Inherited Circuits, Learned Semantics: How Fine-Tuning Creates Evasion Vulnerabilities Invisible to Standard Evaluation
Pith reviewed 2026-06-26 03:42 UTC · model grok-4.3
The pith
Fine-tuning specializes an inherited classification circuit into token-level rules that preserve accuracy but fail under command transformations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
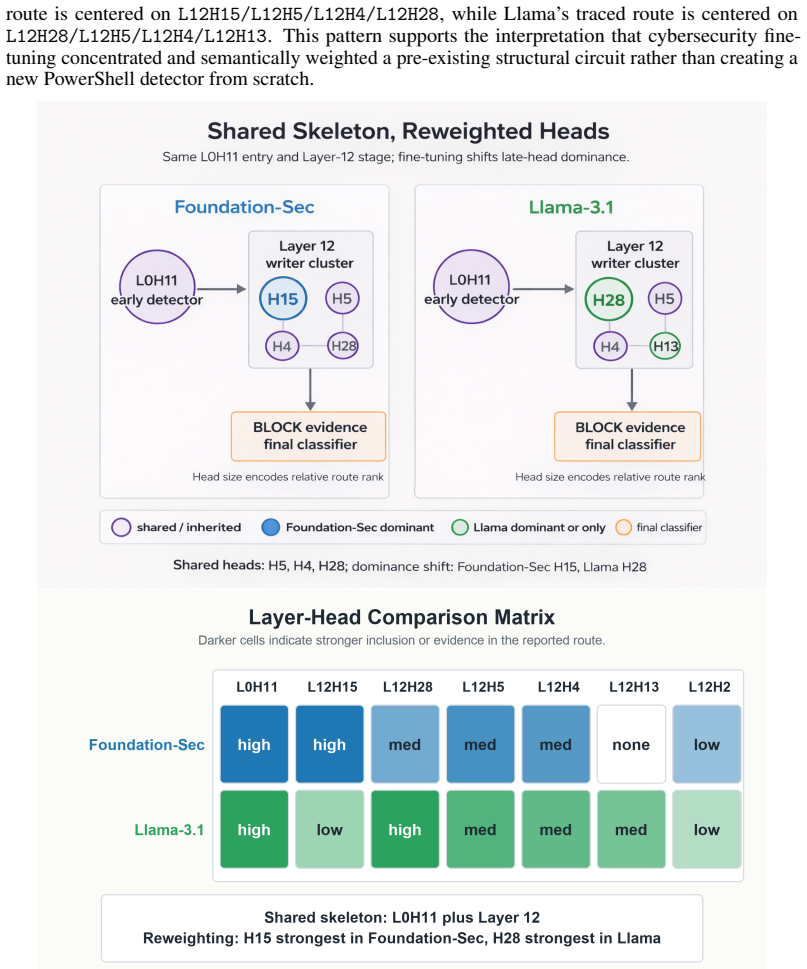
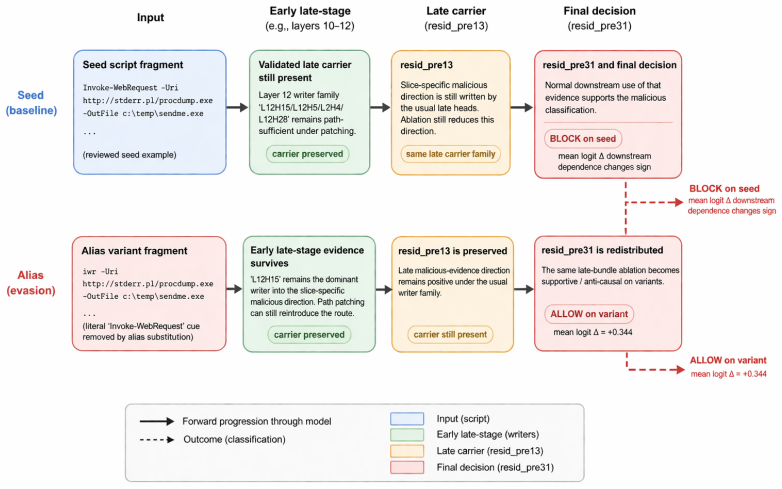
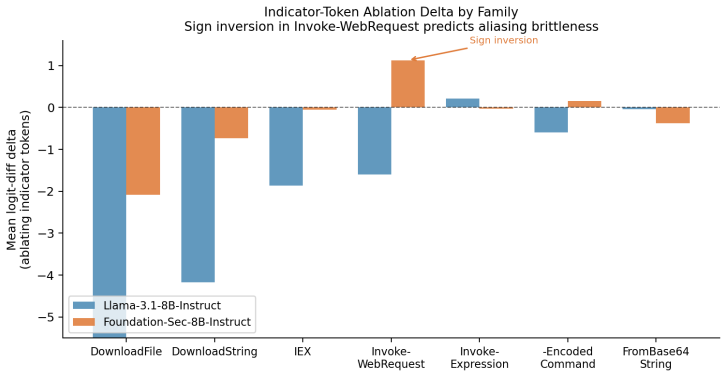
Fine-tuning concentrates and semantically specializes this inherited structure, improving baseline behavior while creating transformation-sensitive attack surfaces. A three-tier evasion benchmark finds Foundation-Sec misses on iwr substitution, Invoke-Expression reconstruction, and case-mutated Invoke-Expression/IEX variants that Llama does not share.
What carries the argument
The late-attention route that functions as the inherited classification circuit and gets specialized by fine-tuning into token-indicator semantics.
If this is right
- Fine-tuning improves canonical accuracy while expanding the evasion surface under behavior-preserving transformations.
- Standard held-out evaluation on the same distribution misses these transformation-sensitive failures.
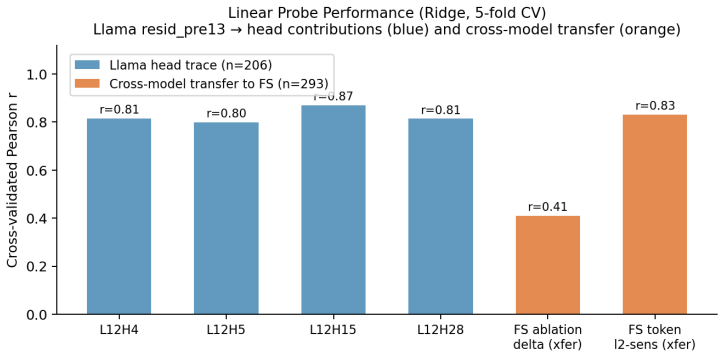
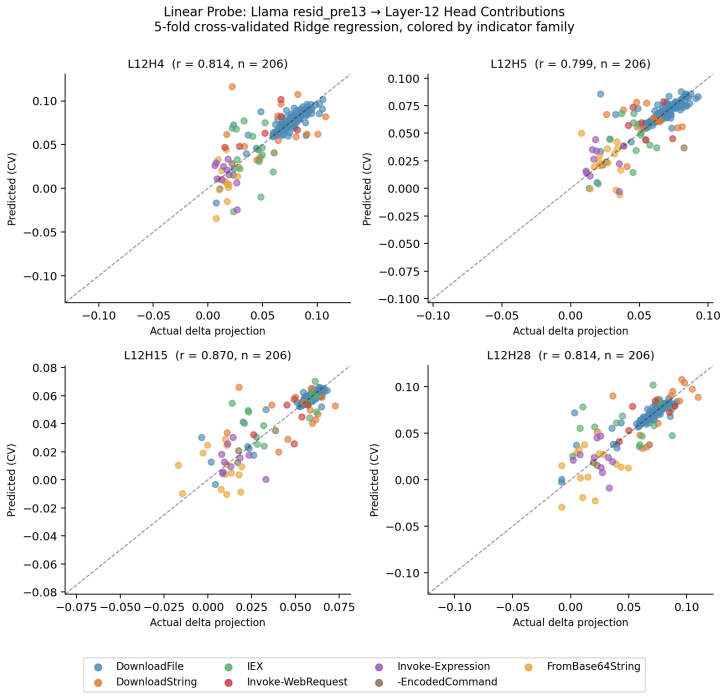
- A linear probe at the classification boundary combined with an indicator-token sign test can detect command families where canonical indicators change role.
- Robust security classifiers require specifying the full transformation space of the task rather than relying on canonical accuracy alone.
- Small task-specific fine-tunes are not straightforwardly safer than base models for security classification.
Where Pith is reading between the lines
- The pattern may appear in fine-tuned detectors for other scripting languages or file formats beyond PowerShell.
- The monitoring signals could be applied during training to select checkpoints that limit semantic narrowing.
- Including behavior-preserving transformations directly in fine-tuning data might reduce the creation of brittle indicator rules.
- Base models may retain broader circuit usage that fine-tuning narrows, suggesting hybrid approaches that preserve more of the original structure.
Load-bearing premise
The causal interventions correctly identify the late-attention route as the classification circuit and the observed differences stem from specialization rather than other training or cohort factors.
What would settle it
If the fine-tuned model shows equivalent or lower miss rates than the base model on the three-tier evasion benchmark for iwr substitution, Invoke-Expression reconstruction, and case-mutated variants, the claim of newly created vulnerabilities would not hold.
Figures
read the original abstract
LLMs fine-tuned for security classification are usually evaluated on held-out examples from the same distribution as their training data. We show that this can miss vulnerabilities introduced by fine-tuning itself: models can learn token-level indicator semantics that preserve canonical accuracy while failing under behavior-preserving transformations such as PowerShell alias substitution, command reconstruction, string construction, execution indirection, and case mutation. We study Foundation-Sec-8B-Instruct and its base model, Llama-3.1-8B-Instruct, on matched PowerShell classification cohorts. Causal interventions localize the classification circuit to a late-attention route inherited from Llama rather than created by fine-tuning. Fine-tuning concentrates and semantically specializes this inherited structure, improving baseline behavior while creating transformation-sensitive attack surfaces. A three-tier evasion benchmark finds Foundation-Sec misses on iwr substitution, Invoke-Expression reconstruction, and case-mutated Invoke-Expression/IEX variants that Llama does not share. We also derive a pre-deployment monitoring method: a linear probe at the classification boundary and an indicator-token sign test identify command families where canonical indicators change role after fine-tuning. These signals prioritize red-team variant generation using only canonical inputs, showing that security fine-tuning can improve task accuracy while expanding the evasion surface. These results caution against treating small task-specific fine-tunes as straightforwardly safer security classifiers: specialization can convert inherited model structure into brittle indicator rules that preserve held-out accuracy while expanding the evasion surface. Robust AI-enabled security will require specifying the full transformation space of the task and monitoring semantic drift through fine-tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that fine-tuning LLMs for security classification on matched PowerShell cohorts can introduce evasion vulnerabilities to behavior-preserving transformations (iwr substitution, Invoke-Expression reconstruction, case mutation) that standard held-out evaluation misses. Causal interventions localize the classification circuit to a late-attention route inherited from the base Llama-3.1-8B-Instruct rather than created by fine-tuning; fine-tuning concentrates and semantically specializes this structure, improving canonical accuracy while creating transformation-sensitive attack surfaces. A three-tier evasion benchmark demonstrates Foundation-Sec-8B-Instruct misses variants that the base model does not. The authors also derive a pre-deployment monitoring method (linear probe at the classification boundary plus indicator-token sign test) to detect semantic drift and prioritize red-team variant generation from canonical inputs.
Significance. If the causal attribution and benchmark results hold, the work is significant for AI-enabled security: it shows that small task-specific fine-tunes can convert inherited model structure into brittle indicator rules that preserve held-out accuracy while expanding the evasion surface, and it supplies a concrete monitoring technique usable before deployment. The emphasis on specifying the full transformation space of the task is a useful framing.
major comments (2)
- [Causal interventions / methods] The description of the causal interventions (late-attention route localization and confirmation that the circuit is inherited rather than created by fine-tuning) is given only at high level in the abstract and methods; exact intervention details, matching criteria for the PowerShell cohorts, and controls for optimization/cohort differences are not reported. This is load-bearing for the central claim that observed evasion differences are attributable to fine-tuning specialization.
- [Evasion benchmark / results] The three-tier evasion benchmark results (Foundation-Sec misses on iwr substitution, Invoke-Expression reconstruction, and case-mutated variants) are presented without reported statistical tests, sample sizes per tier, or ablation on whether the transformations preserve semantics equivalently across models. This undermines the strength of the cross-model comparison.
minor comments (1)
- [Abstract] The abstract contains several long sentences that could be split for readability.
Simulated Author's Rebuttal
We thank the referee for their careful review and constructive feedback. The two major comments identify areas where additional detail and statistical rigor will strengthen the manuscript; we address each below and will incorporate the requested expansions in revision.
read point-by-point responses
-
Referee: [Causal interventions / methods] The description of the causal interventions (late-attention route localization and confirmation that the circuit is inherited rather than created by fine-tuning) is given only at high level in the abstract and methods; exact intervention details, matching criteria for the PowerShell cohorts, and controls for optimization/cohort differences are not reported. This is load-bearing for the central claim that observed evasion differences are attributable to fine-tuning specialization.
Authors: We agree that the current description is insufficiently detailed for reproducibility and for fully supporting the causal attribution. In the revised manuscript we will expand the Methods section with the exact intervention specifications (targeted attention heads and layers, activation patching procedure), the precise cohort-matching criteria (semantic equivalence metrics, size balancing, and syntactic controls), and additional optimization controls (learning-rate schedules, epoch counts, and cohort composition statistics). These additions will make the localization and inheritance claims directly verifiable. revision: yes
-
Referee: [Evasion benchmark / results] The three-tier evasion benchmark results (Foundation-Sec misses on iwr substitution, Invoke-Expression reconstruction, and case-mutated variants) are presented without reported statistical tests, sample sizes per tier, or ablation on whether the transformations preserve semantics equivalently across models. This undermines the strength of the cross-model comparison.
Authors: We accept that statistical reporting and semantic-preservation ablations are required to strengthen the benchmark claims. The revised version will report exact sample sizes per tier, include statistical tests (McNemar’s test for paired model comparisons and binomial confidence intervals), and add an ablation confirming semantic equivalence of the transformations across models via both automated metrics and manual review. These changes will make the cross-model differences more robustly supported. revision: yes
Circularity Check
No significant circularity; empirical claims rest on independent interventions and benchmarks
full rationale
The paper presents empirical findings from causal interventions localizing a classification circuit to a late-attention route in Llama, followed by comparisons of evasion performance on a three-tier benchmark between base and fine-tuned models. No equations, fitted parameters renamed as predictions, self-definitional structures, or load-bearing self-citations are present in the provided text. The monitoring method (linear probe and sign test) is derived from observations rather than reducing to its own inputs by construction. The derivation chain is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The listed transformations (alias substitution, command reconstruction, string construction, execution indirection, case mutation) preserve semantic behavior of PowerShell commands
- domain assumption Causal interventions accurately localize the classification decision to a late-attention route inherited from the base model
Reference graph
Works this paper leans on
-
[1]
Emmanuel Ameisen, Jack Lindsey, Adam Pearce, Wes Gurnee, Nicholas L. Turner, Brian Chen, Craig Citro, David Abrahams, Shan Carter, Basil Hosmer, Jonathan Marcus, Michael Sklar, Adly Templeton, Trenton Bricken, Callum McDougall, Hoagy Cunningham, Thomas Henighan, Adam Jermyn, Andy Jones, Andrew Persic, Zhenyi Qi, T. Ben Thompson, Sam Zimmerman, Kelley Rivo...
2025
-
[2]
Thread: Circuits.Distill, 2020
Nick Cammarata, Shan Carter, Gabriel Goh, Chris Olah, Michael Petrov, Ludwig Schubert, Chelsea V oss, Ben Egan, and Swee Kiat Lim. Thread: Circuits.Distill, 2020. doi: 10.23915/ distill.00024. URLhttps://distill.pub/2020/circuits/
2020
-
[3]
Sunoh Choi. Malicious powershell detection using attention against adversarial attacks.Elec- tronics, 9(11):1817, 2020. doi: 10.3390/electronics9111817. URL https://doi.org/10. 3390/electronics9111817
-
[4]
Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adrià Garriga-Alonso
Arthur Conmy, Augustine N. Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adrià Garriga-Alonso. Towards automated circuit discovery for mechanistic inter- pretability. InAdvances in Neural Information Processing Systems 36 (NeurIPS 2023),
2023
-
[5]
URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/ 34e1dbe95d34d7ebaf99b9bcaeb5b2be-Abstract-Conference.html
2023
-
[6]
A mathematical framework for transformer circuits.Transformer Circuits Thread,
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. A...
-
[7]
URLhttps://transformer-circuits.pub/2021/framework/index.html
2021
-
[8]
Yong Fang, Xiangyu Zhou, and Cheng Huang. Effective method for detecting malicious power- shell scripts based on hybrid features.Neurocomputing, 448:30–39, 2021. ISSN 0925-2312. doi: https://doi.org/10.1016/j.neucom.2021.03.117. URL https://www.sciencedirect.com/ science/article/pii/S0925231221005099
-
[9]
Applied interpretability: Foundation-sec-instruct goes under the microscope, 2025
Ryan Fetterman. Applied interpretability: Foundation-sec-instruct goes under the microscope, 2025. URL https://web.archive. org/web/20260514152031/https://www.linkedin.com/pulse/ applied-interpretability-foundation-sec-instruct-goes-under-microscope-4nutc/ ?trackingId=cDE2TsL2TeuIYnt4MNPhtQ%3D%3D. Web Archive, accessed April 10, 2026
arXiv 2025
-
[10]
Detecting and understanding vulner- abilities in language models via mechanistic interpretability
Jorge García-Carrasco, Alejandro Maté, and Juan Trujillo. Detecting and understanding vulner- abilities in language models via mechanistic interpretability. InProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence (IJCAI 2024), pages 385–393, 2024. doi: 10.24963/ijcai.2024/43. URLhttps://doi.org/10.24963/ijcai.2024/43
-
[11]
Llama-3.1-foundationai- securityllm-base-8b technical report, 2025
Paul Kassianik, Baturay Saglam, Alexander Chen, Blaine Nelson, et al. Llama-3.1-foundationai- securityllm-base-8b technical report, 2025. URLhttps://arxiv.org/abs/2504.21039
arXiv 2025
-
[12]
Jack Lindsey, Wes Gurnee, Emmanuel Ameisen, Brian Chen, Adam Pearce, Nicholas L. Turner, Craig Citro, David Abrahams, Shan Carter, Basil Hosmer, Jonathan Marcus, Michael Sklar, Adly Templeton, Trenton Bricken, Callum McDougall, Hoagy Cunningham, Thomas Henighan, Adam Jermyn, Andy Jones, Andrew Persic, Zhenyi Qi, T. Ben Thompson, Sam Zimmerman, Kelley Rivo...
2025
-
[13]
Reiter, and Mahmood Sharif
Keane Lucas, Samruddhi Pai, Weiran Lin, Lujo Bauer, Michael K. Reiter, and Mahmood Sharif. Adversarial training for raw-binary malware classifiers. In32nd USENIX Security Symposium (USENIX Security 23), pages 1163–1180, 2023. URL https://www.usenix. org/conference/usenixsecurity23/presentation/lucas
2023
-
[14]
Evading provenance-based ML detectors with ad- versarial system actions
Kunal Mukherjee, Joshua Wiedemeier, Tianhao Wang, James Wei, Feng Chen, Muhyun Kim, Murat Kantarcioglu, and Kangkook Jee. Evading provenance-based ML detectors with ad- versarial system actions. In32nd USENIX Security Symposium (USENIX Security 23), pages 1199–1216, 2023. URL https://www.usenix.org/conference/usenixsecurity23/ presentation/mukherjee
2023
-
[15]
Attribution patching: Activation patching at industrial scale
Neel Nanda. Attribution patching: Activation patching at industrial scale. Blog post, 2023. URL https://www.neelnanda.io/mechanistic-interpretability/ attribution-patching
2023
-
[16]
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small
Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: a circuit for indirect object identification in GPT-2 small.CoRR, abs/2211.00593, 2022. doi: 10.48550/arXiv.2211.00593. URL https://arxiv.org/abs/ 2211.00593
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2211.00593 2022
-
[17]
Xu Wang, Yan Hu, Wenyu Du, Reynold Cheng, Benyou Wang, and Difan Zou. Towards under- standing fine-tuning mechanisms of llms via circuit analysis.arXiv preprint arXiv:2502.11812,
-
[18]
URLhttps://arxiv.org/abs/2502.11812
doi: 10.48550/arXiv.2502.11812. URLhttps://arxiv.org/abs/2502.11812
-
[19]
Llama-3.1-foundationai-securityllm-8b-instruct technical report, 2025
Sajana Weerawardhena, Paul Kassianik, Blaine Nelson, Baturay Saglam, Anu Vellore, et al. Llama-3.1-foundationai-securityllm-8b-instruct technical report, 2025. URL https://arxiv. org/abs/2508.01059. 17
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.