Automating Potential-based Reward Shaping with Vision Language Model Guidance
Pith reviewed 2026-06-26 04:58 UTC · model grok-4.3
The pith
VLM preferences over image pairs can train a potential function that shapes rewards, speeds learning, and leaves optimal policies unchanged.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
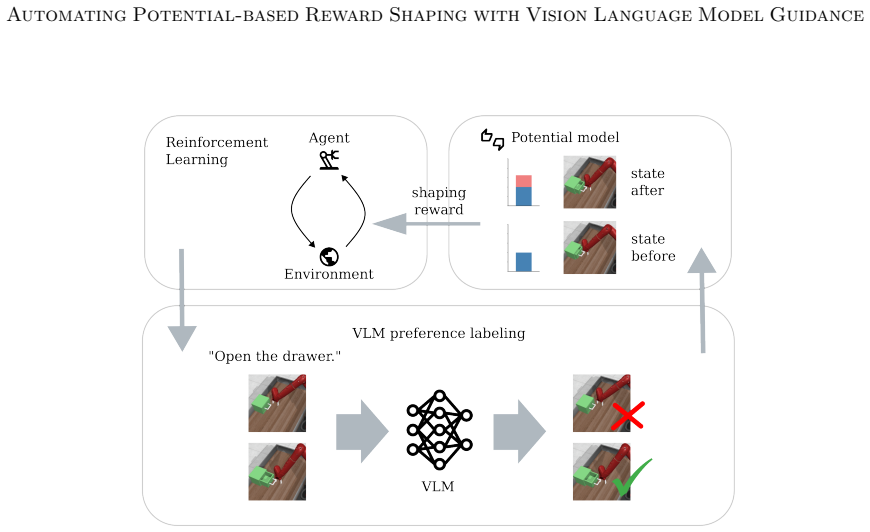
VLM-PBRS queries a lightweight vision language model for preferences over image pairs, trains a model of the potential function on those preferences, and adds the resulting shaping term to the sparse task reward; because the shaping term is potential-based, the original optimal policies remain optimal and the need for expert-designed shaping functions disappears.
What carries the argument
The potential function trained directly on VLM preference labels over pairs of state images, which generates the additive shaping reward in the PBRS framework.
If this is right
- Optimal policies under the original sparse reward remain optimal after shaping.
- Sample efficiency improves in the tested robotic manipulation environments.
- No hand-designed potential function is required.
- The method reduces vulnerability to reward hacking compared with arbitrary shaping.
Where Pith is reading between the lines
- The same preference-to-potential pipeline could be applied to other visual state spaces where sparse rewards currently limit progress.
- If VLM preference accuracy continues to rise, the sample-efficiency gains may increase without changing the framework.
- Automating the potential function could make PBRS practical in domains where domain experts are unavailable to design shaping terms.
Load-bearing premise
That the noisier preference labels produced by smaller VLMs remain informative enough to train a potential function that produces clear sample-efficiency gains.
What would settle it
An experiment in Meta-World or Franka Kitchen in which adding the learned potential produces no measurable reduction in steps to reach target performance or yields a policy that differs from the one optimal under the original sparse reward.
Figures

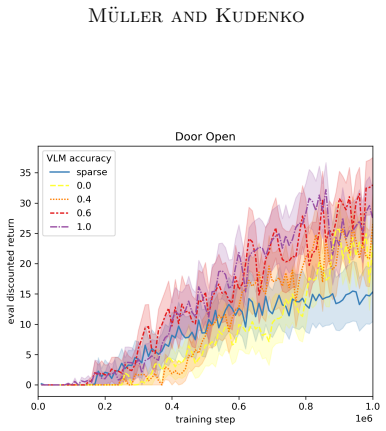
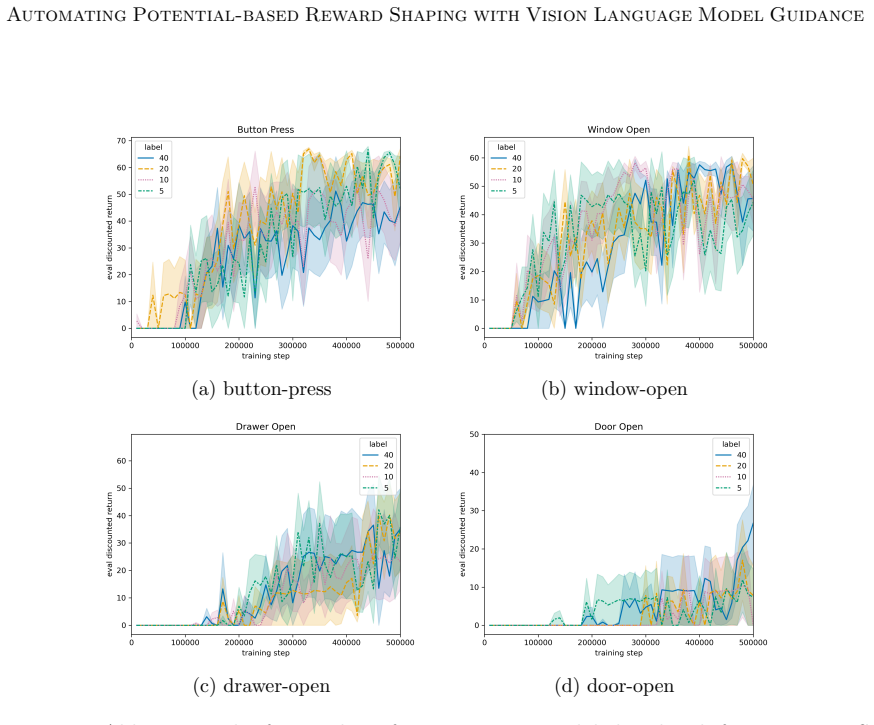
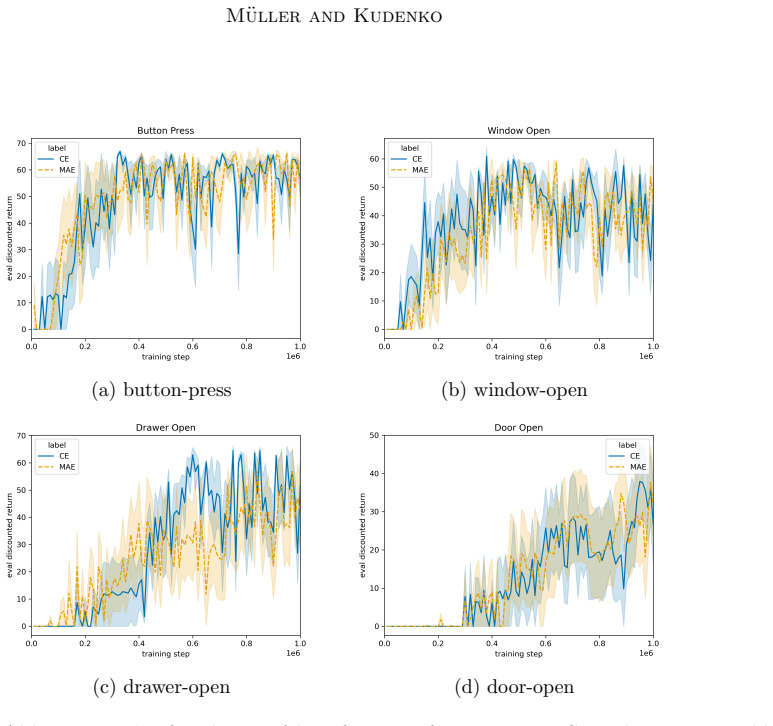


read the original abstract
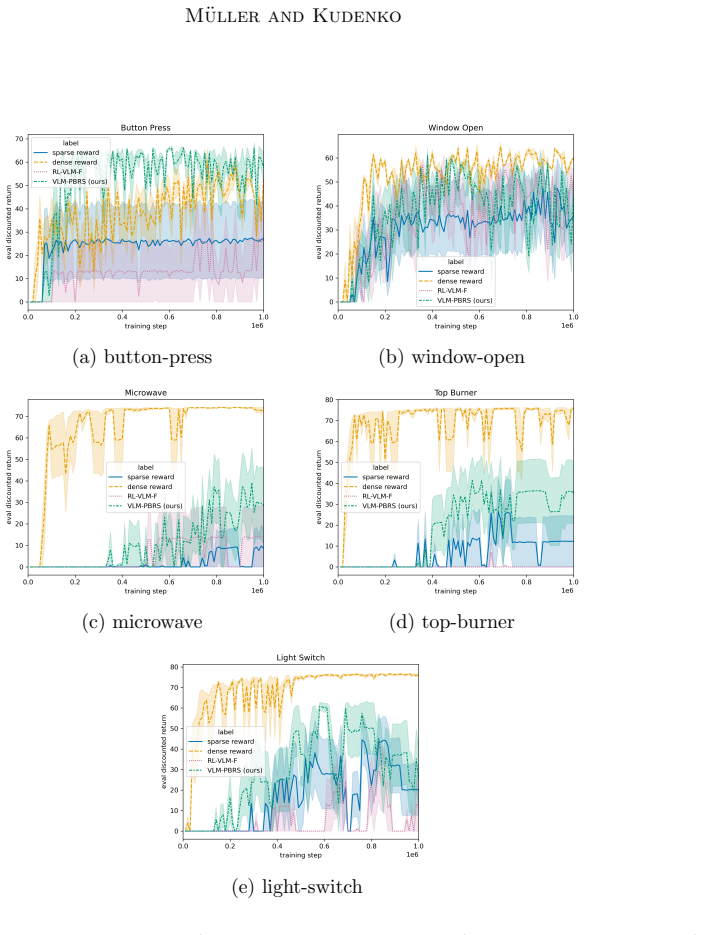
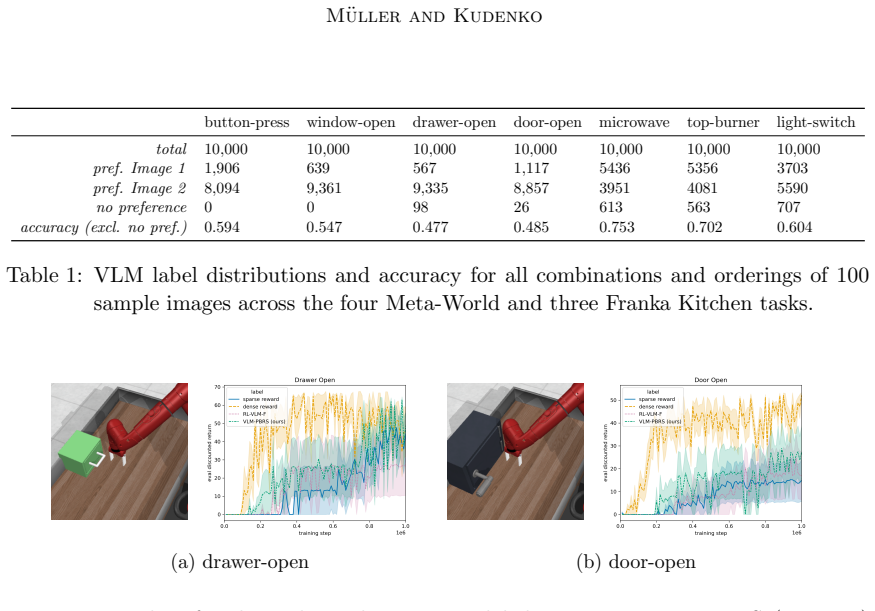
Sparse rewards are inherently challenging for reinforcement learning agents as they lack intermediate feedback to guide exploration and to correctly attribute the sparse success rewards to relevant parts of the trajectory. Naive reward shaping can induce reward hacking, yielding policies that exploit auxiliary signals instead of solving the intended task. Potential-based reward shaping (PBRS) guarantees preservation of the optimal policy set, but requires the definition of a heuristic potential function over the state space. In this work, we introduce the VLM-guided PBRS framework VLM-PBRS that learns the potential function directly from vision language model (VLM) feedback. We query a lightweight VLM to obtain preferences over image pairs and train a model of the potential function using these preferences. As this approach is based on potential-based reward shaping, it preserves the original optimal policies, and removes the need for expert-designed reward shaping terms. Because large VLMs are prohibitively expensive to invoke repeatedly during policy learning, we employ smaller, more computationally efficient VLMs. Although the resulting preference labels are less accurate, empirical evidence shows that the preference labels can still be used to accelerate learning. We validate our method empirically in the Meta-World and Franka Kitchen environments and highlight the connection between VLM preference label accuracy and sample efficiency improvements. Our contributions are threefold: (1) the first application of VLM preference-based learning to synthesize a potential function for PBRS, (2) a principled, low-cost solution that leverages small VLMs, and (3) extensive empirical demonstration of improved sample efficiency and robustness to reward hacking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VLM-PBRS, a framework that queries a lightweight VLM for pairwise preferences over image pairs, trains a potential function Φ from these preferences via a ranking loss, and applies the resulting shaped reward in PBRS to accelerate learning in sparse-reward settings. It claims that the method preserves the original optimal policy set (by PBRS theory), eliminates the need for hand-designed shaping terms, and still yields sample-efficiency gains in Meta-World and Franka Kitchen even when smaller, less accurate VLMs are used; the authors also report a correlation between VLM label accuracy and observed gains.
Significance. If the empirical results hold, the work provides a concrete, low-cost route to automate potential-function design for PBRS using off-the-shelf VLMs, removing a long-standing barrier to applying PBRS in new domains. The explicit linkage between VLM accuracy and sample-efficiency gains is a useful diagnostic contribution.
major comments (2)
- [Abstract, §4] Abstract and §4 (empirical validation): the central claim that 'preference labels can still be used to accelerate learning' with smaller VLMs is load-bearing yet rests on an unverified assumption that noisy pairwise preferences remain sufficiently informative after training. The manuscript must report (i) the exact VLM preference accuracy on the target image pairs, (ii) the quantitative sample-efficiency improvement (e.g., steps to 90 % success) versus both unshaped and expert-shaped baselines, and (iii) an ablation showing that performance degrades gracefully rather than introducing new failure modes when accuracy falls below a stated threshold.
- [§3] §3 (method): the training procedure for Φ is described only at a high level ('ranking loss on image pairs'). The paper must specify the exact loss, the architecture of the potential network, how image pairs are sampled during training, and whether any regularization is applied to keep Φ bounded—details required to reproduce the claim that the learned Φ yields a valid PBRS signal.
minor comments (2)
- [Abstract] The abstract states three contributions but does not explicitly list them; numbering them in the text would improve clarity.
- [Figures] Figure captions should state the number of random seeds and whether shaded regions represent standard error or min/max.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (empirical validation): the central claim that 'preference labels can still be used to accelerate learning' with smaller VLMs is load-bearing yet rests on an unverified assumption that noisy pairwise preferences remain sufficiently informative after training. The manuscript must report (i) the exact VLM preference accuracy on the target image pairs, (ii) the quantitative sample-efficiency improvement (e.g., steps to 90 % success) versus both unshaped and expert-shaped baselines, and (iii) an ablation showing that performance degrades gracefully rather than introducing new failure modes when accuracy falls below a stated threshold.
Authors: We agree that more granular reporting is needed to fully substantiate the claim. While the manuscript already notes the link between VLM accuracy and sample-efficiency gains, it does not provide the exact accuracy percentages on the target pairs or the requested quantitative metrics. In the revision we will add (i) measured VLM preference accuracy on the image pairs, (ii) steps-to-90%-success for VLM-PBRS versus both the unshaped baseline and an expert-shaped baseline in Meta-World and Franka Kitchen, and (iii) an ablation that varies VLM accuracy (via different models or controlled label noise) to demonstrate that performance degrades gracefully without introducing new failure modes. revision: yes
-
Referee: [§3] §3 (method): the training procedure for Φ is described only at a high level ('ranking loss on image pairs'). The paper must specify the exact loss, the architecture of the potential network, how image pairs are sampled during training, and whether any regularization is applied to keep Φ bounded—details required to reproduce the claim that the learned Φ yields a valid PBRS signal.
Authors: We acknowledge that the current description of the potential-function training is high-level and insufficient for full reproducibility. In the revised manuscript we will expand §3 to state the precise ranking loss (including its mathematical form), the neural-network architecture used for Φ, the exact procedure for sampling image pairs from the environments, and any regularization or bounding constraints applied to Φ to ensure it produces a valid PBRS signal. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper applies standard PBRS theory (which guarantees policy preservation for any fixed potential) to a learned Φ trained via ranking loss on VLM pairwise preferences. No equations or steps reduce the output to the input by construction, no self-citations are load-bearing for the core claim, and no fitted parameters are renamed as predictions. Empirical validation in Meta-World and Franka Kitchen stands on external benchmarks rather than definitional equivalence. This is the expected honest non-finding for an empirical RL method.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Wang, Yufei and Sun, Zhanyi and Zhang, Jesse and Xian, Zhou and Biyik, Erdem and Held, David and Erickson, Zackory , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[2]
Deep Reinforcement Learning from Human Preferences , url =
Christiano, Paul F and Leike, Jan and Brown, Tom and Martic, Miljan and Legg, Shane and Amodei, Dario , booktitle =. Deep Reinforcement Learning from Human Preferences , url =
-
[3]
A Survey of Preference-Based Reinforcement Learning Methods , journal =
Christian Wirth and Riad Akrour and Gerhard Neumann and Johannes F. A Survey of Preference-Based Reinforcement Learning Methods , journal =. 2017 , volume =
2017
-
[4]
Proceedings of the 38th International Conference on Machine Learning , pages =
PEBBLE: Feedback-Efficient Interactive Reinforcement Learning via Relabeling Experience and Unsupervised Pre-training , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
2021
-
[5]
2024 , journal=
Ovis: Structural Embedding Alignment for Multimodal Large Language Model , author=. 2024 , journal=
2024
-
[6]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 Technical Report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[7]
Proceedings of the Conference on Robot Learning , pages =
Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning , author =. Proceedings of the Conference on Robot Learning , pages =. 2020 , editor =
2020
-
[8]
arXiv preprint arXiv:1910.11956 , year=
Relay policy learning: Solving long-horizon tasks via imitation and reinforcement learning , author=. arXiv preprint arXiv:1910.11956 , year=
arXiv 1910
-
[9]
2020 , eprint=
D4RL: Datasets for Deep Data-Driven Reinforcement Learning , author=. 2020 , eprint=
2020
-
[10]
Proceedings of the 35th International Conference on Machine Learning , pages =
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , editor =
2018
-
[11]
International Conference on Learning Representations , year=
Adam: A method for stochastic optimization , author=. International Conference on Learning Representations , year=
-
[12]
Navigating Noisy Feedback: Enhancing Reinforcement Learning with Error-Prone Language Models
Lin, Muhan and Shi, Shuyang and Guo, Yue and Chalaki, Behdad and Tadiparthi, Vaishnav and Moradi Pari, Ehsan and Stepputtis, Simon and Campbell, Joseph and Sycara, Katia P. Navigating Noisy Feedback: Enhancing Reinforcement Learning with Error-Prone Language Models. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/...
-
[13]
Second Agent Learning in Open-Endedness Workshop , year=
Vision-Language Models as a Source of Rewards , author=. Second Agent Learning in Open-Endedness Workshop , year=
-
[14]
The Thirteenth International Conference on Learning Representations , year=
On the Modeling Capabilities of Large Language Models for Sequential Decision Making , author=. The Thirteenth International Conference on Learning Representations , year=
-
[15]
Forty-second International Conference on Machine Learning , year=
Enhancing Rating-Based Reinforcement Learning to Effectively Leverage Feedback from Large Vision-Language Models , author=. Forty-second International Conference on Machine Learning , year=
-
[16]
Ghosh, Aritra and Kumar, Himanshu and Sastry, P. S. , title =. Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence , pages =. 2017 , publisher =
2017
-
[17]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Zhao, Yinuo and Yuan, Jiale and Xu, Zhiyuan and Hao, Xiaoshuai and Zhang, Xinyi and Wu, Kun and Che, Zhengping and Liu, Chi Harold and Tang, Jian , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
2025
-
[18]
The method of paired comparisons , author=
Rank analysis of incomplete block designs: I. The method of paired comparisons , author=. Biometrika , volume=
-
[19]
Learning to Drive a Bicycle Using Reinforcement Learning and Shaping , year =
Randl. Learning to Drive a Bicycle Using Reinforcement Learning and Shaping , year =. Proceedings of the Fifteenth International Conference on Machine Learning , pages =
-
[20]
Learning to Utilize Shaping Rewards: A New Approach of Reward Shaping , url =
Hu, Yujing and Wang, Weixun and Jia, Hangtian and Wang, Yixiang and Chen, Yingfeng and Hao, Jianye and Wu, Feng and Fan, Changjie , booktitle =. Learning to Utilize Shaping Rewards: A New Approach of Reward Shaping , url =
-
[21]
Self-Supervised Online Reward Shaping in Sparse-Reward Environments , year=
Memarian, Farzan and Goo, Wonjoon and Lioutikov, Rudolf and Niekum, Scott and Topcu, Ufuk , booktitle=. Self-Supervised Online Reward Shaping in Sparse-Reward Environments , year=
-
[22]
Exploration-Guided Reward Shaping for Reinforcement Learning under Sparse Rewards , url =
Devidze, Rati and Kamalaruban, Parameswaran and Singla, Adish , booktitle =. Exploration-Guided Reward Shaping for Reinforcement Learning under Sparse Rewards , url =
-
[23]
Keeping Your Distance: Solving Sparse Reward Tasks Using Self-Balancing Shaped Rewards , url =
Trott, Alexander and Zheng, Stephan and Xiong, Caiming and Socher, Richard , booktitle =. Keeping Your Distance: Solving Sparse Reward Tasks Using Self-Balancing Shaped Rewards , url =
-
[24]
The Twelfth International Conference on Learning Representations , year=
Motif: Intrinsic Motivation from Artificial Intelligence Feedback , author=. The Twelfth International Conference on Learning Representations , year=
-
[25]
arXiv preprint arXiv:2311.02379 , year=
Accelerating Reinforcement Learning of Robotic Manipulations via Feedback from Large Language Models , author=. arXiv preprint arXiv:2311.02379 , year=
-
[26]
International Conference on Machine Learning , pages=
Zero-shot reward specification via grounded natural language , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[27]
International Conference on Machine Learning , pages=
Learning transferable visual models from natural language supervision , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[28]
2023 , editor =
Ma, Yecheng Jason and Kumar, Vikash and Zhang, Amy and Bastani, Osbert and Jayaraman, Dinesh , booktitle =. 2023 , editor =
2023
-
[29]
RoboCLIP: one demonstration is enough to learn robot policies , year =
Sontakke, Sumedh A and Zhang, Jesse and Arnold, S\'. RoboCLIP: one demonstration is enough to learn robot policies , year =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
-
[30]
NeurIPS 2023 Foundation Models for Decision Making Workshop , year=
Vision-Language Models are Zero-Shot Reward Models for Reinforcement Learning , author=. NeurIPS 2023 Foundation Models for Decision Making Workshop , year=
2023
-
[31]
2023 , eprint=
Language Reward Modulation for Pretraining Reinforcement Learning , author=. 2023 , eprint=
2023
-
[32]
Proceedings of The 4th Annual Learning for Dynamics and Control Conference , pages =
Can Foundation Models Perform Zero-Shot Task Specification For Robot Manipulation? , author =. Proceedings of The 4th Annual Learning for Dynamics and Control Conference , pages =. 2022 , editor =
2022
-
[33]
and Harada, Daishi and Russell, Stuart J
Ng, Andrew Y. and Harada, Daishi and Russell, Stuart J. , title =. Proceedings of the Sixteenth International Conference on Machine Learning , pages =. 1999 , isbn =
1999
-
[34]
International Conference on Autonomous Agents and Multiagent Systems,
Sam Devlin and Daniel Kudenko , title =. International Conference on Autonomous Agents and Multiagent Systems,. 2012 , url =
2012
-
[35]
Reward Shaping in Episodic Reinforcement Learning , year =
Grze\'. Reward Shaping in Episodic Reinforcement Learning , year =. Proceedings of the 16th Conference on Autonomous Agents and MultiAgent Systems , pages =
-
[36]
Theoretical and Empirical Analysis of Reward Shaping in Reinforcement Learning , year=
Grzes, Marek and Kudenko, Daniel , booktitle=. Theoretical and Empirical Analysis of Reward Shaping in Reinforcement Learning , year=
-
[37]
M. Using incomplete and incorrect plans to shape reinforcement learning in long-sequence sparse-reward tasks , journal=. 2025 , month=. doi:10.1007/s00521-024-10615-2 , url=
-
[38]
Improving the Effectiveness of Potential-based Reward Shaping in Reinforcement Learning , year =
M\". Improving the Effectiveness of Potential-based Reward Shaping in Reinforcement Learning , year =. Proceedings of the 24th International Conference on Autonomous Agents and Multiagent Systems , pages =
-
[39]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
DeepSynth: Automata Synthesis for Automatic Task Segmentation in Deep Reinforcement Learning , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2021 , month=. doi:10.1609/aaai.v35i9.16935 , number=
-
[40]
A framework for flexibly guiding learning agents , journal =
Elbarbari, Mahmoud and Delgrange, Florent and Vervlimmeren, Ivo and Efthymiadis, Kyriakos and Vanderborght, Bram and Nowe, Ann , year =. A framework for flexibly guiding learning agents , journal =
-
[41]
and Chernova, Sonia , title =
Suay, Halit Bener and Brys, Tim and Taylor, Matthew E. and Chernova, Sonia , title =. Proceedings of the 2016 International Conference on Autonomous Agents & Multiagent Systems , pages =. 2016 , isbn =
2016
-
[42]
Wu, Yuchen and Mozifian, Melissa and Shkurti, Florian , title =. 2021 , publisher =. doi:10.1109/ICRA48506.2021.9561333 , booktitle =
-
[43]
and Now\'
Brys, Tim and Harutyunyan, Anna and Suay, Halit Bener and Chernova, Sonia and Taylor, Matthew E. and Now\'. Reinforcement Learning from Demonstration through Shaping , year =. Proceedings of the 24th International Conference on Artificial Intelligence , pages =
-
[44]
Proceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems , pages =
Wang, Caroline and Warnell, Garrett and Stone, Peter , title =. Proceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems , pages =. 2023 , isbn =
2023
-
[45]
Improving Sample Efficiency of Reinforcement Learning With Background Knowledge From Large Language Models , year=
Zhang, Fuxiang and Li, Junyou and Li, Yi-Chen and Zhang, Zongzhang and Yu, Yang and Ye, Deheng , journal=. Improving Sample Efficiency of Reinforcement Learning With Background Knowledge From Large Language Models , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.