Chai: Agentic Discovery of Cryptographic Misuse Vulnerabilities
Pith reviewed 2026-06-26 04:17 UTC · model grok-4.3
The pith
An AI system discovers cryptographic misuse by turning library discrepancies into leads for real vulnerabilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
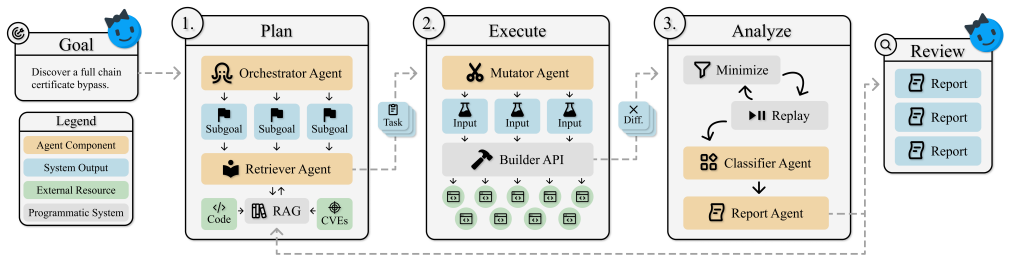
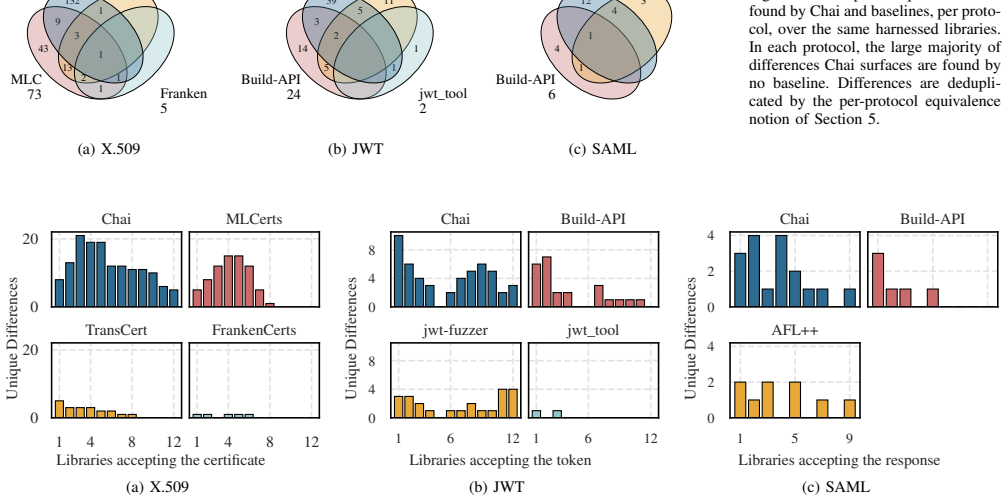
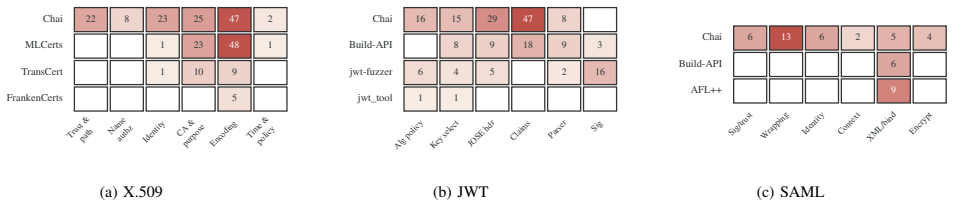
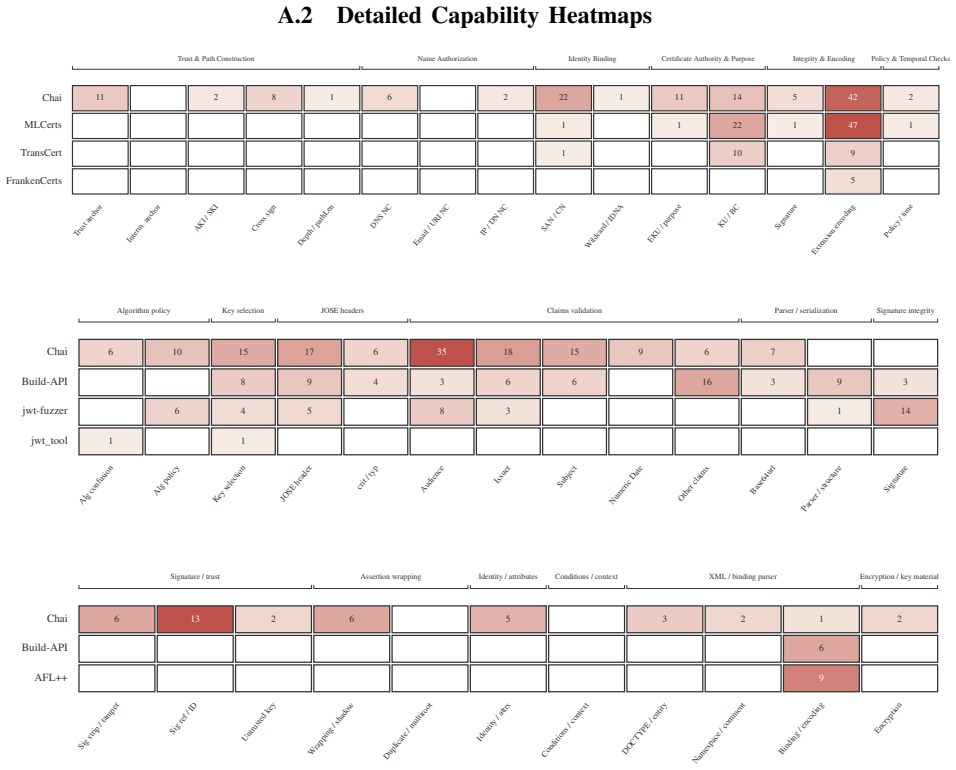
Chai catalogs flaws at the library level and propagates them across a cryptographic dependency graph by using AI to improve the precision of differential testing on naturally occurring discrepancies, thereby discovering a previously unknown critical vulnerability in an SSL library that powers billions of devices along with security bugs in libraries behind a major web browser and major Linux distributions, for a total of over 100 vulnerabilities across X.509, JWT, and SAML libraries.
What carries the argument
AI-enhanced differential testing that repurposes inter-library behavioral discrepancies as signals both to validate issues inside libraries and to locate downstream vulnerabilities in dependent code.
If this is right
- Library-level catalogs of cryptographic issues can be reused across many dependent applications instead of repeating analysis for each one.
- Behavioral differences between implementations become systematic indicators rather than noise to be ignored.
- Focusing effort on a small number of core libraries yields compounded coverage of the larger ecosystem that relies on them.
- The same signals apply across X.509, JWT, and SAML libraries to surface both known and previously unknown bugs.
Where Pith is reading between the lines
- The same discrepancy-driven approach could be tested on other classes of protocol or format handling where direct oracles are unavailable.
- Explicit mapping of software dependency graphs might allow similar propagation of findings in non-cryptographic security domains.
- Combining the method with existing static analysis tools could reduce the manual validation step for flagged discrepancies.
Load-bearing premise
Naturally occurring discrepancies between libraries can be reliably turned into actionable leads for actual vulnerabilities in applications without needing separate instrumentation or ground-truth oracles.
What would settle it
Running Chai on a benchmark set of libraries known to contain cryptographic misuse vulnerabilities and observing that it detects fewer than half of the documented cases.
Figures







read the original abstract
AI-assisted vulnerability discovery has proven effective for bug classes like memory safety, where instrumentation confirms memory violations and efficiently filters false positives. Many dangerous vulnerability classes, such as cryptographic misuse, however, lack any comparable instrumentation. In this work, we present Chai, an AI-based system that discovers and validates cryptographic misuse vulnerabilities through naturally occurring signals. To achieve this, Chai rethinks the classical technique of differential testing by leveraging AI to 1) improve precision for detecting real security issues in libraries, and 2) repurpose commonly overlooked discrepancies as leads for tangible vulnerabilities in downstream applications. In doing so, Chai inverts the prevailing paradigm of AI vulnerability discovery: instead of auditing one codebase for many flaws, it catalogs flaws at the library level and propagates them across a cryptographic dependency graph, delivering compounding efficiency gains. We evaluate Chai across X.509, JWT, and SAML libraries. Chai discovered a previously unknown critical vulnerability in an SSL library that powers billions of devices, along with security bugs in one library behind a major web browser and another in major Linux distributions. In total, these techniques surfaced over 100 vulnerabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Chai, an AI-based agentic system for discovering cryptographic misuse vulnerabilities. It rethinks differential testing by using AI to detect real security issues in libraries (X.509, JWT, SAML) with higher precision and to repurpose library discrepancies as leads for downstream vulnerabilities via propagation across a cryptographic dependency graph. The evaluation claims discovery of a critical unknown vulnerability in an SSL library used by billions of devices, plus bugs in libraries for a major browser and Linux distributions, for a total of over 100 vulnerabilities.
Significance. If the validation of discrepancies as exploitable misuse holds with systematic evidence, the approach could offer compounding efficiency gains over per-codebase auditing and address a gap where traditional instrumentation is unavailable for crypto misuse. The manuscript does not ship machine-checked proofs or parameter-free derivations, but the library-level cataloging idea is a potentially useful inversion of standard AI vuln discovery if supported by reproducible validation.
major comments (2)
- [§5] §5 (evaluation): the claim of >100 vulnerabilities including a critical SSL library bug is load-bearing for the central contribution, yet no explicit oracle, false-positive rate, manual-review protocol, or PoC construction details are provided to show that differential signals were systematically distinguished from benign implementation variance.
- [Section 3] Section 3: the description of differential signals and agentic propagation across the dependency graph does not specify the validation step (static analysis, manual review, or exploit construction) used for the reported cases, leaving the claim that discrepancies reliably surface downstream-exploitable misuse without a comparable instrumentation oracle unsupported.
minor comments (2)
- Abstract: the phrase 'naturally occurring signals' is used without a concrete definition or example of what constitutes a usable discrepancy versus noise.
- The manuscript would benefit from a table summarizing the >100 findings by library, vulnerability class, and validation method.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the evaluation and methodological description. The points raised highlight areas where additional clarity on validation will strengthen the manuscript. We address each major comment below and will incorporate revisions to provide the requested details on validation protocols without altering the core claims.
read point-by-point responses
-
Referee: [§5] §5 (evaluation): the claim of >100 vulnerabilities including a critical SSL library bug is load-bearing for the central contribution, yet no explicit oracle, false-positive rate, manual-review protocol, or PoC construction details are provided to show that differential signals were systematically distinguished from benign implementation variance.
Authors: We agree that §5 would benefit from an explicit description of the validation process. In our evaluation, differential signals were filtered from benign variance through systematic manual review by the authors (with inter-author cross-checks on a subset of cases) followed by PoC exploit construction for high-impact discrepancies. We observed and will report an approximate false-positive rate from this process. We will add a dedicated subsection to §5 detailing the manual-review protocol, criteria for distinguishing security-relevant misuse, the observed false-positive rate, and PoC construction methodology for the reported cases, including the critical SSL library vulnerability. revision: yes
-
Referee: [Section 3] Section 3: the description of differential signals and agentic propagation across the dependency graph does not specify the validation step (static analysis, manual review, or exploit construction) used for the reported cases, leaving the claim that discrepancies reliably surface downstream-exploitable misuse without a comparable instrumentation oracle unsupported.
Authors: We concur that Section 3 should explicitly reference the validation approach. The agentic propagation step surfaces candidate downstream issues from library discrepancies, after which validation is performed via the manual review and exploit construction process (no static analysis oracle or automated instrumentation is employed). We will revise Section 3 to include a brief description of this post-propagation validation step and add a forward reference to the expanded protocol in the revised §5. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an empirical AI system for vulnerability discovery based on differential testing signals and agentic propagation across dependency graphs. No equations, fitted parameters, self-citations, or ansatzes appear in the provided abstract or description that would reduce any claimed result to its inputs by construction. The central claims rest on reported external discoveries (vulnerabilities in specific libraries), which are independent outcomes rather than self-referential. This is a standard empirical contribution without load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Before we knew it: An empirical study of zero-day attacks in the real world,
L. Bilge and T. Dumitras ¸, “Before we knew it: An empirical study of zero-day attacks in the real world,” inProceedings of the 2012 ACM Conference on Computer and Communications Security, 2012
2012
-
[2]
An Empirical Study of Vul- nerability Rewards Programs,
M. Finifter, D. Akhawe, and D. Wagner, “An Empirical Study of Vul- nerability Rewards Programs,” in22nd USENIX Security Symposium (USENIX Security 13), 2013
2013
-
[3]
Nobody Sells Gold for the Price of Silver: Dishonesty, Uncertainty and the UndergroundEconomy,
C. Herley and D. Flor ˆencio, “Nobody Sells Gold for the Price of Silver: Dishonesty, Uncertainty and the UndergroundEconomy,” in Economics of Information Security and Privacy, T. Moore, D. Pym, and C. Ioannidis, Eds., 2010
2010
-
[4]
Assessing Claude Mythos Preview’s cybersecurity capabilities,
Anthropic, “Assessing Claude Mythos Preview’s cybersecurity capabilities,” Apr. 2026, accessed: 2026-06-22. [Online]. Available: https://www.anthropic.com/research/mythos-preview
2026
-
[5]
How Claude Mythos Preview helped harden wolfSSL,
wolfSSL, “How Claude Mythos Preview helped harden wolfSSL,” Apr. 2026, accessed: 2026-06-12. [Online]. Available: https://www. wolfssl.com/how-claude-mythos-preview-helped-harden-wolfssl/
2026
-
[6]
Cyber- Gym: Evaluating AI Agents’ Real-World Cybersecurity Capabilities at Scale,
Z. Wang, T. Shi, J. He, M. Cai, J. Zhang, and D. Song, “Cyber- Gym: Evaluating AI Agents’ Real-World Cybersecurity Capabilities at Scale,” inInternational Conference on Learning Representations, 2025
2025
-
[7]
ExploitGym: Can AI Agents Turn Security Vulnerabilities into Real Attacks?
Z. Wang, N. Schiller, H. Li, S. S. Narayana, M. Nasr, N. Carlini, X. Qi, E. Wallace, E. Bursztein, L. Invernizzi, K. Thomas, Y . Shoshi- taishvili, W. Guo, J. He, T. Holz, and D. Song, “ExploitGym: Can AI Agents Turn Security Vulnerabilities into Real Attacks?”arXiv preprint arXiv:2605.11086, 2026
Pith/arXiv arXiv 2026
-
[8]
ExploitBench: A Capability Lad- der Benchmark for LLM Cybersecurity Agents,
S. Lee and D. Brumley, “ExploitBench: A Capability Lad- der Benchmark for LLM Cybersecurity Agents,”arXiv preprint arXiv:2605.14153, 2026
Pith/arXiv arXiv 2026
-
[9]
Cybersecurity in the age of instant software,
B. Schneier, “Cybersecurity in the age of instant software,” Schneier on Security, Apr. 2026, accessed: 2026-06-21. [Online]. Available: https://www.schneier.com/blog/archives/2026/ 04/cybersecurity-in-the-age-of-instant-software.html
2026
-
[10]
NVD CVE API,
National Institute of Standards and Technology, “NVD CVE API,” 2026, accessed: 2026-05-12. [Online]. Available: https: //nvd.nist.gov/developers/vulnerabilities
2026
-
[11]
Zero Day Clock,
Zero Day Clock, “Zero Day Clock,” 2026, accessed: 2026-05-12. [Online]. Available: https://zerodayclock.com/
2026
-
[12]
Address- Sanitizer: A Fast Address Sanity Checker,
K. Serebryany, D. Bruening, A. Potapenko, and D. Vyukov, “Address- Sanitizer: A Fast Address Sanity Checker,” in2012 USENIX Annual Technical Conference (USENIX ATC 12), 2012
2012
-
[13]
AI-Powered Fuzzing: Breaking the Bug Hunting Barrier,
O. Chang, D. Liu, and A. Arya, “AI-Powered Fuzzing: Breaking the Bug Hunting Barrier,” Aug. 2023, accessed: 2026-06-
2023
-
[14]
Available: https://security.googleblog.com/2023/08/ ai-powered-fuzzing-breaking-bug-hunting.html
[Online]. Available: https://security.googleblog.com/2023/08/ ai-powered-fuzzing-breaking-bug-hunting.html
2023
-
[15]
Leveling up fuzzing: Finding more vulnerabilities with AI,
O. Chang, D. Liu, and J. Metzman, “Leveling up fuzzing: Finding more vulnerabilities with AI,” Nov. 2024, accessed: 2026- 06-22. [Online]. Available: https://security.googleblog.com/2024/11/ leveling-up-fuzzing-finding-more.html
2024
-
[16]
From Naptime to Big Sleep: Using Large Language Models to Catch Vulnerabilities in Real-World Code,
Big Sleep Team, “From Naptime to Big Sleep: Using Large Language Models to Catch Vulnerabilities in Real-World Code,” Nov. 2024, accessed: 2026-06-22. [Online]. Available: https: //projectzero.google/2024/10/from-naptime-to-big-sleep.html
2024
-
[17]
SoK: DARPA’s AI Cyber Challenge (AIxCC): Competition design, architectures, and lessons learned,
C. Zhang, Y . Park, F. Fleischer, Y .-F. Fu, J. Kim, D. Kim, Y . Kim, Q. Xu, A. Chin, Z. Sheng, H. Zhao, M. Pelican, D. J. Musliner, J. Huang, J. Silliman, M. Mcdaniel, J. Casavant, I. Goldthwaite, N. Vidovich, M. Lehman, and T. Kim, “SoK: DARPA’s AI Cyber Challenge (AIxCC): Competition design, architectures, and lessons learned,” 2026. [Online]. Availabl...
Pith/arXiv arXiv 2026
-
[18]
OSS-CRS: Liberating AIxCC Cyber Reasoning Systems for real-world open-source security,
A. Chin, D. Kim, Y .-F. Fu, F. Fleischer, Y . Kim, H. Han, C. Zhang, B. J. Lee, H. Zhao, and T. Kim, “OSS-CRS: Liberating AIxCC Cyber Reasoning Systems for real-world open-source security,”
-
[19]
Available: https://arxiv.org/abs/2603.08566
[Online]. Available: https://arxiv.org/abs/2603.08566
-
[20]
FuzzingBrain V2: A multi-agent LLM system for automated vulnerability discovery and reproduction,
Z. Sheng, Z. Chen, Q. Xu, K. Zhu, and J. Huang, “FuzzingBrain V2: A multi-agent LLM system for automated vulnerability discovery and reproduction,” 2026. [Online]. Available: https: //arxiv.org/abs/2605.21779
Pith/arXiv arXiv 2026
-
[21]
Berkeley vulnerability initiative,
Berkeley Vulnerability Initiative, “Berkeley vulnerability initiative,” 2026, accessed: 2026-05-23. [Online]. Available: https://vuln.cs. berkeley.edu/
2026
-
[22]
OW ASP Top Ten,
OW ASP Foundation, “OW ASP Top Ten,” 2021. [Online]. Available: https://owasp.org/Top10/
2021
-
[23]
2024 CWE Top 25 Most Dangerous Software Weaknesses,
MITRE Corporation, “2024 CWE Top 25 Most Dangerous Software Weaknesses,” 2024. [Online]. Available: https://cwe.mitre.org/top25/ archive/2024/2024 cwe top25.html
2024
-
[24]
The Matter of Heartbleed,
Z. Durumeric, F. Li, J. Kasten, J. Amann, J. Beekman, M. Payer, N. Weaver, D. Adrian, V . Paxson, M. Bailey, and J. A. Halderman, “The Matter of Heartbleed,” inProceedings of the 2014 Conference on Internet Measurement Conference, 2014
2014
-
[25]
DROWN: Breaking TLS Using SSLv2,
N. Aviram, S. Schinzel, J. Somorovsky, N. Heninger, M. Dankel, J. Steube, L. Valenta, D. Adrian, J. A. Halderman, V . Dukhovni, E. K ¨asper, S. Cohney, S. Engels, C. Paar, and Y . Shavitt, “DROWN: Breaking TLS Using SSLv2,” in25th USENIX Security Symposium (USENIX Security 16), 2016
2016
-
[26]
Return Of Bleichenbacher’s Oracle Threat (ROBOT),
H. B ¨ock, J. Somorovsky, and C. Young, “Return Of Bleichenbacher’s Oracle Threat (ROBOT),” in27th USENIX Security Symposium (USENIX Security 18), 2018
2018
-
[27]
Cryptography in the Wild: An Empirical Analysis of Vulnerabilities in Cryptographic Libraries,
J. Blessing, M. A. Specter, and D. J. Weitzner, “Cryptography in the Wild: An Empirical Analysis of Vulnerabilities in Cryptographic Libraries,” inProceedings of the 19th ACM Asia Conference on Computer and Communications Security, 2024
2024
-
[28]
CVE-2018- 0114 Detail,
National Institute of Standards and Technology, “CVE-2018- 0114 Detail,” 2018, accessed: 2026-06-23. [Online]. Available: https://nvd.nist.gov/vuln/detail/CVE-2018-0114
2018
-
[29]
Differential testing for software,
W. M. McKeeman, “Differential testing for software,”Digital Tech- nical Journal, vol. 10, no. 1, 1998
1998
-
[30]
Using Frankencerts for Automated Adversarial Testing of Certificate Vali- dation in SSL/TLS Implementations,
C. Brubaker, S. Jana, B. Ray, S. Khurshid, and V . Shmatikov, “Using Frankencerts for Automated Adversarial Testing of Certificate Vali- dation in SSL/TLS Implementations,” in2014 IEEE Symposium on Security and Privacy, 2014
2014
-
[31]
NEZHA: Efficient Domain-Independent Differential Testing,
T. Petsios, A. Tang, S. Stolfo, A. D. Keromytis, and S. Jana, “NEZHA: Efficient Domain-Independent Differential Testing,” in 2017 IEEE Symposium on Security and Privacy (SP), 2017
2017
-
[32]
Hallucinating Certificates: Differential Testing of TLS Certificate Validation Using Generative Language Models,
M. T. Paracha, K. Posluns, K. Borgolte, M. Lindorfer, and D. Choffnes, “Hallucinating Certificates: Differential Testing of TLS Certificate Validation Using Generative Language Models,” 2026
2026
-
[33]
Token Time Bomb: Evaluating JWT Implementations for Vulnerability Discovery,
J. Yang, E. Wang, J. Chen, Q. Wang, Y . Zhang, H. Duan, W. Xie, and B. Wang, “Token Time Bomb: Evaluating JWT Implementations for Vulnerability Discovery,” inNetwork and Distributed System Security Symposium (NDSS) 2026, 2026
2026
-
[34]
Codex Security, Now in Research Preview,
OpenAI, “Codex Security, Now in Research Preview,” 2026, accessed: 2026-06-12. [Online]. Available: https://openai.com/index/ codex-security-now-in-research-preview/
2026
-
[35]
Small World with High Risks: A Study of Security Threats in the npm Ecosystem,
M. Zimmermann, C.-A. Staicu, C. Tenny, and M. Pradel, “Small World with High Risks: A Study of Security Threats in the npm Ecosystem,” in28th USENIX Security Symposium (USENIX Security 19), 2019
2019
-
[36]
OpenSSL,
OpenSSL Project, “OpenSSL,” 2026, accessed: 2026-06-11. [Online]. Available: https://github.com/openssl/openssl
2026
-
[37]
Analyzing Semantic Correctness with Symbolic Execution: A Case Study on PKCS#1 v1.5 Signature Verification,
S. Y . Chau, M. Yahyazadeh, O. Chowdhury, A. Kate, and N. Li, “Analyzing Semantic Correctness with Symbolic Execution: A Case Study on PKCS#1 v1.5 Signature Verification,” inProceedings 2019 Network and Distributed System Security Symposium, 2019
2019
-
[38]
Systematic Fuzzing and Testing of TLS Libraries,
J. Somorovsky, “Systematic Fuzzing and Testing of TLS Libraries,” inProceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, 2016
2016
-
[39]
Large Language Model guided Protocol Fuzzing,
R. Meng, M. Mirchev, M. B ¨ohme, and A. Roychoudhury, “Large Language Model guided Protocol Fuzzing,” inProceedings 2024 Network and Distributed System Security Symposium, 2024
2024
-
[40]
From One Thousand Pages of Speci- fication to Unveiling Hidden Bugs: Large Language Model Assisted Fuzzing of Matter IoT Devices,
X. Ma, L. Luo, and Q. Zeng, “From One Thousand Pages of Speci- fication to Unveiling Hidden Bugs: Large Language Model Assisted Fuzzing of Matter IoT Devices,” in33rd USENIX Security Symposium (USENIX Security 24), 2024
2024
-
[41]
Guided, Deep Testing of X.509 Certificate Validation via Coverage Transfer Graphs,
J. Zhu, C. Wan, P. Nie, Y . Chen, and Z. Su, “Guided, Deep Testing of X.509 Certificate Validation via Coverage Transfer Graphs,” in 2020 IEEE International Conference on Software Maintenance and Evolution (ICSME), 2020
2020
-
[42]
My ZIP isn’t your ZIP: Identifying and Exploiting Semantic Gaps Between ZIP Parsers,
Y . You, J. Chen, Q. Wang, and H. Duan, “My ZIP isn’t your ZIP: Identifying and Exploiting Semantic Gaps Between ZIP Parsers,” in 34th USENIX Security Symposium (USENIX Security 25), 2025
2025
-
[43]
Incalmo: An Autonomous LLM-Assisted System for Red Teaming Multi-Host Networks,
B. Singer, K. Lucas, L. Adiga, M. Jain, L. Bauer, and V . Sekar, “Incalmo: An Autonomous LLM-Assisted System for Red Teaming Multi-Host Networks,” in2026 IEEE Symposium on Security and Privacy (SP), 2026
2026
-
[44]
FirmAgent: Leveraging Fuzzing to Assist LLM Agents with IoT Firmware Vulnerability Discovery,
J. Ji, C. Zhang, S. Gan, L. Jian, H. Liu, T. Liu, L. Zheng, and Z. Jia, “FirmAgent: Leveraging Fuzzing to Assist LLM Agents with IoT Firmware Vulnerability Discovery,” inNetwork and Distributed System Security Symposium (NDSS) 2026, 2026
2026
-
[45]
ELFuzz: Efficient Input Generation via LLM-driven Synthesis Over Fuzzer Space,
C. Chen, B. Dolan-Gavitt, and Z. Lin, “ELFuzz: Efficient Input Generation via LLM-driven Synthesis Over Fuzzer Space,” in34th USENIX Security Symposium (USENIX Security 25), 2025
2025
-
[46]
Finite-time Analysis of the Multiarmed Bandit Problem,
P. Auer, N. Cesa-Bianchi, and P. Fischer, “Finite-time Analysis of the Multiarmed Bandit Problem,”Machine Learning, vol. 47, no. 2, pp. 235–256, 2002
2002
-
[47]
Criticality Score,
Open Source Security Foundation, “Criticality Score,” 2026, accessed: 2026-05-12. [Online]. Available: https://openssf.org/ projects/criticality-score/
2026
-
[48]
LLM Agents can Autonomously Exploit One-day Vulnerabilities,
R. Fang, R. Bindu, A. Gupta, and D. Kang, “LLM Agents can Autonomously Exploit One-day Vulnerabilities,”arXiv preprint arXiv:2404.08144, 2024
Pith/arXiv arXiv 2024
-
[49]
AFL++: Combin- ing Incremental Steps of Fuzzing Research,
A. Fioraldi, D. Maier, H. Eißfeldt, and M. Heuse, “AFL++: Combin- ing Incremental Steps of Fuzzing Research,”14th USENIX Workshop on Offensive Technologies (WOOT 20), 2020
2020
-
[50]
LLMIF: Augmented Large Language Model for Fuzzing IoT Devices,
J. Wang, L. Yu, and X. Luo, “LLMIF: Augmented Large Language Model for Fuzzing IoT Devices,” in2024 IEEE Symposium on Security and Privacy (SP), 2024
2024
-
[51]
ProtocolGuard: Detecting Protocol Non-compliance Bugs via LLM-guided Static Analysis and Dynamic Verification,
X. Song, L. Pei, J. Wu, Y . Zeng, G. He, C. Zuo, X. Liu, Q. Zhao, and S. Guo, “ProtocolGuard: Detecting Protocol Non-compliance Bugs via LLM-guided Static Analysis and Dynamic Verification,” inProceedings of the 33rd Annual Network and Distributed System Security Symposium (NDSS 2026), 2026
2026
-
[52]
Prompt Fuzzing for Fuzz Driver Generation,
Y . Lyu, Y . Xie, P. Chen, and H. Chen, “Prompt Fuzzing for Fuzz Driver Generation,” inProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, 2024
2024
-
[53]
Generating API Parameter Security Rules with LLM for API Misuse Detection,
J. Liu, Y . Yang, K. Chen, and M. Lin, “Generating API Parameter Security Rules with LLM for API Misuse Detection,” inProceedings 2025 Network and Distributed System Security Symposium, 2025
2025
-
[54]
HVLearn: Automated Black-Box Analysis of Hostname Verification in SSL/TLS Implementations,
S. Sivakorn, G. Argyros, K. Pei, A. D. Keromytis, and S. Jana, “HVLearn: Automated Black-Box Analysis of Hostname Verification in SSL/TLS Implementations,” in2017 IEEE Symposium on Security and Privacy (SP), 2017
2017
-
[55]
The most dangerous code in the world: Validating SSL certificates in non-browser software,
M. Georgiev, S. Iyengar, S. Jana, R. Anubhai, D. Boneh, and V . Shmatikov, “The most dangerous code in the world: Validating SSL certificates in non-browser software,” inProceedings of the 2012 ACM Conference on Computer and Communications Security, 2012
2012
-
[56]
On Breaking SAML: Be Whoever You Want to Be,
J. Somorovsky, A. Mayer, J. Schwenk, M. Kampmann, and M. Jensen, “On Breaking SAML: Be Whoever You Want to Be,” in21st USENIX Security Symposium (USENIX Security 12), 2012
2012
-
[57]
The devil is in the (implementation) details: An empirical analysis of OAuth SSO systems,
S.-T. Sun and K. Beznosov, “The devil is in the (implementation) details: An empirical analysis of OAuth SSO systems,” inProceedings of the 2012 ACM Conference on Computer and Communications Security, 2012
2012
-
[58]
Explicating SDKs: Uncovering Assumptions Underlying Secure Au- thentication and Authorization,
R. Wang, Y . Zhou, S. Chen, S. Qadeer, D. Evans, and Y . Gurevich, “Explicating SDKs: Uncovering Assumptions Underlying Secure Au- thentication and Authorization,” in22nd USENIX Security Symposium (USENIX Security 13), 2013
2013
-
[59]
OAuth Demystified for Mobile Application Developers,
E. Y . Chen, Y . Pei, S. Chen, Y . Tian, R. Kotcher, and P. Tague, “OAuth Demystified for Mobile Application Developers,” inProceedings of the 2014 ACM SIGSAC Conference on Computer and Communica- tions Security, 2014
2014
-
[60]
SSOScan: Automated Testing of Web Appli- cations for Single Sign-On Vulnerabilities,
Y . Zhou and D. Evans, “SSOScan: Automated Testing of Web Appli- cations for Single Sign-On Vulnerabilities,” in23rd USENIX Security Symposium (USENIX Security 14), 2014
2014
-
[61]
Why eve and mallory love android: An analysis of android SSL (in)security,
S. Fahl, M. Harbach, T. Muders, L. Baumg ¨artner, B. Freisleben, and M. Smith, “Why eve and mallory love android: An analysis of android SSL (in)security,” inProceedings of the 2012 ACM Conference on Computer and Communications Security, 2012
2012
-
[62]
An em- pirical study of cryptographic misuse in android applications,
M. Egele, D. Brumley, Y . Fratantonio, and C. Kruegel, “An em- pirical study of cryptographic misuse in android applications,” in Proceedings of the 2013 ACM SIGSAC Conference on Computer & Communications Security, 2013
2013
-
[63]
From Noise to Signal: Precisely Identify Affected Packages of Known Vulnerabilities in npm Ecosystem,
Y . Pu, L. Ying, and Y . Gu, “From Noise to Signal: Precisely Identify Affected Packages of Known Vulnerabilities in npm Ecosystem,” in Network and Distributed System Security Symposium (NDSS) 2026, 2026
2026
-
[64]
VulSCA: A community- level SCA approach for accurate C/C++ supply chain vulnerability analysis,
Y . Hu, C. Li, Y . Wu, Y . Cai, and D. Zou, “VulSCA: A community- level SCA approach for accurate C/C++ supply chain vulnerability analysis,” inNetwork and Distributed System Security Symposium (NDSS) 2026, 2026
2026
-
[65]
Chain- Fuzz: Exploiting Upstream Vulnerabilities in Open-Source Supply Chains,
P. Deng, L. Zhang, Y . Meng, Z. Yang, Y . Zhang, and M. Yang, “Chain- Fuzz: Exploiting Upstream Vulnerabilities in Open-Source Supply Chains,” in34th USENIX Security Symposium (USENIX Security 25), 2025
2025
-
[66]
Brahmastra: Driving Apps to Test the Security of Third-Party Components,
R. Bhoraskar, S. Han, J. Jeon, T. Azim, S. Chen, J. Jung, S. Nath, R. Wang, and D. Wetherall, “Brahmastra: Driving Apps to Test the Security of Third-Party Components,” in23rd USENIX Security Symposium (USENIX Security 14), 2014
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.