Same Scrutiny, More Time: Eye Tracking Insights into Reviewing LLM-Labelled Code
Pith reviewed 2026-06-26 04:35 UTC · model grok-4.3
The pith
Reviewers fixate longer on code labeled as LLM-generated without increasing the thoroughness of their review.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
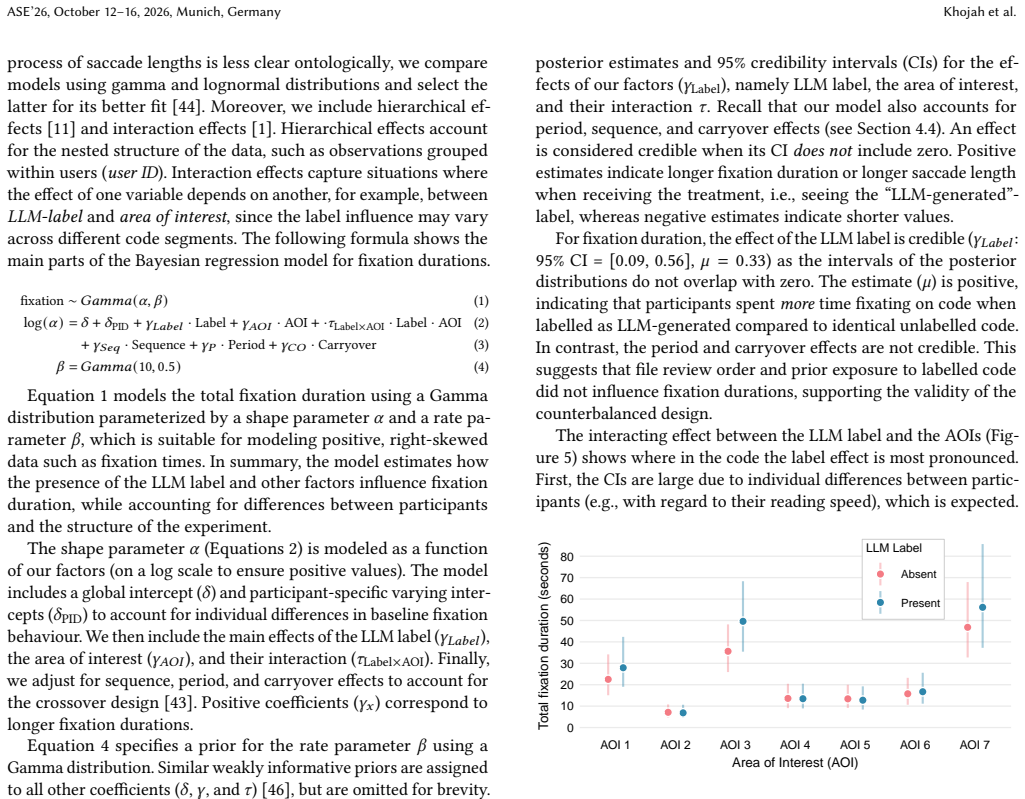
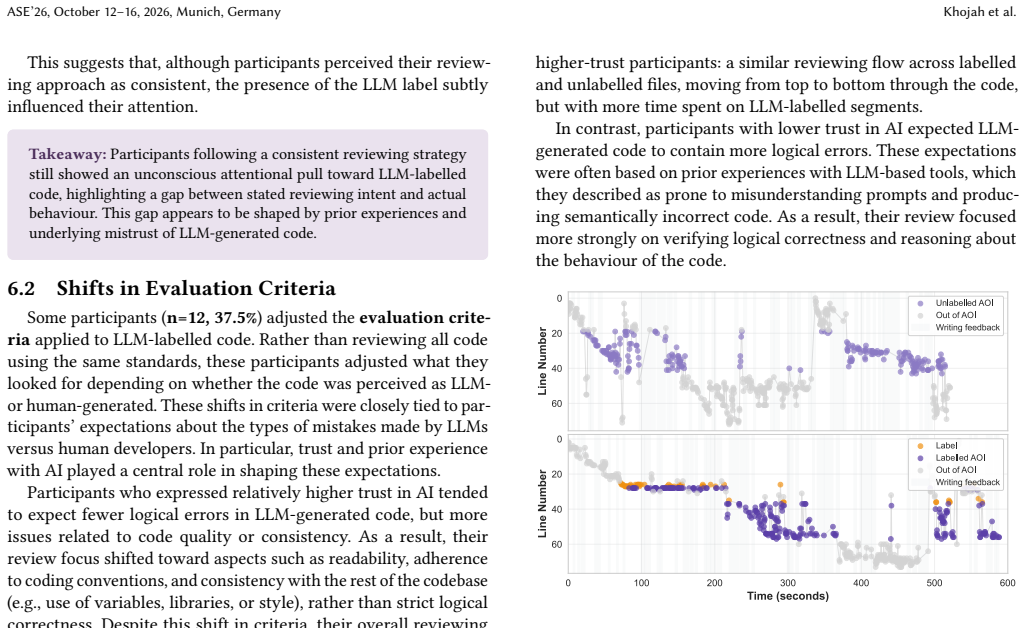
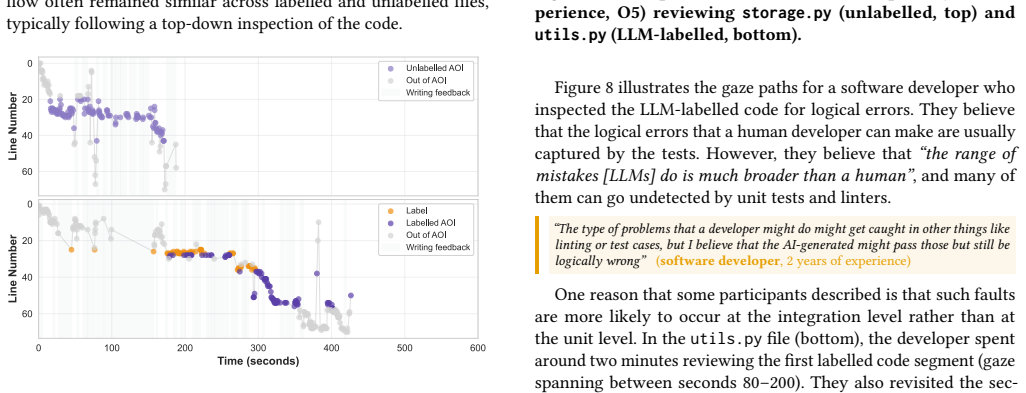
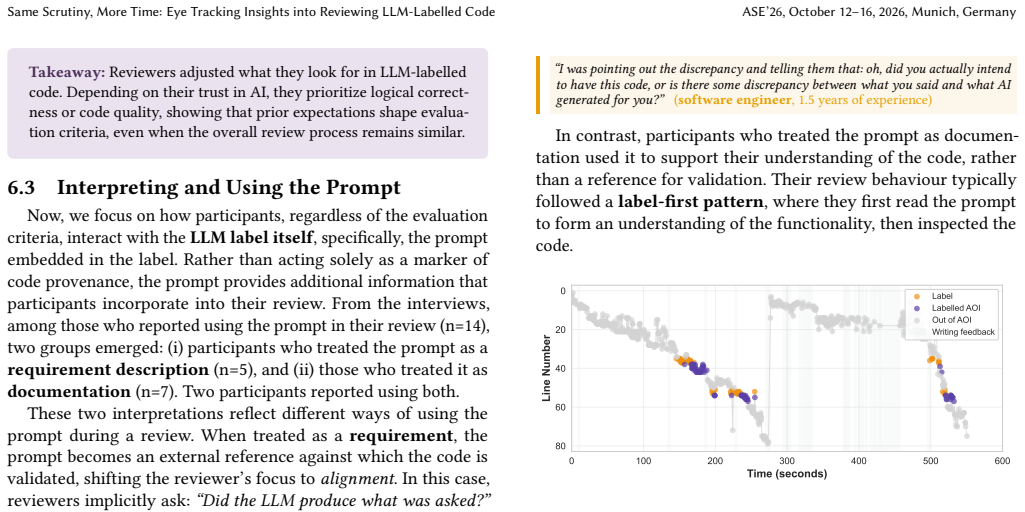
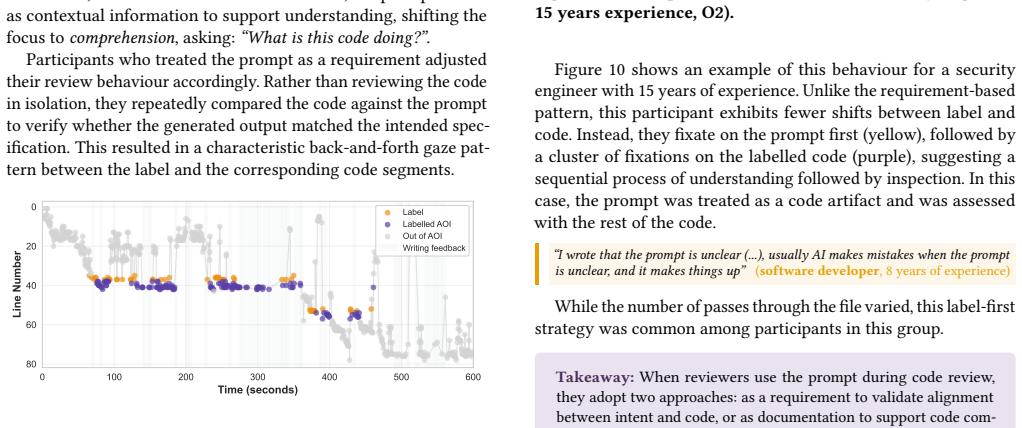
In the experiment, the LLM label increased fixation time on the code but left review thoroughness unchanged; participants adapted by evaluating logical correctness or using the prompt to guide inspection, showing that the label itself redirects attention during code review.
What carries the argument
Eye-tracking fixation duration on labeled versus unlabeled code segments, paired with qualitative interview data on review strategies.
If this is right
- An explicit LLM label alone is enough to increase visual attention during code review.
- Reviewers incorporate the original prompt as an extra artifact when inspecting labeled code.
- Software tools that label LLM output should account for this attention shift when presenting code to reviewers.
- Organizations may need to update policies on LLM-assisted development to address the observed difference between intended and actual review behavior.
Where Pith is reading between the lines
- The attention shift could be tested by comparing fixation patterns when reviewers know code came from an LLM but see no visible label.
- The same label effect might appear in review of other AI-generated artifacts such as documentation or test cases.
- Training programs could explicitly address how labels change attention allocation to reduce reliance on the label as a cue.
Load-bearing premise
The artificial Wizard-of-Oz labeling and eye-tracking task produce attention and review patterns that match real-world behavior with actual LLM-generated code.
What would settle it
A follow-up study in which the same code is reviewed once with an explicit LLM label and once without any label, checking whether the extra fixation time disappears when the label is removed.
Figures





read the original abstract
Modern software development increasingly involves the use of large language models (LLMs) to generate code. Despite their rapid advancement, LLMs remain prone to errors and hallucinations, emphasizing the importance of careful code inspection. However, in practice, developers' trust in LLM-generated code and their willingness to review it thoroughly may differ from these recommendations. How developers actually behave when reviewing LLM-generated code remains largely unexplored. In this study, we conduct a Wizard-of-Oz experiment to examine how software engineers behave when code is explicitly labeled as LLM-generated during a code review task. We collect both behavioral data and participant feedback through eye-tracking and exit interviews. Combining Bayesian data analysis with qualitative analysis, we found that while the thoroughness of code review did not change for participants, they spent more time fixating on LLM-labelled code, indicating that the label itself influences attention. Practitioners also adapted their review strategy for LLM-labelled code by assessing the code based on specific criteria (e.g., logical correctness), or using the prompt to guide their review. These findings inform LLM-based tool design on labelling while incorporating the prompt as a software artifact. Our study reveals a gap between reviewers' intentions and actual reviewing behaviour, highlighting the need for software companies to revisit their AI policies (particularly regarding LLM-assisted development) to better support developers in reviewing LLM-generated code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports a Wizard-of-Oz eye-tracking study in which software engineers reviewed code snippets that were explicitly labeled as LLM-generated. Using eye-tracking metrics, Bayesian analysis, and exit interviews, the authors claim that review thoroughness (e.g., coverage of code elements) did not differ from unlabeled code, yet participants allocated significantly more fixation time to the labeled items; they also report qualitative adaptations such as checking logical correctness or consulting the generating prompt.
Significance. If the increased fixation time can be unambiguously attributed to the LLM label rather than experimental demand, the result supplies concrete behavioral evidence on how explicit labeling affects attention allocation during code review. The combination of quantitative eye-tracking data with qualitative strategy descriptions and the suggestion to treat prompts as review artifacts would be useful for tool designers and policy makers.
major comments (2)
- [Methods / Experimental Protocol] Methods / Experimental Protocol: The design presents code with an overt 'LLM-generated' label inside a study whose purpose is known to participants and contains no control arm (e.g., unlabeled code, blinded labels, or a between-subjects condition that decouples label presence from study demand). Consequently the reported increase in fixation time cannot be attributed unambiguously to the label itself rather than to demand characteristics.
- [Results / Bayesian Analysis] Results / Bayesian Analysis: The abstract and summary state that 'thoroughness of code review did not change' and that fixation time increased, yet no participant count, exclusion criteria, statistical outputs (e.g., posterior probabilities, effect sizes, or model specifications), or power considerations are supplied in the abstract or referenced in the provided summary, preventing evaluation of whether the data support the central claim.
minor comments (2)
- [Abstract] Abstract: The abstract states the main findings but supplies no participant count, statistical outputs, exclusion criteria, or controls, which should be added for completeness even if the full paper contains them.
- [Introduction / Methods] Notation: The term 'thoroughness' is used without an explicit operational definition (e.g., number of code elements inspected, time per element, or coverage metric) before the results are presented.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. Below we respond point-by-point to the major comments and indicate planned revisions.
read point-by-point responses
-
Referee: [Methods / Experimental Protocol] The design presents code with an overt 'LLM-generated' label inside a study whose purpose is known to participants and contains no control arm (e.g., unlabeled code, blinded labels, or a between-subjects condition that decouples label presence from study demand). Consequently the reported increase in fixation time cannot be attributed unambiguously to the label itself rather than to demand characteristics.
Authors: We agree that demand characteristics are a valid concern given the overt labeling and participants' knowledge of the study focus. Our protocol used a within-subjects design in which each participant reviewed both LLM-labeled and unlabeled snippets in counterbalanced order, providing a direct comparison of fixation time and thoroughness. Nevertheless, we will revise the manuscript to add an explicit discussion of demand characteristics as a limitation, including how the within-subjects comparison and exit-interview data help interpret the results. We will also expand the Methods section with further protocol details on label presentation and task sequencing. revision: partial
-
Referee: [Results / Bayesian Analysis] The abstract and summary state that 'thoroughness of code review did not change' and that fixation time increased, yet no participant count, exclusion criteria, statistical outputs (e.g., posterior probabilities, effect sizes, or model specifications), or power considerations are supplied in the abstract or referenced in the provided summary, preventing evaluation of whether the data support the central claim.
Authors: We accept that the abstract would benefit from key quantitative indicators. In the revised version we will update the abstract to report the final participant count after exclusions, the direction and strength of the Bayesian evidence for increased fixation time on labeled code, and a cross-reference to the full model specifications, effect sizes, and power analysis already present in the Methods and Results sections. revision: yes
Circularity Check
No circularity: purely empirical eye-tracking study
full rationale
The paper conducts a Wizard-of-Oz eye-tracking experiment, collects fixation data and interview responses, and applies standard Bayesian analysis plus qualitative coding. No equations, fitted parameters, predictions, or derivations are present. No self-citations are invoked as load-bearing premises for any result. The central claim (increased fixation time on labelled code) is a direct report of observed measurements, not a reduction to prior inputs by construction. This is a standard empirical reporting structure with no circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Eye fixation duration serves as a valid proxy for attention allocation and cognitive processing during code review.
Reference graph
Works this paper leans on
-
[1]
Herman Aguinis and Ryan K Gottfredson. 2010. Best-practice recommendations for estimating interaction effects using moderated multiple regression.Journal of organizational behavior31, 6 (2010), 776–786. doi:10.1002/job.686
-
[2]
Thorsten-V oice Dataset 2022.10,
Anonymous. 2026. Replication package for the paper "Same Scrutiny, More Time: Eye Tracking Insights into Reviewing LLM-Labelled Code". doi:10.5281/zenodo. 19238394
-
[3]
Alberto Bacchelli and Christian Bird. 2013. Expectations, outcomes, and chal- lenges of modern code review. In2013 35th International Conference on Software Engineering (ICSE). IEEE, San Francisco, CA, USA, 712–721. doi:10.1109/ICSE. 2013.6606617
-
[4]
Sebastian Baltes, Timo Speith, Brenda Chiteri, Seyedmoein Mohsenimofidi, Shalini Chakraborty, and Daniel Buschek. 2026. On the Need to Rethink Trust in AI Assistants for Software Development: A Critical Review.IEEE Transactions on Software Engineering(2026), 1–18. doi:10.1109/TSE.2026.3659804
-
[5]
Moritz Beller, Alberto Bacchelli, Andy Zaidman, and Elmar Juergens. 2014. Mod- ern code reviews in open-source projects: which problems do they fix?. InProceed- ings of the 11th Working Conference on Mining Software Repositories(Hyderabad, India)(MSR 2014). Association for Computing Machinery, New York, NY, USA, 202–211. doi:10.1145/2597073.2597082
-
[6]
Niels Ole Bernsen, Hans Dybkjær, and Laila Dybkjær. 1994. Wizard of oz pro- totyping: How and when.Proc. CCI Working Papers Cognit. Sci./HCI, Roskilde, Denmark(1994), 67
1994
-
[7]
Ian Bertram, Jack Hong, Yu Huang, Westley Weimer, and Zohreh Sharafi
-
[8]
Trustworthiness Perceptions in Code Review: An Eye-tracking Study. InProceedings of the 14th ACM / IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM)(Bari, Italy)(ESEM ’20). Asso- ciation for Computing Machinery, New York, NY, USA, Article 31, 6 pages. doi:10.1145/3382494.3422164
-
[9]
Ralf Biedert, Jörn Hees, Andreas Dengel, and Georg Buscher. 2012. A ro- bust realtime reading-skimming classifier. InProceedings of the Symposium on Eye Tracking Research and Applications(Santa Barbara, California)(ETRA ’12). Association for Computing Machinery, New York, NY, USA, 123–130. doi:10.1145/2168556.2168575
-
[10]
K R Chandrika, J Amudha, and Sithu D Sudarsan. 2017. Recognizing eye tracking traits for source code review. In2017 22nd IEEE International Conference on Emerging Technologies and Factory Automation (ETFA). IEEE, San Francisco, CA, USA, 1–8. doi:10.1109/ETFA.2017.8247637
-
[11]
Carlos Cinelli, Andrew Forney, and Judea Pearl. 2024. A crash course in good and bad controls.Sociological Methods & Research53, 3 (2024), 1071–1104. doi:10. 1177/00491241221099552
2024
-
[12]
Neil A Ernst. 2018. Bayesian hierarchical modelling for tailoring metric thresholds. InProceedings of the 15th international conference on mining software repositories. Association for Computing Machinery, New York, NY, USA, 587–591. doi:10. 1145/3196398.3196443
arXiv 2018
-
[13]
Samuel Ferino, Rashina Hoda, John Grundy, and Christoph Treude. 2025. Walking the Tightrope of LLMs for Software Development: A Practitioners’ Perspective. arXiv:2511.06428 [cs.SE] https://arxiv.org/abs/2511.06428
Pith/arXiv arXiv 2025
-
[14]
Julian Frattini, Davide Fucci, and Sira Vegas. 2024. Crossover Designs in Software Engineering Experiments: Review of the State of Analysis. In2024 ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM). ACM, Association for Computing Machinery, New York, NY, USA, 482–
2024
-
[15]
doi:10.1145/3674805.3690754
-
[16]
Carlo A Furia, Robert Feldt, and Richard Torkar. 2019. Bayesian data analy- sis in empirical software engineering research.IEEE Transactions on Software Engineering47, 9 (2019), 1786–1810. doi:10.1109/TSE.2019.2935974
-
[17]
Carlo A Furia, Richard Torkar, and Robert Feldt. 2023. Towards causal analysis of empirical software engineering data: The impact of programming languages on coding competitions.ACM Transactions on Software Engineering and Methodology 33, 1 (2023), 1–35. doi:10.1145/3611667
-
[18]
Andrew Gelman and Donald B Rubin. 1992. Inference from iterative simulation using multiple sequences.Statistical science7, 4 (1992), 457–472. doi:10.1214/ss/ 1177011136
work page doi:10.1214/ss/ 1992
-
[19]
M Maria Glymour, Sander Greenland, et al . 2008. Causal diagrams.Modern epidemiology3 (2008), 183–209
2008
-
[20]
Maletic, Unaizah Obaidellah, Kang-il Park, Bonita Sharif, Zohreh Sharafi, Lynsay Shepherd, and Jürgen Mottok
Lisa Grabinger, Naser Al Madi, Roman Bednarik, Teresa Busjahn, Fabian Engl, Timur Ezer, Hans Gruber, Florian Hauser, Jonathan I. Maletic, Unaizah Obaidellah, Kang-il Park, Bonita Sharif, Zohreh Sharafi, Lynsay Shepherd, and Jürgen Mottok
-
[21]
InProceedings of the 6th European Conference on Software Engineering Education (ECSEE ’25)
A Cookbook for Eye Tracking in Software Engineering. InProceedings of the 6th European Conference on Software Engineering Education (ECSEE ’25). Association for Computing Machinery, New York, NY, USA, 60–76. doi:10.1145/ 3723010.3723018
-
[22]
Lucas Gren and Richard Berntsson Svensson. 2021. Is it possible to disregard obsolete requirements? a family of experiments in software effort estimation. Requirements Engineering26, 3 (2021), 459–480. doi:10.1007/s00766-021-00351-7
-
[23]
Lo Gullstrand Heander, Emma Söderberg, and Christofer Rydenfält. 2026. Code review as decision-making - building a cognitive model from the questions asked ASE’26, October 12–16, 2026, Munich, Germany Khojah et al. during code review.Empirical Software Engineering31, 3 (Jan. 2026), 41 pages. doi:10.1007/s10664-025-10791-2
-
[24]
2025.Support, Not Automation: Towards AI-supported Code Review For Code Quality and Beyond
Lo Heander, Emma Söderberg, and Christofer Rydenfält. 2025.Support, Not Automation: Towards AI-supported Code Review For Code Quality and Beyond. Association for Computing Machinery, New York, NY, USA, 591–595. https: //doi.org/10.1145/3696630.3728505
-
[25]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2024. Large Language Models for Software Engineering: A Systematic Literature Review.ACM Trans. Softw. Eng. Methodol.33, 8, Article 220 (Dec. 2024), 79 pages. doi:10.1145/3695988
-
[26]
Edwin T. Jaynes. 2012.Probability Theory: The Logic of Science. Cambridge University Press. doi:10.1017/cbO9780511790423
-
[27]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real- World GitHub Issues? arXiv:2310.06770 [cs.CL] https://arxiv.org/abs/2310.06770
Pith/arXiv arXiv 2024
-
[28]
Ranim Khojah, Mazen Mohamad, Linda Erlenhov, Francisco Gomes de Oliveira Neto, and Philipp Leitner. 2026. Large Language Model Company Poli- cies and Policy Implications in Software Organizations.IEEE Software43, 1 (2026), 64–72. doi:10.1109/MS.2025.3622039
-
[29]
Ranim Khojah, Mazen Mohamad, Philipp Leitner, and Francisco Gomes de Oliveira Neto. 2024. Beyond Code Generation: An Observational Study of Chat- GPT Usage in Software Engineering Practice.Proc. ACM Softw. Eng.1, FSE, Article 81 (July 2024), 22 pages. doi:10.1145/3660788
-
[30]
Lyu, Baishakhi Ray, Abhik Roychoudhury, Shin Hwei Tan, and Patana- mon Thongtanunam
Michael R. Lyu, Baishakhi Ray, Abhik Roychoudhury, Shin Hwei Tan, and Patana- mon Thongtanunam. 2025. Automatic Programming: Large Language Models and Beyond.ACM Trans. Softw. Eng. Methodol.34, 5, Article 140 (May 2025), 33 pages. doi:10.1145/3708519
-
[31]
Henrique Marques, Nuno Laranjeiro, and Jorge Bernardino. 2021. Injecting software faults in Python applications.Empirical Software Engineering27, 1 (2021), 20. doi:10.1007/s10664-021-10047-9
-
[32]
2009.Clean code: a handbook of agile software craftsmanship
Robert C Martin. 2009.Clean code: a handbook of agile software craftsmanship. Pearson Education, Hoboken, NJ, USA
2009
-
[33]
Roger C Mayer, James H Davis, and F David Schoorman. 1995. An integrative model of organizational trust.Academy of management review20, 3 (1995), 709–734
1995
-
[34]
2018.Statistical rethinking: A Bayesian course with examples in R and Stan
Richard McElreath. 2018.Statistical rethinking: A Bayesian course with examples in R and Stan. Chapman and Hall/CRC, Boca Raton, FL, USA. doi:10.1201/ 9781315372495
2018
-
[35]
Bhaswati Mukherjee, Ashutosh Gupta, and SK Upadhyay. 2010. A Bayesian study for the comparison of generalized gamma model with its components.Sankhya B72, 2 (2010), 154–174
2010
-
[36]
Nadia Nahar, Christian Kästner, Jenna Butler, Chris Parnin, Thomas Zimmer- mann., and Christian Bird. 2025. Beyond the Comfort Zone: Emerging Solutions to Overcome Challenges in Integrating LLMs into Software Products. In2025 IEEE/ACM 47th International Conference on Software Engineering: Software Engi- neering in Practice (ICSE-SEIP). Association for Com...
-
[37]
Kang-il Park, Jack Johnson, Cole S Peterson, Nishitha Yedla, Isaac Baysinger, Jairo Aponte, and Bonita Sharif. 2024. An eye tracking study assessing source code readability rules for program comprehension.Empirical Software Engineering29, 6 (2024), 160
2024
-
[38]
Luca Pascarella, Davide Spadini, Fabio Palomba, Magiel Bruntink, and Alberto Bacchelli. 2018. Information Needs in Contemporary Code Review.Proc. ACM Hum.-Comput. Interact.2, CSCW, Article 135 (Nov. 2018), 27 pages. doi:10.1145/ 3274404
2018
-
[39]
J. Pearl. 2009.Causality. Cambridge University Press, Cambridge, UK. https: //books.google.se/books?id=f4nuexsNVZIC
2009
-
[40]
Keith Rayner. 2009. Eye movements and attention in reading, scene perception, and visual search.The quarterly journal of experimental psychology62, 8 (2009), 1457–1506
2009
-
[41]
Laurel D. Riek. 2012. Wizard of Oz studies in HRI: a systematic review and new reporting guidelines.J. Hum.-Robot Interact.1, 1 (July 2012), 119–136. doi:10.5898/JHRI.1.1.Riek
-
[42]
Julien Siebert. 2023. Applications of statistical causal inference in software engineering.Information and Software Technology159 (2023), 107198. doi:10. 1016/j.infsof.2023.107198
arXiv 2023
-
[43]
Auste Simkute, Lev Tankelevitch, Viktor Kewenig, Ava Elizabeth Scott, Abi- gail Sellen, and Sean Rintel. 2025. Ironies of Generative AI: Understand- ing and Mitigating Productivity Loss in Human-AI Interaction.Inter- national Journal of Human–Computer Interaction41, 5 (2025), 2898–2919. arXiv:https://doi.org/10.1080/10447318.2024.2405782 doi:10.1080/10447...
-
[44]
Ningzhi Tang, Junwen An, Meng Chen, Aakash Bansal, Yu Huang, Collin McMil- lan, and Toby Jia-Jun Li. 2024. CodeGRITS: A Research Toolkit for Developer Behavior and Eye Tracking in IDE. InProceedings of the 2024 IEEE/ACM 46th International Conference on Software Engineering: Companion Proceedings(Lisbon, Portugal)(ICSE-Companion ’24). Association for Compu...
-
[45]
Ningzhi Tang, Meng Chen, Zheng Ning, Aakash Bansal, Yu Huang, Collin McMil- lan, and Toby Jia-Jun Li. 2024. Developer Behaviors in Validating and Repairing LLM-Generated Code Using IDE and Eye Tracking. In2024 IEEE Symposium on Visual Languages and Human-Centric Computing (VL/HCC). IEEE, San Francisco, CA, USA, 40–46. doi:10.1109/VL/HCC60511.2024.00015
-
[46]
Sira Vegas, Cecilia Apa, and Natalia Juristo. 2016. Crossover Designs in Software Engineering Experiments: Benefits and Perils.IEEE Transactions on Software Engineering42, 2 (2016), 120–135. doi:10.1109/TSE.2015.2467378
-
[47]
Aki Vehtari, Andrew Gelman, and Jonah Gabry. 2017. Practical Bayesian model evaluation using leave-one-out cross-validation and WAIC.Statistics and com- puting27 (2017), 1413–1432. doi:10.1007/s11222-016-9696-4
-
[48]
Miku Watanabe, Hao Li, Yutaro Kashiwa, Brittany Reid, Hajimu Iida, and Ahmed E. Hassan. 2026. On the Use of Agentic Coding: An Empirical Study of Pull Requests on GitHub.ACM Trans. Softw. Eng. Methodol.(March 2026). doi:10.1145/3798166 Just Accepted
-
[49]
Jeff S. Wesner and Justin P.F. Pomeranz. 2021. Choosing priors in Bayesian ecological models by simulating from the prior predictive distribution.Ecosphere 12, 9 (2021), e03739:1–e03739:11. doi:10.1002/ecs2.3739
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.