Taxonomy-aware deep learning for hierarchical marine species classification in underwater imagery
Pith reviewed 2026-06-25 19:53 UTC · model grok-4.3
The pith
A taxonomy-aware deep learning framework aligns loss and inference with biological hierarchy to classify marine species in underwater images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
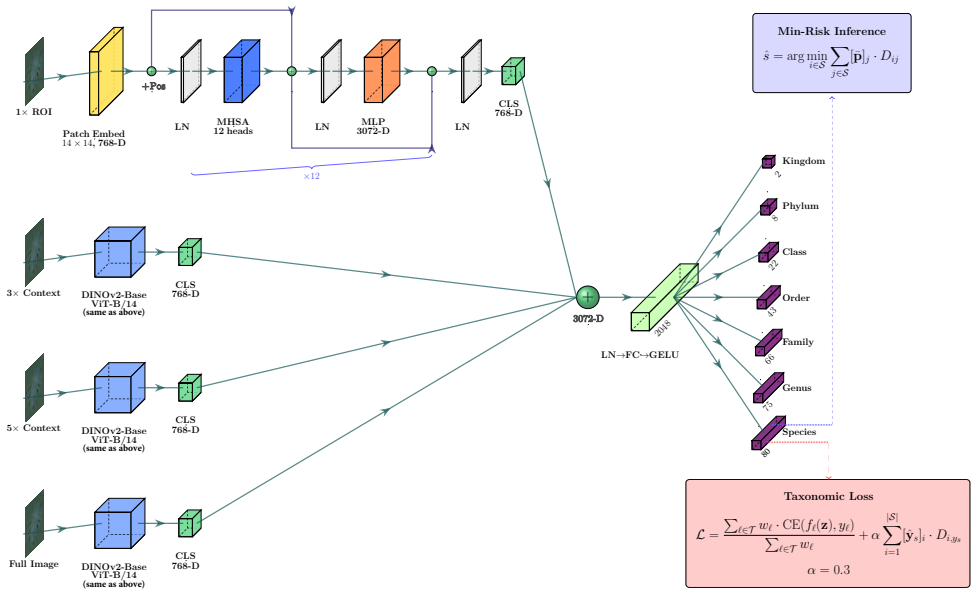
The taxonomy-aware deep learning framework aligns both the training loss and the inference rule with the hierarchical structure of biological classification by combining a taxonomy-weighted loss, minimum-risk Bayesian inference, multi-scale feature encoding, and independent per-rank classification heads. On the FathomNet 2025 dataset of 79 marine classes across seven taxonomic ranks, this yields a mean taxonomic distance of 1.581, within 3 percent of the first-place result of 1.535, with the primary gains arising from the metric-aligned inference and the generalization advantages of simple decoupled components under distribution shift across collection platforms.
What carries the argument
The taxonomy-aware framework that aligns training loss and inference rule with the hierarchical structure of biological classification via taxonomy-weighted loss and minimum-risk Bayesian inference.
If this is right
- The system can handle specimens identified only to genus or coarser ranks due to the hierarchical alignment in loss and inference.
- Decoupled per-rank heads and simple components provide better robustness to distribution shift than models with learned cross-rank dependencies.
- Metric-aligned inference delivers the largest performance gains on the evaluated dataset.
- The approach supports scalable biodiversity monitoring by reducing errors that violate taxonomic consistency.
Where Pith is reading between the lines
- The same alignment strategy could transfer to other image classification tasks that use hierarchical labels, such as plant identification or medical imaging categories.
- Emphasis on independent heads suggests that joint modeling of all ranks may introduce unnecessary complexity in hierarchical settings.
- If taxonomic distance correlates with ecological impact, the metric could guide model tuning toward conservation priorities.
- The framework might extend to video sequences for tracking species over time in dynamic ocean environments.
Load-bearing premise
The FathomNet 2025 dataset and its reported domain shifts across collection platforms sufficiently represent broader underwater imagery settings for the claimed generalization benefits of the taxonomy-aligned components.
What would settle it
Testing the same framework on a new underwater imagery dataset from previously unseen collection platforms and checking whether the mean taxonomic distance remains within 3 percent of the top reported method on that data.
Figures


read the original abstract
Automated classification of marine species from underwater imagery is essential for scalable ocean biodiversity monitoring and conservation policy. Existing approaches struggle with severe domain shift across collection platforms, fine-grained visual similarity between closely related species, and uneven annotation granularity, where many specimens can only be identified to genus or a coarser taxonomic rank. We present a taxonomy-aware deep learning framework that aligns both the training loss and the inference rule with the hierarchical structure of biological classification, combining a taxonomy-weighted loss, minimum-risk Bayesian inference, multi-scale feature encoding, and independent per-rank classification heads. Evaluated on the FathomNet 2025 dataset1 (79 marine classes across seven taxonomic ranks), the system achieves a mean taxonomic distance of 1.581, within 3% of the 1st-place solution (1.535), with the largest gains from metric-aligned inference and simple, decoupled components that generalize better than learned dependencies under distribution shift.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a taxonomy-aware deep learning framework for hierarchical marine species classification from underwater imagery. It combines a taxonomy-weighted loss, minimum-risk Bayesian inference, multi-scale feature encoding, and independent per-rank classification heads. Evaluated on the FathomNet 2025 dataset (79 classes across seven taxonomic ranks), the approach reports a mean taxonomic distance of 1.581 (within 3% of the top entry at 1.535) and attributes the largest gains to metric-aligned inference together with simple decoupled components that generalize better than learned dependencies under distribution shift.
Significance. If the attribution of gains and the generalization benefit were substantiated, the work would offer a practical, biologically aligned method for robust classification under platform-induced domain shift, with direct relevance to ocean biodiversity monitoring. The use of a public dataset and proximity to leaderboard performance are positive indicators of applicability, though the absence of supporting experiments limits the assessed impact.
major comments (2)
- [Abstract] Abstract: the claim that 'the largest gains from metric-aligned inference and simple, decoupled components that generalize better than learned dependencies under distribution shift' lacks any supporting ablation studies, baseline comparisons, error bars, or quantification of domain-shift effects, rendering the attribution of the 1.581 score to specific components unsubstantiated.
- [Evaluation] Evaluation (implied by reported results): no details are supplied on how the mean taxonomic distance was computed, how domain shifts across collection platforms were measured or isolated, or whether cross-dataset or held-out shift experiments were performed, so the generalization advantage over learned-dependency methods cannot be verified from the single reported number alone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger empirical support and clearer evaluation details. We agree that the current manuscript does not sufficiently substantiate the claims regarding component contributions or provide the requested methodological clarifications, and we will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'the largest gains from metric-aligned inference and simple, decoupled components that generalize better than learned dependencies under distribution shift' lacks any supporting ablation studies, baseline comparisons, error bars, or quantification of domain-shift effects, rendering the attribution of the 1.581 score to specific components unsubstantiated.
Authors: We agree that the submitted manuscript provides no ablation studies, baseline comparisons, error bars, or domain-shift quantification to support the attribution of gains stated in the abstract. The claim reflects our internal analysis but is not empirically demonstrated in the text. In revision we will either remove the unsubstantiated phrasing or add the necessary ablation experiments and quantitative comparisons. revision: yes
-
Referee: [Evaluation] Evaluation (implied by reported results): no details are supplied on how the mean taxonomic distance was computed, how domain shifts across collection platforms were measured or isolated, or whether cross-dataset or held-out shift experiments were performed, so the generalization advantage over learned-dependency methods cannot be verified from the single reported number alone.
Authors: We agree that the manuscript omits the exact computation of mean taxonomic distance, any measurement or isolation of platform-induced domain shifts, and any cross-dataset or held-out shift experiments. The revision will add the precise formula for the metric, a description of how the FathomNet 2025 dataset encodes platform variation, and either the relevant experiments or an explicit statement of their absence and resulting limitations on the generalization claim. revision: yes
Circularity Check
No circularity; empirical benchmark on public dataset
full rationale
The paper reports an empirical evaluation of a taxonomy-aware framework (taxonomy-weighted loss, minimum-risk Bayesian inference, multi-scale encoding, per-rank heads) on the named FathomNet 2025 dataset. All performance numbers (mean taxonomic distance 1.581) are direct measurements against an external leaderboard and public data splits. No equations, parameters, or claims reduce to self-definition, fitted inputs renamed as predictions, or self-citation chains. The generalization statement is an interpretation of the reported numbers rather than a mathematical derivation that collapses to its inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
FathomNet2025,
L. Chrobak and K. Barnard, “FathomNet2025,” 2025. [Online]. Available:https://kaggle.com/ competitions/fathomnet-2025
2025
-
[2]
FathomNet: A global image database for enabling artificial intelligence in the ocean,
K. Katija, E. Orenstein, B. Schlining, L. Lundsten, K. Barnard, G. Sainz, et al., “FathomNet: A global image database for enabling artificial intelligence in the ocean,”Scientific Reports, vol. 12, no. 15914, 2022
2022
-
[3]
DINOv2: Learning robust visual features without supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. Vo, M. Szafraniec, V. Khalidov, et al., “DINOv2: Learning robust visual features without supervision,”Trans. Machine Learning Research, 2024
2024
-
[4]
Universal language model fine-tuning for text classification,
J. Howard and S. Ruder, “Universal language model fine-tuning for text classification,” inProc. ACL, 2018, pp. 328–339
2018
-
[5]
ConvNeXt V2: Co-designing and scaling ConvNets with masked autoencoders,
S. Woo, S. Debnath, R. Hu, X. Chen, Z. Liu, I. S. Kweon, and S. Xie, “ConvNeXt V2: Co-designing and scaling ConvNets with masked autoencoders,” inProc. IEEE/CVF CVPR, 2023, pp. 16133–16142
2023
-
[6]
Making better mistakes: Leveraging class hierarchies with deep networks,
L. Bertinetto, R. Mueller, K. Tertikas, S. Samber, and P. H. S. Torr, “Making better mistakes: Leveraging class hierarchies with deep networks,” inProc. IEEE/CVF CVPR, 2020, pp. 12506–12515
2020
-
[7]
Coherent hierarchical multi-label classification networks,
E. Giunchiglia and T. Lukasiewicz, “Coherent hierarchical multi-label classification networks,” inProc. NeurIPS, vol. 33, 2020, pp. 9662–9673
2020
-
[8]
B-CNN: Branch convolutional neural network for hierarchical classification,
X. Zhu and M. Bain, “B-CNN: Branch convolutional neural network for hierarchical classification,” arXiv:1709.09890, 2017
Pith/arXiv arXiv 2017
-
[9]
Semi-supervised learning with taxonomic labels,
J.-C. Su and S. Maji, “Semi-supervised learning with taxonomic labels,” inProc. BMVC, 2021
2021
-
[10]
R. O. Duda, P. E. Hart, and D. G. Stork,Pattern Classification, 2nd ed. Wiley-Interscience, 2001
2001
-
[11]
SAFT: Towards out-of- distribution generalization in fine-tuning,
B. Nguyen, S. Uhlich, F. Cardinaux, L. Mauch, M. Edraki, and A. C. Courville, “SAFT: Towards out-of- distribution generalization in fine-tuning,” inProc. ECCV, 2024, pp. 138–154
2024
-
[12]
D. Lee, B. Kim, G. Kim, H. Kwon, N. Maeng, and W. Kim, “MATANet: A multi-context attention and taxonomy-aware network for fine-grained underwater recognition of marine species,”arXiv:2601.03729, 2026
Pith/arXiv arXiv 2026
-
[13]
FathomNet 2025 – 4th place solution,
Health9819, “FathomNet 2025 – 4th place solution,” 2025. [Online]. Available:https://github.com/ Health9819/FGVC-FathomNet25
2025
-
[14]
On finding lowest common ancestors in trees,
A. V. Aho, J. E. Hopcroft, and J. D. Ullman, “On finding lowest common ancestors in trees,” inProc. ACM STOC, 1976, pp. 253–265
1976
-
[15]
When does label smoothing help?
R. M¨ uller, S. Kornblith, and G. Hinton, “When does label smoothing help?” inProc. NeurIPS, vol. 32, 2019, pp. 4694–4703
2019
-
[16]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inProc. ICLR, 2019
2019
-
[17]
Better bootstrap confidence intervals,
B. Efron, “Better bootstrap confidence intervals,”Journal of the American Statistical Association, vol. 82, no. 397, pp. 171–185, 1987
1987
-
[18]
Three things everyone should know about Vision Transformers,
H. Touvron, M. Cord, and H. J´ egou, “Three things everyone should know about Vision Transformers,” in Proc. ECCV, 2022, pp. 497–515
2022
-
[19]
FathomNet 2025 – 2nd place solution,
kidshock, “FathomNet 2025 – 2nd place solution,” 2025. [Online]. Available:https://www.kaggle.com/ competitions/fathomnet-2025/discussion
2025
-
[20]
FathomNet 2025 – 3rd place solution,
DalhousieAI, “FathomNet 2025 – 3rd place solution,” 2025. [Online]. Available:https://github.com/ DalhousieAI/fathomnet_comp
2025
-
[21]
On calibration of modern neural networks,
C. Guo, G. Pleiss, Y. Sun, and K. Q. Weinberger, “On calibration of modern neural networks,” inProc. ICML, vol. 70, 2017, pp. 1321–1330
2017
-
[22]
The iNaturalist species classification and detection dataset,
G. Van Horn, O. Mac Aodha, Y. Song, Y. Cui, C. Sun, A. Shepard, H. Adam, P. Perona, and S. Belongie, “The iNaturalist species classification and detection dataset,” inProc. IEEE/CVF CVPR, 2018, pp. 8769– 8778
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.