The Red Queen G\"odel Machine: Co-Evolving Agents and Their Evaluators
Pith reviewed 2026-06-26 01:42 UTC · model grok-4.3
The pith
The Red Queen Gödel Machine organizes self-improvement into epochs so agents and evaluators can co-evolve as utilities change.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
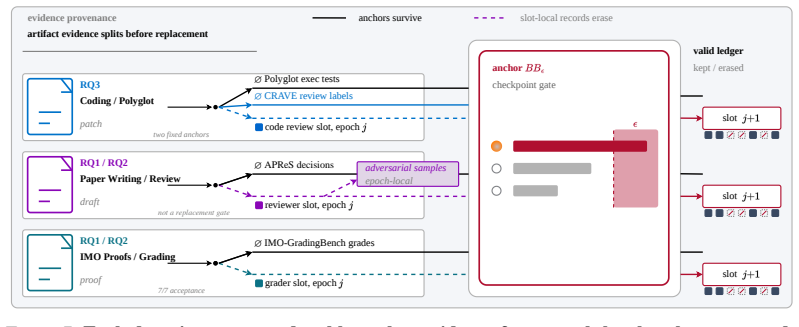
The RQGM makes recursive self-improvement possible under non-stationary utilities by dividing search into epochs that keep a fixed evaluation criterion inside each epoch while permitting the utility function to evolve at epoch boundaries, so that self-improvement guarantees continue to hold locally as the global objective changes.
What carries the argument
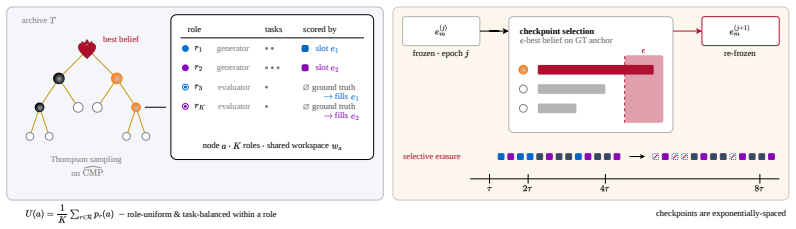
Epoch structure with controlled utility evolution: within each epoch the evaluation criterion is held fixed so local search guarantees apply, while the utility can be updated at boundaries to reflect co-evolution of agents and evaluators.
If this is right
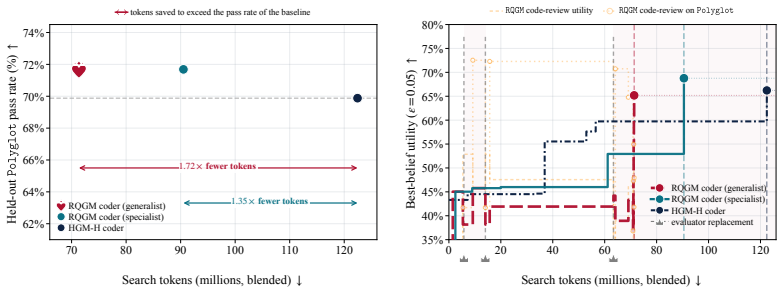
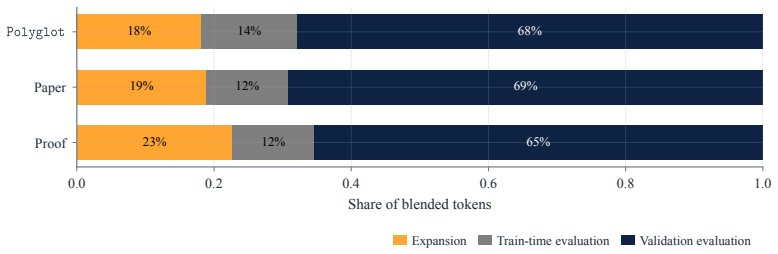
- Adding an agent-as-a-judge code-review signal raises test pass rate on verifiable coding tasks while using 1.35x–1.72x fewer tokens than prior methods.
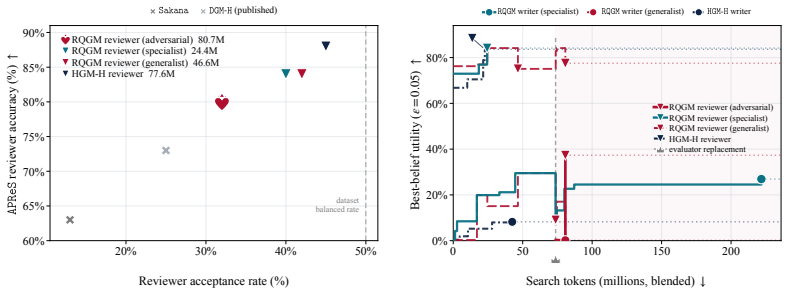
- Co-evolved writers achieve 1.78x–1.86x higher acceptance rates when evaluated by a diverse panel of agent judges.
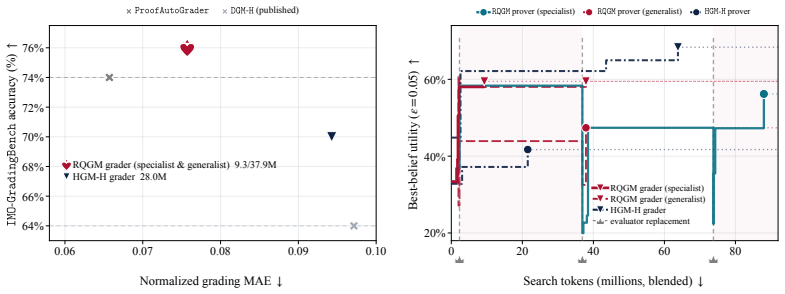
- Co-evolved graders reach 9 percent higher accuracy against ground-truth labels on Olympiad-level proofs.
- An adversarial objective can reduce over-acceptance of AI-generated papers to match the rate applied to human work.
Where Pith is reading between the lines
- The epoch boundary mechanism may generalize to any setting in which short-term fixed criteria must remain stable while longer-term objectives drift.
- Treating evaluation as a co-evolving partner rather than a static oracle could apply to open-ended domains beyond coding and paper review.
- The adversarial signal that equalizes stringency between AI and human output suggests a route to debiasing automated reviewers without external human labels.
Load-bearing premise
Self-improvement guarantees remain valid inside an epoch even after the utility has been allowed to change at the previous boundary, and the fixed within-epoch criterion continues to serve as a useful proxy for the evolving objective.
What would settle it
An experiment in which an agent trained inside one epoch shows no further improvement or violates the expected performance scaling once the utility is updated at the next boundary, or in which the within-epoch metric no longer correlates with outcomes measured under the updated utility.
Figures
read the original abstract
Self-improving agents are state-of-the-art (SOTA) on agentic coding benchmarks and have recently been extended to general domains. However, their search methods generally assume a stationary evaluation criterion: a fixed verifier, benchmark, or labeled dataset that remains valid as the agent improves. This ignores a central feature of evolution: species adapt as their environments change with them. We aim to bring the same principle to recursive self-improvement, making evaluation part of the improvement loop and opening search to evolving evaluators, adversarial objectives, and dynamic utilities that may surpass static benchmarks. We introduce the Red Queen Godel Machine (RQGM), an evolutionary framework for recursive self-improvement under non-stationary utilities. The RQGM makes this possible through controlled utility evolution: search is organized into epochs with a fixed within-epoch evaluation criterion, while the utility can be updated at epoch boundaries, so self-improvement guarantees hold per epoch as the objective evolves across them. We begin by showing that even on verifiable coding tasks, the RQGM improves test pass rate over the prior SOTA by adding a complementary agent-as-a-judge code-review signal. This signal is cheaper and the RQGM uses 1.35x-1.72x fewer tokens. We then turn to scientific paper writing and reviewing, and Olympiad-level proof writing and grading, where the RQGM improves performance over prior self-improving agents: co-evolved writers reach 1.78x-1.86x higher acceptance rates under a diverse agent-as-a-judge panel, while co-evolved graders reach 9% higher ground-truth accuracy. In paper reviewing, the strongest baseline reviewer over-accepts AI-generated papers at up to 1.91x the human rate. The RQGM corrects this by introducing an adversarial objective that discovers reviewers equally stringent on AI and human work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
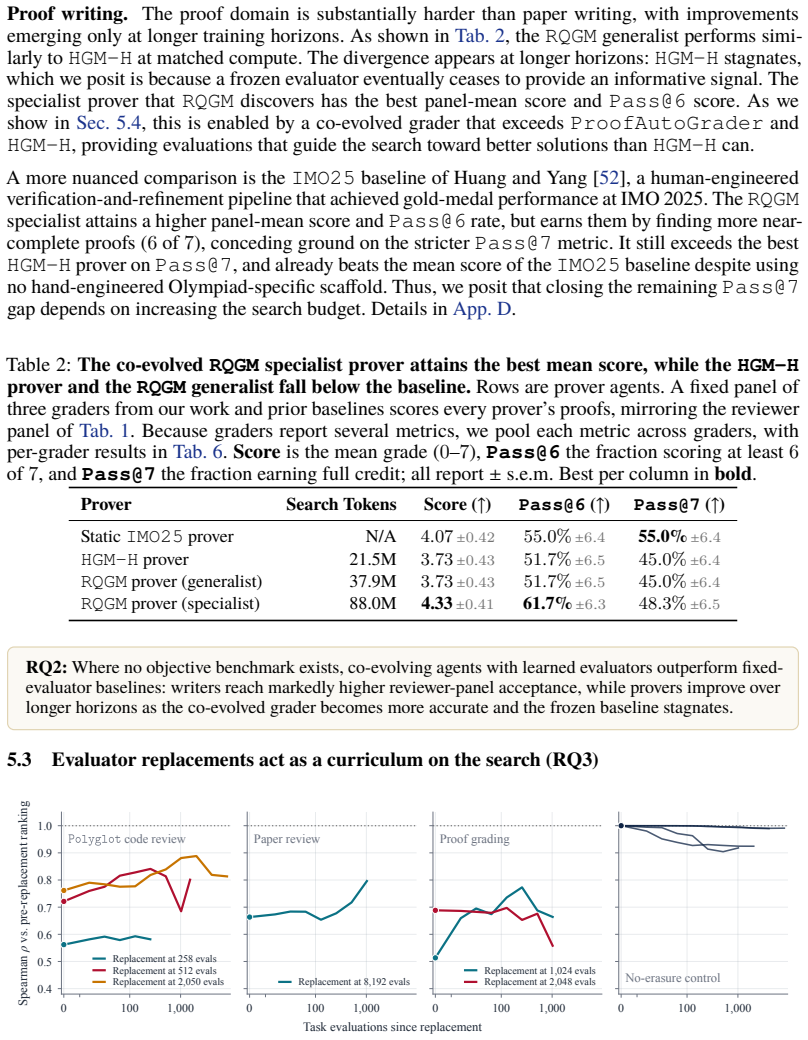
Summary. The paper introduces the Red Queen Gödel Machine (RQGM), an evolutionary framework for recursive self-improvement of agents under non-stationary utilities. Search is partitioned into epochs with a fixed within-epoch evaluation criterion so that self-improvement guarantees hold per epoch, while the utility function can be updated at epoch boundaries. Empirical results are reported on verifiable coding tasks (improved test pass rate and 1.35x-1.72x fewer tokens via an agent-as-a-judge code-review signal), scientific paper writing/reviewing (co-evolved writers achieve 1.78x-1.86x higher acceptance rates under diverse agent judges; co-evolved graders reach 9% higher ground-truth accuracy; an adversarial objective corrects over-acceptance of AI-generated papers), and Olympiad-level proof writing/grading.
Significance. If the per-epoch construction is shown to preserve useful progress under evolving utilities, the framework would address a fundamental limitation of current self-improving agents that assume stationary verifiers or benchmarks. The multi-domain empirical gains, token efficiency, and explicit handling of adversarial objectives (e.g., fair reviewing) would be notable contributions to agentic and evolutionary ML methods.
major comments (2)
- [Abstract and §3 (controlled utility evolution / epoch partitioning)] Abstract and §3 (controlled utility evolution / epoch partitioning): the central claim that 'self-improvement guarantees hold per epoch as the objective evolves across them' is load-bearing for the non-stationary utility handling, yet the manuscript supplies no formal argument, theorem, or transfer proof showing that improvements obtained under fixed criterion C_t remain informative or non-harmful once the utility is replaced by C_{t+1} at the epoch boundary. This directly matches the stress-test concern and leaves open the possibility that the co-evolution loop amplifies misalignment.
- [Empirical evaluation sections (coding, paper, and proof tasks)] Empirical evaluation sections (coding, paper, and proof tasks): all quantitative claims (1.78x-1.86x acceptance rates, 9% accuracy gain, 1.35x-1.72x token reduction, 1.91x over-acceptance correction) are presented without error bars, number of independent runs, or statistical tests, so the reliability of the reported improvements over baselines cannot be assessed.
minor comments (2)
- [Methods] Methods: the description of how the utility update rule itself is learned or constrained at epoch boundaries is underspecified; a concrete algorithm or pseudocode would clarify the mechanism.
- [Notation] Notation: the distinction between the within-epoch fixed criterion and the evolving utility should be given explicit symbols (e.g., C_t vs. U_t) to avoid ambiguity when discussing transfer.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We respond to each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and §3 (controlled utility evolution / epoch partitioning)] Abstract and §3 (controlled utility evolution / epoch partitioning): the central claim that 'self-improvement guarantees hold per epoch as the objective evolves across them' is load-bearing for the non-stationary utility handling, yet the manuscript supplies no formal argument, theorem, or transfer proof showing that improvements obtained under fixed criterion C_t remain informative or non-harmful once the utility is replaced by C_{t+1} at the epoch boundary. This directly matches the stress-test concern and leaves open the possibility that the co-evolution loop amplifies misalignment.
Authors: The per-epoch construction fixes the evaluation criterion for the duration of search within an epoch, allowing any self-improvement procedure that assumes a stationary objective to be invoked without modification. At epoch boundaries the utility is updated in a controlled manner and the subsequent epoch begins from the agents obtained under the prior criterion. We agree that the manuscript would benefit from an explicit statement of this invariance and will add a short clarifying proposition in §3 that formalizes the per-epoch stationarity and the conditions under which intra-epoch improvements are carried forward. revision: yes
-
Referee: [Empirical evaluation sections (coding, paper, and proof tasks)] Empirical evaluation sections (coding, paper, and proof tasks): all quantitative claims (1.78x-1.86x acceptance rates, 9% accuracy gain, 1.35x-1.72x token reduction, 1.91x over-acceptance correction) are presented without error bars, number of independent runs, or statistical tests, so the reliability of the reported improvements over baselines cannot be assessed.
Authors: The current manuscript indeed omits these statistical details. In the revision we will report the number of independent runs performed for each experiment, include error bars or standard deviations on all quantitative metrics, and add appropriate statistical tests comparing RQGM variants against baselines. revision: yes
Circularity Check
No circularity; empirical outcomes reported without definitional reduction
full rationale
The paper describes an evolutionary framework (RQGM) that partitions search into epochs with fixed within-epoch criteria while allowing utility updates at boundaries. All reported results—test pass rates, acceptance rates, token usage, and accuracy improvements—are presented as measured empirical outcomes on coding, paper-writing, and proof tasks rather than as quantities defined in terms of the framework itself or obtained by fitting parameters that are then renamed as predictions. No equations, self-definitional constructions, fitted-input predictions, or load-bearing self-citation chains appear in the abstract or description; the central claims remain independent of the method's own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Self-improvement guarantees hold inside each epoch under a fixed evaluation criterion even as the global utility evolves across epochs.
Reference graph
Works this paper leans on
-
[1]
A new evolutionary law
Leigh Van Valen. A new evolutionary law. Evolutionary Theory, 1:1–30, 1973
1973
-
[2]
Darwin Gödel Machine: Open-ended evolution of self-improving agents
Jenny Zhang, Shengran Hu, Cong Lu, Robert Tjarko Lange, and Jeff Clune. Darwin Gödel Machine: Open-ended evolution of self-improving agents. In ICLR, 2026. URL https:// openreview.net/forum?id=pUpzQZTvGY
2026
-
[3]
Huxley-Gödel Machine: Human-Level Coding Agent Development by an Approximation of the Optimal Self-Improving Machine
Wenyi Wang, Piotr Piękos, Li Nanbo, Firas Laakom, Yimeng Chen, Mateusz Ostaszewski, Mingchen Zhuge, and Jürgen Schmidhuber. Huxley-Gödel Machine: Human-Level Coding Agent Development by an Approximation of the Optimal Self-Improving Machine. In ICLR,
-
[4]
URL https://openreview.net/forum?id=T0EiEuhOOL
-
[5]
Foerster, Jeff Clune, Minqi Jiang, Sam Devlin, and Tatiana Shavrina
Jenny Zhang, Bingchen Zhao, Wannan Y ang, Jakob N. Foerster, Jeff Clune, Minqi Jiang, Sam Devlin, and Tatiana Shavrina. HyperAgents. CoRR, abs/2603.19461, 2026
arXiv 2026
-
[6]
Foerster, Jeff Clune, and David Ha
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob N. Foerster, Jeff Clune, and David Ha. The AI scientist: Towards fully automated open-ended scientific discovery. CoRR, abs/2408.06292, 2024
Pith/arXiv arXiv 2024
-
[7]
Foerster, Jeff Clune, and David Ha
Yutaro Y amada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob N. Foerster, Jeff Clune, and David Ha. The AI scientist-v2: Workshop-level automated scientific discovery via agentic tree search. CoRR, abs/2504.08066, 2025
Pith/arXiv arXiv 2025
-
[8]
Thang Luong, Dawsen Hwang, Hoang H. Nguyen, Golnaz Ghiasi, Yuri Chervonyi, Insuk Seo, Junsu Kim, Garrett Bingham, Jonathan Lee, Swaroop Mishra, Alex Zhai, Clara Huiyi Hu, Hen- ryk Michalewski, Jimin Kim, Jeonghyun Ahn, Junhwi Bae, Xingyou Song, Trieu H. Trinh, Quoc V . Le, and Junehyuk Jung. Towards robust mathematical reasoning. In EMNLP, pages 35418–354...
2025
-
[9]
Learning hand- eye coordination for robotic grasping with deep learning and large-scale data collection
Sergey Levine, Peter Pastor, Alex Krizhevsky, Julian Ibarz, and Deirdre Quillen. Learning hand- eye coordination for robotic grasping with deep learning and large-scale data collection. Int. J. Robotics Res., 37(4-5):421–436, 2018
2018
-
[10]
Benjamin Burger, Phillip M. Maffettone, Vladimir V . Gusev, Catherine M. Aitchison, Y ang Bai, Xiaoyan Wang, Xiaobo Li, Ben M. Alston, Buyi Li, Rob Clowes, Nicola Rankin, Brandon Harris, Reiner Sebastian Sprick, and Andrew I. Cooper. A mobile robotic chemist. Nature, 583 (7815):237–241, 2020. doi: 10.1038/s41586-020-2442-2
-
[11]
Hind- sight experience replay
Marcin Andrychowicz, Filip Wolski, Alex Ray, Jonas Schneider, Rachel Fong, Peter Welin- der, Bob McGrew, Josh Tobin, OpenAI Pieter Abbeel, and Wojciech Zaremba. Hind- sight experience replay. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fer- gus, S. Vishwanathan, and R. Garnett, editors, NeurIPS, volume 30. Curran Associates, Inc.,
-
[12]
URL https://proceedings.neurips.cc/paper_files/paper/ 2017/file/453fadbd8a1a3af50a9df4df899537b5-Paper.pdf
2017
-
[13]
Self-improvement of large language models: A technical overview and future outlook
Haoyan Y ang, Mario Xerri, Solha Park, Huajian Zhang, Yiyang Feng, Sai Akhil Kogilathota, and Jiawei Zhou. Self-improvement of large language models: A technical overview and future outlook. CoRR, abs/2603.25681, 2026
arXiv 2026
-
[14]
Map- ping global dynamics of benchmark creation and saturation in artificial intelligence
Adriano Barbosa-Silva, Simon Ott, Kathrin Blagec, Jan Brauner, and Matthias Samwald. Map- ping global dynamics of benchmark creation and saturation in artificial intelligence. CoRR, abs/2203.04592, 2022
arXiv 2022
-
[15]
o1 tops aider’s new polyglot leaderboard.https://aider.chat/2024/ 12/21/polyglot.html, December 2024
Paul Gauthier. o1 tops aider’s new polyglot leaderboard.https://aider.chat/2024/ 12/21/polyglot.html, December 2024. Accessed: 2026-01-28. 13
2024
-
[16]
Towards end-to-end automation of AI research
Chris Lu, Cong Lu, Robert Tjarko Lange, Yutaro Y amada, Shengran Hu, Jakob Foerster, David Ha, and Jeff Clune. Towards end-to-end automation of AI research. Nature, 651(8107):914– 919, 2026
2026
-
[17]
APReS: an agentic paper revision and evaluation system
Bingchen Zhao, Jenny Zhang, Chenxi Whitehouse, Minqi Jiang, Michael Shvartsman, Ab- hishek Charnalia, Despoina Magka, Tatiana Shavrina, Derek Dunfield, Oisin Mac Aodha, and Y oram Bachrach. APReS: an agentic paper revision and evaluation system. CoRR, abs/2603.03142, 2026
arXiv 2026
-
[18]
Bowman, and Shi Feng
Arjun Panickssery, Samuel R. Bowman, and Shi Feng. LLM evaluators recognize and favor their own generations. In NeurIPS, 2024
2024
-
[19]
Speculations concerning the first ultraintelligent machine
Irving John Good. Speculations concerning the first ultraintelligent machine. Adv. Comput., 6: 31–88, 1965
1965
-
[20]
Jürgen Schmidhuber. Gödel machines: Self-referential universal problem solvers making prov- ably optimal self-improvements. CoRR, cs.LO/0309048, 2003
arXiv 2003
-
[21]
Eliminating meta optimization through self-referential meta learning
Louis Kirsch and Jürgen Schmidhuber. Eliminating meta optimization through self-referential meta learning. CoRR, abs/2212.14392, 2022
arXiv 2022
- [22]
-
[23]
Live-SWE- agent: Can software engineering agents self-evolve on the fly? CoRR, abs/2511.13646, 2025
Chunqiu Steven Xia, Zhe Wang, Y an Y ang, Yuxiang Wei, and Lingming Zhang. Live-SWE- agent: Can software engineering agents self-evolve on the fly? CoRR, abs/2511.13646, 2025
arXiv 2025
-
[24]
Self-taught optimizer (STOP): recursively self-improving code generation
Eric Zelikman, Eliana Lorch, Lester Mackey, and Adam Tauman Kalai. Self-taught optimizer (STOP): recursively self-improving code generation. CoRR, abs/2310.02304, 2023
arXiv 2023
-
[25]
Gödel agent: A self-referential agent framework for recursively self-improvement
Xunjian Yin, Xinyi Wang, Liangming Pan, Li Lin, Xiaojun Wan, and William Y ang Wang. Gödel agent: A self-referential agent framework for recursively self-improvement. In ACL (1), pages 27890–27913. Association for Computational Linguistics, 2025
2025
-
[26]
Promptbreeder: Self-referential self-improvement via prompt evolution
Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero, and Tim Rock- täschel. Promptbreeder: Self-referential self-improvement via prompt evolution. In ICML, vol- ume 235 of Proceedings of Machine Learning Research , pages 13481–13544. PMLR / Open- Review.net, 2024
2024
-
[27]
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah D. Goodman. Star: Bootstrapping reasoning with reasoning. In NeurIPS, 2022
2022
-
[28]
William F. Shen, Alex Iacob, Zichen Zhang, Daoheng Wang, Wenyi Wang, Rui Liang, Yulong Zhang, Xinchi Qiu, and Nicholas D. Lane. Star analyst: Self-tuning alpha research. SSRN preprint, 2026. Available at SSRN: https://doi.org/10.2139/ssrn.6823940
-
[29]
Maxime Robeyns, Martin Szummer, and Laurence Aitchison. A self-improving coding agent. CoRR, abs/2504.15228, 2025
arXiv 2025
-
[30]
Joar Skalse, Nikolaus H. R. Howe, Dmitrii Krasheninnikov, and David Krueger. Defining and characterizing reward gaming. In NeurIPS, 2022
2022
-
[31]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Y onghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P . Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-judge with MT-bench and chatbot arena. In NeurIPS, 2023
2023
-
[32]
Length-controlled AlpacaEval: A simple debiasing of automatic evaluators
Y ann Dubois, Percy Liang, and Tatsunori Hashimoto. Length-controlled AlpacaEval: A simple debiasing of automatic evaluators. In First Conference on Language Modeling , 2024. URL https://openreview.net/forum?id=CybBmzWBX0
2024
-
[33]
Ashley, Wenyi Wang, Dmitrii Khizbullin, Yunyang Xiong, Zechun Liu, Ernie Chang, Raghuraman Krishnamoorthi, Yuandong Tian, Y angyang Shi, Vikas Chandra, and Jürgen Schmidhuber
Mingchen Zhuge, Changsheng Zhao, Dylan R. Ashley, Wenyi Wang, Dmitrii Khizbullin, Yunyang Xiong, Zechun Liu, Ernie Chang, Raghuraman Krishnamoorthi, Yuandong Tian, Y angyang Shi, Vikas Chandra, and Jürgen Schmidhuber. Agent-as-a-judge: Evaluate agents with agents. In ICML, volume 267 of Proceedings of Machine Learning Research . PMLR / OpenReview.net, 2025. 14
2025
-
[34]
Accelerating scientific discovery with Co-Scientist
Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Petar Sirkovic, Artiom Myaskovsky, Grzegorz Glowaty, Felix Weissenberger, Alessio Orlandi, Dan Popovici, et al. Accelerating scientific discovery with Co-Scientist. Nature, pages 1–3, 2026
2026
-
[35]
A multi-agent system for automating scientific discovery
Ali Essam Ghareeb, Benjamin Chang, Ludovico Mitchener, Angela Yiu, Caralyn J Szostkiewicz, Dmytro Shved, Gavin J Gyimesi, Jon M Laurent, Samantha M Wright, Muhammed T Razzak, et al. A multi-agent system for automating scientific discovery. Na- ture, pages 1–3, 2026
2026
-
[36]
Alexander Novikov, Ngân Vu, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. AlphaEvolve: A coding agent for sci- entific and algo...
Pith/arXiv arXiv 2025
-
[37]
Pawan Kumar, Emilien Dupont, Francisco J
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M. Pawan Kumar, Emilien Dupont, Francisco J. R. Ruiz, Jordan S. Ellenberg, Pengming Wang, Omar Fawzi, Pushmeet Kohli, and Alhussein Fawzi. Mathematical discoveries from program search with large language models. Nature, 625(7995):468–475, 2024
2024
-
[38]
Rosin and Richard K
Christopher D. Rosin and Richard K. Belew. New methods for competitive coevolution. Evol. Comput., 5(1):1–29, 1997
1997
-
[39]
Multi-agent learning with the success-story algorithm
Jürgen Schmidhuber and Jieyu Zhao. Multi-agent learning with the success-story algorithm. In ECAI Workshop LDAIS / ICMAS Workshop LIOME, volume 1221 of Lecture Notes in Computer Science, pages 82–93. Springer, 1996
1996
-
[40]
Mastering the game of Go with deep neural networks and tree search
David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. Mastering the game of Go with deep neural networks and tree search. Nature, 529(7587): 484–489, 2016
2016
-
[41]
David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, Timothy Lillicrap, Karen Simonyan, and Demis Hassabis. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science, 362(6419):1140–1144, 2018. doi: 10.112...
-
[42]
Multi-agent evolve: LLM self-improve through co-evolution
Yixing Chen, Yiding Wang, Siqi Zhu, Haofei Yu, Tao Feng, Muhan Zhang, Mostofa Pat- wary, and Jiaxuan Y ou. Multi-agent evolve: LLM self-improve through co-evolution. CoRR, abs/2510.23595, 2025
arXiv 2025
-
[43]
Group-evolving agents: Open-ended self-improvement via experience sharing
Zhaotian Weng, Antonis Antoniades, Deepak Nathani, Zhen Zhang, Xiao Pu, and Xin Eric Wang. Group-evolving agents: Open-ended self-improvement via experience sharing. CoRR, abs/2602.04837, 2026
arXiv 2026
- [44]
-
[45]
Stanley, Joel Lehman, and Lisa Soros
Kenneth O. Stanley, Joel Lehman, and Lisa Soros. Open-endedness: The last grand challenge you’ve never heard of. O’Reilly Radar (online arti- cle), December 2017. URL https://www.oreilly.com/radar/ open-endedness-the-last-grand-challenge-youve-never-heard-of/ . Accessed 2026-06-16
2017
-
[46]
Dennis, Jack Parker-Holder, Feryal M
Edward Hughes, Michael D. Dennis, Jack Parker-Holder, Feryal M. P . Behbahani, Aditi Mavalankar, Yuge Shi, Tom Schaul, and Tim Rocktäschel. Position: Open-endedness is es- sential for artificial superhuman intelligence. In ICML, volume 235 of Proceedings of Machine Learning Research, pages 20597–20616. PMLR / OpenReview.net, 2024
2024
-
[47]
Illuminating search spaces by mapping elites
Jean-Baptiste Mouret and Jeff Clune. Illuminating search spaces by mapping elites. CoRR, abs/1504.04909, 2015. 15
Pith/arXiv arXiv 2015
-
[48]
Adrien Ecoffet, Joost Huizinga, Joel Lehman, Kenneth O. Stanley, and Jeff Clune. Go-explore: a new approach for hard-exploration problems. CoRR, abs/1901.10995, 2019
arXiv 1901
-
[49]
Automated design of agentic systems
Shengran Hu, Cong Lu, and Jeff Clune. Automated design of agentic systems. In ICLR. Open- Review.net, 2025
2025
-
[50]
Jeff Clune. Ai-gas: Ai-generating algorithms, an alternate paradigm for producing general arti- ficial intelligence. CoRR, abs/1905.10985, 2019
arXiv 1905
-
[51]
Algorithms for infinitely many-armed bandits
Yizao Wang, Jean-yves Audibert, and Rémi Munos. Algorithms for infinitely many-armed bandits. In D. Koller, D. Schuurmans, Y . Bengio, and L. Bottou, editors, NeurIPS, volume 21, pages 1729–1736. Curran Associates, Inc., 2008
2008
-
[52]
CRA VE: Code Review Agent Verdict Evaluation
Li Zhang. CRA VE: Code Review Agent Verdict Evaluation. Hugging Face dataset,
-
[53]
Code review classification dataset from curated human code reviews
URL https://huggingface.co/datasets/TuringEnterprises/ CRAVE. Code review classification dataset from curated human code reviews
-
[54]
Jimenez, John Y ang, Alexander Wettig, Shunyu Y ao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Y ang, Alexander Wettig, Shunyu Y ao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? In ICLR. OpenReview.net, 2024
2024
-
[55]
Yichen Huang and Lin F. Y ang. Gemini 2.5 pro capable of winning gold at IMO 2025. CoRR, abs/2507.15855, 2025
arXiv 2025
-
[56]
Api pricing
OpenAI. Api pricing. https://openai.com/api/pricing/, 2026
2026
-
[57]
Anthropic. Pricing. https://platform.claude.com/docs/en/ about-claude/pricing, 2026
2026
-
[58]
Our First Proof Submissions
OpenAI. Our First Proof Submissions. https://openai.com/index/ first-proof-submissions/ , 2025. Gold-medal-level performance at the In- ternational Mathematical Olympiad 2025
2025
-
[59]
Spears, Derya Unutmaz, Kevin Weil, Steven Yin, and Nikita Zhivotovskiy
Sébastien Bubeck, Christian Coester, Ronen Eldan, Timothy Gowers, Yin Tat Lee, Alexandru Lupsasca, Mehtaab Sawhney, Robert Scherrer, Mark Sellke, Brian K. Spears, Derya Unutmaz, Kevin Weil, Steven Yin, and Nikita Zhivotovskiy. Early science acceleration experiments with GPT-5. CoRR, abs/2511.16072, 2025
arXiv 2025
-
[60]
Instruction-following evaluation for large language models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models. CoRR, abs/2311.07911, 2023
Pith/arXiv arXiv 2023
-
[61]
Fengqing Jiang, Yichen Feng, Yuetai Li, Luyao Niu, Basel Alomair, and Radha Poovendran. BadScientist: Can a research agent write convincing but unsound papers that fool LLM review- ers? CoRR, abs/2510.18003, 2025. 16 Table of Contents A Appendix Overview 17 B The Algorithm in Full 17 C Experimental Setup 18 C.1 Domains and Anchor pairs . . . . . . . . . ....
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.