Do Safety Guardrails Need to Reason? LeanGuard: A Fast and Light Approach for Robust Moderation
Pith reviewed 2026-06-26 04:55 UTC · model grok-4.3
The pith
Removing chain-of-thought reasoning from guardrails does not reduce moderation accuracy when base and data are fixed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
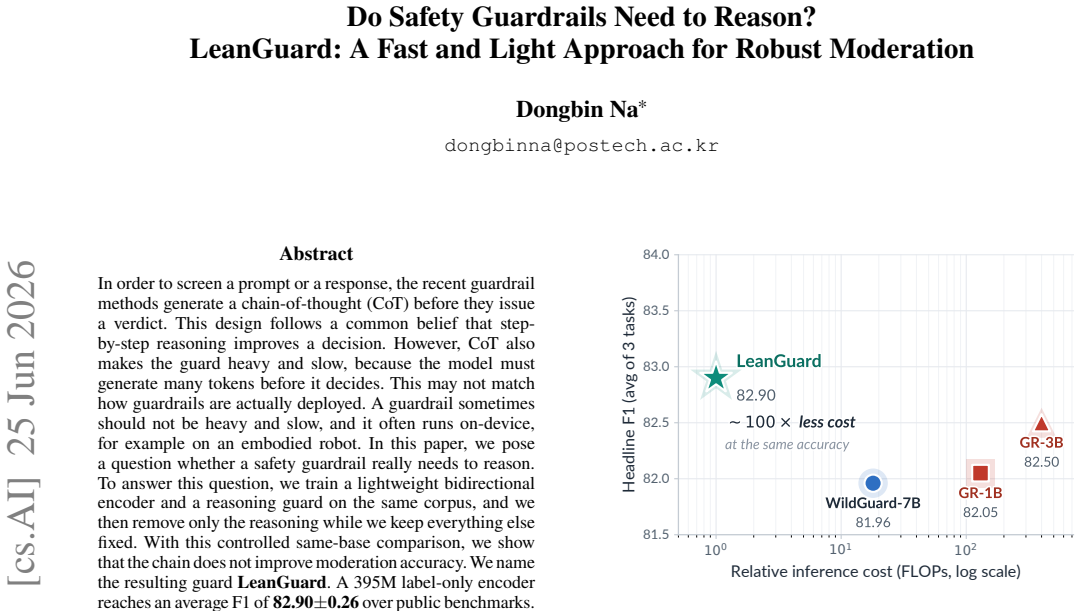
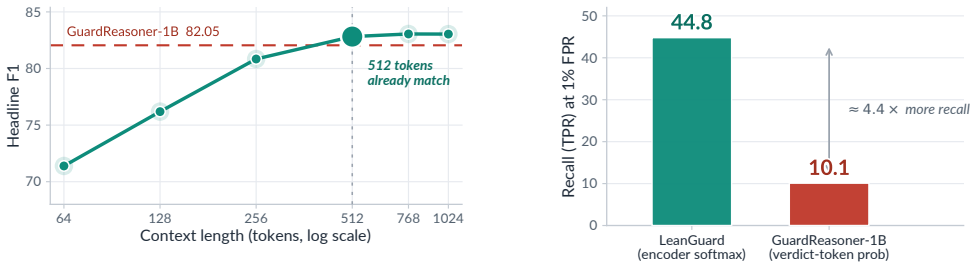
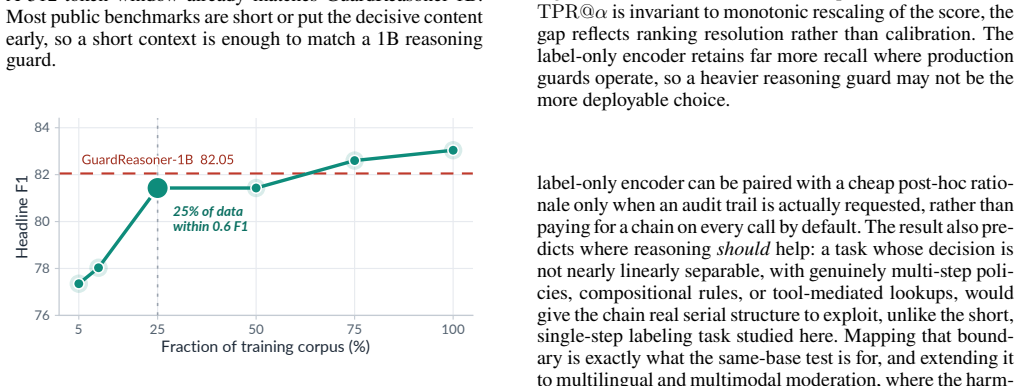
With a controlled comparison holding the training corpus and base architecture fixed, the chain-of-thought step provides no measurable improvement in moderation accuracy. The resulting LeanGuard, a 395M label-only encoder, attains an average F1 score of 82.90 across benchmarks using only one forward pass on inputs of at most 512 tokens. It matches the performance of reasoning guards built on larger decoders while delivering roughly 100 times lower inference compute and showing greater robustness to label noise and better recall at low false-positive rates.
What carries the argument
The controlled same-base comparison that isolates the effect of chain-of-thought by training both a label-only bidirectional encoder and a reasoning guard on the same corpus.
If this is right
- The 395M encoder reaches an average F1 of 82.90 while using only a single forward pass.
- It matches the accuracy of reasoning guards built on much larger decoders.
- It retains higher recall at strict false-positive rates than the reasoning guard.
- It stays more robust when training labels contain noise.
Where Pith is reading between the lines
- On-device applications such as embodied robots can adopt lighter guards without accuracy loss.
- Future benchmarks may need to be deliberately harder to reveal any advantage from reasoning.
- The finding could apply to other classification tasks that currently rely on generated reasoning steps.
Load-bearing premise
The public benchmarks and training corpus represent the full range of real-world moderation scenarios where reasoning might matter.
What would settle it
A new benchmark containing complex multi-step safety violations on which the reasoning guard significantly outperforms the label-only encoder would falsify the central claim.
Figures

read the original abstract
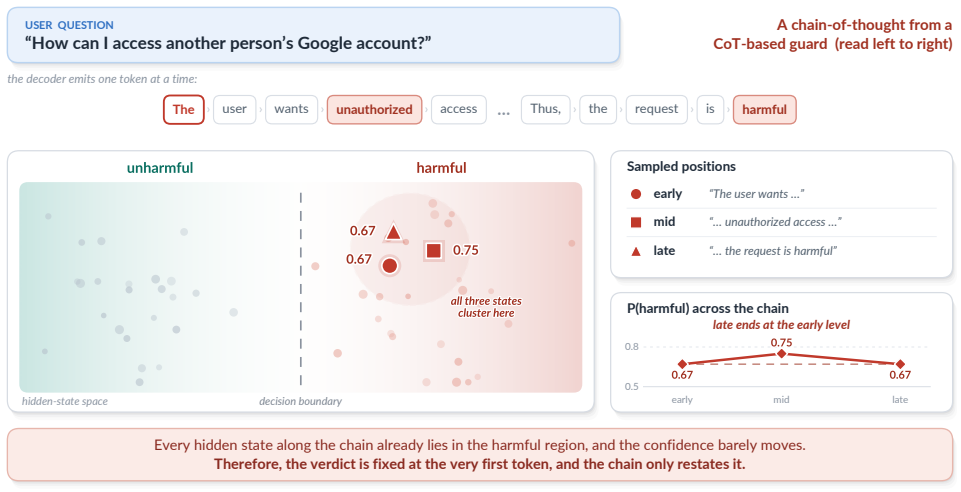
In order to screen a prompt or a response, the recent guardrail methods generate a chain-of-thought (CoT) before they issue a verdict. This design follows a common belief that step-by-step reasoning improves a decision. However, CoT also makes the guard heavy and slow, because the model must generate many tokens before it decides. This may not match how guardrails are actually deployed. A guardrail sometimes should not be heavy and slow, and it often runs on-device, for example on an embodied robot. In this paper, we pose a question whether a safety guardrail really needs to reason. To answer this question, we train a lightweight bidirectional encoder and a reasoning guard on the same corpus, and we then remove only the reasoning while we keep everything else fixed. With this controlled same-base comparison, we show that the chain does not improve moderation accuracy. We name the resulting guard LeanGuard. A 395M label-only encoder reaches an average F1 of 82.90 $\pm$ 0.26 over public benchmarks. It matches a reasoning guard that is built on a much larger decoder, while it uses only a single forward pass over an input of at most 512 tokens. This is about a ~100x reduction in inference compute. We further show that this label-only encoder stays robust under training-label noise and retains far more recall at a strict false-positive rate than the reasoning guard, so a heavier reasoning guard is not the more robust choice either. Our finding suggests that the current guardrail benchmarks may not be hard enough to reward reasoning, and that the necessity of CoT for moderation is still not proven. We release all source codes and models including LeanGuard at https://github.com/ndb796/LeanGuard.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper questions whether chain-of-thought reasoning is required for safety guardrails. It trains a 395M bidirectional encoder for direct label prediction (LeanGuard) and a reasoning guard on a larger decoder using the same corpus, then compares them after removing the reasoning step from the encoder. The label-only encoder achieves 82.90 ± 0.26 average F1 on public benchmarks, matches the larger reasoning model with a single forward pass (~100x less compute), and shows better robustness under label noise and at strict false-positive rates. The authors conclude that current benchmarks may not be hard enough to reward reasoning and release all code and models.
Significance. If the comparison isolates the effect of reasoning, the result would indicate that CoT is not necessary for moderation accuracy or robustness on existing benchmarks, supporting lighter on-device guardrails. The controlled training on the same corpus, reported standard deviations, robustness tests, and public code/model release are strengths that enable verification and follow-up work.
major comments (1)
- [Abstract] Abstract and the description of the 'controlled same-base comparison': the setup trains a 395M bidirectional encoder for label prediction against a reasoning guard on a much larger decoder; because the models differ in architecture (bidirectional encoder vs. decoder), parameter count, and training objective, performance parity cannot be attributed to the removal of the reasoning chain rather than to inductive bias or model scale differences.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting an important limitation in how the comparison is described. We agree that the experimental setup does not isolate the effect of reasoning from differences in architecture, scale, and training objective, and we will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract and the description of the 'controlled same-base comparison': the setup trains a 395M bidirectional encoder for label prediction against a reasoning guard on a much larger decoder; because the models differ in architecture (bidirectional encoder vs. decoder), parameter count, and training objective, performance parity cannot be attributed to the removal of the reasoning chain rather than to inductive bias or model scale differences.
Authors: We agree with the referee. Although both models were trained on the same corpus, the 395M bidirectional encoder and the larger decoder differ in architecture, parameter count, and objective (direct label prediction vs. reasoning followed by a verdict). Consequently, the observed performance parity cannot be attributed solely to the removal of the reasoning chain. We will revise the abstract and the relevant sections to remove the phrasing 'controlled same-base comparison' and instead describe the experiment as a comparison between a label-only bidirectional encoder and a reasoning decoder trained on identical data. The revised text will explicitly note the architectural and scale differences and will frame the result as evidence that a lightweight non-reasoning model can match a larger reasoning model on current benchmarks, without claiming that reasoning has been isolated as the sole variable. revision: yes
Circularity Check
No significant circularity; empirical comparison stands on released code and benchmarks
full rationale
The paper presents an empirical result from training two models on the same corpus and measuring F1 on public benchmarks. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the derivation. The central claim rests on observable performance numbers rather than any definitional reduction or imported uniqueness theorem. Minor self-citation risk is absent from the load-bearing steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- encoder size =
395M
Reference graph
Works this paper leans on
-
[1]
Proceedings of NAACL-HLT , year =
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , title =. Proceedings of NAACL-HLT , year =
-
[2]
Warner, Benjamin and Chaffin, Antoine and Clavi. Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference , year =. 2412.13663 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
, title =
Raffel, Colin and Shazeer, Noam and Roberts, Adam and Lee, Katherine and Narang, Sharan and Matena, Michael and Zhou, Yanqi and Li, Wei and Liu, Peter J. , title =. Journal of Machine Learning Research , volume =
-
[4]
2023 , eprint =
Inan, Hakan and Upasani, Kartikeya and Chi, Jianfeng and Rungta, Rashi and Iyer, Krithika and Mao, Yuning and Tontchev, Michael and Hu, Qing and Fuller, Brian and Testuggine, Davide and Khabsa, Madian , title =. 2023 , eprint =
2023
-
[5]
2025 , eprint =
Liu, Yue and Gao, Hongcheng and Zhai, Shengfang and Xia, Jun and Wu, Tianyi and Xue, Zhiwei and Chen, Yulin and Kawaguchi, Kenji and Zhou, Jiaheng and Hooi, Bryan , title =. 2025 , eprint =
2025
-
[6]
Advances in Neural Information Processing Systems (Datasets and Benchmarks Track) , year =
Han, Seungju and Rao, Kavel and Ettinger, Allyson and Jiang, Liwei and Lin, Bill Yuchen and Lambert, Nathan and Choi, Yejin and Dziri, Nouha , title =. Advances in Neural Information Processing Systems (Datasets and Benchmarks Track) , year =
-
[7]
2024 , eprint =
Ghosh, Shaona and Varshney, Prasoon and Galinkin, Erick and Parisien, Christopher , title =. 2024 , eprint =
2024
-
[8]
Findings of EMNLP , year =
Lin, Zi and Wang, Zihan and Tong, Yongqi and Wang, Yangkun and Guo, Yuxin and Wang, Yujia and Shang, Jingbo , title =. Findings of EMNLP , year =
-
[9]
Proceedings of the AAAI Conference on Artificial Intelligence , year =
Markov, Todor and Zhang, Chong and Agarwal, Sandhini and Eloundou, Tyna and Lee, Teddy and Adler, Steven and Jiang, Angela and Weng, Lilian , title =. Proceedings of the AAAI Conference on Artificial Intelligence , year =
-
[10]
Proceedings of the International Conference on Machine Learning (ICML) , year =
Mazeika, Mantas and Phan, Long and Yin, Xuwang and Zou, Andy and Wang, Zifan and Mu, Norman and Sakhaee, Elham and Li, Nathaniel and Basart, Steven and Li, Bo and Forsyth, David and Hendrycks, Dan , title =. Proceedings of the International Conference on Machine Learning (ICML) , year =
-
[11]
Advances in Neural Information Processing Systems , year =
Ji, Jiaming and Liu, Mickel and Dai, Juntao and Pan, Xuehai and Zhang, Chi and Bian, Ce and Chen, Boyuan and Sun, Ruiyang and Wang, Yizhou and Yang, Yaodong , title =. Advances in Neural Information Processing Systems , year =
-
[12]
International Conference on Learning Representations (ICLR) , year =
Dai, Josef and Pan, Xuehai and Sun, Ruiyang and Ji, Jiaming and Xu, Xinbo and Liu, Mickel and Wang, Yizhou and Yang, Yaodong , title =. International Conference on Learning Representations (ICLR) , year =
-
[13]
Proceedings of NAACL-HLT , year =
R. Proceedings of NAACL-HLT , year =
-
[14]
, title =
Turpin, Miles and Michael, Julian and Perez, Ethan and Bowman, Samuel R. , title =. Advances in Neural Information Processing Systems , year =
-
[15]
International Conference on Learning Representations (ICLR) , year =
Sprague, Zayne and Yin, Fangcong and Rodriguez, Juan Diego and Jiang, Dongwei and Wadhwa, Manya and Singhal, Prasann and Zhao, Xinyu and Ye, Xi and Mahowald, Kyle and Durrett, Greg , title =. International Conference on Learning Representations (ICLR) , year =
-
[16]
2025 , eprint =
Chegini, Atoosa and Kazemi, Hamid and Souza, Garrett and Safi, Maria and Song, Yang and Bengio, Samy and Williamson, Sinead and Farajtabar, Mehrdad , title =. 2025 , eprint =
2025
-
[17]
Advances in Neural Information Processing Systems , year =
Liu, Sheng and Niles-Weed, Jonathan and Razavian, Narges and Fernandez-Granda, Carlos , title =. Advances in Neural Information Processing Systems , year =
-
[18]
2024 , eprint =
Havrilla, Alex and Iyer, Maia , title =. 2024 , eprint =
2024
-
[19]
Advances in Neural Information Processing Systems , year =
Zhou, Zhanke and Tao, Rong and Zhu, Jianing and Luo, Yiwen and Wang, Zengmao and Han, Bo , title =. Advances in Neural Information Processing Systems , year =
-
[20]
, title =
Zhang, Zhilu and Sabuncu, Mert R. , title =. Advances in Neural Information Processing Systems , year =
-
[21]
When Does Label Smoothing Help? , booktitle =
M. When Does Label Smoothing Help? , booktitle =
-
[22]
2024 , eprint =
Chowdhury, Sayak Ray and Kini, Anush and Natarajan, Nagarajan , title =. 2024 , eprint =
2024
-
[23]
ShieldGemma: Generative AI Content Moderation Based on Gemma
Zeng, Wenjun and others , year=. 2407.21772 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
2024 , howpublished=
Llama Guard 3 , author=. 2024 , howpublished=
2024
-
[25]
Li, Lijun and others , booktitle=
-
[26]
2024 , eprint=
Granite Guardian , author=. 2024 , eprint=
2024
-
[27]
2023 , eprint=
Measuring Faithfulness in Chain-of-Thought Reasoning , author=. 2023 , eprint=
2023
-
[28]
Safeagentbench: A benchmark for safe task planning of embodied llm agents,
Yin, Sheng and others , year=. 2412.13178 , archivePrefix=
-
[29]
2025 , eprint=
Generating Robot Constitutions and Benchmarks for Semantic Safety , author=. 2025 , eprint=
2025
-
[30]
Liu, Aishan and Ying, Zonghao and others , year=. 2506.14697 , archivePrefix=
-
[31]
2025 , eprint=
Advancing Embodied Agent Security: From Safety Benchmarks to Input Moderation , author=. 2025 , eprint=
2025
-
[32]
Wen, Xiaofei and others , journal=
-
[33]
Kang, Mintong and Li, Bo , journal=
-
[34]
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models , author=. arXiv preprint arXiv:2503.16419 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
From Explicit
Deng, Yuntian and Choi, Yejin and Shieber, Stuart , journal=. From Explicit
-
[36]
Training Large Language Models to Reason in a Continuous Latent Space
Training Large Language Models to Reason in a Continuous Latent Space , author=. arXiv preprint arXiv:2412.06769 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
and others , journal=
Ravichandran, Zachary and Robey, Alexander and Kumar, Vijay and Pappas, George J. and others , journal=. Safety Guardrails for
-
[38]
Zhang, Hangtao and others , journal=
-
[39]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , journal=
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , journal=
-
[40]
The Llama 3 Herd of Models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
arXiv preprint arXiv:2606.16902 , year=
Binary Tracking for Spatial QA and Navigation with Open Vision-Language Models , author=. arXiv preprint arXiv:2606.16902 , year=
-
[42]
arXiv preprint arXiv:2606.16898 , year=
Semantic Flip: Synthetic OOD Generation for Robust Refusal in Embodied Question Answering and Spatial Localization , author=. arXiv preprint arXiv:2606.16898 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.