How Robust is OCR-Reasoning? Evaluating OCR-Reasoning Robustness of Vision-Language Models under Visual Perturbations
Pith reviewed 2026-06-25 19:11 UTC · model grok-4.3
The pith
Higher clean OCR accuracy does not guarantee robustness to visual perturbations, with charts and tables degrading more than documents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
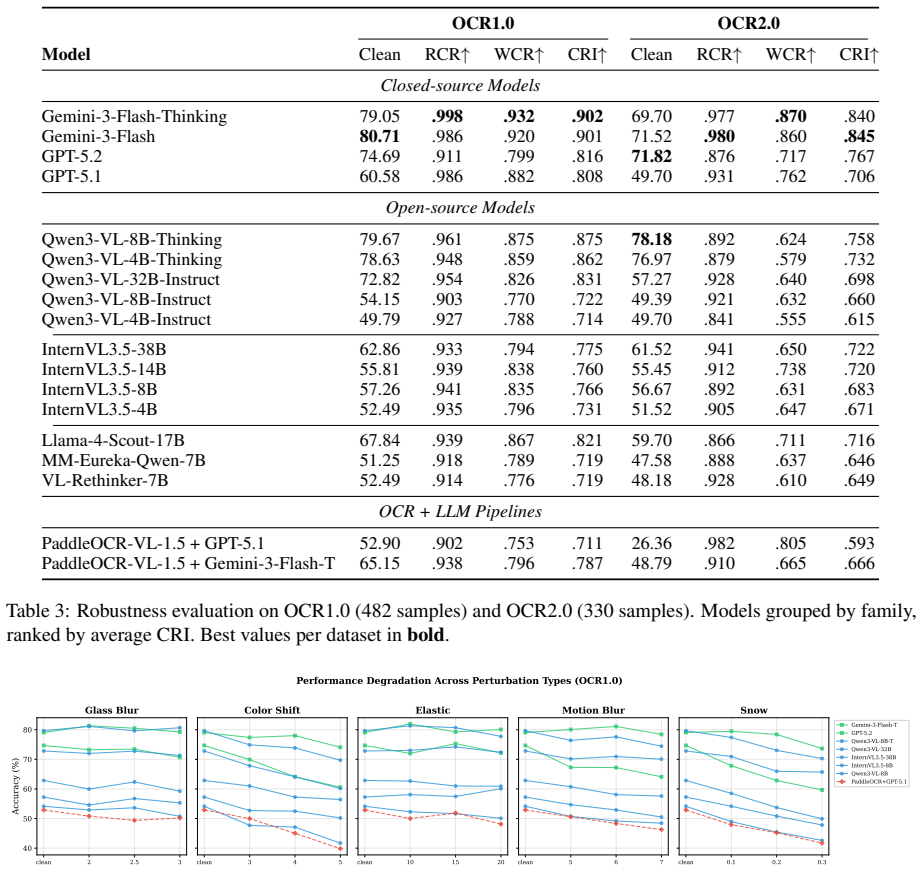
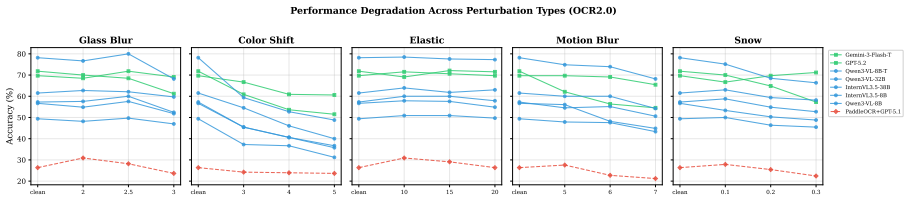
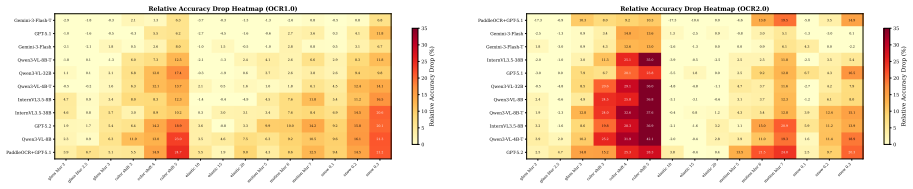
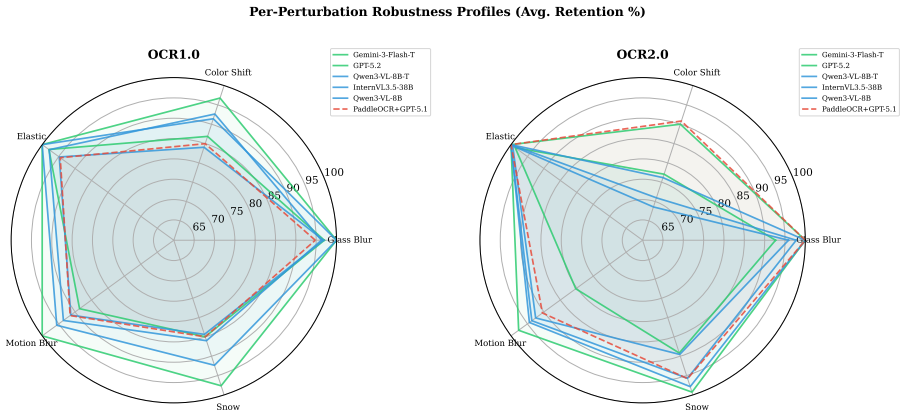
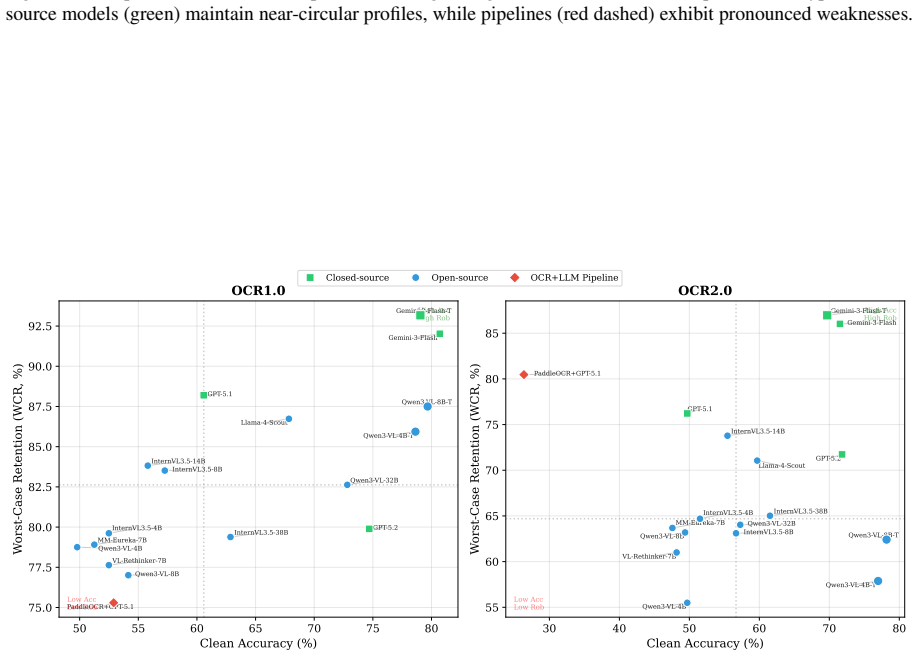
Higher clean accuracy does not necessarily imply stronger robustness, and models can suffer pronounced degradation in the worst case on OCR tasks that are sensitive to structure, with charts and tables substantially more fragile than document-like inputs under perturbation.
What carries the argument
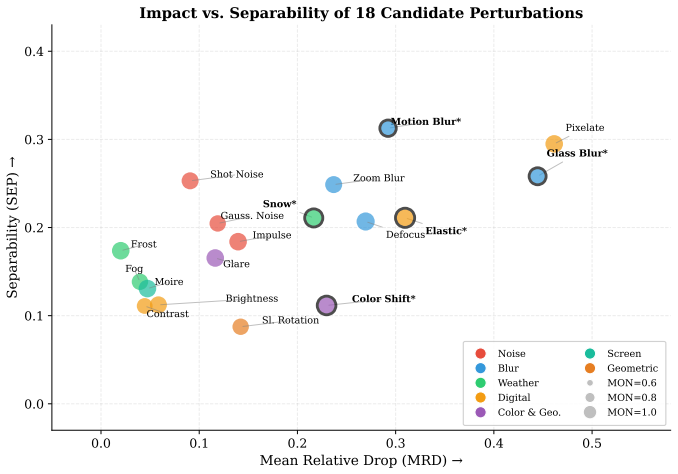
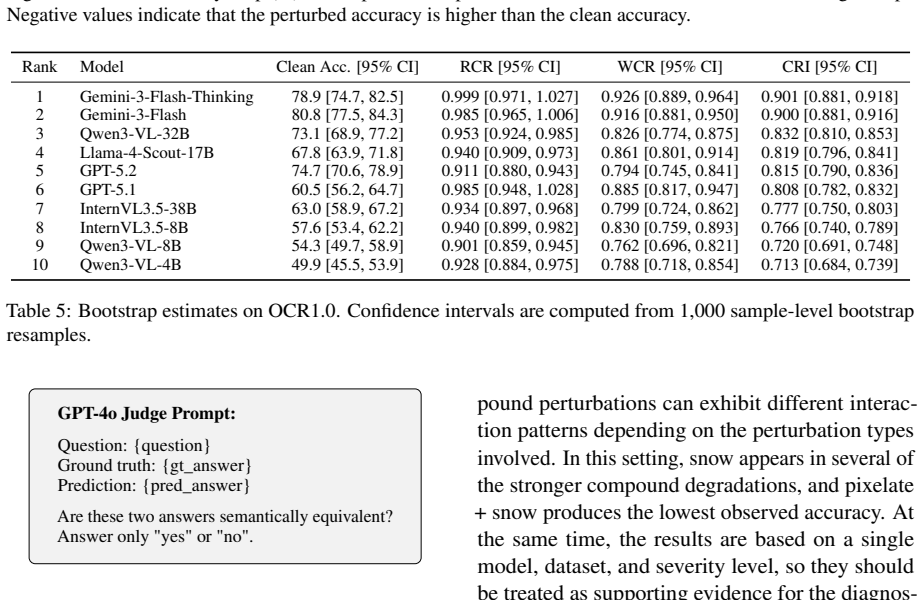
The OCR-Robust benchmark, which supplies 812 samples across OCR1.0 (documents, scene text, receipts, handwriting, math) and OCR2.0 (charts, geometry diagrams, tables) and applies five representative perturbations at three severity levels each.
If this is right
- Clean accuracy alone is insufficient for selecting models in OCR-reasoning applications.
- Structure-sensitive inputs require separate robustness testing beyond document-style material.
- Worst-case retention and composite indices reveal failure modes missed by average metrics.
- OCR+LLM pipelines and open VLMs exhibit distinct robustness profiles under the same perturbations.
Where Pith is reading between the lines
- Real-world systems may need explicit worst-case testing during deployment rather than relying on clean benchmarks.
- Training procedures could incorporate the selected perturbations on chart and table data to close the observed gap.
- Extending the benchmark to video or multi-page inputs would test whether the fragility pattern generalizes.
Load-bearing premise
The five chosen perturbations represent the visual degradations that occur in real OCR-reasoning deployments and the 812 samples cover the needed diversity of structure-sensitive inputs.
What would settle it
A measurement showing that real deployed OCR-reasoning errors under camera noise, compression, or lighting changes do not track the benchmark's worst-case retention scores would undermine the central claim.
Figures




read the original abstract
Vision-language models (VLMs) have achieved strong performance on OCR-based benchmarks and increasingly focused on text-rich understanding, but their robustness under controlled visual degradation remains insufficiently understood. This gap is critical for OCR reasoning, where visual corruption can induce OCR errors and structural distortions, thereby introducing uncertainty into the reasoning task. To systematically study this problem, we introduce OCR-Robust, a benchmark designed for evaluating OCR reasoning robustness under visual perturbations. It contains 812 samples across two complementary subsets: OCR1.0, covering documents, scene text, receipts, handwriting, and mathematical content, and OCR2.0, focusing on charts, geometry diagrams, and tables. To enable efficient yet informative evaluation, we conduct a pilot study over 18 candidate perturbations and select 5 representative types at 3 severity levels each based on their impact and cross-model discriminability. We evaluate robustness using clean accuracy, Relative Corruption Retention (RCR), Worst-Case Retention (WCR), and a composite Corruption Robustness Index (CRI), and benchmark 18 models spanning proprietary systems, open-source VLMs, and OCR+LLM pipelines. Our results show that higher clean accuracy does not necessarily imply stronger robustness, and that models can suffer pronounced degradation in the worst case on OCR tasks that are sensitive to structure, and charts and tables are substantially more fragile than document-like inputs under perturbation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the OCR-Robust benchmark with 812 samples split into OCR1.0 (documents, scene text, receipts, handwriting, mathematical content) and OCR2.0 (charts, geometry diagrams, tables). After piloting 18 perturbations, it retains 5 types at 3 severity levels each based on impact and cross-model discriminability. It evaluates 18 models (proprietary VLMs, open-source VLMs, OCR+LLM pipelines) using clean accuracy, Relative Corruption Retention (RCR), Worst-Case Retention (WCR), and Corruption Robustness Index (CRI), concluding that higher clean accuracy does not imply stronger robustness, that structure-sensitive tasks suffer pronounced worst-case degradation, and that charts/tables are substantially more fragile than document-like inputs.
Significance. If the perturbation set and sample coverage prove representative, the work would be significant as a systematic benchmark exposing that clean-task performance is a poor predictor of robustness on text-rich reasoning and that input structure modulates fragility. The composite CRI and worst-case metrics offer concrete, falsifiable quantities that could guide VLM development for real-world OCR deployments.
major comments (2)
- [Perturbation Selection] Perturbation Selection (pilot study over 18 candidates): the dual criteria of impact and cross-model discriminability favor perturbations that differentiate models rather than those matching the distribution of real degradations (camera motion, uneven lighting, compression, print artifacts). Because the headline claims—no clean-accuracy/robustness correlation and greater fragility of charts/tables—rest directly on the retained five perturbations, this selection requires explicit validation against deployment statistics or an expanded discussion of ecological validity.
- [Dataset Construction] Sample Construction (OCR1.0/OCR2.0 split, 812 samples): the manuscript states that the subsets cover diversity of structure-sensitive inputs, yet supplies no explicit sampling criteria, stratification details, or coverage metrics. Without these, the reported differential fragility between document-like and chart/table inputs risks being benchmark-specific rather than general.
minor comments (2)
- [Evaluation Metrics] The exact formulas for RCR, WCR, and CRI should appear as numbered equations in the main text (or a dedicated metrics subsection) rather than being described only in prose, to support replication.
- [Results] Table or figure captions reporting per-model RCR/WCR values should include error bars or confidence intervals if multiple runs or seeds were used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline planned revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: [Perturbation Selection] Perturbation Selection (pilot study over 18 candidates): the dual criteria of impact and cross-model discriminability favor perturbations that differentiate models rather than those matching the distribution of real degradations (camera motion, uneven lighting, compression, print artifacts). Because the headline claims—no clean-accuracy/robustness correlation and greater fragility of charts/tables—rest directly on the retained five perturbations, this selection requires explicit validation against deployment statistics or an expanded discussion of ecological validity.
Authors: We appreciate the referee's emphasis on ecological validity. Our pilot criteria prioritized perturbations with high impact and strong cross-model differentiation to create an informative diagnostic benchmark, rather than purely mimicking real-world distributions. We agree this leaves room for stronger grounding. In revision we will expand the perturbation section with references to literature on common OCR degradations (e.g., camera motion, uneven illumination, JPEG compression, and print artifacts) and discuss how the retained five perturbations align with or differ from those distributions. Where deployment statistics are available in prior work we will cite them; where direct validation data are absent we will explicitly note the limitation while retaining the current selection rationale. revision: partial
-
Referee: [Dataset Construction] Sample Construction (OCR1.0/OCR2.0 split, 812 samples): the manuscript states that the subsets cover diversity of structure-sensitive inputs, yet supplies no explicit sampling criteria, stratification details, or coverage metrics. Without these, the reported differential fragility between document-like and chart/table inputs risks being benchmark-specific rather than general.
Authors: We agree that additional transparency on sample construction is warranted. The 812 samples were drawn from established public datasets for each OCR category (documents, scene text, receipts, handwriting, math, charts, diagrams, tables) with the goal of balancing structural complexity. In the revised manuscript we will add an explicit subsection detailing the sampling procedure, including any stratification by content type or source dataset, the number of samples per subcategory, and basic coverage statistics (e.g., average text density or structural element counts). This will allow readers to assess generalizability more directly. revision: yes
Circularity Check
Empirical benchmark study with no circular derivations or self-referential reductions
full rationale
The paper is a measurement study that constructs a benchmark (OCR-Robust with 812 samples), selects 5 perturbations from 18 candidates via explicit pilot criteria (impact + discriminability), and reports observed metrics (clean accuracy, RCR, WCR, CRI) across 18 models. No equations, fitted parameters, or derivations are present that reduce any reported robustness index to a quantity defined by the paper's own inputs. The central claims are direct empirical observations rather than predictions derived from self-defined quantities. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Computer Vision -- ECCV 2022 , year =
2022
-
[2]
Science China Information Sciences , volume=
Ocrbench: on the hidden mystery of ocr in large multimodal models , author=. Science China Information Sciences , volume=. 2024 , publisher=
2024
-
[3]
arXiv preprint arXiv:2501.00321 , year=
Ocrbench v2: An improved benchmark for evaluating large multimodal models on visual text localization and reasoning , author=. arXiv preprint arXiv:2501.00321 , year=
-
[4]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Cc-ocr: A comprehensive and challenging ocr benchmark for evaluating large multimodal models in literacy , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[5]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Omnidocbench: Benchmarking diverse pdf document parsing with comprehensive annotations , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[6]
arXiv preprint arXiv:2505.10610 , year=
MMLongBench: Benchmarking Long-Context Vision-Language Models Effectively and Thoroughly , author=. arXiv preprint arXiv:2505.10610 , year=
-
[7]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
M-longdoc: A benchmark for multimodal super-long document understanding and a retrieval-aware tuning framework , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[8]
arXiv preprint arXiv:2505.12307 , year=
LogicOCR: Do Your Large Multimodal Models Excel at Logical Reasoning on Text-Rich Images? , author=. arXiv preprint arXiv:2505.12307 , year=
-
[9]
arXiv preprint arXiv:2505.17163 , year=
Ocr-reasoning benchmark: Unveiling the true capabilities of mllms in complex text-rich image reasoning , author=. arXiv preprint arXiv:2505.17163 , year=
-
[10]
2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , pages=
Visual robustness benchmark for visual question answering (vqa) , author=. 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , pages=. 2025 , organization=
2025
-
[11]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
FRAMES-VQA: Benchmarking Fine-Tuning Robustness across Multi-Modal Shifts in Visual Question Answering , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[12]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Benchmarking Multimodal Large Language Models Against Image Corruptions , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[13]
arXiv preprint arXiv:2510.16926 , year=
Res-Bench: Benchmarking the Robustness of Multimodal Large Language Models to Dynamic Resolution Input , author=. arXiv preprint arXiv:2510.16926 , year=
-
[14]
arXiv preprint arXiv:2504.13690 , year=
Analysing the Robustness of Vision-Language-Models to Common Corruptions , author=. arXiv preprint arXiv:2504.13690 , year=
-
[15]
arXiv preprint arXiv:1903.12261 , year=
Benchmarking neural network robustness to common corruptions and perturbations , author=. arXiv preprint arXiv:1903.12261 , year=
Pith/arXiv arXiv 1903
-
[16]
2024 , eprint=
Benchmarking Large Multimodal Models against Common Corruptions , author=. 2024 , eprint=
2024
-
[17]
CVPR , year=
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric , author=. CVPR , year=
-
[18]
2025 , eprint=
DeepSeek-OCR: Contexts Optical Compression , author=. 2025 , eprint=
2025
-
[19]
2025 , eprint=
HunyuanOCR Technical Report , author=. 2025 , eprint=
2025
-
[20]
2025 , eprint=
PaddleOCR 3.0 Technical Report , author=. 2025 , eprint=
2025
-
[21]
2024 , eprint=
MinerU: An Open-Source Solution for Precise Document Content Extraction , author=. 2024 , eprint=
2024
-
[22]
2024 , eprint=
TableVQA-Bench: A Visual Question Answering Benchmark on Multiple Table Domains , author=. 2024 , eprint=
2024
-
[23]
2026 , eprint=
VLM-RobustBench: A Comprehensive Benchmark for Robustness of Vision-Language Models , author=. 2026 , eprint=
2026
-
[24]
Unveiling the Lack of LVLM Robustness to Fundamental Visual Variations: Why and Path Forward
Fan, Zhiyuan and Wang, Yumeng and Polisetty, Sandeep and Fung, Yi R. Unveiling the Lack of LVLM Robustness to Fundamental Visual Variations: Why and Path Forward. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1037
-
[25]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Coordinated Robustness Evaluation Framework for Vision-Language Models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[26]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Self-training with noisy student improves imagenet classification , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[27]
2025 , eprint=
OpenAI GPT-5 System Card , author=. 2025 , eprint=
2025
-
[28]
2025 , eprint=
Qwen3-VL Technical Report , author=. 2025 , eprint=
2025
-
[29]
2025 , eprint=
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency , author=. 2025 , eprint=
2025
-
[30]
2026 , eprint=
PaddleOCR-VL-1.5: Towards a Multi-Task 0.9B VLM for Robust In-the-Wild Document Parsing , author=. 2026 , eprint=
2026
-
[31]
Qwen2.5-VL , url =
Qwen Team , month =. Qwen2.5-VL , url =
-
[32]
Gemini 3 Flash , year =
-
[33]
Gemini 3 Pro , year =
-
[34]
Kimi Team and Angang Du and Bohong Yin and Bowei Xing and Bowen Qu and Bowen Wang and Cheng Chen and Chenlin Zhang and Chenzhuang Du and Chu Wei and Congcong Wang and Dehao Zhang and Dikang Du and Dongliang Wang and Enming Yuan and Enzhe Lu and Fang Li and Flood Sung and Guangda Wei and Guokun Lai and Han Zhu and Hao Ding and Hao Hu and Hao Yang and Hao Z...
-
[35]
arXiv preprint arXiv:2504.08837 , year=
VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning , author =. arXiv preprint arXiv:2504.08837 , year=
-
[36]
2025 , journal=
MM-Eureka: Exploring the Frontiers of Multimodal Reasoning with Rule-based Reinforcement Learning , author=. 2025 , journal=
2025
-
[37]
Llama-4-Scout-17B-16E-Instruct , year =
-
[38]
CoRR abs/2007.00398 (2020) , author=
DocVQA: A Dataset for VQA on Document Images. CoRR abs/2007.00398 (2020) , author=. arXiv preprint arXiv:2007.00398 , year=
arXiv 2007
-
[39]
2021 , eprint=
InfographicVQA , author=. 2021 , eprint=
2021
-
[40]
Huang, Zheng and Chen, Kai and He, Jianhua and Bai, Xiang and Karatzas, Dimosthenis and Lu, Shijian and Jawahar, C. V. , year=. ICDAR2019 Competition on Scanned Receipt OCR and Information Extraction , url=. doi:10.1109/icdar.2019.00244 , booktitle=
-
[41]
2021 , eprint=
Screen2Words: Automatic Mobile UI Summarization with Multimodal Learning , author=. 2021 , eprint=
2021
-
[42]
ICPR2018 Contest on Robust Reading for Multi-Type Web Images , doi =
He, Mengchao and Liu, Yuliang and Yang, Zhibo and Zhang, Sheng and Luo, Canjie and Gao, Feiyu and Zheng, Qi and Wang, Yongpan and Zhang, Xin and Jin, Lianwen , year =. ICPR2018 Contest on Robust Reading for Multi-Type Web Images , doi =
-
[43]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[44]
T heorem QA : A Theorem-driven Question Answering Dataset
Chen, Wenhu and Yin, Ming and Ku, Max and Lu, Pan and Wan, Yixin and Ma, Xueguang and Xu, Jianyu and Wang, Xinyi and Xia, Tony. T heorem QA : A Theorem-driven Question Answering Dataset. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.489
-
[45]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Towards VQA Models That Can Read , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[46]
C hart QA : A Benchmark for Question Answering about Charts with Visual and Logical Reasoning
Masry, Ahmed and Long, Do Xuan and Tan, Jia Qing and Joty, Shafiq and Hoque, Enamul. C hart QA : A Benchmark for Question Answering about Charts with Visual and Logical Reasoning. Findings of the Association for Computational Linguistics: ACL 2022. 2022. doi:10.18653/v1/2022.findings-acl.177
-
[47]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Gns: Solving plane geometry problems by neural-symbolic reasoning with multi-modal llms , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[48]
arXiv preprint arXiv:2404.19205 , year=
Tablevqa-bench: A visual question answering benchmark on multiple table domains , author=. arXiv preprint arXiv:2404.19205 , year=
-
[49]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Cheng, Hiuyi and Zhang, Peirong and Wu, Sihang and Zhang, Jiaxin and Zhu, Qiyuan and Xie, Zecheng and Li, Jing and Ding, Kai and Jin, Lianwen , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2023 , pages =
2023
-
[50]
Proceedings of the International Conference on Learning Representations , year=
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations , author=. Proceedings of the International Conference on Learning Representations , year=
-
[51]
2015 , eprint=
Deep Residual Learning for Image Recognition , author=. 2015 , eprint=
2015
-
[52]
2011 , eprint=
Modern hierarchical, agglomerative clustering algorithms , author=. 2011 , eprint=
2011
-
[53]
Introducing Claude Sonnet 4.5 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.