LLM-Based Examination of Eligibility Criteria from Securities Prospectuses at the German Central Bank
Pith reviewed 2026-06-26 03:53 UTC · model grok-4.3
The pith
LLM-based systems verify securities eligibility from prospectuses at up to 91% precision with a conservative bias that limits false approvals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
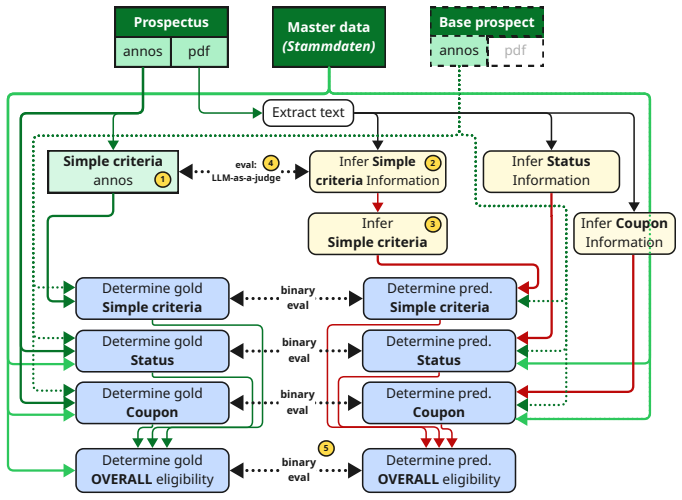
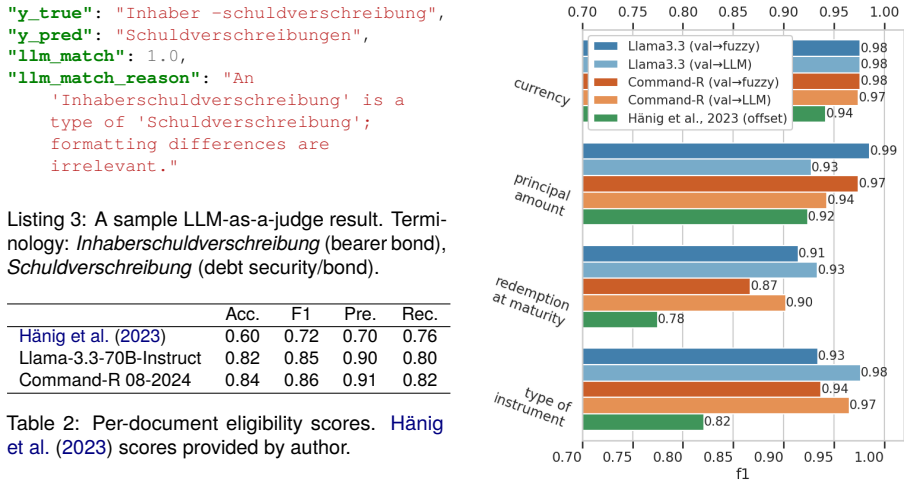
LLM-based systems achieve high precision (up to 91%) in document-level eligibility examination of securities prospectuses, exhibiting a conservative operating profile that minimizes false acceptance. The task is handled through a generative information extraction pipeline that decomposes into extraction, normalization, and interpretation steps and is assessed with a value-based LLM-as-a-judge methodology that provides semantic rather than location-based scoring.
What carries the argument
Generative information extraction pipeline that splits eligibility verification into extraction, normalization, and interpretation stages, paired with LLM-as-a-judge for semantic evaluation of outputs.
If this is right
- Traditional NER approaches can be supplemented or replaced for handling OCR noise, linguistic variance, and bilingual text in financial documents.
- Document-level eligibility decisions can be produced with high precision while maintaining a low rate of false acceptances.
- Value-based LLM-as-a-judge scoring offers a semantic alternative to exact-span metrics for assessing extraction and interpretation quality.
- Automation of this pipeline could reduce the manual workload for collateral eligibility checks at institutions handling prospectuses.
Where Pith is reading between the lines
- The conservative profile may let the system serve as an initial filter that routes only borderline cases to human reviewers.
- The same decomposition into extraction-normalization-interpretation steps could transfer to other regulatory checks on semi-structured financial filings.
- Prompt adjustments or model selection might raise recall while preserving the low false-acceptance behavior observed here.
- Expanding tests to prospectuses from different jurisdictions or time periods would test whether the precision holds outside the current corpus.
Load-bearing premise
The LLM-as-a-judge value-based evaluation provides a more accurate semantic measure of eligibility determination quality than traditional location-based metrics.
What would settle it
Independent human experts reviewing the same set of prospectuses and counting cases where the LLM system accepts securities that the humans deem ineligible.
Figures

read the original abstract
Verifying the eligibility of securities as collateral is a key responsibility of the German Central Bank. However, manually verifying these assets against legal and financial criteria within lengthy, semi-structured, and often bilingual prospectuses is a resource-intensive task. While previous efforts utilized traditional Named Entity Recognition (NER) for information extraction, these methods can struggle with OCR noise, linguistic variance, and rigid span-based constraints, and the need for manually annotated training data for each relevant annotation type. In this paper, we present the first case study applying Large Language Models (LLMs) to the eligibility examination process, shifting the paradigm toward a generative Information Extraction pipeline. Our approach decomposes the task into extraction, normalization, and interpretation, allowing for greater flexibility in handling noisy text and interleaved German-English content. We further introduce a value-based evaluation methodology using LLM-as-a-judge, which offers a more semantic assessment than location-based metrics. Our results demonstrate that LLM-based systems achieve high precision (up to 91%) in document-level eligibility, exhibiting a conservative operating profile that minimizes false acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the first case study applying LLMs to eligibility verification of securities as collateral from lengthy, semi-structured, often bilingual prospectuses at the German Central Bank. It decomposes the task into a generative information extraction pipeline consisting of extraction, normalization, and interpretation steps to handle OCR noise and linguistic variance better than prior NER approaches. The authors introduce a value-based evaluation methodology using LLM-as-a-judge for semantic assessment and report that LLM-based systems achieve up to 91% document-level precision while maintaining a conservative profile that minimizes false acceptances.
Significance. If the central results hold under validated evaluation, the work could meaningfully advance automation of high-stakes financial document review by offering greater flexibility than span-based NER and reducing manual effort in central banking compliance. The emphasis on a conservative false-acceptance profile aligns well with regulatory risk tolerance.
major comments (1)
- [value-based evaluation methodology] The value-based evaluation methodology (described in the abstract and evaluation section) relies on LLM-as-a-judge without any reported human-expert labels, inter-annotator agreement, or calibration set against which the judge's eligibility decisions are measured. This makes the headline 91% precision claim dependent on the untested assumption that the LLM judge's semantic notion of eligibility coincides with the legal and financial criteria applied by the German Central Bank.
minor comments (1)
- [Abstract] The abstract reports positive results but omits details on experimental setup, specific models, dataset size, and statistical significance; these should be summarized early in the main text for clarity.
Simulated Author's Rebuttal
We appreciate the referee's positive assessment of the paper's novelty and potential impact on automating high-stakes financial document review. We address the major comment on the value-based evaluation methodology point by point below.
read point-by-point responses
-
Referee: [value-based evaluation methodology] The value-based evaluation methodology (described in the abstract and evaluation section) relies on LLM-as-a-judge without any reported human-expert labels, inter-annotator agreement, or calibration set against which the judge's eligibility decisions are measured. This makes the headline 91% precision claim dependent on the untested assumption that the LLM judge's semantic notion of eligibility coincides with the legal and financial criteria applied by the German Central Bank.
Authors: We agree that validating the LLM-as-a-judge against human expert annotations is crucial for establishing the reliability of our value-based evaluation, particularly given the high-stakes nature of the application. The manuscript currently presents the LLM judge as a practical proxy for semantic assessment, drawing on its established use in similar NLP tasks, but does not include a direct calibration against Central Bank experts. In the revised manuscript, we will add a section detailing a calibration study: we will have a small set of prospectuses (e.g., 20-30 documents) annotated for eligibility by domain experts, compute inter-annotator agreement, and measure agreement between the LLM judge and the expert consensus. This will allow us to report the alignment and any discrepancies, thereby grounding the 91% precision claim. We believe this addresses the concern while preserving the innovative aspects of the generative pipeline. revision: yes
Circularity Check
No significant circularity; evaluation protocol is independent of the extraction pipeline
full rationale
The paper introduces an LLM-based extraction pipeline and separately introduces an LLM-as-a-judge evaluation protocol. The reported 91% document-level precision is an empirical outcome measured by the judge on the pipeline outputs, not a quantity derived by algebraic identity, parameter fitting to the same data, or self-citation chain. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The evaluation method is novel within the paper but does not reduce the headline result to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can effectively handle noisy OCR text and bilingual content in prospectuses through generative extraction, normalization, and interpretation.
Reference graph
Works this paper leans on
-
[1]
Kydlı́ček, Hynek and Penedo, Guilherme and von Werra, Leandro , year =
-
[2]
Farquhar, Sebastian and Gal, Yarin and Rainforth, Tom , month = may, year =. On. doi:10.48550/arXiv.2101.11665 , abstract =
-
[3]
Kossen, Jannik and Farquhar, Sebastian and Gal, Yarin and Rainforth, Tom , month = jun, year =. Active. doi:10.48550/arXiv.2103.05331 , abstract =
-
[4]
Berrada, Gabrielle and Kossen, Jannik and Razzak, Muhammed and Smith, Freddie Bickford and Gal, Yarin and Rainforth, Tom , month = aug, year =. Scaling. doi:10.48550/arXiv.2508.09093 , abstract =
-
[5]
and Sitawarin, Chawin and Guo, Chuan and Kokhlikyan, Narine and Suh, G
Morris, John X. and Sitawarin, Chawin and Guo, Chuan and Kokhlikyan, Narine and Suh, G. Edward and Rush, Alexander M. and Chaudhuri, Kamalika and Mahloujifar, Saeed , month = jun, year =. How much do language models memorize? , url =. doi:10.48550/arXiv.2505.24832 , abstract =
-
[6]
Gienapp, Lukas and Hagen, Tim and Fröbe, Maik and Hagen, Matthias and Stein, Benno and Potthast, Martin and Scells, Harrisen , month = apr, year =. The. doi:10.1145/3726302.3730093 , abstract =
-
[7]
Singh, Shivalika and Nan, Yiyang and Wang, Alex and D'Souza, Daniel and Kapoor, Sayash and Üstün, Ahmet and Koyejo, Sanmi and Deng, Yuntian and Longpre, Shayne and Smith, Noah and Ermis, Beyza and Fadaee, Marzieh and Hooker, Sara , month = apr, year =. The. doi:10.48550/arXiv.2504.20879 , abstract =
-
[8]
Zhong, Ming and Liu, Yang and Yin, Da and Mao, Yuning and Jiao, Yizhu and Liu, Pengfei and Zhu, Chenguang and Ji, Heng and Han, Jiawei , month = oct, year =. Towards a. doi:10.48550/arXiv.2210.07197 , abstract =
-
[9]
Chan, David and Petryk, Suzanne and Gonzalez, Joseph and Darrell, Trevor and Canny, John , year =. Proceedings of the 2023. doi:10.18653/v1/2023.emnlp-main.841 , language =
-
[10]
Lin, Yen-Ting and Chen, Yun-Nung , year =. Proceedings of the 5th. doi:10.18653/v1/2023.nlp4convai-1.5 , language =
-
[11]
Liu, Yinhong and Zhou, Han and Guo, Zhijiang and Shareghi, Ehsan and Vulić, Ivan and Korhonen, Anna and Collier, Nigel , month = jan, year =. Aligning with. doi:10.48550/arXiv.2403.16950 , abstract =
-
[14]
Computational Linguistics , author =. 2025 , pages =. doi:10.1162/coli_a_00561 , abstract =
-
[15]
BERTScore: Evaluating Text Generation with BERT
Zhang, Tianyi and Kishore, Varsha and Wu, Felix and Weinberger, Kilian Q. and Artzi, Yoav , month = feb, year =. doi:10.48550/arXiv.1904.09675 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1904.09675 1904
-
[16]
GPTScore: Evaluate as You Desire
Fu, Jinlan and Ng, See-Kiong and Jiang, Zhengbao and Liu, Pengfei , month = feb, year =. doi:10.48550/arXiv.2302.04166 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.04166
-
[17]
Wang, Alex and Cho, Kyunghyun and Lewis, Mike , month = apr, year =. Asking and. doi:10.48550/arXiv.2004.04228 , abstract =
-
[18]
Gopalakrishnan, Karthik and Hedayatnia, Behnam and Chen, Qinlang and Gottardi, Anna and Kwatra, Sanjeev and Venkatesh, Anu and Gabriel, Raefer and Hakkani-Tur, Dilek , month = aug, year =. Topical-. doi:10.48550/arXiv.2308.11995 , abstract =
-
[19]
Transactions of the Association for Computational Linguistics , author =. 2021 , pages =. doi:10.1162/tacl_a_00373 , abstract =
-
[20]
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang , month = may, year =. G-. doi:10.48550/arXiv.2303.16634 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.16634
-
[21]
doi:10.48550/arXiv.2407.11691 , abstract =
Duan, Haodong and Yang, Junming and Qiao, Yuxuan and Fang, Xinyu and Chen, Lin and Liu, Yuan and Agarwal, Amit and Chen, Zhe and Li, Mo and Ma, Yubo and Sun, Hailong and Zhao, Xiangyu and Cui, Junbo and Dong, Xiaoyi and Zang, Yuhang and Zhang, Pan and Wang, Jiaqi and Lin, Dahua and Chen, Kai , month = sep, year =. doi:10.48550/arXiv.2407.11691 , abstract =
-
[22]
Jacob, Marc , month = feb, year =. German. doi:10.7910/DVN/FSCDPI , abstract =
-
[23]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and Mathur, Akhil and Schelten, Alan and Vaughan, Alex and Yang, Amy and Fan, Angela and Goyal, Anirudh and Hartshorn, Anthony and Yang, Aobo and Mitra, Archi and Sravankumar, Archie and Korenev, Artem and Hinsvark, A...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[24]
doi:10.48550/arXiv.2411.15296 , abstract =
Fu, Chaoyou and Zhang, Yi-Fan and Yin, Shukang and Li, Bo and Fang, Xinyu and Zhao, Sirui and Duan, Haodong and Sun, Xing and Liu, Ziwei and Wang, Liang and Shan, Caifeng and He, Ran , month = dec, year =. doi:10.48550/arXiv.2411.15296 , abstract =
-
[25]
Proceedings of the 2024 joint international conference on computational linguistics, language resources and evaluation (
Hamotskyi, Serhii and Kozaeva, Nata and Hänig, Christian , editor =. Proceedings of the 2024 joint international conference on computational linguistics, language resources and evaluation (. 2024 , pages =
2024
-
[26]
Development and evaluation of a
Kozaeva, Nata and Hamotskyi, Serhii and Hanig, Christian , editor =. Development and evaluation of a. Proceedings of the joint workshop of the 7th financial technology and natural language processing, the 5th knowledge discovery from unstructured data in financial services, and the 4th workshop on economics and natural language processing , publisher =. 2...
2024
-
[27]
Proceedings of the
Krieg-Holz, Ulrike and Schuschnig, Christian and Matthies, Franz and Redling, Benjamin and Hahn, Udo , editor =. Proceedings of the. 2016 , pages =
2016
-
[28]
Proceedings of
Hänig, Christian and Schlösser, Markus and Hamotskyi, Serhii and Zambaku, Gent and Blankenburg, Janek , year =. Proceedings of
-
[29]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
2025 , note =. doi:10.48550/arXiv.2501.12948 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12948 2025
-
[31]
Docling technical report , url =. 2024 , note =. doi:10.48550/arXiv.2408.09869 , author =
-
[34]
Deduplicating
Lee, Katherine and Ippolito, Daphne and Nystrom, Andrew and Zhang, Chiyuan and Eck, Douglas and Callison-Burch, Chris and Carlini, Nicholas , month = mar, year =. Deduplicating
-
[36]
Ali, Syed Musharraf and Deu. Automatic. Proceedings of the Northern Lights Deep Learning Workshop , volume =. doi:10.7557/18.6816 , url =
-
[37]
Biesner, David and Ramamurthy, Rajkumar and Stenzel, Robin and L. Anonymization of. Int J Data Sci Anal , volume =. doi:10.1007/s41060-021-00285-x , url =
-
[40]
Chu, Zhixuan and Guo, Huaiyu and Zhou, Xinyuan and Wang, Yijia and Yu, Fei and Chen, Hong and Xu, Wanqing and Lu, Xin and Cui, Qing and Li, Longfei and Zhou, Jun and Li, Sheng , year = 2023, month = nov, number =. Data-. doi:10.48550/arXiv.2310.17784 , url =. arXiv , keywords =:2310.17784 , primaryclass =
-
[42]
Proceedings of the Twelfth Language Resources and Evaluation Conference , author =
-
[44]
Farimani, Saeede Anbaee and Jahan, Majid Vafaei and Milani Fard, Amin , year = 2022, month = sep, journal =. From. doi:10.3390/info13100466 , url =
-
[45]
ColPali: Efficient Document Retrieval with Vision Language Models
Faysse, Manuel and Sibille, Hugues and Wu, Tony and Omrani, Bilel and Viaud, Gautier and Hudelot, C. doi:10.48550/arXiv.2407.01449 , url =. arXiv , keywords =:2407.01449 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.01449
-
[48]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (
Hamotskyi, Serhii and Kozaeva, Nata and H. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (
2024
-
[49]
Jay, Rabi , year = 2024, pages =. Introduction to. Generative. doi:10.1007/979-8-8688-0882-1_1 , url =
-
[50]
Kang, Juyeon and Patel, Mauli Mehulkumar and Agrawal, Anushka and Sevitha, Simhadri and Srinivasa, R and Bellato, Sandra and Anand Kumar, M and Tsang, Ngawang Dempa and. Advancements in. 2023. doi:10.1109/BigData59044.2023.10386125 , url =
-
[51]
doi:10.48550/arXiv.2111.15664 , url =
Kim, Geewook and Hong, Teakgyu and Yim, Moonbin and Nam, Jeongyeon and Park, Jinyoung and Yim, Jinyeong and Hwang, Wonseok and Yun, Sangdoo and Han, Dongyoon and Park, Seunghyun , year = 2022, month = oct, number =. doi:10.48550/arXiv.2111.15664 , url =. arXiv , keywords =:2111.15664 , primaryclass =
-
[52]
Development and Evaluation of a. Proceedings of the Joint Workshop of the 7th Financial Technology and Natural Language Processing, the 5th Knowledge Discovery from Unstructured Data in Financial Services, and the 4th Workshop on Economics and Natural Language Processing , author =
-
[53]
Lam, Laurent and Ratnamogan, Pirashanth and Tang, Jo. Information. Document. doi:10.1007/978-3-031-41679-8_12 , url =
-
[55]
Li, Minghan and Luo, Miyang and Lv, Tianrui and Zhang, Yishuai and Zhao, Siqi and Nie, Ercong and Zhou, Guodong , year = 2025, month = oct, number =. A. doi:10.48550/arXiv.2509.07759 , url =. arXiv , keywords =:2509.07759 , primaryclass =
-
[56]
Liusie, Adian and Manakul, Potsawee and Gales, Mark J. F. , year = 2024, month = feb, number =. doi:10.48550/arXiv.2307.07889 , url =. arXiv , keywords =:2307.07889 , primaryclass =
-
[58]
Financial Named Entity Recognition:
Lu, Yi-Te and Huo, Yintong , editor =. Financial Named Entity Recognition:. Proceedings of the Joint Workshop of the 9th Financial Technology and Natural Language Processing (
-
[60]
Kani and Sridhar, Rajeswari , editor =
Sumithra, M. Kani and Sridhar, Rajeswari , editor =. Information. Evolving. doi:10.1007/978-981-15-7804-5_20 , url =
- [61]
-
[62]
Advances in neural information processing systems , volume =
Attention Is All You Need , author =. Advances in neural information processing systems , volume =
-
[63]
Villota, Jesus , year = 2025, publisher =. Structured. doi:10.2139/ssrn.5636430 , url =
-
[64]
arXiv , keywords =:2303.17564 , primaryclass =
Wu, Shijie and Irsoy, Ozan and Lu, Steven and Dabravolski, Vadim and Dredze, Mark and Gehrmann, Sebastian and Kambadur, Prabhanjan and Rosenberg, David and Mann, Gideon , year = 2023, month = dec, number =. arXiv , keywords =:2303.17564 , primaryclass =
Pith/arXiv arXiv 2023
-
[67]
Effects of Inserting Domain Vocabulary and Fine-Tuning
Yeung, Chin Man , year = 2019, month = nov, url =. Effects of Inserting Domain Vocabulary and Fine-Tuning
2019
-
[68]
Zhang, Qintong and Wang, Bin and Huang, Victor Shea-Jay and Zhang, Junyuan and Wang, Zhengren and Liang, Hao and He, Conghui and Zhang, Wentao , year = 2024, publisher =. Document. doi:10.48550/ARXIV.2410.21169 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.21169 2024
-
[69]
Zhu, Yutao and Yuan, Huaying and Wang, Shuting and Liu, Jiongnan and Liu, Wenhan and Deng, Chenlong and Chen, Haonan and Liu, Zheng and Dou, Zhicheng and Wen, Ji-Rong , year = 2026, month = jan, journal =. Large. doi:10.1145/3748304 , url =
-
[70]
Lars Ackermann, Julian Neuberger, Martin K \"a ppel, and Stefan Jablonski. 2023. https://doi.org/10.1007/978-3-031-34560-9_28 Bridging Research Fields : An Empirical Study on Joint , Neural Relation Extraction Techniques . In Marta Indulska, Iris Reinhartz-Berger , Carlos Cetina, and Oscar Pastor, editors, Advanced Information Systems Engineering , volume...
-
[71]
Ga \"e tan Caillaut, Raheel Qader, Jingshu Liu, Mariam Nakhl \'e , Arezki Sadoune, Massinissa Ahmim, and Jean-Gabriel Barthelemy. 2025. https://doi.org/10.48550/arXiv.2511.08621 The LLM Pro Finance Suite : Multilingual Large Language Models for Financial Applications
-
[72]
Lun-Chi Chen, Hsin-Tzu Weng, Mayuresh Sunil Pardeshi, Chien-Ming Chen, Ruey-Kai Sheu, and Kai-Chih Pai. 2025. https://doi.org/10.3390/electronics14112145 Evaluation of Prompt Engineering on the Performance of a Large Language Model in Document Information Extraction . Electronics, 14(11):2145
-
[73]
u rkan Solmaz, and Jonathan F \
Gaye Colakoglu, G \"u rkan Solmaz, and Jonathan F \"u rst. 2025. https://doi.org/10.18653/v1/2025.findings-emnlp.973 Problem solved? Information extraction design space for layout-rich documents using LLMs . In Findings of the Association for Computational Linguistics: EMNLP 2025 , pages 17908--17927, Suzhou, China. Association for Computational Linguistics
-
[74]
European Central Bank . 2017. https://doi.org/10.2866/176048 The Eurosystem Collateral Framework Explained . Publications Office, LU
-
[75]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle , Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. http://arxiv.org/abs/2407.21783 The llama 3 herd of models . arXiv preprint arXiv:2407.21783
Pith/arXiv arXiv 2024
-
[76]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Yuanzhuo Wang, Wen Gao, Lionel Ni, and Jian Guo. 2025. https://doi.org/10.48550/arXiv.2411.15594 A Survey on LLM-as-a-Judge
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2411.15594 2025
-
[77]
Serhii Hamotskyi, Nata Kozaeva, and Christian H \"a nig. 2024. https://aclanthology.org/2024.lrec-main.639/ FinCorpus-DE10k : A corpus for the German financial domain . In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation ( LREC-COLING 2024) , pages 7277--7285, Torino, Italia. ELRA and ICCL
2024
-
[78]
Christian H \"a nig, Markus Schl \"o sser, Serhii Hamotskyi, Gent Zambaku, and Janek Blankenburg. 2023. https://arxiv.org/abs/2302.04562 NLP-based Decision Support System for Examination of Eligibility Criteria from Securities Prospectuses at the German Central Bank . In Proceedings of AAAI23 Bridge 8: AI for Financial Institutions , Washington, D. C., USA
arXiv 2023
-
[79]
Nata Kozaeva, Serhii Hamotskyi, and Christian Hanig. 2024. https://aclanthology.org/2024.finnlp-1.5/ Development and evaluation of a German language model for the financial domain . In Proceedings of the Joint Workshop of the 7th Financial Technology and Natural Language Processing, the 5th Knowledge Discovery from Unstructured Data in Financial Services,...
2024
-
[80]
David Kuo Chuen Lee, Chong Guan, Yinghui Yu, and Qinxu Ding. 2024. https://doi.org/10.3390/fintech3030025 A Comprehensive Review of Generative AI in Finance . FinTech, 3(3):460--478
-
[81]
Nikolaos Livathinos, Christoph Auer, Maksym Lysak, Ahmed Nassar, Michele Dolfi, Panos Vagenas, Cesar Berrospi Ramis, Matteo Omenetti, Kasper Dinkla, Yusik Kim, Shubham Gupta, Rafael Teixeira de Lima, Valery Weber, Lucas Morin, Ingmar Meijer, Viktor Kuropiatnyk, and Peter W. J. Staar. 2025. https://doi.org/10.48550/arXiv.2501.17887 Docling: An Efficient Op...
-
[82]
Yi-Te Lu and Yintong Huo. 2025. https://aclanthology.org/2025.finnlp-1.15/ Financial named entity recognition: How far can LLM go? In Proceedings of the Joint Workshop of the 9th Financial Technology and Natural Language Processing ( FinNLP ), the 6th Financial Narrative Processing ( FNP ), and the 1st Workshop on Large Language Models for Finance and Leg...
2025
-
[83]
Julian Neuberger, Lars Ackermann, Han van der Aa, and Stefan Jablonski. 2024. https://doi.org/10.48550/arXiv.2407.18540 A Universal Prompting Strategy for Extracting Process Model Information from Natural Language Text using Large Language Models
-
[84]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems, 30
2017
-
[85]
Qianqian Xie, Weiguang Han, Zhengyu Chen, Ruoyu Xiang, Xiao Zhang, Yueru He, Mengxi Xiao, Dong Li, Yongfu Dai, Duanyu Feng, Yijing Xu, Haoqiang Kang, Ziyan Kuang, Chenhan Yuan, Kailai Yang, Zheheng Luo, Tianlin Zhang, Zhiwei Liu, Guojun Xiong, Zhiyang Deng, Yuechen Jiang, Zhiyuan Yao, Haohang Li, Yangyang Yu, Gang Hu, Jiajia Huang, Xiao-Yang Liu, Alejandr...
-
[86]
Yi Yang, Mark Christopher Siy UY, and Allen Huang. 2020. http://arxiv.org/abs/2006.08097 FinBERT : A Pretrained Language Model for Financial Communications
arXiv 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.