Perception, Verdict, and Evolution: Hindsight-Driven Self-Refining Forensics Agent for AI-Generated Image Detection
Pith reviewed 2026-06-26 05:23 UTC · model grok-4.3
The pith
ForeAgent evolves its forensic reasoning by reflecting on mistakes with ground-truth hindsight to improve AI-generated image detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
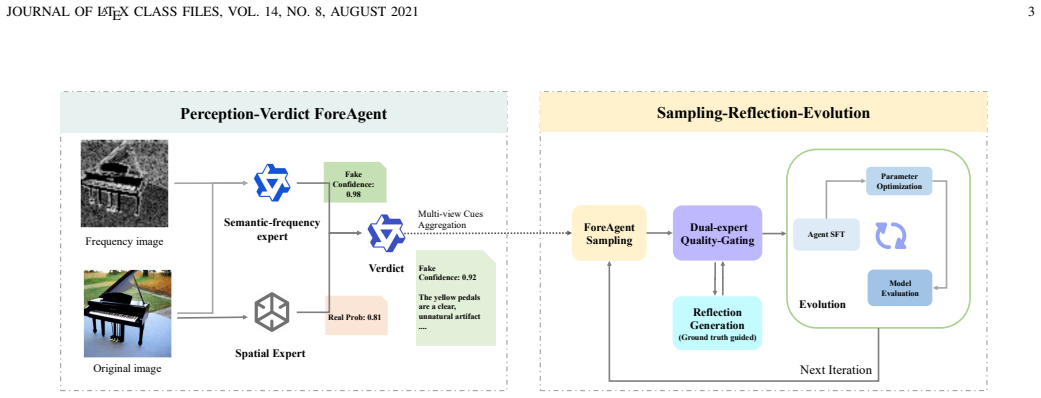
ForeAgent adopts a Perception-Verdict architecture that aggregates multi-view cues spanning semantic, spatial, and frequency-domain features, and leverages an MLLM as a verdict module to fuse these signals for a logical-grounded verdict. It then uses a Hindsight-Driven Self-Refining strategy following a Sampling-Reflection-Evolution paradigm where the agent performs inference rollouts on training instances, reflects on failure cases guided by ground-truth labels, regenerates higher-quality reasoning traces, filters them through a dual-expert quality gating module, and continuously evolves via fine-tuning on self-curated high-quality samples, reaching 82.18% accuracy on Chameleon and 93.3% me
What carries the argument
Hindsight-Driven Self-Refining strategy following a Sampling-Reflection-Evolution paradigm, where ground-truth labels guide reflection on failure cases to regenerate higher-quality reasoning traces that are filtered by dual-expert quality gating before fine-tuning.
If this is right
- The agent produces more consistent and causally grounded reasoning compared to GPT-5 and GPT-5-mini.
- It achieves state-of-the-art accuracy of 82.18% on the Chameleon benchmark, a gain of 16.41% over AIDE.
- It reaches 93.3% mean accuracy across 16 generators on the AIGCDetect-Benchmark.
- The framework supports continual self-improvement by fine-tuning on self-curated high-quality samples.
Where Pith is reading between the lines
- This self-evolution loop could reduce dependence on large external labeled datasets if the curated traces transfer well.
- The same reflection and gating process might apply to other reasoning tasks where errors can be identified after the fact.
- Multiple rounds of evolution risk compounding any initial biases if the gating mechanism favors certain reasoning styles.
- Real-world deployment without reliable ground truth would need an alternative source of hindsight to continue the process.
Load-bearing premise
Ground-truth labels used as hindsight during reflection will produce reasoning traces that generalize beyond the training distribution and the dual-expert quality gating will reliably filter out low-quality samples without introducing new selection artifacts.
What would settle it
If testing on images from a generator absent from the training and reflection data shows that the evolved agent's accuracy does not exceed the initial non-evolving model or other baselines, the claim would be falsified.
Figures



read the original abstract
The rapid advancement of generative models presents a significant challenge to existing deepfake detection methods, particularly given the widespread dissemination of highly realistic AI-generated images. Although Multimodal Large Language Models (MLLMs) show strong potential for this task, existing approaches suffer from two key limitations: insufficient sensitivity to fine-grained forensic artifacts and reliance on static synthetic supervision from frontier models, leading to limited flexibility and high-cost. To address these issues, we propose ForeAgent, an agentic forensics framework for AI-generated image detection with iterative self-evolution. First, ForeAgent adopts a Perception-Verdict architecture that aggregates multi-view cues spanning semantic, spatial, and frequency-domain features, and leverages an MLLM as a verdict module to fuse these signals for a logical-grounded verdict. Second, to enable continual self-improvement, we introduce a Hindsight-Driven Self-Refining strategy following a Sampling-Reflection-Evolution paradigm. The agent performs inference rollouts on training instances. Guided by ground-truth labels as hindsight, it reflects on failure cases and low-quality reasoning trajectories to regenerate higher-quality reasoning traces. These synthesized samples are then strictly filtered through a dual-expert quality gating module. ForeAgent continuously evolves via fine-tuning on self-curated high-quality samples. Extensive experiments demonstrate that ForeAgent achieves state-of-the-art performance on the Chameleon benchmark, reaching 82.18% accuracy (+16.41% over AIDE), and achieves 93.3% mean accuracy on AIGCDetect-Benchmark across 16 generators. In addition, external evaluation shows that ForeAgent produces more consistent and causally grounded reasoning compared to GPT-5 and GPT-5-mini.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ForeAgent, an agentic framework for AI-generated image detection. It introduces a Perception-Verdict architecture that aggregates semantic, spatial, and frequency-domain cues and uses an MLLM as a verdict module for logical fusion. A Hindsight-Driven Self-Refining strategy is presented under a Sampling-Reflection-Evolution paradigm: inference rollouts on training data, reflection guided by ground-truth labels to regenerate reasoning traces, dual-expert quality gating to filter samples, and iterative fine-tuning for self-evolution. The paper claims state-of-the-art results of 82.18% accuracy on the Chameleon benchmark (+16.41% over AIDE) and 93.3% mean accuracy across 16 generators on AIGCDetect-Benchmark, plus superior reasoning consistency versus GPT-5 models.
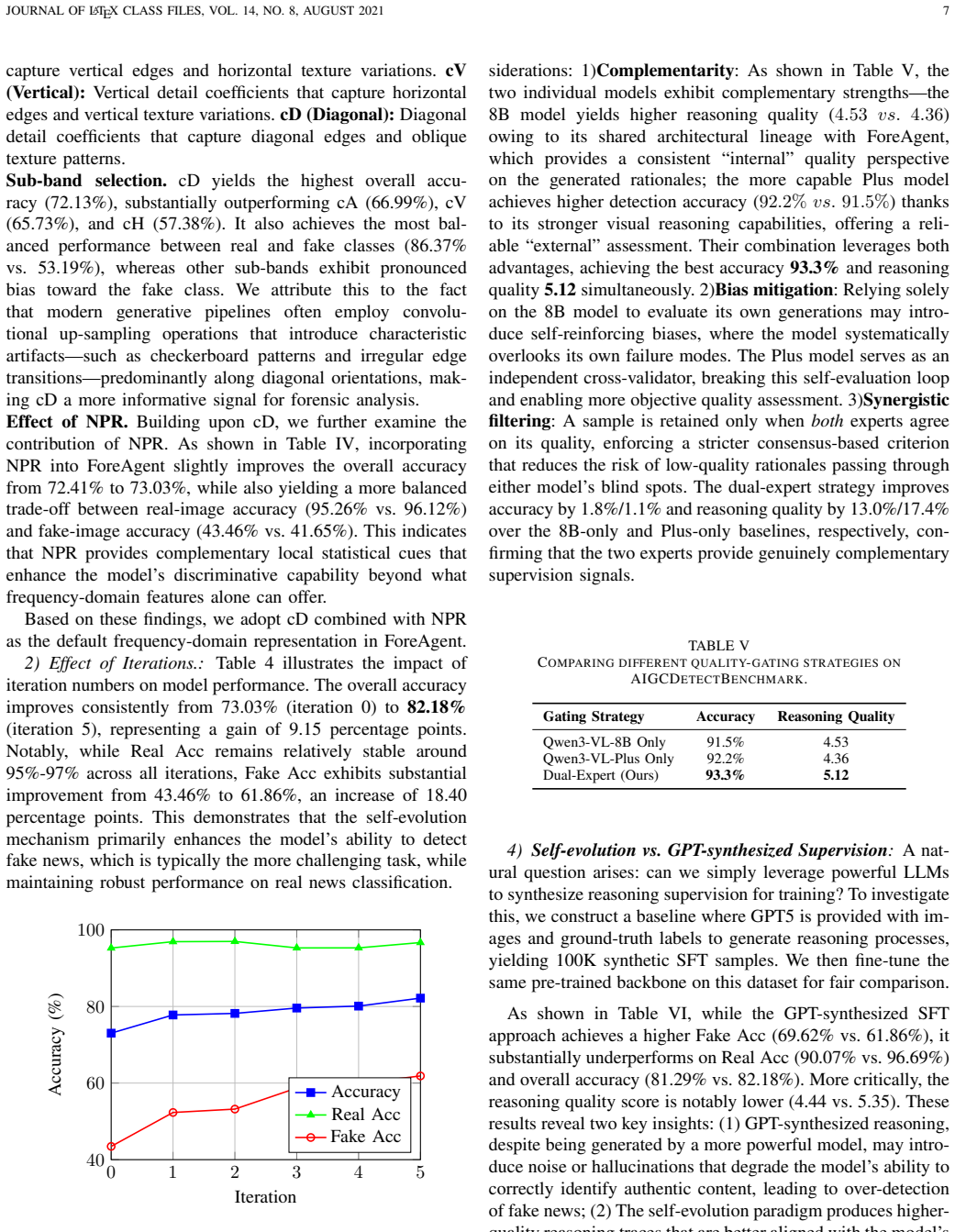
Significance. If the self-refining loop produces reasoning traces that generalize without ground-truth access at test time, the framework could reduce reliance on static frontier-model supervision and enable continual improvement in MLLM-based forensics. The dual-expert gating and multi-view perception are potentially load-bearing innovations, but the absence of any derivation, ablation, or validation details for these components prevents assessment of whether the reported gains are attributable to the method rather than curation artifacts.
major comments (2)
- [Abstract] Abstract: The central performance claims (82.18% on Chameleon, 93.3% mean on AIGCDetect-Benchmark) and the assertion of 'more consistent and causally grounded reasoning' are stated without any experimental setup, baseline descriptions, ablation studies, error bars, or validation of the dual-expert gating and reflection steps. This renders the contribution of the Hindsight-Driven Self-Refining strategy impossible to evaluate from the provided text.
- [Abstract] Abstract, paragraph on Hindsight-Driven Self-Refining strategy: The reflection step is explicitly guided by ground-truth labels on training instances, yet no experiments or analysis are described that test whether the synthesized traces improve detection on unseen generators once hindsight is removed at inference time. This leaves the generalization claim vulnerable to label leakage or selection bias from the dual-expert filter, directly undermining the SOTA attribution.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications drawn from the full manuscript and indicate planned revisions to improve transparency around experimental details and generalization.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims (82.18% on Chameleon, 93.3% mean on AIGCDetect-Benchmark) and the assertion of 'more consistent and causally grounded reasoning' are stated without any experimental setup, baseline descriptions, ablation studies, error bars, or validation of the dual-expert gating and reflection steps. This renders the contribution of the Hindsight-Driven Self-Refining strategy impossible to evaluate from the provided text.
Authors: The abstract is kept concise per typical length constraints, but the full manuscript provides the requested details in Section 4: experimental setup (datasets, splits, and protocols in 4.1), baselines including AIDE (4.2), ablation studies on Perception-Verdict multi-view fusion and dual-expert gating (Tables 2–3 in 4.3), error bars from three independent runs, and reasoning consistency evaluation via human raters and GPT-4o judge (4.4). We will revise the abstract to briefly reference these validations. revision: yes
-
Referee: [Abstract] Abstract, paragraph on Hindsight-Driven Self-Refining strategy: The reflection step is explicitly guided by ground-truth labels on training instances, yet no experiments or analysis are described that test whether the synthesized traces improve detection on unseen generators once hindsight is removed at inference time. This leaves the generalization claim vulnerable to label leakage or selection bias from the dual-expert filter, directly undermining the SOTA attribution.
Authors: Ground-truth labels are used only during the training-phase Sampling-Reflection-Evolution loop to curate improved traces; at inference the evolved model operates without any hindsight or labels. The AIGCDetect-Benchmark results use 16 generators with self-refining performed on a training subset and evaluation on held-out generators, providing evidence of generalization. To directly quantify the contribution of the synthesized traces, we will add an ablation comparing models trained with versus without the hindsight-driven samples on unseen generators. revision: partial
Circularity Check
No significant circularity; derivation is self-contained against external benchmarks
full rationale
The paper describes a Perception-Verdict architecture plus Hindsight-Driven Self-Refining (Sampling-Reflection-Evolution) that uses ground-truth labels only during the training-phase reflection step, followed by dual-expert filtering and fine-tuning. Performance is then reported on external benchmarks (Chameleon, AIGCDetect-Benchmark across 16 generators). No equations, self-citations, or internal definitions are shown that reduce the claimed accuracy gains to a fit or renaming of the training inputs themselves. The method is a standard form of label-guided self-improvement evaluated on held-out data; the derivation chain therefore remains independent of the target metrics.
Axiom & Free-Parameter Ledger
free parameters (2)
- dual-expert quality gating thresholds
- reflection prompt templates and rollout count
axioms (1)
- domain assumption MLLM can reliably fuse semantic, spatial, and frequency-domain cues into a logically grounded verdict
Reference graph
Works this paper leans on
-
[1]
Generative adversarial nets,
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde- Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial nets,” inAdvances in Neural Information Processing Systems, Z. Ghahramani, M. Welling, C. Cortes, N. Lawrence, and K. Weinberger, Eds., vol. 27. Curran Associates, Inc.,
-
[2]
Available: https://proceedings.neurips.cc/paper files/ paper/2014/file/f033ed80deb0234979a61f95710dbe25-Paper.pdf
[Online]. Available: https://proceedings.neurips.cc/paper files/ paper/2014/file/f033ed80deb0234979a61f95710dbe25-Paper.pdf
2014
-
[3]
Denoising diffusion probabilistic mod- els,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic mod- els,” inProceedings of the 34th International Conference on Neural Information Processing Systems, ser. NIPS ’20. Red Hook, NY , USA: Curran Associates Inc., 2020
2020
-
[4]
Autoregressive image generation without vector quantization,
T. Li, Y . Tian, H. Li, M. Deng, and K. He, “Autoregressive image generation without vector quantization,” inThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. [Online]. Available: https://openreview.net/forum?id=VNBIF0gmkb
2024
-
[5]
Visual autoregressive modeling: Scalable image generation via next-scale prediction,
K. Tian, Y . Jiang, Z. Yuan, B. PENG, and L. Wang, “Visual autoregressive modeling: Scalable image generation via next-scale prediction,” inThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. [Online]. Available: https: //openreview.net/forum?id=gojL67CfS8
2024
-
[6]
Fighting fake news: Image splice detection via learned self-consistency,
M. Huh, A. Liu, A. Owens, and A. A. Efros, “Fighting fake news: Image splice detection via learned self-consistency,” inProceedings of the European Conference on Computer Vision (ECCV), September 2018
2018
-
[7]
Copyright protection in generative ai: A technical perspective,
J. Ren, H. Xu, P. He, Y . Cui, S. Zeng, J. Zhang, H. Wen, J. Ding, P. Huang, L. Lyu, H. Liu, Y . Chang, and J. Tang, “Copyright protection in generative ai: A technical perspective,” 2024. [Online]. Available: https://arxiv.org/abs/2402.02333
-
[8]
Detecting gan-generated imagery using saturation cues,
S. McCloskey and M. Albright, “Detecting gan-generated imagery using saturation cues,” in2019 IEEE International Conference on Image Processing (ICIP), 2019, pp. 4584–4588
2019
-
[9]
Cnn- generated images are surprisingly easy to spot...for now,
S.-Y . Wang, O. Wang, R. Zhang, A. Owens, and A. A. Efros, “Cnn- generated images are surprisingly easy to spot...for now,” inCVPR, 2020
2020
-
[10]
Leveraging frequency analysis for deep fake image recogni- tion,
J. Frank, T. Eisenhofer, L. Sch ¨onherr, A. Fischer, D. Kolossa, and T. Holz, “Leveraging frequency analysis for deep fake image recogni- tion,” inProceedings of the 37th International Conference on Machine Learning, ser. ICML’20. JMLR.org, 2020
2020
-
[11]
Progressive growing of GANs for improved quality, stability, and variation,
T. Karras, T. Aila, S. Laine, and J. Lehtinen, “Progressive growing of GANs for improved quality, stability, and variation,” inInternational Conference on Learning Representations, 2018. [Online]. Available: https://openreview.net/forum?id=Hk99zCeAb
2018
-
[12]
Orthogonal subspace decomposition for generalizable AI-generated image detection,
Z. Yan, J. Wang, P. Jin, K.-Y . Zhang, C. Liu, S. Chen, T. Yao, S. Ding, B. Wu, and L. Yuan, “Orthogonal subspace decomposition for generalizable AI-generated image detection,” inForty-second International Conference on Machine Learning, 2025. [Online]. Available: https://openreview.net/forum?id=GFpjO8S8Po
2025
-
[13]
Rethinking the up-sampling operations in cnn-based generative network for gener- alizable deepfake detection,
C. Tan, H. Liu, Y . Zhao, S. Wei, G. Gu, P. Liu, and Y . Wei, “Rethinking the up-sampling operations in cnn-based generative network for gener- alizable deepfake detection,” 2023
2023
-
[14]
A sanity check for AI-generated image detection,
S. Yan, O. Li, J. Cai, Y . Hao, X. Jiang, Y . Hu, and W. Xie, “A sanity check for AI-generated image detection,” inThe Thirteenth International Conference on Learning Representations, 2025. [Online]. Available: https://openreview.net/forum?id=ODRHZrkOQM
2025
-
[15]
SIDA: social media image deepfake detection, localization and explanation with large multimodal model,
Z. Huang, J. Hu, X. Li, Y . He, X. Zhao, B. Peng, B. Wu, X. Huang, and G. Cheng, “SIDA: social media image deepfake detection, localization and explanation with large multimodal model,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR) 2025, 2025
2025
-
[16]
Toward Generalizable Forgery Detection and Reasoning
Y . Gao, D. Chang, B. Yu, H. Qin, M. Diao, L. Chen, K. Liang, and Z. Ma, “Towards generalizable forgery detection and reasoning,” 2025. [Online]. Available: https://arxiv.org/abs/2503.21210
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Research about the ability of llm in the tamper-detection area,
X. Yang and J. Zhou, “Research about the ability of llm in the tamper-detection area,” 2024. [Online]. Available: https: //arxiv.org/abs/2401.13504
-
[18]
Common sense reasoning for deepfake detection,
Y . Zhang, B. Colman, X. Guo, A. Shahriyari, and G. Bharaj, “Common sense reasoning for deepfake detection,” 2024. [Online]. Available: https://arxiv.org/abs/2402.00126
-
[19]
Z. Zhou, Y . Luo, Y . Wu, K. Sun, J. Ji, K. Yan, S. Ding, X. Sun, Y . Wu, and R. Ji, “Aigi-holmes: Towards explainable and generalizable ai-generated image detection via multimodal large language models,” arXiv preprint arXiv:2507.02664, 2025
-
[20]
Legion: Learning to ground and explain for synthetic image detection,
H. Kang, S. Wen, Z. Wen, J. Ye, W. Li, P. Feng, B. Zhou, B. Wang, D. Lin, L. Zhanget al., “Legion: Learning to ground and explain for synthetic image detection,”arXiv preprint arXiv:2503.15264, 2025
-
[21]
P. Agrawal, S. Antoniak, E. B. Hanna, B. Bout, D. Chaplot, J. Chudnovsky, D. Costa, B. D. Monicault, S. Garg, T. Gervet, S. Ghosh, A. H ´eliou, P. Jacob, A. Q. Jiang, K. Khandelwal, T. Lacroix, G. Lample, D. L. Casas, T. Lavril, T. L. Scao, A. Lo, W. Marshall, L. Martin, A. Mensch, P. Muddireddy, V . Nemychnikova, M. Pellat, P. V . Platen, N. Raghuraman, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Fakeshield: Explainable image forgery detection and localization via multi-modal large language models,
Z. Xu, X. Zhang, R. Li, Z. Tang, Q. Huang, and J. Zhang, “Fakeshield: Explainable image forgery detection and localization via multi-modal large language models,” inInternational Conference on Learning Rep- resentations, 2025
2025
-
[23]
OpenAI, “Gpt-4o system card,” 2024. [Online]. Available: https: //arxiv.org/abs/2410.21276
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Fusing global and local features for generalized ai-synthesized image detection,
Y . Ju, S. Jia, L. Ke, H. Xue, K. Nagano, and S. Lyu, “Fusing global and local features for generalized ai-synthesized image detection,” in2022 IEEE International Conference on Image Processing (ICIP), 2022, pp. 3465–3469
2022
-
[25]
Detecting generated images by real images,
B. Liu, F. Yang, X. Bi, B. Xiao, W. Li, and X. Gao, “Detecting generated images by real images,” inComputer Vision – ECCV 2022, S. Avidan, G. Brostow, M. Ciss ´e, G. M. Farinella, and T. Hassner, Eds. Cham: Springer Nature Switzerland, 2022, pp. 95–110
2022
-
[26]
Learning on gradients: Generalized artifacts representation for gan-generated images detection,
C. Tan, Y . Zhao, S. Wei, G. Gu, and Y . Wei, “Learning on gradients: Generalized artifacts representation for gan-generated images detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 12 105–12 114
2023
-
[27]
Dire for diffusion-generated image detection,
Z. Wang, J. Bao, W. Zhou, W. Wang, H. Hu, H. Chen, and H. Li, “Dire for diffusion-generated image detection,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Oc- tober 2023, pp. 22 445–22 455
2023
-
[28]
Towards universal fake image detectors that generalize across generative models,
U. Ojha, Y . Li, and Y . J. Lee, “Towards universal fake image detectors that generalize across generative models,” inCVPR, 2023
2023
-
[29]
Patchcraft: Exploring texture patch for efficient ai-generated image detection,
N. Zhong, Y . Xu, S. Li, Z. Qian, and X. Zhang, “Patchcraft: Exploring texture patch for efficient ai-generated image detection,” 2024. [Online]. Available: https://arxiv.org/abs/2311.12397
-
[30]
Q. Team, “Qwen3-vl technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2511.21631
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Genimage: A million-scale benchmark for detecting ai-generated image,
M. Zhu, H. Chen, Q. Y AN, X. Huang, G. Lin, W. Li, Z. Tu, H. Hu, J. Hu, and Y . Wang, “Genimage: A million-scale benchmark for detecting ai-generated image,” inAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, Eds., vol. 36. Curran Associates, Inc., 2023, pp. 77 771–77 782. [Online]. Av...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.