Re-mixing Embeddings for Patient Augmentation in Data Scarce Multiple Instance Learning
Pith reviewed 2026-06-25 20:23 UTC · model grok-4.3
The pith
Re-mixing embeddings clustered by GMM generates synthetic patients that recover full-dataset MIL performance when an entire class is missing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
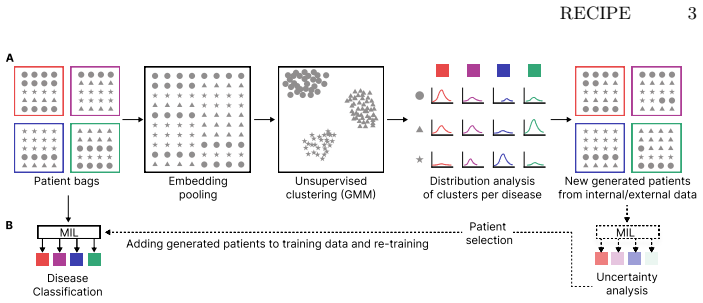
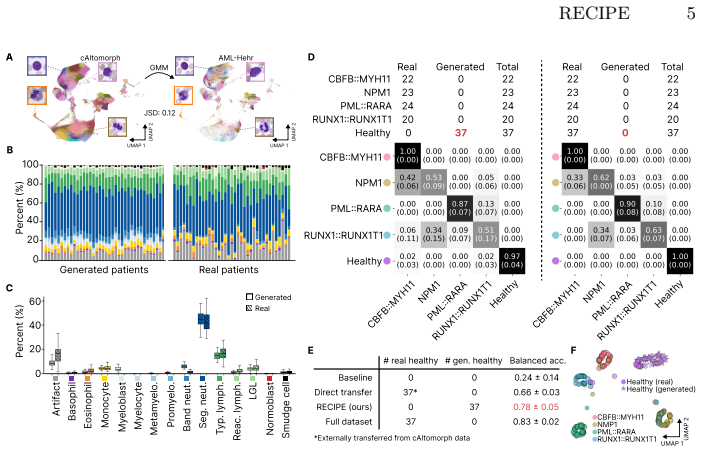
By fitting GMMs to pooled instance embeddings and extracting per-class mixing proportions across the discovered clusters, the method produces new patient bags whose instance composition matches the statistical structure of real patients. In the missing-class setting these generated bags allow an MIL classifier to reach accuracy comparable to training on the complete original dataset.
What carries the argument
Disease-specific recipes: the learned proportions of embeddings drawn from each GMM cluster that characterize a given patient class, used to remix pooled embeddings into new bags.
If this is right
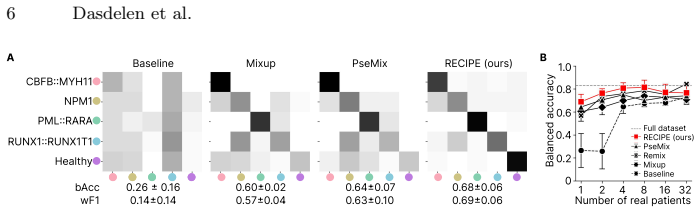
- In the missing-class scenario the generated healthy patients let the MIL model reach performance comparable to full-dataset training.
- The same recipe-based generation improves accuracy in low-sample regimes and on small-cohort non-image tasks such as single-cell RNA-seq.
- Generated bags can be produced offline without requiring examples from every class in the target dataset.
- Uncertainty-based selection of the synthetic bags further boosts downstream MIL performance over unfiltered mixing baselines.
Where Pith is reading between the lines
- The approach could allow diagnostic models for rare diseases to be trained without collecting large numbers of real cases from every category.
- Because generation occurs entirely in embedding space after a single forward pass, the method supports privacy-preserving augmentation without moving raw patient data.
- The recipe construction might be applied to other embedding-based tasks that operate on bags or sets rather than single instances.
Load-bearing premise
The GMM clusters found on pooled embeddings contain stable, transferable disease-specific distributions that can be recombined to form realistic new patient bags.
What would settle it
Train an MIL model on bags generated for the missing healthy class and measure whether its accuracy on a held-out set of real patients falls significantly below the accuracy obtained when the real healthy class is present.
Figures
read the original abstract
Data scarcity is a major bottleneck in medical Multiple Instance Learning (MIL), especially for rare diseases or expensive modalities. We introduce a statistically grounded patient augmentation approach that generates realistic patients directly in embedding space. Using Gaussian Mixture Models as a probabilistic clustering approach on pooled instance embeddings from all patients, our method learns disease-specific "recipes"-statistical distributions of instances across unsupervised clusters. New patients are then generated by sampling embeddings from clusters based on learned recipes. Unlike existing methods that require examples from all categories, our method can generate patients offline by re-mixing pooled embeddings. Generated patients are further selected based on uncertainty quantification to improve MIL performance. We evaluate our method across three clinically relevant scarcity scenarios: (i) cross-dataset transfer, where an entirely missing "healthy" class is generated using statistics from an external cohort; (ii) low-data regimes, where class sizes are extremely limited; and (iii) small-cohort non-image tasks, including single-cell RNA-seq and flow cytometry. Across all experiments, our method improves performance over baseline, often outperforming other bag-mixing strategies. Notably, in the missing-class scenario, a performance comparable to full-dataset training is achieved, demonstrating its potential for rare disease diagnostic and privacy-preserving patient augmentation. The code is available at https://github.com/marrlab/RECIPE
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RECIPE, a patient augmentation method for data-scarce multiple instance learning that learns disease-specific 'recipes' as GMM cluster distributions over pooled instance embeddings and generates new bags by remixing sampled embeddings according to those distributions. It targets three scarcity settings, with the central claim being that in the missing-class (cross-dataset) scenario an entirely absent healthy class can be synthesized from an external cohort's embeddings using target-cohort recipes, yielding MIL performance comparable to training on the full original dataset. The method also includes uncertainty-based selection of generated bags and is evaluated on imaging and non-imaging tasks with code released.
Significance. If the transferability assumption holds, the approach offers a practical route to rare-disease MIL and privacy-preserving augmentation without requiring real examples from every class. Releasing code and testing across three distinct scarcity regimes are concrete strengths that would support adoption if the empirical claims are robustly supported.
major comments (2)
- [Abstract] Abstract (missing-class scenario): the claim that performance comparable to full-dataset training is achieved by generating the missing healthy class from an external cohort rests on the unstated assumption that GMM-derived cluster membership distributions learned on the target (diseased) embeddings remain valid when applied to embeddings from a separate healthy cohort. No joint embedding training, domain-adaptation step, or cohort-matching procedure is described, so the generated bags may exhibit instance statistics that do not match real healthy patients.
- [Abstract] Abstract (cross-dataset transfer): because the embedding extractor is presumably fit only on the available diseased data, external healthy embeddings occupy a shifted region of the space; remixing then produces bags whose cluster occupancy statistics are unlikely to reflect the true healthy distribution. An ablation that measures the effect of this shift (e.g., via MMD between real and generated healthy bags or via a domain-adversarial baseline) is required to substantiate the central performance claim.
minor comments (2)
- The abstract states that generated patients are 'further selected based on uncertainty quantification' but provides no detail on the uncertainty estimator or the selection threshold; this should be clarified with a precise description or equation.
- The GitHub link is given; confirm that the released code reproduces the exact missing-class experiment (including embedding extraction and GMM fitting) so that the domain-shift concern can be directly tested by reviewers.
Simulated Author's Rebuttal
We thank the referee for the insightful comments on the assumptions underlying the cross-dataset transfer in the missing-class scenario. We clarify our approach and agree to strengthen the manuscript with additional quantitative analyses of distribution shifts.
read point-by-point responses
-
Referee: [Abstract] Abstract (missing-class scenario): the claim that performance comparable to full-dataset training is achieved by generating the missing healthy class from an external cohort rests on the unstated assumption that GMM-derived cluster membership distributions learned on the target (diseased) embeddings remain valid when applied to embeddings from a separate healthy cohort. No joint embedding training, domain-adaptation step, or cohort-matching procedure is described, so the generated bags may exhibit instance statistics that do not match real healthy patients.
Authors: We acknowledge the assumption that cluster distributions learned from the target cohort's embeddings can be applied to remix embeddings from an external healthy cohort. The method intentionally avoids joint training or adaptation to enable use of external data without access to target healthy examples. Our experiments demonstrate that this yields performance comparable to full-dataset training, indicating practical transferability of the learned recipes. To address the concern directly, we will add a quantitative comparison of instance statistics (including MMD) between generated and real healthy bags in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract (cross-dataset transfer): because the embedding extractor is presumably fit only on the available diseased data, external healthy embeddings occupy a shifted region of the space; remixing then produces bags whose cluster occupancy statistics are unlikely to reflect the true healthy distribution. An ablation that measures the effect of this shift (e.g., via MMD between real and generated healthy bags or via a domain-adversarial baseline) is required to substantiate the central performance claim.
Authors: We agree that the embedding extractor trained on diseased data may induce a shift for external healthy embeddings. The central empirical claim is supported by consistent performance improvements across datasets, but we recognize the value of explicit shift quantification. In revision we will include an MMD analysis between real and generated healthy bags to measure the effect. A domain-adversarial baseline is outside the current scope as the method is designed for direct use of external cohorts without adaptation; the MMD results will substantiate the claim. revision: yes
Circularity Check
No circularity: generative augmentation method evaluated empirically
full rationale
The paper presents a GMM-based procedure to learn cluster 'recipes' from pooled embeddings and remix them to generate augmented patients for MIL under data scarcity. This is a statistical generative algorithm whose outputs are assessed via downstream classifier performance on held-out data across three scenarios. No equations or steps reduce by construction to fitted inputs renamed as predictions, no self-definitional loops, and no load-bearing self-citations or imported uniqueness theorems. The central claim (comparable performance via external-cohort remix) rests on empirical results rather than any internal derivation that collapses to its own inputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of GMM components
- uncertainty selection threshold
axioms (1)
- domain assumption Instance embeddings from different patients can be pooled and clustered with GMM to recover disease-specific distributions.
Reference graph
Works this paper leans on
-
[1]
Dasdelen, M.F., Kukuljan, I., Lienemann, P., Ozlugedik, F., Sadafi, A., Hehr, M., Spiekermann, K., Pohlkamp, C., Marr, C.: AI-based hematological malignancy prediction from peripheral blood smears in a large diagnostic laboratory cohort. Leukemia pp. 1–5 (2026). https://doi.org/10.1038/s41375-026-02934-1
-
[2]
Scientific Reports (2026)
Ding,Z.,Baras,A.:Applicationandcharacterizationofthemultipleinstancelearn- ing framework in flow cytometry. Scientific Reports (2026). https://doi.org/10. 1038/s41598-025-32093-9
2026
-
[3]
In: International conference on machine learning
Gal, Y., Islam, R., Ghahramani, Z.: Deep bayesian active learning with image data. In: International conference on machine learning. pp. 1183–1192. PMLR (2017)
2017
-
[4]
PLOS Digital Health2(3), e0000187 (2023)
Hehr, M., Sadafi, A., Matek, C., Lienemann, P., Pohlkamp, C., Haferlach, T., Spiekermann, K., Marr, C.: Explainable ai identifies diagnostic cells of genetic aml subtypes. PLOS Digital Health2(3), e0000187 (2023). https://doi.org/10.1371/ journal.pdig.0000187
2023
-
[5]
arXiv preprint arXiv:1112.5745 (2011)
Houlsby, N., Huszár, F., Ghahramani, Z., Lengyel, M.: Bayesian active learning for classification and preference learning. arXiv preprint arXiv:1112.5745 (2011)
Pith/arXiv arXiv 2011
-
[6]
In: Dy, J., Krause, A
Ilse,M.,Tomczak,J.,Welling,M.:Attention-baseddeepmultipleinstancelearning. In: Dy, J., Krause, A. (eds.) Proceedings of the 35th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 80, pp. 2127–
-
[7]
PMLR (10–15 Jul 2018), https://proceedings.mlr.press/v80/ilse18a.html
2018
-
[8]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Koch, V., Wagner, S.J., Kazeminia, S., Sancar, E., Hehr, M., Schnabel, J.A., Peng, T., Marr, C.: Dinobloom: a foundation model for generalizable cell embeddings in hematology. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 520–530. Springer (2024). https://doi.org/ 10.1007/978-3-031-72390-2_49 10 Dasdelen et al
-
[9]
In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, B., Li, Y., Eliceiri, K.W.: Dual-stream multiple instance learning network for whole slide image classification with self-supervised contrastive learning. In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14318–14328 (2021)
2021
-
[10]
Nature communica- tions13(1), 7255 (2022)
Liechti, T., Iftikhar, Y., Mangino, M., Beddall, M., Goss, C.W., O’Halloran, J.A., Mudd, P.A., Roederer, M.: Immune phenotypes that are associated with subse- quent covid-19 severity inferred from post-recovery samples. Nature communica- tions13(1), 7255 (2022). https://doi.org/10.1038/s41467-022-34638-2
-
[11]
Litinetskaya, A., Shulman, M., Hediyeh-zadeh, S., Moinfar, A.A., Curion, F., Sza- łata, A., Omidi, A., Lotfollahi, M., Theis, F.J.: Multimodal weakly supervised learning to identify disease-specific changes in single-cell atlases. bioRxiv pp. 2024– 07 (2024). https://doi.org/10.1101/2024.07.29.605625
-
[12]
IEEE Transactions on Med- ical Imaging43(5), 1841–1852 (2024)
Liu, P., Ji, L., Zhang, X., Ye, F.: Pseudo-bag mixup augmentation for multiple in- stance learning-based whole slide image classification. IEEE Transactions on Med- ical Imaging43(5), 1841–1852 (2024). https://doi.org/10.1109/TMI.2024.3351213
-
[13]
Nature methods15(12), 1053–1058 (2018)
Lopez,R.,Regier,J.,Cole,M.B.,Jordan,M.I.,Yosef,N.:Deepgenerativemodeling for single-cell transcriptomics. Nature methods15(12), 1053–1058 (2018). https: //doi.org/10.1038/s41592-018-0229-2
-
[14]
Nature biomedical engineering5(6), 555–570 (2021)
Lu, M.Y., Williamson, D.F., Chen, T.Y., Chen, R.J., Barbieri, M., Mahmood, F.: Data-efficient and weakly supervised computational pathology on whole-slide images. Nature biomedical engineering5(6), 555–570 (2021). https://doi.org/10. 1038/s41551-020-00682-w
2021
-
[15]
Mumuni, A., Mumuni, F.: Data augmentation: A comprehensive survey of modern approaches. Array16, 100258 (2022). https://doi.org/10.1016/j.array.2022.100258
-
[16]
A mathematical theory of communication,
Shannon, C.E.: A mathematical theory of communication. The Bell system tech- nical journal27(3), 379–423 (1948). https://doi.org/10.1002/j.1538-7305.1948. tb01338.x
-
[17]
In: Seventh International Conference on Document Analysis and Recognition, 2003
Simard, P., Steinkraus, D., Platt, J.: Best practices for convolutional neural net- works applied to visual document analysis. In: Seventh International Conference on Document Analysis and Recognition, 2003. Proceedings. pp. 958–963 (2003). https://doi.org/10.1109/ICDAR.2003.1227801
-
[18]
Na- ture Reviews Bioengineering1(12), 930–949 (Dec 2023)
Song, A.H., Jaume, G., Williamson, D.F.K., Lu, M.Y., Vaidya, A., Miller, T.R., Mahmood, F.: Artificial intelligence for digital and computational pathology. Na- ture Reviews Bioengineering1(12), 930–949 (Dec 2023). https://doi.org/10.1038/ s44222-023-00096-8
2023
-
[19]
Nature medicine 27(5), 904–916 (2021)
Stephenson, E., Reynolds, G., Botting, R.A., Calero-Nieto, F.J., Morgan, M.D., Tuong, Z.K., Bach, K., Sungnak, W., Worlock, K.B., Yoshida, M., et al.: Single- cell multi-omics analysis of the immune response in covid-19. Nature medicine 27(5), 904–916 (2021). https://doi.org/10.1038/s41591-021-01329-2
-
[20]
Information Science and Statistics, Springer, New York, NY, 2 edn
Vapnik, V.N.: The Nature of Statistical Learning Theory. Information Science and Statistics, Springer, New York, NY, 2 edn. (2000)
2000
-
[21]
Cancer cell41(9), 1650–1661 (2023)
Wagner, S.J., Reisenbüchler, D., West, N.P., Niehues, J.M., Zhu, J., Foersch, S., Veldhuizen, G.P., Quirke, P., Grabsch, H.I., van den Brandt, P.A., et al.: Transformer-based biomarker prediction from colorectal cancer histology: A large- scale multicentric study. Cancer cell41(9), 1650–1661 (2023). https://doi.org/10. 1016/j.ccell.2023.08.002
2023
-
[22]
https://doi.org/10.1007/978-3-031-16434-7_4 RECIPE 11
Yang, J., Chen, H., Zhao, Y., Yang, F., Zhang, Y., He, L., Yao, J.: Remix: A general and efficient framework for multiple instance learning based whole slide image classification (2022). https://doi.org/10.1007/978-3-031-16434-7_4 RECIPE 11
-
[23]
CoRRabs/1611.03530(2016), http: //arxiv.org/abs/1611.03530
Zhang, C., Bengio, S., Hardt, M., Recht, B., Vinyals, O.: Understanding deep learning requires rethinking generalization. CoRRabs/1611.03530(2016), http: //arxiv.org/abs/1611.03530
Pith/arXiv arXiv 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.