PhysReflect-VLA: Physical Feasibility and Self-Reflective Regulation for Reliable Vision-Language-Action Policies
Pith reviewed 2026-06-26 04:59 UTC · model grok-4.3
The pith
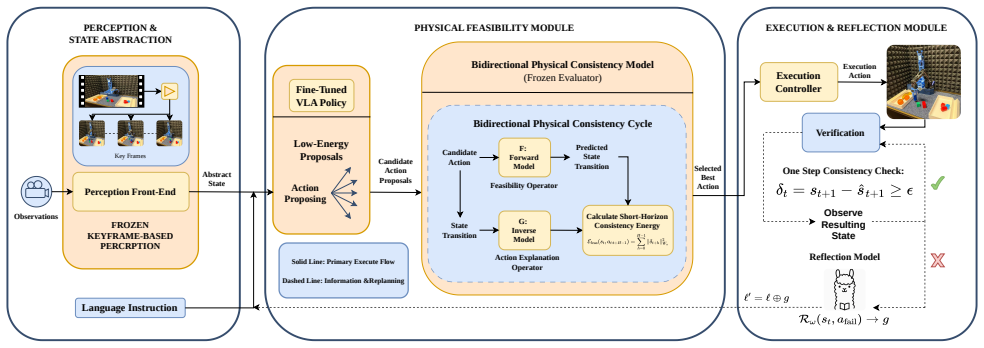
PhysReflect-VLA adds a Feasibility Operator and LLM reflection module to existing VLA policies for real-time physical consistency checks during robotic manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PhysReflect-VLA augments any VLA policy with a closed-loop reliability layer: the Feasibility Operator rejects actions that would produce physically inconsistent transitions, the Action Explanation Operator verifies coherence of accepted moves, and the LLM Reflection Module converts observed state errors into targeted corrective instructions for the next step; this combination, trained in two stages, raises execution robustness without retraining the base policy.
What carries the argument
The Feasibility Operator, which evaluates whether candidate actions induce dynamically consistent state transitions in real time.
If this is right
- Stage-wise stability increases because infeasible moves are filtered before execution.
- Overall task success rises by an average of 5.4 percent on contact-rich multi-stage manipulation.
- Both the feasibility check and the reflection-based correction are required for the observed robustness gains.
- The framework functions as a plug-and-play addition that does not require changes to the underlying VLA model weights.
Where Pith is reading between the lines
- The same operators could be attached to non-VLA policies such as diffusion-based or reinforcement-learned controllers.
- If the reflection module generalizes across tasks, it may reduce the frequency of full policy retraining when new physical constraints appear.
- Hardware-specific tuning of the Feasibility Operator may still be needed when transferring to robots with different dynamics or sensor latency.
Load-bearing premise
The Feasibility Operator can detect physically infeasible transitions reliably and fast enough on the target robot hardware without blocking valid actions or adding excessive delay.
What would settle it
A controlled test in which the robot is presented with a known physically impossible transition (such as attempting to lift an object already held by another gripper) and the system either accepts the action or fails to correct it within one control cycle.
Figures

read the original abstract
Long-horizon robotic manipulation is highly sensitive to physically infeasible transitions, contact-induced disturbances, and the lack of effective self-correction during execution. Although Vision-Language-Action (VLA) models provide strong task grounding through multimodal learning, they typically generate actions in a feed-forward manner without explicitly checking physical feasibility or diagnosing execution errors online. We present PhysReflect-VLA, a plug-and-play execution-time reliability framework that augments VLA policies with physical feasibility evaluation and structured self-reflection in a closed-loop control pipeline. A Feasibility Operator evaluates whether candidate actions induce dynamically consistent state transitions; an Action Explanation Operator verifies transition coherence; and an LLM-based Reflection Module analyzes state discrepancies to generate corrective guidance for subsequent actions. A two-stage training procedure stabilizes feasibility modeling and integrates reflection into the control loop. Experiments on multi-stage, contact-rich real-world manipulation tasks show consistent improvements in stage-wise stability and overall task success compared with representative VLA baselines with an average gain of 5.4\%. Ablation results further indicate that feasibility checking and reflection-based correction both contribute to improved execution robustness. These results highlight the importance of embedding physical consistency checks and online self-reflection for reliable long-horizon robotic manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PhysReflect-VLA, a plug-and-play execution-time framework that augments existing Vision-Language-Action (VLA) policies with a Feasibility Operator to check dynamic consistency of candidate actions, an Action Explanation Operator for transition coherence, and an LLM-based Reflection Module that analyzes state discrepancies to produce corrective guidance. A two-stage training procedure is described to stabilize feasibility modeling and integrate reflection. Experiments on multi-stage contact-rich real-world manipulation tasks are reported to yield consistent gains in stage-wise stability and an average 5.4% improvement in overall task success relative to representative VLA baselines, with ablations indicating contributions from both feasibility checking and reflection.
Significance. If the empirical results can be substantiated, the work offers a practical route to improving reliability of long-horizon VLA policies in contact-rich settings without retraining the base model. The closed-loop self-reflection mechanism addresses a recognized limitation of feed-forward VLA approaches, and the plug-and-play design could facilitate adoption across multiple VLA architectures.
major comments (1)
- [Experiments] Experiments section: The central claim of a 5.4% average task-success gain and improved stage-wise stability rests on the Feasibility Operator reliably detecting physically infeasible transitions in closed-loop execution. The manuscript supplies no precision/recall figures for the operator, no measured end-to-end latency on the target robot hardware, and no breakdown of blocked valid actions versus caught infeasible ones across the reported trials. Without these data it is impossible to isolate the operator's contribution or confirm it satisfies the implied real-time requirement.
minor comments (1)
- [Abstract] Abstract: The reported 5.4% average gain is stated without the number of tasks, trials per task, or any measure of variance, which would help readers assess the robustness of the result.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of PhysReflect-VLA as a practical plug-and-play approach. We address the single major comment below and will revise the manuscript to incorporate the requested quantitative details on the Feasibility Operator.
read point-by-point responses
-
Referee: Experiments section: The central claim of a 5.4% average task-success gain and improved stage-wise stability rests on the Feasibility Operator reliably detecting physically infeasible transitions in closed-loop execution. The manuscript supplies no precision/recall figures for the operator, no measured end-to-end latency on the target robot hardware, and no breakdown of blocked valid actions versus caught infeasible ones across the reported trials. Without these data it is impossible to isolate the operator's contribution or confirm it satisfies the implied real-time requirement.
Authors: We agree that the current manuscript lacks these specific metrics, which limits the ability to fully isolate the Feasibility Operator's contribution. In the revised version we will add: (1) precision and recall for the operator, computed by comparing its decisions against ground-truth feasibility labels derived from simulation rollouts and post-hoc expert review of the real-robot trials; (2) end-to-end latency measurements (including both operator inference and LLM reflection) recorded on the same robot hardware used in the experiments; and (3) a per-trial breakdown of actions blocked by the operator, distinguishing cases where valid actions were incorrectly rejected versus infeasible actions that were correctly caught. These additions will be placed in an expanded Experiments section with a new table and accompanying text. We believe this directly addresses the concern while preserving the plug-and-play nature of the framework. revision: yes
Circularity Check
No circularity: framework is described empirically without self-referential derivations
full rationale
The paper introduces PhysReflect-VLA as a plug-and-play framework with a Feasibility Operator, Action Explanation Operator, and LLM-based Reflection Module, trained via a two-stage procedure. All claims rest on experimental comparisons (5.4% average task success gain) rather than any mathematical derivation chain, fitted parameters renamed as predictions, or self-citation load-bearing uniqueness theorems. No equations appear in the provided text, so no step reduces by construction to its inputs. The central results are external empirical measurements on real-world tasks and are therefore self-contained against benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The developments and challenges towards dexterous and embodied robotic manipulation: A survey,
G. Li, R. Wang, P. Xu, Q. Ye, and J. Chen, “The developments and challenges towards dexterous and embodied robotic manipulation: A survey,” 2025. [Online]. Available: https://arxiv.org/abs/2507.11840
-
[2]
Embodied intelligence: A synergy of morphology, action, perception and learning,
H. Liu, D. Guo, and A. Cangelosi, “Embodied intelligence: A synergy of morphology, action, perception and learning,”ACM Computing Surveys, vol. 57, pp. 1 – 36, 2025. [Online]. Available: https://api.semanticscholar.org/CorpusID:276333529
2025
-
[3]
Aligning cyber space with physical world: A comprehensive survey on embodied ai, 2025
Y . Liu, W. Chen, Y . Bai, X. Liang, G. Li, W. Gao, and L. Lin, “Aligning cyber space with physical world: A comprehensive survey on embodied ai,” 2025. [Online]. Available: https://arxiv.org/abs/2407.06886
-
[4]
Pure vision language action (vla) models: A comprehensive survey,
D. Zhang, J. Sun, C. Hu, X. Wu, Z. Yuan, R. Zhou, F. Shen, and Q. Zhou, “Pure vision language action (vla) models: A comprehensive survey,” 2025. [Online]. Available: https://arxiv.org/abs/2509.19012
-
[5]
A Survey on Vision-Language-Action Models for Embodied AI
Y . Ma, Z. Song, Y . Zhuang, J. Hao, and I. King, “A survey on vision-language-action models for embodied ai,” 2026. [Online]. Available: https://arxiv.org/abs/2405.14093
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Efficient vision-language- action models for embodied manipulation: A systematic survey,
W. Guan, Q. Hu, A. Li, and J. Cheng, “Efficient vision-language- action models for embodied manipulation: A systematic survey,”
-
[7]
Efficient Vision-Language-Action Models for Embodied Manipulation: A Systematic Survey
[Online]. Available: https://arxiv.org/abs/2510.17111
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Survey of general end-to-end autonomous driving: A unified per- spective,
Y . Yang, C. Han, R. Mao,et al., “Survey of general end-to-end autonomous driving: A unified per- spective,”TechRxiv, December 2025. [Online]. Available: https://doi.org/10.36227/techrxiv.176523315.56439138/v1
-
[9]
Vision-language-action (vla) models: Concepts, progress, applications and challenges,
R. Sapkota, Y . Cao, K. I. Roumeliotis, and M. Karkee, “Vision-language-action (vla) models: Concepts, progress, applications and challenges,” 2026. [Online]. Available: https://arxiv.org/abs/2505.04769
-
[10]
World-VLA-Loop: Closed-Loop Learning of Video World Model and VLA Policy
X. Liu, Z. Bai, H. Ci, K. Y . Ma, and M. Z. Shou, “World-vla-loop: Closed-loop learning of video world model and vla policy,” 2026. [Online]. Available: https://arxiv.org/abs/2602.06508
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
T. Kato, T. Kiyokawa, N. Saito, and K. Harada, “Replanning human-robot collaborative tasks with vision-language models via semantic and physical dual-correction,” 2026. [Online]. Available: https://arxiv.org/abs/2602.14551
-
[12]
Rethinking visual-language- action model scaling: Alignment, mixture, and regularization,
Y . Wang, S. Zheng, H. Luo, W. Zhang, H. Yuan, C. Xu, H. Xu, Y . Feng, M. Yu, Z. Kang, Z. Lu, and Q. Jin, “Rethinking visual-language- action model scaling: Alignment, mixture, and regularization,” 2026. [Online]. Available: https://arxiv.org/abs/2602.09722
-
[13]
Fpc-vla: A vision-language-action framework with a supervisor for failure prediction and correction,
Y . Yang, Z. Duan, T. Xie, F. Cao, P. Shen, P. Song, P. Jin, G. Sun, S. Xu, Y . You, and J. Liu, “Fpc-vla: A vision-language-action framework with a supervisor for failure prediction and correction,”
-
[14]
Available: https://arxiv.org/abs/2509.04018
[Online]. Available: https://arxiv.org/abs/2509.04018
-
[15]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, T. Jackson, S. Jesmonth, N. J. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, I. Leal, K.-H. Lee, S. Levine, Y . Lu, U. Malla, D. Manjunath, I. Mordatch, O. Nachum, C. Parada, J. Peralta, E. Perez, K. Pertsch, J...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Octo: An Open-Source Generalist Robot Policy
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, J. Luo, Y . L. Tan, L. Y . Chen, P. Sanketi, Q. Vuong, T. Xiao, D. Sadigh, C. Finn, and S. Levine, “Octo: An open-source generalist robot policy,” 2024. [Online]. Available: https://arxiv.org/abs/2405.12213
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
RoboMD: Uncovering Robot Vulnerabilities through Semantic Potential Fields
S. Sagar, J. Duan, S. Vasudevan, Y . Zhou, H. B. Amor, D. Fox, and R. Senanayake, “From mystery to mastery: Failure diagnosis for improving manipulation policies,” 2025. [Online]. Available: https://arxiv.org/abs/2412.02818
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Vision-language-policy model for dynamic robot task planning,
J. Wang, K. T. Ly, J. Cloete, N. Tsagarakis, and I. Havoutis, “Vision-language-policy model for dynamic robot task planning,”
-
[19]
Available: https://arxiv.org/abs/2512.19178
[Online]. Available: https://arxiv.org/abs/2512.19178
-
[20]
W. Guo, G. Lu, H. Deng, Z. Wu, Y . Tang, and Z. Wang, “Vla- reasoner: Empowering vision-language-action models with reasoning via online monte carlo tree search,” 2026. [Online]. Available: https://arxiv.org/abs/2509.22643
-
[21]
Reflective planning: Vision-language models for multi-stage long-horizon robotic manipulation,
Y . Feng, J. Han, Z. Yang, X. Yue, S. Levine, and J. Luo, “Reflective planning: Vision-language models for multi-stage long-horizon robotic manipulation,” 2025. [Online]. Available: https://arxiv.org/abs/2502.16707
-
[22]
arXiv preprint arXiv:2509.14889 (2025)
N. Sun, Y . Li, C. Wang, H. Li, and H. Liu, “Collabvla: Self-reflective vision-language-action model dreaming together with human,” 2025. [Online]. Available: https://arxiv.org/abs/2509.14889
-
[23]
Inner Monologue: Embodied Reasoning through Planning with Language Models
W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florence, A. Zeng, J. Tompson, I. Mordatch, Y . Chebotar, P. Sermanet, N. Brown, T. Jackson, L. Luu, S. Levine, K. Hausman, and B. Ichter, “Inner monologue: Embodied reasoning through planning with language models,” 2022. [Online]. Available: https://arxiv.org/abs/2207.05608
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
OpenVLA: An Open-Source Vision-Language-Action Model
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn, “Openvla: An open-source vision-language-action model,” 2024. [Online]. Available: https://arxiv.org/abs/2406.09246
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
M. J. Kim, C. Finn, and P. Liang, “Fine-tuning vision-language-action models: Optimizing speed and success,” 2025. [Online]. Available: https://arxiv.org/abs/2502.19645
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
π0: A vision-language-action flow model for general robot control,
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky, “π0: A vision-language-action flow model for general robot control,”
-
[27]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
[Online]. Available: https://arxiv.org/abs/2410.24164
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,” 2024. [Online]. Available: https://arxiv.org/abs/2303.04137
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,” 2023. [Online]. Available: https://arxiv.org/abs/2304.13705
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Towards a dynamic shapley value-based evaluations for autonomous robotic learning from videos,
X. Chang, F. Chao, N. Copner, C. Shang, and Q. Shen, “Towards a dynamic shapley value-based evaluations for autonomous robotic learning from videos,” inUKCI. Springer, 2025, pp. 382–394
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.