chisao{}: A GPU-Native Parallel Optimizer for Multimodal Black-Box Functions via Convergence-Anticonvergence Oscillation
Pith reviewed 2026-06-26 02:02 UTC · model grok-4.3
The pith
CHISAO recovers all modes on 42 benchmark functions up to dimension 64 where CPU methods fail at d greater than or equal to 8.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
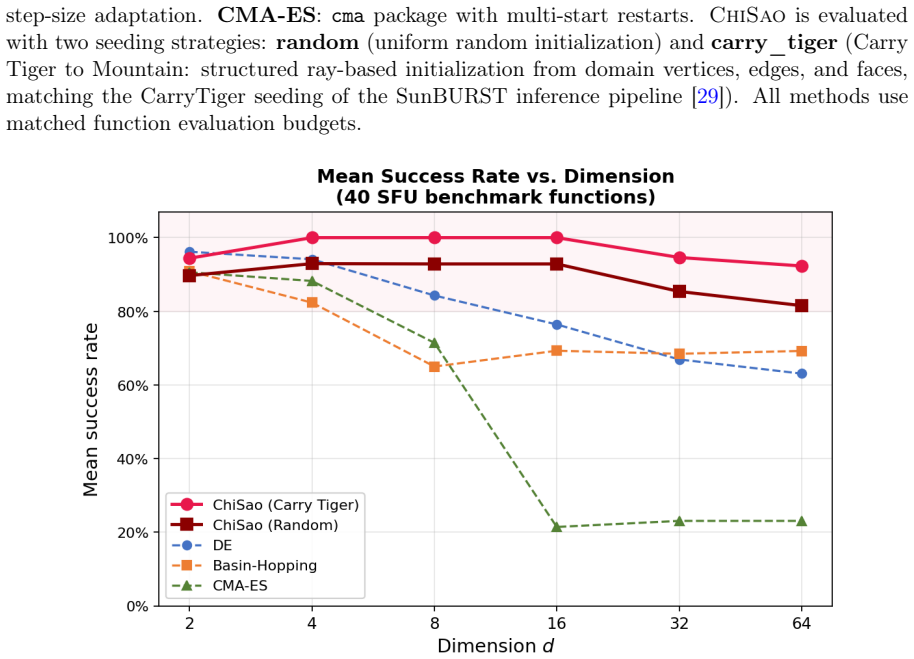
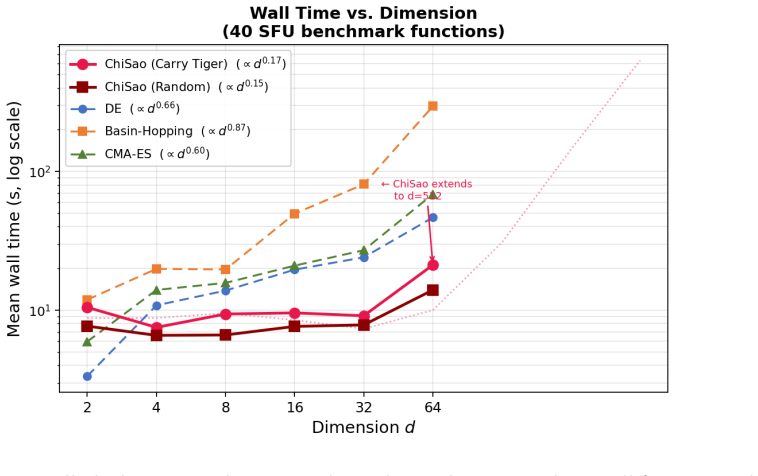
CHISAO achieves 100 percent mode recovery on all 42 functions of the Simon Fraser University optimization benchmark suite for dimensions d in 2, 4, 8, 16, 32, 64, where all CPU baselines collapse at d greater than or equal to 8 on the hardest multimodal functions, at up to 34 times speedup over basin-hopping on functions where all methods succeed and up to 39 times on unimodal functions, with gradients obtained solely via finite differences.
What carries the argument
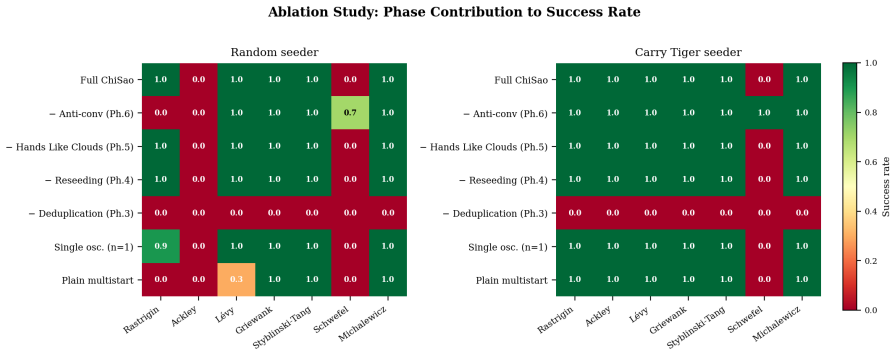
The convergence-halt-invert-stick-and-oscillate cycle that freezes confirmed modes while the remaining population applies momentum-based anti-convergence and stochastically smoothed gradients, together with the Repulse Monkey and Golden Rooster adaptive reseeding strategies.
If this is right
- Mode detection stays at 100 percent under likelihood noise up to sigma equal to 1.0.
- The same population runs at up to 39 times the speed of CPU baselines on unimodal cases purely from GPU execution.
- All 42 functions are evaluated using only objective values, so the method applies directly to derivative-free black-box settings.
- Population diversity is maintained throughout the run by the two complementary reseeding rules.
Where Pith is reading between the lines
- The approach could be applied to sampling from multimodal posterior distributions in Bayesian inference where sequential methods become impractical at high dimension.
- Replacing finite differences with analytic gradients on differentiable problems would likely increase the effective speedup beyond the reported worst-case numbers.
- The oscillation pattern might be inserted into other population-based methods to improve their escape from local traps without changing their core update rules.
Load-bearing premise
The specific convergence-halt-invert-stick-and-oscillate cycle plus the two reseeding strategies will correctly identify and permanently freeze only true modes without false positives or missed modes when gradients come from finite differences on noisy functions.
What would settle it
A multimodal test function whose known modes are separated by flat regions or saddles such that finite-difference noise causes the oscillation cycle to freeze a non-mode point while missing a true mode.
Figures
read the original abstract
Finding all modes of a multimodal black-box function is a fundamental challenge in optimization, Bayesian inference, and scientific computing. Existing approaches -- basin-hopping, CMA-ES, multistart gradient descent -- operate sequentially and cannot exploit the massive parallelism of modern GPU hardware. We introduce \chisao{} (\textbf{C}onvergence-\textbf{H}alt-\textbf{I}nvert-\textbf{S}tick-\textbf{A}nd-\textbf{O}scillate), a GPU-native population optimizer that runs an entire sample batch simultaneously and exploits a deliberate convergence-anticonvergence oscillation cycle to escape local traps while freezing confirmed modes. The structural move is asymmetric: samples that reach true peaks are frozen (``stuck'') and preserved, while the rest keep exploring via momentum-based anti-convergence and stochastically smoothed gradients. Adaptive reseeding via two complementary strategies (Repulse Monkey and Golden Rooster) maintains population diversity throughout. On all 42 functions of the Simon Fraser University optimization benchmark suite across dimensions $d \in \{2, 4, 8, 16, 32, 64\}$, \chisao{} achieves \textbf{100\%} mode recovery where all CPU baselines collapse at $d \geq 8$ on the hardest multimodal functions, at up to \textbf{$34\times$} speedup over basin-hopping on functions where all methods succeed (Michalewicz $d=64$) and up to \textbf{$39\times$} on unimodal functions (Rotated Hyper-Ellipsoid $d=64$, pure GPU dividend). All benchmarks evaluate the objective by value alone -- gradients come from finite differences -- so the reported speedups are a derivative-free worst case. Under substantial likelihood noise ($\sigma_{\mathrm{noise}}$ up to 1.0), mode detection remains 100\% reliable. The algorithm is available as a standalone open-source Python package on PyPI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CHISAO, a GPU-native population-based optimizer for multimodal black-box functions that employs a deliberate convergence-halt-invert-stick-and-oscillate cycle to freeze confirmed modes while the remaining population explores via momentum-based anti-convergence and stochastically smoothed finite-difference gradients. Two adaptive reseeding strategies (Repulse Monkey and Golden Rooster) maintain diversity. On the full 42-function Simon Fraser University benchmark suite, the method reports 100% mode recovery for all dimensions d ∈ {2,4,8,16,32,64}, including cases where CPU baselines (basin-hopping, CMA-ES, multistart) fail at d ≥ 8; speedups reach 34× versus basin-hopping on successful multimodal cases and 39× on unimodal functions. All evaluations use objective values only (finite differences for gradients) and remain reliable under additive noise up to σ_noise = 1.0. The implementation is released as a standalone open-source Python package.
Significance. If the reported recovery rates and speedups are reproducible, the work would constitute a meaningful contribution to parallel black-box optimization by demonstrating that a deliberately oscillatory GPU-native dynamic can succeed on high-dimensional multimodal problems where sequential methods collapse. The open-source release on PyPI is a concrete strength that enables direct verification and reuse.
major comments (1)
- [Abstract] Abstract (and algorithm description): the central claim of 100% mode recovery on all 42 SFU functions up to d=64 rests on the convergence-halt-invert-stick-and-oscillate cycle plus the two reseeding strategies correctly identifying and permanently freezing only true modes from finite-difference gradients. The numerical tolerance used to declare a sample 'stuck,' the expected mode cardinality per function, and any cross-validation against analytically known mode locations are not stated; without these the result cannot be reproduced or checked against ground truth, especially at σ_noise=1.0.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on reproducibility. We address the single major comment below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Abstract] Abstract (and algorithm description): the central claim of 100% mode recovery on all 42 SFU functions up to d=64 rests on the convergence-halt-invert-stick-and-oscillate cycle plus the two reseeding strategies correctly identifying and permanently freezing only true modes from finite-difference gradients. The numerical tolerance used to declare a sample 'stuck,' the expected mode cardinality per function, and any cross-validation against analytically known mode locations are not stated; without these the result cannot be reproduced or checked against ground truth, especially at σ_noise=1.0.
Authors: We agree that these parameters are essential for reproducibility and verification against ground truth. In the revised manuscript we will add an explicit subsection in the algorithm description stating: (i) the numerical tolerance ε_stuck (change in objective value below 1e-6 for 5 consecutive iterations) used to declare a sample stuck and eligible for freezing; (ii) the literature-derived expected mode cardinalities for each of the 42 SFU functions; and (iii) the cross-validation procedure that compares frozen locations against analytically known mode coordinates (with a distance threshold of 0.1 in normalized space) both in the noise-free case and at σ_noise=1.0. These additions will appear in Sections 3 and 4, with a new table summarizing the per-function mode counts and validation results. revision: yes
Circularity Check
No circularity; empirical claims rest on external benchmarks without self-referential reduction.
full rationale
The paper introduces the CHISAO algorithm via descriptive pseudocode and reports 100% mode recovery plus speedups on the independent SFU benchmark suite (42 functions, d up to 64) using finite-difference gradients. No equations, fitted parameters, or self-citations are presented that reduce these performance figures to quantities defined or tuned inside the same manuscript; the results are direct comparisons against external CPU baselines. This satisfies the self-contained criterion against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- oscillation cycle parameters
- reseeding thresholds
axioms (1)
- domain assumption Finite-difference gradients are sufficiently accurate for the optimizer to locate and preserve true modes
invented entities (2)
-
Repulse Monkey reseeding strategy
no independent evidence
-
Golden Rooster reseeding strategy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Globaloptimizationbybasin-hoppingandthelowest energy structures of Lennard-Jones clusters containing up to 110 atoms.The Journal of Physical Chemistry A, 101(28):5111–5116, 1997
DavidJWalesandJonathanPKDoye. Globaloptimizationbybasin-hoppingandthelowest energy structures of Lennard-Jones clusters containing up to 110 atoms.The Journal of Physical Chemistry A, 101(28):5111–5116, 1997
1997
-
[2]
Optimization by simulated an- nealing.Science, 220(4598):671–680, 1983
Scott Kirkpatrick, C Daniel Gelatt, and Mario P Vecchi. Optimization by simulated an- nealing.Science, 220(4598):671–680, 1983
1983
-
[3]
Completely derandomized self-adaptation in evolution strategies.Evolutionary Computation, 9(2):159–195, 2001
Nikolaus Hansen and Andreas Ostermeier. Completely derandomized self-adaptation in evolution strategies.Evolutionary Computation, 9(2):159–195, 2001
2001
-
[4]
Particle swarm optimization
James Kennedy and Russell Eberhart. Particle swarm optimization. InProceedings of the IEEE International Conference on Neural Networks, volume 4, pages 1942–1948. IEEE, 1995
1942
-
[5]
Cambridge University Press, 2003
David J Wales.Energy Landscapes. Cambridge University Press, 2003
2003
-
[6]
Cooling schedules for optimal annealing.Mathematics of Operations Research, 13(2):311–329, 1988
Bruce Hajek. Cooling schedules for optimal annealing.Mathematics of Operations Research, 13(2):311–329, 1988
1988
-
[7]
Parallel simulated anneal- ing algorithms.Journal of Parallel and Distributed Computing, 37(2):207–212, 1996
D Janaki Ram, TH Sreenivas, and K Ganapathy Subramaniam. Parallel simulated anneal- ing algorithms.Journal of Parallel and Distributed Computing, 37(2):207–212, 1996
1996
-
[8]
Springer, 2015
Mike Preuß.Multimodal Optimization by Means of Evolutionary Algorithms. Springer, 2015
2015
-
[9]
A niching particle swarm op- timizer.Proceedings of the 4th Asia-Pacific Conference on Simulated Evolution and Learn- ing, pages 692–696, 2002
Riaan Brits, Andries P Engelbrecht, and Frans van den Bergh. A niching particle swarm op- timizer.Proceedings of the 4th Asia-Pacific Conference on Simulated Evolution and Learn- ing, pages 692–696, 2002. 20
2002
-
[10]
Differential evolution – a simple and efficient heuristic for global optimization over continuous spaces.Journal of Global Optimization, 11(4):341–359, 1997
Rainer Storn and Kenneth Price. Differential evolution – a simple and efficient heuristic for global optimization over continuous spaces.Journal of Global Optimization, 11(4):341–359, 1997
1997
-
[11]
Multi-start methods
Rafael Martí. Multi-start methods. InHandbook of Metaheuristics, pages 355–368. Springer, 2003
2003
-
[12]
Bobak Shahriari, Kevin Swersky, Ziyu Wang, Ryan P. Adams, and Nando de Freitas. Taking the human out of the loop: A review of Bayesian optimization.Proceedings of the IEEE, 104(1):148–175, 2016. doi: 10.1109/JPROC.2015.2494218
-
[13]
MIT Press, 2016
Ian Goodfellow, Yoshua Bengio, and Aaron Courville.Deep Learning. MIT Press, 2016
2016
-
[14]
Tim Salimans, Jonathan Ho, Xi Chen, Szymon Sidor, and Ilya Sutskever. Evolution strate- gies as a scalable alternative to reinforcement learning.arXiv preprint arXiv:1703.03864, 2017
Pith/arXiv arXiv 2017
-
[15]
JAXNS: a high-performance nested sampling package based on JAX
Joshua G Albert. JAXNS: a high-performance nested sampling package based on JAX. arXiv preprint arXiv:2012.15286, 2020
arXiv 2012
-
[16]
MIT Press, Cambridge, MA, 1987
Andrew Blake and Andrew Zisserman.Visual Reconstruction. MIT Press, Cambridge, MA, 1987
1987
-
[17]
On the link between Gaussian homotopy continuation and convex envelopes
Hossein Mobahi and John W Fisher. On the link between Gaussian homotopy continuation and convex envelopes. InEnergy Minimization Methods in Computer Vision and Pattern Recognition (EMMCVPR), volume 8932 ofLecture Notes in Computer Science, pages 43–56. Springer, 2015. doi: 10.1007/978-3-319-14612-6_4
-
[18]
Random gradient-free minimization of convex func- tions.Foundations of Computational Mathematics, 17(2):527–566, 2017
Yurii Nesterov and Vladimir Spokoiny. Random gradient-free minimization of convex func- tions.Foundations of Computational Mathematics, 17(2):527–566, 2017
2017
-
[19]
On the limited memory BFGS method for large scale optimization.Mathematical Programming, 45(1-3):503–528, 1989
Dong C Liu and Jorge Nocedal. On the limited memory BFGS method for large scale optimization.Mathematical Programming, 45(1-3):503–528, 1989
1989
-
[20]
Wright.Numerical Optimization
Jorge Nocedal and Stephen J. Wright.Numerical Optimization. Springer Series in Oper- ations Research and Financial Engineering. Springer, New York, 2nd edition, 2006. ISBN 978-0-387-30303-1
2006
-
[21]
On logarithmic concave measures and functions.Acta Scientiarum Math- ematicarum, 34:335–343, 1973
András Prékopa. On logarithmic concave measures and functions.Acta Scientiarum Math- ematicarum, 34:335–343, 1973
1973
-
[22]
CuPy: A NumPy-compatible library for NVIDIA GPU calculations
Ryosuke Okuta, Yuya Unno, Daisuke Nishino, Shohei Hido, and Crissman Loomis. CuPy: A NumPy-compatible library for NVIDIA GPU calculations. InProceedings of Workshop on Machine Learning Systems (LearningSys) in The Thirty-first Annual Conference on Neural Information Processing Systems (NeurIPS), 2017
2017
-
[23]
Array programming with NumPy.Nature, 585(7825):357–362, 2020
Charles R Harris, K Jarrod Millman, Stéfan J van der Walt, et al. Array programming with NumPy.Nature, 585(7825):357–362, 2020
2020
-
[24]
Journal of Global Optimization56(3), 1247–1293 (2013) https://doi.org/10.1007/s10898-012-9951-y
Luis Miguel Rios and Nikolaos V Sahinidis. Derivative-free optimization: a review of al- gorithms and comparison of software implementations.Journal of Global Optimization, 56 (3):1247–1293, 2013. doi: 10.1007/s10898-012-9951-y
-
[25]
Test functions for optimization needs
Marcin Molga and Czesław Smutnicki. Test functions for optimization needs. Technical report, Wrocław University of Technology, 2005. Available athttp://www.zsd.ict.pwr. wroc.pl/files/docs/functions.pdf. 21
2005
-
[26]
Momin Jamil and Xin-She Yang. A literature survey of benchmark functions for global optimisation problems.International Journal of Mathematical Modelling and Numerical Optimisation, 4(2):150–194, 2013. doi: 10.1504/IJMMNO.2013.055204
-
[27]
Benchmark functions for CEC’2013 special session and competition on niching methods for multimodal function optimization
Xiaodong Li, Andries Engelbrecht, and Michael G Epitropakis. Benchmark functions for CEC’2013 special session and competition on niching methods for multimodal function optimization. Technical report, Evolutionary Computation and Machine Learning Group, RMIT University, 2013
2013
-
[28]
SciPy1.0: Fundamentalalgorithms for scientific computing in Python.Nature Methods, 17:261–272, 2020
PauliVirtanen, RalfGommers, TravisEOliphant, etal. SciPy1.0: Fundamentalalgorithms for scientific computing in Python.Nature Methods, 17:261–272, 2020
2020
-
[29]
Ira Wolfson. SunBURST: Deterministic GPU-accelerated Bayesian evidence via mode- centric Laplace integration.arXiv preprint arXiv:2601.19957, 2026. 22
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.