Kolmogorov Arnold networks (KAN) for aerodynamic prediction: a comparison with MLPs and GNNs
Pith reviewed 2026-06-26 05:10 UTC · model grok-4.3
The pith
Kolmogorov-Arnold networks predict airfoil pressure distributions with performance comparable to multilayer perceptrons but lower complexity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
KAN models show good performance in predicting the whole pressure coefficients and are able to interpolate across Mach numbers and angles of attack, however their performance is comparable --marginally inferior-- to a suitably trained MLP, where best performance is achieved by a GNN at the expense of requiring lengthier training. Optimal KAN models have typically much lower complexity than MLP and GNN hence resulting in faster training, but KANs suffer from training instabilities and their performance is highly dependent on proper hyperparameter optimisation.
What carries the argument
Kolmogorov-Arnold network, which uses trainable parameters to adapt activation functions rather than the coefficients of affine transformations.
If this is right
- KANs can predict entire pressure coefficient distributions on airfoils.
- KANs interpolate across varying Mach numbers and angles of attack.
- Optimal KANs have lower complexity than MLPs and GNNs, enabling faster training.
- GNNs provide the highest accuracy but require longer training times.
- KAN performance depends heavily on hyperparameter optimization and can suffer instabilities.
Where Pith is reading between the lines
- KANs could be advantageous in resource-constrained settings where model size matters more than peak accuracy.
- Stabilizing training procedures might make KANs competitive in other physics simulation tasks.
- Graph structures may better capture the spatial relationships in aerodynamic data than standard network architectures.
- Future comparisons should ensure identical hyperparameter search efforts for fair assessment.
Load-bearing premise
Hyperparameter optimization was performed with equivalent rigor and computational budget for KAN, MLP, and GNN models.
What would settle it
Retraining all three model types with an identical extensive hyperparameter search procedure and comparing the resulting test errors on the same airfoil pressure dataset.
Figures
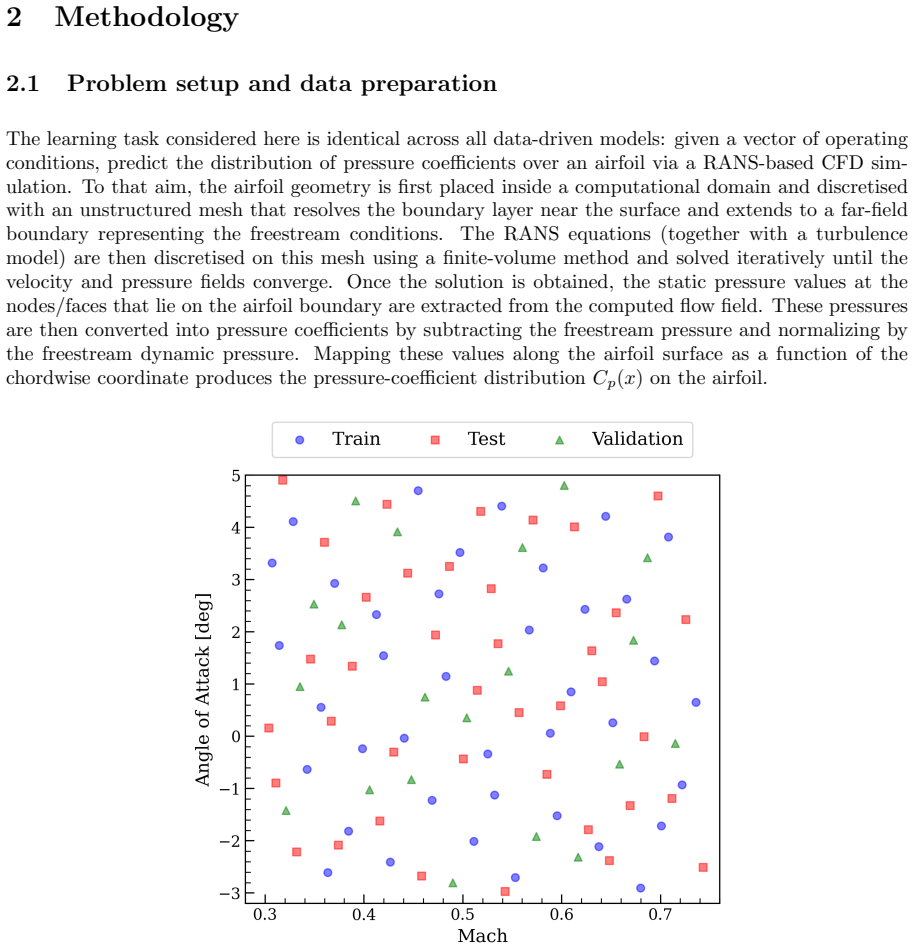
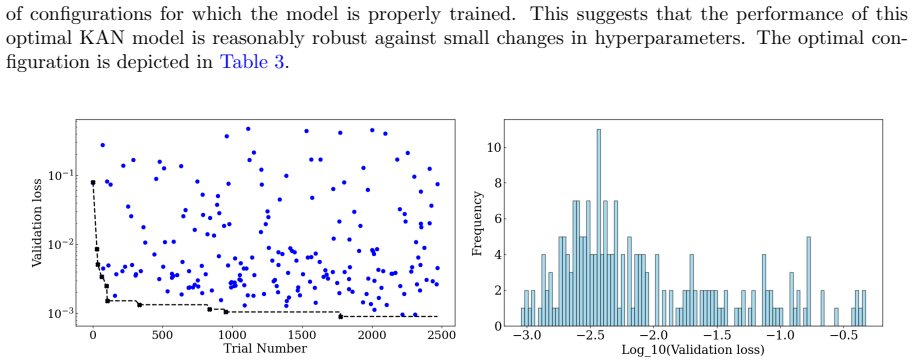
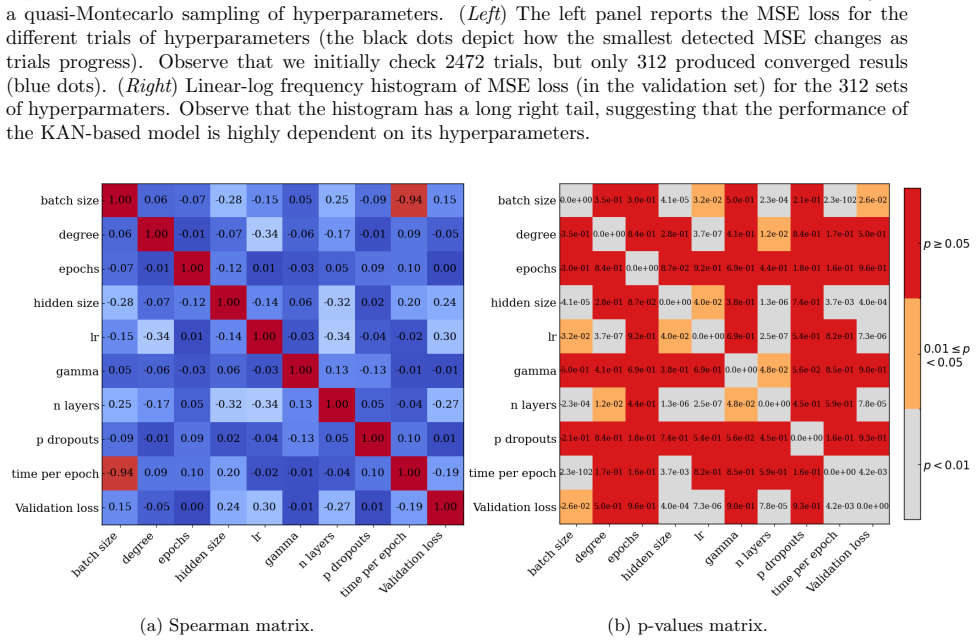
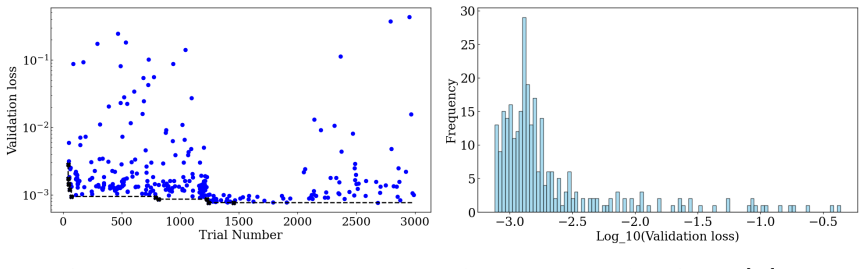
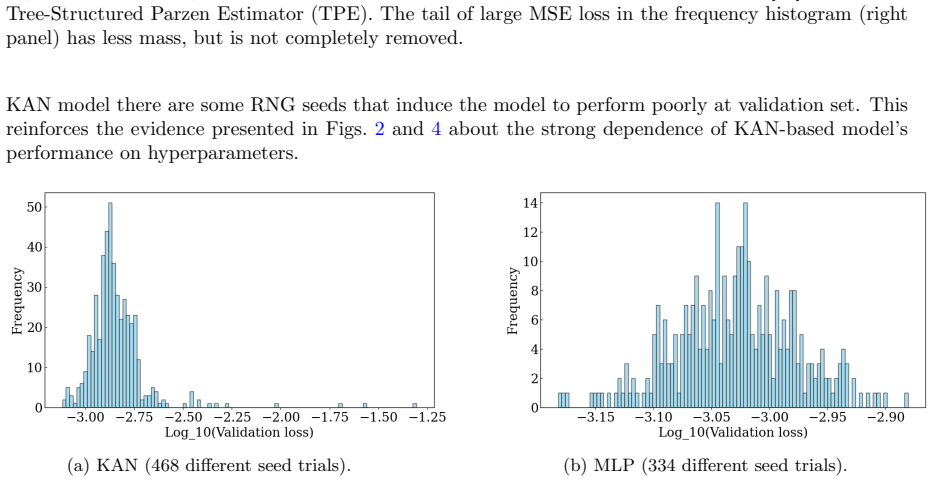
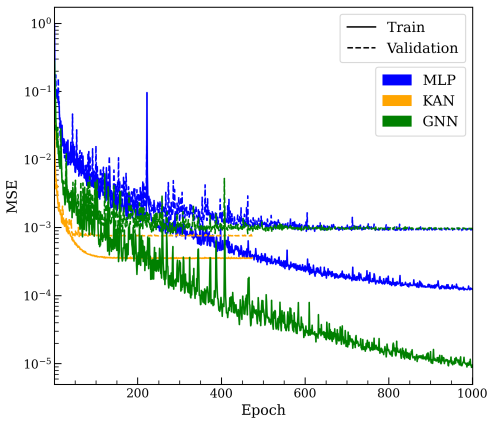
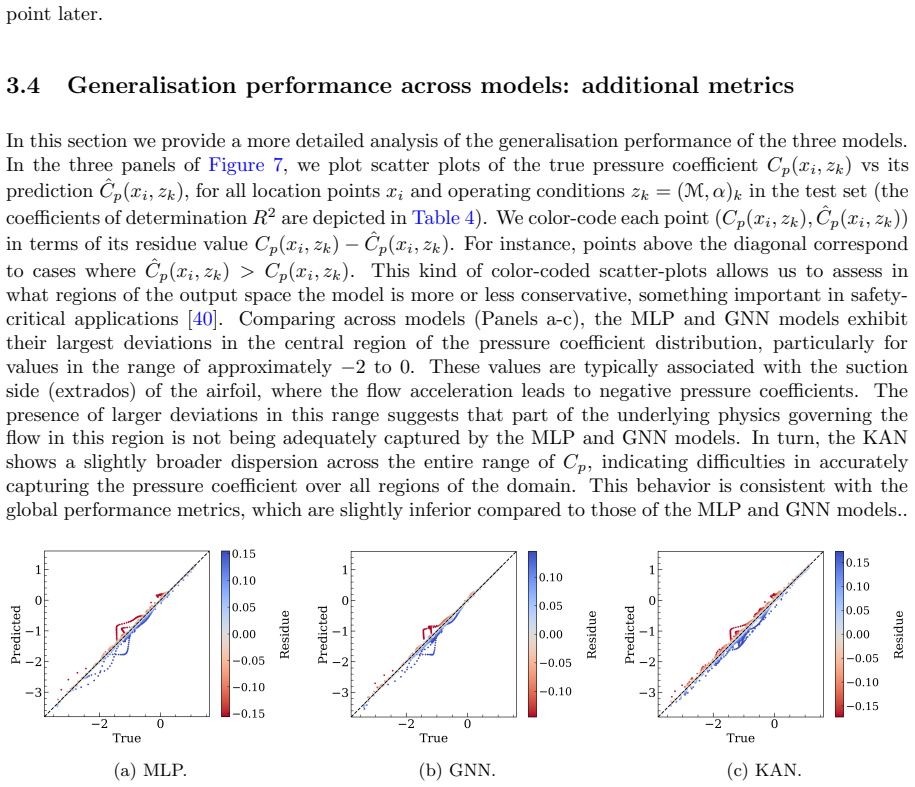
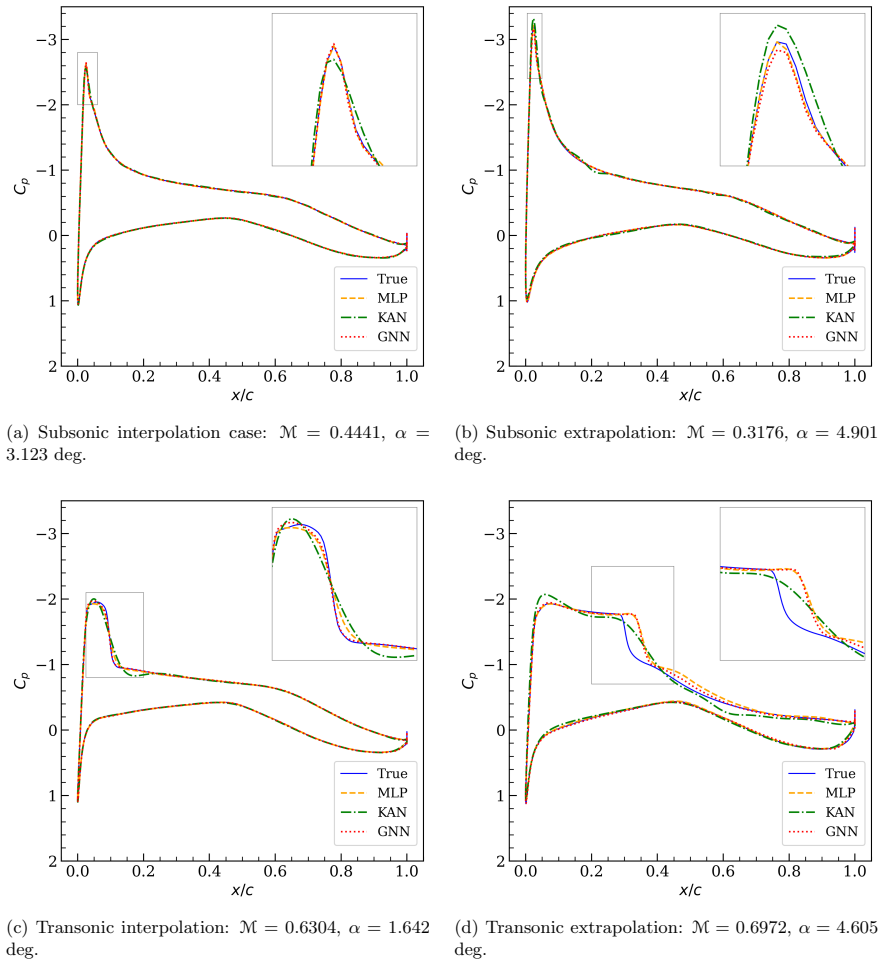
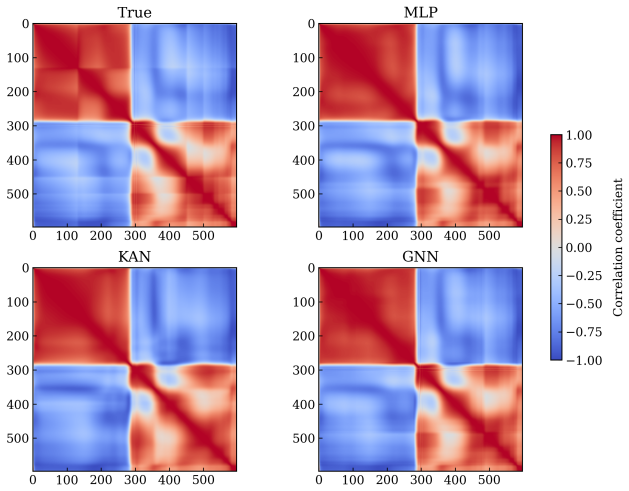
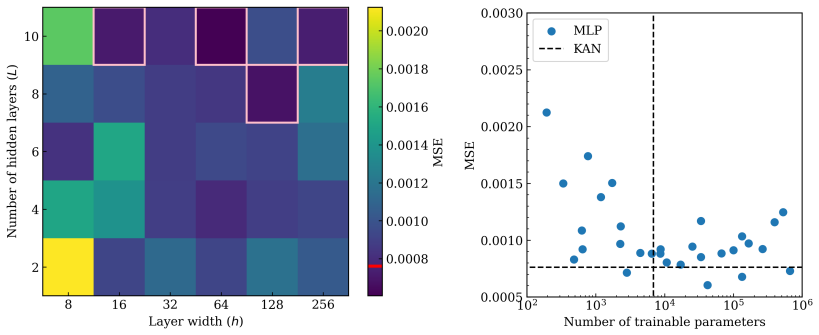
read the original abstract
Kolmogorov Arnold networks (KAN) have recently been introduced as a (deep) neural network architecture whose trainable parameters adapt the activation functions, instead of the coefficients of the affine transformations at the core of traditional architectures such as deep multilayer perceptrons (MLPs). This architecture builds on the Kolmogorov-Arnold theorem, which endows it with universal approximation properties. While the advent of KANs has been received with excitement, there is a current debate about the possible KAN supremacy over deep multilayer perceptrons (MLPs) for classic fields such as symbolic regression, generic-purpose machine learning, natural language processing or computer vision. Here we assess the performance of KANs --and its nuanced comparison against MLPs and graph neural networks (GNNs)-- in the realm of fluid dynamics surrogate modelling. To that aim, we consider the task of predicting the surface pressure distribution over subsonic and transonic airfoils, a canonical task in aerodynamics. Our results show that KAN models show good performance in predicting the whole pressure coefficients and is able to interpolate across Mach numbers and angles of attack, however its performance is comparable --marginally inferior-- to a suitably trained MLP, where best performance is achieved by a GNN at the expense or requiring lengthier training. While the optimal KAN model have typically much lower complexity than MLP and GNN --hence resulting in faster training--, we find that KANs suffer from training instabilities, and their performance is highly dependent on a proper hyperparameter optimisation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates Kolmogorov-Arnold Networks (KANs) as surrogate models for predicting surface pressure coefficient distributions on subsonic and transonic airfoils. It reports that KANs achieve good predictive performance and can interpolate across Mach numbers and angles of attack, but are marginally inferior to suitably trained MLPs; GNNs yield the best accuracy at the cost of longer training, while optimal KANs exhibit lower complexity (hence faster training) but suffer from training instabilities and strong dependence on hyperparameter choices.
Significance. If the comparative ordering is shown to be robust under equivalent hyperparameter optimization effort, the work supplies a useful empirical benchmark for architecture selection in aerodynamic surrogate modeling. The study is a pure empirical comparison with no derivations or self-referential claims, and its emphasis on training speed versus accuracy trade-offs is directly relevant to engineering applications where model complexity matters.
major comments (1)
- [Abstract] Abstract: the headline comparative claims (KAN marginally inferior to MLP; GNN best) rest on performance numbers obtained after tuning, yet the text explicitly states that KAN performance is highly dependent on proper hyperparameter optimisation and that KANs suffer from training instabilities. No information is supplied on search spaces, number of trials, grid sizes, early-stopping criteria, or wall-clock resources allocated to each architecture family, leaving the fairness of the comparison unverified and the reported ordering potentially sensitive to unequal tuning budgets.
minor comments (1)
- [Abstract] Abstract: minor grammatical issues ('or requiring lengthier training' should read 'of requiring'; 'optimal KAN model have' should read 'models have').
Simulated Author's Rebuttal
We thank the referee for their constructive feedback highlighting the need for greater transparency in our hyperparameter tuning procedures. We address this point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline comparative claims (KAN marginally inferior to MLP; GNN best) rest on performance numbers obtained after tuning, yet the text explicitly states that KAN performance is highly dependent on proper hyperparameter optimisation and that KANs suffer from training instabilities. No information is supplied on search spaces, number of trials, grid sizes, early-stopping criteria, or wall-clock resources allocated to each architecture family, leaving the fairness of the comparison unverified and the reported ordering potentially sensitive to unequal tuning budgets.
Authors: We agree that the absence of explicit details on the hyperparameter optimization process limits the ability to verify the fairness of the reported performance ordering. The manuscript already notes the sensitivity of KANs, but does not provide the requested specifics. In the revised version we will add a new subsection (or appendix) that documents, for each architecture family: the hyperparameter search spaces explored, the number of trials performed, the search method employed, early-stopping criteria, and approximate wall-clock resources allocated to tuning. This addition will allow readers to assess whether the comparative results are robust under comparable tuning effort. We do not claim that the original tuning budgets were provably equal; the revision will make this limitation transparent. revision: yes
Circularity Check
Empirical benchmark with no derivation chain or self-referential steps
full rationale
The paper is a pure empirical comparison of KAN, MLP and GNN performance on airfoil pressure prediction. No equations, derivations, fitted parameters presented as predictions, or load-bearing self-citations appear in the abstract or described content. All claims rest on observed numerical results after training, with no reduction of outputs to inputs by construction. The Kolmogorov-Arnold theorem is cited externally as background, not as an internal self-definition. Hyperparameter sensitivity is noted as an experimental observation, not a circular premise.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Butterworth-Heinemann, 2015
Jiri Blazek.Computational fluid dynamics: principles and applications. Butterworth-Heinemann, 2015
2015
-
[2]
Cambridge University Press, 2022
Steven L Brunton and J Nathan Kutz.Data-driven science and engineering: Machine learning, dynamical systems, and control. Cambridge University Press, 2022
2022
-
[3]
Proper orthogonal decomposition, surrogate mod- elling and evolutionary optimization in aerodynamic design.Computers & Fluids84 (2013), pp
Emiliano Iuliano and Domenico Quagliarella. Proper orthogonal decomposition, surrogate mod- elling and evolutionary optimization in aerodynamic design.Computers & Fluids84 (2013), pp. 327– 350
2013
-
[4]
Interpolation-based reduced- order modelling for steady transonic flows via manifold learning.International Journal of Compu- tational Fluid Dynamics28.3-4 (2014), pp
Thomas Franz, Ralf Zimmermann, Stefan G¨ ortz, and Niklas Karcher. Interpolation-based reduced- order modelling for steady transonic flows via manifold learning.International Journal of Compu- tational Fluid Dynamics28.3-4 (2014), pp. 106–121
2014
-
[5]
Evaluation of aerodynamic loads via reduced-order methodology.AIAA Journal 53.8 (2015), pp
Marco Fossati. Evaluation of aerodynamic loads via reduced-order methodology.AIAA Journal 53.8 (2015), pp. 2389–2405
2015
-
[6]
Cambridge, MA: MIT Press, 2016.url:https://www.deeplearningbook.org
Ian Goodfellow, Yoshua Bengio, and Aaron Courville.Deep Learning. Cambridge, MA: MIT Press, 2016.url:https://www.deeplearningbook.org
2016
-
[7]
Machine learning for fluid mechan- ics.Annual review of fluid mechanics52.1 (2020), pp
Steven L Brunton, Bernd R Noack, and Petros Koumoutsakos. Machine learning for fluid mechan- ics.Annual review of fluid mechanics52.1 (2020), pp. 477–508
2020
-
[8]
Improving aircraft performance using machine learning: A review.Aerospace Science and Technology138 (2023), p
Soledad Le Clainche, Esteban Ferrer, Sam Gibson, Elisabeth Cross, Alessandro Parente, and Ri- cardo Vinuesa. Improving aircraft performance using machine learning: A review.Aerospace Science and Technology138 (2023), p. 108354
2023
-
[9]
Layered reduced-order models for nonlinear aerodynamics and aeroelasticity.Journal of Fluids and Structures68 (2017), pp
Jiaqing Kou and Weiwei Zhang. Layered reduced-order models for nonlinear aerodynamics and aeroelasticity.Journal of Fluids and Structures68 (2017), pp. 174–193
2017
-
[10]
Xiaowei Jin, Peng Cheng, Wen-Li Chen, and Hui Li. Prediction model of velocity field around circular cylinder over various Reynolds numbers by fusion convolutional neural networks based on pressure on the cylinder.Physics of Fluids30.4 (2018)
2018
-
[11]
Pre- diction of aerodynamic flow fields using convolutional neural networks.Computational Mechanics 64 (2019), pp
Saakaar Bhatnagar, Yaser Afshar, Shaowu Pan, Karthik Duraisamy, and Shailendra Kaushik. Pre- diction of aerodynamic flow fields using convolutional neural networks.Computational Mechanics 64 (2019), pp. 525–545
2019
-
[12]
A deep learning approach for efficiently and accurately evaluating the flow field of supercritical airfoils.Computers & Fluids 198 (2020), p
Haizhou Wu, Xuejun Liu, Wei An, Songcan Chen, and Hongqiang Lyu. A deep learning approach for efficiently and accurately evaluating the flow field of supercritical airfoils.Computers & Fluids 198 (2020), p. 104393
2020
-
[13]
Deep learning methods for Reynolds-averaged Navier–Stokes simulations of airfoil flows.AIAA Journal58.1 (2020), pp
Nils Thuerey, Konstantin Weißenow, Lukas Prantl, and Xiangyu Hu. Deep learning methods for Reynolds-averaged Navier–Stokes simulations of airfoil flows.AIAA Journal58.1 (2020), pp. 25– 36
2020
-
[14]
Data-driven prediction of unsteady pressure distribu- tions based on deep learning.Journal of Fluids and Structures104 (2021), p
Vladyslav Rozov and Christian Breitsamter. Data-driven prediction of unsteady pressure distribu- tions based on deep learning.Journal of Fluids and Structures104 (2021), p. 103316
2021
-
[15]
Reinforcement learning to maximize wind turbine energy generation.Expert Systems with Applications249 (2024), p
Daniel Soler, Oscar Mari˜ no, David Huergo, Mart´ ın de Frutos, and Esteban Ferrer. Reinforcement learning to maximize wind turbine energy generation.Expert Systems with Applications249 (2024), p. 123502. 15
2024
-
[16]
Transfer learning-enhanced deep reinforcement learning for aerodynamic airfoil optimization subject to structural constraints
David Ramos, Lucas Lacasa, Eusebio Valero, and Gonzalo Rubio. Transfer learning-enhanced deep reinforcement learning for aerodynamic airfoil optimization subject to structural constraints. Physics of Fluids37.8 (2025)
2025
-
[17]
Aeroacoustic airfoil shape optimization enhanced by autoencoders.Expert Sys- tems with Applications217 (2023), p
Jiaqing Kou et al. Aeroacoustic airfoil shape optimization enhanced by autoencoders.Expert Sys- tems with Applications217 (2023), p. 119513
2023
-
[18]
A certifiable machine learning-based pipeline to predict fatigue life of aircraft structures.Engineering Failure Analysis(2025), p
´Angel Ladr´ on et al. A certifiable machine learning-based pipeline to predict fatigue life of aircraft structures.Engineering Failure Analysis(2025), p. 110334
2025
-
[19]
On the application of surrogate regression mod- els for aerodynamic coefficient prediction.Complex & Intelligent Systems7.4 (2021), pp
Esther Andr´ es-P´ erez and Carlos Paulete-Peri´ a˜ nez. On the application of surrogate regression mod- els for aerodynamic coefficient prediction.Complex & Intelligent Systems7.4 (2021), pp. 1991– 2021
2021
-
[20]
Fast predictions of aircraft aerody- namics using deep-learning techniques.AIAA Journal60.9 (2022), pp
Christian Sabater, Philipp St¨ urmer, and Philipp Bekemeyer. Fast predictions of aircraft aerody- namics using deep-learning techniques.AIAA Journal60.9 (2022), pp. 5249–5261
2022
-
[21]
Graph neural networks for the prediction of aircraft surface pressure distributions.Aerospace Science and Technology137 (2023), p
Derrick Hines and Philipp Bekemeyer. Graph neural networks for the prediction of aircraft surface pressure distributions.Aerospace Science and Technology137 (2023), p. 108268
2023
-
[22]
David Ramos, Lucas Lacasa, Ferm´ ın Guti´ errez, Eusebio Valero, and Gonzalo Rubio. FluidFlow: a flow-matching generative model for fluid dynamics surrogates on unstructured meshes.arXiv preprint arXiv:2604.08586(2026)
Pith/arXiv arXiv 2026
-
[23]
Approximation capabilities of multilayer feedforward networks.Neural networks4.2 (1991), pp
Kurt Hornik. Approximation capabilities of multilayer feedforward networks.Neural networks4.2 (1991), pp. 251–257
1991
-
[24]
Kan: Kolmogorov-Arnold Networks.arXiv preprint arXiv:2404.19756(2024)
Ziming Liu et al. Kan: Kolmogorov-Arnold Networks.arXiv preprint arXiv:2404.19756(2024)
Pith/arXiv arXiv 2024
-
[25]
American Mathematical Society, 1961
Andre Nikolaevich Kolmogorov.On the representation of continuous functions of several variables by superpositions of continuous functions of a smaller number of variables. American Mathematical Society, 1961
1961
-
[26]
Addressing common misinterpretations of KART and UAT in neural network literature.Neural Networks(2025), p
Vugar E Ismailov. Addressing common misinterpretations of KART and UAT in neural network literature.Neural Networks(2025), p. 108361
2025
-
[27]
A survey on kolmogorov-arnold network.ACM Computing Surveys58.2 (2025), pp
Shriyank Somvanshi, Syed Aaqib Javed, Md Monzurul Islam, Diwas Pandit, and Subasish Das. A survey on kolmogorov-arnold network.ACM Computing Surveys58.2 (2025), pp. 1–35
2025
-
[28]
Khemraj Shukla, Juan Diego Toscano, Zhicheng Wang, Zongren Zou, and George Em Karniadakis. A comprehensive and FAIR comparison between MLP and KAN representations for differential equations and operator networks.Computer Methods in Applied Mechanics and Engineering431 (2024), p. 117290
2024
-
[29]
KAN or MLP: A fairer comparison.arXiv preprint arXiv:2407.16674(2024)
Runpeng Yu, Weihao Yu, and Xinchao Wang. KAN or MLP: A fairer comparison.arXiv preprint arXiv:2407.16674(2024)
arXiv 2024
-
[30]
Ali Kashefi. Kolmogorov-Arnold PointNet: Deep learning for prediction of fluid fields on irregular geometries.arXiv preprint arXiv:2408.02950(2024)
arXiv 2024
-
[31]
Kolmogorov-Arnold Networks for Online Reinforcement Learning
Victor A Kich, Jair A Bottega, Raul Steinmetz, Ricardo B Grando, Ayano Yorozu, and Akihisa Ohya. “Kolmogorov-Arnold Networks for Online Reinforcement Learning”.2024 24th International Conference on Control, Automation and Systems (ICCAS). IEEE. 2024, pp. 958–963
2024
-
[32]
David Picard. Torch. manual seed (3407) is all you need: On the influence of random seeds in deep learning architectures for computer vision.arXiv preprint arXiv:2109.08203(2021)
arXiv 2021
-
[33]
The DLR TAU-code: recent applications in research and industry
Dieter Schwamborn, Thomas Gerhold, and Ralf Heinrich. “The DLR TAU-code: recent applications in research and industry”.ECCOMAS CFD 2006: Proceedings of the European Conference on Computational Fluid Dynamics, Egmond aan Zee, The Netherlands, September 5-8, 2006. Delft University of Technology; European Community on Computational Methods . . . 2006
2006
-
[34]
The graph neural network model.IEEE transactions on neural networks20.1 (2008), pp
Franco Scarselli, Marco Gori, Ah Chung Tsoi, Markus Hagenbuchner, and Gabriele Monfardini. The graph neural network model.IEEE transactions on neural networks20.1 (2008), pp. 61–80
2008
-
[35]
Graph neural networks.Nature Reviews Methods Primers4.1 (2024), p
Gabriele Corso, Hannes Stark, Stefanie Jegelka, Tommi Jaakkola, and Regina Barzilay. Graph neural networks.Nature Reviews Methods Primers4.1 (2024), p. 17
2024
-
[36]
Ziming Liu.pykan. Apr. 2024.url:https://github.com/KindXiaoming/pykan/tree/master
2024
-
[37]
Max Kuhn, Kjell Johnson, et al.Applied predictive modeling. Vol. 26. Springer, 2013
2013
-
[38]
JHU press, 2013
Gene H Golub and Charles F Van Loan.Matrix computations. JHU press, 2013. 16
2013
-
[39]
Optuna: A Next-generation Hyperparameter Optimization Framework
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. “Optuna: A Next-generation Hyperparameter Optimization Framework”.Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2019
2019
-
[40]
Towards certification: A complete statistical validation pipeline for supervised learning in industry.Expert Systems with Applications277 (2025), p
Lucas Lacasa et al. Towards certification: A complete statistical validation pipeline for supervised learning in industry.Expert Systems with Applications277 (2025), p. 127169
2025
-
[41]
2022.url:https://github.com/ArnauMiro/UPM_BSC_LowOrder
Benet Eiximeno, Beka Begiashvili, Arnau Miro, Eusebio Valero, and Oriol Lehmkuhl.pyLOM: Low order modelling in Python. 2022.url:https://github.com/ArnauMiro/UPM_BSC_LowOrder. 17
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.