MinGram: A Minimalist Unigram Tokenizer with High Compression and Competitive Morphological Alignment
Pith reviewed 2026-06-26 04:56 UTC · model grok-4.3
The pith
MinGram simplifies Unigram training with a BPE seed and Hard EM to compress better than BPE and standard Unigram while retaining higher morphological alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
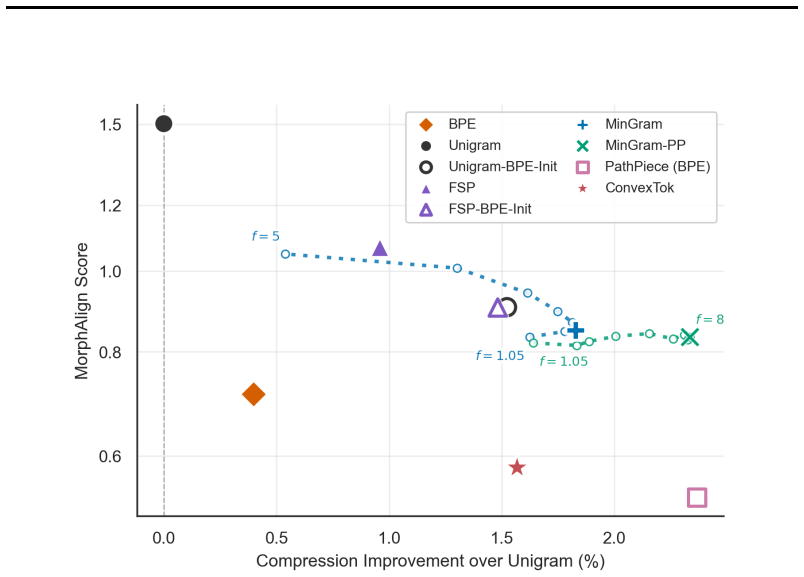
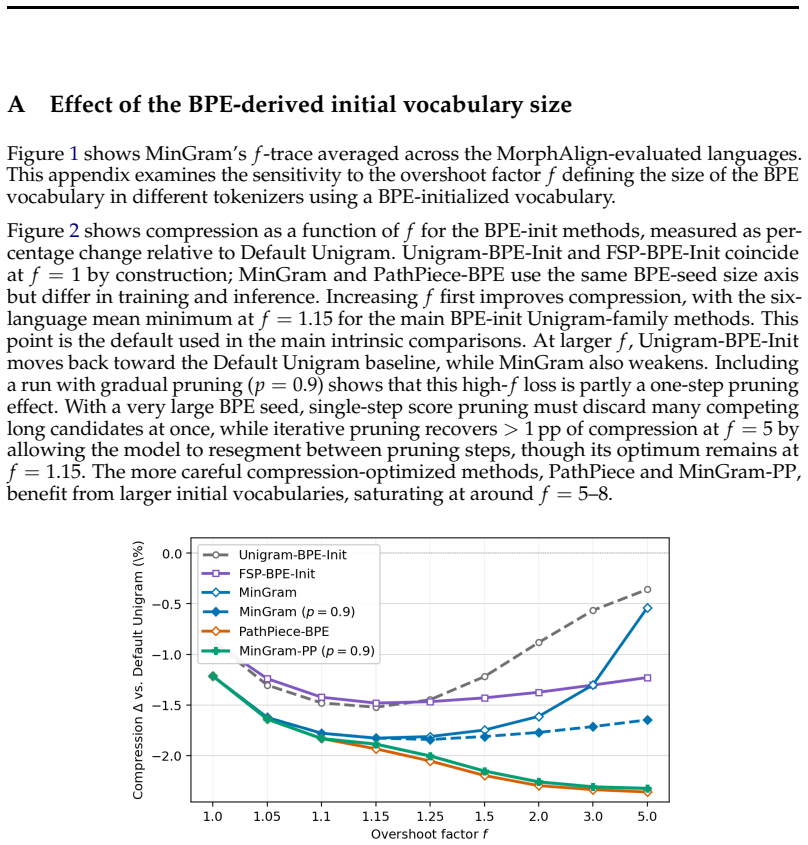
MinGram keeps the token-list representation of Unigram but replaces its heavy training machinery with a BPE-derived seed vocabulary, Hard EM on a minimum-token path, and a single flat score-pruning step. By making token count the primary objective and the Unigram score only a tiebreaker, MinGram produces tokenizers that compress better than both BPE and standard Unigram across six languages while retaining substantially higher morphological alignment than pure token-count compressors. In controlled downstream language-model training, Unigram-family tokenizers with MinGram among the best consistently beat BPE when measured by bits-per-byte.
What carries the argument
BPE-derived seed vocabulary plus Hard EM on the minimum-token path and a single flat score-pruning step that ranks token count first and Unigram score second.
If this is right
- Simpler training procedures can produce tokenizers that are at least as effective as the more complex originals.
- Unigram-family tokenizers can be chosen over BPE when downstream language-model bits-per-byte is the performance metric.
- A compression-oriented variant can approach the best token-count compressors without sacrificing as much morphological alignment.
- Tokenizer development can focus on minimum-token paths rather than full probabilistic inference.
- The same simplification pattern may be reusable for other tokenizer families that currently rely on heavy training loops.
Where Pith is reading between the lines
- The method could let practitioners iterate tokenizer vocabularies more quickly when adapting to new domains or data distributions.
- Removing the iterative prune loop may reduce the compute barrier to experimenting with Unigram-style tokenizers on modest hardware.
- The emphasis on minimum token count may translate into smaller effective model sizes or faster inference in resource-limited settings.
- Similar seed-and-prune shortcuts might be tested on other tokenization objectives such as fertility or downstream task performance.
Load-bearing premise
That a BPE-derived seed vocabulary, Hard EM restricted to the minimum-token path, and one flat pruning step will yield tokenizers whose compression and morphological properties match or exceed those obtained from full Unigram training with its removed components.
What would settle it
Run MinGram and standard Unigram on a seventh language; if MinGram no longer compresses better than BPE or loses the morphological-alignment advantage, the central claim is falsified.
Figures
read the original abstract
The Unigram tokenizer uses an elegant representation which makes it straightforward to edit vocabularies, but its training is comparatively heavy and complex. We introduce MinGram (Minimalist Unigram), which keeps the token-list representation but simplifies training using a BPE-derived seed vocabulary, Hard EM on a minimum-token path, and a single flat score-pruning step. This removes the suffix array, the forward-backward pass, and the iterative prune loop, leaving a procedure that requires little beyond tokenizer inference itself. By making token count the primary objective and using a Unigram score only as a tiebreak, MinGram keeps the compression of pure token-count methods while retaining much of the morphological alignment and downstream quality of probabilistic ones. Across six languages, MinGram compresses better than both BPE and standard Unigram, and a compression-oriented variant matches the strongest token-count compressors while retaining substantially higher morphological alignment. In controlled downstream language-model training, Unigram-family tokenizers, with MinGram among the best, consistently beat BPE in bits-per-byte.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MinGram, a minimalist Unigram tokenizer that starts from a BPE-derived seed vocabulary and applies Hard EM restricted to minimum-token paths followed by a single flat score-pruning step. This removes the suffix array, forward-backward algorithm, and iterative prune loop from standard Unigram training. The central empirical claims are that MinGram achieves higher compression than both BPE and standard Unigram across six languages, a compression-oriented variant matches the strongest token-count compressors while retaining substantially higher morphological alignment, and Unigram-family tokenizers (with MinGram among the best) consistently outperform BPE in controlled downstream language-model training as measured by bits-per-byte.
Significance. If the results hold after verification of the simplifications, the contribution would be significant for NLP tokenization research. It demonstrates that a substantially lighter training procedure can match or exceed the compression and downstream performance of both BPE and full Unigram while preserving morphological alignment better than pure count-based methods. The explicit prioritization of token count with Unigram score used only as tiebreak is a clean way to combine objectives. The work would be strengthened by reproducible code or parameter-free derivations, but none are mentioned.
major comments (2)
- [Training procedure (§3) and Experiments (§4)] The central claim that the BPE-seeded Hard EM on minimum-token paths plus single pruning produces tokenizers whose compression and morphological properties meet or exceed those of full Unigram rests on the unverified assumption that the removed components (suffix array, forward-backward, iterative pruning) are dispensable. No ablation or direct comparison to standard Unigram training is described that would confirm the resulting token probabilities and segmentations remain sufficiently close.
- [Abstract and §4.3] The abstract and experimental claims state improvements 'across six languages' and 'consistently beat BPE in bits-per-byte' but supply no baselines, statistical tests, number of runs, variance estimates, or exact metric values. This makes it impossible to assess whether the reported gains are robust or load-bearing for the downstream conclusion.
minor comments (2)
- [§3] Notation for the 'flat score-pruning step' and 'minimum-token path' should be defined with explicit equations or pseudocode to allow replication.
- [§4.1] The six languages used in the multilingual experiments are not listed; adding this detail would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We address each major comment below, indicating planned revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: [Training procedure (§3) and Experiments (§4)] The central claim that the BPE-seeded Hard EM on minimum-token paths plus single pruning produces tokenizers whose compression and morphological properties meet or exceed those of full Unigram rests on the unverified assumption that the removed components (suffix array, forward-backward, iterative pruning) are dispensable. No ablation or direct comparison to standard Unigram training is described that would confirm the resulting token probabilities and segmentations remain sufficiently close.
Authors: The manuscript directly compares the final MinGram tokenizers to standard Unigram on the key metrics of compression ratio, morphological alignment, and downstream bits-per-byte performance, with MinGram showing higher compression and competitive alignment. These end-to-end results serve as empirical validation that the simplifications preserve (and in some cases improve) the desired properties. We agree that an explicit internal comparison of token probabilities or segmentation distributions would strengthen the argument. We will add such a comparison (e.g., vocabulary overlap and average path length statistics) in the revised version. revision: yes
-
Referee: [Abstract and §4.3] The abstract and experimental claims state improvements 'across six languages' and 'consistently beat BPE in bits-per-byte' but supply no baselines, statistical tests, number of runs, variance estimates, or exact metric values. This makes it impossible to assess whether the reported gains are robust or load-bearing for the downstream conclusion.
Authors: We will revise the abstract and §4.3 to report exact baseline values, the number of runs (five random seeds for the language-model experiments), variance estimates, and the results of statistical significance tests (paired t-tests across seeds) to make the robustness of the gains explicit. revision: yes
Circularity Check
No circularity: empirical claims rest on measured outcomes, not self-referential definitions or derivations.
full rationale
The paper defines MinGram via an explicit algorithmic procedure (BPE seed vocabulary + Hard EM restricted to minimum-token paths + single flat score-pruning) and then reports measured compression ratios, morphological alignment scores, and downstream bits-per-byte on held-out data across six languages. No equations, first-principles derivations, or predictions appear; the central claims are direct experimental results that can be falsified by re-running the procedure on the same corpora. No self-citations are invoked as load-bearing uniqueness theorems, no fitted parameters are relabeled as predictions, and the method is not shown to be equivalent to its inputs by construction. The simplification's validity is an empirical question, not a definitional one.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Minimizing the number of tokens produced is a valid primary objective for tokenizer quality, with probabilistic scores used only as tiebreakers.
Reference graph
Works this paper leans on
-
[1]
Schmidt, Varshini Reddy, Haoran Zhang, Alec Alameddine, Omri Uzan, Yuval Pinter, and Chris Tanner
Schmidt, Craig W and Reddy, Varshini and Zhang, Haoran and Alameddine, Alec and Uzan, Omri and Pinter, Yuval and Tanner, Chris. Tokenization Is More Than Compression. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.40
-
[2]
and Tanner, Chris and Pinter, Yuval
Uzan, Omri and Schmidt, Craig W. and Tanner, Chris and Pinter, Yuval. Greed is All You Need: An Evaluation of Tokenizer Inference Methods. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2024. doi:10.18653/v1/2024.acl-short.73
-
[3]
Tokenization and the Noiseless Channel
Zouhar, Vil \'e m and Meister, Clara and Gastaldi, Juan and Du, Li and Sachan, Mrinmaya and Cotterell, Ryan. Tokenization and the Noiseless Channel. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.284
-
[4]
Two Counterexamples to Tokenization and the Noiseless Channel
Cognetta, Marco and Zouhar, Vil \'e m and Moon, Sangwhan and Okazaki, Naoaki. Two Counterexamples to Tokenization and the Noiseless Channel. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024
2024
-
[5]
NLLB Team and Costa-juss \`a , Marta R. and Cross, James and C elebi, Onur and Elbayad, Maha and Heafield, Kenneth and Heffernan, Kevin and Kalbassi, Elahe and Lam, Janice and Licht, Daniel and Maillard, Jean and Sun, Anna and Wang, Skyler and Wenzek, Guillaume and Youngblood, Al and Akula, Bapi and Barrault, Loic and Gonzalez, Gabriel Mejia and Hansanti,...
-
[6]
Byte pair encoding is suboptimal for language model pretraining
Bostrom, Kaj and Durrett, Greg. Byte Pair Encoding is Suboptimal for Language Model Pretraining. Findings of the Association for Computational Linguistics: EMNLP 2020. 2020. doi:10.18653/v1/2020.findings-emnlp.414
-
[7]
Incorporating Context into Subword Vocabularies
Yehezkel, Shaked and Pinter, Yuval. Incorporating Context into Subword Vocabularies. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics. 2023. doi:10.18653/v1/2023.eacl-main.45
-
[8]
Vemula, Saketh Reddy and Dandapat, Sandipan and Sharma, Dipti and Krishnamurthy, Parameswari. Rethinking Tokenization for Rich Morphology: The Dominance of U nigram over BPE and Morphological Alignment. The 14th International Joint Conference on Natural Language Processing and The 4th Conference of the Asia-Pacific Chapter of the Association for Computati...
-
[9]
Ehsaneddin Asgari and Yassine El Kheir and Mohammad Ali Sadraei Javaheri , year=. 2502.00894 , archivePrefix=
-
[10]
Sander Land and Yuval Pinter , year=. Which Pieces Does. 2512.12641 , archivePrefix=
-
[11]
2025 , publisher =
Guilherme Penedo , title =. 2025 , publisher =
2025
-
[12]
2020 , eprint=
BPE-Dropout: Simple and Effective Subword Regularization , author=. 2020 , eprint=
2020
-
[13]
Stephen, Abishek and Libovick \'y , Jind r ich. Evaluating Morphological Plausibility of Subword Tokenization via Statistical Alignment with Morpho-Syntactic Features. Findings of the A ssociation for C omputational L inguistics: EACL 2026. 2026. doi:10.18653/v1/2026.findings-eacl.196
-
[14]
2025 , eprint=
Evaluating Morphological Alignment of Tokenizers in 70 Languages , author=. 2025 , eprint=
2025
-
[15]
A. P. Dempster and N. M. Laird and D. B. Rubin , journal =. Maximum Likelihood from Incomplete Data via the
-
[16]
Kudo, Taku and Richardson, John. SentencePiece : A simple and language independent subword tokenizer and detokenizer for Neural Text Processing. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2018. doi:10.18653/v1/D18-2012
work page internal anchor Pith review doi:10.18653/v1/d18-2012 2018
-
[17]
Combinatorial Pattern Matching , pages=
Linear-Time Longest-Common-Prefix Computation in Suffix Arrays and Its Applications , author=. Combinatorial Pattern Matching , pages=. 2001 , organization=
2001
-
[18]
Sander Land and Catherine Arnett , year=. 2505.24689 , archivePrefix=
-
[19]
BPE Gets Picky: Efficient Vocabulary Refinement During Tokenizer Training
Chizhov, Pavel and Arnett, Catherine and Korotkova, Elizaveta and Yamshchikov, Ivan P. BPE Gets Picky: Efficient Vocabulary Refinement During Tokenizer Training. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.925
-
[20]
and Bergen, Benjamin
Arnett, Catherine and Chang, Tyler A. and Bergen, Benjamin. Proceedings of the 3rd Annual Meeting of the Special Interest Group on Under-resourced Languages @ LREC-COLING 2024. 2024
2024
-
[21]
Neural machine translation of rare words with subword units
Sennrich, Rico and Haddow, Barry and Birch, Alexandra. Neural Machine Translation of Rare Words with Subword Units. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2016. doi:10.18653/v1/P16-1162
-
[22]
Proceedings of the 31st International Conference on Computational Linguistics
Velayuthan, Menan and Sarveswaran, Kengatharaiyer. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[23]
Pre-tokenization on punctuation in
Sander Land , year=. Pre-tokenization on punctuation in
-
[24]
Catherine Arnett , year=
-
[25]
A Monolingual Approach to Contextualized Word Embeddings for Mid-Resource Languages
Ortiz Suarez, Pedro Javier and Romary, Laurent and Sagot, Benoit. A Monolingual Approach to Contextualized Word Embeddings for Mid-Resource Languages. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020
2020
-
[26]
Pedro Javier. Asynchronous pipelines for processing huge corpora on medium to low resource infrastructures , series =. 2019 , language =. doi:10.14618/ids-pub-9021 , url =
-
[27]
Rossi and Thien Huu Nguyen , year=
Thuat Nguyen and Chien Van Nguyen and Viet Dac Lai and Hieu Man and Nghia Trung Ngo and Franck Dernoncourt and Ryan A. Rossi and Thien Huu Nguyen , year=. 2309.09400 , archivePrefix=
-
[28]
Jamo-Level Subword Tokenization in Low-Resource K orean Machine Translation
Lee, Junyoung and Cognetta, Marco and Moon, Sangwhan and Okazaki, Naoaki. Jamo-Level Subword Tokenization in Low-Resource K orean Machine Translation. Proceedings of the Eighth Workshop on Technologies for Machine Translation of Low-Resource Languages (LoResMT 2025). 2025
2025
-
[29]
doi: 10.18653/v1/2024.emnlp-main.649
Land, Sander and Bartolo, Max. Fishing for M agikarp: Automatically Detecting Under-trained Tokens in Large Language Models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.649
-
[30]
Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin L...
Pith/arXiv arXiv 1910
-
[31]
2017 , eprint=
Tying Word Vectors and Word Classifiers: A Loss Framework for Language Modeling , author=. 2017 , eprint=
2017
-
[32]
Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates
Kudo, Taku. Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018. doi:10.18653/v1/P18-1007
-
[33]
BPE -Dropout: Simple and Effective Subword Regularization
Provilkov, Ivan and Emelianenko, Dmitrii and Voita, Elena. BPE -Dropout: Simple and Effective Subword Regularization. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.170
-
[34]
Sabrina J. Mielke and Zaid Alyafeai and Elizabeth Salesky and Colin Raffel and Manan Dey and Matthias Gallé and Arun Raja and Chenglei Si and Wilson Y. Lee and Benoît Sagot and Samson Tan , year=. Between words and characters: A Brief History of Open-Vocabulary Modeling and Tokenization in. 2112.10508 , archivePrefix=
-
[35]
Too Much in Common: Shifting of Embeddings in Transformer Language Models and its Implications
Bi \'s , Daniel and Podkorytov, Maksim and Liu, Xiuwen. Too Much in Common: Shifting of Embeddings in Transformer Language Models and its Implications. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021. doi:10.18653/v1/2021.naacl-main.403
-
[36]
2025 , url=
Alisa Liu and Jonathan Hayase and Valentin Hofmann and Sewoong Oh and Noah A Smith and Yejin Choi , booktitle=. 2025 , url=
2025
-
[37]
2025 , eprint=
Parity-Aware Byte-Pair Encoding: Improving Cross-lingual Fairness in Tokenization , author=. 2025 , eprint=
2025
-
[38]
2026 , url =
Proceedings of the Fourteenth International Conference on Learning Representations , author =. 2026 , url =
2026
-
[39]
Language Model Tokenizers Introduce Unfairness Between Languages , url =
Petrov, Aleksandar and La Malfa, Emanuele and Torr, Philip and Bibi, Adel , booktitle =. Language Model Tokenizers Introduce Unfairness Between Languages , url =
-
[40]
Do All Languages Cost the Same? T okenization in the Era of Commercial Language Models
Ahia, Orevaoghene and Kumar, Sachin and Gonen, Hila and Kasai, Jungo and Mortensen, David and Smith, Noah and Tsvetkov, Yulia. Do All Languages Cost the Same? Tokenization in the Era of Commercial Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.614
-
[41]
Tokenizer Choice For LLM Training: Negligible or Crucial?
Ali, Mehdi and Fromm, Michael and Thellmann, Klaudia and Rutmann, Richard and L \"u bbering, Max and Leveling, Johannes and Klug, Katrin and Ebert, Jan and Doll, Niclas and Buschhoff, Jasper and Jain, Charvi and Weber, Alexander and Jurkschat, Lena and Abdelwahab, Hammam and John, Chelsea and Ortiz Suarez, Pedro and Ostendorff, Malte and Weinbach, Samuel ...
-
[42]
Lotz, Jonas F. and Lopes, Ant \'o nio V. and Peitz, Stephan and Setiawan, Hendra and Emili, Leonardo. Beyond Text Compression: Evaluating Tokenizers Across Scales. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1546
-
[43]
Why do language models perform worse for morphologically complex languages?
Arnett, Catherine and Bergen, Benjamin. Why do language models perform worse for morphologically complex languages?. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[44]
doi: 10.18653/v1/2021.acl-long.243
Rust, Phillip and Pfeiffer, Jonas and Vuli \'c , Ivan and Ruder, Sebastian and Gurevych, Iryna. How Good is Your Tokenizer? On the Monolingual Performance of Multilingual Language Models. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volum...
-
[45]
Hofmann, Valentin and Pierrehumbert, Janet and Sch. Superbizarre Is Not Superb: Derivational Morphology Improves BERT ' s Interpretation of Complex Words. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10.1...
-
[46]
2026 , eprint=
Tokenisation via Convex Relaxations , author=. 2026 , eprint=
2026
-
[47]
2026 , eprint=
Goldfish: Monolingual Language Models for 350 Languages , author=. 2026 , eprint=
2026
-
[48]
Lian, Haoran and Xiong, Yizhe and Niu, Jianwei and Mo, Shasha and Su, Zhenpeng and Lin, Zijia and Chen, Hui and Han, Jungong and Ding, Guiguang , title =. 2025 , isbn =. doi:10.1609/aaai.v39i23.34633 , booktitle =
-
[49]
The U niversity of E dinburgh ' s Neural MT Systems for WMT 17
Sennrich, Rico and Birch, Alexandra and Currey, Anna and Germann, Ulrich and Haddow, Barry and Heafield, Kenneth and Miceli Barone, Antonio Valerio and Williams, Philip. The U niversity of E dinburgh ' s Neural MT Systems for WMT 17. Proceedings of the Second Conference on Machine Translation. 2017. doi:10.18653/v1/W17-4739
-
[50]
Second Conference on Language Modeling , year=
Boundless Byte Pair Encoding: Breaking the Pre-tokenization Barrier , author=. Second Conference on Language Modeling , year=
-
[51]
Investigating the Effectiveness of BPE : The Power of Shorter Sequences
Gall \'e , Matthias. Investigating the Effectiveness of BPE : The Power of Shorter Sequences. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1141
-
[52]
2026 , eprint=
Tokenization with Split Trees , author=. 2026 , eprint=
2026
-
[53]
Shizhe Diao and Yu Yang and Yonggan Fu and Xin Dong and Dan Su and Markus Kliegl and Zijia Chen and Peter Belcak and Yoshi Suhara and Hongxu Yin and Mostofa Patwary and Yingyan Lin and Jan Kautz and Pavlo Molchanov , year=. Nemotron-. 2504.13161 , archivePrefix=
-
[54]
2025 , publisher =
Andrej Karpathy , title =. 2025 , publisher =
2025
-
[55]
and Carmon, Yair and Dave, Achal and Schmidt, Ludwig and Shankar, Vaishaal , booktitle =
Li, Jeffrey and Fang, Alex and Smyrnis, Georgios and Ivgi, Maor and Jordan, Matt and Gadre, Samir and Bansal, Hritik and Guha, Etash and Keh, Sedrick and Arora, Kushal and Garg, Saurabh and Xin, Rui and Muennighoff, Niklas and Heckel, Reinhard and Mercat, Jean and Chen, Mayee and Gururangan, Suchin and Wortsman, Mitchell and Albalak, Alon and Bitton, Yona...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.