputs by construction. All results are descriptive experimental outcomes from training SOTA GNNs on fixed benchmarks and measuring leakage, with no load-bearing steps that invoke uniqueness theorems, ansatzes, or renamed known results. The central claims rest on direct observation rather than any self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Graph convolutional networks: a comprehensive review,
S. Zhang, H. Tong, J. Xu, and R. Maciejewski, “Graph convolutional networks: a comprehensive review,”Computational Social Networks, vol. 6, no. 1, pp. 1–23, 2019
2019
-
[2]
Benchmarking backdoor attacks on graph convolution neural networks: A comprehensive analysis of poisoning techniques,
R. R. Karn and O. Sinanoglu, “Benchmarking backdoor attacks on graph convolution neural networks: A comprehensive analysis of poisoning techniques,” inInternational Conference on Security, Privacy, and Applied Cryptography Engineering. Springer, 2024, pp. 149–174
2024
-
[3]
Circuit-gnn: Graph neural networks for distributed circuit design,
G. Zhang, H. He, and D. Katabi, “Circuit-gnn: Graph neural networks for distributed circuit design,” inInternational conference on machine learning. PMLR, 2019, pp. 7364–7373
2019
-
[4]
Gnn-based hierarchical annotation for analog circuits,
K. Kunal, T. Dhar, M. Madhusudan, J. Poojary, A. K. Sharma, W. Xu, S. M. Burns, J. Hu, R. Harjani, and S. S. Sapatnekar, “Gnn-based hierarchical annotation for analog circuits,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 42, no. 9, pp. 2801–2814, 2023
2023
-
[5]
Graph of circuits with gnn for exploring the optimal design space,
A. Shahane, S. Swapna Manjiri, A. Jain, and S. Kumar, “Graph of circuits with gnn for exploring the optimal design space,”Advances in Neural Information Processing Systems, vol. 36, pp. 6014–6025, 2023
2023
-
[6]
Trustworthy graph neural networks: Aspects, methods, and trends,
H. Zhang, B. Wu, X. Yuan, S. Pan, H. Tong, and J. Pei, “Trustworthy graph neural networks: Aspects, methods, and trends,”Proceedings of the IEEE, 2024
2024
-
[7]
Poisonedgnn: Backdoor attack on graph neural networks-based hardware security systems,
L. Alrahis, S. Patnaik, M. A. Hanif, M. Shafique, and O. Sinanoglu, “Poisonedgnn: Backdoor attack on graph neural networks-based hardware security systems,”IEEE Transactions on Computers, vol. 72, no. 10, pp. 2822–2834, 2023
2023
-
[8]
Graph neural networks: a survey on the links between privacy and security,
F. Guan, T. Zhu, W. Zhou, and K.-K. R. Choo, “Graph neural networks: a survey on the links between privacy and security,”Artificial Intelligence Review, vol. 57, no. 2, p. 40, 2024
2024
-
[9]
Deep leakage from gradients,
L. Zhu, Z. Liu, and S. Han, “Deep leakage from gradients,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[10]
Gradient leakage attacks in federated learning,
H. Gong, L. Jiang, X. Liu, Y . Wang, O. Gastro, L. Wang, K. Zhang, and Z. Guo, “Gradient leakage attacks in federated learning,”Artificial Intelligence Review, vol. 56, no. Suppl 1, pp. 1337–1374, 2023
2023
-
[11]
Dropout is not all you need to prevent gradient leakage,
D. Scheliga, P. M ¨ader, and M. Seeland, “Dropout is not all you need to prevent gradient leakage,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 8, 2023, pp. 9733–9741
2023
-
[12]
Privacy leakage on dnns: A survey of model inversion attacks and defenses,
H. Fang, Y . Qiu, H. Yu, W. Yu, J. Kong, B. Chong, B. Chen, X. Wang, S.-T. Xia, and K. Xu, “Privacy leakage on dnns: A survey of model inversion attacks and defenses,”arXiv preprint arXiv:2402.04013, 2024
-
[13]
Graphsage-based multi-path reliable routing algorithm for wireless mesh networks,
P. Lu, C. Jing, and X. Zhu, “Graphsage-based multi-path reliable routing algorithm for wireless mesh networks,”Processes, vol. 11, no. 4, p. 1255, 2023
2023
-
[14]
Omla: An oracle- less machine learning-based attack on logic locking,
L. Alrahis, S. Patnaik, M. Shafique, and O. Sinanoglu, “Omla: An oracle- less machine learning-based attack on logic locking,”IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 69, no. 3, pp. 1602–1606, 2021
2021
-
[15]
Parsing netlists of integrated circuits from images via graph attention network,
W. Hu, X. Zhan, and M. Tong, “Parsing netlists of integrated circuits from images via graph attention network,”Sensors, vol. 24, no. 1, p. 227, 2023
2023
-
[16]
Trojansaint: Gate-level netlist sampling-based inductive learning for hardware trojan detection,
H. Lashen, L. Alrahis, J. Knechtel, and O. Sinanoglu, “Trojansaint: Gate-level netlist sampling-based inductive learning for hardware trojan detection,” in2023 IEEE International Symposium on Circuits and Systems (ISCAS), 2023
2023
-
[17]
Defense against adversarial attacks via controlling gradient leaking on embedded manifolds,
Y . Li, S. Cheng, H. Su, and J. Zhu, “Defense against adversarial attacks via controlling gradient leaking on embedded manifolds,” inEuropean Conference on Computer Vision. Springer, 2020, pp. 753–769
2020
-
[18]
Gradient leakage attack resilient deep learning,
W. Wei and L. Liu, “Gradient leakage attack resilient deep learning,” IEEE Transactions on Information Forensics and Security, vol. 17, pp. 303–316, 2021
2021
-
[19]
Breaking secure aggregation: Label leakage from aggregated gradients in federated learning,
Z. Wang, Z. Chang, J. Hu, X. Pang, J. Du, Y . Chen, and K. Ren, “Breaking secure aggregation: Label leakage from aggregated gradients in federated learning,” inIEEE INFOCOM 2024-IEEE Conference on Computer Communications. IEEE, 2024, pp. 151–160
2024
-
[20]
Model compression hardens deep neural networks: A new perspective to prevent adversarial attacks,
Q. Liu and W. Wen, “Model compression hardens deep neural networks: A new perspective to prevent adversarial attacks,”IEEE Transactions on Neural Networks and Learning Systems, vol. 34, no. 1, pp. 3–14, 2021
2021
-
[21]
Deep models under the gan: information leakage from collaborative deep learning,
B. Hitaj, G. Ateniese, and F. Perez-Cruz, “Deep models under the gan: information leakage from collaborative deep learning,” inProceedings of the 2017 ACM SIGSAC conference on computer and communications security, 2017, pp. 603–618
2017
-
[22]
Inverting gradients-how easy is it to break privacy in federated learning?
J. Geiping, H. Bauermeister, H. Dr ¨oge, and M. Moeller, “Inverting gradients-how easy is it to break privacy in federated learning?”Advances in neural information processing systems, vol. 33, pp. 16 937–16 947, 2020
2020
-
[23]
Exploiting unintended feature leakage in collaborative learning,
L. Melis, C. Song, E. De Cristofaro, and V . Shmatikov, “Exploiting unintended feature leakage in collaborative learning,” in2019 IEEE symposium on security and privacy (SP). IEEE, 2019, pp. 691–706
2019
-
[24]
A survey on gradient inversion: Attacks, defenses and future directions,
R. Zhang, S. Guo, J. Wang, X. Xie, and D. Tao, “A survey on gradient inversion: Attacks, defenses and future directions,”arXiv preprint arXiv:2206.07284, 2022
-
[25]
Gradient inver- sion attack on graph neural networks,
D. A. Sinha, R. Du, Y . Liu, A. Markopolou, and Y . Shen, “Gradient inver- sion attack on graph neural networks,”arXiv preprint arXiv:2411.19440, 2024
-
[26]
Everything is connected: Graph neural networks,
P. Veliˇckovi´c, “Everything is connected: Graph neural networks,”Current Opinion in Structural Biology, vol. 79, p. 102538, 2023
2023
-
[27]
Mathematical expres- siveness of graph neural networks,
G. Lachaud, P. Conde-Cespedes, and M. Trocan, “Mathematical expres- siveness of graph neural networks,”Mathematics, vol. 10, no. 24, p. 4770, 2022
2022
-
[28]
Vision gnn: An image is worth graph of nodes,
K. Han, Y . Wang, J. Guo, Y . Tang, and E. Wu, “Vision gnn: An image is worth graph of nodes,”Advances in neural information processing systems, vol. 35, pp. 8291–8303, 2022
2022
-
[29]
Graph neural network via edge convolution for hyperspectral image classification,
H. Hu, M. Yao, F. He, and F. Zhang, “Graph neural network via edge convolution for hyperspectral image classification,”IEEE Geoscience and Remote Sensing Letters, vol. 19, pp. 1–5, 2021
2021
-
[30]
Graphs, convolutions, and neural networks: From graph filters to graph neural networks,
F. Gama, E. Isufi, G. Leus, and A. Ribeiro, “Graphs, convolutions, and neural networks: From graph filters to graph neural networks,”IEEE Signal Processing Magazine, vol. 37, no. 6, pp. 128–138, 2020
2020
-
[31]
Membership inference attacks on machine learning: A survey,
H. Hu, Z. Salcic, L. Sun, G. Dobbie, P. S. Yu, and X. Zhang, “Membership inference attacks on machine learning: A survey,”ACM Computing Surveys (CSUR), vol. 54, no. 11s, pp. 1–37, 2022
2022
-
[32]
Advances in logic locking: Past, present, and prospects,
H. M. Kamali, K. Z. Azar, F. Farahmandi, and M. Tehranipoor, “Advances in logic locking: Past, present, and prospects,”Cryptology ePrint Archive, 2022
2022
-
[33]
A survey of the implementations of model inversion attacks,
J. Song and D. Namiot, “A survey of the implementations of model inversion attacks,” inInternational Conference on Distributed Computer and Communication Networks. Springer, 2022, pp. 3–16
2022
-
[34]
An automated framework for board-level trojan benchmarking,
A. Bhattacharyay, S. Yang, J. Cruz, P. Chakraborty, S. Bhunia, and T. Hoque, “An automated framework for board-level trojan benchmarking,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 42, no. 2, pp. 397–410, 2022
2022
-
[35]
The state-of-the-art in ic reverse engineering,
R. Torrance and D. James, “The state-of-the-art in ic reverse engineering,” inInternational Workshop on Cryptographic Hardware and Embedded Systems. Springer, 2009, pp. 363–381
2009
-
[36]
Netlist reverse engineering for high- level functionality reconstruction,
T. Meade, S. Zhang, and Y . Jin, “Netlist reverse engineering for high- level functionality reconstruction,” in2016 21st Asia and South Pacific Design Automation Conference (ASP-DAC). IEEE, 2016, pp. 655–660
2016
-
[37]
Adaptivenet: Post-deployment neural architecture adaptation for diverse edge environments,
H. Wen, Y . Li, Z. Zhang, S. Jiang, X. Ye, Y . Ouyang, Y . Zhang, and Y . Liu, “Adaptivenet: Post-deployment neural architecture adaptation for diverse edge environments,” inProceedings of the 29th Annual International Conference on Mobile Computing and Networking, 2023, pp. 1–17
2023
-
[38]
Side channel attacks for architecture extraction of neural networks,
H. Chabanne, J.-L. Danger, L. Guiga, and U. K¨uhne, “Side channel attacks for architecture extraction of neural networks,”CAAI Transactions on Intelligence Technology, vol. 6, no. 1, pp. 3–16, 2021
2021
-
[39]
Deep learning with differential privacy,
M. Abadi, A. Chu, I. Goodfellow, H. B. McMahan, I. Mironov, K. Talwar, and L. Zhang, “Deep learning with differential privacy,” inProceedings of the 2016 ACM SIGSAC conference on computer and communications security, 2016, pp. 308–318
2016
-
[40]
Deep Graph Library: A Graph-Centric, Highly-Performant Package for Graph Neural Networks
M. Wang, D. Zheng, Z. Ye, Q. Gan, M. Li, X. Song, J. Zhou, C. Ma, L. Yu, Y . Gaiet al., “Deep graph library: A graph-centric, highly-performant package for graph neural networks,”arXiv preprint arXiv:1909.01315, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[41]
A survey of handwritten character recognition with mnist and emnist,
A. Baldominos, Y . Saez, and P. Isasi, “A survey of handwritten character recognition with mnist and emnist,”Applied Sciences, vol. 9, no. 15, p. 3169, 2019
2019
-
[42]
Unveiling the iscas-85 benchmarks: A case study in reverse engineering,
M. C. Hansen, H. Yalcin, and J. P. Hayes, “Unveiling the iscas-85 benchmarks: A case study in reverse engineering,”IEEE Design & Test of Computers, vol. 16, no. 3, pp. 72–80, 1999
1999
-
[43]
The epfl combinational benchmark suite,
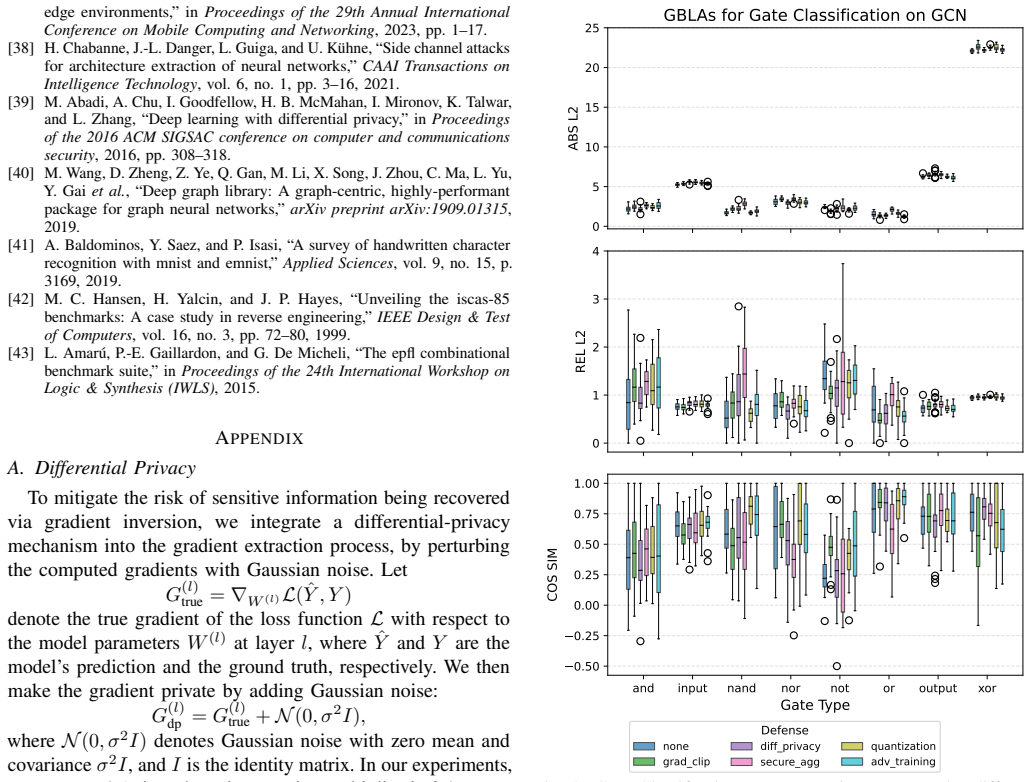
L. Amar ´u, P.-E. Gaillardon, and G. De Micheli, “The epfl combinational benchmark suite,” inProceedings of the 24th International Workshop on Logic & Synthesis (IWLS), 2015. APPENDIX A. Differential Privacy To mitigate the risk of sensitive information being recovered via gradient inversion, we integrate a differential-privacy mechanism into the gradient...
2015
-
[44]
This transformation limits the granularity of feature updates, reducing inversion fidelity
Quantization:During the forward pass of the GCNN, numerical outputs are quantized using: Xquant = round(X·Q) Q , where Q= 255 simulates 8-bit fixed-point representation. This transformation limits the granularity of feature updates, reducing inversion fidelity
-
[45]
This process eliminates weak connections in the NN, making gradient inversion less effective
Compression via Pruning:After backpropagation, small- magnitude model weights are set to zero: W (l) compressed = ( 0,if|W (l)|< τ W (l),otherwise where τ= 0.01 is the pruning threshold. This process eliminates weak connections in the NN, making gradient inversion less effective. 0 5 10 15 20 25ABS L2 GBLAs for Gate Classification on GAT 0.0 0.5 1.0 1.5 2...
-
[46]
Generating Adversarial Perturbations:To generate ad- versarial examples, we use the Fast Gradient Sign Method (FGSM), where the perturbation applied to the feature matrix Xis computed as: Xadv =X+ϵ·sign(∇ X L(X, Y)), where ϵ is the perturbation strength (set to 0.1 in our experi- ments), L(X, Y) is the loss function, and ∇X L represents the gradient of th...
-
[47]
This forces the model to optimize for robustness rather than merely fitting the clean training data
Adversarial Training Procedure:During training, instead of using the original features, we compute adversarial pertur- bations and feed the model with Xadv, reinforcing its ability to generalize across perturbed data: min W NX i=1 L(fW (Xadv,i), Yi). This forces the model to optimize for robustness rather than merely fitting the clean training data. 0 2 4...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.