Where Do CoT Training Gains Land in LLM based Agents?
Pith reviewed 2026-06-26 04:52 UTC · model grok-4.3
The pith
CoT training improves LLM agents mainly by raising the quality of direct prompt-to-action predictions rather than widening the extra benefit from reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
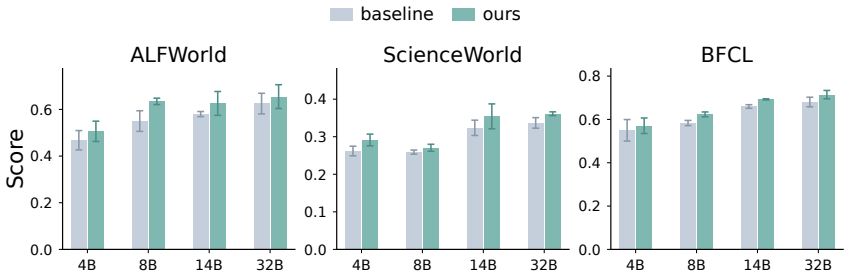
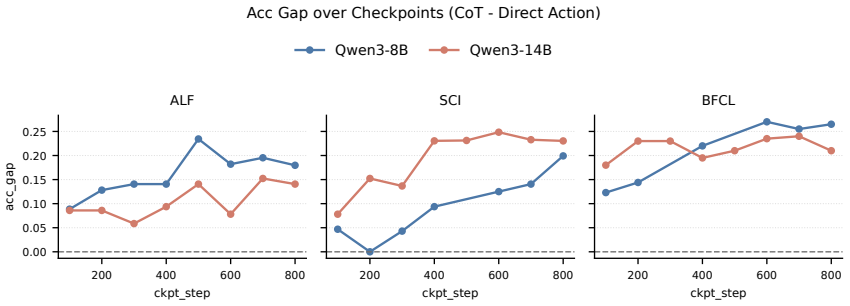
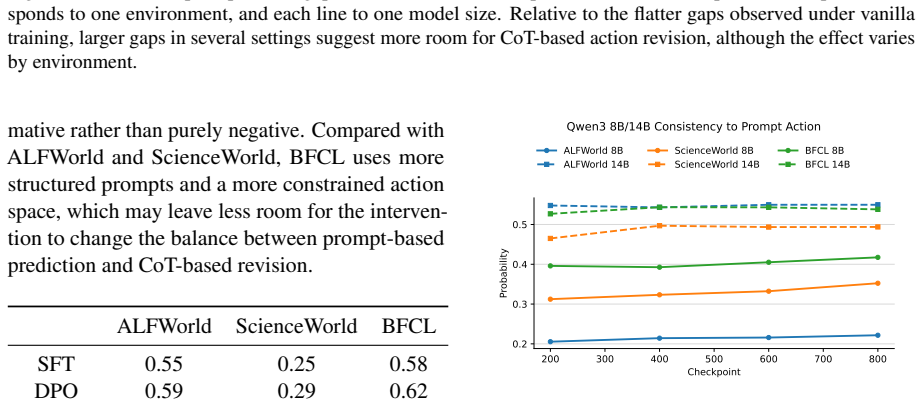
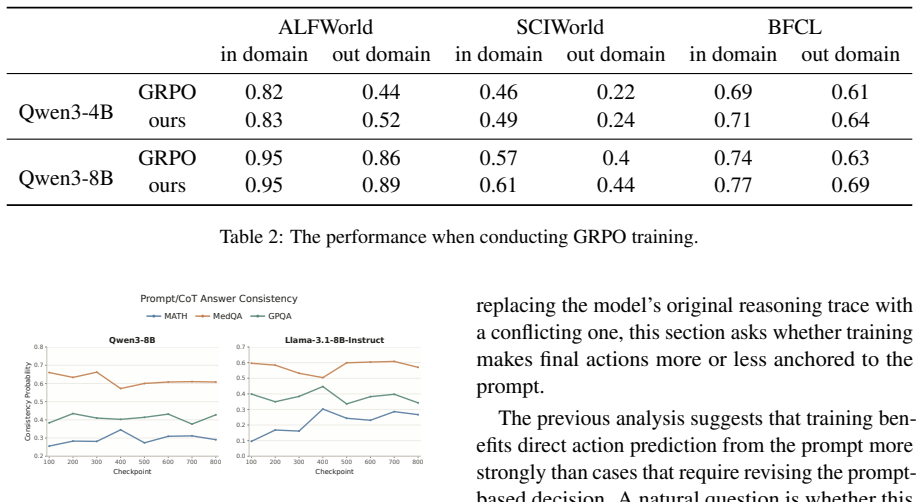
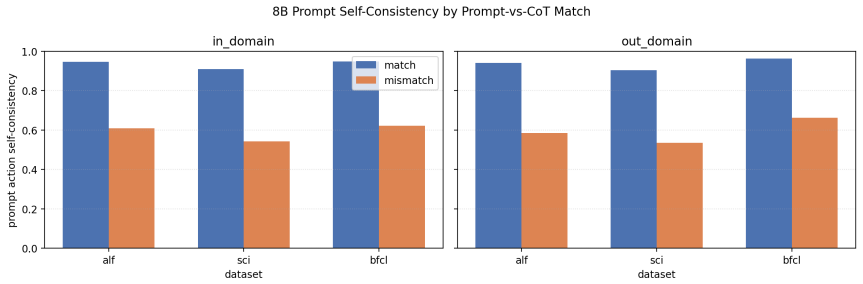
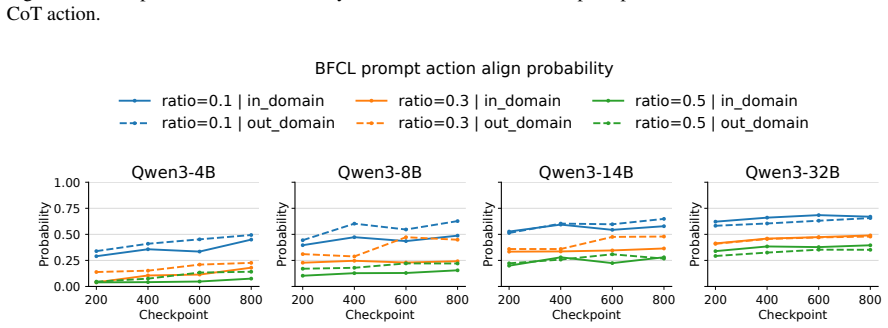
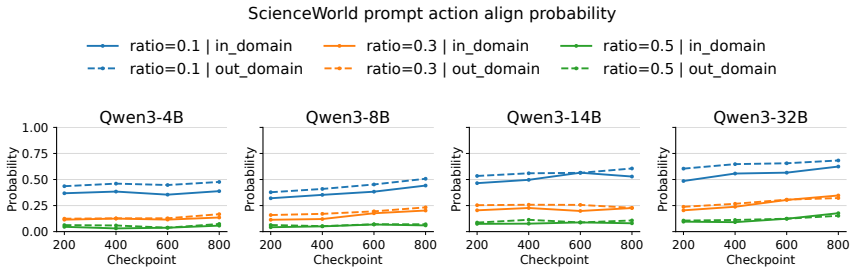
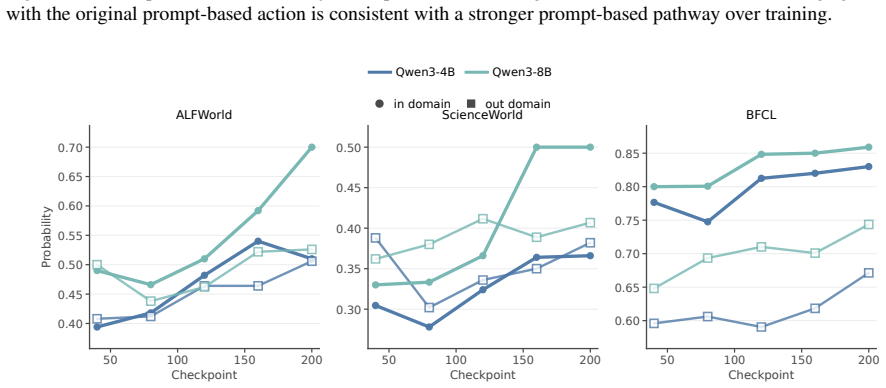
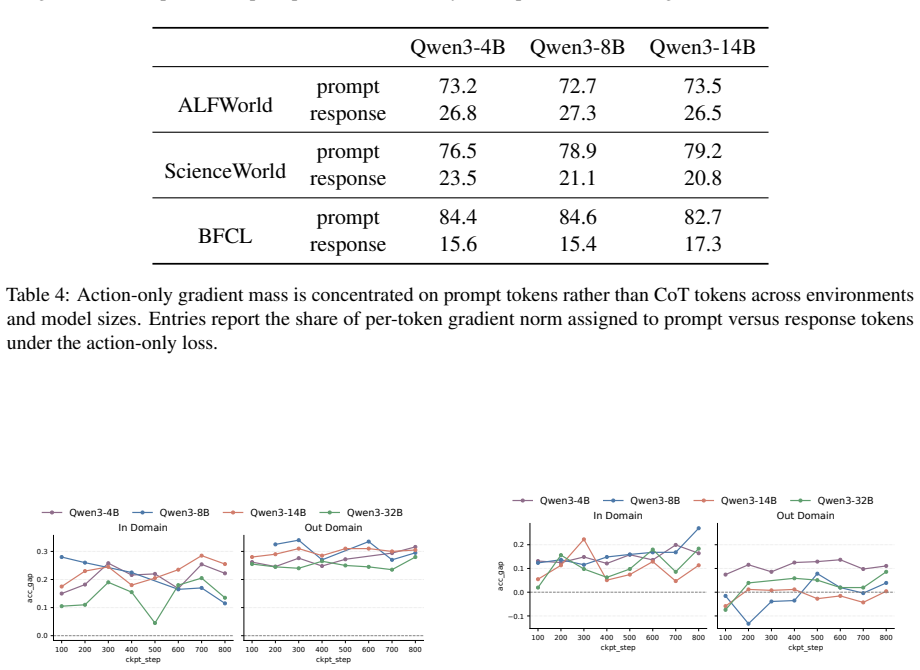
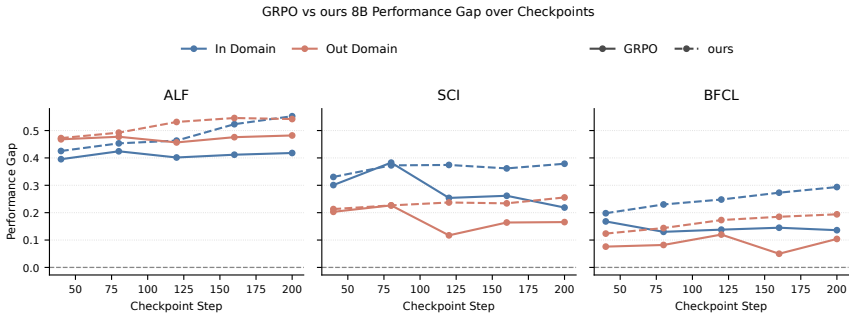
Across training checkpoints, prompt-action quality improves substantially while the relative advantage of CoT actions over prompt actions remains similar during environment interaction; later checkpoints revise actions less often in response to CoT, indicating greater prompt reliance, and selectively masking action-token supervision on a fraction of examples improves out-of-domain generalization.
What carries the argument
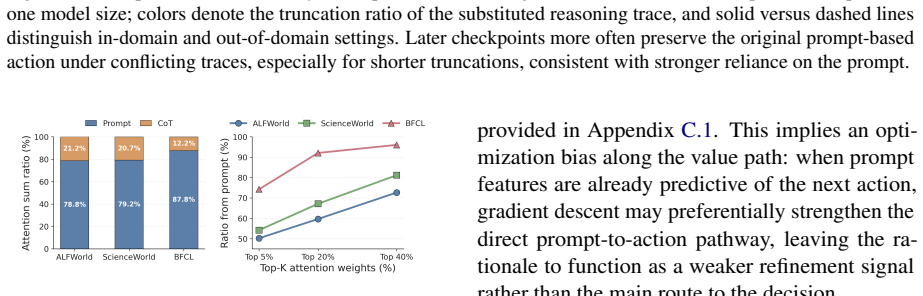
The side-by-side comparison of prompt actions (direct prediction without generated reasoning) versus CoT actions (prediction after verbalized reasoning), measured across checkpoints and interaction steps.
If this is right
- Prompt-action quality rises substantially with continued CoT training.
- The relative advantage of CoT actions over prompt actions stays roughly constant during environment interaction.
- Later checkpoints revise their initial action less often after generating CoT.
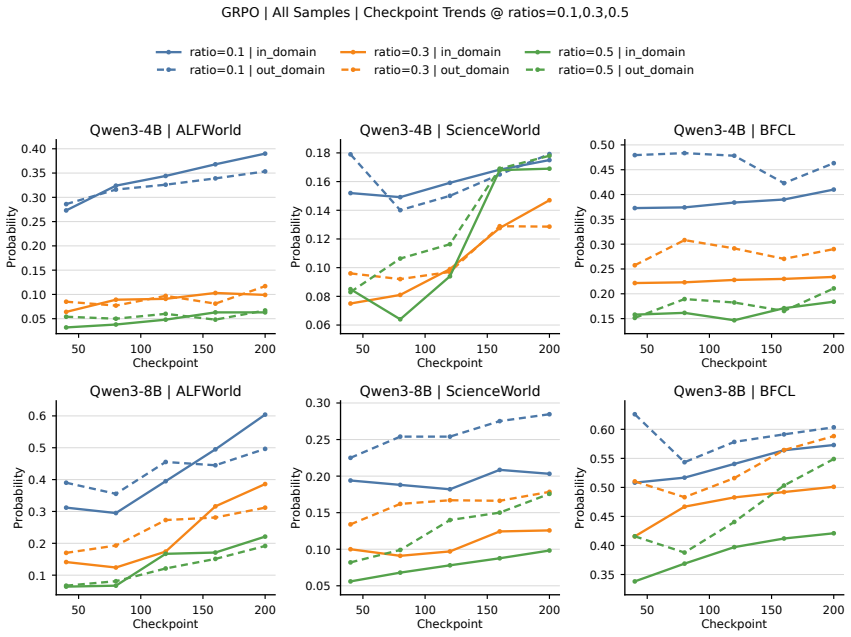
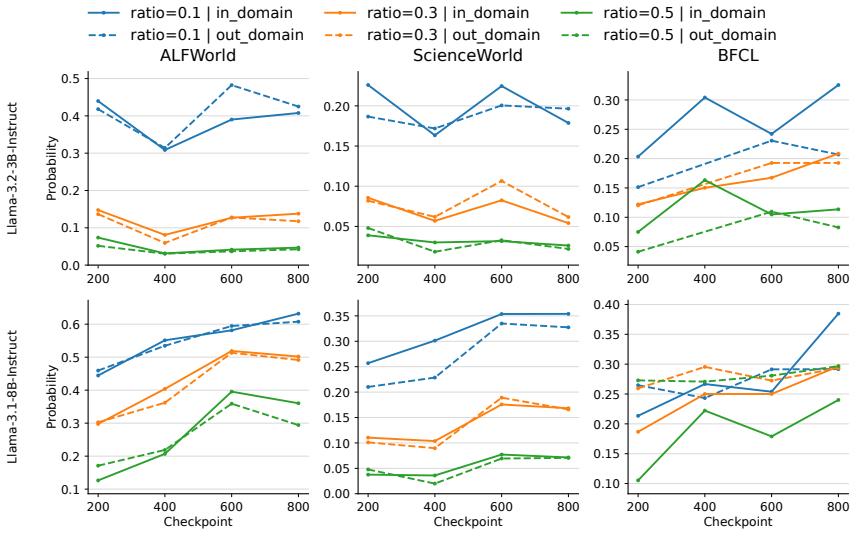
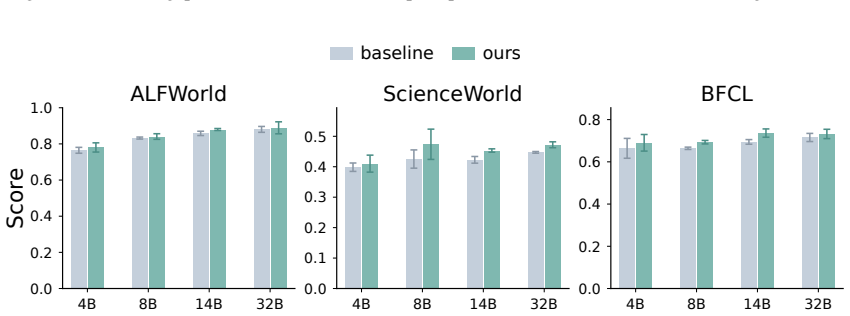
- Masking action-token supervision on a fraction of training examples improves out-of-domain generalization.
Where Pith is reading between the lines
- The pattern suggests CoT training may function more as a way to strengthen base prompt-to-action mapping than as training for the reasoning step itself.
- If the same separation holds in other agent benchmarks, selective supervision masking could become a standard regularization step for better generalization.
- The reduced revision rate in later checkpoints raises the question of whether faithfulness of CoT decreases as direct prediction improves.
Load-bearing premise
Performance differences between prompt actions and CoT actions can be attributed cleanly to the presence or absence of generated reasoning rather than to how the model was trained or how the outputs were sampled.
What would settle it
If the gap between CoT-action and prompt-action success rates widened steadily across later checkpoints while interacting with the environment, the claim that training gains do not widen the CoT advantage would be contradicted.
Figures
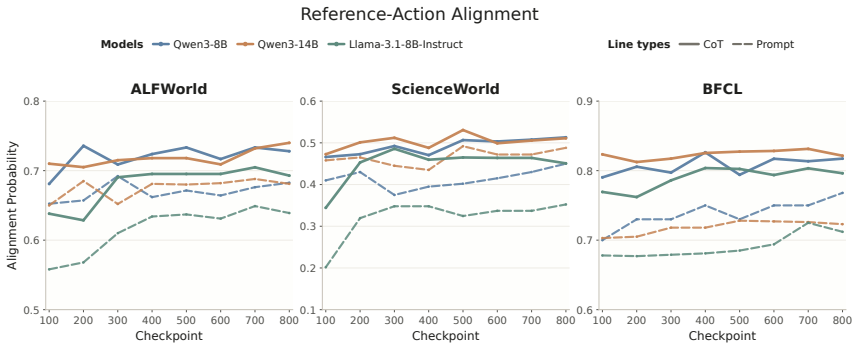
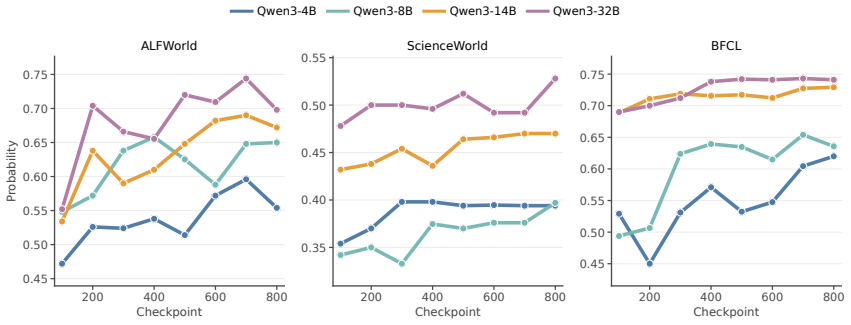
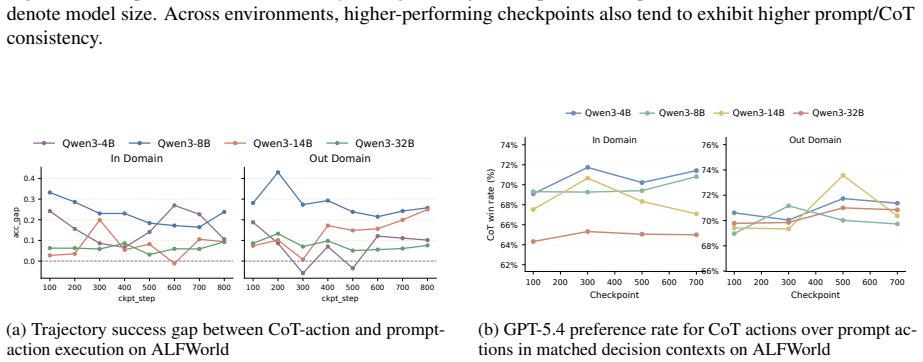
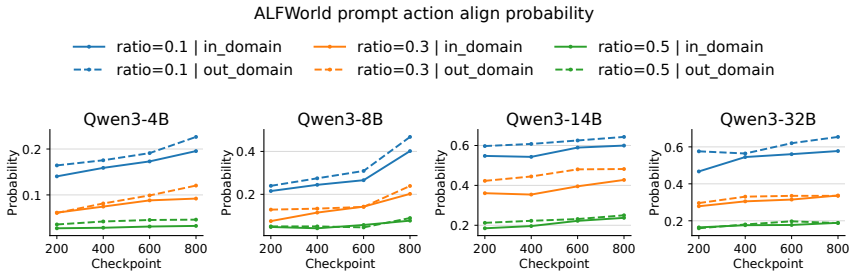
read the original abstract
Chain-of-thought (CoT) reasoning is widely used in language-model agents, but prior work has shown that verbalized CoT is not always faithful and may instead reflect post-hoc reasoning, which means the model already knows the answer before reasoning. We therefore ask what CoT training is actually improving: is the model getting better at changing its action through generated reasoning, or is it getting better at predicting the action directly from the prompt? We study this question by comparing \emph{prompt actions} (predicting action without CoT) with CoT actions (predicting action with CoT). Across checkpoints, prompt-action quality improves substantially. While interacting with the environment, the relative advantage of CoT actions over prompt actions remains similar, showing that CoT training does not widen the advantage of CoT reasoning, and it helps to improve the quality of prompt actions. We further find that later checkpoints are less likely to revise the action in response to CoT, suggesting greater reliance on the prompt. Motivated by these patterns, we selectively mask action-token supervision on a fraction of training examples. This intervention improves out-of-domain generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates where gains from Chain-of-Thought (CoT) training accrue in LLM agents by comparing prompt actions (direct action prediction without generated reasoning) against CoT actions across training checkpoints. It reports that prompt-action quality improves substantially while the relative advantage of CoT actions stays roughly constant, that later checkpoints revise actions less often in response to CoT, and that selectively masking action-token supervision on a fraction of examples improves out-of-domain generalization.
Significance. If the empirical patterns hold after controls for sampling and elicitation, the work clarifies that CoT training primarily strengthens direct prompt-to-action mapping rather than widening the benefit of verbalized reasoning, and supplies a simple masking intervention with measurable OOD gains. The direct checkpoint-wise comparison is a strength that avoids post-hoc parameter fitting.
major comments (3)
- [§3] §3 (Methods) and abstract: the central claim that CoT training improves prompt-action quality while leaving the relative CoT advantage unchanged requires that prompt-action and CoT-action outputs differ only in the presence/absence of reasoning. The manuscript must specify exactly how prompt actions are elicited (modified prompt, token suppression, or temperature change) and confirm that the elicitation procedure is held fixed across checkpoints; without this, measured prompt-action gains could arise from changes in decoding behavior outside the CoT training distribution rather than improved direct prediction.
- [§4] §4 (Results) and abstract: no numerical values, standard errors, or statistical tests are supplied for the reported improvements in prompt-action quality or the stability of the CoT advantage. Checkpoint selection criteria, environment statistics, number of episodes, and temperature controls are also omitted; these details are load-bearing for the claim that the relative advantage “remains similar.”
- [§5] §5 (Intervention): the selective masking experiment is presented as motivated by the observed patterns, yet the manuscript does not report the fraction of examples masked, the precise masking schedule, or an ablation against random masking; without these, it is unclear whether the reported OOD gain is specific to the hypothesized mechanism.
minor comments (2)
- Figure captions and axis labels should explicitly state whether error bars represent standard error across seeds or across episodes.
- The term “prompt action” is used before it is formally defined; add a short definition in the introduction or §2.
Simulated Author's Rebuttal
We appreciate the referee's careful review and constructive suggestions. We address each of the major comments below and will incorporate the necessary revisions to improve the clarity and completeness of the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Methods) and abstract: the central claim that CoT training improves prompt-action quality while leaving the relative CoT advantage unchanged requires that prompt-action and CoT-action outputs differ only in the presence/absence of reasoning. The manuscript must specify exactly how prompt actions are elicited (modified prompt, token suppression, or temperature change) and confirm that the elicitation procedure is held fixed across checkpoints; without this, measured prompt-action gains could arise from changes in decoding behavior outside the CoT training distribution rather than improved direct prediction.
Authors: We thank the referee for highlighting this important clarification. The prompt actions are elicited by using a prompt template that does not include the instruction to generate chain-of-thought reasoning, while all other aspects of the input and decoding parameters remain unchanged. This elicitation method is applied consistently across all training checkpoints. We will update §3 and the abstract to explicitly describe this procedure. revision: yes
-
Referee: [§4] §4 (Results) and abstract: no numerical values, standard errors, or statistical tests are supplied for the reported improvements in prompt-action quality or the stability of the CoT advantage. Checkpoint selection criteria, environment statistics, number of episodes, and temperature controls are also omitted; these details are load-bearing for the claim that the relative advantage “remains similar.”
Authors: We agree that providing quantitative details and statistical support is necessary. In the revised manuscript, we will include the specific numerical improvements observed in prompt-action quality along with standard errors and appropriate statistical tests. We will also specify the checkpoint selection criteria, the number of evaluation episodes, environment statistics, and confirm that temperature is held fixed. These additions will substantiate the claim regarding the stability of the CoT advantage. revision: yes
-
Referee: [§5] §5 (Intervention): the selective masking experiment is presented as motivated by the observed patterns, yet the manuscript does not report the fraction of examples masked, the precise masking schedule, or an ablation against random masking; without these, it is unclear whether the reported OOD gain is specific to the hypothesized mechanism.
Authors: We will revise §5 to report the exact fraction of training examples on which action-token supervision was masked, describe the masking schedule in detail, and include an ablation study comparing the selective masking to random masking. This will clarify that the out-of-domain generalization gains are attributable to the hypothesized mechanism. revision: yes
Circularity Check
No circularity; claims rest on direct empirical comparisons
full rationale
The paper reports observational measurements of prompt-action quality versus CoT-action quality across training checkpoints, with the relative advantage remaining stable. These are direct comparisons of output modes on held-out interactions, not derivations, fitted parameters renamed as predictions, or self-citation chains. No equations appear that reduce any reported advantage to a quantity defined inside the paper, and the masking intervention is presented as an empirical follow-up motivated by the observations rather than a mathematical necessity. The central claims therefore remain independent of the inputs they analyze.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Standard assumptions of supervised fine-tuning on next-token prediction apply to the agent training runs.
- domain assumption The difference between prompt-action and CoT-action outputs isolates the contribution of generated reasoning.
Reference graph
Works this paper leans on
-
[1]
Iv \'a n Arcuschin, Jett Janiak, Robert Krzyzanowski, Senthooran Rajamanoharan, Neel Nanda, and Arthur Conmy. 2025. Chain-of-thought reasoning in the wild is not always faithful. arXiv preprint arXiv:2503.08679
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Hao Bai, Yifei Zhou, Jiayi Pan, Mert Cemri, Alane Suhr, Sergey Levine, and Aviral Kumar. 2024. Digirl: Training in-the-wild device-control agents with autonomous reinforcement learning. Advances in Neural Information Processing Systems, 37:12461--12495
2024
-
[3]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, and 1 others. 2023. Qwen technical report. arXiv preprint arXiv:2309.16609
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Siddhant Bhambri, Mudit Verma, and Subbarao Kambhampati. 2025. Do think tags really help llms plan? a critical evaluation of react-style prompting. Transactions on Machine Learning Research
2025
-
[5]
Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V Le, Sergey Levine, and Yi Ma. 2025. Sft memorizes, rl generalizes: A comparative study of foundation model post-training. arXiv preprint arXiv:2501.17161
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, and 1 others. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Hangzhan Jin, Sitao Luan, Sicheng Lyu, Guillaume Rabusseau, Reihaneh Rabbany, Doina Precup, and Mohammad Hamdaqa. 2025. Rl fine-tuning heals ood forgetting in sft. arXiv preprint arXiv:2509.12235
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, and 1 others. 2023. Measuring faithfulness in chain-of-thought reasoning. arXiv preprint arXiv:2307.13702
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Junwei Liao, Muning Wen, Jun Wang, and Weinan Zhang. 2025. Marft: Multi-agent reinforcement fine-tuning. arXiv preprint arXiv:2504.16129
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [10]
-
[11]
Elita Lobo, Chirag Agarwal, and Himabindu Lakkaraju. 2025. On the impact of fine-tuning on chain-of-thought reasoning. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 11679--11698
2025
-
[12]
Shishir G Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E Gonzalez. 2025. The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models. In Forty-second International Conference on Machine Learning
2025
-
[13]
Debjit Paul, Robert West, Antoine Bosselut, and Boi Faltings. 2024. Making reasoning matter: Measuring and improving faithfulness of chain-of-thought reasoning. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 15012--15032
2024
-
[14]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728--53741
2023
-
[15]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, and 1 others. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [16]
-
[17]
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre C \^o t \'e , Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. 2020. Alfworld: Aligning text and embodied environments for interactive learning. arXiv preprint arXiv:2010.03768
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[18]
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, and 1 others. 2024. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel Bowman. 2023. Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting. Advances in Neural Information Processing Systems, 36:74952--74965
2023
- [20]
- [21]
- [22]
- [23]
- [24]
- [25]
- [26]
- [27]
-
[28]
Kai Zhang, Xiangchao Chen, Bo Liu, Tianci Xue, Zeyi Liao, Zhihan Liu, Xiyao Wang, Yuting Ning, Zhaorun Chen, Xiaohan Fu, and 1 others. 2025 a . Agent learning via early experience. arXiv preprint arXiv:2510.08558
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [29]
- [30]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.