Dynamic-dLLM: Dynamic Cache-Budget and Adaptive Parallel Decoding for Training-Free Acceleration of Diffusion LLM
Pith reviewed 2026-06-29 13:25 UTC · model grok-4.3
The pith
Dynamic-dLLM accelerates diffusion LLMs over threefold on average by adaptively setting cache budgets and decoding thresholds based on token dynamics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
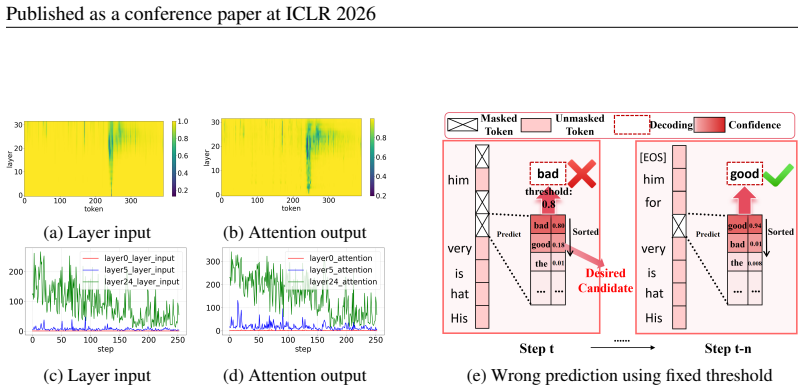
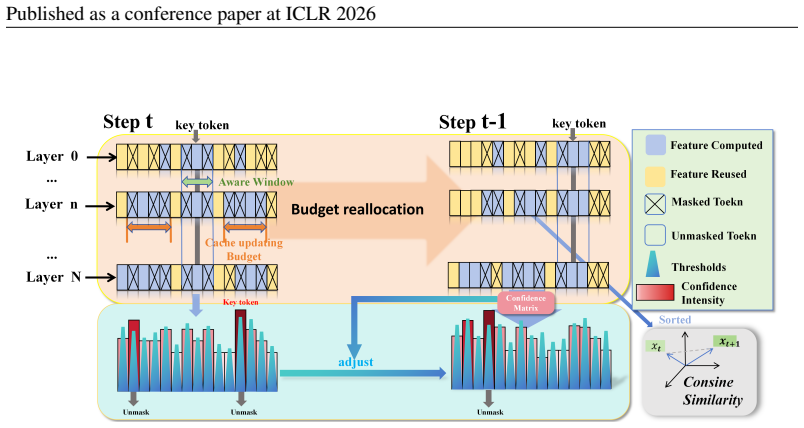
Dynamic-dLLM is a training-free framework consisting of Dynamic Cache Updating, which adaptively allocates cache-update budgets according to layer-wise token dynamics, and Adaptive Parallel Decoding, which dynamically calibrates decoding thresholds according to step-wise token dynamics; together these yield an average inference speedup exceeding 3 times on LLaDA-8B-Instruct, LLaDA-1.5, and Dream-v0-7B-Instruct while matching baseline performance on MMLU, GSM8K, and HumanEval.
What carries the argument
Dynamic Cache Updating (DCU) and Adaptive Parallel Decoding (APD), which measure layer-wise and step-wise token dynamics to set adaptive cache budgets and acceptance thresholds.
If this is right
- dLLMs become viable for longer sequences and real-time generation without retraining.
- The same dynamic rules outperform both static cache methods and fixed-threshold parallel decoding across multiple model sizes.
- The framework functions as a plug-and-play module that can be added to existing dLLM deployments.
- Inference cost scales more gracefully with sequence length because cache updates and parallel steps are allocated only where token dynamics indicate they matter.
Where Pith is reading between the lines
- The same measurement of token dynamics could be applied to other non-autoregressive generative models that currently lack efficient caching.
- Energy use in large-batch dLLM serving would drop proportionally to the observed speedup if the method scales to production hardware.
- Combining the dynamic rules with orthogonal techniques such as quantization or speculative decoding remains an open extension.
- If token dynamics prove stable across training runs, the method could support on-the-fly adaptation during continued pretraining of dLLMs.
Load-bearing premise
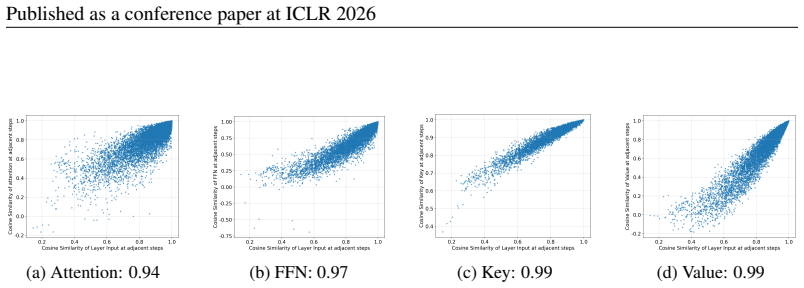
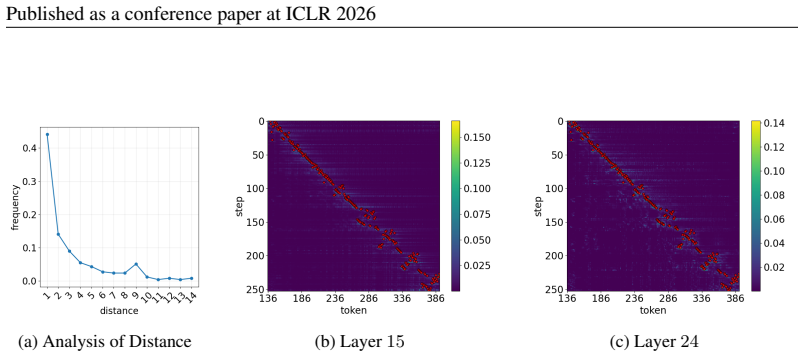
Layer-wise and step-wise token dynamics can be measured and used to set cache-update budgets and decoding thresholds in a way that generalizes across models and tasks without any training or task-specific tuning.
What would settle it
Running the same DCU and APD rules on a held-out dLLM architecture and task yields either less than 2 times speedup or a clear drop in accuracy on MMLU or GSM8K compared with the unaccelerated baseline.
Figures

read the original abstract
Diffusion Large Language Models (dLLMs) offer a promising alternative to autoregressive models, excelling in text generation tasks due to their bidirectional attention mechanisms. However, their computational complexity scales on the order of L cubed with the sequence length L. This poses significant challenges for long-sequence and real-time applications, primarily due to the lack of compatibility with key-value caching and the non-autoregressive nature of denoising steps. Existing acceleration methods rely on static caching or parallel decoding strategies, which fail to account for the dynamic behavior of token properties across layers and decoding steps. We propose Dynamic-dLLM, a training-free framework that enhances dLLM inference efficiency through two components: Dynamic Cache Updating (DCU), which adaptively allocates cache-update budgets based on layer-wise token dynamics, and Adaptive Parallel Decoding (APD), which dynamically calibrates decoding thresholds to balance generation quality and efficiency. Extensive experiments on models like LLaDA-8B-Instruct, LLaDA-1.5, and Dream-v0-7B-Instruct across benchmarks such as MMLU, GSM8K, and HumanEval demonstrate that Dynamic-dLLM significantly improves inference speed. It attains an average speedup exceeding 3 times while maintaining performance. Dynamic-dLLM outperforms state-of-the-art acceleration methods and provides a plug-and-play solution for efficient dLLM deployment without compromising performance. The code is available at https://github.com/TianyiWu233/DYNAMIC-DLLM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Dynamic-dLLM, a training-free framework for accelerating diffusion LLMs via two components: Dynamic Cache Updating (DCU), which adaptively allocates cache-update budgets according to measured layer-wise token dynamics, and Adaptive Parallel Decoding (APD), which sets per-step decoding thresholds to trade off quality and speed. Experiments on LLaDA-8B-Instruct, LLaDA-1.5 and Dream-v0-7B-Instruct across MMLU, GSM8K and HumanEval report an average speedup exceeding 3× with no performance degradation and superiority to prior acceleration methods; code is released.
Significance. If the empirical claims hold under the stated conditions, the work would be a useful practical contribution to efficient dLLM inference. The training-free, plug-and-play framing and public code release are positive features that could facilitate adoption for long-sequence generation.
major comments (2)
- [Abstract and method description of DCU/APD] The central generalization claim—that layer- and step-wise token dynamics can be measured and mapped to cache budgets and decoding thresholds in a manner that transfers across the three evaluated models and three benchmarks with zero training or per-task tuning—is load-bearing for the 'plug-and-play without compromising performance' assertion. No equations, pseudocode, or ablation tables demonstrate the exact functional form of the mapping or its invariance to task/model shifts (Abstract; description of DCU and APD).
- [Experimental results section] Table or figure reporting the >3× average speedup (and the per-model/per-benchmark numbers) does not include error bars, number of runs, or statistical tests; without these, it is impossible to assess whether the reported gains are robust or could be explained by run-to-run variance.
minor comments (2)
- [Method section] Notation for 'token dynamics' and 'cache-update budget' should be defined once with a consistent symbol before being used in the DCU description.
- [Abstract and experiments] The abstract states 'outperforms state-of-the-art acceleration methods' but does not name the baselines or cite their papers; this should be explicit in both abstract and experimental section.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to incorporate additional details and statistical reporting as outlined.
read point-by-point responses
-
Referee: [Abstract and method description of DCU/APD] The central generalization claim—that layer- and step-wise token dynamics can be measured and mapped to cache budgets and decoding thresholds in a manner that transfers across the three evaluated models and three benchmarks with zero training or per-task tuning—is load-bearing for the 'plug-and-play without compromising performance' assertion. No equations, pseudocode, or ablation tables demonstrate the exact functional form of the mapping or its invariance to task/model shifts (Abstract; description of DCU and APD).
Authors: We agree that the manuscript would benefit from more explicit formalization. In the revision we will add the precise equations defining token dynamics measurement, the mapping functions to cache budgets and decoding thresholds, algorithm pseudocode for DCU and APD, and new ablation tables that quantify invariance across the three models and benchmarks under fixed hyperparameters with no per-task tuning. revision: yes
-
Referee: [Experimental results section] Table or figure reporting the >3× average speedup (and the per-model/per-benchmark numbers) does not include error bars, number of runs, or statistical tests; without these, it is impossible to assess whether the reported gains are robust or could be explained by run-to-run variance.
Authors: We concur that statistical robustness indicators are necessary. The revised experimental section will report results from multiple independent runs with error bars (standard deviation), state the exact number of runs, and include statistical significance tests comparing Dynamic-dLLM against baselines. revision: yes
Circularity Check
No circularity: empirical method with no fitted predictions or self-referential derivations
full rationale
The paper presents Dynamic-dLLM as a training-free empirical framework with two components (DCU and APD) whose behavior is measured on specific models and benchmarks. No equations, fitted parameters, or predictions are described that reduce by construction to the inputs. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The speedup claims rest on reported experimental outcomes rather than any definitional or statistical equivalence to the method's own measurements. This is the normal non-circular case for an acceleration paper whose central assertions are externally falsifiable via replication on the listed models and tasks.
Axiom & Free-Parameter Ledger
free parameters (2)
- cache-update budget allocation rule
- decoding threshold calibration
axioms (1)
- domain assumption Token properties exhibit measurable dynamic behavior across layers and decoding steps that can guide cache and decoding decisions without training.
Reference graph
Works this paper leans on
-
[1]
L Berglund, M Tong, M Kaufmann, M Balesni, AC Stickland, T Korbak, and O Evans. The reversal curse: Llms trained on “a is b” fail to learn “b is a”. arxiv 2023.arXiv preprint arXiv:2309.12288. Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. ...
-
[2]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[5]
Junchao Huang, Xinting Hu, Boyao Han, Shaoshuai Shi, Zhuotao Tian, Tianyu He, and Li Jiang. Memory forcing: Spatio-temporal memory for consistent scene generation on minecraft.arXiv preprint arXiv:2510.03198, 2025a. Junchao Huang, Xinting Hu, Shaoshuai Shi, Zhuotao Tian, and Li Jiang. Edit360: 2d image edits to 3d assets from any angle. InICCV, 2025b. Li ...
-
[6]
Step-DPO: Step-wise Preference Optimization for Long-chain Reasoning of LLMs
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia. Lisa: Rea- soning segmentation via large language model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9579–9589, 2024a. 10 Published as a conference paper at ICLR 2026 Xin Lai, Zhuotao Tian, Yukang Chen, Senqiao Yang, Xiangru Peng...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
dLLM-Cache: Accelerating Diffusion Large Language Models with Adaptive Caching
Feng Liu, Shiwei Zhang, Xiaofeng Wang, Yujie Wei, Haonan Qiu, Yuzhong Zhao, Yingya Zhang, Qixiang Ye, and Fang Wan. Timestep embedding tells: It’s time to cache for video diffusion model. InProceedings of the Computer Vision and Pattern Recognition Conference, pp. 7353– 7363, 2025a. Zhiyuan Liu, Yicun Yang, Yaojie Zhang, Junjie Chen, Chang Zou, Qingyuan W...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
dkv-cache: The cache for diffusion language models.arXiv preprint arXiv:2505.15781,
Xinyin Ma, Runpeng Yu, Gongfan Fang, and Xinchao Wang. dkv-cache: The cache for diffusion language models.arXiv preprint arXiv:2505.15781,
-
[9]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models.arXiv preprint arXiv:2502.09992,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Boosting few-shot 3d point cloud segmentation via query-guided enhancement
Zhenhua Ning, Zhuotao Tian, Guangming Lu, and Wenjie Pei. Boosting few-shot 3d point cloud segmentation via query-guided enhancement. InProceedings of the 31st ACM international con- ference on multimedia, pp. 1895–1904,
1904
-
[11]
Scalable language model with generalized continual learning.arXiv preprint arXiv:2404.07470, 2024a
Bohao Peng, Zhuotao Tian, Shu Liu, Mingchang Yang, and Jiaya Jia. Scalable language model with generalized continual learning.arXiv preprint arXiv:2404.07470, 2024a. Bohao Peng, Xiaoyang Wu, Li Jiang, Yukang Chen, Hengshuang Zhao, Zhuotao Tian, and Jiaya Jia. Oa-cnns: Omni-adaptive sparse cnns for 3d semantic segmentation. InProceedings of the IEEE/CVF Co...
-
[12]
Explore the potential of clip for training- free open vocabulary semantic segmentation
11 Published as a conference paper at ICLR 2026 Tong Shao, Zhuotao Tian, Hang Zhao, and Jingyong Su. Explore the potential of clip for training- free open vocabulary semantic segmentation. InEuropean Conference on Computer Vision, pp. 139–156. Springer,
2026
-
[13]
Yuerong Song, Xiaoran Liu, Ruixiao Li, Zhigeng Liu, Zengfeng Huang, Qipeng Guo, Ziwei He, and Xipeng Qiu. Sparse-dllm: Accelerating diffusion llms with dynamic cache eviction.arXiv preprint arXiv:2508.02558,
-
[14]
Declip: Decoupled learning for open-vocabulary dense perception
Junjie Wang, Bin Chen, Yulin Li, Bin Kang, Yichi Chen, and Zhuotao Tian. Declip: Decoupled learning for open-vocabulary dense perception. InProceedings of the Computer Vision and Pat- tern Recognition Conference, pp. 14824–14834, 2025a. Junjie Wang, Keyu Chen, Yulin Li, Bin Chen, Hengshuang Zhao, Xiaojuan Qi, and Zhuotao Tian. Generalized decoupled learni...
-
[15]
Senqiao Yang, Tianyuan Qu, Xin Lai, Zhuotao Tian, Bohao Peng, Shu Liu, and Jiaya Jia. Lisa++: An improved baseline for reasoning segmentation with large language model.arXiv preprint arXiv:2312.17240,
-
[16]
Dream 7B: Diffusion Large Language Models
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
Fengqi Zhu, Rongzhen Wang, Shen Nie, Xiaolu Zhang, Chunwei Wu, Jun Hu, Jun Zhou, Jianfei Chen, Yankai Lin, Ji-Rong Wen, et al. Llada 1.5: Variance-reduced preference optimization for large language diffusion models.arXiv preprint arXiv:2505.19223,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
14 B.2 Implementation Details
12 Published as a conference paper at ICLR 2026 CONTENTS Contents 13 A Algorithm Supplement 14 B Experiment Details 14 B.1 Benchmarks and Settings . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 B.2 Implementation Details . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 C Example Description 15 D Rela...
2026
-
[19]
Ensure:Final predictionx 0 ▷/* Initialize caches at stept=T*/ 1:C←InitializeCache(L,x T )▷Cache Key, Value, Attention Output and FFN Output ofL tokens
Algorithm 1Dynamic Cache Updating Require:Mask predictorf θ, promptcand initial masked sequencex T with lengthL, denoising stepsT, cache update budgetB window andB layer, initial thresholdτ T . Ensure:Final predictionx 0 ▷/* Initialize caches at stept=T*/ 1:C←InitializeCache(L,x T )▷Cache Key, Value, Attention Output and FFN Output ofL tokens. 2:Generate ...
2026
-
[20]
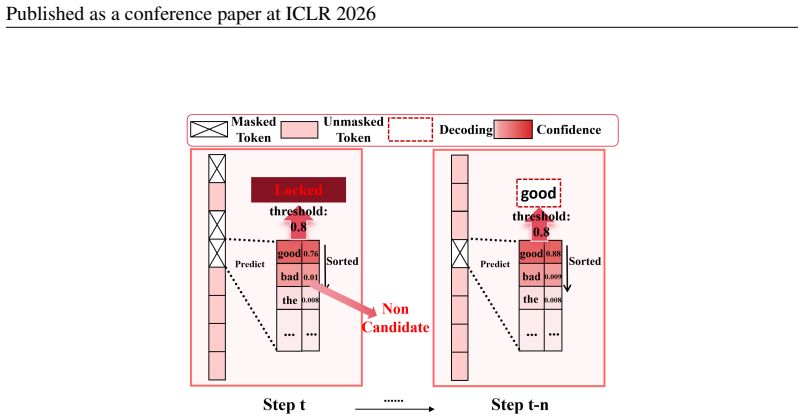
In addition, for Adaptive Parallel Decoding (APD) in Dynamic-dLLM, we setα= 0.001and β= 0.0008based on extensive statistical analysis. Datasets Steps Block Len Gen Len MMLU 256 32 256 ARC-C 256 32 256 GSM8K 256 32 256 Math 256 32 256 HumanEval 512 32 512 Table 4: Configuration of Benchmarks C EXAMPLEDESCRIPTION As shown in Figure 7, in the absence of cand...
2026
-
[21]
in reasoning segmentation. Diffusion Large Language Models.Diffusion models, which excel in continuous data generation through iterative denoising processes (Sohl-Dickstein et al., 2015; Ho et al., 2020), have recently shown promising potential in natural language processing. Unlike their success in image domains (Rombach et al., 2022; Peebles & Xie, 2023...
2015
-
[22]
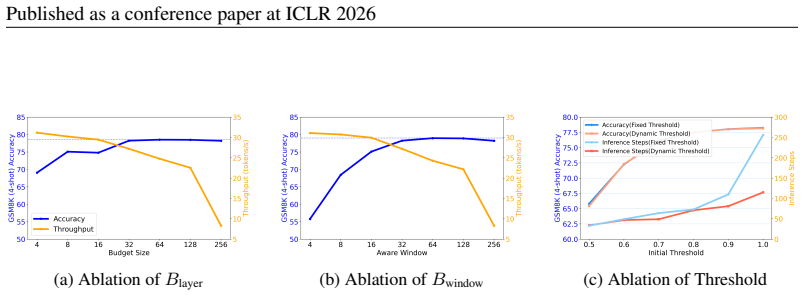
puts tokens outside the current block to the cache and updates tokens 16 Published as a conference paper at ICLR 2026 Bwindow 32 64 128 192 64 0 256 Blayer 32 64 128 64 192 256 0 score 73.92 77.62 79.15 78.03 78.92 74.07 75.74 Table 5: Performance of DCU with different settings ofB window andB layer, using 1024 generated tokens on the GSM8K dataset with t...
2026
-
[23]
However, with appropriate increases in these two parameters, the accu- racy gradually recovers
exhibits a slight decline. However, with appropriate increases in these two parameters, the accu- racy gradually recovers. Furthermore, when the sum ofB layer andB window is fixed, different proportional allocations between them lead to varying impacts on performance. Through these experiments, we confirmed that settingB layer equal toB window yields opti...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.